
Abstract
Decomposing a network flow into weighted paths is a problem with numerous applications, ranging from networking, transportation planning, to bioinformatics. In some applications we look for a decomposition that is optimal with respect to some property, such as the number of paths used, robustness to edge deletion, or length of the longest path. However, in many bioinformatic applications, we seek a specific decomposition where the paths correspond to some underlying data that generated the flow. In these cases, no optimization criteria guarantee the identification of the correct decomposition. Therefore, we propose to instead report the safe paths, which are subpaths of at least one path in every flow decomposition. In this work, we give the first local characterization of safe paths for flow decompositions in directed acyclic graphs, leading to a practical algorithm for finding the complete set of safe paths. In addition, we evaluate our algorithm on RNA transcript data sets against a trivial safe algorithm (extended unitigs), the recently proposed safe paths for path covers (TCBB 2021) and the popular heuristic greedy-width. On the one hand, we found that besides maintaining perfect precision, our safe and complete algorithm reports a significantly higher coverage (
1. INTRODUCTION
Network flows are a central topic in computer science, enabling us to define problems with countless practical applications. Assuming that the flow network has a unique source s and a unique sink t, every flow can be decomposed into a collection of weighted s–t paths and cycles (Ford and Fulkerson, 2010); for directed acyclic graphs (DAGs), such a decomposition contains only paths. One application of such a view of a flow is to indicate how to optimally route information or goods from s to t. For example, flow decomposition is a key step in network routing problems (Cohen et al, 2014; Hartman et al, 2012; Hong et al, 2013; Mumey et al, 2015) and transportation problems (Ohst, 2015; Olsen et al, 2022).
Finding the decomposition with the minimum number of paths and possibly cycles (or minimum flow decomposition) is NP-hard, even if the flow network is a DAG (Vatinlen et al, 2008). On the theoretical side, this hardness result led to research on approximation algorithms (Baier et al, 2005; Baier et al, 2002; Hartman et al, 2012; Mumey et al, 2015; Suppakitpaisarn, 2016; Pieńkosz and Kołtyś, 2015) and FPT algorithms (Kloster et al, 2018). On the practical side, many approaches usually use a standard greedy-width heuristic (Vatinlen et al, 2008), of repeatedly removing an s–t path carrying the most amount of flow. Another pseudopolynomial-time heuristic called Catfish was recently proposed by Shao and Kingsford (2017b), which tries to iteratively simplify the graph so that smaller decompositions can be found.
Many applications study flow networks built by superimposing a set of weighted paths, and seek the decomposition corresponding to that underlying set of paths and weights. This is the decomposition sought by the more recent and prominent application of reconstructing biological sequences [RNA transcripts (Bernard et al, 2013; Gatter and Stadler, 2019; Pertea et al, 2015; Tomescu et al, 2015; Tomescu et al, 2013; Williams et al, 2019) or viral quasispecies genomes (Baaijens et al, 2020; Baaijens et al, 2019)]. Each flow path represents a reconstructed sequence, and so, a different set of flow paths encode a different set of biological sequences, which may differ from the real ones.
If there are multiple flow decomposition solutions, then the reconstructed sequences may not match the original ones, and thus be incorrect. Williams et al (2021) analyzed an error-free transcript data set to find that 20% of the human genes admit multiple minimum flow decomposition solutions.
1.1. Overcoming multiple solutions
A first heuristic used to overcome the issue of multiple solutions (flow decompositions) was to seek one of minimum cardinality through different heuristics (Kloster et al, 2018; Pertea et al, 2015; Shao and Kingsford, 2017b; Tomescu et al, 2013) (since the problem is NP-hard). This approach was also used by transcript assemblers modeling the problem as a minimum path cover (Liu and Dickerson, 2017; Trapnell et al, 2010), which can be solved in polynomial time [see Cáceres et al (2021) for a comprehensive survey on the problem]. However, even when the solution is restricted to minimum cardinality, multiple solutions still arise (Caceres et al, 2021; Williams et al, 2021). Therefore, practical methods usually incorporate different variations of the minimum-cardinality criterion (Baaijens et al, 2020; Baaijens et al, 2019; Bernard et al, 2013).
Motivated by the RNA assembly application, Ma et al (2020a) were the first to address the issue of multiple solutions to the flow decomposition problem under a probabilistic framework. Later, they (Zheng et al, 2022) solved a problem (AND-Quant), which, in particular, leads to a quadratic-time algorithm for the following problem: given a flow in a DAG, and edges
We build upon the AND-Quant problem, by addressing the flow decomposition problem under the safety framework (Tomescu and Medvedev, 2017), first introduced for genome assembly. For a problem admitting multiple solutions, a partial solution is said to be safe if it appears in all solutions to the problem. In the case of the flow decomposition problem, a path P is safe if for every flow decomposition into paths
Safety has precursors in combinatorial optimization, under the name of persistency. For example, persistent edges present in all maximum bipartite matchings were studied by Costa (1994). Persistency has also been studied for the maximum flow problem, by finding that persistent edges always having a nonzero flow value in any maximum flow solution (Cechlárová and Lacko, 2001; Lacko, 1998), which is easily verified if the maximum flow decreases after removing the corresponding edge.
In bioinformatics, safety has been previously studied for the genome assembly problem, which at its core solves the problem of computing arc-covering walks on the assembly graph. Again since the problem admits multiple solutions where only one is correct, practical genome assemblers output only those solutions likely to be correct. The prominent approach dating back to 1995 (Kececioglu and Myers, 1995) is to compute trivially correct unitigs (having internal nodes with unit indegree and unit outdegree), which can be computed in linear time. Later, unitigs were generalized to be extended by adding their unique incoming and outgoing paths (Jackson, 2009; Kingsford et al, 2010; Medvedev et al, 2007; Pevzner et al, 2001).
These extended unitigs, although safe, are not guaranteed to report everything that can be correctly assembled, presenting an important open question (Boisvert et al, 2010; Bresler et al, 2013; Guénoche, 1992; Lam et al, 2014; Nagarajan and Pop, 2009; Shomorony et al, 2016) about the assembly limit (if any). This question was finally resolved by Tomescu and Medvedev (2017) [later optimized in Cairo et al (2021) and Cairo et al (2019)] for a specific genome assembly formulation (single circular walk) by introducing safe and complete algorithms, which report everything that can be theoretically reported as safe. Safe and complete algorithms were also studied by Acosta et al (2018) under a different genome assembly formulation of multiple circular walks.
Recently, Caceres et al (2021) studied safe and complete algorithms for path covers in an application on RNA assembly. They optimized an avoid-and-test approach for computing all maximal safe paths for constrained path covers, which were able to cover 70% of transcripts with a precision of more than 99% on splice graphs built from transcript annotation.
1.2. Flow decomposition in RNA assembly
The prominent application of flow decomposition in bioinformatics is the RNA transcript assembly, which is described as follows. In complex organisms, a gene may produce multiple RNA molecules (RNA transcripts, i.e., strings over an alphabet of four characters), each having a different abundance. Current high-throughput sequencing techniques (Wang et al, 2009) allow to partially read the RNA transcripts (and find their abundances) from a sample. This technology produces short overlapping substrings of the RNA transcripts. The main approach for recovering the RNA transcripts from such data is to build an edge-weighted DAG from these fragments, then to transform the weights into flow values by various optimization criteria, and finally to decompose the resulting flow into an “optimal” set of weighted paths (i.e., the RNA transcripts and their abundances in the sample) (Mäkinen et al, 2015).
A common approach used in practice is the popular greedy-width heuristic (Pertea et al, 2015; Tomescu et al, 2013). Greedy-width is also used in the related problem of viral quasispecies assembly (Baaijens et al, 2019; Fritz et al, 2021). Furthermore, some tools attempt to incorporate additional information into the flow decomposition process, such as by using longer reads or super reads (Gatter and Stadler, 2019; Pertea et al, 2015; Shao and Kingsford, 2017a; Williams et al, 2021). Despite the large number of tools and methods that have been developed for RNA transcript assembly, there is no method that consistently reports the correct set of transcripts (Pertea et al, 2015; Yu et al, 2020). All these, plus the promising results of safe and complete algorithms for constrained path covers (Caceres et al, 2021), suggest that addressing the problem under the safety framework may be a promising approach. However, while a safe and complete solution clearly gives the maximally reportable correct solution, it is significant to evaluate whether such a solution covers a large part of the true transcript, to be useful in practice. A possible application of such partial and reliable solutions is to consider them as constrains [see e.g., Williams et al (2021)] of real RNA transcript assemblers, to guide the assembly process of such heuristics. Another possible application could be to evaluate the accuracy of assemblers: does the output of the assembler include the safe and complete solution?
1.3. Our results
Our contributions can be succinctly described as follows.
1.
The previous work (Zheng et al, 2022) on AND-Quant describes a global characterization using the maximum flow of the entire graph transformed according to P, requiring
2.
This approach starts with a candidate solution and uses the characterization on its subpaths in an efficient manner [a similar approach was previously used by Costa (1994); Acosta et al (2018); Caceres et al (2021)]. In particular, since
The solution of the algorithm is reported using a compact representation (referred as
3.
Hence, the significance of our approach in quality parameters increases with the increase in complex graph instances in the data set, while the performance parameters are significantly better than greedy-width, without significantly losing performance over the previous safe algorithms.
2. PRELIMINARIES AND NOTATIONS
We consider a DAG
For any flow graph (DAG), a flow decomposition of it, it is a set of weighted paths
We would like to report all the maximal paths ending with e along which some
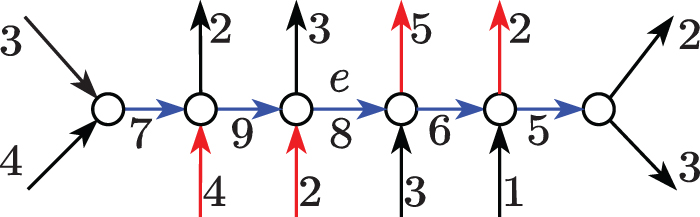
The prefix of the path (blue) up to e contributes at least 2 U of flow to e, as the rest may enter the path by the edges (red) with flow 4 and 2. Similarly, the suffix of the path (blue) from e maintains at least 1 U of flow from e, as the rest may exit the path from the edges (red) with flow 5 and 2. Both these safe paths are maximal as they cannot be extended left or right.
Previous notions of safety used in other problems naturally extend to flow decomposition as follows. Paths having internal nodes with unit indegree and unit outdegree are called unitigs (Kececioglu and Myers, 1995). Unitigs are trivially safe because every source-to-sink path passing through an edge of a unitig also passes through the entire unitig. Furthermore, a unitig can naturally be extended to include its unique incoming path (having nodes with unit indegree), and its unique outgoing path (having nodes with unit outdegree). This extension of a unitig is called the extended unitig (Jackson, 2009; Kingsford et al, 2010; Medvedev et al, 2007; Pevzner et al, 2001), which is also safe using the same argument.
For some graphs the above notions already define the safety of flow decomposition completely. Recently, Millani et al (2020) defined a class of DAGs called funnels, where every source-to-sink path is uniquely identifiable by at least one edge, which is not used by any other source-to-sink path. Hence, considering such an edge as a trivial unitig (having a single edge), its extended unitig is exactly the corresponding source-to-sink path, making it safe. Thus, in a funnel, all source-to-sink paths are naturally safe and hence trivially complete. Moreover, it implies that a funnel has a unique flow decomposition, making the problem trivial for funnel instances.
Proof. The forward direction of the equivalence was already discussed. For the reverse direction suppose by contradiction that G is not a funnel. Consider a minimal butterfly subgraph of G. As such, the body of this butterfly is a unitig in G. Since the first vertex of this unitig has an indegree greater than 1, and the last vertex of the unitig has an outdegree greater than 1, it is also an extended unitig. However, this path is not left or right maximal. Therefore, the set of maximal safe paths is not complete, a contradiction.
Finally, since flow decompositions are always constrained path covers, safe and complete paths for constrained path covers (Caceres et al, 2021) are potentially not complete for flow decompositions. The main hypothesis of our work is that the maximal safe paths for flow decompositions are significantly longer than the previous notions of safety for RNA transcript assembly.
3. CHARACTERIZATION AND PROPERTIES OF SAFE AND COMPLETE PATHS
The safety of a path can be characterized by its excess flow (see Fig. 2), defined as follows.
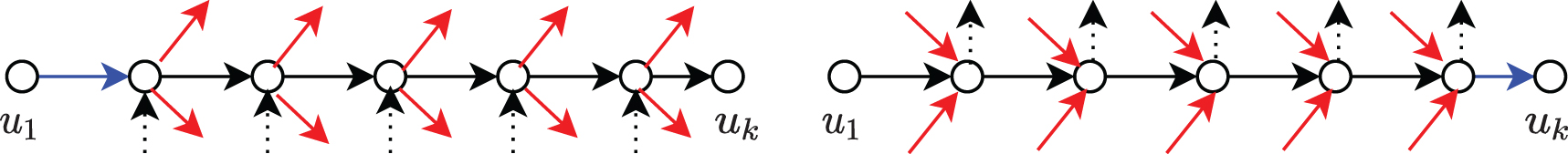
The excess flow of a path (left) is the incoming flow (blue) that necessarily passes through the whole path despite the flow (red) leaving the path at its internal vertices. It can be analogously described (right) as the outgoing flow (blue) that necessarily came through the whole path despite the flow (red) entering the path at its internal vertices.
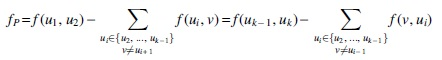
where the former and later equations are called diverging and converging formulations, respectively.
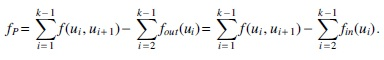
The converging and diverging formulations are equivalent by the conservation of flow on internal vertices. The idea behind the notion of an excess flow fP is that even in the worst case, the maximum leakage (see Fig. 2), that is, the flow leaving (or entering) P at the internal nodes, is the sum of the flow on the outgoing (or incoming) edges of the internal nodes of P, that are not in P. However, if the value of incoming flow (or outgoing flow) is higher than this maximum leakage, then this excess value fP necessarily passes through the entire P. The following results give the simple characterization and an additional property of safe paths.
Proof. The excess flow fP of a path P trivially makes it
We can repeat such modifications until flow on P is fP (or 0, if
Proof. Using the converging formulation in Remark 1, adding an edge at the start of a path modifies its excess flow by
4. SIMPLE VERIFICATION AND ENUMERATION ALGORITHMS
4.1. Verification algorithm
The characterization (Theorem 1) can be directly adapted to verify the safety of a path optimally. We preprocess the graph to compute the incoming flow
4.2. Enumeration of all maximal safe paths
Given a flow decomposition
The main idea of the algorithm is that it is possible to use two pointers to vertices delimiting a subpath
Caceres et al (2021) (Lemma 3) implement a safety test taking
4.3. Tightness and worst case for a simple enumeration algorithm
The example shown in Figure 3 demonstrates the worst case and the best case graphs where the simple enumeration algorithm is optimal, and inefficient, respectively. We have two paths

The worst case (left) and best case (right) graphs for the simple enumeration algorithm.
(1) In the worst case graph (left), the flow on the remaining edges is according to the flow conservation assuming a1 as the source and bk as the sink. Each edge in
(2) In the best case graph (right), the two edges from
5. EXPERIMENTAL EVALUATION
We now evaluate the performance of our safe and complete algorithm on the problem of RNA Assembly. We consider the flow networks representing splice graphs of simulated RNA-Seq experiments. That is, starting from a set of RNA transcripts, we simulate their expression levels and superimpose the transcripts to create a flow graph. Evaluating our approach in such perfect scenario allows us to remove the biases introduced by real RNA-Seq experiments (Srivastava et al, 2020) and focus the features offered by each technique instead. We say that the number k of transcripts or ground truth paths * is the complexity of the graph. Intuitively, the more paths in the ground truth, the harder to decompose the corresponding splice graph.
We first investigate the practical significance of safety by comparing our solution with the popular flow decomposition heuristic greedy-width. Greedy-width (Vatinlen et al, 2008) decomposes the flow by sequentially selecting the heaviest possible path, resulting in a simple algorithm that is both scalable and performs well in practice. However, flow decomposition algorithms may not always report the ground truth paths, but a different (incorrect) solution. Thus, it is important to measure the reported solution using a precision metric that evaluates the correctness of the solution. We thus investigate how the precision of greedy-width varies particularly as the value of k increases.
We then investigate the practical significance of completeness as reported by our solution, over the previously known safe solutions as reported by extended unitigs (recall Section 2) and safe paths for path covers of Caceres et al (2021) (recall Section 4.2). Note that every safe solution should be
Finally, to understand the overall impact of the different approaches, we combine the coverage and precision measures by computing their harmonic mean, that is, F-score. ‡ We thus investigate the variation in F-score over different values of k (graph complexities). In addition, to understand the practicality of the algorithms, we also measure their time and space performance.
5.1. Data sets
We consider two RNA transcript data sets, generated based on the approach of Shao and Kingsford (2017b). They created “perfect” flow graphs where the true set of transcripts and abundances is always a flow decomposition of the graph (which also means that the graphs satisfy conservation of flow). They start with a ground truth set of transcripts and abundances and create the input instances by superimposing these transcripts into a single flow graph with a unique source s pointing to the beginning of each transcript, and a unique sink t pointed from the end of each transcript.
5.1.1. Funnel instances
As described in Section 2, funnels (Millani et al, 2020) have a unique flow decomposition, thus making the problem trivial. As such, any flow decomposition algorithm (including greedy-width) reaches perfect scores in coverage and precision on these instances. Moreover, as shown in Theorem 4, this is also the case for extended unitigs, and thus for our safe and complete algorithm. Interestingly, safe paths for constrained path covers (Caceres et al, 2021) are not necessarily complete on funnels. § This means that for any flow decomposition algorithm (including greedy-width) and most safe algorithms (including extended unitigs and our safe and complete algorithm), the resulting paths always achieve the perfect value of coverage, precision, and F-score on funnel instances. As a result, funnels dilute the relative measures of the different algorithms.
Previously, Kloster et al (2018, Lemma 8) described a contraction of graphs that transforms funnels to trivial instances (
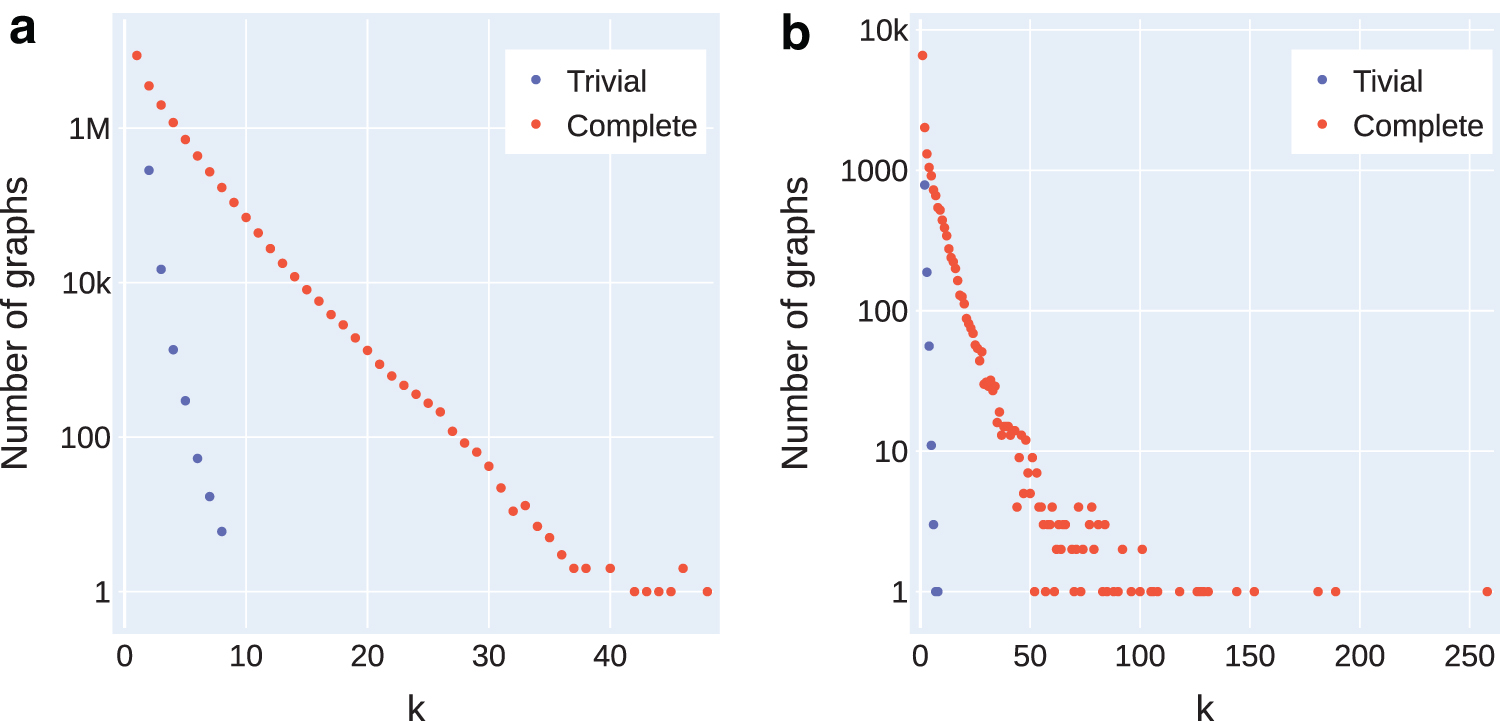
Distribution of graphs in the data sets by its complexity k with respect to the trivial instances (funnels).
5.1.2. Catfish data set
We consider the data set first used by Shao and Kingsford (2017b), which includes 100 simulated human transcriptomes for human, mouse, and zebrafish built using the Flux-Simulator (Griebel et al, 2012). In addition, it includes 1000 experiments from the Sequence Read Archive, with simulated abundances for transcripts using salmon (Patro et al, 2017). In both cases, the weighted transcripts are superimposed to build splice graphs as described above. This data set has also been used in other flow decomposition benchmarking studies (Kloster et al, 2018; Williams et al, 2021). There are 17,335,407 graphs in total in this data set, of which 8,301,682 are nontrivial (47.89%). The log-scale distribution of the complete data set (and its funnels) by k is shown in Figure 4a. However, in this data set, the details about the number of bases on each node (exons or pseudoexons) are omitted, only allowing us to compute the metrics in terms of nodes.
5.1.3. Reference-Sim data set
We modified the procedure described for building the splice graphs of the human transcriptome by Caceres et al (2021). For each transcript, we first simulate its expression level by sampling a value from the lognormal distribution
**
with mean and variance both equal to
5.2. Evaluation metrics
We compute the metric weighted precision, maximum relative coverage as done by Caceres et al (2021). In addition, we compute F-score as the harmonic mean of the other two. For the sake of completeness we explain them next.
5.2.1. Weighted precision
We classify a reported path R as correct if R is a subpath of some ground truth transcript T of the flow graph. Weighted precision is the total length of correctly reported paths divided by the total length of reported paths. The commonly used precision metric (Pertea et al, 2015; Shao and Kingsford, 2017a) for measuring the accuracy of RNA assembly methods considers only as correct those paths that are (almost) exactly contained in the ground truth decomposition, and precision is computed as the number of correctly reported paths divided by the total reported paths. However, since the safe algorithms report (possibly) partial transcripts, we use subpaths instead of (almost) exactly the same paths. To highlight how much is reported correctly instead of how many, we use weighted precision to give a better score for longer correctly reported paths.
5.2.2. Maximum relative coverage
Given a ground truth transcript T and a reported path R, we define a segment of R inside T as a maximal subpath of R that is also a subpath of T. We define the maximum relative coverage of T as the length of the longest segment of a reported path inside T, divided by the length of T. The corresponding value for the entire graph is the average of the values over all transcripts of the graph. While it is common in the literature (Pertea et al, 2015; Shao and Kingsford, 2017a) to report sensitivity (the proportion of ground truth transcripts correctly predicted), we measure sensitivity based on coverage since the safe algorithms report paths that (possibly) do not cover an entire transcript.
5.2.3. F-score
The standard measure to combine precision and sensitivity is using an F-score, which is the harmonic mean of the two. In our evaluation, we correspondingly use the weighted precision and the maximum relative coverage for computing the F-score.
We compute all metrics in terms of nodes and bases for the Reference-Sim data set. For the Catfish data sets, we only report them in terms of nodes.
5.3. Implementation and environment details
We evaluate the following approaches in our experiments.
5.3.1. SafePC
It computes the safe paths for path covers by using the implementation of Caceres et al (2021). We use
5.3.2. ExtUnitigs
It computes the extended unitigs, by considering each unitig including single edges, and extending it toward the left as long as the internal nodes have unit indegree, and toward the right as long as internal nodes have unit outdegree.
5.3.3. Safe&Comp
It computes the safe and complete paths for flow decomposition using our enumeration algorithm described in Section 4. However, since the metric evaluation scripts use each safe path individually (as reported by other algorithms), we output all safe paths separately instead of using
5.3.4. Greedy
It computes the greedy-width heuristic using Catfish (Shao and Kingsford, 2017b) with the -a greedy parameter.
All algorithms are implemented in C++, whereas the scripts for evaluating metrics are implemented in Python. SafePC, ExtUnitigs, and Safe&Comp implementations use optimization level 3 of GNU C++ (compiled with
5.4. Results
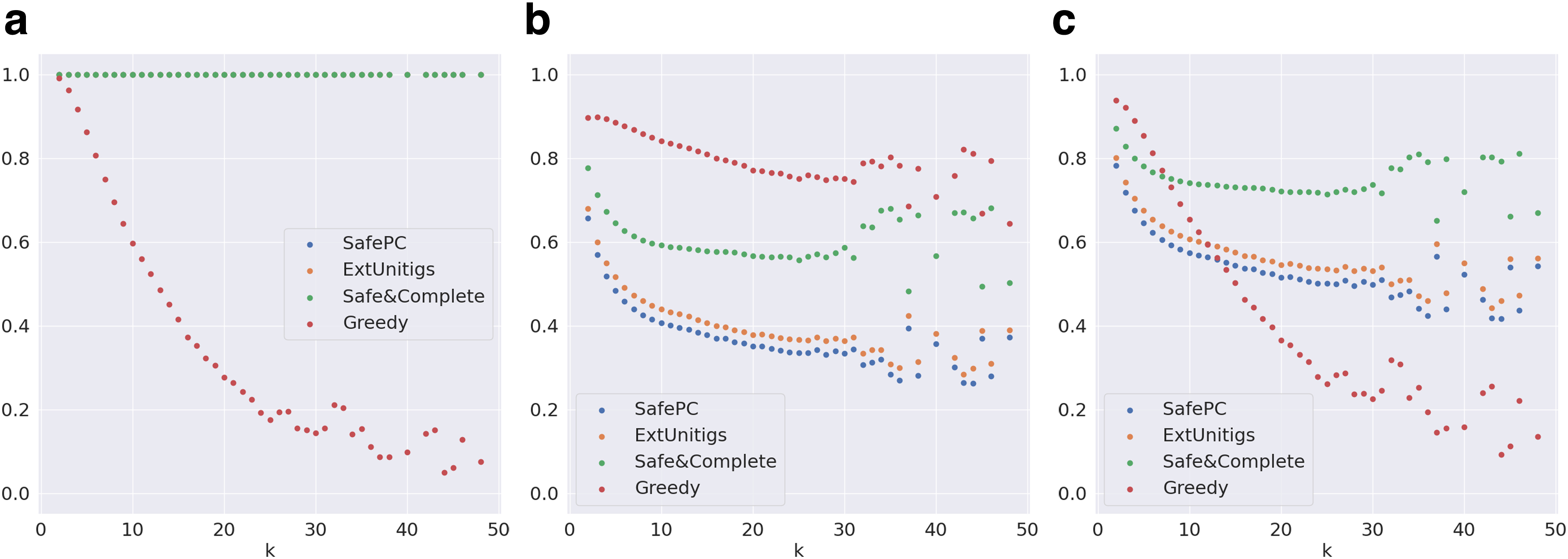
We first evaluate the significance of safety among the reported solutions. Figure 5a compares the weighted precision, distributed over the complexity k (number of transcripts in the ground truth), of all the algorithms on the Reference-Sim data set. Safe algorithms (except SafePC) report perfect precision as expected. In the case of SafePC, there is a small loss in precision due to the pruning of solutions performed by the algorithm. However, the precision of the Greedy algorithm sharply declines with the increase in k, almost linearly to
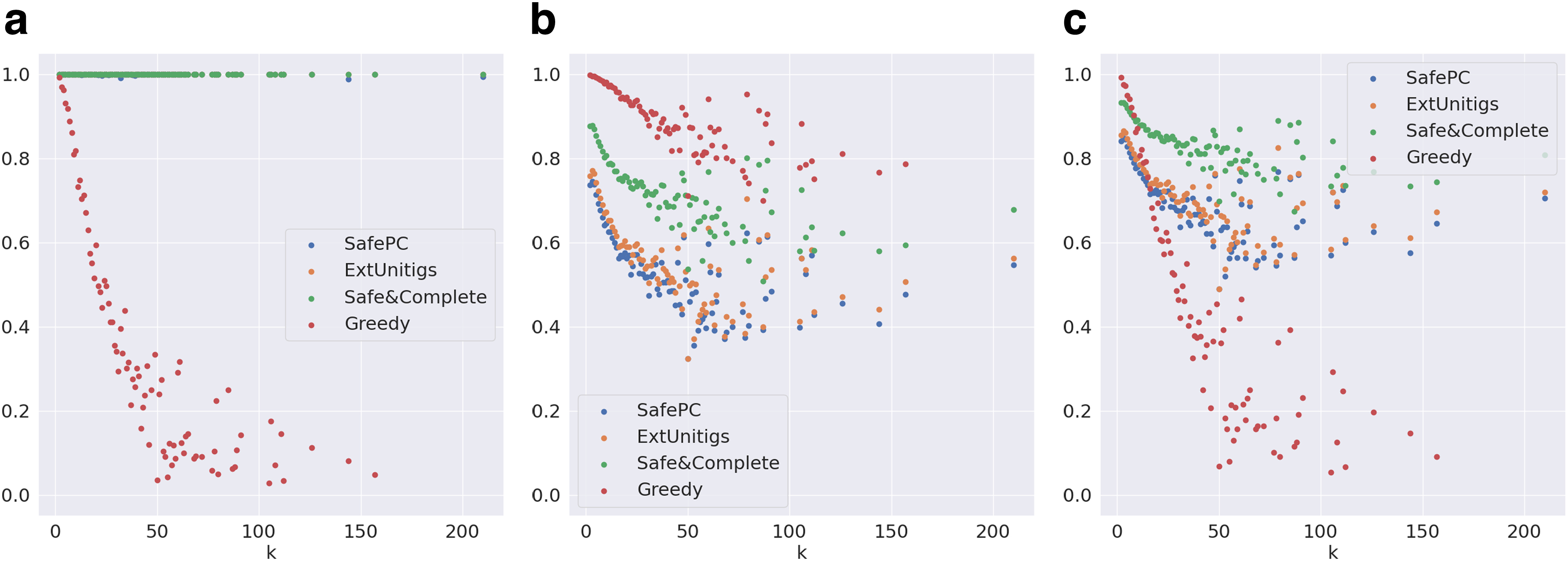
Evaluation metrics on graphs distributed by k for the Reference-Sim data set.
Next, we evaluate the significance of completeness of the safe algorithms. Figure 5b compares the maximum relative coverage, distributed over k, of all the algorithms on the Reference-Sim data set. As expected, Greedy outperforms all the other, followed by Safe&Comp, ExtUnitigs, and SafePC. The reason why ExtUnitigs outperforms SafePC is because the latter only requires to cover the nodes of the splice graph, motivating further research on the same techniques, but for edge path covers. We note that, as k reaches 20, Safe&Comp, ExtUnitigs, and SafePC sharply fall to
Figure 5c supports the above inference by evaluating the combined metric F-score. Safe&Comp dominates SafePC and ExtUnitigs by definition. Safe&Comp also dominates Greedy for
Besides, we evaluate a summary of the above results averaged over all graphs regardless of k. Table 1 summarizes the evaluation metrics of all the algorithms for simple graphs (
Summary of Evaluation Metrics for the Reference-Sim Data Set
Finally, we evaluate the practicality of the algorithms by comparing their running time and peak memory. In Tables 2 and 3, we see that ExtUnitigs are the fastest, whereas Safe&Comp takes roughly
Time and Memory Requirements of the Different Algorithms for the Evaluated Data Sets
Time and Memory Requirements of the Different Algorithms for the Evaluated Data Sets (Continuation)
5.4.1. Experimental results on the Catfish Data set
Since the Catfish data set does not have the genomic coordinates of nodes (exons or pseudoexons), the evaluation is based only on nodes.
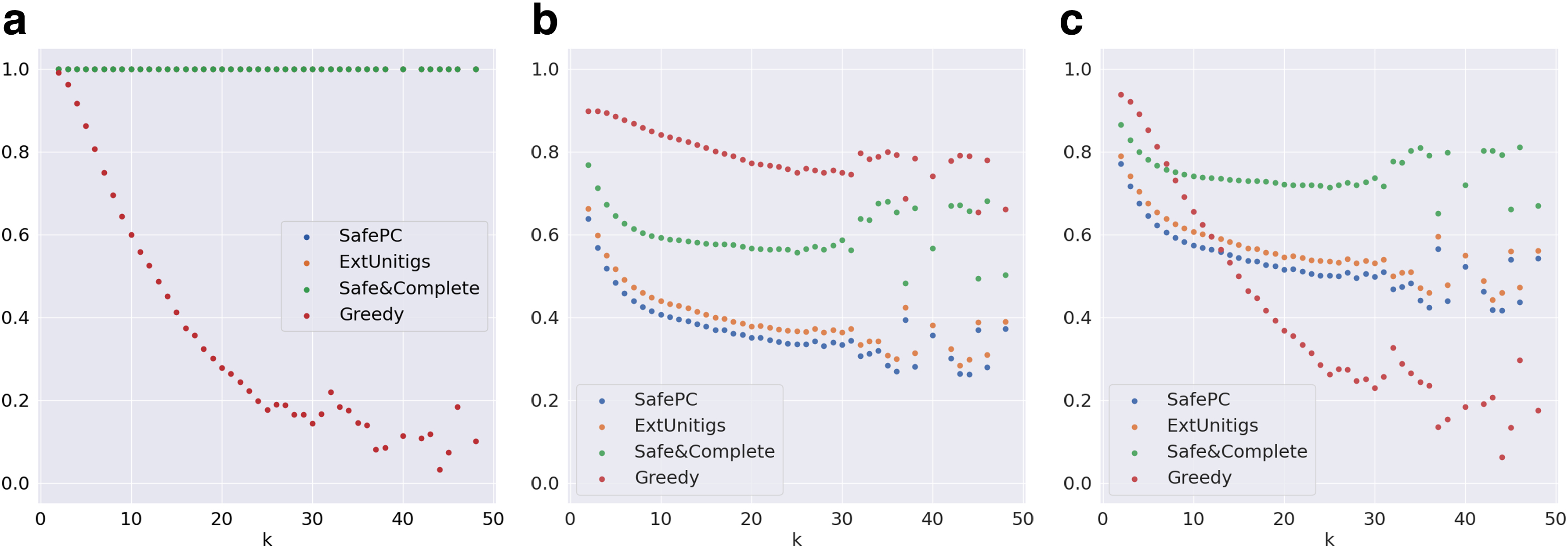
Evaluation metrics on graphs distributed by k for the Catfish data set.
1. Base versus node computations for metrics: When considering the genomic content that is predicted (i.e., bases), Safe&Comp outperforms Greedy with respect to F-score over all graphs, as seen in Table 1. Because the Catfish data set has no base information, we can only report node information, but it is possible that the same patterns we observe in Reference-Sim with bases would hold for Catfish in terms of bases as well.
2. Ratio of simpler graphs: Catfish data sets are more skewed toward simpler graphs than the Reference-Sim data set. Table 1 shows that Reference-Sim has 32% of graphs with
Summary of Evaluation Metrics for the Catfish Data Set Without Funnels, Computed Relative to Nodes
5.4.2. Experimental results including funnel instances
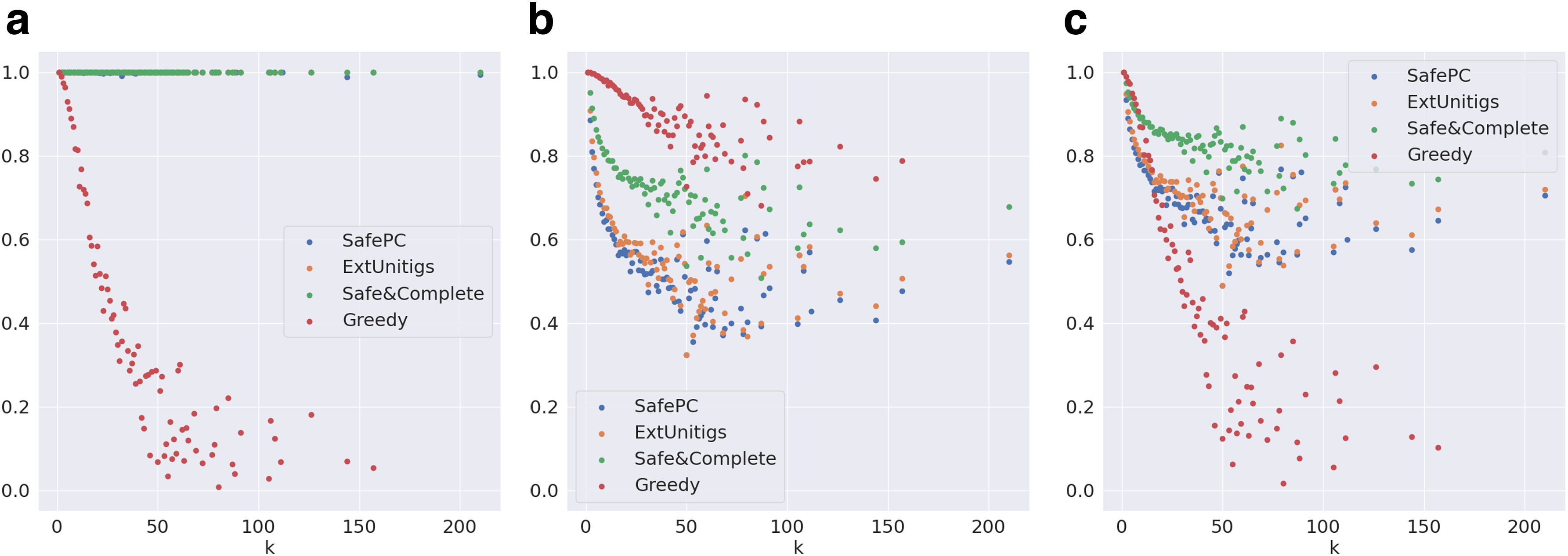
Evaluation metrics on graphs distributed by k for the complete (including funnels) Reference-Sim data set.
Evaluation metrics on graphs distributed by k for the complete (including funnels) Catfish data set.
Summary of Evaluation Metrics for the Complete (Including Funnels) Reference-Sim Data Set
Summary of Evaluation Metrics for the Complete (Including Funnels) Catfish Data Set, Computed Relative to Nodes
6. CONCLUSION
We study the flow decomposition problem in DAGs under the Safe and Complete paradigm, which has applications in various domains, including the more prominent multiassembly of biological sequences. Previous work characterized such paths (and their generalizations) using a global criterion. Instead, we present a simpler characterization based on a more efficiently computable local criterion, which is directly adapted into an optimal verification algorithm, and a simple enumeration algorithm. Intuitively, it is a weighted adaptation of extended unitigs, which is a prominent approach for computing safe paths.
Through our experiments, we show that the safe and complete paths found by our algorithm outperform the popularly used greedy-width heuristic for RNA assembly instances with relatively complex graph instances, both on quality (F-score) and performance (running time and memory) parameters. On simple graphs, Greedy outperforms Safe&Comp, and Safe&Comp outperforms ExtUnitigs mildly (
Hence, the importance of Safe&Comp algorithms increases with the increase in complex graph instances in the data set, and prominently when we consider information about the genetic information represented by each node. In terms of performance, Safe&Comp takes roughly
Despite the optimality of our characterization of safe and complete paths, the enumeration algorithm is not time optimal. In addition, the concise representation of the safe paths
Footnotes
ACKNOWLEDGMENTS
We thank Romeo Rizzi and Edin Husić for helpful discussions as well as all the anonymous reviewers for their useful comments and suggestions.
AUTHOR DISCLOSURE STATEMENT
The authors declare they have no conflicting financial interests.
FUNDING INFORMATION
This work was partially funded by the European Research Council (ERC) under the European Union's Horizon 2020 research and innovation programme (Grant Agreement No. 851093, SAFEBIO) and partially by the Academy of Finland (Grant Nos. 322595 and 328877) and the US NSF (award 1759522).