
Abstract
Abstract
We consider the problem of aligning two metabolic pathways. Unlike traditional approaches, we do not restrict the alignment to one-to-one mappings between the molecules (nodes) of the input pathways (graphs). We follow the observation that, in nature, different organisms can perform the same or similar functions through different sets of reactions and molecules. The number and the topology of the molecules in these alternative sets often vary from one organism to another. With the motivation that an accurate biological alignment should be able to reveal these functionally similar molecule sets across different species, we develop an algorithm that first measures the similarities between different nodes using a mixture of homology and topological similarity. We combine the two metrics by employing an eigenvalue formulation. We then search for an alignment between the two input pathways that maximizes a similarity score, evaluated as the sum of the similarities of the mapped subnetworks of size at most a given integer k, and also does not contain any conflicting mappings. Here we prove that this maximization is NP-hard by a reduction from the maximum weight independent set (MWIS) problem. We then convert our problem to an instance of MWIS and use an efficient vertex-selection strategy to extract the mappings that constitute our alignment. We name our algorithm
1. Introduction
The efforts on analyzing pathways can be classified into two types. The first type considers one pathway at a time and explores its important properties such as its robustness (Edwards and Palsson, 2000), steady states (Devloo et al., 2003; Garg et al., 2007; Ay et al., 2009b), modular structure (Lu et al., 2006; Schuster et al., 2002; Ay et al., 2010), network motifs (Milo et al., 298; Wernicke and Rasche, 2006; Grochow and Kellis, 2007), as well as its representation (Michal, 1998; Babur et al., 2010). The second type is the comparative approach which considers multiple pathways to identify their frequent subgraphs (Koyuturk et al., 2004; Qian and Yoon, 2009) and their alignments (Singh et al., 2008, 2007; Liao et al., 2009; Kalaev et al., 2008; Sharan et al., 2005; Kalaev et al., 2009; Dost et al., 2007; Flannick et al., 2006; Koyuturk et al., 2005; Pinter et al., 2005; Berg and Lassig, 2004; Dandekar et al., 1999; Tohsato and Nishimura, 2008; Tohsato et al., 2000; Cheng et al., 2009; Ay et al., 2008, 2009a). Alignment is a fundamental type of comparative analysis that aims to identify similar parts between pathways. For metabolic pathways, these similarities provide insights for drug target identification (Sridhar et al., 2007; Watanabe et al., 2007), metabolic reconstruction of newly sequenced genome (Francke et al., 2005), phylogenic reconstruction (Clemente et al., 2005; Heymans and Singh, 2003), and identification of enzyme clusters and missing enzymes (Ogata et al., 2000; Green and Karp, 2004).
In the literature, performing an alignment is often considered as finding one-to-one mappings between the molecules of two pathways. In this case, the global/local pathway alignment problems are GI (Graph isomorphism)/NP complete as the graph/subgraph isomorphism problems can be reduced to them in polynomial time (Damaschke, 1991). A number of studies have been done to systematically align different types of biological networks. For alignment of protein-protein interaction (PPI) networks, a number of methods such as IsoRank (Singh et al., 2008, 2007), QNet (Dost et al., 2007), Greamlin (Flannick et al., 2006), and that of Koyuturk et al. (2005) have been successfully applied to identify conserved parts among PPI networks of different organisms. For metabolic pathways, Pinter et al. (2005) devised an algorithm that aligns query pathways with specific topologies by using a graph theoretic approach. Tohsato and colleagues proposed two algorithms for metabolic pathway alignment, one relying solely on Enzyme Commission (EC) (Webb, 1992) numbers of enzymes and the other considering only the chemical structures of compounds of the query pathways (Tohsato and Nishimura, 2008; Tohsato et al., 2000). Cheng et al. (2009) developed a tool, MetNetAligner, for metabolic pathway alignment that allows a certain number of insertions and deletions of enzymes. However, most of these methods limit the query pathways to certain topologies, such as trees, non-branching paths or limited cycles. In order to alleviate this limitation, they either change the topology of the networks (e.g., breaking the cycles) or only consider queries up to a certain size which degrades their accuracy and applicability to complex networks. A number of these methods avoid the restrictions on queries and use heuristic algorithms to scale for real size problems. For instance, IsoRank (Singh et al., 2008, 2007) uses an iterative framework that combines topological features of the networks and the sequence similarity of proteins to do the global alignment of two PPI networks. They map the alignment problem to graph isomorphism and align genome-wide PPI networks of well-studied organisms. We extended this framework in our earlier work to align metabolic pathways while considering the interactions between non-homogenous entities such as reactions, enzymes, and compounds (Ay et al., 2008, 2009a). These two methods showed that formulating the similarity score in this manner and not restricting the query topologies improve accuracy and applicability of the alignment algorithm.
However, all the methods discussed above limit the possible molecule mappings to only one-to-one mappings. As also pointed out by Deutscher et al. (2008) considering each molecule one by one fails to reveal its function(s) in complex pathways. This restriction prevents all the above methods from identifying biologically relevant mappings when different organisms perform the same function through a varying number of steps. As an example, there are alternative paths for LL-2,6-diaminopimelate production in different organisms (Watanabe et al., 2007; McCoy et al., 2006). LL-2,6-diaminopimelate is a key intermediate compound since it lies at the intersection of different paths on the synthesis of L-lysine. Figure 1 illustrates two paths both producing LL-2,6-diaminopimelate starting from 2,3,4,5-tetrahydrodipicolinate. The upper path represents the shortcut used by plants and Chlamydia to synthesize L-lysine. This shortcut is not an option, for example, for E. coli or H. sapiens, due to the lack of the gene encoding LL-DAP aminotransferase (2.6.1.83). E. coli and H. sapiens have to use a three-step process shown with the gray path in Figure 1 to do this transformation. Thus, a meaningful alignment should map the two paths when the lysine biosynthesis pathways of human and a plant are aligned. However, since these two paths have a different number of reactions, traditional alignment methods that are limited to one-to-one mappings fail to identify this mapping.
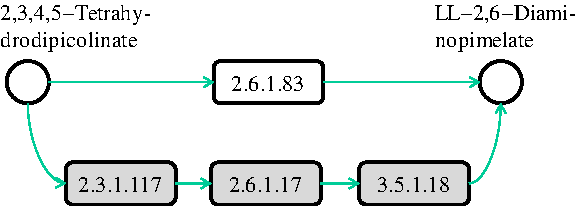
A portion of lysine biosynthesis pathway. Each reaction is represented by the Enzyme Commission (EC) number of the enzyme that catalyzes it. Circles represent compounds (intermediate compounds are not shown). E. coli and H. sapiens (human) use the path colored with gray with three reactions, whereas plants and Chlamydia achieve this transformation directly through the path with a single reaction shown in white.
For PPI networks, the idea of extending alignments beyond one-to-one mappings and allowing multiple alignments has been proposed by Liao et al. (2009) (IsoRankN), by Sharan et al. (2005), and by Kalaev et al. (2009) (NetworkBLAST-M). IsoRankN creates a functional similarity graph from input networks and searches for near cliques of highly similar proteins using spectral clustering on the induced graph of pairwise alignment scores. NetworkBLAST-M constructs a network alignment graph from queries and uses a heuristic seed-extension method to search for conserved paths or cliques. To the best of our knowledge, no current method explicitly allows mappings beyond one-to-one for metabolic pathways.
Our aim in this article is to design an algorithm that can accurately identify such biologically relevant mappings by allowing one-to-many mappings of molecules in metabolic pathways. Note that, in Figure 1, both reaction sets form linear paths. It is possible to have reaction sets with different topologies performing a certain function (see Fig. 5 below). Therefore, we use the term subnetwork to denote all types of topologies. Also, since we only consider the sets of reactions that are connected, we will simply use the term subnetwork instead of connected subnetwork.
1.1. Problem definition
We consider the problem of aligning two metabolic pathways. Unlike traditional alignment approaches, we allow aligning a molecule of one pathway to a connected subnetwork of the other. More formally, let Each molecule in Each molecule can appear in at most one mapping.
The first condition above allows one-to-many mappings. The reason for having one-to-many mappings in our alignment is not only that they capture functionally similar parts, but also they enable us to construct many-to-many mappings of arbitrary sizes. Identifying many-to-many mappings of molecule sets of different sizes is essential and is not possible with only one-to-one mappings as their combinations enforce both sides of a many-to-many mapping to be of the same size. The second condition enforces consistency. That is, if a molecule is already mapped alone or as a part of a subnetwork, it cannot map to another molecule. We elaborate on consistency and the problem definition later in Section 2. Note that, allowing one-to-many mappings in an alignment introduces new computational challenges (e.g., exponential increase in the problem size, conflicting mappings) that cannot be addressed using existing methods and hence novel methods are needed to tackle this problem.
1.2. Contributions
In this article, we propose a novel algorithm that finds subnetwork mappings in alignment of pathways. SubMAP accounts for both the effect of pairwise similarities (homology) and the organization of pathways (topology). This combination is motivated by its successful applications on network alignment by Singh et al. (2007, 2008) and Ay et al. (2008, 2009a). However, allowing one-to-many mappings makes it impossible to trivially extend these methods to our problem. Here, we describe our method that addresses this challenge. Similar to IsoRank and our earlier work, we first formulate the alignment as an eigenvalue problem and solve it using an iterative technique called power method. The result of the power method provides us an eigenvector that defines a weighted bipartite graph where each node corresponds to a molecule or a subnetwork. The edges are only between two nodes from different pathways and their weights define the similarity of these nodes. Unlike the case of only one-to-one molecule mappings, the nodes on the same side of the bipartite graph can be intersecting as the same molecule can appear in more than one subnetwork. If two such intersecting nodes on one side are mapped to two different nodes of the other side, they create inconsistent mappings for the elements of the intersection. We term such pairs of mappings as conflicting mappings. Our aim is to extract a set of mappings that has no conflicts and maximizes the sum of the similarity scores of the mappings. We prove that this maximization is NP-hard (see Theorem 1). We then construct a vertex weighted conflict graph with nodes representing a mapping of two subnetworks, one from each pathway, and edges representing a conflict between two mappings. The weights of the nodes in this graph are the edge weights of the bipartite graph from the earlier step. At this point, our alignment problem is equivalent to finding a maximum weight independent set (MWIS) of the conflict graph. To extract an independent set from the conflict graph, we use a vertex-selection strategy proposed for MWIS problem. We report the mappings that correspond to the selected set of nodes from the conflict graph as the alignment of the query pathways. Our experiments on the metabolic pathways from KEGG (Ogata et al., 1999) database suggest that SubMAP finds biologically meaningful alignments efficiently. Also, SubMAP is scalable for subnetwork sizes up to three or four as it can align two real size metabolic pathways in about a minute.
The rest of the article is organized as follows. Section 2 describes our algorithm. Section 3 presents experimental results. Section 4 concludes the paper.
Implementation in C++ is available at http://bioinformatics.cise.ufl.edu/SubMAP.html.
2. Our Algorithm: SubMAP
In this section, we present our algorithm for pairwise metabolic pathway alignment that allows one-to-many molecule mappings. We begin by introducing some notation that we use throughout this section. Then, we formally state the problem and describe the SubMAP algorithm in detail (Table 1).
Let,
A subnetwork of a pathway is a subset of its reaction set such that the induced undirected graph of the elements of this subset forms a connected graph. Let Ri ⊆ V be such a subnetwork of
Definition 1
Let
Let us denote the number of reactions of
The alignment of
Recall that for a mapping
Definition 2
Let φ be a binary relation and
Conflicts can cause inconsistencies about which reaction subset of one pathway should be aligned to the one of the other pathway. If φ has a conflicting pair of elements, we say φ is inconsistent. Since this is not a desirable property, we limit our alignment to the consistent relations only.
In addition to discarding the conflicting mappings, we also need to use a meaningful scoring score in order to gather biologically relevant alignments. One standard scoring scheme for this purpose incorporates the homology of the aligned molecules with their topologies (Singh et al., 2007, 2008; Ay et al., 2008, 2009a). Here, we generalize this scheme to one-to-many mappings. We will elaborate on this similarity score later in Section 2.4. Next, we state our problem formally.
Problem formulation
Given k and two pathways
In the following, we present our algorithm SubMAP. Section 2.1 explains the enumeration of the subnetworks of query pathways. Section 2.2 and 2.3 discuss homological and topological similarities, respectively. Section 2.4 describes the eigenvalue formulation that combines these similarities and explains the extraction of subnetwork mappings.
2.1. Enumeration of connected subnetworks
The first step of SubMAP is to create the sets of all connected subnetworks of size at most k for each query pathway. Here, we describe the enumeration process for a single query pathway. Let G = (V, E) represent a pathway and k be a positive integer. We construct the set of subnetworks
The size of the set
2.2. Homological similarity of subnetworks
Recall that the relation φ maps a reaction to a subnetwork that can contain multiple reactions. This necessitates computing the similarity between reaction sets. Since reactions are defined by their input and output compounds (i.e., substrates and products) and the enzymes that catalyze them, we measure the homological similarity between reactions using the similarities of these components.
In the literature, there are alternative pairwise similarity scores for compounds, enzymes and reactions. Particularly, two well known measures are information content similarity for enzyme pairs (Pinter et al., 2005) and SIMCOMP (Hattori et al., 2003) for compound pairs. We denote these measures by SimE and SimC, respectively. We defer the readers to Ay et al. (Ay et al., 2009a) for details on computing these similarities. Here, we utilize these similarity measures to compute the homological similarity between two reaction sets. To calculate this, we first construct three sets for both reaction sets. These are the union of (1) the input compounds (Ii), (2) the output compounds (Oi), and (3) the enzymes (Ei) of the reactions in each subnetwork Ri. For instance, in Figure 1 if we take the upper path as the subnetwork Ri, then Ei = {2.3.1.117, 2.6.1.17, 3.5.1.8}.
Next, we compute the similarity of each of these three set pairs and combine them using weights (i.e., non-negative real numbers) to calculate the homological similarity of the two reaction sets. Let W(A, B, SimX) denote the similarity between two sets A and B with respect to the similarity score SimX, where W is calculated as the sum of the similarities of the pairs returned by their maximum weight bipartite matching (MWBM). Also, let γ
e
, γ
i
, γ
o
denote the relative weights of the similarities of enzymes, input and output compounds respectively with the constraint γ
e
+ γ
i
+ γ
o
= 1. We define the similarity of the reaction sets Ri and
In this article, we use γ
i
= γ
o
= 0.3 and γ
e
= 0.4 as they provide a good balance between enzymes and compounds. However, in general we prefer to leave the choice of these parameters to the user as it provides flexibility to our method and allows it to be used in different scenarios. For instance, setting γ
E
= 1 and
We calculate SimRSet for all possible one-to-many mappings between the subnetworks of two pathways. Therefore, we do this calculation ∣φ k ∣ times in total. This way, we assess the homological similarities between all possible subnetwork mappings. Even though this scoring can be considered a good measure of similarity, relying solely on this score ignores the topology similarity which we explain next.
2.3. Topological similarity of subnetworks
We follow the intuition of IsoRank that if the subnetwork Ri is mapped to
Definition 3
Let
Definition 4
Let Ri,
Definition 5
Let
Definition 4 states that the mapping of Ri to
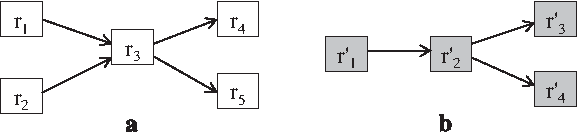
Reaction-based representation of two hypothetical metabolic pathways
There can be cases when one mapping does not provide support to any others. In such cases, we simply distribute its support equally to all possible mappings (∣φ k ∣). Notice that, by construction, the entries in each column of S sums up to 1. This is important as it ensures the stability and convergence of our algorithm as we explain in Section 2.4. Interested reader can find a detailed description of the properties of support matrix in a previous work of ours (Ay et al., 2009a).
Before moving into describing how we use the support matrix, it is important to explain how we create it in our implementation. A trivial but costly way of doing this is to check each mapping against all the others to calculate the support values. However, such an exhaustive strategy will require computing a huge matrix S of size ∣φ
k
∣ × ∣φ
k
∣. Since the creation of S will incur prohibitive computational costs, we do not construct this matrix literally. Instead, for each mapping Ri,
2.4. Aligning two pathways
We discussed what homology and topology similarities are and how we calculate them. In the following, we first describe how we combine these two similarities to get a better similarity measure for subnetworks. Then, we explain the heuristic method we use to extract the set of subnetwork mappings (i.e., the alignment) that maximizes the sum of the similarities of the mapped pairs.
2.4.1. Combining homology and topology
Both the homological similarities of subnetworks and their topological organization provide us significant information for the alignment of metabolic pathways. A good alignment algorithm needs to combine these two factors in an efficient and accurate way. Recently, the authors of IsoRank (Singh et al., 2007, 2008) have described an iterative technique named power method that achieves this combination. Here, we describe how we use power method to obtain this combination for alignment of metabolic pathways with subnetwork mappings.
Let k be a given parameter and
Let S be the ∣φ
k
∣ × ∣φ
k
∣ support matrix as described in Section 2.3. Given a parameter
In this equation,
2.4.2. Extracting subnetwork mappings
Recall that our aim is to find an alignment that maximizes the summation of the similarity scores defined by Hi while preserving the consistency between different mappings. In case of pairwise alignments with only one-to-one mappings, maximum weight bipartite matching provides an optimal and an efficient way to extract the alignment (Singh et al., 2007; Ay et al., 2009a). However, efficient heuristics are needed for this extraction phase when multiple networks are aligned or one-to-many mappings are allowed. For aligning multiple networks, IsoRank (Singh et al., 2008) used a greedy strategy to extract a maximum weight k-partite matching and IsoRankN (Liao et al., 2009) employed spectral clustering to find the alignment clusters.
Here, we first show that finding an optimal alignment while allowing one-to-many mappings is NP-hard by a reduction from the MWIS problem in bounded degree graphs. MWIS problem, even for graphs with largest degree 3, is NP-hard (Lovasz, 1994) and there is no constant factor approximation to the optimal solution in polynomial time (Austrin et al., 2009; Berman and Karpinski, 1999). We then describe how we construct a conflict graph from our alignment problem and apply a greedy vertex-selection strategy to extract a MWIS of the conflict graph which gives us the set of mappings that generates the alignment.
Theorem 1
(F
Proof
We prove the NP-hardness of our problem by a reduction from the MWIS problem in bounded degree graphs. Let G = (V, E, w) be a vertex weighted undirected graph with largest degree k − 1 (i.e.,
R
We initialize V1, V2, E1 and E2 as the empty set. We then insert a vertex ri in V1 for each
Next, we populate E1. Let ri and rj be two vertices in V1 which correspond to a vertex v in G and to an edge e in G respectively. We include an edge between ri and rj in E1 if e has v at one of its ends in G. This completes the construction of
Figure 3 illustrates the construction of the two hypothetical pathways
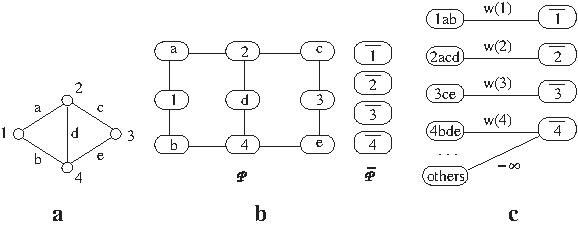
An illustrative example for the reduction from the MWIS problem to the metabolic pathway alignment problem. (
Following from the construction, we ensure that there is a connected subnetwork in
We complete our reduction by assigning similarities to subnetwork pairs one from
Let Ri be a subnetwork of
C Cost of reduction. For a given vertex weighted graph G, we can reduce the MWIS problem on G to our problem in polynomial time. This is because we create one reaction for each edge and two reactions for each vertex in G. We also create two interactions for each edge in G. Thus, we conclude that the reduction is polynomial in the size of G. Equivalence of the result. Next, we prove that the optimal alignment of
Clearly, the optimal alignment cannot contain a subnetwork pair whose similarity is −∞. This is because it is possible to choose an arbitrary subnetwork pair that has a positive score. Also, the optimal alignment cannot contain two overlapping subnetworks from the same pathway as they will conflict with each other. By construction, two subnetworks from
We demonstrate our result on the hypothetical example in Figure 3. Assume that all the vertices in Figure 3a have the same weight w. The optimal alignment of
Construction of conflict graph
Now that we proved extracting the best alignment is NP-hard, the next part is to describe how we tackle this problem. In the first step, we use the scores of mappings represented by Hi and the definition of conflict (Definition 2) to create a vertex weighted undirected graph Gc = (Vc, Ec, w), which we name as the conflict graph as follows. We define a one-to-one correspondence from the mappings (

(
Handling conflicting mappings
In the second step, we explain the greedy vertex-selection strategy we adopt from Sakai et al. (2003) in order to extract the MWIS of Gc as our alignment. Let N(v) denote the set of vertices that are connected to
3. Experimental Results
In this section, we experimentally evaluate the performance of SubMAP. We use the metabolic pathways of 20 organisms taken from the KEGG database. Our dataset contains 1,842 pathways in total. The average number of reactions per pathway is 21, and the largest pathway has 72 reactions. We also combined 12 different pathways under the metabolism of cofactors and vitamins for 10 different organisms. The average number of reactions of the largest connected components of these 10 pathways is 98, and the biggest one has 130 reactions.
3.1. Alternative subnetworks
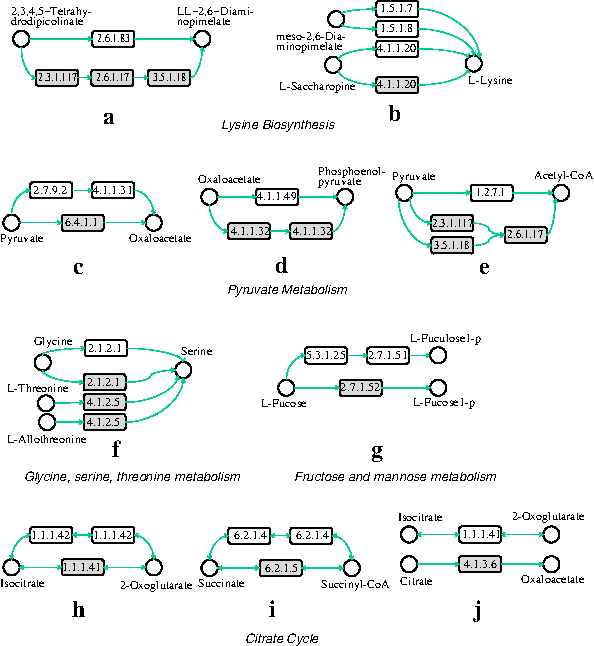
Different organisms can perform the same function through different subnetworks. We name such altered parts that have similar functions as alternative subnetworks. An accurate alignment should reveal alternative subnetworks in different pathways. In our first experiment, we evaluate whether SubMAP can find them in real metabolic pathways. We align the pathway pairs which are known to contain functionally similar parts with different reaction sets and topologies. Table 2 presents a subset of reaction subnetwork mappings that are found by our algorithm. Figure 5 visualizes the topologies of these mappings by using an enzyme based representation.
Main input compound utilized by the given set of reactions.
Main output compound produced by the given set of reactions.
Reactions mappings that corresponds to alternative paths. Reactions are represented by their KEGG identifiers.
The first row of Table 2 corresponds to alternative subnetworks in Figure 5a (also in Fig. 1). The reaction R07613 represents the top path in Figure 5a that plants and Chlamydia use to produce LL-2,6-diaminopimelate from 2,3,4,5-tetrahydrodipicolinate. This path is discovered and reported as a shortcut on the L-lysine synthesis path for plants and Chlamydia, which is not present in humans or E. coli (Watanabe et al., 2007; McCoy et al., 2006). Also, Watanabe et al. (2007) suggested that, since humans lack the catalyzer of the reaction R07613, namely LL-DAP aminotransferase (EC:2.6.1.83), this is an attractive target for the development of new drugs (antibiotics and herbicides). When we aligned the lysine biosynthesis pathways of H. sapiens and A. thaliana, our algorithm mapped the reaction R07613 of A. thaliana to the three reactions that H. sapiens has to use to transform 2,3,4,5-tetrahydrodipicolinate to LL-2,6-diaminopimelate (R02734, R04365, R04475). In other words, SubMAP successfully identified the alternative subnetworks of different size (one for A. thaliana and three for H. sapiens) that perform the same function.
Another interesting example is the second row that is extracted from the same alignment described above. In this case, the three reactions that can independently produce L-lysine for A. thaliana are aligned to the only reaction that produces L-lysine for H. sapiens (Fig. 5b). R00451 is common to both organisms and it utilizes meso-2,6-diaminopimelate to produce L-lysine. The reactions R00715 and R00716 take place and produce L-lysine in A. thaliana in the presence of L-saccharopine (Saunders and Broquist, 1966).
For the alignment of pyruvate metabolisms of E. coli and H. sapiens, the third and fourth rows show two mappings that are found by SubMAP. The first one maps the two-step process in E. coli that first converts pyruvate to orthophosphate (R00199) and then orthophosphate to oxaloacetate (R00345) to the single reaction that directly produces oxaloacetate from pyruvate (R00344) in H. sapiens (Fig. 5c). The second one shows another mapping in which a single reaction of E. coli is replaced by two reactions of H. sapiens (Fig. 5d). The first two rows for citrate cycle also report similar mappings for other organism pairs (Fig. 5e).
Note that all the above examples (rows 6–9 of Table 2 depicted in Fig. 5f–i) are one-to-many reaction mappings and hence a merit of the new algorithm we propose here. Our algorithm SubMAP also reports one-to-one mappings. The last row of Table 2 is an example in which one reaction of an organism is replaced by exactly one reaction of another organism. Aligning citrate cycles of H. sapiens and A. tumefaciens reveals that even though both the input and output compounds of the two reactions R00709 and R00362 are different, SubMAP maps these reactions (Fig. 5j). Also, if we look at the EC numbers of the enzymes catalyzing these reactions (1.1.1.41 and 4.1.3.6) their similarity is zero (see Information content enzyme similarity) (Ay et al., 2009a). If we were to consider only the homological similarities, these two reactions could not have been mapped to each other. However, both of these reactions are the neighbors of the two other reactions R01325 and R01900 that are present in both organisms. The mappings of R01325 to R01325 and R01900 to R01900 support the mapping of their neighbors R00709 to R00362. Therefore, by incorporating the topological similarity, our algorithm is able to find meaningful mappings with similar topologies and distinct homologies. An algorithm not considering pathway topologies would fail to identify such mappings.
These results suggest the following: (i) By allowing one-to-many mappings, our method identifies functionally similar subnetworks even if they have a different number of reactions. (ii) Incorporation of topological similarity makes it possible to find mappings that can be missed by only considering pairwise similarities of different entities.
3.2. Number of connected subnetworks
Given the parameter k, our algorithm enumerates all connected reaction subnetworks of size at most k for each query pathway. One question that we need to answer is: How many such subnetworks exist? Figure 6 plots this average for different pathway sizes in our dataset. When k = 1, the figure shows the number of reactions. For k > 1 the results demonstrate that the number of subnetworks increase exponentially with k. However, the increase is significantly lower than the theoretical worst case
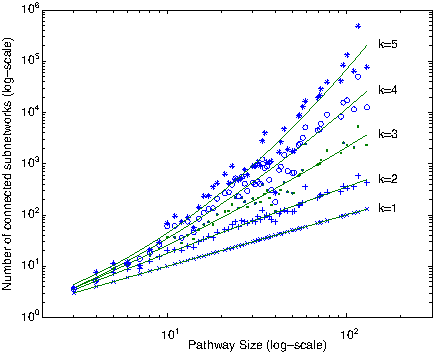
The number of subnetworks with at most k reactions for pathways of different sizes. Fitting curves are drawn using second degree polynomials.
The figure also suggests that the number of subnetworks increases as a low-degree polynomial of the size of the pathway. This is mainly because the average number of edges (i.e., neighbors) of a node (i.e., subnetwork) remains roughly the same as the size of the network increases. As a result, we conclude that for k ≤ 4, we can enumerate and store all the subnetworks of the pathways in KEGG dataset. In practice it is unlikely for a single reaction to replace a subnetwork with more than three or four reactions. Therefore, we expect that using k ≤ 4 would be sufficient to find most of the biologically relevant alternative subnetworks.
3.3. One-to-many mappings within and across major clades
In Section 3.1, we demonstrated that our algorithm can find alternative subnetworks on a number of examples. An obvious question that follows is: How frequent are such alternative subnetworks and what are their characteristics? In other words, is there really a need to allow one-to-many mappings in alignment. In this experiment, we aim to answer these questions.
We conduct an experiment as follows. We first pick nine different organisms, three from each major phylogenic clade. These organisms are T. acidophilum, Halobacterium sp., and M. thermoautotrophicum from Archaea; H. sapiens, R. norvegicus, and M. musculus from Eukaryota; and E. coli, P. aeruginosa, and A. tumefaciens from Bacteria.
We then extract 10 common pathways for each of these nine organisms from KEGG. For each of these common pathways, we choose all possible pairs of organisms
Table 3 summarizes the results of this experiment. The percentages of each mapping type between two clades is shown as a row in this table. The first three rows correspond to alignments within a clade and the last three represents alignments across two different clades. An important outcome of these results is that there are considerably large number of one-to-many mappings between organisms of different clades. In the extreme case (last row), nearly half of the mappings are one-to-many. The results also support our hypothesis that one-to-one mappings are more frequent for alignments within the clades compared to across clades due to high similarity between the organisms of the same clade. For instance, for both the first and last row, one side of the query set is the Eukaryota. However, going from first row to last, we see around 40% decrease in the number of one-to-one mappings and 250%, 850%, and 450% increase in the number of 1-to-2, 1-to-3, and 1-to-4 mappings, respectively. Considering Archaea are single-cell microorganisms (e.g., Halobacteria) and Eukaryota are complex organisms with cell membranes (e.g., animals and plants), these jumps in the number of one-to-many mappings suggest that the individual reactions in Archaea are replaced by a number of reactions in Eukaryota. These results have two major implications. (i) One-to-many mappings are frequent in nature. To obtain biologically meaningful alignments we need to allow such mappings. (ii) The characteristics of the alterative subnetworks can help in inferring the phylogenic relationship among different organisms.
3.4. Running time and memory utilization
SubMAP allows one-to-many mappings to find biologically relevant alignments. This however comes at the expense of increased computational cost. Theoretically, this increase can be exponential in k. The worst case happens when the pathway is highly connected. Metabolic pathways however are sparse and their connectivity follows power law distribution (Jeong et al., 2000). In order to understand the capabilities and limitations of our method, we examine its performance on real datasets in terms of its running time and memory usage.
We evaluate the performance of our method for querying a database of pathways as follows. We create a query set by selecting 50 pathways of varying sizes from KEGG and adding it to the combined pathways for cofactors and vitamins metabolism of 10 different organisms as described at the beginning of this section. We then select another 50 pathways of different sizes to use as our database set for this experiment. We pick the latter 50 pathways such that the average reactions per pathway is 21.4, which is very close to that of the entire database. We then align each of the 60 query pathways with all the database pathways one by one for different values of k. We measure the average running time and the average memory usage for each query pathway and k value combination. Note that we do not present any performance comparison with an existing method as the existing methods do not allow one-to-many mappings. However, our results for k = 1 show the performance of our algorithm when we restrict it to one-to-one mappings similar to the traditional alignment methods.
Figure 7a shows the average running time of SubMAP for query pathways with increasing number of reactions. When k = 1 (i.e., only one-to-one mappings as in existing methods), it runs in less than a few seconds even for the largest query pathway in our query set. As k increases, the running time increases significantly. This is because the number of subnetworks and the average number of forward and backward neighbors of subnetworks increase with k. We observe that our method can perform alignments in practical time even when k = 4 for pathways with around 70 reactions. Hence, it is scalable for all the individual pathways in KEGG. However, for the 10 combined pathways of cofactors and vitamins metabolism, the running time and memory use becomes a bottleneck when we consider k > 3.
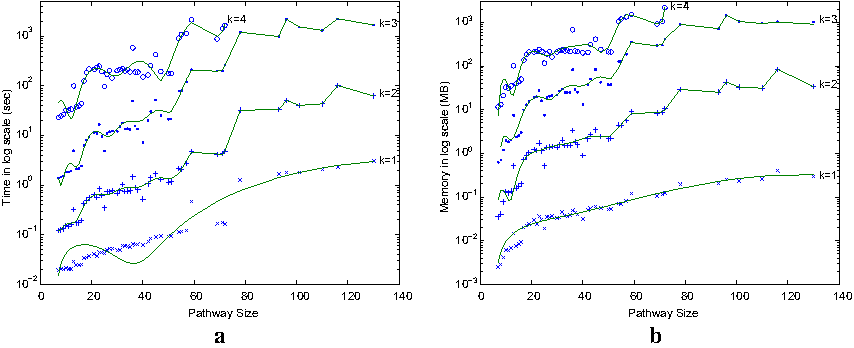
(
We also measure the actual memory usage of our algorithm for real pathways of varying sizes and k values in Figure 7b. For k = 1 or 2, the memory usage is negligible (100 MB or less) for all pathways. Although the memory usage increases quickly with k, it remains feasible for query pathways with around 70 reactions for k = 4. For k = 3, the biggest pathway of 130 reactions requires 1GB of memory per query on the average. These results show that, SubMAP can run on a standard computer for aligning real-sized metabolic pathways for k ≤ 4.
4. Conclusion
In this article, we considered the problem of aligning two metabolic pathways. The distinguishing feature of our work from the literature is that we allow mapping one molecule of one pathway to a set of molecules of the other. To address this problem, given two metabolic pathways
Footnotes
Acknowledgments
This work was supported partially by the National Science Foundation (grants CCF-0829867 and IIS-0845439).
Disclosure Statement
No conflicting financial interests exist.