
Abstract
A testable, explicit origin for Darwinian behavior, feasible on a chaotic early Earth, would aid origins discussion. Here I show that a pool receiving unreliable supplies of unstable ribonucleotide precursors can recurrently fill this role. By using numerical integration, the differential equations governing a sporadically fed pool are solved, yielding quantitative constraints for the proliferation of molecules that also have a chemical phenotype. For example, templated triphosphate nucleotide joining is >104 too slow, suggesting that a group more reactive than pyrophosphate activated primordial nucleotides. However, measured literature rates are sufficient if the Initial Darwinian Ancestor (IDA) resembles a 5′-5′ cofactor-like dinucleotide RNA, synthesized via activation with a phosphorimidazolide-like group. A sporadically fed pool offers unforeseen advantages; for example, the pool hosts a novel replicator which is predominantly unpaired, even though it replicates. Such free template is optimized for effective selection during its replication. Pool nucleotides are also subject to a broadly based selection that impels the population toward replication, effective selection, and Darwinian behavior. Such a primordial pool may have left detectable modern traces. A sporadically fed ribonucleotide pool also fits a recognizable early Earth environment, has recognizable modern descendants, and suits the early shape of the phylogenetic tree of Earthly life. Finally, analysis points to particular data now needed to refine the hypothesis. Accordingly, a kinetically explicit chemical hypothesis for a terran IDA can be justified, and informative experiments seem readily accessible. Key Words: Cofactor—RNA—Origin of life—Replication—Initial Darwinian Ancestor (IDA). Astrobiology 12, 870–883.
Introduction
W
The nature of the pool
A sporadically fed pool gets occasional supplies of partly activated ribonucleotides from geochemical sources. Is there a chemically plausible route to a long-lived system that both has a phenotype and a genotype?
The modeled route to this goal (Fig. 1) combines several straightforward ideas. Firstly, I have previously emphasized the value of molecular simplicity in making a structure accessible to primitive synthesis (Illangasekare and Yarus, 1999; Kennedy et al., 2008; Yarus, 2011b). Aminoacyl-RNA synthesis via a 5 nt ribozyme is a characterized experimental example (Yarus, 2011b); such a molecule would occur via untemplated RNA synthesis as soon as mildly activated nucleotides existed. This aminoacyl transfer center would also recur in virtually any RNA synthesized (Illangasekare and Yarus, 2012). The molecular target in Fig. 1 is yet simpler; it is the posited (Yarus, 2011a) simplest molecule with varied biochemical effects which also might replicate; a 5′-5′ linked cofactor-like ribodinucleotide. Further, the two nucleotide components of the A- -B ribodinucleotide are complementary by hypothesis, simplifying discussion because we need consider a single template and chemically active product. Perhaps A is an adenosine nucleotide and B is a modified chemically reactive, complementary pyrimidine or pyrimidine-like moiety, together akin to modern NAD (Yarus, 2011a).
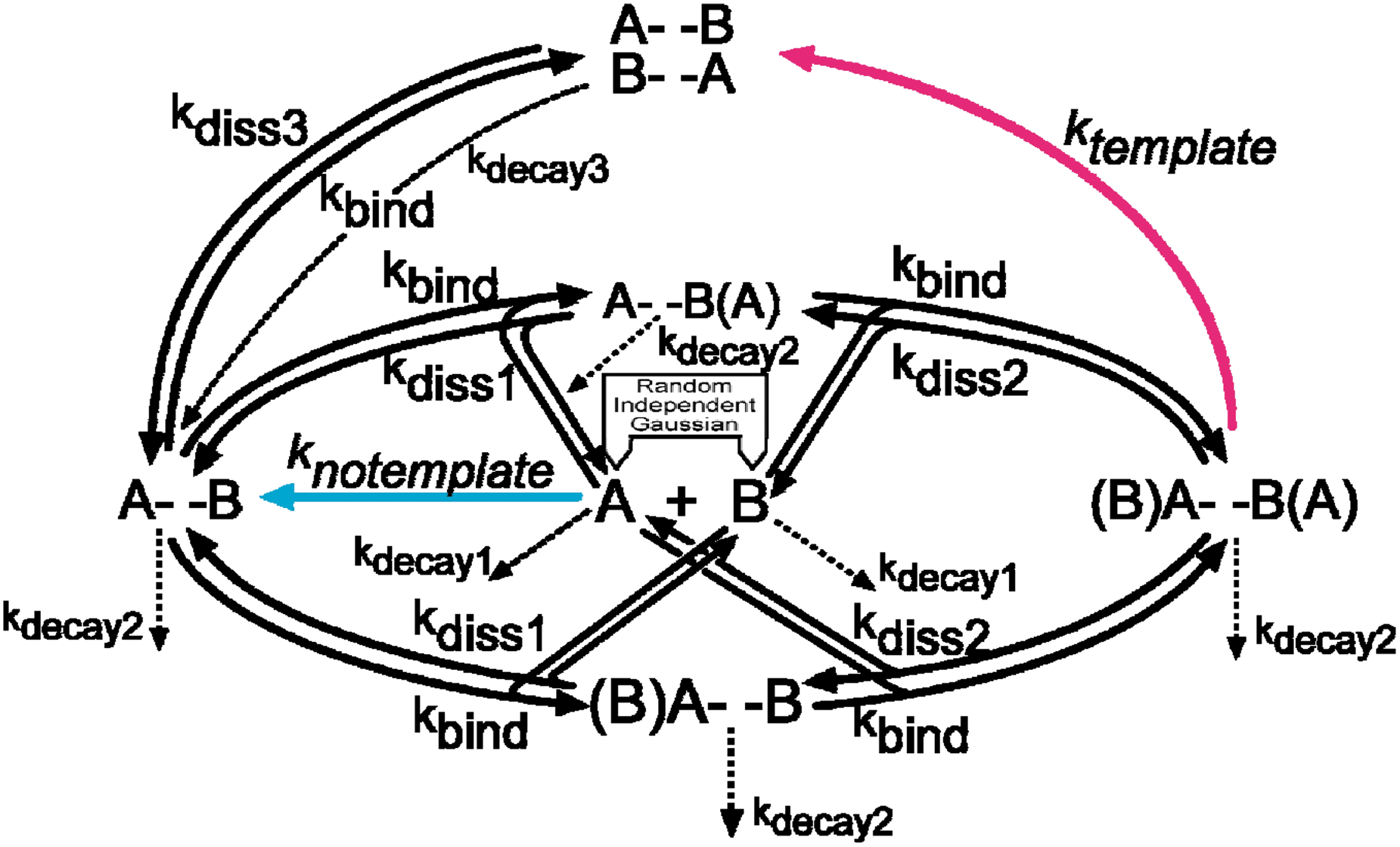
The reaction scheme for synthesis of a chemically competent, replicating dimer ribonucleotide from randomly timed, Gaussian supplies of precursors—an IDA from a sporadically fed pool. The magenta process (templated dimer synthesis) and the blue process (untemplated dimer synthesis), as well as the peak production of all forms of dimer, Σ A- -B, are emphasized in the discussion.
After initial untemplated synthesis of A- -B (Fig. 1, blue), a product dimer can pair with complementary nucleotides and template its own replication (magenta). Note that because a 5′-5′ backbone is symmetrical (does not show polarity), A- -B and B- -A are identical molecules. All forms of the A, B, and A- -B are unstable, including paired (A- -B)(B- -A) dimer, and disappear at characteristic rates.
The dual hyphen between A and B commemorates the 5′-5′-linked backbone of the cofactor hypothesis (Yarus, 2011a), but because the analysis below is kinetic rather than structural, the reader is free to think of the outcome with a 3′-5′ RNA backbone. Primordial backbone polarities are in any case presently ambiguous (discussed in Yarus, 2011a) and must be decided by Bayesian analysis of current oligonucleotide experiments (explained in Yarus et al., 2005; see also Discussion ). However, A- -B as a 5′-5′ cofactor-like dimer offers multiple advantages—for example, a stable alternative RNA backbone. For example, replication is arguably self-limiting because of the unusual ←→ backbone symmetry in both template and product. Finally, even in the absence of any knowledge of the evolutionary route to the present, similar structures exist abundantly today as mRNA caps (Schoenberg and Maquat, 2009) and protein cofactors (Yarus, 2011a), providing empirical evidence for the ancient origins and evolutionary potential of the 5′-5′ ribodinucleotide.
Calculations below emphasize results that seem sufficiently robust to survive varied assumptions. For this purpose, some reactions take slow rates (see
Separate supplies of the precursors
In Fig. 1, nucleotides A and B appear in the pool at times that are random and uncorrelated. If A and B are purine- and pyrimidine-like, then because likely chemical routes to purine nucleobases (Oro, 1961) and pyrimidine nucleotides (Powner et al., 2009) currently appear chemically distinct, it is plausible that their arrivals would be uncorrelated, because they are expected to be products of differing chemical environments. In addition, A and B quantities are each the sum of several random processes with their own particular distribution of yields. Therefore the Central Limit Theorem suggests that their summed amounts should be distributed as a Gaussian, or normal, distribution (Feller, 1957). Therefore substrates A and B appear as spikes in the pool at random times, with both spike heights distributed as Gaussians.
The dimer synthesis reaction is assumed to be
where Ψ is an activating group for the 5′ phosphate of A. For example, if ΨpA is the phosphorimidazolide introduced by the Orgel lab as a model-activated nucleotide (Inoue and Orgel, 1983), this overall reaction is well known (Kanavarioti et al., 1992). In addition, the phosphorimidazolide of A is one of many P-N-bond activated nucleotides that has a possibly prebiotic, moderately efficient synthesis from AMP, imidazole (or a variety of primary amines), and trimetaphosphate (Lohrmann, 1977). Notably, nucleotide pB enters the pool as its unactivated 5′ nucleotide, perhaps occurring in several related forms. Thus, we require only one activated nucleotide for all such syntheses, ΨpA. Accordingly, activation chemistry for pA phosphate can be geographically separated from synthesis of the chemically reactive pB, decreasing destructive cross reactions. Possible side reactions in which activated pA reacts with itself are neglected with respect to the above reaction.
Random arrival of substrates
Random appearance means that substrates are completely uncoordinated. Thus, little or no reaction occurs subsequent to many substrate spikes (Fig. 2). Accordingly, any arrival schedule that partially synchronizes A and B arrival would increase their reaction and increase the productivity of the pool. This consideration returns in discussion below.
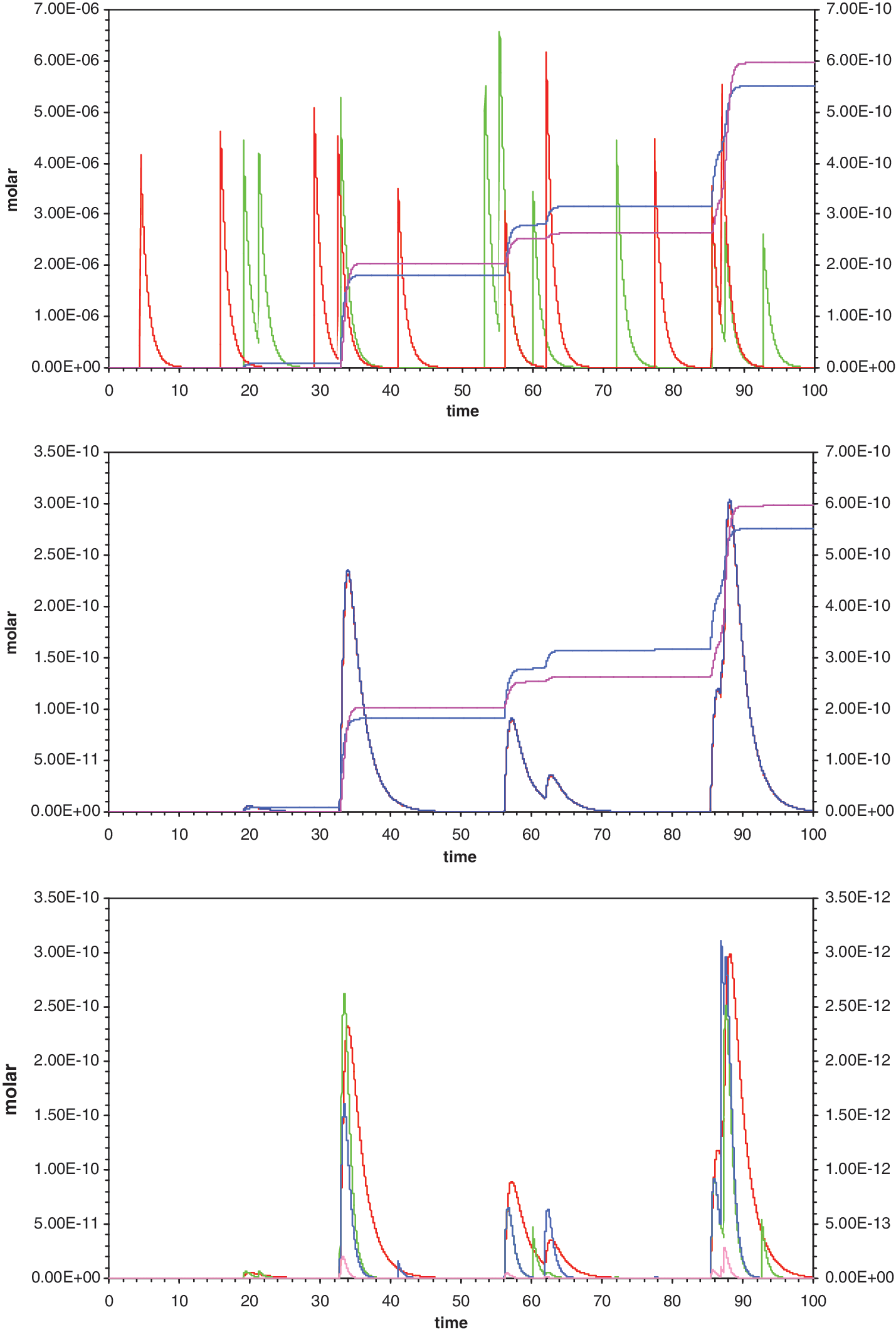
One particular kinetics for all pool reactants, under standard conditions, over 100 lifetimes. (
Universal decay
All biomolecules have finite stabilities, significant on the likely pool timescale. Therefore, A and B nucleotides decay at a first-order rate k decay1 and have mean lifetime k decay1 −1 if they do not react. Such rates of disappearance of A and B are usually assumed the same for simplicity, though A might plausibly be taken as the less stable (see below). If A and B do react directly, via k notemplate (leftward blue arrow in Fig.1; data for this reaction will be in blue below), they create the first molecules of the chemically capable replicator, A- -B, shown at the left. All forms of A- -B are themselves unstable, decaying at k decay2. Finally, paired dimers decay at k decay3 to release an undamaged strand. “Decay” is meant to include hydrolysis, but also perhaps adsorption to surfaces or other first-order side reactions like cyclization.
Replication
A- -B can replicate via the magenta arrow in Fig. 1 (data for this reaction in magenta below), after acting as a template which pairs B with A and thereby brings reactive precursors together in the base-paired complex (B)A- -B(A) (Fig. 1). To predict the outcome, we solve the model equations suggested by Fig. 1 to determine whether A- -B proliferation is likely. For Darwinian evolution, A- -B must replicate, so that its information is derived from preexisting templates; therefore requirements for replication are said below to “define the Darwinian domain.”
Results
Solving the system
The method of solution is simultaneous numerical integration of the 18 reactions of Fig. 1, which is detailed in
Pool evolution is episodic
Sporadically fed pool dynamics (Fig. 2) are dominated by the fact that reactants strongly vary in the short term but are determined when averaged over a large number of lifetimes, and secondly that all species decay at rates that embody their finite stabilities. The angled declines on the right of every peak in Fig. 2 reflect those inevitable first-order decays, as well as sporadic syntheses and dissociations. Inputs are therefore balanced with decays—the long-term solution for the pool is an “unsteady state” reflecting poise between rates of substrate appearance and universal decay.
However, the special nature of this unsteady state is of great consequence for pool chemistry. In Fig. 2, the random nature of precursor supply means that, usually, spikes of one substrate decay before a spike of the other. This ensures that both templated and untemplated A- -B synthesis take place in relatively short intervals, at times when A and B overlap by chance. Instability of all species ensures that always, after episodes of synthesis, the results decay, until the next sporadic synthesis occurs. Thus, the history of the pool is sporadic A- -B synthesis, at varying spacing in time, interleaved with (potentially) prolonged decays (Fig. 2, all panels).
Decay sets the timescale in the following sense: RNA bases are fairly stable—at pH 7 and 0°C, G has a mean lifetime of 1.9×106 years (Levy and Miller, 1998). C, the least stable base because of facile deamination to U, has a mean lifetime of 2.5×104 years. However, the mean life of a normal 3′,5′ ribonucleotide phosphodiester bond is only about 95 years at 0°C and pH 7 (calculated from data of Soukup and Breaker, 1999). Least stable of all is ribose, however, with a mean life of 63 years (Larralde et al., 1995) at pH 7 and 0°C. Activated nucleotide phosphates are less stable yet, with nucleotide 5′ imidazolides having a mean lifetime of the order of 10 days at lowered temperature. Thus I adopt the shortest mean lifetime of 10 days for calculation (mean lifetime=rate−1=t ½/ln 2). Under this assumption, Fig. 2 spans about 3 years in the life of the pool. However, other similar lifetimes could clearly be justified, expanding or contracting the time spanned by a typical simulation. Any plausible lifetime, however, puts pool behavior at the far edge of current experimentation, in a range that only calculation can thoroughly explore.
I emphasize one important numerical implication: consider a peak of A- -B as a “trial” (Fig. 2, middle), that is, an opportunity for assembly of a more complex biological network utilizing the chemical capabilities of A- -B. Then if one has several×108 years to find a successful combination, there will be of the order of hundreds of millions of trials per currently active pool. Thus, quick or probable access to an IDA is not a hidden assumption in these results.
Episodic synthesis during random overlaps between substrates shapes the overall dynamics of A- -B appearance. We focus on the domain of replication, where the majority of A- -B comes from templated synthesis (see below)—past this point most A- -B information comes from previous A- -B template, and (if there are differing candidates for, e.g., B) Darwinian selection can accompany A- -B propagation. The mean integrated appearance of A- -B is not exponential in time but linear after an accelerating beginning. That is, episodes of synthesis vary in spacing but after 100 lifetimes have occurred at a determined mean rate that increases with the 3.76 power of the A and B spike frequency (see
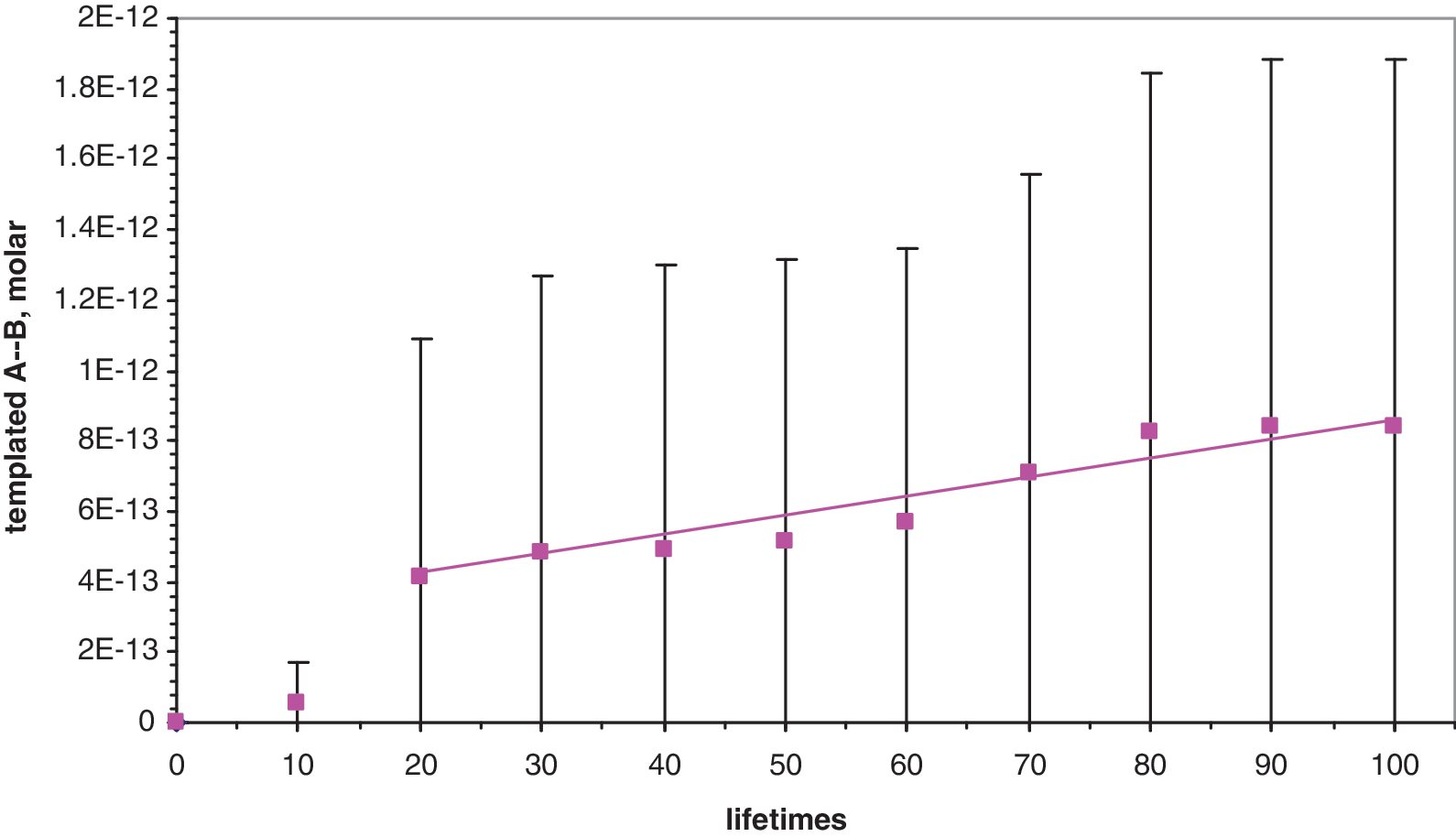
Mean templated A- -B, with standard deviation bars, in 10 averaged simulations, showing an accelerating start and later linearity with time.
A- -B is largely free
In the middle panel of Fig. 2, total A- -B in all forms has been plotted with free A- -B on the same scale. The two plots superpose—only one line is visible, except during the greatest transients or peaks. Similar superposition occurs under all conditions below, with the implication that most A- -B is free for biochemistry or replication, not tied up in complex. While there is no reason a base-paired A- -B dimer cannot be chemically active on its unpaired faces, and so also have a phenotype, the standard dinucleotide system analyzed is not dominated by template base pairing. It needs no helix-destabilizing activity to free replicated strands for use as, for example, replication templates (von Kiedrowski, 1986).
Over a broad range of conditions, the oligonucleotide pool is therefore a system that replicates even though its template is always substantially free (Fig. 2, Fig. 4). A worst case can be found at the rightmost peak of A- -B in Fig. 2 (where potential ligands for A- -B are near maximal); the dimer is 98.3 % free. This differs from larger nucleic acids, even from self-complementary oligonucleotides only slightly larger (von Kiedrowski, 1986; Sievers and von Kiedrowski, 1994).
(
Predominantly free A- -B is at the root of a number of important pool properties. For example, the rate of templated A- -B synthesis is first order (proportional to) total or free A- -B concentration, when traced through a peak in Fig. 2. This is necessary and sufficient to ensure that A- -B is a replicator whose properties are optimal for change under selection (Szathmáry and Maynard Smith, 1997). As expected, direct chemical synthesis of A- -B is, in contrast, zeroth order (independent of) A- -B concentration. Thus as replication increases, a new pool is first independent of preexisting A- -B concentration, then approaches first-order dependence on its A- -B when templating becomes the dominant mode of A- -B production. Whenever variance in behavior and selection align during replication, pool properties should evolve rapidly. Because replicator evolution can sometimes be related to differential molecular stabilities (Lifson and Lifson, 1999; Scheuring and Szathmary, 2001), standard pool A- -B was also checked through the point of replication with the same lifetimes for all reactants. Free A- -B was observed throughout. Not only is free A- -B crucial to selection, below we also find that its freedom determines dynamic pool behavior.
Peak A- -B
The other quantity presented in detail (e.g., in Fig. 4) is peak A- -B; the maximum A- -B present during the most effective episode of synthesis. Peak A- -B (e.g., the rightmost peak in Fig. 2, middle and bottom) is the maximum molecular concentration of A- -B in all forms, with all kinetic factors taken into account. By contrast, untemplated A- -B is the integrated amount made by direct reaction between A and B (with no decay), a quantity useful for discussion of the effectiveness of untemplated synthesis. Templated A- -B is, similarly, the integrated amount of A- -B made on a preexisting A- -B template (with no decay), a quantity useful for discussion of the effectiveness of replication. Put another way, templated and untemplated A- -B are the total amounts that would be present if all decay were negligible.
Figure 2 shows that total A- -B synthesis in 100 lifetimes occurs in a small number of episodes. An episode's contribution can be close to the amount plotted as peak A- -B (Fig. 4). Thus the black line (peak A- -B) is usually within a factor of 2 or 3 of totaled synthesis [total untemplated A- -B (blue) plus templated A- -B (magenta)]. Almost without exception here, total A- -B synthesis during 100 lifetimes has occurred in one, two, or three episodes, though an episode can be complex, entraining several substrate spikes, as seen here for the latter two episodes in Fig. 2.
Intrinsic stability selection in the pool
Episodic synthesis has another important implication. Deep troughs appear between episodic peaks, where many orders of magnitude in template concentration are lost (Fig. 2, all panels). Therefore, there is unavoidably rigorous selection for A- -B stability. If a sporadically fed pool contains A and B variable in stability (and stability is expressed in the oligomer), more stable variants will rapidly be selected. As we will see below (Fig. 4C), this rapidly elevates production of A- -B and increases replication, bringing on transition to the Darwinian domain. Afterward, synthetic episodes usually begin with preexisting templates selected for stability. The basis for this tendency is already visible in episodes that begin just past 56 and 85 lifetimes in Fig. 2; in each case A- -B is continuously present and actively serving as template for ≈15 lifetimes, through several spikes. Further examination of such a transition to increased stability seems likely to provide further useful information.
Possible fossilization
Figures 2 and 4 implicitly offer a possibility for experimental detection of an ancient sporadically fed pool where Darwinian life might have originated. Successive layered episodes along the time axis might fossilize, if the pool communicates with a sediment-forming zone. Synthetic episodes necessarily contain simultaneous peaks of both substrates and products (Fig. 2), so could be recorded as strongly varying concentrations of elemental phosphate in sedimentary rocks and perhaps detected after an indefinite time. It is intriguing to think that sporadic pool kinetics and (e.g.) microprobe mass spectrometry might define possible regions for life's origin and even tell us something about its kinetics, despite intervening gigayears.
A quantum for creation
A final aspect of pool A- -B synthesis discernible from overall inspection of Figs. 2 and 4 is that there is a minimum episode of synthesis, which is not decreased by, for example, further decreases in substrate frequency. That is, overlap between substrates becomes less frequent as spike frequencies decrease (trend shown explicitly in Fig. 4C), but both the average and maximum size of an A- -B creation episode have a lower limit, determined by the integrated overlap between spikes. The average of 250 completely isolated, simultaneous A and B spikes generated here had a yield of 0.55±0.04 nM A- -B (mean±standard error of the mean). With less frequent supplies of A and B, pool tempo alters in that overlaps become less frequent, but neither the distribution nor peak yields from an episode will decrease. The maximal synthetic episode, from precisely overlapping spikes, will always occur if one has time to wait.
Calculations
Synthesis and decay of a self-complementary A- -B dimer in a sporadically fed pool (Fig. 1) were embodied in the algebraic and differential equations in Fig. 5. This system of differential equations was integrated and plotted by using Rosenbrock integration (Rosenbrock, 1963) at 103 intervals/lifetime, employing Berkeley Madonna v 8.3.18 (R.I. Macey and G.F. Oster, University of California) running on a Lenovo T61 computer (simulation code and results are in Supplementary Information, available online at

The pool mechanism of Fig. 1 formulated as differential equations, to be solved by numerical integration.
Standard errors for total direct A- -B synthesis over 100 lifetimes are well determined, with standard errors frequently ≈10% of the mean, but peak and templated A- -B have large variance, often of the order mean2. Note the standard deviations in Fig. 3. However, the averaging process adopted gives relatively reliable behavior (data in Fig. 4 panels). Other integration methods and variations of the integration interval give similar numerical results; thus integrations appear quantitatively dependable.
The last three equations of Fig. 5 define quantities given particular emphasis in discussion. Proceeding downward, these three equations describe the total synthesis of oligomer by direct reaction between nucleotides [used to define (blue) untemplated A- -B synthesis], then the total synthesis of oligomer by templated reaction [used to define (magenta) effects on A- -B replication], and last, the instantaneous summed concentration of all oligomer (black; totaled A- -B peaks exemplify the maximum contribution of the pool to its environment).
Detailed results and individual variations
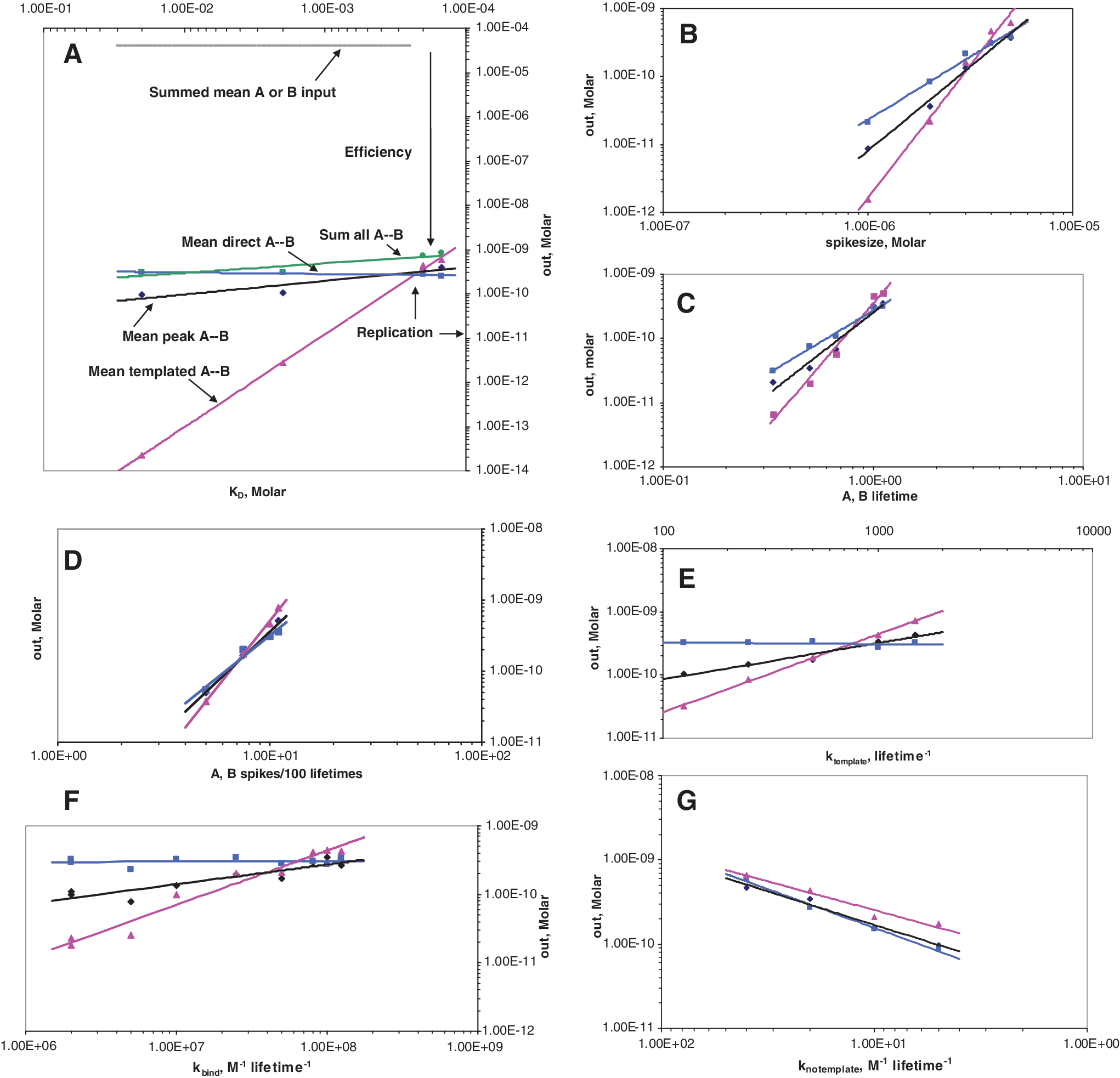
In the panels of Fig. 4, log-log plotted lines are least-squares lines fit to data points (themselves the means of twenty-five 100 lifetime simulations; see Numerical Results, Supplementary Information online).
The first panel (Fig. 4A) has additional labeling to clarify interpretation. At the top, the standard total peak input per 100 lifetimes (a mean of 10 spikes with a mean peak size of 4 μM) is shown. In most panels this line is flat at 4×10−5 M, as in Fig. 4A, but when peak substrate is varied, input has a slope of unity (linearly increasing; Fig. 4B and 4D).
In Fig. 4A, the ratio of templated, direct, or templated plus direct A- -B synthesis to total input can be thought of as an efficiency, or yield, of A- -B. Thus we say of panel 4A that the efficiency of total A- -B synthesis grows as nucleotide binding increases. In fact, this is important in discussion because it is true in Fig. 4A through Fig. 4F—that which increases replication also, in almost all cases, increases the total yield of A- -B dimer (the exception being
Where the blue (direct reaction of A and B) and magenta (templated reaction of A and B) lines cross is the point at which integrated untemplated synthesis and integrated templated synthesis are equal. Thus in Fig. 4A decreasing
Finally in Fig. 4A, mean peak dimer (black line) parallels total synthesis (green line) across all tested spike magnitudes. Because the largest synthetic peak is a large, near-constant fraction of total A- -B synthesis, the episodic nature of synthesis, which occurs in only a few events in 100 lifetimes, is preserved across the range explored. To increase clarity, total synthesis data (green) are not plotted in other panels, but similar episodic synthesis (almost parallel, close, total A- -B and peak A- -B lines) is the rule throughout.
Individual pool quantities
We now consider the sporadically fed pool, quantity by quantity Q (e.g.,
In particular, the variation of replication as pool quantity Q is varied is
And the exponent Y
Templated - Y
Untemplated can be used as an index of Q's influence on replication after 100 lifetimes. Greater exponents mean sharper dependence and more influence. Q
Darwin, where total untemplated and templated A- -B synthesis are equal is
Past Q Darwin (rightward in all panels of Fig. 4), replication of A- -B is predominant over untemplated synthesis, and I write of being in the Darwinian domain.
Nucleotide dissociation constants
To allow
These
Mean spike size
The size of substrate spikes is the second most significant quantity for replication. Substrate supply in Fig. 4B also deserves discussion because bigger spikes are an influential way to elevate the A- -B yield and degree of pool replication. Templated A- -B output increases as
These two most influential pool quantities,
Molecule lifetimes
Both templated (∝
Long molecular lifetime has particular importance for the history of a pool; if different forms of A and B with varied stabilities coexist, such an initially mixed pool can rapidly be selected to climb rightward in Fig. 4C, toward increased yield and replication. Evolution of more stable A- -B is also of particular interest because selected A- -B potentially records earlier selection of all types and potentially allows pool properties to evolve coherently through extended times. Conditions for transition to coherent long-term evolution seem worth further exploration.
Mean spike frequency
The next most influential replication variable is the frequency of substrate appearance. Total templated pool output goes as
Templated reaction rate
The first-order rate,
In Fig. 4E,
It is interesting to compare triphosphate-mediated ribonucleotide ligation with these calculations. Rohatgi et al. (1996) studied a potentially comparable templated, but minimally catalyzed, ribonucleotide 5′-3′ ligation reaction. Fastest observed ligation rates were 6.9×10−8 s−1, in mixtures of Mg2+ and Pb2+ at pH 7.4 and 37°C. Thus, minimally catalyzed triphosphate-mediated 5′-3′ joining is more than four orders below the Darwinian boundary of the sporadically fed pool. This suggests the need for a more reactive primordial phosphate-activating group than pyrophosphate. Such a requirement is not an accident but a consequence of the stability of phosphate diesters in the absence of specific catalysis (Westheimer, 1987). Rates required for replication are instead close to those measured for imidazolide-activated 5′-3′ nucleotide joining.
Nucleotide pairing
In Fig. 4F, the effects of
Variation in this rate hardly alters untemplated synthesis at all, as would be expected because this pathway uses no pairing. Template activity instead increases with faster pairing, but slowly—mean peak A- -B increases as
Untemplated reaction rate
This is the untemplated, second-order, solution reaction of A and B to give A- -B. In Fig. 4G,
These rates resemble those for phosphorimidazolides. For example, the untemplated rate at which imidazolyl-A reacts to form oligomeric ribonucleotides is ≈2×10−5 M −1 s−1 in Mg2+ and more than 10-fold faster in 25 mM Zn2+, as estimated from the data of Sawai and Orgel (1975). More explicit data from von Kiedrowski (1986) agree, putting the rate of untemplated imidazolyl-oligonucleotide reaction to form 2′-5′ and 3′-5′ backbones at 3×10−5 M −1 s−1.
Unusually among pool
The Fig. 4G abscissa declines to the right, so that replication increases rightward as in other panels. Slowing untemplated dimer formation decreases all pool outputs but forces more dependence on templated synthesis, so replication increases rightward. All pool output dependences on
Mean simulation results are summarized in part in Table 1 above, which collects standard pool quantities, as well as the boundary values (Q
Darwin) for replication under standard conditions. However, no sooner is an explicit solution for one set of conditions seen than it evokes the need for a general solution, valid at any chosen Q. I close
Effect of available spikesize on required KD
Consider the question: precursor spikes here are dilute, several micromolar; what could happen if a pool had access to more abundant precursors? After all, pool synthesis of A- -B becomes more efficient at higher substrate concentrations (described in Detailed results and individual variations, above). Simple extrapolation of synthesis to much larger spikes can be inaccurate, because other reactions become limiting. For example, no special activity is required to dissociate (A- -B)(B- -A) in Fig. 4, because it spontaneously dissociates. However, at high-enough substrate concentrations, self-complementary template will become significantly paired (von Kiedrowski, 1986; Sievers and von Kiedrowski, 1994), reducing templated A- -B output. Unfortunately, precise calculation of this effect is not possible because the present integration, though designed for stiff reaction networks like these (Rosenbrock, 1963), becomes unstable with larger spikes.
But suppose we nevertheless wish to follow up on the hint above that, to preserve replication with weaker nucleotide binding to template (higher
Lifetime, spike frequency, and other variations
The list of Q above offers broader clues about molecular abundance in the pool. The list is ordered by decreasing influence on replication near Q Darwin and thus offers guidance about which pool quantities most readily respond to selection for abundance. Alternatively, because selection for molecular abundance is inevitable at some stage, the list can be used to discuss the robustness of replication itself.
I argue (in Intrinsic stability selection in the pool, above) that strong selection for longer nucleotide lifetime in the pool is inevitable. Because molecular lifetimes strongly influence replication (Fig. 4C), greater A- -B stability and thus greater output, along with transition to the Darwinian domain, will be selected if relevant variance in lifetime exists. This argument can be seen to be a special case of a much more general conclusion.
Because A- -B is mostly free, there is a reliable relation between the exponents for pool quantities
Thus, preferred molecules in the long run are readily selected replicators, and these should arise easily because they can appear as natural chemical variants in any pool quantity
Discussion
The method of this investigation is to use chemical kinetics and measured literature reactions to demonstrate realizable examples of system behavior. For example, it is shown that pools of small ribonucleotides plausibly exist that replicate even though its template is mostly unassociated: always free.
Other implications of these calculations
Naming the IDA is worthwhile in that it focuses thought to a defined, crucial point; the simplest or earliest system that might both replicate and express a chemical phenotype. A third plausible requirement for the IDA is continuity with the later, but arguably overlapping, RNA world (Yarus, 2011a). Notably, small RNAs exist which appear to meet the three requirements. These are the ribodinucleotide cofactors, chemical relatives of modern NAD or FAD (Yarus, 2011a). This prior argument is carried further here, where the kinetic requirements for ribodinucleotide replication in a sporadically fed pool of unstable nucleotides are calculated. Calculations focus around the point where pool replication begins to transmit information to descendants (
The crux of the argument is the numerical solution of the differential equations that constrain the sporadically fed pool (Figs. 1 and 5). To interpret the results (e.g., Fig. 2), consider that the problem is not framed in a way favorable to replication. For example, substrates appear at random times, completely uncorrelated. Amounts are varied, distributed as a Gaussian and always very dilute. Substrate spikes are infrequent, typically about one in 10 lifetimes. All reactants decay in a time measured in days. Some rates, such as
In order of decreasing effect on replication (and thereby on entry into a selective Darwinian era), the important pool reactions are (compare Fig. 1, Fig. 4) as follows:
Nucleotide A and B dissociation constants (
With these kinetic thresholds in hand, measured values for imidazolide-activated nucleotide behavior already published can be seen to approximate the calculated requirements. A major conclusion is, therefore, by using sporadic geochemical sources of varied, dilute, unstable activated 5′ nucleotides reacting via already-known homogeneous chemical kinetics, a sporadically fed pool can readily become a cofactor-like system(s) that evolve(s).
The sporadically fed pool has a plausible early Earth context
Earth in the era of life's origin is arguably not hot but rather a heterogeneous ice ball. After the Moon-forming impact at about 4.5 gigayears ago, a very hot planet probably cooled in a few million years (Sleep et al., 2001). Whereupon, given the lowered luminosity of the early Sun prior to its entry onto the stellar main sequence (≈70% of present luminosity; Sagan and Mullen, 1972), Earth could readily have descended to subfreezing temperatures (Zahnle, 2006). An ancient icy Earth was locally liquefied by bombardment by intersecting planetesimals (Bada et al., 1994; Valley et al., 2002), and a “cool early Earth” was ultimately thawed by a CO2/H2O greenhouse effect (Sagan and Mullen, 1972; Bada et al., 1994; Zahnle, 2006). Recent zircon isotopic data are consistent with clement conditions through this era, suggesting continental crust in contact with liquid water back to at least 4.3–4.4 gigayears (Mojzsis et al., 2001; Harrison et al., 2005).
Further, not only is an icy pool plausible on early Earth but in a surprising variety of other Solar System locales: for example, within Jupiter's satellite Europa (Pappalardo, 1999) and in the subsurface of saturnian satellite Enceladus (Postberg et al., 2011). Thus sporadically fed pool events arguably bear on the breadth of life's distribution.
Cold water and ice are excellent media for RNA chemistry. Cold facilitates nucleotide pairing, and freezing facilitates reactions by concentrating solutes in the last-to-freeze eutectic phase (Kanavarioti et al., 2001) and by stabilizing RNA structures disrupted by higher temperatures (Vlassov et al., 2004). Chemical RNA synthesis is accordingly facilitated: templated addition of all four chemically activated ribonucleotides to a primer has been observed only in the cold (Deck et al., 2011). Moreover, the eutectic phase itself forms a fine arboreal network that might have served to compartmentalize primordial biochemistry for evolution (Attwater et al., 2010). In fact, the sporadically fed icy pool has successive access to both the concentrated reactants of the eutectic and the homogeneous effects of the pool. Alternation between liquid and eutectic deserves more investigation than it has received.
Further, a watery pool on glacier ice is a surprisingly benign environment for ribonucleotides. Modern Antarctic summer ponds, in areas free of endogenous biota, have a mean pH of 7.8, with 11 mM Na+, 1.1 mM Mg2+, and 0.25 mM Ca2+ from aerosol and liquid transport of dilute sea salts (de Mora et al., 1994).
And not only is ice physically and chemically compatible with RNA chemistry, but seasonal and/or impact melting supplies a plausible valving mechanism to orchestrate sporadic flows of reactants, or transitions between the eutectic and solution. Notably, seasonal and impact flows would not be randomly timed but would be synchronized, likely elevating A- -B yields over those calculated here.
Distribution of pool contents to nearby neighbors via melting is also an apt way of testing novel mixtures of pool contents. The potential of a population of pools is definitely beyond the scope of this manuscript, but production of something that depresses the freezing point of ice might be selected. In a sporadically freezing environment, this would lengthen the mean life of a pool at both thawing and freezing, and also catalyze pool fusion. An icy pool, that is, will exert its own native selection logic.
The broad consistency of an evolving sporadically fed RNA pool with an icy container (for example, compared to a rocky environment) is another rationale for minimal rates in calculations, to retain compatibility with lowered temperatures.
The posited pool product has a plausible position in biochemical history
A pool's reactive cofactor-like dinucleotide is readily connected to the later biochemical record (Yarus, 2011a), including modern organisms. Bona fide cofactors can be synthesized on oligomeric RNA by ribozymes (Huang et al., 2000) or incorporated into RNAs using ribozyme activity (Jadhav and Yarus, 2002). They are useful biochemical reactants, once RNA-linked. For example, ribozymic synthesis of RNA-bound acetyl-CoA has been characterized (Jadhav and Yarus, 2002). Thus the chemical phenotype proposed here exists and could be transmitted to a later RNA world composed of longer ribozymes. In turn, reactive modern 5′-5′ dinucleotide cofactors used by proteins have long been cited as evidence of an ancestral generation of RNA enzymes, whose active groups were the progenitors of modern dinucleotide enzyme cofactors (White, 1976). Consequently, hypothetical pool events are plausibly continuously connected to modern biochemistry.
The sporadically fed pool has a plausible place before the big tree
Carl Woese has proposed (Woese, 2000) that there was an extended era before vertical inheritance was possible, recorded in the long, unbranched lines at the base of the big rRNA tree for Earthly life. This era supported evolution (e.g., of the genetic code) in a population dominated by horizontal gene transfer. This is readily consistent with an ancestry in a sporadically fed pool, which readily divides and distributes its active molecules randomly but is too primitive to support reproducible vertical inheritance.
Epistemology
I conclude with comment on what is shown. A particular route to Darwinian biomolecules on Earth is not proven, but a credible IDA via small oligoribonucleotides now seems a likely hypothesis. Certainly, many potential problems—inconstant supplies of unstable precursors at low peak concentrations, or availability of only minimal catalysis—do not prove particularly challenging in the context of a realistic kinetic analysis. Further, a pool easily favors replication and efficient selection for a more catalytically effective product, the dimer, taking advantage of natural variance in molecular reactivities at almost any elementary step (Figs. 1 and 4). Known ribonucleotide reactions thus appear sufficient for robust progress from undirected beginnings (near zeroth order in A- -B, leftward in Fig. 4 panels) to a system structured by Darwinian change (near first order in A- -B, rightward in Fig. 4 panels). Nonetheless, particular data require further investigation. Most urgently, stabilities, pairing, and reaction rates for varied, small, 3′-5′, 2′-5′, and 5′-5′ oligonucleotides in eutectic ice and cold water are crucially influential and insufficiently known. A primordial leaving group Ψ, with rates similar to phosphorimidazolides, remains to be specified. Nevertheless, calculations find no bar to the appearance of an IDA via minimally catalyzed nucleotide chemistry at lowered temperatures. Such an origin for terran life, as for Darwinian biology elsewhere, is not unimaginable. Instead, it is entirely feasible to discuss its necessities.
Online Supplements
Two supplementary files (see Supplementary Information at
Numerical Results – full Figure 4 quantitation
Berkeley Madonna Simulation Code – the runnable Figure 1 model.
Footnotes
Abbreviation
IDA, Initial Darwinian Ancestor.