
Abstract
In the near future wireless sensor networks will be employed in a wide variety of applications establishing ubiquitous networks that will pervade society. The inherent vulnerability of these massively deployed networks to a multitude of threats, including physical tampering with nodes exacerbates concerns about privacy and security. For example, denial of service attacks (DoS) that compromise or disrupt communications or target nodes serving key roles in the network, e.g. sink nodes, can easily undermine the functionality as well as the performance delivered by the network. Particularly vulnerable are the components of the communications or operation infrastructure. Although, by construction, most sensor network systems do not possess a built-in infrastructure, a virtual infrastructure, that may include a coordinate system, a cluster structure, and designated communication paths, may be established post-deployment in support of network management and operation. Since knowledge of this virtual infrastructure can be instrumental for successfully compromising network security, maintaining the anonymity of the virtual infrastructure is a primary security concern.
Somewhat surprisingly, in spite of its importance, the anonymity problem has not been addressed in wireless sensor networks. The main contribution of this work is to propose an energy-efficient protocol for maintaining the anonymity of the virtual infrastructure in a class of sensor network systems. Our solution defines schemes for randomizing communications such that the cluster structure, and coordinate system used remain undetectable and invisible to an observer of network traffic during both the setup and operation phases of the network.
Introduction
Recent advances in nano-technology made it technologically feasible and economically viable to develop low-power, battery-operated devices that integrate special-purpose computing with low-power sensing and wireless communications capabilities [16], [23], [24], [40], [49], [55], [59]. It is expected that these small devices, referred to as sensor nodes, will be mass-produced making production costs negligible [20], [44], [60], [76]. Individual sensor nodes have a non-renewable power supply and, once deployed, must work unattended. We envision a massive random deployment of sensor nodes, numbering in the thousands or tens of thousands. Aggregating sensor nodes into sophisticated computation and communication infrastructures, called sensor networks, will have a significant impact on a wide array of applications including military, scientific, industrial, health, and domestic. The fundamental goal of a wireless sensor network is to produce, over an extended period of time, meaningful global information from local data obtained by individual sensor nodes [1], [11], [15], [28], [49], [55], [63], [64], [70].
However, a wireless sensor network is only as good as the information it produces [2]–[6], [8], [9], [12]–[14], [17]–[19], [45]. In this respect, perhaps the most important concern is information security. Indeed, in most application domains sensor networks will constitute a mission critical component requiring commensurate security protection [41], [45], [48], [71]–[75]. Sensor network communications must prevent disclosure and undetected modification of exchanged messages. Due to the fact that individual sensor nodes are anonymous and that communication among sensors is via wireless links, sensor networks are highly vulnerable to security attacks. If an adversary can thwart the work of the network by perturbing the information produced, stopping production, or pilfering information, then the perceived usefulness of sensor networks will be drastically curtailed. Thus, security is a major issue that must be resolved in order for the potential of wireless sensor networks to be fully exploited [21]–[24], [29]–[39]. The task of securing wireless sensor networks is complicated by the fact that the sensors are mass-produced anonymous devices with a severely limited energy budget and initially unaware of their location [1], [41]–[43], [51]–[53].
In many application domains, safeguarding output data assets, data produced by the sensor network and consumed by the end user (application), against loss or corruption is a major security concern. In these application domains, a sensor network is deployed into a hostile target environment for a relatively extended amount of time. The network self-organizes and works to generate output data that is of import to the application. For example, a sensor network may be deployed across a vast expanse of enemy territory ahead of a planned attack; the network system monitors the environment and produces reconnaissance data that is key to a mission planning application. Periodically, during the network lifetime, a mobile gateway, mounted on a person, land or airborne vehicle, or a satellite, collects the output data assets from the network system, to maintain an up to date state. This means the network system must store the output data assets from the time it is produced until it is collected. Therefore, securing the output data assets in the network is an important problem in this class of applications [7], [10], [15], [26], [27], [34], [45], [48], [50]–[52], [54], [56]–[58], [62], [63].
We view an attack on the output data assets in the sensor network as a type of denial of service attacks. This is based on the abstraction that output data is stored in a logical repository, and, that access to this output data repository constitutes, in effect, a service provided by the network system to the application; corruption or loss of output data denies the application access to that service. Many wireless sensor networks are mission-oriented, must work unattended, and espouse data-centric processing. Consequently, they are significantly different in their characteristics from ad-hoc networks; security solutions designed specifically for wireless sensor networks are therefore required.
What is Anonymity?
With the recent growth and wide acceptance of novel applications including e-banking, e-commerce, e-voting, and e-government, concerns about privacy and security have become extremely important. In all these applications anonymity protects the identity of the sender or receiver and guarantees that both parties involved in a communication transaction remain anonymous to each other. Recent years have seen a flurry of activity and many anonymous communication systems have been developed for the Internet [3], [7], [8], [9], [11], [32], [33], [34], [41], [43], [61], [62]. Most of the work on anonymity is concerned with sender anonymity, receiver anonymity, and mutual anonymity. Of the various forms of anonymity mentioned above, sender anonymity seems to be the most critical in current applications. In e-voting, for example, a vote should not be traceable back to the voter that cast it. Likewise, users may not wish to disclose their identities when visiting web sites. Quite recently, traffic anonymity has also received well-deserved attention in the literature. Indeed, if an adversary can identify traffic patterns and routers effecting them, the security risks to the traffic increase multifold. In a homeland security context, a group of terrorists may attempt a surgical operation taking out those routers whose loss will inflict the heaviest damage on the network.
Recently, the problem of securing ad-hoc networks has received a great deal of well-deserved attention in the literature [5], [6], [9], [29], [30], [33], [42], [48]. Somewhat surprisingly, however, in spite of its importance, the anonymity problem has not been addressed in wireless sensor networks.
We view this work as an initial contribution towards developing a lightweight solution for the anonymity problem in wireless sensor networks. In this paper, we focus primarily on structure anonymity in a wireless sensor network. Although the exact statement of the problem we address are presented in Sec. 5, suffice it to say that the basic infrastructure of a wireless sensor network that is constructed immediately after deployment is a coordinate system that affords natural clustering. Our main contribution is to protect the coordinate system from an external adversary by making the process of acquiring the coordinate system anonymous and, thus, invisible, to the adversary.
The Network Model
The network model used in this paper is a derivative of the model introduced in [46], [67]. Specifically, we assume a class of wireless sensor networks consisting of a large number of sensors nodes randomly deployed in the environment of interest. A training process, as explained below, establishes a coordinate system and defines a clustering of all nodes. In post training, the network undergoes multiple operation cycles during its lifetime. The training process also endows the role of sink upon one or more of the defined clusters. The sink role is transient, however, since new sink clusters are designated at the beginning of each operation cycle. Each sink cluster, henceforth called sink, acts as a repository for a portion of the sensory data, generated in the network during an operation cycle. At the end of an operation cycle, each sink transfers data stored in its repository to a gateway. In the following we describe the three primary entities in our network model in more detail.
The Sensor Node
We assume a sensor to be a device that possesses three basic capabilities; sensing, computing, and communication. At any point in time, a sensor node is either performing one of a fixed set of sensor primitive operations, or is idle (asleep).
We assume that individual sensor nodes have four fundamental constraints:
Sensors are anonymous; initially a sensor node has no unique identifier, Each sensor has a limited non-renewable energy budget, Each sensor attempts to maximize the time it is in sleep mode; a sensor wakes up at specific (possibly random) points in time for short intervals under the control of a timer, and Each sensor has a modest transmission range, perhaps a few meters with the ability to send and receive over a wide range of frequencies. In particular, communication among sensor nodes in the sensor network must be multi-hop.
The Sink
The sink granularity in our network model is a cluster in a trained network. For each operation cycle a number of clusters are designated to serve as sinks. This means that all nodes in a sink cluster serve as sink nodes. Coarser sink granularity supports higher sink storage capacity, and thus potentially longer operation cycles. However, coarser sink granularity, as envisioned here, comes at a potentially higher risk of anonymity attacks due to the space correlation among sink nodes. If it is discovered that a node, x, is a sink node then it immediately follows that there exists at least one other sink node (typically more) in the vicinity of x. Thus, the success of an anonymity attack in our model is sensitive to the probability of identifying the first node in a sink. One approach to decrease the latter probability is to have only a subset of the nodes in a sink cluster serve as sink nodes. There is a tradeoff between sink granularity, and hence its capacity and operation longevity, and the amount of security a sink has against anonymity attacks.
A notable advantage of our sink model is that sinks are dynamic configurations of regular nodes in the sensor network, as opposed to being, for example, special supernodes. This makes the system less complex to design and operate, and eliminates a would-be attractive focus for anonymity attacks. Another major advantage is that the sink, in our model, is not a single point of failure, in two distinct ways. First, the network uses multiple sink entities, as opposed to a single sink entity. Second, a sink entity is not a single node; rather it is a set of nodes.
The solution proposed in this paper for the anonymity problem uses whole cluster granularity for the sink. It encompasses techniques for randomly and securely choosing sinks for an operation cycle, and maintaining the anonymity of these sinks.
The Gateway
The gateway is an entity that connects the sensor network system to the outside world. The gateway is not constrained in mobility, energy, computation, or communication capabilities. There are two basic functions for the gateway in our network model:
Training. The gateway performs the network training process, post deployment. For training purposes the gateway is assumed to be able to send long-range, possibly, directional broadcasts to all sensors. It should be noted that our training process does not involve any transmission from the sensor nodes deployed in the network. Thus, in principle, the gateway does not have to be geographically co-located with the sensor nodes during the training process. Harvesting (data collection). At the end of an operation period, the gateway must collect sensory data stored in each sink. In a simple collection scenario the gateway traverses the deployment environment to collect data from all the sinks. If we assume that nodes comprising a sink perform collaborative data fusion, then the harvesting process requires a relatively short period of time. Specific harvesting protocols are beyond the scope of this paper. Harvesting (data collection). At the end of an operation period, the gateway must collect sensory data stored in each sink. In a simple collection scenario the gateway traverses the deployment environment to collect data from all the sinks. If we assume that nodes comprising a sink perform collaborative data fusion, then the harvesting process requires a relatively short period of time. Specific harvesting protocols are beyond the scope of this paper.
In our proposed solution for the anonymity problem discussed in detail in Sec. 4, the gateway is assigned the additional function of a group key management server for the sensor network.
Figure 1(a) features an untrained sensor network immediately after deployment in an environment that is represented here as a 2-dimensional plane. For simplicity, we assume that the trainer is centrally located relative to all deployed nodes. Namely, considering the nodes to be points in the plane, we assume, in this paper, that the trainer is located at the center of the smallest circle in the plane that contains all deployed nodes. It should be noted that this is not a necessary condition. To be specific, our proposed training scheme is applicable if the trainer is located either at the center of, or at a point outside of the smallest circle that contains all deployed nodes.

(a) An untrained sensor network with a centrally located trainer; (b) A trained sensor network
The primary goal of training is to establish a coordinate system, to provide the nodes location awareness in that system, and to organize the nodes into clusters. The coordinate system, and clustering are briefly explained next. We refer the interested reader to [20] for an in-depth description of the training process.
The training process establishes a polar coordinate system as exemplified by Figure 1(b). The coordinate system divides the sensor network area into equiangular wedges. In turn, these wedges are divided into sectors by means of concentric circles or coronas centered at the trainer location. Corona radii can be determined based on several criteria, e.g. in [46], [67] they are designed to maximize the efficiency of sensors-to-sink multihop communication. The intersection of every wedge and corona defines a unique sector; each sector is uniquely identifiable by the combination of its unique wedge identifier, and unique corona identifier. The training process guarantees that each node belongs to one and only one sector in the coordinate system, and that each node knows the identity of its sector [46], [67].
Let c, and w be, respectively, the set of coronas, and the set of wedges defined by the training process. The resulting coordinate system can thus be formally represented by {(r0, r1, …, r|c|–1), θ}, where ri is the radius of corona i, 0 ≤ i ≤|c|–1, θ is the wedge angle, and |w|= 2π/θ . A fundamental assumption here is that any coordinate system is designed such that all nodes located in the same sector can communicate using direct (single hop) transmission.
Clustering
A major advantage of our coordinate system is that sectors implement the concept of clustering (at no additional cost). A sector effectively constitutes a cluster; clusters are disjointed, and are uniquely identifiable. All nodes located in the same sector are members of the same cluster, and have the same location coordinates, namely, the corona and wedge identifiers corresponding to that sector. This clustering scheme is ideally suited for sensor nodes that are intrinsically anonymous. Wadaa et al. proposed in [67] a scalable training protocol where each untrained node incurs a communication cost equal to log|w|+log|c|, and the nodes do not transmit any messages during the training process.
The Work Model
The work model defines how sensor nodes work collaboratively to generate and store sensory data during an operation cycle. We propose a work model that is based on two principles:
Intra-cluster activity generates sensory data of interest to the application, and Inter-cluster activity transports each granule of sensory data to a sink, randomly chosen from among those available, for storage.
Intra-cluster Activity
In our model, the sensory data resulting from intra-cluster activity encodes states of a process of interest. Namely, we assume that the goal of intra-cluster activity is to monitor a process (or phenomenon), and report on its local state at any point in time. The state space of the phenomenon is given by {s0,s1,s2, …, sz}. State s0denotes the normal state, and each of si, 1 ≤ i ≤ z denotes an exception state. The assumption here is each state si, 1 ≤ i ≤ z, corresponds to an application-defined exception of a particular type. The normal state corresponds to the fact that no exception of any type is detected.
We propose a transaction-based model for managing the computation and reporting of target process states. The model is a specialization of a transaction-based management model for sensor networks introduced in [46], [67]. In this model, intra-cluster activity proceeds as follows. For a given cluster, subsets of nodes located in the cluster dynamically band together forming workforces.
Periodically, members of each workforce collaborate to perform an instance of a state computation transaction preloaded into each node. The transaction computes and reports the local process state. Note that the system allows for a fresh transaction to be downloaded to the nodes at the beginning of each operation cycle. In the simplest case, performing an instance of the state computation transaction entails that each member in the corresponding workforce perform a sensing operation and formulate a node report. A specific member of the workforce, designated as a transaction instance manager, then receives all node reports, and formulates a Transaction Instance Report (TIR). The TIR is the encoding of the local process state of interest at the time. This TIR is subsequently transported to a sink for storage. In principle, after transmitting the TIR the corresponding workforce disbands. For simplicity, we assume that at most one transaction instance is in progress in a given cluster at any given point in time.
The state diagram in Figure 2 represents the behavior of an arbitrary workforce in a cluster assuming the special case of a target process that has one normal state, s0, and one exception state, s1. T in the figure denotes the state computation transaction.

A model for workforce behaviour assuming a two-state target process and a canonical transaction
Two important design parameters in the above transaction-based model are workforce size, and workforce setup. These are discussed in the following.
Workforce size
This is application dependent. Applications negotiate QoS requirements, for example, the ‘confidence level’ associated with TIRs. These QoS parameters are, in turn, mapped to constraints at the transaction level. A constraint we assume in the anonymity solution proposed in this paper is that the average workforce size must be larger than or equal to λ, where λ is derived from application-level QoS parameters.
Workforce setup
This is governed by criteria such as load balancing or energy conservation, and thus represents a system concern. We distinguish two basic approaches to workforce setup, static and dynamic. The dynamic approach trades dynamic load balancing at the node level, and robustness to node failures for added delay time and energy overhead of the setup protocol. The static approach trades savings in energy and time of static setup for dynamic load balancing at the node level and robustness to node failures. In our proposed anonymity solution, we organize the node population of a cluster, prior to each operation cycle, into a fixed number of static workforces that have the same size on the average. Workforces are tasked to work (do an instance of the state computation transaction) in a round-robin fashion. The goal of our approach is to eliminate the energy and time overhead of dynamic setup while achieving load balancing at the coarser granularity of a workforce.
As indicated earlier, the goal of inter-cluster activity in our work model is to route TIRs from their clusters of origin to the sinks, by means of multi-hop communication. We define a hop in a route as a direct transmission from one cluster to a neighbor cluster. A cluster uj is a neighbor of a cluster ui if and only if both uj and ui are located in the same corona, or the same wedge, for all i and j, i ≠ j. It follows that in any instance of the coordinate system defined in Sec. 3, each cluster has either three or four neighbors. The set of all neighbors of a cluster u i is called the neighborhood of ui. In the our proposed anonymity solution we define a distributed inter cluster routing protocol that yields optimal routes in terms of the number of hops from source to sink, and is highly scalable in the number of clusters in the network. Scalability can be attributed to two characteristics of the protocol. First, the protocol uses no dynamic global or regional state information. This eliminates the need for control messages to support routing. Second, the protocol uses distributed (incremental) route computation; the destination of hop i, computes, in turn, the destination of hop i+1,i≥1. In the remainder of this paper we assume the availability of a MAC layer that supports inter-cluster communication.
The Anonymity Problem
In this section we formulate a definition for the anonymity problem addressed in this paper. The problem is defined in the context of the network system described earlier. First, we introduce an anonymity threat model.
The Anonymity Threat Model
The threat model assumed in this paper emanates from a data-centric view of the sensor network. The model is predicated on the assumption that the end-goal of anonymity attacks on the sensor network is to identify and eliminate the minimum number of nodes to inflict maximum loss of data assets; eliminating a node means disabling that node so that it is permanently non operational. In our sensor network model, TIRs are the data assets of import to the end user (application). For any operation cycle, if a sink suffers a permanent failure before transferring the contents of its TIR repository to the gateway, then a portion of the data assets corresponding to the cycle is irrevocably lost. Therefore, sinks, or nodes comprising them to be precise, are the assumed targets of anonymity attacks in our model. Specifically, the goal of the adversary system is to eliminate all sink nodes. There are two main approaches to eliminating sink nodes:
Brute-Force (Sink nodes are not identified)
This may take the form of randomly eliminating nodes in the network on the assumption that, statistically, some sink nodes will be eliminated in the process. Coarse sink granularity, and sink redundancy mitigate the risk of loss of data assets as a result of this type of attack. A trivial special case is the massive elimination of all nodes in the network.
Smart (Sink nodes are identified)
The adversary system analyzes network traffic to deduce information about network topology, traffic flow patterns, and other system attributes. The goal is to discover, i.e. compromise the anonymity of, sink nodes, and, hence, eliminate them.
In this paper we assume the adversary system engages in smart elimination attacks. The specifics of the architecture and the implementation of the adversary system are assumed unknown.
Terminology and Notation
The main goal of this subsection is to establish terminology and notation that will be used in our solution to the anonymity problem.

The assumptions underlying our anonymity threat model can be summarized as follows:
Pre-deployment
All nodes are trusted
Nodes are in a secure environment
Trudy does not have access to any message m transmitted in the system.
Post deployment (training and operation cycles)
Trudy receives every message transmitted in the system. Note that receiving a message does not imply being able to interpret it. A message m transmitted in the system is represented in Trudy's system as follows:

Anonymity Problem Statement
Let I be an arbitrary time interval, that starts post deployment, and let the set M = {(mi, ts(mi), l(mi), cvr(mi)) |1 ≤ i ≤ h} be the set of all messages transmitted in the system (and hence recorded by Trudy) during the interval I. Also, let the coordinate system, O, established by training be given by {(r0,r1, …, r |c| −1)q}, and the set of all nodes located in sink clusters be denoted by S.
The anonymity problem (from Trudy's point of view) can thus be stated as follows:
Given:

Find:
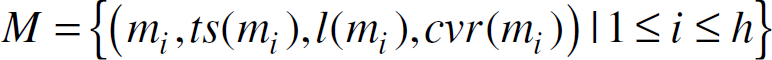
Note that for the message mq in (2), destination(mq) ∊ S. In general, for each message mq that satisfies (2), it follows that

The challenge for the sensor network system is to devise training, intra cluster, and inter cluster protocols that minimize the probability that the anonymity problem stated in equations (1), and (2) is solved, for arbitrary O,I,S, and M. In this work we only look at the problem of providing anonymity during the training period.
The main goal of this section is to propose a protocol for training that addresses the anonymity problem formulated above. The primary goal of the training protocol is to establish the canonical coordinate system,Os, for the network, anonymous to Trudy. For a given sensor network system, the canonical coordinate system is the instance of the polar coordinate system described in 3.4.1 that has the maximum precision. Osdefines the set of canonical coronas, cs, and the set of canonical wedges, ws; we assume that |cs| and |ws| are powers of 2. Os is defined by
Post training, the coordinate system used during any operation cycle is derived from the canonical coordinate system using three integer parameters, 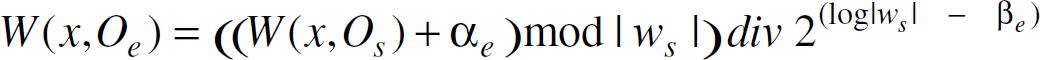
Note that α
e
∊ [0,| ws | −1], β
e
∊ [0, log | ws |], and γ
e
∊ [0, log | cs |]. The corona, and wedge of x according to Oe are defined as follows,


In equation (3) above, γ
e
determines the corona precision of the coordinate system Oe, the minimum precision (a single corona) corresponds to γ
e
and the maximum precision (that of the canonical coordinate system) corresponds to γ
e
= log | cs |. In equation (4)
We are now in a position to present the details of our proposed anonymity-compliant training protocol.
Sensor nodes are randomly and uniformly deployed in a deployment area. The deployment area completely contains a circular area called the network area; nodes located in the network area will comprise our trained sensor network. The mission of the nodes that are located outside the network area is to generate fake message traffic to help keep the network area anonymous.
The gateway is mobile
Pre deployment, the following is loaded into each sensor node:
Secret key, Kmaster used for decrypting training protocol messages from the gateway. Also, Kmaster is used to derive the keys K
The parameters qs, ∊s, D, and rgateway. D is the diameter of the network area, we assume rgateway » D.
Internal clocks in all sensor nodes are synchronized to the gateway.
Do a random traversal of the deployment area, visiting a set of random anchor points A = {a1,a2, …, aA,}, For each ai, 1 ≤ i ≤| A |, do:
Transmit a call-for-training message: Transmit an omni directional broadcast message using rgateway. The message is encrypted by Kmaster and contains a Boolean flag f that identifies ai as either the true anchor point or a false anchor point; the true anchor point is the geographical center of the circular network area.
Corona train: using the sink side of the training protocol described in [67] do corona training to establish coronas for Os, such that Wedge train: using the analogous sink side of the wedge training protocol described in [67], do wedge training to establish the wedges for Os.
Terminate the protocol
Note that the corona training done in step i.2 covers an area considerably larger than the network area. This means that corona training, in this case, defines fake coronas that lie outside the network area (i.e. at a distance more than the diameter D from the true anchor point). The objective is to help keep the diameter D unknown. Because sensor nodes know D, each node, after learning the canonical corona it is located in, can determine if it is located in the network area, and hence, in the trained network. The multiplicity and randomness of anchor points help keep the true anchor point unknown.
In the following assume node x is the node executing the protocol.
Compute | c
s
| = rgateway / ∊
s
, | ws | = 2π / θ
s
Do forever:
Receive the next call-for-training message: receive and decrypt, using Kmaster, the next call-for-training message, m. If the Boolean flag f in m is true, then do:
HGet corona trained: invoke the node side of the training protocol described in [67] to get corona trained to learn the canonical corona number you are located in, c(x,Os). Compute your corona radius: Compute r = (C(x,Os) + 1) × ∊s. (Note that if r ≤ D then you know you are located in the network area, and thus will be a node in the trained network, otherwise you know you do not belong to the trained network.) If you belong to the trained network, do:
Compute | cs | = D/∊
s
Get wedge trained: invoke the node side of the training protocol described in [20] to get wedge trained to learn the canonical wedge number you are located in, W(x,Os).
Using Kα,Kβ, and K
γ
generate via a random number generator (or a preloaded CBC block as described in [12]), respectively, the parameters
Compute
Terminate the protocol.
Else
Sleep for |ws| message times; terminate the protocol.
Else
Sleep for |cs|+|ws| message times.

It is widely recognized that sensor network research is in its infancy. In particular, there is precious little known about how to get sensor networks to self-organize in a way that maximizes the operational longevity of the network and that guarantees a high level of availability in the face of potential security attacks. However, given the characteristics of sensor networks, anonymity protocols developed for wired, cellular, or ad-hoc networks do not apply.
We view this paper as an initial contribution towards developing a lightweight solution for the anonymity problem in wireless sensor networks. Research is underway toward a solution that provides security not only for the various individual layers of the system but also for the entire system in an integrated fashion.