
Abstract
Node clustering in sensor networks increases scalability, robustness, and energy-efficiency. In hostile environments, unexpected failures or attacks on cluster heads (through which communication takes place) may partition the network or degrade application performance. We propose REED (Robust Energy-Efficient Distributed clustering), for clustering sensors deployed in hostile environments in an interleaved manner with low complexity. Our primary objective is to construct a k-fault-tolerant (i.e., k-connected) clustered network, where k is a constant determined by the application. Fault tolerance is achieved by selecting k independent sets of cluster heads (i.e., cluster head overlays) on top of the physical network, so that each node can quickly switch to other cluster heads in case of failures. The independent cluster head overlays also give multiple vertex-disjoint routing paths for load balancing and security. Network lifetime is prolonged by selecting cluster heads with high residual energy and low communication cost, and periodically re-clustering the network. We prove that REED asymptotically achieves k-connectivity if certain conditions on node density are met. We also discuss inter-cluster routing and MAC layer considerations, and investigate REED clustering properties via extensive simulations.
Introduction
Sensor networks are emerging as versatile computing platforms for several monitoring and control applications. These networks are typically deployed and left unattended under possibly harsh conditions, e.g., in volcanic areas or battle fields. Operating in hostile environments necessitates devising efficient self-organization techniques to give the applications a robust and fault-tolerant computing and communication platform. Energy efficiency is also critical. For example, in a sensor network for seismic monitoring or radiation level control in a nuclear plant, the lifetime of each sensor significantly impacts the quality of surveillance.
Clustering is a self-organization technique to prolong the network lifetime. In a clustered network, a set of cluster heads is selected from sensor nodes. The remaining nodes, which we refer to as regular nodes, register themselves with one or more cluster heads. A cluster head is responsible for:
communicating with its registered cluster nodes, typically via a single hop or a few hops, and communicating with other cluster heads or with the observer(s) on behalf of its cluster (via a single-hop or multi-hops).
Clustering prolongs the network lifetime by reducing contention on transmission channels, supporting data aggregation at cluster heads, and giving nodes the opportunity to sleep while not sensing. In addition, cluster heads can rotate their functionality to distribute energy consumption [1], [2], [3], [4], [5], [6], [7].
In this work, we consider applications that operate on large-scale networks deployed in harsh environments. These applications may be
Toward this end, we propose REED (Robust, Energy Efficient, Distributed clustering) — a protocol to build multiple independent cluster head overlays on top of the physical network. These cluster head overlays (i.e., sets of cluster heads and their associated regular nodes) provide means for every node to automatically and independently switch cluster heads on detecting a cluster head failure. In REED, nodes use a transmission range Rc as the cluster range (for cluster formation and intra-cluster communication), and reserve a higher transmission range Rt for inter-cluster communication. REED is completely distributed and has low asymptotic computation and communication overhead, as will be shown in Section III. REED interleaves the construction of the k cluster head overlays, and operates correctly with unsynchronized nodes. We use HEED clustering [3] as the underlying clustering approach for REED because of its generality and energy efficiency. Our ideas, however, can be easily incorporated into any clustering protocol (e.g., REED was combined with LEACH clustering [4] in [10].
We prove that REED constructs k-fault-tolerant clustered networks if certain conditions on node density are satisfied. A graph G = (V, E) is k-fault-tolerant (i.e., k-connected) if it remains connected under failures of up to k − 1 nodes, where k is a constant determined by the application. Figure 1(a) illustrates a possible organization of a 2-fault-tolerant clustered network. In this organization, two cluster head overlays are built on top of the physical network. Each node belongs to 2 clusters in 2 separate cluster head overlays, but only uses one at a time. To the best of our knowledge, no distributed protocols have been proposed in the literature to construct k-fault tolerant clustered sensor networks. Our approach also allows vertex-disjoint multi-path routing by selecting node-disjoint cluster head overlays when the node density allows it. Node-disjoint-paths between a (source, destination) pair can be established by constructing a path through the cluster heads on each overlay. This is demonstrated in Fig. 1(b) Fig. 1(c), where node-disjoint paths exist through dark-colored and light-colored cluster heads.

A network with 2 cluster head overlays. Larger circles denote cluster heads.
The remainder of this paper is organized as follows. Section 2 defines the system model and states the protocol requirements. Section 3 presents our proposed protocol, REED, and argues that it achieves its goals. Section 4 demonstrates the effectiveness of REED via simulations. Section 5 briefly surveys related work. Finally, Section 6 gives concluding remarks and directions for future work.
Consider a set of sensor nodes dispersed uniformly and independently at random on a field. We study utilize a large-scale network; may impose different load in different parts of the network (i.e., energy consumption not necessarily uniform for all nodes); can exploit data aggregation. The applications may be source-driven or query-driven; and operate in hostile, unattended environments, where nodes may unexpectedly fail or are compromised.
Failure may depend on time, network density, or human intervention. The above assumptions describe a class of application scenarios that requires scalable self-organization mechanisms. A hierarchical network organization will not only facilitate data aggregation, but will also facilitate the formation of uniform, robust backbones, and give an opportunity for nodes to sleep while not sensing or transmitting.
We consider a nodes are quasi-stationary, which is typical for most sensor network applications; links are symmetric, and communication is multi-hop; all nodes have similar processing and communication capabilities and equal significance; nodes are not location-aware, have limited battery power, and are not necessarily synchronized (we discuss node asynchrony in Section 3-D); all nodes use a single radio frequency, e.g., 900 MHz for Mica2 sensor motes, or 2.4 GHz for MicaZ motes (the selection of a MAC layer protocol depends on the type of the application as discussed in Section 3-E); failed nodes can not be revived since they are left unattended. If it is possible for a failed node to recover, it starts the clustering process as a newly deployed node (see Section 3-F); and each node has a number (at least 2) of transmission power levels. An example of such sensor nodes is Berkeley motes [11].
The only limiting assumption about the network is the availability of at least two usable transmission power levels for intra-cluster and inter-cluster communication. We only assume link symmetry for nodes that are using the same transmission power. To avoid link asymmetry in practical settings, a node u does not consider node v to be its neighbor unless v declares that it has heard the heartbeat from u. The fifth assumption does not limit our solution, as we will show in Section 3-E. Our primary objective is to design a distributed algorithm for constructing a fault-tolerant clustered network. Note that our assumption about node stationarity is essential at least for the elected cluster heads to maintain k-connectivity during network operation. The following requirements of the algorithm must be met:
The clustered network should be k-fault-tolerant if certain conditions on node density are satisfied (defined in Section 3-C). In a k-fault-tolerant network, the network remains connected even under the failure of up to k − 1 nodes. If the conditions on node density cannot be met, the protocol performance should degrade gracefully. The network should provide k node-disjoint paths between every source-destination pair in the network. Clustering must be fully distributed; clustering must terminate within a fixed number of iterations, regardless of network diameter; clustering must be efficient in terms of processing complexity and message exchange; and cluster heads must have relatively high residual energy, compared to regular nodes.
The REED Protocol
In this section, we discuss the design and operation of REED, and prove that it satisfies its requirements.
Design Rationale
To achieve k-connectivity in a clustered network, every node must a least be able to connect to k distinct cluster heads. There are two options for selecting these k cluster heads:
maintaining k − 1 backup cluster heads in every cluster, or maintaining k independent cluster head overlays, such that each node can connect to one cluster from each overlay.
A cluster head overlay is a set of clusters (and their associated cluster heads) that covers the entire network. The first option has one major limitation: it is difficult to guarantee that there exist k nodes in a cluster that can cover — using the same cluster power level Rc (i.e., same transmission range) — all cluster members. The second option overcomes this limitation and allows low-overhead construction of k disjoint paths between every source-destination pair in the network. It also handles the worst-case scenario of k-1 cluster head failures. Therefore, we investigate the second option further in this paper. If the node-disjoint paths requirement is unessential, and node failures are random (i.e., cluster heads are not targeted), the number of constructed overlays can be reduced to < k.
Figure 2 illustrates a network with k cluster head overlays. Observe that each sensor node can register with one cluster head in each overlay. In order to achieve k fault-tolerance, the protocol must not select the same node as cluster head in multiple cluster head overlays. This can only be satisfied if the node distribution and density in the network allow it (as specified in Section 3-C). We can now re-state the first requirement in Section 2 as follows: Each node v should be assigned a cluster head CHj from each independent cluster head overlay CSi, where 1 ≤ j ≤ nchi, nchi is the number of cluster heads in a certain cluster head overlay CSi, CHj ϵ CSi, and 1 ≤ i ≤ k. Single-hop communication is used for intra-cluster routing (except where mentioned below), while multi-hop communication is likely among cluster heads for inter-cluster routing and to communicate with the observer(s).

A network with k cluster head overlays. Every node has one cluster head in each overlay.
When a cluster head fails during network operation, nodes communicating with that cluster head simply switch to another cluster head in another cluster head overlay (see Section 3-G). The primary advantage of our approach is that the node quickly finds an alternate head and alternate communication paths, without waiting until re-clustering is triggered. Observe, however, that in this case, media access control protocols must take into consideration that the same node can be simultaneously acting as a cluster head to other nodes and as a regular node with respect to another cluster head. Media access considerations in this case are discussed in Section 3-E. We use the same cluster power level Rc in all cluster head overlays. This approach allows the application to select the best cluster range a priori and use it, even under failures. Selection of the best cluster range is beyond the scope of this work: it is typically selected to increase spatial reuse, maintain connectivity, and reduce energy consumption.
The REED clustering process constructs k-cluster head overlays. Within a single cluster head overlay, clusters are disjointed, i.e., a node belongs to exactly one cluster. In this section, we apply the REED approach to HEED clustering [3]. We have also applied REED to LEACH [4] clustering in [10]. REED cluster head selection is based upon two parameters:
a primary parameter, which is the node residual energy, and a configurable secondary parameter, communication cost, which is used to break ties among selected cluster heads within each other cluster range.
Each node u ϵ V executing REED proceeds through three phases:
Initialization, Main Processing, and Finalization.
In the “Initialization” phase, u sets its probability of becoming a cluster head to:

where Er is the estimated residual energy in u, Emax is a reference maximum energy (e.g., corresponding to a fully charged battery), and Cprob is a small fixed probability (e.g., 0.05) used to limit the initial number of nodes competing to become cluster heads.
Node u then discovers the neighbors within its cluster range Rc, and computes its communication cost at this cluster range. The communication cost for node u (which should be minimized) can be [3]:
degree(u), if the application requirement is to balance load among cluster heads, or the average minimum reachability power (AMRP), which is the mean of the minimum power levels required by all M nodes within a cluster range to reach the cluster head u, i.e.,
In the “Main processing” phase, REED interleaves the construction of cluster head overlays. Node u iterates Ninitia times. Each iteration has a fixed duration that accommodates a small number of messages (cluster head announcements)
1
. At the end of each iteration, u arbitrates among the cluster head announcements that it receives to select its cluster head for each cluster head overlay according to the lowest cost. u also probabilistically elects itself to become a cluster head for the first of the remaining “uncovered” overlays. A node is uncovered in an overlay if it has not received cluster head announcements for that particular overlay. Therefore, if the uncovered cluster head overlays for a node are CSk1, CSk2,…, CSk, k1 < k2 < … < k, then u competes for CSk1 first, then CSk2, and so on. If successfully elected, u announces itself as a tentative cluster head (T_CH) for that overlay. Node u does not compete to become a cluster head for more than one cluster head overlay. At the end of each iteration, u doubles its CHprob. This operation is repeated until CHprob reaches 1. Thus, Ninitial is computed as follows:
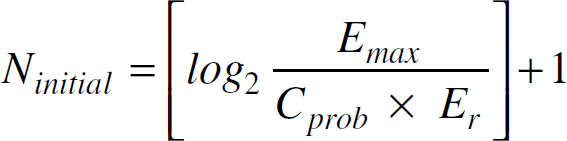
When CHprob reaches 1, u announces itself as a final cluster head (F_CH) for any cluster head overlay within which it had previously announced itself a tentative cluster head (if any), provided that it has not received any announcements of other tentative cluster heads with lower cost. After doing so, u continues to listen to cluster head announcements for cluster head overlays in which it is not covered. This process continues for a total of Ncomplete iterations (including the Ninitial iterations). This ensures that all nodes, even those with high residual energy (i.e., CHprob reaches 1 quickly), are likely to have distinct cluster heads for different cluster head overlays. Note that the initial value of CHprob is not allowed to fall below a threshold pmin. Thus, the value of Ncomplete is a constant, computed as:
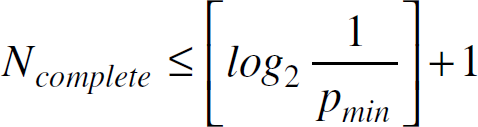
Since Ncomplete is a constant, the protocol terminates in O(1) iterations. For example, for pmin = 10−4, Ncomplete = 15. Assuming that the value of k is small (below 10), that pmin is correctly selected, and that the sensor network is sufficiently dense (as described in Section 3-C), the probability of nodes serving as cluster heads in more than one cluster overlay is extremely small. We verify this via simulations in Section 4.
In the “Finalization” phase, REED ensures that, if possible, a node is a cluster head in no more than one cluster head overlay. A node u that is uncovered in ku < k overlays sends a list Sun of these overlays to all its neighbors in its cluster range. Each neighbor nbri, which is covered in one or more of the overlays in Sun, waits for a random period of time inversely proportional to its residual energy before responding. Each nbri then replies back with its covered overlays among Sun to u if it does not hear any other replies to u. Node u arbitrates among the replies and selects one neighbor for each uncovered overlay to act as its proxy. For these uncovered overlays, node u can reach a cluster head in two hops via the proxies. For the covered overlays, node u reaches its cluster head in a single hop. A node does not act as a proxy for more than one neighbor, in order to maintain the uniqueness of paths in each cluster head overlay. If a node cannot find a cluster head or a proxy to cover an overlay, it simply represents itself in that overlay. Figure 9 gives a pseudo-code for the REED protocol executed at a node u. In the pseudo-code, Snbr is set of neighbors of u (i.e., at a distance ≤ Rc), and CSi is the ith cluster head overlay, i ≤ k. The variable my_CH[i] stores the cluster head of u for CSi, SCH[i] stores the set of cluster heads in CSi, and proxy_CH is the set of messages from neighbors indicating the cluster head overlays in which they can serve as proxies. We do not show message reception in the pseudo-code.
We now show that the REED protocol meets the requirements outlined in Section 2.
Observation 1
The number of iterations in the Main Processing phase of REED is a function of pmin. Thus, pmin must be selected such that at least k iterations are performed. REED terminates in Ω(k) and is O(1) iterations.
Lemma 1
REED has a worst case processing time and message exchange complexity of O(kn) and O(k) per node, respectively, where n is the number of nodes in the network.
Proof
For each node, the Initialization phase takes a processing time of at most n to compute the cost for each cluster range. For the Main Processing phase, the time taken to arbitrate among cluster heads in all iterations is at most Ncomplete × k × n. Similarly, the Finalization phase takes a processing time of at most kn to arbitrate among the nodes which declared themselves as tentative cluster heads. Therefore, the total time complexity is O(kn). For message exchange, a node is not permitted to send more than one cluster head message at any iteration in the Main Processing phase. Therefore, a node sends at most Ncomplete cluster head messages. A regular node is silent until it sends a join message to a cluster head. The number of these join messages per node is at most k (i.e., O(k)).
We have previously demonstrated that using appropriate bounds on the cluster range and inter-cluster transmission range, and under the density model defined in [13], a cluster head overlay is connected asymptotically almost surely (a.a.s) [3]. In this section, we show that with REED, the network graph is k-connected a.a.s. under the density model described below.
Assume that n nodes are uniformly and independently dispersed at random in an area
We now show that a minimum cell occupancy of at least k a.a.s., together with our protocol operation (which assigns unique cluster heads for all k cluster head overlays), allow satisfying the k-connectivity and cluster head uniqueness requirements of REED. Let ŋ(n, N) be a random variable that denotes the minimum number of nodes in a cell, α be n/N, and ph (α) be
Theorem 1
If
Based upon this theorem, we extend the analysis in [13] to give sufficient conditions for k-connectivity. We prove the following two theorems:
Theorem 2
For any fixed arbitrary k > 0, assume that n nodes are uniformly and independently distributed at random in an area R = [0,L]2. Assume R is divided into N square cells, each of side
Proof
According to Theorem 1, a minimally occupied cell has either h or h + 1 nodes a.a.s. if the condition stated in the theorem holds. Assume that the relation
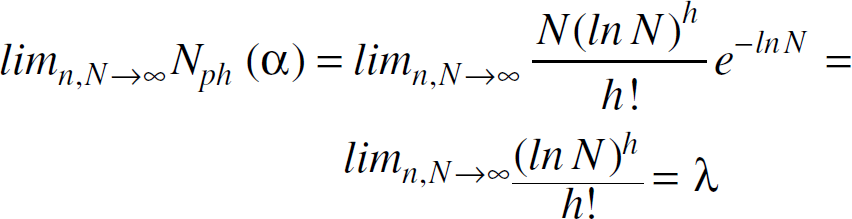
Taking the logarithm of both sides, and using the Sterling formula approximation:

which will not converge to a constant result unless h ln N (h k in Theorem 2).
Theorem 3
REED produces a k-connected network among all k cluster head overlays a.a.s. for networks satisfying the conditions in Theorem 1 and Theorem 2.
Proof
We have shown in [3] that a cluster head in cluster head overlay CSi is connected (at the cluster head level) to at least four other cluster heads a.a.s., assuming a density model in which each
Observe that the coverage problem is orthogonal to the connectivity problem addressed in this work. If the coverage/sensing and transmission ranges of nodes are similar, simple sleep/wake up protocols, such as PEAS [16], can be employed to maintain coverage. Conditions on the number of nodes and its relation to the coverage range and failure probability are given in [17]. Our density model remains valid for connectivity and coverage as long as the sensing range Rs exceeds or is equal to Rc.
Node synchronization is not required for REED operation. Lack of synchronization may only result in less optimal choices of cluster heads (in terms of residual energy) in the first cluster head overlay. When nodes with slower clocks start receiving cluster head messages for the first cluster head overlay from nodes with faster clocks, REED is triggered at these slower nodes which may become cluster heads in other overlays. The REED design—which interleaves the selection of cluster heads for different overlays—has an important advantage (in addition to low complexity): it eliminates any need for synchronizing the start of each cluster head overlay construction. The particular sensor application may, however, need to synchronize the network, e.g., for data aggregation, caching, TDMA scheduling, or if nodes use a duty cycle to switch to sleep mode during idle periods. Mechanisms such as [18], [19],[20] can easily be employed to synchronize the nodes, thus paving the way for more efficient clustering. The synchronization requirement in these cases is pertinent to the multi-hop nature of the network, and is not required by the clustering protocol.
To accommodate nodes with highly variable clocks, as well as newly deployed nodes in the network, we trigger REED as follows. When the clustering timer is triggered in a cluster head with a fast clock, it broadcasts a message to its members and all its neighboring heads to start REED clustering. A cluster head that receives such a trigger message immediately broadcasts a message to its members and neighboring heads and starts REED clustering. Therefore, when REED is triggered in certain regions in the network, these in turn trigger other regions. In addition, nodes that do not receive the trigger messages are automatically triggered when they start receiving cluster head announcements as described above.
A newly deployed node v must start REED clustering immediately after deployment. If cluster head announcements (through routing updates or heartbeats) reach v before its clustering process is complete, v can join existing clusters. Otherwise, v elects to become a cluster head during the rest of this round for uncovered overlays, and it is triggered by a neighboring cluster head for the start of the next round. We have implemented this approach on Berkeley sensor motes for single overlay clustering [21].
Medium Access Control and Duty Cycle
The network organization resulting from REED clustering is ideal if each node possesses k+1 different radios or non-interfering channels. In this case, different frequencies can be assigned for intra-cluster and inter-cluster communication for each of the k overlays. For cheap sensors, however, only a single radio frequency is typically available (as stated in Section 2). In this case, we recommend parallelizing the intra-cluster and inter-cluster communications by assigning two different CDMA codes: one for intra-cluster communication and the other for inter-cluster communication, to enable them to proceed simultaneously. At the inter-cluster level, contention-based MAC schemes, such as the 802.11 DCF, can be used. At the intra-cluster level, it is typically easy to synchronize a regular node with its cluster head(s) using techniques such as [18], [19]. Intra-regional synchronization facilitates constructing TDM schedules for each cluster. Therefore, after the k overlays are constructed, every node contacts each of its k cluster heads to be assigned a time slot in the TDM frame of the cluster head. A node keeps a list of its schedules with each cluster head to be able to switch to another head when one fails. Since it is difficult to assign different frequencies or CDMA codes to the cluster heads, cluster heads should compete for the medium using contention-based MAC layer protocols, e.g., 802.11 DCF.
Energy-efficiency is significantly improved if a duty cycle is applied where nodes wake up for short periods of time to sense the medium and report their information, and then go back to sleep. Clustering gives an opportunity for regular nodes to exploit this duty cycle because they are not part of the routing infrastructure. In a clustered, multi-hop network, the cluster head will be responsible for synchronizing its members' sleep and wakeup cycles to ensure their participation in the clustering process, guarantee an effective data rate, and coordinate the TDMA schedule (if applicable). Three considerations are important for duty cycle support:
the protocol used for scheduling the node duty cycles should effectively yield an active set of nodes that uniformly covers the entire network area. This is possible if sleeping nodes are selected intelligently or a sampling technique is used, such as [22]; the set of active nodes should satisfy the density model specified in Section 3-C; and a node that acts as a cluster head in any of the k overlays should not be put to sleep until it gives up its role when clustering is re-triggered, or its duty cycle is synchronized with its cluster members and its neighboring cluster heads. Integrating node duty cycle with topology management is planned in our future work.
Detecting Cluster Head Failures
In hostile environments, a cluster head must periodically broadcast a “heartbeat” message to inform its members that it is still functional. A regular node determines that its cluster head has failed if it does not receive any heartbeats for a specified interval of time. This approach entails that cluster members are synchronized with their cluster heads to be able to wake up to capture heartbeats. Alternatively, a regular node can solicit a heartbeat from its cluster head after sending a certain number of messages. This is useful in networks where regular nodes go through a duty cycle and cannot hear periodic cluster head heartbeats. The cluster head would, however, need to respond to each individual member instead of periodically broadcasting a heartbeat to the entire cluster in this case. Cluster heads detect neighboring cluster head failures using routing updates if pro-active routing is used at the inter-cluster level. Failures are implicitly detected without extra overhead if reactive routing is used. If failed nodes can be revived, a node starts the clustering process as any newly deployed node would, and listens to cluster head announcements in order to cover its k overlays. Regular nodes are not part of the routing infrastructure and their failure does not impact network connectivity. When a node detects the failure of its primary cluster head, it switches its transmissions to the next cluster head on its list.
Inter-cluster Routing
In the cluster head overlays, an ad-hoc routing protocol, such as Directed Diffusion or Dynamic Source Routing (DSR), is employed for determining routes among cluster heads for selected subsets of the overlays. These routes are used to communicate among clusters, or among clusters and observer(s). As discussed in Section 3-E, CDMA is used to allow inter-cluster and intra-cluster communications to proceed simultaneously without interference. Two alternatives are possible to exploit the multiple overlay organization according to the environment:
If unexpected node failures are common, all the cluster heads in the k overlays participate in the routing infrastructure to increase the degree of connectivity. This alternative is demonstrated in Fig. 3(a). We quantify the increase in the number of successful transmissions with this approach in Section 4-B and Section 4-C. In the presence of compromised nodes that may deliberately drop packets, a source node transmits duplicate packets on each of the k overlays independently. In other words, node-disjoint paths are exploited to avoid black holes (nodes that drop packets instead of forwarding them) in the network. This is demonstrated in Fig. 3(b) where only the packet on overlay 2 succeeds to reach the destination. We demonstrate the effectiveness of this approach in Section 4-C. Note that we are merely trying to find more than one connected path to get around compromised nodes and not to identify the compromised nodes.
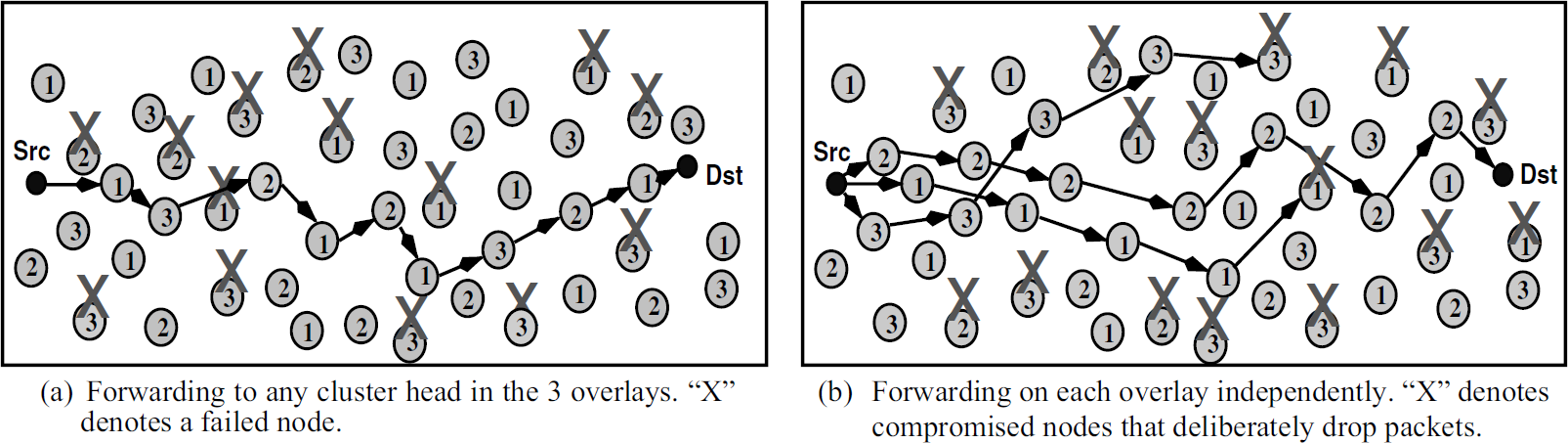
Inter-cluster routing alternatives on a network with 3 overlays. The number on each node denotes which overlay it belongs to.
Thus far, we have assumed that k is a constant determined by the application. Since our model assumes that nodes fail unexpectedly or due to energy depletion, the node density decreases during network operation. Thus, it may become impossible to construct k independent overlays. A reasonable action to take in this case is to reduce the value of k. It is difficult, however, to have the entire network agree on a new value of k, since we do not assume the presence of any centralized control entity. Fortunately, this problem is mitigated by the clustering approach itself. Since cluster head overlays are “gradually” constructed, nodes in some areas of the network will be unable to find cluster heads for all k overlays. Therefore, these nodes will have to represent themselves for some of the k overlays. If this holds for nodes in different areas of the network, this implies that nodes are actually using a smaller k. In other words, only k' < k overlays are independent. Therefore, the protocol degrades gracefully when the density constraints cannot be met. We show in Section 4-A that cluster heads serve in more than one overlay when the density decreases (Figs. 5(b) and 5(c)). This corresponds to a smaller k.
Performance Evaluation
In this section, we study the connectivity and fault tolerance of REED clusters, as well its energy-efficiency and routing properties. We have implemented our own discrete-event simulator that is much simpler than existing simulators, such as ns-2 or GloMoSim. This simplicity allows the simulator to scale to thousands of nodes. The simulator does not model all the details of a realistic MAC layer protocol, e.g., interference. This is a reasonable approach for three reasons. First, all the results presented below are comparative and use the same simplifications for all the scenarios. Second, we assume that the MAC layer uses CDMA (or orthogonal channels) to allow simultaneous intra-cluster and inter-cluster transmissions. The size of the DSSS codes is accounted for in the simulations. Third, the typical packet sizes are small (the default is 29 bytes for TinyOS [23]), which reduces the probability of collisions, especially when aggregation is used.
Cluster and Connectivity Properties
We assume that 1000 nodes are uniformly dispersed in R = [0, L]2 area where L = 100 m, unless otherwise specified. We set Cprob to 0.05, and pmin to 0.0005. Therefore, Ncomplete = 12. Each node initially has a residual energy Er = Uniform(0,1) Joule. We use AMRP as the secondary clustering parameter (to break ties). Each result shown is the average of 1000 simulation runs. We have verified that each independent cluster head overlay that REED constructs exhibits several properties shown for HEED [3] (we omit these results for brevity). The most important property is that cluster heads have high residual energy, compared to regular nodes.
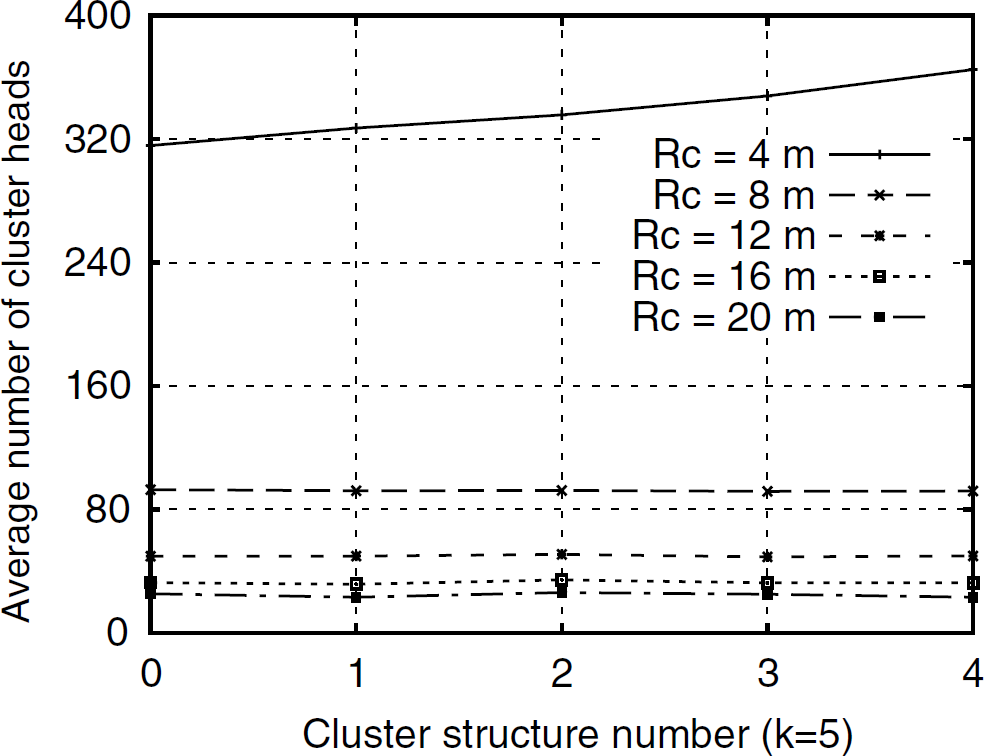
Average number of cluster heads in a cluster head overlay.

Cluster properties and connectivity after employing REED.
We compare the cluster properties of the independent cluster head overlays. Results (shown in Fig. 4) illustrate that the average number of cluster heads for 5 independent cluster head overlays (k = 5) at different cluster ranges (from 4 m to 20 m) tends to be uniform for all cluster head overlays. This is because the cluster range Rc is the same for all overlays and the basic clustering approach selects cluster heads that are not neighbors at Rc.
We also investigate the number of neighboring cluster heads for each cluster head in any cluster head overlay, for different values of k and transmission range Rt. The cluster range Rc is set to 20 m and Rt is varied from 20 m to 64 m. Figure 5(a) illustrates that each cluster head can find neighboring cluster heads, even for small values of Rt (close to Rc). As Rt increases, every cluster head has an increasing number of neighboring cluster heads, thus increasing connectivity and fault tolerance. This agrees with our discussion in Section 3-C which concluded that Rt < 2Rc is typically sufficient for inter-cluster connectivity. Since Rc = 20 m satisfies the condition in Theorem 2 (for a = 10), as Rt grows with respect to Rc, the network is k-connected as illustrated in the figure. The node degree of a cluster head is therefore dependent on the Rt / Rc ratio. We can see from the figure that each cluster head about 4–8 neighboring cluster heads per overlay for ratios of 2.5–3.
Figure 5(b) shows the percentage of nodes that act as cluster heads in multiple cluster head overlays, as the number of nodes in the network increases. Here, Rc is set to 10 m. From the figure, the percentage is small and depends on the cluster density α = n/N, which depends on the number of nodes, their distribution, and the cluster range. This percentage becomes zero as the mean cluster density increases from α = 2.5 nodes/cell (for n = 500 nodes, and N = 200 cells) to α = 25 nodes/cell (for n = 5000 nodes and N = 200 cells). Note that
In this section, we study the fault tolerance of a simple sensor data aggregation application that utilizes REED clustering. In this application, regular nodes report their data to their cluster heads. Cluster heads periodically send their aggregated reports to a single distant observer (e.g., a base station) via a single hop (Section 4-C studies mutli-hop communication). Each cluster head is assumed to create a TDMA schedule for its nodes. All regular nodes send their data to their respective cluster heads according to this specified TDMA schedule. We assume Direct Sequence Spread Spectrum (DSSS) codes are used to minimize inter-cluster interference. Therefore, we ignore collisions in our simulation. We assume that the data propagated by the sensor nodes is aggregated (using operations such as minimum, average, sum). Each cluster head aggregates the data it receives from its nodes into one frame and sends it to the observer. Clustering is triggered every NTDMA TDM frames. Let the clustering process interval, TCP, be the time taken by the clustering protocol to cluster the network. Let the network operation interval, TNO, be the time between the end of a TCP interval and the start of the subsequent TCP interval. The network operation interval TNO = Tf × NTDMA, where Tf is the time required to collect messages and send one TDM frame. We send 30 TDM frames every TNO in our simulations.
We use a simple radio model, as in [4]. The following parameters are defined in that model:
Eelec: energy expended in digital electronics, and Eamp: energy expended in communication.
Two models are considered:
free space model, in which Eamp = ϵ
fs
when d < d0, and multi-path model, in which Eamp = ϵ
mp
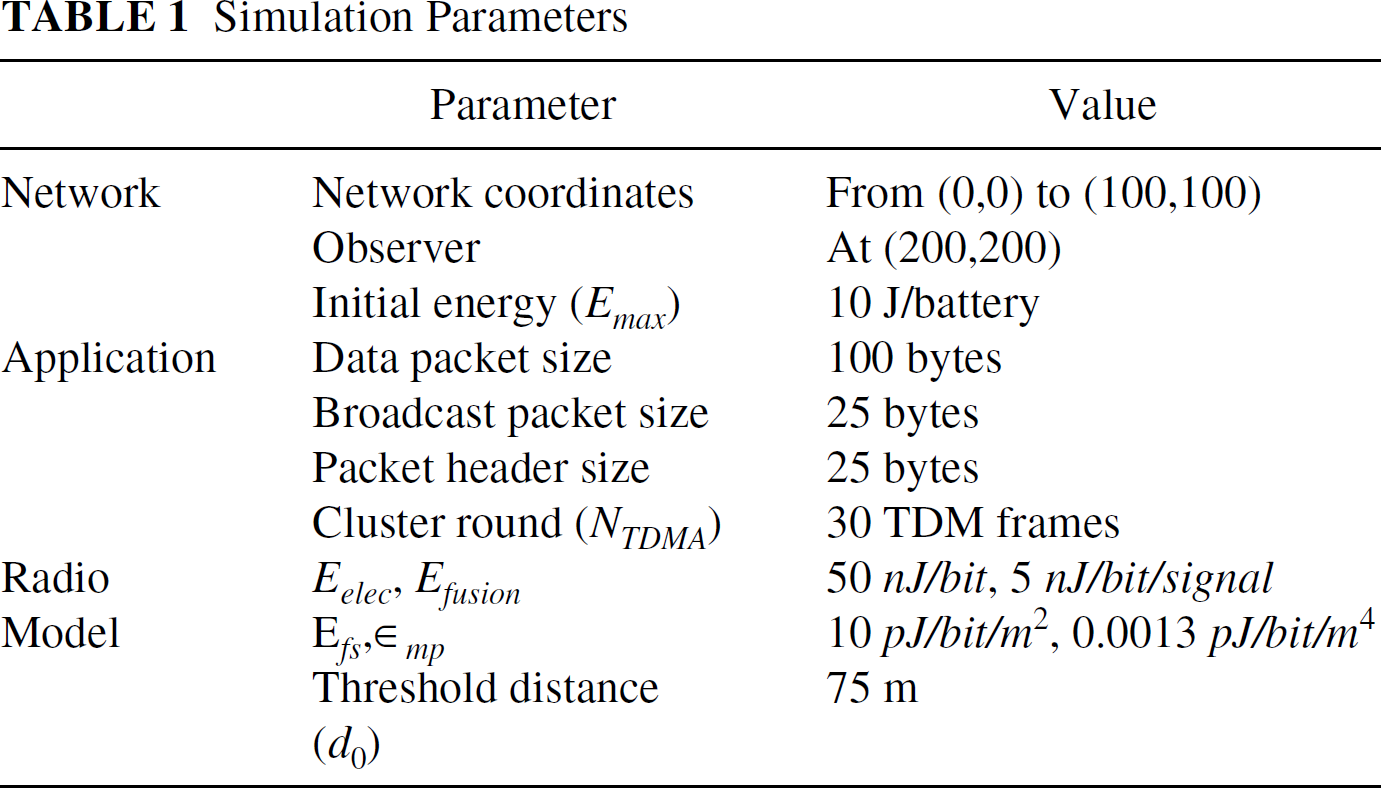
when d > d0, where d0 is a constant distance that depends on the environment. Our simulation parameters are listed in Table 1.
We study the performance of REED during the first 10 clustering rounds, where a clustering round = TCP + TNO. This allows for the isolation of the effect of unexpected failures from that of energy depletion. To study a worst case scenario, we consider failure of cluster heads only, not regular nodes. This can occur if, for instance., an eavesdropper receives cluster head announcement messages and destroys a number of these cluster heads. We quantify the gains of applying REED clustering to the network under two different fault scenarios.
Fault Scenario 1. We assume that at the beginning of every TDM frame interval, r = 2 or r = 4 cluster heads fail. For the case of r = 2, one (two for r = 4) randomly selected cluster head from the currently used cluster head overlay fails, and another randomly selected cluster head (two for r = 4) from any other randomly selected cluster head overlay fails (and thus does not send its cluster information to the observer). Without REED, nodes assigned to a cluster with a failed cluster head have to wait until clustering is re-triggered to transmit their sensed information. We use two values of k. We measure the percentage of increase in the number of successful transmissions from a regular node to a cluster head with r = 2 and r = 4. The increase in successful transmissions is compared to the case where k = 1 (the HEED protocol [3]). Figure 6(a) illustrates that the increase is significant. The increase is more pronounced for the case of an increased number of failures (r = 4). A value of k = 3 is sufficient for this failure rate, and k = 5 only slightly increases successful transmissions.
Fault Scenario 2. At the beginning of each TDM frame, two (or four) randomly selected cluster heads fail from any of the k cluster head overlays. In addition, any node (cluster head or regular node) may fail at any time with probability p. We plot the increase in the number of successful transmissions for k = 3 and k = 5, using p = 4% (with r = 2) and p = 8% (with r = 4). Figure 6(b) illustrates that a significant increase is observed with both values of k (a slightly higher increase is observed for both fault rates with larger k). The increase is not as large as that in Fig 6(a). This is attributed to the difference in initial node failures. In the first scenario, failures directly target the top cluster head overlay, thus resulting in a lower number of successful transmissions for k = 1.

Effect of using REED on the number of successful transmissions (single hop communication).
Simulation Parameters
In this section, we investigate REED multi-path routing and energy-efficiency properties to assess the energy-reliability trade-off.
Inter-cluster Routing. We use the same simulation parameters as in Section 4-B, except that packets are being transmitted from the bottom left corner of the network (the closest cluster head to (0,0)) to the top right corner of the network (the closest cluster head to (100,100)). We use Rt = 2.5 × Rc. The application operates for 20 clustering rounds, with 30 TDM frames per TNO interval (a maximum of 600 packets can be transmitted). After every TNO interval, Ne cluster heads fail, where Ne = Uniform(10, 110). When a regular node detects a cluster head failure for k = 2 or k = 3, it automatically switches forwarding to another cluster head on the next available cluster head overlay. We exploit all functional cluster heads in all overlays in this experiment, which is the first routing alternative in Section 3-G.
We compare REED performance for k = 2 and k = 3 to the case of k = 1 (which corresponds to the HEED protocol [3]) and the case of the Distributed Clustering Algorithm (DCA) [2]. We chose DCA as a representative weight-based clustering approach that selects well-distributed cluster heads in the network (other examples of weight-based approaches are given in Section 5). Figure 7(a) shows that the successful transmission gains (computed here for both intra and inter-cluster transmissions) for larger k are significant, especially for low network density. This is because low density implies low inter-cluster network connectivity. As the network becomes denser, the gain with larger values of k diminishes. This can be attributed to the fact that although the number of nodes in a cluster increases with increased density (which implies a more severe cluster head failure effect), the percentage of failed nodes decreases, since our choice of number of failed nodes is independent of network density. This leaves more operational nodes during each round, resulting in less room for improvement by increasing k. The figure also shows that higher reliability is achieved at smaller node densities for larger values of k due to increased path availability.

Effect of REED on the number of successful transmissions (multi-hop communication).
We now study the second inter-cluster routing alternative described in Section 3-G, and compute the number of successful transmissions from a source at the bottom left corner of the network to a destination at the top right corner. In this scenario, the source sends every packet on each of the k overlays independently to improve its chance of reaching its destination. At every TNO interval, 2.5% of the nodes fail, which means that at the end of 20 rounds, 50% of the nodes in the network have failed. Figure 7(b) shows that as k increases, the number of successful transmissions increases significantly, compared to DCA and k = 1 (HEED). The number of successful transmissions is higher for lower node densities. This is because fewer nodes (and consequently cluster heads) fail at lower densities.
Energy-efficiency. REED elects cluster heads which are rich in residual energy, and rotates the cluster head functionality among nodes. We compute the average residual energy per cluster head, weighted by the number of nodes in the cluster using the settings in Section 4-A. Let m be the number of clusters in CSi, 1 ≤ i ≤ k. Let ej be the residual energy of cluster head ch for cluster Cj ϵ CSi, 1 ≤ j ≤ m. Let nj be the number of nodes in Cj. The average weighted residual energy for CSi, ewi, is computed as follows:

Energy-efficiency and clustering overhead in REED.
Using the first scenario described in Section 4-B, we estimate the percentage of energy dissipated by the clustering process as a fraction of the total dissipated energy. The energy dissipated by the clustering process includes energy for:
message exchange to announce a cluster head or to join a cluster, and processing and data aggregation performed at the cluster head, in order to send one message on behalf of its cluster members to the external observer.
We assume that additional processing overhead, such as computing costs, is negligible. The total dissipated energy includes:
message exchange between regular nodes and their cluster heads, message exchange between cluster heads and the observer, and clustering overhead.
The results demonstrated in Fig. 8(b) indicate that
the ratio of energy dissipated by REED is ≤ 8% of the total energy dissipated, the REED energy consumption slightly increases as the network density increases, and the energy dissipation is not significantly affected by using larger values of k.

Pseudo-code of the REED protocal at node u.
Fig. 8(c) shows the energy dissipation for control overhead and total energy dissipation during the operation period. The control overhead corresponds to the packets used for clustering. The three curves at the bottom of Fig. 8(c) indicate that the control overhead for k = 3 is at most twice that for k = 1 (which corresponds to HEED clustering [3]). In addition, the control overhead is reduced as k increases (e.g., k = 5). This is because the competition for high-index overlays results in less cluster head announcements than low-index overlays, since the cluster head probability is closer to 1 and fewer iterations than Niter 2 are remaining. Note that the routing update overhead (heartbeat messages) is not accounted for in both the overhead and total dissipation results in Fig. 8(c). The results only account for clustering-related overhead.
The results in Figs. 8(b) and (c), in conjunction with the results in Fig. 7, clearly indicate that the energy cost for achieving significant reliability improvements using REED is extremely small. We therefore conclude that REED is an effective topology management protocol for sensor networks.
Clustering protocols have been investigated as either independent protocols for organizing ad-hoc networks, e.g., [1], [7], [2], [24], [5], or in the context of routing and power management, e.g., [12], [25], [4], [26]. Weight-based clustering protocols use a generic parameter(s) or weight associated with each node to make clustering decisions [2], [1], [3], [4]. In [24], the authors propose using a spanning tree (or BFS tree). Earlier work also proposed clustering based on degree or lowest identifier heuristics [25], [27], [28], [29]. LEACH [4] is an application-specific data dissemination protocol that uses clustering to prolong the network lifetime. In [6], a multi-level hierarchical structure is proposed, where cluster heads are elected according to their residual energy and degree. CLUSTERPOW [12] proposes that a node use the minimum possible power level to forward data packets to the next hop, in order to maintain connectivity while increasing the network capacity and saving energy. Another approach proposed for mobile radio networks [30] builds multiple virtual subnets by carefully assigning node addresses. We proposed HEED [3]— a low complexity clustering protocol that converges in constant time and aims at prolonging the network lifetime and selecting well-distributed cluster heads. The impact of sudden failures due to harsh environmental condition, however, was not considered in all the above studies, including our own previous work.
Our model assumes that sensor nodes are all equally significant and location unaware, unlike protocols such as [14], [31], where nodes are classified according to their geographic location into equivalence classes (cells). A fraction of nodes in each class (representatives) participate in the routing process, while remaining nodes are turned off to save energy. In the Probing Environment and Adaptive Sleeping (PEAS) protocol [16], a sleeping node wakes up after a random period of time to check if there is a working neighbor. If so, it goes back to sleep. As the network becomes denser, cell-based techniques have been shown to significantly prolong the network lifetime [13].
Several approaches have been proposed to modify the network topology by changing the transmission power levels in such a way that the resulting communication graph is k-connected. Finding the minimum cost k-connected graph is an NP-hard problem [32]. In [33], an approximation of this problem is formulated as a linear programming (LP) problem. Solving the LP problem is difficult for sensor nodes with limited processing capabilities. This approach also requires centralized control. In [34], a number of heuristics are proposed for efficient energy consumption using centralized control. Distributed algorithms are also presented in for the 2-connectivity and 3-connectivity problems. In [35], a distributed heuristic solution, the Cone-Based Topology Control (CBTC), is proposed. The CBTC approach, however, assumes that nodes can determine the direction of their neighbors.
Conclusions
In this paper, we have presented REED, a distributed clustering protocol for robust ad-hoc sensor networks. REED achieves fault tolerance by constructing multiple independent cluster head overlays on top of the physical network. A node joins one cluster in each of the independent overlays. The REED clustering process terminates in a constant number of iterations and has low message and computation overhead. By carefully selecting the cluster and transmission power levels, k-connectivity is achieved a.a.s. when node density allows it. Multiple vertex-disjoint routing paths are also available in this case. This is useful for security protocols, such as those using threshold cryptography to withstand node compromises. Simulation results show that REED can significantly increase the number of successful transmissions for both single-hop and multi-hop networks. Results also indicate that the energy cost for achieving significant reliability improvements using REED is extremely small.
Our approach can be applied to the design of sensor network protocols that require scalability, fault tolerance, prolonged network lifetime, security, and load balancing. We plan to study how to adapt REED to changing node density and duty cycles, and how it performs under different node distribution models.
Footnotes
1
Due to our probabilistic clustering approach, the number of cluster head announcements per iteration is small. Observe also that even if node u misses an announcement in one iteration, it is likely to receive one in a subsequent iteration(s).