
Abstract
When searching for information on the Internet, it can be stored in a bookmarking system. The ability to organize this information in such a system depends on one’s own prior knowledge to create an appropriate classification scheme. Providing a classification system for bookmarks might support people with low prior knowledge. Even though different bookmarking systems exist, hierarchical menus and tagging are being most widely used. In the current exploratory study with 95 ninth-grade students, a 2 × 2 between-subjects design was used to investigate the influence of providing classification support (or not) for either a tagging or a hierarchical system. Results showed that despite the low familiarity with tagging systems, using a hierarchical system is not necessarily a better approach than using a tagging system to organize previously found information. Rather, a tagging system seems to yield storage of fewer but higher-quality information sources. The most important conclusion is that, despite the low familiarity with tagging systems, using a hierarchical system was not beneficial over using a tagging system to organize previously found information.
Since the rise of the Internet in the eighties and nineties, it is hard to imagine the world without it. It is one of the primary information sources nowadays. Almost everybody uses the Internet to find information (Jansen & Spink, 2006); this is particularly true for adolescent students (Rouet, Ros, Goumi, Macedo-Rouet, & Dinet, 2011). Sometimes, just a simple search suffices to receive the information that is needed, for instance, when looking for a fact like the height of the Eiffel tower. Whereas when searching for information on controversial topics (e.g., the causes of obesity), where not one clear and simple answer exists, a more complex search process is needed to select useful and trustworthy information (e.g., Brand-Gruwel, Wopereis, & Walraven, 2009; Wildemuth, Freund, & Toms, 2014). Irrespective of the type of search task, students often find information they may want to use later (Jones, 2007). As a consequence, they want to re-access this information they found at a later time, and the question arises of how to keep interesting information sources for later use. It is assumed that good organization of found information supports understanding of the topic and knowledge building (Kalyuga, 2007; Kalyuga, Ayres, Chandler, & Sweller, 2003; Stadtler & Bromme, 2008), which is likely particularly the case for adolescent students (De Vries, Van der Meij, & Lazonder, 2008). The way information is organized can be different; that is, one can use a hierarchical structure to bookmark and store information, or one can use a tagging system. With a hierarchical structure, bookmarks are organized in folders and subfolders. This results in a tree-like structure. With a tagging system, users assign tags (labels) to a bookmark. This results in a flat structure where each tag is on the same ‘hierarchical’ level.
Furthermore, independent of the used system (hierarchical or tagging), students’ knowledge on the topic is important to build a useful system to find the stored information (e.g., Kirschner, Sweller, & Clark, 2006). For instance, having a broad knowledge scheme makes it easier to come up with relevant tags. The question is, thus, is it beneficial for students with less knowledge to provide them with a given classification?
In the current study, we investigated whether providing support for organizing information using a hierarchical or tagging system has an influence on students’ bookmark behaviour. Moreover, we investigate the effect of support given by a classification scheme in the different systems on students’ bookmark behaviour. Before we will elaborate on the need for such support, we will review the literature on how information on the Internet can be re-accessed, how bookmarks can function as a personal library and how information can be organized and classified.
Re-accessing information on the Internet
Especially when information is collected over time and/or not used immediately, it becomes important to know how to re-access it. Tauscher and Greenberg (1997) already showed that a majority of web page visits are revisits. This was corroborated by Teevan, Adar, Jones, and Potts (2007), who also showed that a large part of search queries were attempts to re-find information. As school assignments regularly span several weeks, this issue becomes a concern for students as well. In such situations students can rely on two strategies: search again when they need the information or save the information for later use. The strategy of searching again has the advantage that it is not necessary to think about how to store the found information. However, when trying to re-access previously found information through searching again, students are confronted with several obstacles. First, they may easily forget the earlier used search terms (Aula, Jhaveri, & Käki, 2005; Teevan, 2008). When using slightly different terms than in the original search to find a specific source again, this specific source might not show up in the search results again. Second, the specific source might not be available anymore (Capra & Pérez-Quinones, 2005). This could be due to a paywall or that the source is not online anymore. Third, search algorithms change over time (Marshall & Bly, 2005; Selberg & Etzioni, 2000). As a result, the source will show up in another place in the search results or even not show up at all. Fourth, the specific source has been changed and is therefore less recognizable (Adar, Teevan, Dumais, & Elsas, 2009). All those obstacles result in a decreased ability to re-access previously found information by searching again.
Another and more efficient strategy is to save the found information. Saving information is not subjected to changes in search algorithms, the recall of used search keywords, the availability of information (supposing a copy is made) or changes in the state in which the information was previously found (again, supposing a copy is made). Several previous studies (e.g., Alhenshiri, 2013; Aula et al., 2005) describe strategies people use for saving information for later use, such as saving documents as a file, printing, adding bookmarks to favourites, emailing the URL or writing down the URLs. Of these strategies, the bookmarking system is the only tool that is specifically designed for the task of storing and organizing information from the Internet. A bookmark is a record of the address of a website, file or other data made to enable quick access in the future (Bookmark, n.d.). The concept of bookmarks was first introduced in the Mosaic browser in 1993 (Andreesen, 1993) and quickly gained popularity among users (Abrams, Baecker, & Chignell, 1998; Pitkow & Kehoe, 1996). It is also the most used strategy for facilitating re-access (Bruce, Jones, & Dumais, 2004). However, over time, such a collection of bookmarks will grow bigger and bigger (Abrams et al., 1998).
Bookmarks as a personal library
The main reason for bookmarking is to make sure that found information can be accessed easily in the future (Abrams et al., 1998). However, Abrams et al. (1998) also indicate that to reap the benefits of such a bookmark collection, some sort of organizational structure for these bookmarks is necessary. However, people often do not structure their bookmark collection (Abrams et al., 1998; Stadtler & Bromme, 2008). Abrams et al. (1998) posed the question of how to organize collections of many hundreds or even thousands of bookmarks when the Internet was still in its infancy and thus much smaller than nowadays.
As the number of bookmarks grew over time, people started to organize their bookmarks to fight entropy and maintain accessibility (Abrams et al., 1998). You can structure bookmarks in folders, just like any other data on your computer. However, for several reasons, using folder bookmarks in the browser is inadequate (Heckner, Heilemann, & Wolff, 2009; Shen & Prior, 2013): (1) organizing bookmarks revolves mainly around the use of folders which can become difficult to manage when the number of folders and the levels in the folder hierarchy increases; (2) it is often difficult to name the folders, especially when people have too little knowledge about the subject of the search and thus have difficulties coming up with a classification scheme; and (3) limited contextual information is available as mostly only the bookmark and folder names are available. As Shen and Prior (2013) report, although most people bookmark web pages regularly, they often also have problems finding a recently visited web page. Thus, organizing these bookmarks is important to keep them accessible. However, according to Jones (2007), the act of storing a bookmark is difficult and error prone. The decision to bookmark a web page elicits several implicit questions, such as: Is the web page useful? Should it be kept? Where? In what form? Often, people develop a set of rules by which they organize their information (e.g., Wash & Rader, 2007; Whittaker & Sidner, 1996). Unfortunately, they often have difficulties maintaining a consistent organizing system over time (Golder & Huberman, 2006; Wash & Rader, 2007). Thus, strategies for organizing bookmarks are needed.
Two different ways of organizing bookmarks: hierarchical or tagging
When storing and organizing information sources on the Internet, one can essentially choose between two approaches of organizing information: a hierarchical or a tagging approach. In a hierarchical approach, one organizes bookmarks in a folder structure where folders can contain subfolders, which results in a tree-like structure. In the tagging approach, bookmarks are not divided across folders but are given labels. The tagging approach allows for assigning multiple tags to a bookmark and also one tag to different bookmarks. The bookmarking service Delicious™ introduced this approach to bookmarking in 2003 (Social bookmarking, 2015). Other examples of the tagging approach are Pinboard (bookmarking websites), YouTube (video), Flickr (photos), Connotea (science) or Last.fm (music).
Historically, the dominant approach of organizing information is hierarchical, because of the physical characteristics of information storage in offices and libraries (Wright, 2007). For example, although a book can be classified into several categories, a library can store this book in only one place (unless several copies are kept). Most studies take only a hierarchical approach into account (e.g., Chen & Dumais, 2000; De Vries et al., 2008; Stadtler & Bromme, 2008). However, several researchers claim that tagging systems can overcome several of the shortcomings of the traditional bookmarks in browsers (Golder & Huberman, 2006; Heckner et al., 2009; Wash & Rader, 2007). Although the tagging approach might be more laborious, in the digital era it has become a viable solution for organizing information sources, as one information object can now be assigned to several categories, thus alleviating classification problems. Moreover, by assigning multiple tags to a bookmark, it is easier to add contextual information.
Unfortunately, there has been little research into the differences between those two approaches and how individuals behave when organizing and storing information using either a hierarchical or a tagging approach. Civan, Jones, Klasnja, and Bruce (2008) compared two existing products (Hotmail, hierarchical, & Gmail, tagging) with 10 participants. All were students at undergraduate and graduate levels with an average age of 25. Each participant received two assignments: for one assignment participants stored the information in folders and for the other in tags. Civan et al. (2008) interviewed participants afterwards about their experiences. They found several differences. First, organizing with tags requires more physical effort because several tags were regularly assigned to an information source which requires more clicks for the users. Second, hierarchical organizing requires a higher cognitive effort because the participants found it difficult to decide in which folder a specific information source had to be stored. Third, most participants found that tags are a better and more flexible way for searching in the stored information. Not only was the greater flexibility appreciated, but the descriptive characteristics of tags were valued as well. According to the participants, tags give an indication about the content of the source. Besides that, participants also found it easier to jump between related concepts. A study by Voit, Andrews, and Slany (2012) involved both storing and re-finding information with either a hierarchical folder structure or a tagging system. In both conditions, the participants, seven students and 11 employees, had to create the hierarchical folder structure or the tags themselves. After a break, participants were asked to re-find a set of six test items. They concluded that there are no significant differences between hierarchical folder structures and tagging with regard to storing and re-finding behaviour. Research by Bergman, Gradovitch, Bar-Ilan, and Beyth-Marom (2013b) asking 168 science students about their preferences for either hierarchical folders or tags revealed several interesting findings. Although they see a favourable attitude towards the use of tagging for managing information, actual behaviour shows that hierarchical folders are preferred over tags. They indicate that familiarity with using hierarchical folders is the driver for this discrepancy. Also, perceived simplicity is a possible explanation for this preference. Pak, Pautz, and Iden (2007) compared the performance and subjective workload of 30 undergraduate students between using hierarchical folders and using tags. In the two experiments they carried out, they found mixed results. On the one hand, participants experienced more frustration when organizing with tags, while the results with regard to actual performance were mixed. On the other hand, a tagging system leads to better re-finding, requiring fewer clicks to get to the desired result. This might indicate that using tags is a viable alternative to the use of hierarchical folders for organizing information. Especially for large amounts of information, tags might unfold their potential with regard to easier accessibility (Walhout et al., 2015).
Prior knowledge and the need for support
Unfortunately, as shown by Stadtler and Bromme (2008), saving information for later re-access is accompanied by its own problems. Participants in their study (120 undergraduate students) did not organize the found information in a proper way, and nor did they structure the information according to straightforward principles, which makes retrieving previously found information problematic. A possible reason for this might be the lack of domain knowledge, which hinders the construction of such a classification scheme (Walhout, Oomen, Jarodzka, & Brand-Gruwel, 2017; White, Dumais, & Teevan, 2009). To overcome this lack of knowledge, especially for people with little to no prior knowledge of a topic, providing support can be beneficial (Kalyuga, 2007; Kalyuga et al., 2003). People with a low level of prior knowledge cannot rely on an existing knowledge structure because they have a low level of prior knowledge about the subject at hand. It is therefore difficult for them to come up with a classification scheme to classify the found information. Supporting them with a given classification scheme can function as a replacement for such an already existing knowledge structure. On the contrary, people with a higher level of prior knowledge might be hindered by such support as it can contradict with their existing knowledge structure.
People develop their own information classification scheme based on their needs and prior knowledge (Bergman, Gradovitch, Bar-Ilan, & Beyth-Marom, 2013a). This matches findings from cognitive science. When judging the relevancy of new information, this new information is connected to existing knowledge and organized into already existing schemata (Rogers & Swan, 2004). However, when there is no or not much existing knowledge, there are also no schemata (Kalyuga, 2007; Kalyuga et al., 2003). Hence, individuals with low or no prior knowledge of a topic might need support to develop a classification scheme. Research also suggests that providing any form of support might be beneficial for individuals with low prior knowledge; however, it might be counterproductive for individuals with high prior knowledge, as suggested by the expertise reversal effect (Kalyuga, 2007; Kalyuga et al., 2003). For individuals with low prior knowledge, support in the form of a given classification scheme might function as a replacement scheme for the knowledge structures that are used by individuals with high prior knowledge. On the other hand, individuals with higher levels of prior knowledge rely on their existing prior knowledge structure when solving complex cognitive problems like information problems. Providing them with a classification scheme might therefore lead to an increased cognitive burden because they have to match their own scheme with the provided one.
Thus, one may assume that supporting low prior knowledge participants with a classification scheme will result in better selection and organization of information and that they will be better able to connect new information with existing knowledge. This is indeed supported by the research of De Vries et al. (2008). In their study of search behaviour they gave fifth- and sixth-grade pupils a structured set of information sources. In their first experiment the sources were structured in only five broad categories, while in their second experiment the sources were structured with a detailed classification scheme. Compared to the first experiment, the number of correct answers increased considerably in the second experiment. Thus, supporting students with organizing information sources helped them to select relevant information.
A study by Stadtler and Bromme (2008), although not about bookmaking, gives another clue that providing support is beneficial for individuals with low prior knowledge. In their research, participants with little medical knowledge were asked to complete a search task about cholesterol. With the tool met.a.ware participants could store information. In this tool, a classification scheme about cholesterol was incorporated. Stadtler and Bromme found that the use of the supporting tool met.a.ware had a positive effect on the organization of notes and that the tool had a positive effect on knowledge acquisition about cholesterol. Moreover, the control groups showed hardly any type of structuring of their saved sources. These results suggest that providing support can help with organizing and possibly also with re-accessing a collection of information sources.
Thus, prior knowledge is an important variable to take into account when students are learning to organize information while searching the Internet for information, because the amount of prior knowledge can be beneficial for organizing and using a well-defined classification scheme.
The present study
The Internet enables us to access huge amounts of information. This is an incredible opportunity on the one hand, and consequently people increasingly make use of it (Jansen & Spink, 2006; Rouet et al., 2011). But on the other hand, access to this sheer amount of information comes with its own challenges. One crucial challenge is how to store and organize found information to re-use it later (Jones, 2007). Since its introduction in the early nineties, bookmarking has been widely used for this purpose (Abrams et al., 1998; Pitkow & Kehoe, 1996). Roughly spoken, there are two ways to organize information in bookmarks, either in a traditional hierarchical folder structure or in tags. There is very little research thus far showing which of those would be better. First studies indicate that although the attitude towards using tags is rather positive and they also seem to be efficient for re-finding information (Civan et al., 2008; Pak et al., 2007), hierarchical folders are used in practice due to their familiarity (Bergman et al., 2013b), although several findings were inconclusive (Pak et al., 2007; Voit et al., 2012). Another open issue surrounding bookmarks is — next to their concrete organizer style — whether one should start with a blank organizer or whether a certain frame of concepts should already be provided as support to start off with. We know from prior research that, in particular, individuals with low prior knowledge, like students often are, could profit from such a support (De Vries et al., 2008)
Thus, the central research question in this exploratory study was: how is bookmarking behaviour influenced by the support with a classification scheme and by different types of organizers (hierarchical and tagging), and what is the relation with prior knowledge?
Bookmarking behaviour was expressed by several measurements in this study, such as number of bookmarks (cf. Abrams et al., 1998; Boardman & Sasse, 2004; Wash & Rader, 2007), quality of the bookmarked pages and diversity of the used classifications (cf. Boardman & Sasse, 2004; Wash & Rader, 2007). So, support is given along two dimensions: type of classification support (no classification scheme versus a given classification scheme) and type of organizer (hierarchical versus tagging). In the study, a 2 × 2 factorial design is used and prior knowledge is taken into account to see whether it interacts with bookmarking behaviour.
Method
Participants
A total of 95 ninth-grade students (37 male, 58 female; M age 14.49 years, SD age = 0.6) in the highest level of secondary education in the south of the Netherlands took part in this study. Prior to the experiment, both the students and their parents received an explanation of the study (students during the lesson, parents via a letter of consent).
Material
Task
The task was constructed in cooperation with teachers to ensure that the task domain and workload were comparable to what is common in education and this group of students. To ensure enough interest in this topic, a pilot was conducted. Several groups of students were asked to indicate which subject from a list of five they would like to know more about. The subject of ‘obesity’ was named most frequently.
Hence, a task on the topic ‘obesity’ was constructed. It is a topic that students are vaguely familiar with, but it is no part of their regular curriculum. Participants were asked to find an answer to three questions: (1) what is obesity, (2) what are the causes of obesity and (3) what are the consequences of having obesity. From the Google-like search results page the participants had to locate and store the relevant web pages with a bookmarking tool. At the end the participants had to indicate which of the bookmarks were the three most important ones to answer the three posed questions.
To ensure both experimental control and ecological validity, a simulated task like the one used in this study should meet several requirements. The task needs to have content to which the participants can relate, it should provide enough imaginative context and it should allow for multidimensional and dynamic relevance judgements (Borlund, 2000, 2003). The multi-dimensionality stems from the fact that information is not only judged on its usefulness but also on dimensions such as quality, topicality or the origin of the information. Dynamic relevance refers to the changing importance of relevance criteria during the information solving problem process. This multi-dimensionality was reflected in the evaluation protocol used to determine the quality of the search results.
Search results pages
A Google-like search results page with 25 preselected search results was constructed. When constructing this list of websites, we ensured that a heterogeneous set of sources was included with regard to quality and relevance of the information in relation to the topic of obesity. To collect the websites, we conducted several searches with the Google search engine. Approximately 100 websites were considered. The final list of websites contained relevant as well as irrelevant pages with varying levels of quality of the information provided. The order of the search results was varied and five different search results pages were constructed. The search function and all links except the search results were disabled. Two independent raters scored each of the 25 web pages on a scale from 1 to 10 on several aspects: connection to the task, appearance quality of the web page, target audience, reliability of the organization or person behind the website, the use of references to other sources and whether (contact) information about the author was given. Based on the scores on each aspect, an aggregated score for each website was calculated. The quality scores of the websites ranged from 1.8 to 7.9 on a scale from 1 to 10. The website with the lowest score was a blog expressing a personal opinion about the disadvantages of being overweight. The website with the highest score was from the Dutch obesity association, which gives a lot of factual information about, for example, possible causes and treatments of obesity. The interrater reliability, expressed as Pearson’s correlation coefficient, showed a significant correlation (r = .89, p < .01). Close examination of the aggregated scores by the two raters revealed several differences in scores which were larger than 1.5. These web pages were re-evaluated by the two raters. The raters explained to each other how they scored these websites on the different criteria. After taking note of the explanations, the raters scored these websites again. After this re-evaluation, the interrater reliability increased slightly (r = .96, p < .01).
Bookmarking support
For this experiment a bookmarking tool was developed that enabled four different conditions: hierarchical structuring with no classification support, hierarchical structuring with classification support, tag cloud structuring with no classification support and tag cloud structuring with classification support. To bookmark a web page, the participants had to click on a button in the browser after which a pop-up appeared (see Figure 1(a) for the hierarchical structuring with classification support group and Figure 1(b) for the tag cloud structuring with classification support group) in which they could specify how to save the bookmark. The options in the pop-up depended on the conditions to which the participant was assigned. In the web application the participants could star their bookmarks, thus indicating the importance of the bookmark. To bookmark a webpage, participants clicked on a button in the browser (1a), after which a pop-up appeared (1b) in which they could specify how to save the bookmark.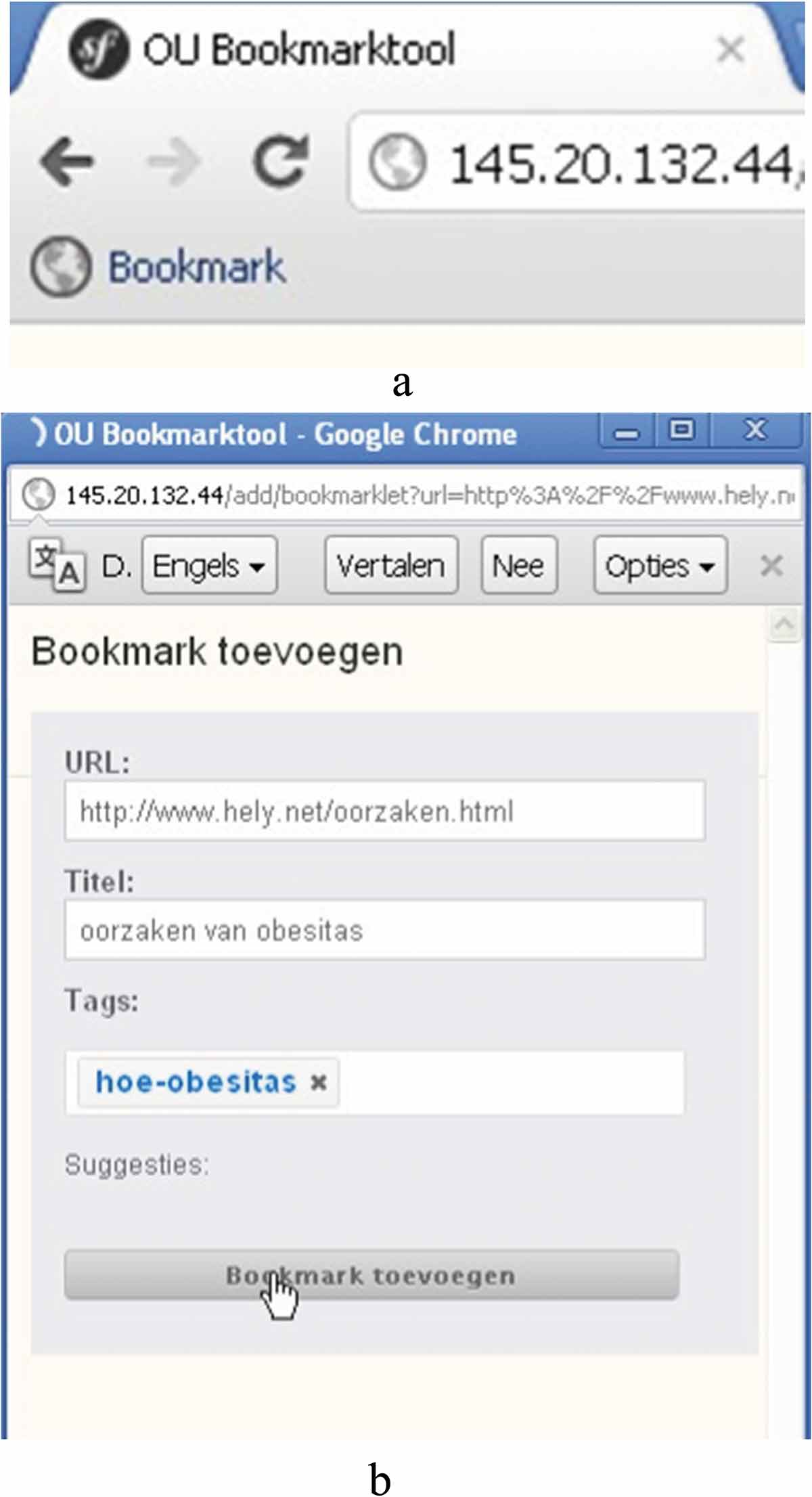
Note
These are screenshots from the original system provided in Dutch. In English, the upper and lower lines say ‘add bookmark’, the title says ‘reasons for obesity’, the folders (‘mappen’) and the tags include the following concepts: heredity, nutrition, environment, illness, social aspects, movement, etc. For both conditions this is the view when concepts are already in the bookmarking system. This is either the case for given bookmarks or when participants created bookmarks themselves. Otherwise, the part below ‘mappen’ or ‘tags’ was empty.
Software
BB Flashback from Blueberry software was used to capture the activity on the computers. Data processing and all data analysis was done with the R language for statistical computing (R Core Team, 2017).
Measurements
For each of the research questions quantitative as well as qualitative measurements were taken into account. Bookmarking behaviour (i.e., performance outcome) was operationalized by the number of bookmarked web pages, the quality of the bookmarked web pages, the diversity of the used classifications and a similarity score.
The number of bookmarked pages were counted. To determine the quality of the bookmarked web pages, the aggregated reliability scores were used. For each participant a quality score was calculated by taking the mean of the scores of the bookmarked web pages. Furthermore, the participants had to indicate a top 3 in their bookmarks, for which a separate quality score was calculated, thus resulting in a top 3 quality score.
The diversity of the used classifications was measured as the number of unique classifications used for storing all web pages during the task.
Another way of looking at the effect of classification support is measuring whether participants use classifications in the two no-classification support groups and to what extent this differs from the classifications the other two groups received. To measure whether no classification support would lead to the use of other classifications, a similarity score was calculated for each participant in the two no classification support groups. This similarity score expressed the resemblance of the used classification and the corresponding given classifications (i.e., the classifications of the users in the tagging, no support group were compared with the given classification for the tagging classification support group).
To measure prior knowledge of participants, they were asked to create a mind map of what they knew about the topic of obesity prior to the experiment. First, the number of nodes in the mind maps was calculated as the prior knowledge score. These nodes represent the number of concepts that a participant associates with the topic of ‘obesity’. Hence, someone creating few nodes has low prior knowledge, while someone creating many nodes (thus, knowing many concepts) has higher prior knowledge on this topic. Second, the words used by the participants in the mind maps were matched with the used classifications. Thus, the prior knowledge usage score expresses the number of words from the prior knowledge of the participants that were used as a classification. To determine this measure, we calculated a Levenshtein distance with a maximum allowed edit distance of two to determine a match between the words used to express the prior knowledge and the used classifications.
Design
To study the influence of support on bookmarking behaviour in solving information problems, a 2 × 2 factorial design with the factors type of organizer (hierarchical structure vs. tag cloud) and classification support (no support vs. given classification scheme) as between-subject factors was used. The dependent variables were bookmarking behaviour measurements (i.e., number of bookmarked web pages, the quality of the bookmarked web pages, the diversity of the used classifications and a similarity score). Participants were divided into four groups: hierarchical structuring with no classification support (n = 27), hierarchical structuring with classification support (n = 24), tag cloud structuring with no classification support (n = 19) and tag cloud structuring with classification support (n = 25). This study was set up as a quasi-experiment in which the participating students came from four school classes. Each class was randomly assigned to one condition. Prior knowledge of these four school classes on the task topic was significantly different (F(3, 88) = 4.31, p = .007, η2 = .13). Pairwise comparisons revealed that the tag cloud no classification support group had significantly less prior knowledge than the tag cloud classification support group.
Procedure
For each participant, the demographic data (age and sex) and prior knowledge were collected several weeks prior to the experiment. The experiment was conducted in group sessions, one session for each condition. Each session started with a detailed explanation of the procedure and a demonstration of how to use the bookmarking tool. Participants were given 30 minutes to complete the task, in which they had to collect at least three information sources from the 25 preselected search results. The sessions were recorded with BB Flashback. The total duration of the sessions was approximately 50 minutes (including instructions). After the instruction, the participants performed the search task. When they had completed the task, they could stop and save the screen recording. The exact wording of the task was as follows:
During the birthday party of your cousin Tim, your aunt tells you that the doctor worries about Tim’s weight. That sounds quite strange to you as Tim is quite healthy, although he does have an above-average weight. According to the doctor, Tim is overweight and risks becoming obese. A while ago you saw a TV programme about obesity, but that was about people who were clearly, visibly overweight. You decide you want to know about the issue and you need the answers to three questions:
What is obesity?
What are the causes of obesity?
What are the consequences of having obesity?
Look at the search results and save the web pages which you think are helpful in answering those three questions with the bookmarking tool as demonstrated.
You have 25 minutes to complete the search task. After that you will get an extra five minutes to select the three best sources from the ones you saved. You can do this by clicking the stars in front of the appropriate links in bookmark tool.
Results
Means and standard deviations of the bookmark data.
A two-way independent ANOVA with prior knowledge as a covariate revealed a significant effect for the interaction between type of organizer and classification support (F(1, 89) = 5.53, p = .02, partial η2 = .06) on the number of bookmarked web pages. Pairwise comparisons with Bonferroni adjustment showed that the participants in the hierarchical organizer classification support group bookmarked more web pages than the participants in the tag cloud organizer classification support group (p = .046). No significant differences were found for the main effects organizer (F(1, 89) = 1.49, p > .05) and classification support (F(1, 90) = 0.06, p > .05). The covariate, prior knowledge, was not significantly related to the number of bookmarked web pages (F(1, 89) = 1.01, p > .05).
There was no difference in the quality of all bookmarked web pages with prior knowledge as a covariate with regard to type of organizer (F(1, 89) = 0.25, p > .05), type of classification support (F(1, 89) = 0.17, p > .05) or an interaction between these two factors (F(1, 89) = 0.29, p > .05) when looking at all bookmarked web pages. The covariate, prior knowledge, was not significantly related to the quality of all bookmarked web pages (F(1, 89) = 1.09, p > .05). When looking at the top 3 quality score, with prior knowledge as a covariate, there was a significant difference with regard to the type of organizer (F(1, 89) = 4.63, p = .03, partial η2 = .05). The participants in the tag cloud groups selected web pages of higher quality than the participants in the hierarchical organizer groups. No significant differences were found for the main effect of classification support (F(1, 89) = 0.36, p > .05) and the interaction between type of organizer and classification support (F(1, 89) = 0.38, p > .05). The covariate, prior knowledge, was not significantly related to the top 3 quality score (F(1, 89) = 0.09, p > .05).
With regard to the diversity of the used classifications, the analysis was split into two parts: a separate analysis for each organizing system. This is based on the fact that inherent to the nature of the classification systems, the participants in the tag cloud condition could use more than one classifier for each bookmark. A two-way independent ANOVA with prior knowledge as a covariate showed no significant differences in the number of unique classifications between the groups getting classification support and the groups getting no support for both the tag cloud organizer (F(1, 40) = 0.27, p > .05) as well as the hierarchical organizer (F(1, 48) = 0.90, p > .05). The covariate, prior knowledge, was not significantly related to the diversity of the used classifications in the tag cloud organizer groups (F(1, 89) = 0.70, p > .05) or the hierarchical organizer groups (F(1, 48) = 0.01, p > .05).
The similarity of the self-made classifications in both no classification support groups with the respective given classifications was significantly higher for the participants in the tag cloud organizer no classification support group than for the participants in the hierarchical organizer no classification support group (F(1, 43) = 4.51, p = .04, partial η2 = .09). The covariate, prior knowledge, was not significantly related to the similarity of the self-made classifications (F(1, 43) = 0.19, p > .05).
The prior knowledge usage score was significantly higher for the participants who were given a classification scheme compared to the participants who had no support of a classification scheme (W= 746, p < .001, r = .343). A Kruskal-Wallis test revealed a significant difference for the interaction between type of organizer and type of classification support (H(3) = 14.257, p = .003). However, this difference was only significant for a comparison between the participants in the hierarchical organizer no classification support and the participants in the tag cloud organizer classification support group.
Discussion
The purpose of this study was to gain insight into the influence of classification support (no vs. given classification) and support with an organizing system (hierarchical vs. tag cloud) on bookmarking behaviour (i.e., performance outcome) and in what way this interacts with prior knowledge. Bookmarking behaviour was operationalized by the number of bookmarks, the quality of the bookmarks, the diversity of used classifications and the similarity of the used classifications.
The results with regard to bookmarking behaviour showed an interaction effect of the two types of support on the number of bookmarks saved. Specifically, when provided with a classification scheme, participants stored more bookmarks when using hierarchical folders than when using tag clouds. Albeit storing fewer bookmarks in the tagging condition (at least with the provided classification scheme), their quality was higher (for the top three websites) and it was more similar to the provided (optimal) scheme when they had to create their own classification scheme. This suggests that the lower amount of stored bookmarks within a tagging system might go together with a higher quality of the stored information. The reason might be that, as Civan et al. (2008) showed, it simply requires more clicks to bookmark a website in a tagging system. Hence, maybe our participants ‘thought twice’ before doing so, and only stored those websites that were really useful (i.e., of high quality).
In itself, prior knowledge was not related to any of the outcome measures in our study. However, students receiving support with a classification scheme used more classifications than they had already available in their prior knowledge. This corroborates the finding of earlier outcomes that providing support might be beneficial for individuals with low prior knowledge (Kalyuga, 2007; Kalyuga et al., 2003; Rader & Wash, 2008; Špiranec & Ivanjko, 2013; Stadtler & Bromme, 2008). Additionally, the fact that the prior knowledge usage score is low means that students used other words in their mindmap than were used in the classification scheme. This is the case for students in the conditions with as well as without a supporting classification scheme.
Unexpectedly, neither providing support with a classification scheme nor the bookmarking type had any effect on the quality of all bookmarked web pages or the diversity of the used classifications. Based on previous research, we expected to see differences in these measurements (Kalyuga, 2007; Kalyuga et al., 2003; Rogers & Swan, 2004; Špiranec & Ivanjko, 2013; Stadtler & Bromme, 2008). It might be that potential beneficial effects wash out on a larger scale when an infinite amount of websites may be stored and show mainly on a forced narrow selection (here: top three). Thus, a beneficial effect of support may be present for searches executed under time pressure when only few information sources must be quickly chosen, but not for searches without these limitations.
Furthermore, it can be concluded that the students did not have the ability to select the three websites with the highest quality, because the scores of the top three did not differ from the overall quality score. This is not a coincidence, as several studies (e.g., Brand-Gruwel, Kammerer, Meeuwen, & Gog, 2017; Walraven, Brand-Gruwel, & Boshuizen, 2008) have found that students have problems judging search results and websites on their validity and quality.
A further possible explanation for these findings could be the low familiarity of participants with using a tagging system to organize information. This gave the participants in the hierarchical conditions an advantage because they could use a system they were familiar with. Thus, potential beneficial effects of a tagging system might have been outweighed by the simple habituality with the hierarchical system. Although people indicate a preference for tagging when being asked about it explicitly, they fall back to what they already know and are used to in practice (Bergman et al., 2013b). Of the previous studies, only the study of Bergman et al. (2013a) used a short familiarization period for the tagging approach before participants were given a free choice of approach. This study also presented mixed results. Hence, it still remains an open research question, under which conditions using a hierarchical system or a tagging system would be beneficial.
In our study we did not use such a familiarization phase, which can be seen as a limitation to our study because one might argue that not using such a familiarization period leads to a disadvantage for the less known approach. Another limitation is that this study focused on the observed behaviour in the bookmarking process. However, this bookmarking process is part of a larger entirety: the search process. To improve the ecological validity in the future, it is important to embed the different conditions of this study in a more complete search process. Third, although we had a strong subjective impression that tagging was not well known to the participants, we did not explicitly measure participants’ knowledge of different bookmarking systems. Finally, the focus on the observed behaviour leaves the opportunity open to study the motivations behind the choice of tags. This can be done using a think aloud procedure or cued retrospective report (Brand-Gruwel et al., 2017).
Future research should investigate the differences between the hierarchical and the tagging approaches while taking the low familiarity of tagging into account. To do that, participants need to either be experienced with the tagging approach or have an extensive period to gain such experience. Lee, Goh, Razikin, and Chua (2009) already showed that high familiarity with the concept of tagging leads to better performance. Whether this also leads to better performance in comparison with more traditional folder-based systems needs to be investigated. Furthermore, different uses of tags might influence the outcome as well. Basile, Peroni, Tamburini, and Vitali (2015) make a rather general distinction between topical (describing the contents of the source) and non-topical (describing non-content aspects of the information) use of tags. Another, similar classification of the types of tags is the distinction between content tags, attitude tags or self-reference tags (Arolas & Ladrón-de-Guevar, 2012; Melenhorst & van Setten, 2007), in which the content tags are similar to the topical tags and the other two types are similar to the non-topical tags of Basile et al. (2015). In a study by Fastrez and Jacques (2015), tags were exclusively used to describe the contents of a source. This finding suggests that tags might be better suited to topical or content use.
Concluding remarks
The most important conclusion is that despite the low familiarity with tagging systems, using a hierarchical system (i.e., folders) was not beneficial over using a tagging system to organize previously found information. Our findings rather suggest that a tagging system forces people to elaborate more on which information to store, ultimately yielding a higher quality of stored information — at least for restricted searches.
Moreover, our finding that participants storing with tags and classification support created classifications more similar to their prior knowledge than participants storing with the hierarchical organizer and no classification support suggests that tags might support the use of prior knowledge when storing found information, thus enabling a better link to already existing knowledge structures, which ultimately leads to learning.
¿Con etiquetas o sin etiquetas? Cómo asistir en la organización y clasificación de los marcadores de páginas Web
Tras su aparición y expansión en los años 80 y 90, se hace difícil imaginar el mundo actual sin Internet. En nuestros días es una de las principales fuentes de información. Prácticamente todos recurrimos a Internet para buscar información (Jansen & Spink, 2006), especialmente los estudiantes adolescentes (Rouet, Ros, Goumi, Macedo-Rouet, & Dinet, 2011). En ocasiones, una simple búsqueda basta para obtener la información que necesitamos como, por ejemplo, conocer la altura de la Torre Eiffel. Sin embargo, la búsqueda de información sobre temas más complejos (e.g., las causas de la obesidad), en los que no existe una única respuesta, implica procesos de búsqueda más elaborados y necesarios para seleccionar información útil y fiable (e.g., Brand-Gruwel, Wopereis, & Walraven, 2009; Wildemuth, Freund, & Toms, 2014). Independientemente del tipo de tarea de búsqueda, los estudiantes suelen encontrar información que desean utilizar más adelante (Jones, 2007). Por tanto, necesitan volver a acceder a esa información y surge la pregunta de cómo guardar estas informaciones interesantes para su uso posterior. Se supone que una buena organización de la información facilita el conocimiento del tema y la construcción del conocimiento sobre el (Kalyuga, 2007; Kalyuga, Ayres, Chandler, & Sweller, 2003; Stadtler & Bromme, 2008), lo cual probablemente sea particularmente cierto en el caso de los estudiantes adolescentes (De Vries, Van der Meij, & Lazonder, 2008). El modo de organizar la información puede variar, es decir, se puede utilizar una estructura jerárquica para marcar y almacenar información, o se puede utilizar un sistema de etiquetas. En una estructura jerárquica, los marcadores se organizan en carpetas y subcarpetas que reflejan una estructura de árbol. Con un sistema de etiquetas, los usuarios asignan una serie de etiquetas a cada marcador, creando una estructura plana en la que todas las etiquetas están en un mismo nivel jerárquico.
No obstante, independientemente del sistema utilizado (jerárquico o de etiquetas), los conocimientos previos de los estudiantes sobre el tema son importantes para construir un sistema útil que les permita encontrar la información almacenada (e.g., Kirschner, Sweller, & Clark, 2006). Por ejemplo, disponer de un amplio conocimiento del tema facilita la aplicación de etiquetas relevantes. La cuestión es, ¿resulta ventajoso para los estudiantes con pocos conocimientos disponer de un sistema de clasificación determinado?
En el presente estudio investigamos si ofrecer ayuda a los estudiantes para organizar la información utilizando un sistema jerárquico o de etiquetas ejerce alguna influencia en su conducta de marcación de páginas. Además, investigamos los efectos que los distintos sistemas de clasificación facilitados ejercen en dichas conductas. Antes, desarrollamos nuestra argumentación sobre la necesidad de ofrecerles este tipo de ayuda y revisamos la literatura existente sobre cómo recuperar informaciones de Internet, cómo se pueden utilizar los marcadores a modo de biblioteca personalizada y cómo se puede organizar y clasificar la información.
Cómo recuperar información en Internet
Es importante sabre cómo podemos volver a acceder a ciertas informaciones, particularmente cuando estas se recaban durante un tiempo amplio y no se utilizan de inmediato. Tauscher and Greenberg (1997) ya demostraron que la mayoría de las visitas a páginas web no son primeros accesos. Lo confirmaron Teevan, Adar, Jones, y Potts (2007), que demostraron también que gran parte de las búsquedas eran intentos de recuperar informaciones obtenidas con anterioridad. Puesto que algunas tareas escolares suelen desarrollarse durante varias semanas, esta cuestión concierne también a los estudiantes. En estas situaciones, los estudiantes pueden desarrollar dos estrategias: buscar de nuevo la información que necesitan o guardar la información para un uso posterior. La primera estrategia tiene la ventaja de que no es necesario pensar cómo guardar la información. No obstante, cuando tratan de recuperar informaciones que habían encontrado previamente mediante nuevas búsquedas, tienen que superar varios obstáculos. En primer lugar, pueden olvidar con facilidad los términos utilizados en las búsquedas anteriores (Aula, Jhaveri, & Käki, 2005; Teevan, 2008). Si, para localizar una fuente específica de nuevo, utilizan términos ligeramente distintos de los utilizados en la búsqueda original, es posible que esa fuente no aparezca entre los resultados de la nueva búsqueda. En segundo lugar, dicha fuente puede no estar disponible (Capra & Pérez-Quinones, 2005), bien porque se trate de un servicio de pago o porque la página haya sido retirada. En tercer lugar, los algoritmos de búsqueda cambian con el tiempo (Marshall & Bly, 2005; Selberg & Etzioni, 2000). Por consiguiente, la fuente puede aparecer en otra posición en los resultados de la búsqueda o no aparecer entre ellos. En cuarto lugar, esa fuente particular podría haber cambiado y, por tanto, podría no ser reconocible (Adar, Teevan, Dumais, & Elsas, 2009). Todos estos obstáculos minan la capacidad de los estudiantes de recuperar informaciones obtenidas con anterioridad mediante nuevas búsquedas.
Otra estrategia más eficaz es guardar la información interesante cuando se encuentra. De este modo se evita el efecto de los cambios en los algoritmos de búsqueda o del olvido de los términos utilizados o de la disponibilidad de la información (si se guarda una copia de esta) o de los cambios en el estado en que se obtuvo (de nuevo, siempre que se guarde una copia). Diversos estudios previos (e.g., Alhenshiri, 2013; Aula et al., 2005) describen las estrategias que utilizamos para guardar informaciones que queremos utilizar en otro momento, entre ellas: guardar documentos en un archivo, imprimir, añadir un marcador en los favoritos, enviar el enlace en un email o escribir la dirección o URL. De todas ellas, el sistema de marcadores es la única herramienta diseñada especialmente para guardar y organizar información en Internet. Un marcador es un registro de la dirección de una página web, archivo u otra información que permite su acceso rápido en el futuro (Bookmark, s.f.). El concepto de marcador se introdujo por primera vez en el navegador Mosaic en 1993 (Andreesen, 1993) y rápidamente cobró gran popularidad entre los usuarios (Abrams, Baecker, & Chignell, 1998; Pitkow & Kehoe, 1996). También constituye la estrategia más utilizada para facilitar el acceso posterior a la información (Bruce, Jones, & Dumais, 2004). Sin embargo, con el tiempo, esta colección de marcadores se hará cada vez mayor (Abrams et al., 1998).
Los marcadores como biblioteca personal
El principal motivo para guardar marcadores es asegurarse de que se puede volver a acceder a cierta información con facilidad en el futuro (Abrams et al., 1998). No obstante, Abrams et al. (1998) apuntan que, para poder utilizar una colección de marcadores, es necesario conferir cierta estructura organizativa al conjunto. Sin embargo, las personas no suelen estructurar su lista de marcadores (Abrams et al., 1998; Stadtler & Bromme, 2008). Abrams et al. (1998) plantearon la cuestión de cómo organizar conjuntos de cientos o incluso miles de marcadores ya en los primeros tiempos de Internet, cuando todavía no se había convertido en lo que es hoy.
A medida que el número de marcadores crecía en el tiempo, los usuarios empezaron a organizarlos para combatir la entropía y mantener su accesibilidad (Abrams et al., 1998). Los marcadores se pueden estructurar en carpetas, como cualquier otra información en el ordenador. Sin embargo, por varias razones, el uso de carpetas de marcadores en el navegador es inadecuado (Heckner, Heilemann, & Wolff, 2009; Shen & Prior, 2013): (1) la organización de los marcadores implica principalmente el uso de carpetas, cuya gestión puede resultar difícil cuando el número de carpetas y los niveles jerárquicos de estas se incrementa, (2) suele resultar particularmente difícil nombrar las carpetas, especialmente cuando se tienen escasos conocimientos del tema objeto de búsqueda y, por tanto, no se sabe crear un sistema de clasificación, y (3) existe poca información contextual, puesto que en la mayoría de los casos solo se dispone del enlace y del nombre de la carpeta. Como indican Shen y Prior (2013), aunque la mayoría de los usuarios marcan páginas web con frecuencia, también suelen tener problemas para localizar una página que han visitado recientemente. Por tanto, es importante organizar los marcadores para que sean accesibles. Sin embargo, según Jones (2007), el acto de guardar un marcador presenta dificultades y es proclive a errores. La decisión de marcar una página web plantea diversas preguntas implícitas, tales como: ¿Es la página útil? ¿Debería guardarse? ¿Dónde? ¿En qué formato? Con frecuencia, las personas desarrollan una serie de normas para organizar su información (e.g., Wash & Rader, 2007; Whittaker & Sidner, 1996). Desafortunadamente, suelen tener dificultades para mantener un sistema constante de organización en el tiempo (Golder & Huberman, 2006; Wash & Rader, 2007). Por tanto, es necesario contar con estrategias para organizar los marcadores.
Dos maneras de organizar marcadores: estructura jerárquica o etiquetas
Para guardar y organizar fuentes de información en Internet, básicamente se puede elegir entre dos enfoques organizativos: un sistema jerárquico o un sistema de etiquetas. En un sistema jerárquico, los marcadores se organizan en una estructura de carpetas que pueden contener subcarpetas, de modo que se produce una estructura de árbol. En un sistema de etiquetas, los marcadores no se clasifican en carpetas, sino que se les adjudican etiquetas. Este enfoque permite asignar diversas etiquetas a un marcador y también una misma etiqueta a varios marcadores. El servicio de marcadores Delicious™ presentó este enfoque en 2003 (Marcadores sociales, 2015). Otros ejemplos de sistema de etiquetas son Pinboard (repositorios de marcadores), YouTube (vídeos), Flickr (fotos), Connotea (ciencias) o Last.fm (música).
Históricamente, el enfoque dominante para la organización de información es el jerárquico, debido a las características físicas de la organización de información en oficinas y bibliotecas (Wright, 2007). Por ejemplo, aunque un libro puede clasificarse bajo diversas categorías, en una biblioteca solo se puede almacenar ese libro en una única ubicación (a menos que se disponga de diversas copias). La mayoría de los estudios únicamente tienen en cuenta el enfoque jerárquico (e.g., Chen & Dumais, 2000; De Vries et al., 2008; Stadtler & Bromme, 2008). Sin embargo, diversos investigadores defienden que los sistemas de los sistemas de etiquetaje pueden superar algunas de las dificultades de los marcadores tradicionales que proporcionan los navegadores (Golder & Huberman, 2006; Heckner at al., 2009; Wash & Rader, 2007). Aunque el uso de etiquetas puede resultar más laborioso, en la era digital se ha convertido en una solución viable para organizar fuentes de información, puesto que a un objeto informativo se le pueden asignar diversas categorías, aliviando así los problemas de clasificación. Además, al asignar diversas etiquetas a un marcador, resulta más fácil añadir información contextual.
Desafortunadamente, se han investigado poco las diferencias entre estos dos enfoques y las conductas de las personas al guardar y organizar información con cualquiera de los dos sistemas. Civan, Jones, Klasnja, y Bruce (2008) compararon el uso de dos productos (Hotmail, un sistema jerárquico, y Gmail, de etiquetaje) con una muestra de 10 participantes. Todos ellos eran estudiantes de grado y posgrado con una media de edad de 25 años. Cada uno de los participantes recibió dos tareas: en una de ellas, tenían que guardar información en carpetas y en la otra, con etiquetas. Civan y sus colegas (2008) entrevistaron después a los participantes sobre sus experiencias. Observaron diversas diferencias. En primer lugar, la organización mediante etiquetas requería más esfuerzo físico porque, por lo general, se asignaban diversas etiquetas a cada fuente de información, lo que requiere varios clics por parte del usuario. En segundo lugar, la organización jerárquica requiere un esfuerzo cognitivo más elevado, puesto que los participantes tenían dificultades para decidir en qué carpeta tenían que guardar cada fuente de información. En tercer lugar, la mayoría de los participantes opinaban que las etiquetas eran un sistema mejor y más flexible para buscar la información guardada. No solo apreciaban su mayor flexibilidad, sino que valoraban en gran medida las características descriptivas de las etiquetas. Según los participantes, las etiquetas dan indicios sobre el contenido de la fuente. Además, los participantes también encontraban más fácil saltar entre conceptos relacionados. Voit, Andrews, y Slany (2012) llevaron a cabo un estudio en el que los participantes tenían que guardar y recuperar ciertas informaciones mediante un sistema jerárquico de carpetas o un sistema de etiquetas. En ambas condiciones, los siete estudiantes y 11 empleados que formaban la muestra, tenían que crear por sí mismos una estructura jerárquica de carpetas o las etiquetas para los marcadores. Después de un descanso, se les pedía que recuperasen seis fuentes de información. Los investigadores no observaron diferencias significativas entre ambos sistemas por lo que respecta a las conductas de almacenaje y recuperación de la información. Por otro lado, un estudio realizado por Bergman, Gradovitch, Bar-Ilan, y Beyth-Marom (2013b) en el que preguntaba a 168 estudiantes de ciencias sobre sus preferencias por uno u otro sistema, arrojó unos resultados interesantes. Aunque los investigadores observaron una actitud favorable hacia el uso de etiquetas para gestionar la información, la conducta real de los participantes demostró que estos preferían el uso de carpetas jerárquicas frente a las etiquetas. Lo explican aludiendo a la familiaridad de los participantes con el sistema de carpetas. Además, su simplicidad percibida podría ser otra posible explicación de esta preferencia. Pak, Pautz, y Iden (2007) compararon el rendimiento y la carga subjetiva de 30 estudiantes de grado en el uso de ambos sistemas. En los dos experimentos realizados se obtuvieron resultados contradictorios. Por un lado, los participantes sentían mayor frustración con el uso de etiquetas, mientras que los resultados relacionados con el rendimiento real eran dispares. Por otro lado, el sistema de etiquetas facilitaba la recuperación de la información, con menos clics necesarios para obtener los resultados deseados. Esto podría indicar que el uso de etiquetas es una alternativa viable al uso de carpetas jerárquicas para organizar la información. En particular, para grandes cantidades de información, las etiquetas podrían tener mayor potencial para un acceso más fácil a la información (Walhout et al., 2015).
Conocimientos previos y la necesidad de apoyo
Lamentablemente, como se muestra en Stadtler y Bromme (2008), el propio hecho de guardar información para su uso posterior conlleva una serie de problemas. Los participantes de este estudio (120 estudiantes universitarios de grado) no organizaron la información que obtenían de manera apropiada ni la estructuraron siguiendo unos principios claros, lo que dificultó su recuperación posterior. Una posible razón podría ser la falta de conocimientos sobre el tema, que dificulta la elaboración de un sistema apropiado de clasificación (Walhout, Oomen, Jarodzka, & Brand-Gruwel, 2017; White, Dumais, & Teevan, 2009). Para superar esta falta de conocimientos, especialmente para quienes no poseen o poseen muy pocos conocimientos sobre el tema, proporcionarles alguna ayuda podría ser ventajoso (Kalyuga, 2007; Kalyuga et al., 2003). Las personas con un nivel bajo de conocimientos previos no pueden depender de una estructura previa de conocimientos puesto que apenas poseen conocimientos sobre el tema. Por tanto, les resulta difícil crear un sistema de clasificación para organizar la información que encuentran. Si se les ofrece un sistema de clasificación dado, esta ayuda podría reemplazar la estructura de conocimientos de la que carecen. Por el contrario, las personas con un alto nivel de conocimientos previos podrían verse perjudicados por este apoyo puesto que podría entrar en conflicto con su estructura de conocimientos preexistentes.
Las personas desarrollan su propio sistema de clasificación de la información en función de sus necesidades y de sus conocimientos previos (Bergman, Gradovitch, Bar-Ilan, & Beyth-Marom, 2013a). Esta observación es coherente con los resultados de las ciencias cognitivas. Cuando se valora la relevancia de la información nueva, esta nueva información se vincula con los conocimientos existentes y se organiza en esquemas preexistentes (Rogers & Swan, 2004). Sin embargo, cuando no existen conocimientos previos o estos son muy escasos, tampoco existen esquemas organizativos (Kalyuga, 2007; Kalyuga et al., 2003). Por tanto, las personas con niveles bajos de conocimientos previos o sin ellos, podrían necesitar ayuda para desarrollar un sistema de clasificación. La investigación sugiere que ofrecer cualquier tipo de ayuda podría ser ventajoso para individuos con niveles bajos de conocimientos previos, pero podría resultar contraproducente para personas con niveles altos, como sugiere el efecto inverso del conocimiento (Kalyuga, 2007; Kaluya et al., 2003). Para las personas con pocos conocimientos previos, la ayuda en forma de un esquema clasificatorio dado podría reemplazar las estructuras que utilizan los individuos con alto nivel de conocimientos. Por otro lado, las personas con un nivel elevado de conocimiento dependen en gran medida de la estructura de sus conocimientos preexistentes para resolver problemas cognitivos como la organización de información. Ofrecerles un esquema de clasificación ya dado, podría crearles una carga cognitiva adicional puesto que tendrían que contrastar su propio esquema con el que se les propone.
Por lo tanto, podríamos asumir que ayudar a los participantes con bajo nivel de conocimientos ofreciéndoles un sistema de clasificación podría resultar en mejor selección y organización de la información y de ese modo, serían capaces de vincular mejor la nueva información obtenida con sus conocimientos previos. El trabajo de De Vries et al. (2008) corrobora esta propuesta. En su estudio sobre las conductas de búsqueda ofrecieron a estudiantes de 5° y 6° grado una serie de fuentes de información ya estructuradas. En un primer experimento, las fuentes estaban estructuradas en cinco categorías generales, mientras que en el segundo experimento, se estructuraron las fuentes siguiendo un detallado sistema de clasificación. En comparación con el primer experimento, el número de respuestas correctas del segundo experimento se incrementó considerablemente, por lo que se puede afirmar que el apoyo con la organización de la información ayudó a los estudiantes a seleccionar mejor información relevante.
Otro estudio de Stadtler y Bromme (2008), a pesar de no analizar el uso de marcadores, ofrece indicios de que disponer de ese apoyo es ventajoso para los estudiantes con escasos conocimientos previos. En esta investigación, participantes con bajo nivel de conocimientos médicos tenían que llevar a cabo una búsqueda sobre el colesterol. Los participantes podían almacenar información utilizando la herramienta met.a.ware. En esta herramienta se había incluido una propuesta de clasificación sobre el colesterol. Stadtler y Bromme observaron que el uso de esta herramienta ejercía un efecto positivo en la organización de las notas y en la adquisición de conocimientos sobre el colesterol. Además, los grupos de control apenas mostraron ningún tipo de estructura en las fuentes que almacenaron. Estos resultados sugieren que ofrecer este tipo de apoyo puede ser ventajoso para la organización y posiblemente para la recuperación de fuentes de información.
Así pues, el conocimiento previo es una variable importante que debe tenerse en cuenta cuando los estudiantes aprenden a organizar la información que obtienen en sus búsquedas en Internet, puesto que el nivel de conocimientos previos puede ser beneficial para organizar y utilizar un sistema bien definido de clasificación de la información.
El presente estudio
Internet nos permite acceder a una enorme cantidad de información. Esto, por un lado, es una oportunidad excelente y, por tanto, las personas hacen un uso cada vez mayor de estos recursos (Jansen & Spink, 2006; Rouet et al., 2011). Pero el acceso a una cantidad tan ingente de información plantea ciertos problemas. Uno de los retos que plantea es cómo guardar y organizar información relevante para utilizarla en otro momento (Jones, 2007). Desde su creación a principios de los 90, los marcadores (favoritos) se han utilizado ampliamente con este propósito (Abrams et al., 1998; Pitkow & Kehoe, 1996). En general, existen dos maneras de organizar los marcadores y la información que estos contienen: bien en un sistema jerárquico de carpetas o mediante etiquetas. Hasta la fecha, se ha investigado muy poco cuál de los dos sistemas es mejor. Los primeros estudios sugieren que, aunque las actitudes respecto al uso de etiquetas son bastante positivas y parece ser un método eficaz para recuperar información (Civan et al., 2008; Pak et al., 2007), el sistema jerárquico de carpetas es más utilizado en la práctica debido a su familiaridad (Bergman et al., 2013b), si bien no todos los resultados son conclusivos (Pak et al., 2007; Voit et al., 2012). Además del sistema adoptado para organizar marcadores, otra cuestión abierta sobre este tema es si se debería comenzar desde cero, con un marco de organización en blanco, o si se debería facilitar un marco conceptual como apoyo para iniciar el proceso de clasificación. Sabemos por investigaciones anteriores que, especialmente las personas con niveles bajos de conocimientos previos, como suele ser el caso de los estudiantes, podrían beneficiarse particularmente de este tipo de apoyo (De Vries et al., 2008).
De este modo, la pregunta central de investigación en este estudio exploratorio era la siguiente: ¿Cómo influye la provisión de un sistema de clasificación y el tipo de sistema de organización (jerárquico o etiquetas) en la conducta de marcado de páginas y cuál es su relación con los conocimientos previos?
Las conductas de marcado de páginas se expresó en este estudio mediante varias medidas como el número de marcadores (cfr. Abrams et al., 1998; Boardman & Sasse, 2004; Wash & Rader, 2007), la calidad de las páginas marcadas y la diversidad de las clasificaciones utilizadas (cfr. Boardman & Sasse, 2004; Wash & Rader, 2007). Por tanto, se ofrece apoyo en dos aspectos o dimensiones: la presencia de apoyo para la clasificación de marcadores (sin esquema de clasificación dado frente a un esquema de clasificación dado) y el tipo de organización de los marcadores (organización jerárquica frente a etiquetas). En este estudio se aplicó un diseño factorial 2 × 2 y se tuvieron en cuenta los conocimientos previos para analizar su correlación con la conducta de marcado y organización de la información.
Método
Participantes
En el estudio participaron un total de 95 estudiantes de Grado 9 (37 hombres, 58 mujeres; M edad 14.49 años, SD edad = 0.6) que cursaban el último año de secundaria en el sur de los Países Bajos. Antes del experimento, tanto los estudiantes como sus padres recibieron información sobre el estudio (los estudiantes durante una de sus clases y los padres a través de un documento de consentimiento).
Materiales
Tarea
La tarea se elaboró en colaboración con los profesores para garantizar que tanto el tema a tratar como la carga eran comparables con los habituales para este grupo de estudiantes. Para garantizar suficiente interés en el tema, llevamos a cabo un estudio piloto. Varios grupos de estudiantes tenían que indicar qué tema de una lista de cinco les gustaría conocer más a fondo. El que se mencionó más veces fue tema ‘obesidad’.
Por tanto, se elaboró una tarea sobre este tema, ‘la obesidad’. Se trata de un tema que a los estudiantes les resulta vagamente familiar, pero no forma parte de su currículum habitual. Se pidió a los participantes que respondiesen a tres preguntas: (1) ¿Qué es la obesidad? (2) ¿Cuáles son las causas de la obesidad? y (3) ¿Cuáles son las consecuencias de sufrir obesidad? A partir de los resultados ofrecidos por Google, los estudiantes tenían que localizar y guardar las páginas más relevantes utilizando una herramienta de marcadores. Al final, tenían que indicar los tres marcadores más importantes (top 3) y contestar a las tres preguntas mencionadas.
Para garantizar tanto el control experimental como la validez ecológica, una tarea simulada como la utilizada en esta investigación debería cumplir con diversos requisitos. La tarea debería tener un contenido con el que los participantes puedan identificarse, ofrecer suficiente contexto imaginativo y permitir juicios dinámicos y multidimensionales (Borlund, 2000, 2003). La multidimensionalidad surge de que la información no se juzga únicamente por su utilidad sino también por otras dimensiones como la calidad, la actualidad o el origen de la información. La relevancia dinámica hace referencia a la importancia cambiante de los criterios de relevancia durante el proceso de resolución de problemas informativos. Esta multidimensionalidad se vio reflejada en el protocolo de evaluación utilizado para determinar la calidad los resultados de la búsqueda.
Páginas de resultados de la búsqueda
Se elaboró una página de resultados similar a las de Google con 25 enlaces preseleccionados. Para la elaboración de esta lista de enlaces, nos aseguramos de incluir un conjunto heterogéneo de fuentes respecto a la calidad y relevancia de la información sobre la obesidad. Para recopilar estas páginas, realizamos diversas búsquedas utilizando el buscador de Google. Consideramos aproximadamente 100 páginas web. El listado final de enlaces contenía páginas relevantes y páginas irrelevantes con diversos niveles de calidad en cuanto a la información que ofrecían. El orden de presentación de los resultados se varió y elaboramos cinco páginas de resultados distintas. La función de búsqueda y todos los enlaces, excepto los de los resultados de búsqueda, se deshabilitaron. Dos evaluadores independientes evaluaron cada una de las 25 páginas sobre una escala de 1 a 10 en relación con los siguientes aspectos: conexión con la tarea, apariencia de calidad de la página, audiencia meta, fiabilidad de la organización o persona responsable de la página, uso de referencias a otras fuentes y disponibilidad de información o datos de contacto del autor. Con las puntuaciones de cada aspecto se calculó un valor agregado para cada página. Las puntuaciones sobre calidad oscilaban entre 1.8 y 7.9 sobre una escala de 1 a 10. La página con la puntuación más baja era un blog en el que se expresaba una opinión personal sobre las desventajas de tener sobrepeso. La página con la mayor puntuación era una página de la asociación holandesa contra la obesidad, que ofrecía una gran cantidad de información factual sobre, por ejemplo, posibles causas y tratamientos de la obesidad. La fiabilidad interevaluador, expresada mediante el coeficiente de Pearson, mostró una correlación significativa (r = .89, p < .01). Un análisis detallado de las puntuaciones agregadas por los dos evaluadores reveló diversas diferencias por encima de 1.5. Estas páginas fueron reevaluadas por los dos evaluadores, que se explicaron mutuamente sus puntuaciones de las páginas en función de los diversos criterios. Tras tomar nota de las explicaciones, los evaluadores puntuaron de nuevo las páginas. Después de esta reevaluación, la fiabilidad interevaluador mejoró ligeramente (r = .96, p < .01).
Ayuda para marcar y guardar las páginas
Para este experimento se desarrolló una herramienta de marcadores que facilitaba cuatro condiciones distintas: una estructura jerárquica sin ayuda para su clasificación, una estructura jerárquica con ayuda para su clasificación, una estructura de etiquetas en nube sin ayuda para su clasificación y una estructura de etiquetas en nube con ayuda para su clasificación. Para marcar una página web, los participantes tenían que pulsar un botón en el navegador, tras lo que aparecía una ventana emergente (véase Figura 1(a) con la estructura jerárquica con ayuda para su clasificación y Figura 1(b) con la estructura de etiquetas en nube con ayuda para su clasificación) en la que podían especificar cómo guardar el marcador. Las opciones en la ventana emergente dependían de la condición a la que se asignaba al participante. En la aplicación web, los participantes podían valorar los marcadores para indicar la importancia de cada uno. Para marcar una página, los participantes hacían clic en un botón del navegador (1a), tras lo que se abría una ventana (1b) en la que podían especificar cómo almacenar la página marcada.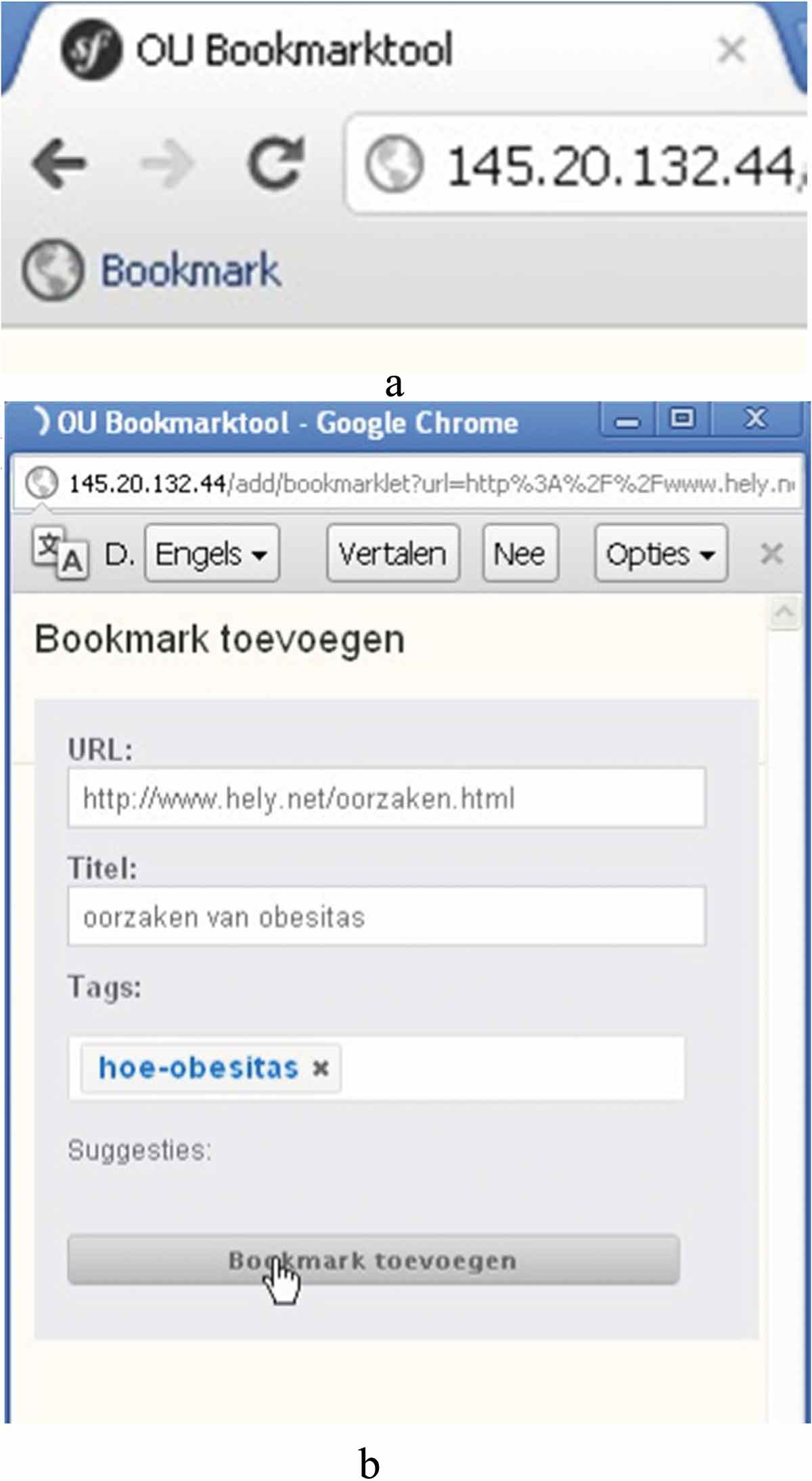
Nota
Estas son imágenes del sistema original en holandés. En español, la línea superior e inferior indican ‘añadir marcador’, el titulo indica ‘causas de la obesidad’, las carpetas (‘mappen’) y las etiquetas incluyen los siguientes conceptos: herencia, nutrición, entorno, enfermedad, aspectos sociales, movimiento, etc. En ambas condiciones, esta es la imagen cuando dichos conceptos aparecen en el sistema de marcadores, tanto para las clasificaciones propuestas como para las que los participantes han creado ellos mismos. De otro modo, la parte por debajo de ‘mappen’ o ‘tags’ aparece vacía.
Software
Se utilizó el programa BB Flashback de Blueberry para capturar la actividad de los ordenadores. Tanto el procesamiento de la información como el análisis de datos se realizaron utilizando el entorno estadístico R (R Core Team, 2017).
Medidas
Para cada una de las preguntas de investigación, se realizaron medidas cualitativas y cuantitativas. La conducta de marcación (es decir, el resultado de rendimiento) se operacionalizó mediante el número de páginas marcadas, la calidad de las páginas marcadas, la diversidad de las clasificaciones utilizadas y una puntuación de semejanza.
Se computó el número de páginas marcadas. Para determinar la calidad de las páginas marcadas, se recurrió a la media de las puntuaciones de fiabilidad. Para cada participante se calculó una puntuación de calidad tomando la media de las puntuaciones de las páginas marcadas. Además, los participantes tenían que indicar sus tres mejores marcadores (top 3), con los que se calculó una puntuación de calidad separada, la puntuación de calidad top 3.
La diversidad de las clasificaciones utilizadas se midió como el número de clasificaciones singulares utilizadas para el conjunto de los marcadores durante la tarea.
Otra manera de observar el efecto de la ayuda de clasificación es midiendo si los participantes utilizaban clasificaciones en las condiciones sin ayuda de clasificación y en qué medida estas clasificaciones diferían de las utilizadas por los otros dos grupos. Para medir si la ausencia de ayuda para la clasificación de los marcadores llevaría al uso de otras clasificaciones, se calculó una puntuación de semejanza para cada participante en los grupos sin ayuda para la clasificación. Esta puntuación de semejanza expresaba la proximidad de las clasificaciones utilizadas y las correspondientes clasificaciones ofrecidas (es decir, las clasificaciones de los participantes en el grupo de etiquetas sin ayuda de clasificación se compararon con la clasificación propuesta para el grupo de etiquetaje con ayuda para su clasificación).
Para medir los conocimientos previos de los participantes, se les pidió que creasen un mapa conceptual de sus conocimientos sobre la obesidad con anterioridad al experimento. Primero, el número de nodos en dichos mapas se adoptó como puntuación de los conocimientos previos. Estos nodos representan el número de conceptos que el participante asocia con el tema ‘obesidad’. Por tanto, los participantes que crearon muy pocos nodos, tendrían pocos conocimientos previos, mientas que aquellos que crearon muchos nodos (es decir, conocían muchos conceptos) poseían un nivel más alto de conocimientos sobre el tema. En segundo lugar, las palabras utilizadas por los participantes en los mapas conceptuales se compararon con las clasificaciones utilizadas. Por tanto, la puntuación del uso de conocimientos previos expresaba el número de palabras de los conocimientos previos de los participantes que se utilizaron en la clasificación. Para determinar esta medida, calculamos la distancia de Levenshtein con una distancia de edición máxima de dos para determinar la coincidencia entre las palabras utilizadas para expresar los conocimientos previos y las clasificaciones utilizadas.
Diseño
Para estudiar la influencia del apoyo al uso de marcadores en la resolución de problemas de información, se aplicó un diseño factorial 2 × 2 con los factores tipo de organización (estructura jerárquica vs. etiquetas en la nube) yapoyo de clasificación (sin apoyo vs. sistema de clasificación propuesto) como factores intersujeto. Las variables dependientes eran las medidas de la conducta de uso de marcadores (es decir, el número de páginas marcadas, la calidad de las páginas marcadas, la diversidad de las clasificaciones utilizadas y la puntuación de semejanza). Los participantes se dividieron en cuatro grupos: estructura jerárquica sin apoyo de clasificación (n= 27), estructura jerárquica con apoyo de clasificación (n= 24), estructura de etiquetas en nube sin apoyo de clasificación (n= 19) y estructura de etiquetas en nube con apoyo de clasificación (n= 25). Este estudio se planteó como un cuasiexperimento cuyos participantes pertenecían a cuatro clases de escolares. Cada clase se asignó de manera aleatoria a una de las cuatro condiciones. Los conocimientos previos sobre el tema de las cuatro clases diferían significativamente (F(3, 88) = 4.31, p = .007, η2 = .13). Las comparaciones directas revelaron que el grupo de etiquetas en nube sin apoyo de clasificación tenía un nivel de conocimientos previos significativamente menor que el grupo de etiquetas en nube con apoyo de clasificación.
Procedimiento
Varias semanas antes de comenzar el experimento se recabaron los datos demográficos de cada participante (edad y sexo) así como sus conocimientos previos. El experimento se llevó a cabo en sesiones de grupo, una por cada condición. Cada sesión se abrió con una explicación detallada del procedimiento y una demostración sobre el uso de la herramienta de marcación. Los participantes disponían de 30 minutos para completar la tarea, en la que tenían que seleccionar y guardar al menos tres fuentes de información de las 25 preseleccionadas en la página de resultados. Las sesiones se grabaron utilizando el sistema BB Flashback. La duración total de las sesiones era de aproximadamente 50 minutos (instrucciones incluidas). Después de las instrucciones, los participantes realizaron las correspondientes tareas de búsqueda. Después de completar la tarea, podían guardar el registro en pantalla. La redacción exacta de la tarea era la siguiente:
Durante la fiesta de cumpleaños de tu primo Tim, tu tía te explica que el doctor está preocupado por su peso. Esto te suena algo extraño, porque Tim parece gozar de buena salud, aunque su peso está por encima de la media. Según el doctor, Tim sufre sobrepeso y corre el riesgo de convertirse en obeso. Algún tiempo atrás viste un programa de TV sobre la obesidad, pero las personas que salían en el tenían un sobrepeso muy evidente. Decides que quieres conocer más sobre el tema y necesitas respuesta a estas tres preguntas:
¿Qué es la obesidad?
¿Cuáles son las causas de la obesidad?
¿Cuáles son las consecuencias de la obesidad?
Observa los resultados de la búsqueda y guarda las páginas que creas que son más útiles para responder a estas tres preguntas utilizando la herramienta como has visto en la demostración. Dispones de 25 minutos para completar la tarea. Después, tendrás cinco minutos más para seleccionar las tres mejores fuentes entre las que hayas guardado. Puedes calificar las páginas utilizando las estrellas que aparecen frente a los enlaces en la herramienta de marcación.
Resultados
Medias y desviaciones típicas de los datos sobre el uso de marcadores.
Un ANOVA bidireccional independiente con el nivel de conocimientos previos como covariable reveló un efecto significativo de la interacción entre el tipo de organización de los marcadores y el apoyo a la clasificación (F(1, 89) = 5.53, p = .02, parcial η2 = .06) sobre el número de páginas marcadas. Las comparaciones directas con ajuste de Bonferroni revelaron que los participantes en el grupo de clasificación jerárquica con apoyo para la clasificación marcaron más páginas que los del grupo de etiquetas en nube con apoyo para la clasificación (p = .046). No se observaron diferencias significativas para los principales efectos del tipo de organización (F(1, 89) = 1.49, p > .05) y apoyo a la clasificación (F(1, 90) = 0.06, p > .05). La covariable, el nivel de conocimientos previos, no se relacionaba significativamente con el número de páginas marcadas (F(1, 89) = 1.01, p > .05).
No se observó ninguna diferencia en la calidad de las páginas marcadas con el nivel de conocimientos previos como covariable por lo que respecta al tipo de organización (F(1, 89) = 0.25, p > .05), al tipo de ayuda para la clasificación (F(1, 89) = 0.17, p > .05) o a la interacción entre estos dos factores (F(1, 89) = 0.29, p > .05) tras analizar todas las páginas marcadas. La covariable, nivel de conocimientos previos, no guardaba una relación significativa con la calidad de las páginas marcadas (F(1, 89) = 1.09, p > .05). Tras analizar la puntuación de calidad top 3, con el nivel de conocimientos previos como covariable, se observó una diferencia significativa respecto al tipo de organización (F(1, 89) = 4.63, p = .03, parcial η2 = .05). Los participantes en los grupos de etiquetas en nube seleccionaron páginas de mayor calidad que los participantes en los grupos del sistema jerárquico. No se observaron diferencias significativas para el efecto principal de ayuda a la clasificación (F(1, 89) = 0.36, p > .05) y de la interacción entre el tipo de organización y la ayuda a la clasificación (F(1, 89) = 0.38, p > .05). La covariable, el nivel de conocimientos previos, no estaba relacionada significativamente con la puntuación de calidad top 3 (F(1, 89) = 0.09, p > .05).
Por lo que respecta a la diversidad de las clasificaciones utilizadas, el análisis se dividió en dos partes, un análisis independiente para cada sistema de organización. Esta decisión se basaba en que, por la naturaleza de los distintos sistemas de clasificación, los participantes en la condición de etiquetas en nube podían utilizar más de una etiqueta para cada página marcada. Un ANOVA bidireccional con el nivel de conocimientos previos como covariable no arrojó diferencias significativas en el número de clasificaciones únicas entre los grupos con ayuda para la clasificación o sin ella, tanto para el sistema de etiquetas en nube (F(1, 40) = 0.27, p > .05) como para el sistema de organización jerárquica (F(1, 48) = 0.90, p > .05). La covariable, el nivel de conocimientos previos, no guardaba una relación significativa con la diversidad de las clasificaciones utilizadas en los grupos con el sistema de etiquetas (F(1, 89) = 0.70, p > .05) ni en los del sistema jerárquico (F(1, 48) = 0.01, p > .05).
La semejanza de las clasificaciones propias con las clasificaciones propuestas en ambos grupos sin apoyo a la clasificación era significativamente mayor para los participantes en el grupo de etiquetas sin apoyo que el del sistema jerárquico sin apoyo (F(1, 43) = 4.51, p = .04, parcial η2 = .09). La covariable, el nivel de conocimientos previos, no estaba relacionada significativamente con la semejanza de las clasificaciones propias (F(1, 43) = 0.19, p > .05).
La puntuación de uso de los conocimientos previos era significativamente mayor para los participantes a quienes se les propuso un sistema de clasificación que para los que no contaron con ningún tipo de apoyo a la clasificación (W= 746, p < .001, r = .343). Una prueba de Kruskal-Wallis reveló una diferencia significativa en la interacción entre el tipo de organización y el tipo de apoyo a la clasificación (H(3) = 14.257, p = .003). No obstante, esta diferencia solo era significativa para la comparación entre los participantes en el grupo de sistema jerárquico sin apoyo para la clasificación y los del sistema de etiquetas en nube con apoyo para la clasificación.
Discusión
El objetivo de este estudio era mejorar nuestro conocimiento de la influencia del apoyo para la clasificación de los marcadores (sin apoyo vs. clasificación propuesta) y el apoyo con un tipo de sistema propuesto para organizar los marcadores (jerárquico vs etiquetas en nube) en la conducta de uso de marcadores (resultado de ejecución) y su interacción con el nivel de conocimientos previos. La conducta de uso de marcadores se operacionalizó mediante el número de páginas marcadas, la calidad de estas y la diversidad de las clasificaciones utilizadas, así como la semejanza entre estas y la clasificación propuesta. La conducta de marcaje de páginas se operacionalizó mediante el número de marcadores, la calidad de las páginas marcadas, la diversidad de las clasificaciones utilizadas y su semejanza con las clasificaciones propuestas.
Los resultados relacionados con la conducta de marcación revelaron un efecto de interacción de los dos tipos de apoyo en el número de marcadores guardados. En particular, cuando se propone un esquema de clasificación, los participantes que utilizaron carpetas jerárquicas guardaron más marcadores que los que utilizaron etiquetas en nube. Aunque el grupo de etiquetas en nube (por lo menos el que disponía de un sistema de clasificación), la calidad de las páginas guardadas era mayor (en las páginas ‘top 3’) y las etiquetas utilizadas eran más similares a las propuestas en el sistema de clasificación (óptimo) cuando tenían que crear su propio sistema. Esto sugiere que guardar un número reducido de marcadores en un sistema de etiquetas podría estar relacionado con una mejor calidad de la información guardada. La razón podría ser sencillamente, como Civan y sus colegas (2008) mostraron, que el sistema de etiquetas requiere que el usuario haga más clics. Por tanto, es posible que nuestros participantes tuvieron que ‘pensar dos veces’ antes de usar las etiquetas y solo guardaron los enlaces a las páginas que realmente resultaban útiles (es decir, las de mayor calidad).
Por sí mismo, el nivel de conocimientos no estaba relacionado con ninguna de las medidas de resultados en nuestro estudio. Sin embargo, los estudiantes que disponían de un sistema de clasificación propuesto utilizaron más clasificaciones provenientes de sus conocimientos previos. Esto corrobora los resultados de otros estudios previos en los que se observa que disponer de este tipo de apoyo puede ser beneficial para los estudiantes con menor nivel de conocimientos (Kalyuga, 2007; Kalyuga et al., 2003; Rader & Wash, 2008; Špiranec & Ivanjko, 2013; Stadtler & Bromme, 2008). Además, el hecho de que los valores de uso de los conocimientos previos sea bajo significa que los estudiantes utilizaron otros términos en sus mapas conceptuales que después utilizaron también en sus sistemas de clasificación. Este es también el caso tanto en la condición de apoyo de clasificación como sin él.
Contra lo esperado, ni la disponibilidad de un sistema de clasificación propuesto ni el tipo de marcadores utilizados ejercían ningún tipo de efecto en la calidad de las páginas marcadas o en la diversidad de las clasificaciones utilizadas. Basándonos en investigaciones previas, esperábamos observar diferencias en estas medidas (Kalyuga, 2007; Kalyuga et al., 2003; Rogers & Swan, 2004; Špiranec & Ivanjko, 2013; Stadtler & Bromme, 2008). Es posible que los posibles efectos beneficiales se diluyan a una escala mayor cuando se pueden guardar un número infinito de enlaces y estos efectos se observen principalmente en una selección forzada de estos (aquí, los top 3). Por tanto, el efecto beneficial del apoyo podría observarse en un contexto de búsquedas bajo presión cuando solo se puede seleccionar una cantidad limitada de informaciones en un periodo de tiempo limitado, pero no para búsquedas sin estas limitaciones.
Asimismo, podríamos concluir que los estudiantes no tenían habilidad suficiente para seleccionar las tres páginas de mayor calidad, porque las puntuaciones de las top 3 no diferían significativamente de la puntuación global de calidad. Este resultado no coincide con los de otros estudios (e.g., Brand-Gruwel, Kammerer, Meeuwen, & Gog, 2017; Walraven, Brand-Gruwel, & Boshuizen, 2008) en los que se observa que los estudiantes tienen dificultades para juzgar los resultados de las búsquedas y las páginas en relación con su validez y calidad.
Otra explicación posible de estos resultados podría ser la falta de familiarización de los participantes con el uso de las etiquetas para organizar la información. Esta falta de familiarización podría haber dado ventaja a los grupos del sistema jerárquico porque podían utilizar un sistema con el que estaban familiarizados. Por tanto, los posibles efectos positivos del sistema de etiquetas podrían verse contrarrestados por la familiaridad con el sistema jerárquico. Aunque, cuando se les pregunta sobre ello explícitamente, las personas expresan preferencia por las etiquetas, suelen revertir a lo que conocen y están habituados en la práctica (Bergman et al., 2013b). De los diversos estudios previos, solo el de Bergman et al. (2013a) hace uso de un breve periodo de familiarización para el sistema de etiquetas antes de brindar a los participantes la oportunidad de elegir libremente. También este estudio obtuvo resultados dispares. Por tanto, sigue siendo un tema de investigación abierto identificar qué condiciones son más ventajosas para el uso de un sistema jerárquico o de etiquetas.
En nuestro estudio no recurrimos a un periodo de familiarización, lo cual podría considerarse una limitación puesto que podría considerarse que la ausencia de este periodo de familiarización produce desventajas para el sistema menos conocido. Otra limitación del estudio se centra en el comportamiento es que se centra en las conductas observadas durante el uso de marcadores. No obstante, este proceso es parte de un todo más amplio: el proceso de búsqueda. Para mejorar la validez ecológica en el futuro, es importante integrar las distintas condiciones de este estudio en un proceso más amplio de búsqueda de información. En tercer lugar, aunque teníamos una impresión subjetiva muy fuerte de que el sistema de etiquetas no era muy conocido por los participantes, no medimos explícitamente sus conocimientos sobre los distintos sistemas de marcado de páginas. Por último, el enfoque en las conductas observadas brinda la oportunidad de estudiar las motivaciones tras la selección de etiquetas. Esto puede hacerse mediante un procedimiento de ‘pensar en voz alta’ o un informe retrospectivo asistido (Brand-Gruwel et al., 2017).
Futuras investigaciones deberían estudiar las diferencias entre el sistema jerárquico y el uso de etiquetas teniendo en cuenta la falta de familiarización con este último. Para ello, los participantes deberían tener experiencia con el uso de etiquetas o bien disponer de un amplio periodo de prácticas para adquirir la experiencia necesaria. Lee, Goh, Razikin y Chua (2009) demostraron que un alto nivel de familiarización de los participantes con el uso de etiquetas produce mejores rendimientos. Queda por demostrar si también producen mejor rendimiento en comparación con sistemas más tradicionales basados en carpetas. Además, el uso de distintas etiquetas también influye en los resultados. Basile, Peroni, Tamburini, y Vitali (2015) distinguen de un modo general entre un uso tópico (describir los contenidos de las fuentes) y no tópico (describir aspectos de las fuentes distintos del contenido) de las etiquetas. Otra calificación similar del tipo de etiquetas es la distinción entre etiquetas de contenido, de actitud o de autorreferencia (Arolas & Ladrón-de-Guevar, 2012; Melenhorst & van Setten, 2007). Las etiquetas de contenido son similares a las tópicas y los otros dos tipos se asemejan a las etiquetas no tópicas de Basile et al. (2015). En un estudio de Fastrez y Jacques (2015), las etiquetas se utilizaban exclusivamente para describir el contenido de las fuentes. Este resultado sugiere que las etiquetas podrían ser más apropiadas para un uso tópico (relacionado con el contenido).
Consideraciones finales
La conclusión más importante, a pesar de la falta de familiaridad con los sistemas de etiquetas, es que el uso de un sistema jerárquico (como el de carpetas) no es necesariamente ventajoso sobre el de etiquetas para organizar la información obtenida con anterioridad. Nuestros resultados sugieren más bien que el sistema de etiquetas fuerza al usuario a procesar mejor qué información guardar y resulta, en definitiva, en la selección de una información de mayor calidad, por lo menos en las búsquedas restringidas.
Asimismo, nuestros resultados revelan que los participantes que utilizaban las etiquetas con ayuda para la clasificación de los marcadores creaban clasificaciones más similares a sus conocimientos previos que los que utilizaban un sistema jerárquico y no disponían de ninguna ayuda para su clasificación, lo que sugiere el uso de los conocimientos previos para la selección y almacenado de la información. De este modo se facilita el vínculo con la estructura de los conocimientos existentes sobre el tema que, a su vez, fomenta el aprendizaje.