
Abstract
Are there any boundaries that separate mental disorders from normal conditions? Current diagnostic systems in psychiatry, such as the DSM and ICD, have based a categorical classification system that divides mental disorders into types based on criterion sets with defining features, regardless of whether there are any boundaries between normal and abnormal conditions [1, 2]. Although it is pragmatically useful to draw a line somewhere and make a categorical diagnosis, many researchers have argued that the dimensional classification in the diagnostic systems is a viable alternative [3]. The debate of whether mental disorders are categorical or dimensional (i.e. the continuity controversy) is a research agenda for the ongoing revision of the DSM [4, 5].
Flett et al. described four approaches that have been applied to the investigation of the continuity controversy with regard to depression, namely, the phenomenological, typological, aetiological, and psychometric approaches, and concluded that most of the existing research supports the dimensional model of depression [6]. This conclusion, however, was limited by serious methodological and statistical shortcomings. Recognizing the limitation of existing evidence, Flett et al. called for studies utilizing sophisticated statistical techniques [6], called taxometric procedures, that examine the latent structure of a given construct such as depression [7–9]. In response to this suggestion, a number of investigators have performed taxometric investigations of various mental disorders [10, 11].
Summary of previous taxometric investigations of depression
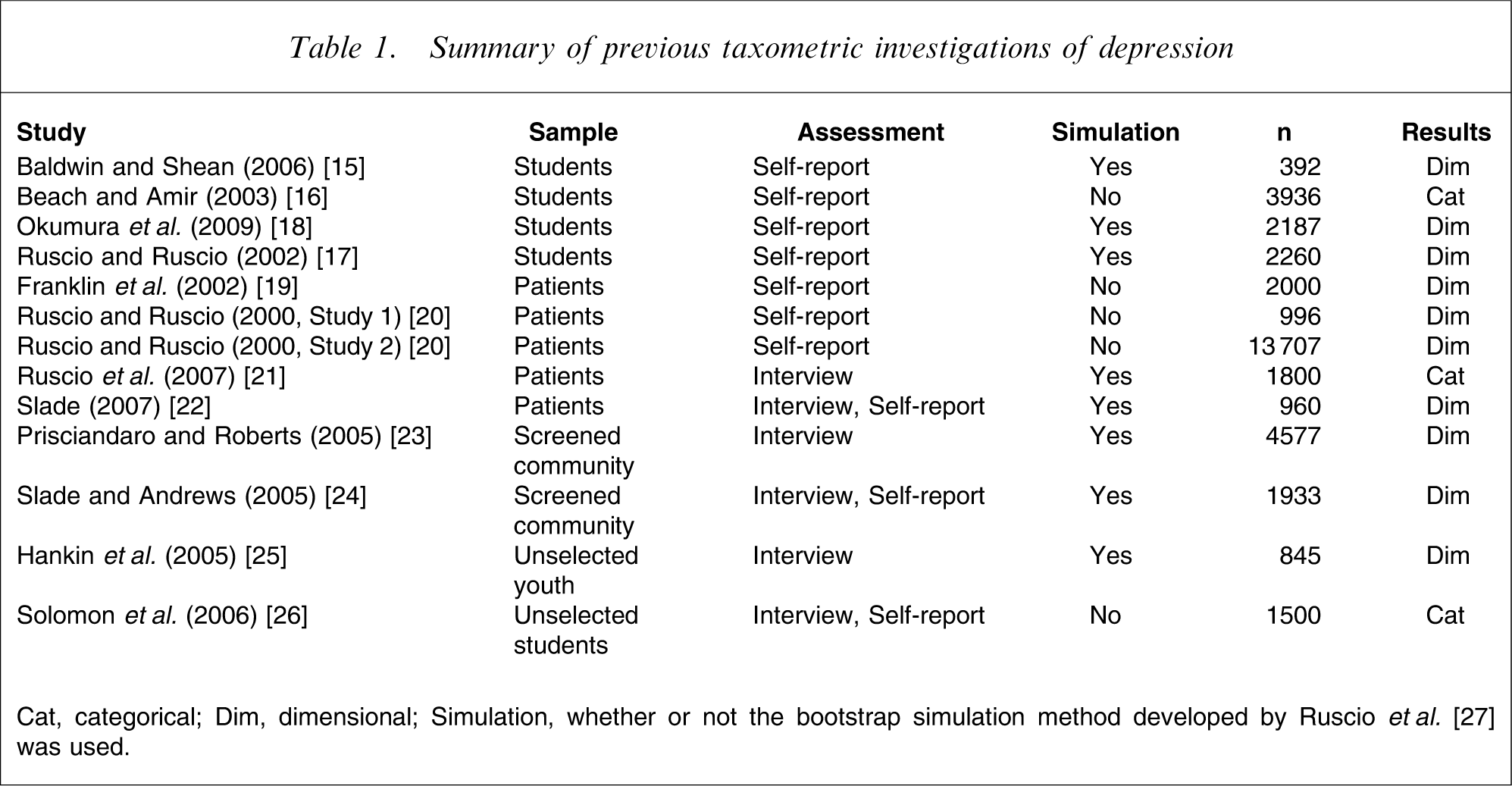
Cat, categorical; Dim, dimensional; Simulation, whether or not the bootstrap simulation method developed by Ruscio et al. [27] was used.
As shown in Table 1, most of the previous studies have relied on samples from selected populations, which may cause methodological problems. These sampling procedures lead to an artificial truncation of the depressive symptom severity that can distort results by violating the assumption of conditional independence needed to obtain unbiased estimates [28], and such selection bias can complicate formal inferences about the latent structure [29]. In studies using students, a focus only on students attending classes introduces systematic sampling bias. That is, the data collected in classes are limited to high-functioning (i.e. low in depression) students, because low-functioning (i.e. high in depression) students may be absent [25]. Moreover, focusing only on clinical patients or screened community samples introduces institutional bias, because high-functioning individuals may not be included in these studies [23]. Therefore it is important to use unselected samples with a full range of depression severity.
As far as we know, there are two studies using unselected samples [25, 26]. Hankin et al. used taxometric procedures on an unselected youth sample aged 9–17 years old, and found evidence that the latent structure of depression was dimensional [25]. Still, Solomon et al. noted that the limitation of their study was the assessment of depressive symptoms, which involved reference to the presence of depression at any time in the preceding year [26]. Still, Solomon et al. noted that the limitation of the Hankin et al. study was the assessment of depressive symptoms, which involved reference to the presence of depression at any time in the preceeding year [26]. Previous findings using unselected samples, however, focus only on the structure of depression among a relatively young population. It will therefore be important for taxometric studies of depression to sample unselected community populations to aid generalizability of the previous findings. The present study attempted to solve this problem by conducting a secondary analysis of the Japanese national survey of physical and mental well-being [30]. The main research question investigated in this paper is whether depression assessed using the Japanese version [31] of the Center for Epidemiologic Studies Depression scale (CES-D) [32] is categorical or dimensional.
Method
Data source
Participants were community volunteers who were selected as part of the Japanese national survey of physical and mental well-being [30]. The survey was conducted in June 2000 by the Japanese Ministry of Health and Welfare (the present Ministry of Health, Labour and Welfare). A total of 32 022 people who were ≥ 12 years old were randomly selected from the Japanese population using a cluster sampling procedure. Three hundred clusters were randomly selected from geographical districts. Survey teams visited all the members aged ≥ 12 years old of households in each cluster and asked them to complete the questionnaire. Beginning with the complete data set, we retained a subset of cases for the present investigation according to two conservative criteria. First, cases flagged in the database because of suspect response validity (e.g. those who answered ‘Rarely or none of the time’ for all items regardless of the valence of items) were removed from the sample. Second, cases with missing data on the CES-D, sex and age were also removed from the data set. A final sample of 20 987 cases satisfied the two inclusion criteria. The final sample was 51% female (n = 10 793) and included a broad range of ages (mean = 42.05 years, SD = 18.03, range = 12–97 years).
Measure
To measure depression symptoms, we used the Japanese version [31] of the CES-D [32], which consists of 20 items chosen to reflect the various aspects of depression. Respondents report the frequency of occurrence with regard to each item during the preceding week on the following 4-point scale: 0 = rarely or none of the time, less than 1 day), 1 = some or a little of the time, 1–2 days, 2 = occasionally or a moderate amount of time, 3–4 days, and 3 = most or all of the time, 5–7 days. The summed score of the 20 items can range from 0 to 60, with higher scores indicating more severe depressive symptoms. Four of the CES-D items are symptom positive and are reverse scored. Researchers most often use a CES-D cut-off score of 16 to identify respondents with clinically relevant levels of depression in a community sample [33].
Data analyses
Indicators drawn from the CES-D were subjected to a series of taxometric procedures developed by Meehl and Yonce, and Waller and Meehl for the purpose of examining the latent structure of depression [7, 9]. Taxometric procedures explore the relations among a set of manifest variables in order to determine whether their underlying structure is categorical or dimensional. The latent structure of depression was evaluated using two mathematically distinct taxometric procedures: means above and below a sliding cut (MAMBAC) [7], and maximum eigenvalue (MAXEIG) [9]. The MAMBAC and MAXEIG were performed with two non-redundant sets of indicators drawn from the CES-D. Furthermore, the bootstrap simulation method developed by Ruscio et al. [27] was used to create 100 simulated taxonic and 100 simulated dimensional data sets with skews and correlations that were similar to those of the indicators drawn from the CES-D. The Ruscio et al. method helps researchers evaluate the suitability of research data for taxometric procedures, and facilitate the interpretation of taxometric results. To interpret taxometric curves, we computed the values of the comparison curve fit index (CCFI) [27]. This index assesses the degree to which an averaged curve, obtained through analysis of research data, resembles curves in the sampling distributions of simulated dimensional and taxonic data set. A CCFI value near 0.50 can indicate an equally good or equally poor fit for the two structures; a CCFI value close to 0 and 1 can indicate a dimensional and taxonic structure, respectively. We performed taxometric procedures using the Ruscio taxometric software program for R [34, 35].
Because we retained a subset of cases (n = 20 987) according to two conservative criteria (i.e. removing cases with suspected response validity, and with missing data on the CES-D, sex and age), it is possible that these criteria might have biased the results. In addition, the inclusion of children as young as 12 years old in the sample could potentially bias the sample in some way. We therefore carried out sensitivity analyses. First, we created the following four datasets: (i) removal of subjects with suspected response validity, and with missing data on the CES-D (n = 21 094); (ii) removal of subjects with suspected response validity, and with missing data on the CES-D, sex and age, and inclusion of subjects aged ≥ 18 (n = 19 151); (iii) removal of subjects with suspected response validity, and with missing data on the CES-D, and inclusion of subjects aged ≥ 18 (n = 19 258); and (iv) imputing missing data on the CES-D using a multiple imputation method [36] (n = 32 022). Second, on each dataset we performed the MAMBAC and MAXEIG following the aforementioned procedures.
Results
Selection and construction of indicator
CES-D items selected for use in taxometric procedures

CES-D, Center for Epidemiologic Studies Depression scale. †Items combined into the Somatic/Vegetative composite. ‡Items combined into the Depressed Affect composite. §Items combined into the Positive Affect composite. ¶Items combined into the Interpersonal Relations composite. ††Used in paired-item indicators; pairs consist of items 6 and 7, 14 and 18, 5 and 20, 9 and 10, and 15 and 19.
Summary statistics and validity estimates
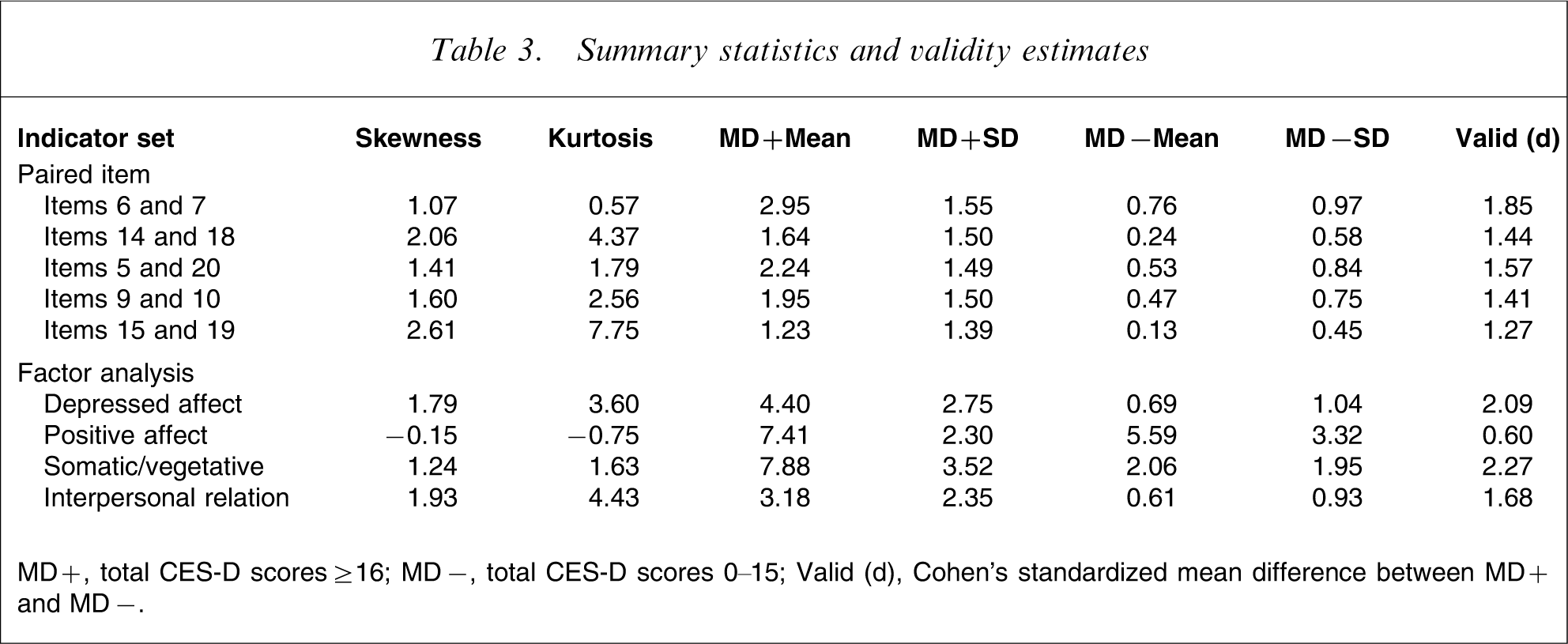
MD+, total CES-D scores ≥ 16; MD−, total CES-D scores 0–15; Valid (d), Cohen's standardized mean difference between MD+ and MD−.
MAMBAC
MAMBAC procedures were performed on each input/output configuration of variables for each indicator set. Summed input indicators were created by removing one indicator from a given set to serve as the output, and by summing the remaining indicators from that set to serve as the input. The panels of individual curves for MAMBAC and MAXEIG, and of the averaged curves for MAXEIG, using 25, 75, and 100 windows, have been omitted due to space constraints. They are available, on request, from the first author. The averaged MAMBAC curves for each indicator set are shown in the first column of Figure 1, and the averaged MAMBAC curves from the simulated taxonic and dimensional data for each indicator set are portrayed in the second and third columns, respectively. As can be observed in Figure 1, each averaged MAMBAC curve resembled the curves from the simulated dimensional rather than taxonic data, although the averaged MAMBAC curves produced by simulated taxonic and dimensional data appeared somewhat ambiguous. Additionally, we computed the values of the comparison curve fit index (CCFI). The values of the CCFI in the present data set were 0.37 and 0.26, respectively (Table 4).
Means above and below a sliding cut (MAMBAC) and maximum eigenvalue (MAXEIG) curves of paired-item and factor analysis indicator sets. In each row, the left graph represents the averaged results for the research data; the middle graph, averaged results for 100 sample simulated taxonic comparison data; and the right graph, averaged results for 100 sample simulated dimensional comparison data
Comparison curve fit indices
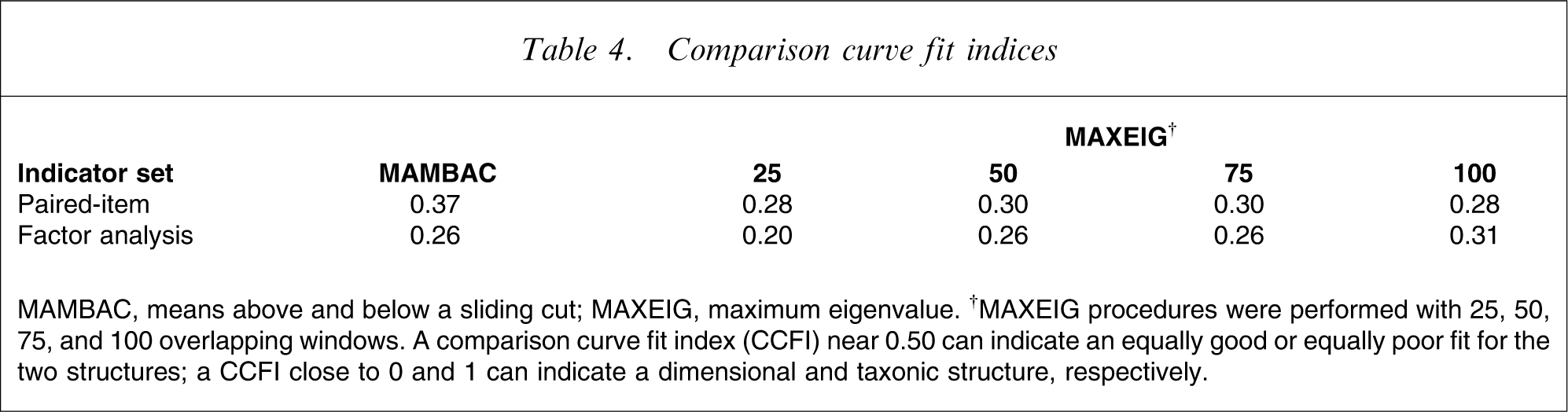
MAMBAC, means above and below a sliding cut; MAXEIG, maximum eigenvalue. †MAXEIG procedures were performed with 25, 50, 75, and 100 overlapping windows. A comparison curve fit index (CCFI) near 0.50 can indicate an equally good or equally poor fit for the two structures; a CCFI close to 0 and 1 can indicate a dimensional and taxonic structure, respectively.
MAXEIG
MAXEIG procedures were performed using each indicator as the input and all the other indicators as the output. MAXEIG procedures were repeated with 25, 50, 75, and 100 overlapping windows to implement inchworm consistency test. As can be observed in Figure 1, each averaged MAXEIG curve resembled the curves from the simulated dimensional rather than taxonic data. Additionally, each CCFI ranged from 0.20 to 0.31, with a mean of 0.27.
Sensitivity analyses
We carried out sensitivity analyses to investigate whether the main results were consistent with those obtained with alternative inclusion criteria. On the four datasets, we performed the MAMBAC and MAXEIG procedures. The values of the CCFI on the four datasets ranged from 0.18 to 0.44, with a mean of 0.32. The panels of individual and averaged curves for MAMBAC and MAXEIG, and the values of the CCFI, have been omitted due to space constraints. They are available, on request, from the first author.
Discussion
To determine whether the latent structure of depression is categorical or dimensional, we carried out taxometric procedures on a general population-based sample of >20 000 individuals selected using a cluster sampling procedure. Both the MAMBAC and MAXEIG procedures using indicators drawn from the CES-D yielded results that the latent structure of depression is dimensional. The results of the current study replicate and extend the findings of earlier taxometric procedures of depression (Table 1). Past findings of taxometric studies of depression have been somewhat contradictory and difficult to reconcile. One reason for the disagreement was that most researchers relied only on selected samples (students, clinical patients, or screened community samples). By implementing taxometric procedures in a sample that includes individuals with a wide range of depression severity, the current study extends the conclusion of dimensionality in depression from selected samples to samples in the unselected general community.
Implications of the present study
These dimensional findings raise questions about the current categorical classifications of depression and the associated methods of assessment. Current diagnostic systems suggest that individuals either suffer or do not suffer from depressive disorders. Such a typological classification, in the context of the current results, may conceal the graduated nature of depressive symptomatology and may subsequently hinder the collection of clinically and empirically relevant information about the phenomenon of depression. One approach for organizing and classifying individual differences in depression is to conceptualize them in terms of having varying continuity [3]. A dimensional model of classification could provide a more specific and individualized profile description of the severity of a patient's symptoms, which may, in turn, have more differentiated and specific treatment implications.
In addition, the common practice of forming groups by dichotomizing continuously distributed depression scores can lead to serious problems with regard to precision in measurement. Approximately one in three studies in Japanese depression literature used such a practice [39]. Such a practice could reduce statistical power [40, 41], obscure the conceptual nature of the construct, disguise potential non-linear relationships between depressive symptoms and other variables of interest [42], potentially create spurious statistically significance, and increase Type I errors [43]. Due to these weaknesses, correlational research designs that include individuals with a wide range of depressive severity would likely replace group comparison designs in the study of depression [42].
Strengths and limitations
There are several methodological advantages in the present investigation. First, the sample was drawn from a general population-based sample. The use of a general population-based sample is a substantial strength as compared with previous taxometric studies that used more restricted samples (e.g. students, clinical patients, or screened community samples). Second, the relatively large sample size (n = 20 987) increased the statistical power to investigate the latent structure of depression. Depressive disorder common in the clinical population might be difficult to detect in a general population because they are relatively uncommon. Although Monte Carlo research suggests that taxometric procedures can indicate a taxonic structure with a taxon base rate as low as 0.10 [7, 44], it is possible for a taxon base rate of <0.10 to be detected in very large samples [42].
We should also note some of the limitations of the present study. First, we focused only on the CES-D symptoms of depression rather than additional potential indicators of depression, such as the interview-based, biological, or psychosocial assessments of depression. Second, the generalizability of the present results is limited by the predominately Japanese composition of the sample. Third, whereas all the values of the CCFI supported dimensional structure for MAMBAC and MAXEIG, the averaged MAMBAC curves produced by simulated taxonic and dimensional data appeared somewhat ambiguous. Finally, although we used a cluster sampling procedure that leads to clustered data (i.e. people within a given household are more likely to be similar to each other than people between different households), it was unclear to what extent such intra-class correlations biased the results. Further research is required to replicate the results of the present study, using other measures, other populations, and other sophisticated statistical methods.
Conclusions
The continuity controversy of depression has been one of the most widely discussed issues in the field of psychopathology. Although several previous taxometric studies in selected samples have shown contradictory findings with regard to the latent structure of depression, the current study builds on previous taxometric studies of depression in unselected samples by demonstrating that depression measured by the CES-D is continuously distributed in a community population. The dimensional structure of depression should be considered when classifying individual differences and selecting suitable research designs.
Footnotes
Acknowledgements
We are grateful to Ms Kahoru Takabatake for her feedback on an earlier draft of this article.