
Abstract
“Public health surveillance (PHS) is the ongoing and systematic collection, analysis, interpretation, and dissemination of data regarding a health-related event for use in public health action to reduce morbidity and mortality and to improve health.” As information technology gains acceptance as a core element of public health practice, many approaches to the design of PHS systems have been proposed, much has been spent implementing them, and expectations have been high. Unfortunately, the systems implemented so far have been criticized as having not met expectations, especially in the domain of early detection and bioterrorism readiness, or so-called syndromic surveillance (The term “syndromic surveillance” applies to monitoring health-related data that precede diagnosis to signal a sufficient probability of a case or an outbreak that warrants public health response.). There are no fully established frameworks to enable seamless interoperability, information sharing, and collaboration among PHS stakeholders and the technological and infrastructural requirements to fulfill the grand vision of initiatives such as the Public Health Information Network and National Health Information Network are poorly investigated and documented.
In this article, we examine the current state of the conceptualization, design, analysis, and implementation of PHS systems from a translational informatics perspective. Although most examples in this article are informed by the needs of public health preparedness (syndromic and bioterrorism detection and response), we believe the framework we introduce is generalizable and applicable to the broader context of PHS systems. We also apply concepts from cognitive science and knowledge engineering to suggest directions for improvement and further research.
Keywords
Introduction
“Public health surveillance (PHS) is the ongoing and systematic collection, analysis, interpretation, and dissemination of data regarding health-related events to enable public health personnel to reduce morbidity and mortality and to promote public health.” 1 PHS has attracted the attention of informaticians in recent years and important initiatives have been founded to create PHS standards, protocols, guidelines, and best practices. 5 9 These include the U.S. Centers for Disease Control and Prevention's (CDC) Public Health Information Network (PHIN) initiative. PHIN is intended to elevate and integrate the capabilities of information systems across various public health organizations and interrelated public health needs. 10 To fulfill the vision of PHIN, PHS systems will need to interoperate with other systems that support disease surveillance, national health status indicator reporting, data analysis, public health decision support, knowledge management, alerting and notification, and assist in public health response management. 8 10 Because PHIN focuses on introducing and prioritizing the functional requirements, capabilities, performance measures, and operational characteristics of public health systems, it leaves open the enabling approaches, methodologies, and conceptualization of the IT infrastructures needed to implement its requirements. For instance, although the use of controlled vocabularies is frequently recommended throughout the PHIN documentation, there is no discussion of methods for representing, mapping and mediating, translating, or extending these vocabularies to support different local use cases, as they interoperate with federal and regional mandates.
As public health systems rely on clinical data and reports from various health care providers as inputs (e.g., patient records from hospitals and outpatient clinics, clinical laboratory test results), PHIN calls for a tighter integration of PHS systems with electronic health record (EHR) systems to enable timely and reliable information exchange. 8 This is also a call for informaticians to discuss the theoretical and practical implications of the construction, transport, transformation, integration, and interpretation of messages exchanged among disparate information systems, each of which having significant structural and semantic differences from the others. For instance, the field should address questions such as “How can ICD9-CT codes recorded for billing purposes be integrated with SNOMED CT codes recorded for documentation of patients' health status?”, and “How data from clinical systems can be integrated with local health status indicators, surveys, and field reports that are not coded with any standard vocabulary?”, and “How this process can be validated and automated to scale for practical use?”.
Frequently, the significance of the collected data may not be immediately clear, so public health officials use epidemiological investigation techniques to answer questions about the existence and nature of, causes of, and associations among observed patterns or aberrations in data. This allows them to develop hypotheses and rationale for disseminating public health alerts. Because each public health event is unique in nature, PHS systems face unique requirements concerning the type, complexity, and heterogeneity of data they must be prepared to process. However, the minimum set of data needed to support effective hypothesis building for a given PHS application has always been a controversial issue. For example, important information for bioterrorism preparedness may come from equivocal and controversial inputs that may be indirect indicators of public health events. These include such diverse sources as prescription and over-the-counter drug sales, veterinary surveillance, environmental safety (e.g., exposure to pollutants or toxins), active surveys (e.g., telephonic polling), and intelligence reports. 11
This article is intended to promote discussions between health information scientists and public health informaticians regarding the theoretical and practical implications of the design and implementation of integrated PHS systems as robust as those envisioned by PHIN framework and tasked to the public health informatics community.
We will use concepts from the “Translational Public Health Informatics” as the grounding framework that motivates this paper and provides context for this analysis. We firmly believe that public health informatics as a discipline is an integral component of the greater health informatics (that includes other disciplines such as biomedical, clinical, and nursing informatics), and that its conceptualizations, criticism, and analysis should take into account its relationships and contributions to the evolutionary processes of the health sciences as a whole. Hence, this analysis is influenced greatly by the main thrust and ongoing discussions of the health informatics community as it relates to translational research.
This article discusses the significance of a translational approach to the problems of public health informatics in general and PHS in particular, as it introduces some of the enabling principles for conceptualization and design of an optimal PHS system that may fulfill the requirements of the PHIN and can meet the vision for the translational informatics. It then reviews and discusses the theoretical specifications and practical implications of some high-level functions of an optimal PHS system in light of these enabling principles.
Translational Public Health Informatics
Translational informatics is a rather new integrative vision that seeks to meaningfully integrate information and knowledge from all levels of biology including molecules (biological data such as genomic, proteomic, and metabulomic), tissues and organ systems (physiological data, including clinical laboratory test), individuals (clinical and phenotype data), populations (public health data), and environmental data to facilitate and promote the process of hypothesis building and discoveries necessary for understanding, diagnosing, treating, and preventing human diseases.
The intent is to transition today's inefficient, costly, and slow process of communication and information exchange between silos of scientific research and practice (Fig. 1, today) to an integrated platform where scientists and practitioners can hypothesize theories and make decisions based on findings and evidence available from basic science to population health research.
Translational research seeks to leverage deep relationships that exist between principles of science (chemistry, biology, physiology, pathology, epidemiology, etc.) to construct holistic and evidence-based interpretive models of the world. The idea is to arrive at better and more complete solutions faster, by asking better and more informed questions and using all relevant data, information, and knowledge from all disciplines of science. This vision largely depends on the effectiveness of the research infrastructure (and its cultural environment) in “translating” new discoveries in one discipline (e.g., genomics) to meaningful information in others (e.g., epidemiology). Informatics solutions are the cornerstone of any translational approach as they provide the enabling platforms to interoperate, and access information from silos of disparate data and contextualize and integrate them into a shared perspective that all researchers and practitioners can access, retrieve, understand, and use (Fig. 1).

Transition from current information sharing model to translational research model.
PHS shares principle requirements with the translational research in that it depends on the meaningful integration of heterogeneous data and its contextualization for multidisciplinary reuse. However, the current state of conceptualization and implementation of PHS systems has created yet another information and knowledge silo in the big picture translational research view that needs to be revisited. It is the task of the public health informaticians to conceptualize next generation of informatics infrastructure and PHS systems that can seamlessly and effectively interact, share, and exchange information with other communities of research and practice (Fig. 1).
Enabling Principles
To start a discussion on requirements of PHS systems to meet the expectations of PHIN and NHIN, and to enable a multidisciplinary and translational public health practice and research we examine the current conceptualizations through the lens of the following four high-level enabling principles. These principles are abstract and conceptual, and closely related, but helpful to inform readers of the way we are thinking about the research into, and the development of next generation PHS systems. Later in the article, we will address the implications of these principles in the design and implementation of selected system components of a model PHS system.
Dynamic Adaptability
A PHS system should be flexible enough to adapt dynamically to the requirements of daily public health practice. An ideal system might be precoordinated to account for the day-to-day PHS operations and from the points of view of different user groups. However, it should also be flexible enough to change properly to address use cases that arise ad hoc, and as a result of evolving situations and unprecedented scenarios.
The behavior of an adaptive system should coordinate with the characteristics of its operational environment and produce relevant outputs and interactions. For example, one would expect a PHS system to operate and behave differently when applied to the needs of a small border town than when it is used in a metropolis.
A general-purpose system seems the obvious candidate, but it would not have the functionality needed for specific use cases and problems that may arise locally. Instead, what is needed is a “dynamically specific” system that can change its behavior based on contextual information, such as the knowledge that a population under study has been given antibiotics or been vaccinated, thereby altering its risk. Such an ideal system may be specialized and precoordinated to account for generic aspects of PHS, yet be flexible enough to accommodate local needs and novel use cases.
To be this flexible, the system must readily integrate disparate types of information and represent and use contextual and background information. It should also be able to capture and use domain knowledge that is required to interpret the data and the contextual information effectively.
Interoperability in a Distributed Environment
The conceptualization of PHS systems has been transformed by such major trends as the adoption of EHR systems in all sectors of health care, the evolution of the Internet, and local and federal mandates for information sharing and collaboration. Next generation of PHS systems have to operate beyond boundaries of a single cubicle, department, or agency and must address the needs of a larger, more complex, and dynamically changing environment.
For reasons technical, practical, and logical, it is implausible to precoordinate all possible interfaces among all participants at design time. It is plausible, however, to design a system that is aware of such interoperability needs and is able to share information and services on demand (just in time) on an ad hoc basis with collaborative systems.
This involves using information representation frameworks based on standards and vocabularies as well as system architectures that enable interoperability and sharing of both information and services, and is flexible enough to adapt to new standards or changes in existing ones, without disruption. A framework that enables ubiquitous and pervasive PHS systems that share information and services 16 17 on demand and across variety of platforms, devices, jurisdictions, and networks of users.
Support for Multidisciplinary (RE)use of Information
Informational resources are among the most critical assets of a health department. 18 A model PHS system should therefore enable reusing data by different parties, allowing each to contextualize and repurpose information according to its own perspective. 19 For example, law enforcement and intelligence community views and interprets biosurveillance data from a contextually different perspective than an infectious disease specialist or an epidemiologist. Hence, the PHS system should also enable asking and answering questions such as “is this man made? What bio-agents are involved and who has access to them? How this has been released and propagated?”.
Another important aspect of information reuse is accountability and protection of the confidentiality of the individuals. Because access to and reuse of patient data is controlled, regulatory policies should be available at the system level to dynamically govern (enforce and audit) access rights. For example, information transformation can be automated to protect patient privacy by altering the granularity of data (e.g., by age group rather than date of birth) and by encrypting or omitting identifiers when data are reused between operational and research communities.
The original context of data should be preserved and made available so that the information can be repurposed for novel use cases. The context of repurposing should be available to the system such that it can be used to enforce relevant access and use policies and to invoke pertinent protection or transformations. It is critical to unambiguously associate original data with its subsequent transformation and with the rules and logic of the transformation in a traceable, accountable, and maintainable way.
Human Factors and Human—Computer Interaction
The field of human—computer interaction (HCI) studies the interaction between users and computers. As an interdisciplinary subject, its primary goal is to improve communications between users and information systems through effective, goal-oriented, intuitive, and effective user interfaces (UIs). 20 The key challenge of the HCI is to understand the interactions of cognitive constructs such as perception, attention, memory, and mental workload along with higher-order concepts such as learning, decision making, and awareness to construct artifacts (devices, applications, interfaces, and visualizations) that interact effectively with them.
PHS systems operate in a complex and dynamic environment subject to time pressures, and high-impact decision making. Such an environment is challenging to a human decision maker because people tend to perform poorly under high stress, high risk, and high workload. 21 22 Conversely, studies have shown that humans also perform poorly under conditions of low stress and low workload (e.g., continuous monitoring tasks). 21 Both extremes are typical of PHS especially when used for bioterrorism preparedness, where long periods of inactivity may be punctuated by rapidly developing situations requiring quick investigation, characterization, and response. 23
These four enabling principles (dynamic adaptability, interoperability and collaboration, multidisciplinary reuse, and HCI) inform conceptualization of an integrated and ubiquitous biosurveillance system where all information, processes, and activities are supported by a dynamic, distributed, and context-aware architecture. They are interrelated and share important architectural and technical prerequisites such as a robust and scalable information exchange and integration systems built upon high bandwidth and secured communication infrastructures. They depend on expressive information representation frameworks that explicitly, precisely, and unambiguously represent data, metadata, information, and knowledge, along with its meaning and context in a shared network of collaborators. They all require tapping into computer reasoning, deductions, and inductions that can be used to enable automation, discoveries, and intelligent interactions among components of the system, and between the system and its users. However, these prerequisites, strong and effective as they are, can greatly constrain the technical infrastructure that is required and is available at the time to conceptualize and implement them.
Application of the Enabling Principles to phs System Design
For illustration purposes, we have selected some functions and components from PHS systems used for syndromic surveillance and bioterrorism preparedness. However, we maintain that points made here are equivalently applicable to the PHS system in general. Figure 2 illustrates the proposed conceptual relationships between the principles and components.

The four enabling principles as they relate to critical public health surveillance system components.
Natural Language Processing
Natural language processing (NLP) is concerned with the conversion of human language to a machine-readable form. 24 Free text contains some of the most important yet underused data in health care. Such text entries may yield valuable information for PHS systems such as syndromic surveillance and bioterrorism preparedness systems. 25 26
Different NLP methods have been proposed, broadly including statistical, syntactical, and semantic methods. 27 Statistical methods use data-driven approaches (e.g., Bayesian methods) to match lexical symbols to a controlled set of terms. 26 Syntactic approaches use heuristic and text-parsing techniques to find morphologic similarities or grammatical relationships among lexical forms and map them to a controlled set of terms. Semantic approaches use a knowledgebase to identify explicit concepts and their relationships within the text. 24
Most surveillance systems take a combination of syntactic and statistical (data-driven) approaches. They maintain lists of keywords such as “abdominal pain” and may miss semantically approximate forms such as “pain in the stomach” or “stomach ache.” They may also fail to capture negations (“no pain”) and uncertainty (“rule out MI”). Likewise, they cannot detect inconsistencies, such as when a patient is referred to as both male and pregnant at the same time. Data-driven and syntactic approaches are sensitive to changes in morphology of lexical expressions that are often specific to certain data sets. Hence, a training and reevaluation process may be required with new data sets or the same data set over time.
On the other hand, semantic methods require representation of relationships such the synonymy, hyponymy, hypernymy, and various senses of a word in context (Polysemy). They are process intensive and complex to implement and use, compared with other methods and rely on the existence of valid knowledgebases to represent domain knowledge and task-specific concepts and their relationships. In health care, much of this knowledge may be found within controlled vocabularies or knowledge sources such as the National Library of Medicine's Unified Medical Language System. 28 29
All four enabling principles require a robust NLP that can interpret and contextualize information-rich text entries from health care providers, field reports, first responders, and intelligence reports, extracting relevant information in a form that is not only computer interpretable for the use case at hand, but also usable in a collaborative environment and retrievable for future requirements.
The relevance of raw text to a spectrum of needs may not be obvious at the time of information processing. For this reason, NLP should be agnostic to specific applications and generalizable enough to allow for reuse of its output in future and for novel situations. For example, one system may be tracking patient complaints while the other tracks medication history. Each system has a different purpose but is able to make use of the same output. Hence, NLP outputs should be complete and understandable to collaborating systems with different needs. These requirements pose interesting challenges and opportunities for application of hybrid algorithms that combine syntactic, statistic, and semantic approaches in text understanding and output representation for PHS systems.
Information Integration
PHS systems use data from disparate, heterogeneous sources such as clinical laboratory test results, patient encounter data, environmental monitoring, pharmaceutical sales data, insurance claims data, vaccination registries, vital statistics, morbidity and mortality data, and notifiable disease reports (e.g., AIDS, STDs). Frequently, the information are not originally intended for public health use and cannot be used immediately by PHS systems due to differences in schema, terminologies, semantics, and content.
Structural differences occur when different schemas are used to represent relations and type associations between the same real world objects (spreadsheet vs relational database). Naming differences occur when lexically distinct terms are used to refer to semantically identical objects (fever and pyrexia both mean high body temperature). Semantic differences occur when lexically identical terms are used to refer to semantically different objects (MI may mean mitral valve insufficiency or myocardial infarction). Content differences occur when certain real world objects are not modeled or are not accessible in different data sets due to different local objectives or constraints (content of data from veterinary health surveillance system are different from human health surveillance sources). 30
An example illustrating these differences is that of a spreadsheet used to report clinical lab results for a patient with a reportable condition, versus an XML message containing admission data from a hospital for the same condition. These two sets of data may be considered heterogeneous on the basis of structure (XLS vs. XML), semantics (test result vs. diagnosis), naming (Patient ID vs. Medical Record Number), and content (lab data vs. chart data).
The core solution to the information integration problem is to provide a single, unified reference model that reconciles such disparities while also providing a query model to retrieve integrated information. 30 This query model should consist of an abstract model of the integrated data and a query interface with a clear syntax and semantics for human use.
Translating data from heterogeneous sources into the reference model may involve data transformation. This may cause a new problem: distortion or loss of the original meaning and content during transformation. The original data may be translated, generalized, specialized, merged, or even removed to conform to the reference model. This makes it impossible to preserve the context and semantics of the original data, reducing the ability to repurpose it or to update it to reflect modifications to the reference model itself (forward compatibility). This may also prevent the implementation of a proof mechanism that can track from conclusions back to the data that generated them, a problem for the traceability often required in public health investigations.
Most PHS systems are designed to use data in an isolated, fragmentary way and therefore perform only a superficial integration of data. For example, although prescriptions and lab reports may be maintained in the same database, they are not integrated by a unifying model and are instead processed, queried, and reported as two distinct data sets. This may prevent from detecting associations that may emerge only by fusing clusters of data.
Alongside with unifying (reference) models for data integration, the use of standard-based terminology systems has been suggested as one of the significant steps to support information integration and multidisciplinary reuse of data. PHS systems should support the use of controlled vocabularies (such as LOINC 31 SNOMED 32 ) and standards (such as HL-7 Clinical Document Architecture 33 and PHIN-Logical Data Model 7 11 ) but with a flexibility that allows users to extend these vocabularies and standards to meet local needs. Any such extension, addition, or change should be explicated precisely and made available to the collaborators to enable interoperability. The reference model used internally by PHS system to integrate multisource data should be available to collaborators so that they can build meaningful queries or transformations of their own. The information integration presents with opportunities for use of ontologies and other knowledge representation frameworks that have long been proposed, but are rarely considered in the conceptualization of PHS systems.
Context Representation
Context is a model of the elements of the environment relevant to mission and task. 34 35 Its use is essential for illustrating the appropriate view of a dynamic problem. 22 Context of a public health problem may include such things as location and time; environmental hazards and exposures; geographic features; the social, cultural, economic, and political characteristics of the operational environment; historical and current events; decisions made; response activities deployed; and their results.
Note that context is not the same as knowledge. 34 36 Context is a dynamic model of the background information relevant to the task at hand that the system needs to take into account to do analysis on demand. 34 37 It is specific to location, time, user, task, and system. A context-laden statement might be “Hourly ozone levels have been measured above 80 ppm for the past eight hours in Brazoria County, TX.” Knowledge, by contrast, is a static set of facts and beliefs available to the system for the purpose of making analyses in general. A statement of knowledge might be “High ozone levels may exacerbate asthma attacks.”
To disambiguate data, distinguish most relevant pieces of information, and target action, it is important to build a system that makes use of contextual data.
Although the principles of dynamic adaptability and HCI highlight the need for a shared understanding between users and their computational environments, 38 in current public health practice it is human experts who provide most, if not all, contextual information. The fundamental design question that context representation aims to answer is “how, at design time, to construct a software system for multiple users, scenarios, and environments while making the system operate at run time, as if it were designed for each individual user, scenario, environment, and problem. 19 ” System needs to be developed which can capture and represent the contextual information in a computationally understandable way (formally), such that computer programs can understand the importance of data in specific circumstances and retrieve and use valuable background information to interpret new data.
Context awareness has implications for system architecture. 19 39 Fischer (2001) proposes building systems that infer a use-time context automatically and then allow users to extend this inferred context by articulating other contextual factors that will add to the information available to the system. Banavar and Bernstein cite the need for semantic modeling to enable the representation of user preferences and the characteristics of the environment so that they may be incorporated into applications. 19 They also cite the need for the further development and use of shared services so that the flow of information and processes among system components can be modified dynamically in light of contextual information. We maintain that lessons learned from knowledge and context representation research 17 40 42 can inform the design and implementation of context representation and context awareness in PHS systems.
Concept Definition
One of the most important aspects of information processing in PHS systems is the definition of concepts used by the system to refer to existing data and information. Furthermore, many operationally useful concepts may not be immediately available from the original data. A PHS system therefore needs a method for defining concepts by clearly associating them with other concepts within the system and with objects that they represent. For example, syndromic surveillance can only produce meaningful results if there is a clear understanding and definition of which observations constitute a syndrome such as “RESP,” “GI,” or “DERM” 43 and consequently, how a syndrome relates to high profile community events such as “Influenza Outbreak.” 44
There is a problem, however, in that the constituent elements of such syndromes are poorly characterized and are rarely explicitly defined by users and developers of the PHS system. Graham et al., surveyed 15 different syndromic surveillance systems currently in use. They reported different case definitions for “acute respiratory illness due to the intentional release of biological weapons” in all systems. All 15 surveillance approaches used different criteria with substantial conceptual heterogeneity for enumerating and tallying illness syndromes attributable to biological illness, with little or no evidence of a coordinated or evidence-based approach. 45
Public health officers at one of the city departments of health and human services reported during a Superbowl event that there was no documented consensus as to how health care providers should define “Respiratory syndromes” in their daily surveillance reports in preparation for the big event. Rather, each reporting entity used implicit personal or organizational definitions when communicating surveillance data to the city department of health. These scenarios present with serious but avoidable sources of semantic heterogeneity in the surveillance data and barriers to meaningful integration, interpretation, and reuse of data.
Ideally, PHS systems should use a method that defines a concept in an explicit, unambiguous, and traceable (provable) manner, making the concept available to experts for validation 45 and to computers for unambiguous interpretation. A definition with multiple connotations may mislead if we do not know the assumptions or intent behind it. If a system defines a concept based on a set of rules and assumptions, the existence and validation of the rules and assumptions should be made an explicit and verifiable component of the concept definition. The method for defining new concepts should allow for the representation of qualitative constraints such as equivalency, disjointness, inheritance, set membership, transitivity, and cardinality, among other things.
By contrast, black box approaches define concepts using heuristics or statistics compiled into machine code and lookup tables, or through complex scripts that interfere with the enabling principles of dynamic adaptability, interoperability, multidisciplinary reuse, and HCI. A combination of taxonomic descriptions, ontological representations, and logic or rule-based classifications can be used to implement concept definitions. 46 48 These methodologies directly address the enabling principles of dynamic adaptability, interoperability, and multidisciplinary reuse. They may enable PHS systems to redefine and refine existing concepts as relevant to novel problems and adapt to changing environment as new facts become available to the system.
Signal Detection and Signal Characterization
Almost all PHS systems use some form of signal detection to identify potentially important events such as disease cases, aberrations, or outbreaks. A signal may be defined as the crossing of an established threshold in time and measured in terms of averages, counts, standard deviations, etc. Thresholds can be: Theoretical, suggested by simulations and approximations, Historical, extracted from baseline or historic data, or Heuristic, developed through seasoned opinion, rules of thumb, and intuition. With respect to identifying unexpected or unfamiliar events, these categories are all hypothetical and specific only to assumptions, algorithms and data sets used to produce them, time of calculation, and other circumstances. The problem of signal detection can be further exacerbated when a signal is anticipated, as in the case of avian flu, by the “sluggish beta” phenomenon. 49 This refers to the human cognitive tendency to set a threshold, intentionally or subconsciously, where it should not be in the hope of detecting signals as soon as they occur, increasing the sensitivity. In reality, this process only hides true signals in more noise, reducing the specificity.
A signal can also be defined as an unexpected cluster or aggregate in some measure of time, space, or space-time. 50 Clusters may be defined based on their shape, size, and distribution. However, an unprecedented public health event may not be detectable in a timely manner using a hypothetical threshold, or may not present itself as a cluster with an anticipated shape or size.
Signal Characterization
Once a signal is detected—that is, a measurement has crossed a threshold, or a cluster is found to meet a certain criteria for size and shape—the salient question the public health expert must ask is “So what?” An aberration may or may not signify an outbreak and may or may not be of public health interest. 51 Signal characterization is part of the investigation process that follows signal detection and involves determining the public health implications of a signal once it is detected. As such, it is concerned with such questions as “What makes this a true signal?,” “Is it important?” and “Why?,” “How similar and different this is from events in the past?,” “What is the population at risk and how does it impact other sectors of the community?,” and “How can we explain the root cause of the event?.” Answering these questions is a knowledge-intensive process beyond the scope of most statistically driven systems, which stop after the detection of a signal.
The method used to define a signal is a significant component of its characterization. It is difficult to evaluate the nature and significance of a signal, especially when it is based on implicit and ambiguous definitions such as “respiratory,” “gastrointestinal,” or “rash.” Furthermore, not knowing the intent behind the operational definition of a signal prevents experts from making an unambiguous, problem-specific interpretation in the context of the situation at hand. For example, detecting a signal in “RESP” does not by itself distinguish among potential outbreaks of SARS, influenza, asthma related to particles and Ozone, or bioterrorist attack if the definition and the intent behind “RESP” are black boxes not available through the PHS system.
Ideally, signal detection should be informed by explicit definitions of concepts and the intent behind them. For example, different concepts can be defined to represent influenza, influenza-like illness, asthma, SARS, etc. The PHS system should be able to place a signal in its proper context using background and baseline information and in accordance with its definition.
It is important to emphasize the significance of context representation in signal detection and characterization in a PHS system. That is, inclusion of other inputs which may inform conclusions about a signal under investigation: concurrency with other observations (such as weather, air, and water quality), travel history of population involved, spatial and temporal aggregates within a pattern such as clusters in the vicinity of potential exposure sites, sociopolitical factors (such as political conventions in a major city, intelligence reports) might render an otherwise unassuming pattern into a signal even in the absence of a crossed threshold or render a signal insignificant in the light of other considerations.
Therefore, from the HCI point of view, the signal detection marks the beginning of a knowledge-intensive and interactive process among domain experts and information systems and needs to be supported by sophisticated PHS systems. The research questions for the public health informaticians are how to capture the epidemiological and cognitive models effectively and completely, how to represent them in a computationally interpretable way, and then how to implement computer systems that can instantiate them based on availability of data. 53 Implementing such systems may require creating epidemiological models based on the acquisition and representation of the knowledge from public health practitioners, knowledgebases and published literature, the goal-directed task analysis of surveillance practices 54 56 that establishes relationships between evidence, its interpretations and the appropriate course of action, and the development of systems that integrate data from multiple domains without distorting their original semantics 23 and translating that into unambiguous evidence. This effort could improve signal detection and characterization, one of the most resource-intensive activities in epidemiology, thereby reducing the cost of dealing with false positives. More broadly, such a development would also be the first step in implementing systems that guide users, support decision making, and enable situational awareness. In short, a system driven by domain knowledge and contextualized information taken from an operational environment. Such epidemiological models, once made available online, would enable information sharing and collaboration in a distributed environment among experts from multiple disciplines. The techniques for defining and creating such models, and for implementing the systems to use them, are a fruitful area of research.
Information Representation and Visualization
PHS systems are built on a multidimensional information space. Some of the most salient representational dimensions of public health data include time (when things happen), locale (where things happen), role (the purpose of a representation), and data domains (the sources of the information). 13
The human brain is sophisticated and flexible in recognizing patterns and detecting relations in visually perceived information. 57 Hence, the visual representation of information allows users to detect patterns and associations among components of information. Geographical Information Systems have long been used in PHS systems to visually represent geographical data, including overlays of disparate information with common geospatial components. Conventional graphical visualization techniques—charts, graphs, and tables, etc.—are extensively used by PHS systems to represent information for human interpretation. However, painting “the big picture” of public health status using conventional approaches is reminiscent of the legend of the blind men and the elephant. 58 Fragmented visualization of public health information using traditional techniques may fail to provide a comprehensive view of the dynamic and complex underlying information structure. 13
Providing such comprehensive view has always been a challenge. Information visualization for PHS needs a theory of representation that accounts not only for the capabilities of display technology, but the structure of complex information and its dimensions, human cognitive capacity, and the social context of work. 59 It should provide the user with the ability to explore an entire body of information through the techniques similar to those proposed by Scheiderman (1996): “Overview first, zoom and filter, then detail on demand. 60 ” This involves allowing the user to see all dimensions of the information as needed and at any required level of granularity in an easy and intuitive manner. 61
Semantic and domain visualization research may help provide such a “big picture” insight into complex and multidimensional information structures 62 63 by enhancing the user's perception of structure in large information spaces and navigation. They enable users to use their cognitive processing and observation capacities to interpret information, to extract knowledge more efficiently, and to gain insight. 60
Cognitive Support through User Interaction
Another challenge for the current state of PHS systems is the lack of cognitive support for human users during emergency, risk, and higher workload. 15 21 Scientists have documented cognitive limitations of various kinds. These include limitations of human cognition for signal detection, such as sluggish beta, falsifiability, and vigilance. 49 There are also limitations of information processing, such as absolute judgment, fixation and tunneling, salience and recency bias, and training transfer. 21 49 In addition, there are limitations of decision making and planning, such as uncertainty, representativeness, confidence, anchoring, confirmation, and framing bias 64 The field has been extensively studied for building interactive information systems for air traffic control; aircraft piloting; combat communication, command and control, and intelligence (C3I); and some medical procedures such as tele-operations, anesthesiology, and intensive care. 65 66 Common to all of these domains are as follows 34 :
Multiple competing goals and objectives that are active at any given time. Operators need to prioritize and share time between tasks and objectives.
Diverse sources of information need to be objectively and constantly inspected for cues. This may overwhelm human operators and increase error.
Limited time is available for the interpretation of information, and for making high-impact and (often) risky decisions.
A short window of opportunity exists to deploy effective response.
We maintain that operational environment for the PHS systems especially in areas related to outbreak detection and bioterrorism preparedness shares all these characteristics. However, body of evidence and literature evaluating the usability and HCI considerations for the PHS systems to provide the appropriate cognitive support for public health practitioners are scarce if not absent.
Although current PHS systems use some degree of intelligence to automate tasks such as signal alerts and notifications, the burden of interpretation is always on the cognitive system of a human operator, which is prone to errors and limitations when risk and emergency overwhelm psychological factors. The following high-level HCI desiderata —if applied properly and systematically—may improve the usability of the PHS systems especially in the time of high pressure and overwhelming workload:
Usability and usefulness—The UI should be operable with ease and efficiency. It should allow the user to complete all relevant tasks without unnecessary bottlenecks and avoidable steps.
Intuitiveness and naturalness—The UI should be intuitive, its operations seemingly natural to the user. Often, software systems are described as “intuitive” simply because they have a graphical user interface (GUI). A poorly designed GUI may be very unusable.
Data density, information scatter, and information absorption—The UI should use technology and innovative design to present information to users with an appropriate degree of density while improving information absorption. The rapid growth in the density of computer screen real estate, as well as advances in virtual reality and multidimensional displays, has created an opportunity to accelerate data density to much higher levels.
User-centered design (UCD)—UCD is a modern design philosophy rooted in the idea that users must take center-stage in the design of any computer system. Users, designers, and system engineers work together to articulate the wants, needs, and limitations of the user community and create a system that addresses these elements.
Human-centric distributed information system design (HCDID) 16 —HCDID meets the cognitive requirements of an optimum collaborative environment where a group of humans and artifacts need to interact to perform a task and when cognitive resources (i.e., processes, information, and knowledge) are distributed among both humans and computers. HCDID aims at optimizing the efficacy of the collaboration among groups of computer systems and users. 13 As mentioned in a prior section PHS systems present with a prototypical environment where researchers and practitioners from multiple disciplines interact with information systems and database artifacts distributed in a wide collaborative network. This is an indication that the design and conceptualization of PHS systems can benefit from adoption of some of the HCDID concepts.
According to Endsley, SA is the internal mental model representing the current state of an individual's dynamic environment. 34 In this model, SA is meaningful within the context of mission and task and it informs—but is distinguishable from—decision making, performance, and other cognitive processes. There are four reasons why we believe applying principles of SA research is important to the design of PHS systems 22 :
SA can be linked to performance—Measures of SA have been correlated directly with performance in aviation and military research. 35 67
Inadequate SA may be associated with errors—Bell and Lyon found that fighter pilots with lower SA during a combat scenario had a significantly greater number of decision errors than pilots rated highly for their SA.
SA may be related to expertise—Experienced physicists have been shown to classify physics problems differently than novices. 38 66 This may imply that the expert constructs a different mental model of the environment and its dynamics. Such models, if captured and formally represented, can be a basis for conceptualizing more robust PHS systems and for evaluating the performance of the systems and their users.
SA is the basis for decision making in most cases—Endsley and Klein propose a recognition-primed model to explain the phenomenon of decision making. This model may inform the conceptualization of a decision support model for PHS systems. 34
In addition to these four reasons, multidimensional measures of SA, such as the Situation Awareness Global Assessment Technique, have been shown to be sensitive to differences in information seeking, information interpretation, and the projection of future courses of events, which are not reflected in traditional performance measures 54 56 used to evaluate PHS systems. The design of objective measures of SA may help identify performance problems and error mechanisms in current and future PHS systems. Performance problems may occur due to poor UIs, poor information representations, poor information seeking behaviors, poor communications, and teamwork among collaborators in a distributed environment.
Although the analysis of the domain with respect to SA is resource intensive and requires a considerable investment of energy and time, the resultant analysis provides a highly useful foundation for directing design efforts, and training needs to effectively use existing systems. It may prove to be well worth the effort, given the success this approach has seen in fields such as aviation, nuclear power, C3I, and combat control.
Discussion
Despite the expenditure of millions of dollars on the design, implementation, and support of PHS systems in the hope that they would yield better public health preparedness, there is growing criticism as to whether or not they work and are cost-effective. In response to these criticisms, CDC has started initiatives to create a consensus on the definition and standardization of the key functional requirements of PHS systems, and to lay out an objective evaluation methodology for their implementation. Although these efforts are important, the health informatics community must start a discussion on the higher-level architecture and conceptualization of PHS systems, informed by public health practice.
From the designer's perspective, it is difficult to conceptualize and implement an ideal PHS system that can measurably, significantly, and effectively improve the situational awareness and performance of public health practitioners. Our understanding of how the situational awareness develops and is communicated among different groups of experts in a typical public health setting is extremely limited. We do not know how experts distinguish and attend to important elements among diverse information sources. We do not know how this information is synthesized into a coherent bird's eye (holistic) view of the situation and its dynamics. We do not know the composition of this holistic view, its salient features, and its representation. We do not know how this mental image is used to project the future states of the dynamic environment or to explain past events, a factor which is significant for signal characterization. Finally, we do not know how all of this information is used by domain experts to select appropriate courses of action or make decisions. It is little wonder that the current state of the design and implementation of information systems for PHS is less than satisfactory as it lacks the orientation that may lead to greater situational awareness.
Next generation PHS systems should be driven by epidemiological models that capture contextual information, as well as organizational mission and tasks, so that system behavior is a direct and traceable function of the epidemiological models, input data, and a well-studied system of information interpretation. The systems should adapt dynamically to changes in the environment, users, and the problems at hand. They should interoperate seamlessly with collaborators online. They should enable the multidisciplinary repurposing of data and a mutually interactive environment where systems and users learn from each other, promote their understanding of the information, and select the right set of actions according to the results of user interaction.
Systems Architecture: A Distributed and Collaborative Design
An ideal PHS infrastructure should be pervasively available and customizable to suit the requirements of specific incidents as they happen. This structure would consist of interoperable systems that can function regardless of their hardware (PC, tablet, handheld, etc.), software (operating system, browser, etc.), or network (LAN, WAN, Internet). To achieve such an infrastructure, designers must consider the systems design frameworks that support distributed, dynamic, and collaborative operations. We propose that service-oriented architecture (SOA), if combined with more sophisticated technologies from information and knowledge representation technologies, is a sufficiently mature framework to support the conceptualization of large-scale PHS networks at local, regional, and national levels.
SOA is a framework to define and use loosely coupled software services to support the requirements of business processes and users. 68 A service in this framework consists of a system function that is well defined, self-contained, and whose functionality does not depend on the context or state of other services. An information system built on SOA makes use of resources on a collaborative network of such services, each of which can be accessed without knowledge of their underlying platform. Theoretically, SOA is agnostic to any specific-service implementation technology and may be comprised of a wide variety of interoperability solutions and standards, such as Remote Procedure Call, Distributed Common Object Model, Common Object Request Brokerage Architecture, Web Services Description Language, and Semantic Web Web Services.
Note that SOA is not equivalent to Web services. 69 Rather, SOA is a design principle—a framework—whereas Web services are technology specifications for an XML-centric realization of SOA. 68 Web services use a body of Internet standards and methods to be deployed, advertised, discovered, and invoked ad hoc and on demand on the Web. 69 A typical SOA application is one whose components are distributed on the Web and whose functionality materializes by invoking services from remote locations. A service can therefore participate in multiple distinct SOA applications and can support different use cases simultaneously.
SOA is a flexible, adaptive, and customizable system architecture that allows for the reuse of existing components to solve novel problems. We can think of services as building blocks, similar to Lego pieces, which can be loosely coupled together or rearranged ad hoc to create novel, customizable information systems on the Internet. SOA enables the creation of a distributed information system where services can be implemented by various organizations and reused by collaborators at remote locations throughout the Web, regardless of the disparity among hardware, software, and network platforms among participants, thus enabling true interoperability.
Service reuse in the context of public health information systems enables best practices in areas such as NLP; disease classification; and signal, cluster, and aberration detection algorithms; visualization; business intelligence; and data mining; to be shared among all participants immediately, effortlessly, and transparently as they become available or as they are enhanced, updated, and improved on the Web. Perhaps, the most important aspect of SOA is its adaptive and dynamic nature, where features of the system can be tailored to local needs without substantial effort and expenditure. The system can adapt to changes as an organic whole when the environment, users, or both changes.
The Figure 3 demonstrates a high-level and abstract architectural perspective that uses many of the concepts brought forward in this paper for conceptualization of next generation PHS systems with agility, dynamism, and interoperability in mind. The architecture is based on the triangulation of three modern system design concepts: (1) using goal-directed, user-centric task analysis techniques to identify and document the operational competencies of an optimal PHS system with their prerequisites, dependencies, and governing cultural, regulatory, and environmental constraints; (2) using knowledge engineering and modeling techniques to create formal models that describe the competencies in a computationally interpretable way (ontologies a ). Computational implications of each competency should be explicated in terms of the type of information it needs as inputs and outputs and interpretations and transformations that needs to take place to produce the outputs. Ontologies may contain all information that is required to configure and orchestrate services that can in effect implement and instantiate competencies; (3) using an array of services that are invoked on demand to implement a given competency using information provided by the ontologies (Fig. 3).
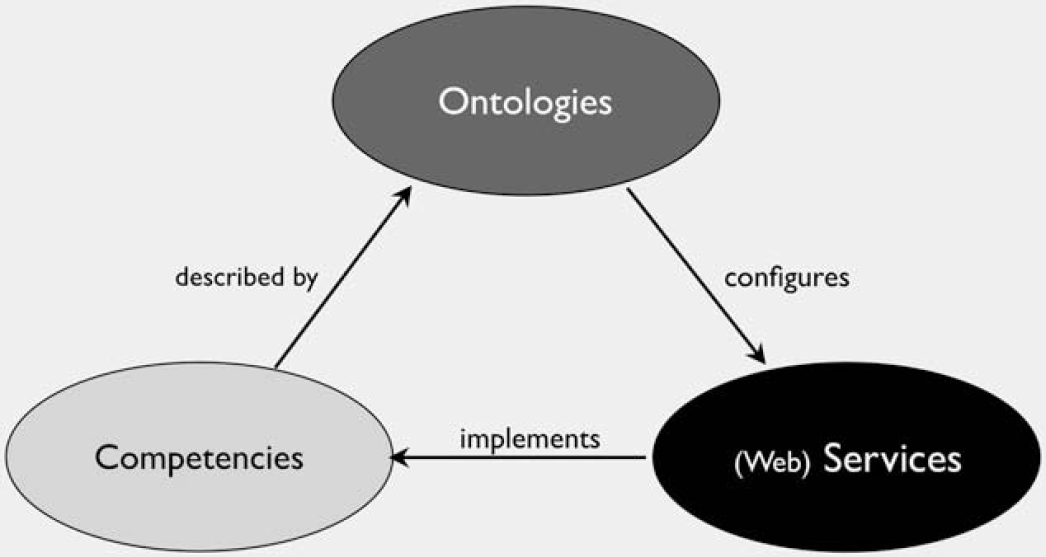
A high-level model for conceptualization of next generation public health surveillance systems.
This high-level architecture conceptualizes an iterative process where new competencies are described reusing and extending existing ontologies or by constructing new ones, and are implemented by reusing or extending existing services or by adding a new service to the portfolio of system services. This enables an integrated and organically growing architecture that maximizes utility of existing computational resources by capitalizing on reuse of existing models and services, and can scale up to meet future challenges by using technological frameworks that are designed for agility and dynamic evolution as well as interoperability and integration. It can also leverage Internet-based technologies such as Semantic Web and SOA for creating formal ontologies and asynchronous information integration on a heterogeneous environment that is distributed in time and space. This enables envisioning of a distributed and collaborative consortium, where participants contribute their share of information with ontologies that describe them and services to access and interpret them to the consortium and benefit from using and customizing information, ontologies, and services that are shared within the consortium.
The high-level system architecture proposed in this model does not make any assumptions on the underlying lines of technology and tools or the design and implementation roadmaps to instantiate such a system. However, it highlights and advocates for the three main enabling processes of such undertaking: (1) goal-oriented and user-centric task analysis, (2) ontological (formal and explicit) representation of all computational resources; (3) Internet-based and platform independent services to implement all processes.
The research questions that need to be addressed when conceptualizing an architecture for PHS systems not only concern the selection and application of lines of technology and frameworks that can make such a vision feasible but also requires a thorough analysis of the short- and long-term costs, utility, and impact, including any implied process reengineering of PHS practice itself.
Next generation PHS systems will require functionalities beyond the simple data-driven information-processing model currently in place. This points to several avenues of research in information integration, information sharing, and communication; information representation and visualization; knowledge engineering and knowledge representation; context modeling and representation; computer reasoning; and HCI. The complexities of the system design highlight some key research and developments necessary to set the stage for practical implementation of such systems:
Innovative architecture—The current public health information infrastructure is built on platforms adopted from traditional data mining and data warehousing approaches. Research is needed to develop flexible, robust, and scalable technologies that specifically address PHS problems and to provide access to information sources not currently available either electronically or in real time. What is needed is a fresh architectural overview that offers unique perspectives, principles, and procedures rooted in the theory of distributed cognition at multiple levels of analysis 13 to enable a robust, multidisciplinary and distributed health information system for public health.
A technology refresh process—PHS needs an active research and development infrastructure to seek the latest technologies, methodologies, and advancements in the field, and to communicate shortcomings and hurdles with researchers and technology providers. Appropriate licensing and partnerships between technology providers and academic research organizations would enhance the introduction of the latest technologies in real operational settings. On the other hand, academic prototypes usually fail to scale up to large, mission critical systems. 13 Methodological approaches are needed to turn the development of intellectual properties and technology prototypes from an art into an engineering discipline and enable the full transition of best-of-breed technologies to operational environments.
Academic—private partnerships—A partnership model that includes private technology providers, academic researchers, public health practitioners, and decision makers in a joint collaboration environment to support the conceptualization, evaluation, and implementation of next generation public health systems with innovative architecture and a technology refresh process.
Conclusion
As is often the case in technology, the introduction of new surveillance systems to the workflow of public health practice has not considered the need for the study of higher-level cognitive, psychosocial, and methodological concepts. Most information systems have been designed to streamline the collection and integration of information. The underlying belief is that improving access to information will directly and proportionately increase the quality and performance of the public health infrastructure.
However, meeting the grand vision of frameworks such as PHIN and the current trends in translational research requires more than the development of systems to collect and communicate information. It requires the development of a culture, and an infrastructure, that enables the meaningful integration of knowledge and information across organizations to support the just-in-time interpretation, sharing, and communication of information collaboratively and in a distributed environment.
We strongly recommend the analysis of the entire public health domain from a high-level conceptual perspective and in light of the four enabling principles iterated here to inform the design of desirable solutions. An extensive and explicit goal-directed task analysis for the entirety of the domain may be required to prioritize the tasks and subtasks and their informational needs in the context of public health practice. Such objective task analyses can serve as a road map for the design and implementation of information systems and lay out a framework for the evaluation of technologies that come with big claims about their capabilities.
Acknowledgments
This research is supported by the “Texas Training and Technology for Trauma and Terrorism—T5” program, funded through the Telemedicine & Advanced Technology Research Center—USAMRC, Ft. Detrick. We would like to acknowledge the contribution and support provided by the University of Texas Health Science Center at Houston, Office of Biotechnology and School of Health Information Sciences, The Center for Biosecurity and Public Health Informatics Research.
Footnotes
aOntology: Ontology is a formal (computer interpretable) and explicit (unambiguous and precise) specification of a domain. Ontologies are computational models that define concepts, and describe their relationships with each other and with objects in real world that they represent. Ontologies are used to establish a consensus between human experts and machines on how to interpret and interact with heterogeneous and multisource information.