
Abstract
Behaviour and the individual person are important but widely neglected topics of personality psychology. We argue that new technologies to collect and new methods to analyse Big (Behavioural) Data have the potential to bring back both more behaviour and the individual person into personality science. The call for studying the individual person in the history of personality science, the related idiographic/nomothetic divide, as well as attempts to reconcile these two approaches are briefly reviewed. Furthermore, different meanings of the term idiographic and some unique selling points that emphasize the importance of idiographic research are highlighted. A nonexhaustive literature review shows that a wealth of behaviours are considered in extant personality studies using such Big Data but only in a nomothetic way. Against this background, we demonstrate the potential of Big Data collection and analysis with regard to four idiographic research topics: (i) unique manifestations of common traits and the resurgence of personal dispositions, (ii) idiographic prediction, (iii) intraindividual consistency versus variability of behaviour and (iv) intraindividual personality trait change through intervention. Methodological, ethical and legal pitfalls of doing Big Data research with individual persons as well as potential countermeasures are considered.
During the last two decades, it was criticized that ‘real’ behaviour was only scarcely considered in studies of personality, individual differences and social–psychological phenomena (Baumeister, Vohs, & Funder, 2007; Funder, 2001; Furr, 2009). This neglect is mostly explained by the fact that direct behavioural observation is time–consuming and costly (e.g. Back & Egloff, 2009). Furr (2009) has determined the percentage of papers (studies) published in the years 1997, 2002 and 2007 in the odd–numbered issues of the Personality Processes and Individual Differences section of the Journal of Personality and Social Psychology (JPSP) and all issues of the Journal of Personality (JP) that claim or imply behaviour in the title or abstract. In total, 17.3% of 173 papers (19.1% of 356 studies) claimed or implied that behaviour would be studied. We have repeated this analysis for the years 2008, 2012 and 2019 of the JPSP and JP and found that a total of 26.5% of the 257 papers and 14.0% of the 485 studies claimed or implied behaviour would be studied. Thus, although the percentage of papers including behaviour has increased in the last decade by approximately one third, the respective percentage of studies including behaviour has decreased by around a quarter.
Apart from the relative lack of considering behaviour, there is still another research desideratum in personality science: the study of the individual person that is reflected in the idiographic/nomothetic dichotomy in psychology in general. The terms idiographic and nomothetic were introduced by the German philosopher Wilhelm Windelband (1904) to differentiate the methodological approaches of the natural sciences and the humanities (especially historical science) that he both conceived of as empirical sciences. The natural sciences search for general laws that are always true (nomothetic), whereas the humanities describe unique events and phenomena (idiographic). According to Windelband (1904), the special characteristic of psychology is that this science belongs to the humanities, and even is the basis of all other humanities that follow an idiographic approach, but itself aims at general laws and thus is methodologically a natural science (natural science of the inner sense). Although Windelband (1904) did not restrict the idiographic approach to the study of individual persons, the call for a careful analysis of the individual person as an alternative to the analysis of aggregates was echoed throughout the history of personality psychology (Allport, 1937; Beck, 1953; Beck & Jackson, 2020a; Carlson, 1971; Lamiell, 1981; Magnusson, 2001; Shoda, Mischel, & Wright, 1994; Stern, 1911), and there are indeed idiographic studies in personality science that are but low in number compared with the vast amount of nomothetic research (e.g. Allport, 1965; Beck & Jackson, 2020a; Cervone, Mercurio, & Lilley, 2020; Grice, 2004; Hermans, 1988; Karch, Sander, von Oertzen, Brandmaier, & Werkle–Bergner, 2015; Nasby & Read, 1997; Pelham, 1993; Schmitz & Skinner, 1993; Shoda et al., 1994; Simonton, 1998).
In fact, the study of the individual person is a constituting element of personality science. There is a vast consensus that a central aim of personality psychology is the study of the individual person, that is the intraindividual organization of structures and processes (e.g. Allport, 1937; Lamiell, 1981; Laux & Weber, 1987; Mayer, 2005; McAdams & Pals, 2006; Mischel & Shoda, 1995; Stern, 1911), and there is also consensus that research on this intraindividual organization is missing (Amelang, 2005; Carlson, 1971; McAdams & Pals, 2006). In 1900, William Stern termed individuality as the problem of 20th century, and in the same vein, Allport (1937) pointed out that ‘the outstanding characteristic of man is his individuality’ (p. 3). In addition, Kluckhohn and Murray's (1949) famous dictum that every man is in certain respects like all other men, like some other men, and like no other man reminds us that the uniqueness of the individual person (like no other man) is an important part of personality research.
At the same time, attempts to reconcile the idiographic/nomothetic divide had been proposed from the very beginning (Allport, 1961; Bem, 1983; Falk, 1956; Grice, 2004; Hermans, 1988; Krauss, 2008; Lamiell, 1981; Magnusson, 2012) and recently also with regard to statistical procedures (GIMME = group iterative multiple model estimation; Gates & Molenaar, 2012; Beltz, Wright, Sprague, & Molenaar, 2016; Wright et al., 2019). The possibility to reconcile and integrate idiographic and nomothetic approaches in personality science is also implied in the last two of three different meanings of the term idiographic Krauss (2008) identified based on a review of self–declared idiographic research in the literature: the first meaning of the term idiographic relates to approaches that aim at describing the uniqueness of a single person while denying general laws. The second meaning refers to the idea that general laws or principles manifest in unique ways in the individual person, and the third meaning concerns intraindividual or longitudinal research that examines a single person or a group of persons over time. We will illustrate these three meanings in more detail in the following paragraphs on the potential of Big Data for an idiographic personality science.
The fact that aggregates over persons within samples, or populations are much more frequently the object of psychological studies compared with the individual person, may be perceived as surprising by people outside academia because the public in general has a keen and legitimate interest for the reasons of certain behaviours of individuals (e.g. Donald Trump; McAdams, 2016). In addition, in many applied settings, especially in the context of counselling, coaching and psychotherapy, individual persons and not aggregates over multiple persons are much more often the subjects of psychology. Furthermore, there are indeed some more academic unique selling points that emphasize the importance of considering and analysing the individual person especially in personality psychology: (i) results from nomothetic studies can only be transferred to single persons under the very strict conditions of ergodicity that are almost never met in the vast majority of psychological research (Molenaar, 2004; Molenaar & Campbell, 2009). (ii) Idiographic approaches are better able to examine the effects of context and time. We will substantiate this claim in the paragraph on intraindividual consistency and variability of behaviour below. (iii) Although nomothetic studies show that certain behaviours are differentially related, for example to explicit or implicit anxiety (Egloff & Schmukle, 2002) or shyness (Asendorpf, Banse, & Mücke, 2002), there is evidence that one and the same behaviour does have a different indicative meaning for different individuals (Asendorpf, 1988). This point is also important when it comes to personality change through intervention.
Against this background, we argue that new technologies to collect and new methods to analyse Big Data have the potential to bring back both more behaviour and the individual person into personality science. According to DeMauro et al. (2015, p. 103), ‘Big Data is the Information asset characterized by such a High Volume, Velocity and Variety to require specific Technology and Analytical Methods for its transformation into Value.’ Volume, that is the magnitude or sheer size, is the most important and sometimes the only characteristic that is explicitly or implicitly used to define Big Data. Velocity describes the speed with which analogue phenomena of interest are digitized and made available for further analysis and action. Variety, that is heterogeneity or diversity of data modalities or sources, is the third characteristic of Big Data. In addition, the preliminary consensual definition introduced by DeMauro et al. (2015) highlights the fact that Big Data itself are worthless unless they are transformed into value by technology and analytical methods regarding a (research) question or decision making. According to Gandomi and Haider (2015), there are no universal benchmarks, neither for volume, nor for velocity and variety. Whenever new and interdisciplinary concepts are introduced, it is not unusual that different explications and definitions are proposed, leading to more or less ambiguity and vagueness. This is also true for the concept of Big Data. The different aspects and meanings of Big Data—Cartledge (2016) for example has identified 19 (!) Vs that were proposed by different authors in order to define the characteristics of Big Data—and also the speed of technological developments prevent a one–for–all–time definition of Big Data but reveal the complexity of this contested concept. Thus, the Big Data concept is likely to be differentiated in the future. For example, ‘Big Social Data’ as one kind of Big Data (Olshannikova, Olsson, Huhtamäki, & Kärkkäinen, 2017, p. 11) and also the terms ‘Big Psychological Data’ or ‘psychological Big Data’ (Obschonka, 2017) are already occasionally used (e.g. Williamson, 2017).
In a nonexhaustive literature review that is available as Supporting Information, we show which kind of behaviours have been considered in personality studies using Big Data up to now. In fact, a wealth of different behaviours is comprised in extant studies, albeit with a very different coverage of verbal and nonverbal behaviours and an over–reliance on Big Data that refer to written language. We point to the possibility to assess other kinds of micro (non–verbal and paraverbal behaviours like mimic, gestures and pitch of the voice) and macro (e.g. hearing music, doing sports and working) behaviours using new technologies already applied in studies outside personality science. Furthermore, the studies in our review applied Big Data in a nomothetic framework only.
In the remainder of this contribution, we demonstrate the potential of Big Data collection and analysis for an idiographic and behavioural personality science. In doing so, we contribute to the field in six important ways:
We argue that Big Data may revive Allport's concept of personal dispositions, that is unique traits or characteristics that only apply to a single individual. With regard to prediction, we encourage the utilization of Big Data in Personality Science to (i) establish predictive models at the level of the individual (idiographic prediction), (ii) compare whether nomothetic or idiographic prediction models are more accurate and (iii) test whether predictions of theories also hold true for the individual level. Extending Wilt's and Revelle's (2015) ABCDs of personality by an E for environment (=situation), we provide a new model for analysing consistency and variability using Big Data in a transactional framework that assumes dynamic interactions between situational or context features (E), cognitive, emotional and motivational or ACD states and macro or micro behavioural states (B). In this model, personality (traits) are conceptualized as more or less stable contextualized patterns of cognitive, emotional, motivational and behavioural states that evolve as attractors or idiodynamic figures over time. In terms of data modalities, we propose a pure idiographic version of Cattell's (1952) covariation chart that combines profiles of ABCD–states, several situational, contextual or environmental features (=E), and measurement points over time that refer to specific ABCDE–patterns for an individual person. With regard to the emerging field of personality trait change through intervention, we recommend utilizing the benefits of personalizing interventions using Big Data as already done in other fields like medicine, health and clinical psychology. Finally, we sensitize readers to methodological, ethical and legal pitfalls of doing Big Data research with individual persons and recommend respective countermeasures.
How Can Big Data Fuel an Idiographic Personality Science?
The definition introduced by DeMauro et al. (2015) highlights the fact that Big Data itself are worthless unless they are transformed into value by technology and analytical methods. Thus, which value may Big Data have for personality science? Apart from predicting personality traits from digital footprints (e.g. Facebook likes; Kosinski, Bachrach, Kohli, Stillwell, & Graepel, 2014), Big Data may advance our understanding of trait content, foster the understanding of personality development by identifying and distinguishing age–general and age–specific indicators of personality traits, and help to identify culture–specific and culture–free personality markers (Bleidorn, Hopwood, & Wright, 2017). These three ‘values’ for personality science are examples of how Big Data may be used in a broad construct validation framework to advance personality assessment and theory (Bleidorn & Hopwood, 2019). We argue that the scientific value of Big (Behavioural) Data also lies in the possibility to bring back the individual person into personality psychology and to foster the integration of idiographic and nomothetic approaches in personality science (e.g. Baumert et al., 2017). A revival of idiographic perspectives based on Big Data technologies and analyses is also predicted in a very recent paper (Matthews et al., in press). Our contribution elaborates this prediction with regard to the idiographic/nomothetic dichotomy, the assessment of different kinds of behaviour using new technologies and the above–mentioned four research questions. As already highlighted in the first section, idiographic approaches aim at the whole person in terms of the complex intraindividual organization, patterning or interaction of many variables (structures and processes) in constant interaction with the environment, that is across situations and time (Allport, 1961; Beck, 1953; Falk, 1956; Magnusson, 1992, 2012). In order to achieve this aim, a whole lot of various data regarding (an) individual person(s) and also adequate methods of data analysis are necessary. Besides value, high volume and variety as the two other characteristics of Big Data can provide this kind of intensive information. Variety, that is heterogeneity or diversity of data modalities may, for example (Wenzel & van Quaquebeke, 2018, p. 12) refer to space (e.g. location, proximity, acceleration and three–dimensional orientation), time (e.g. date, time, weekday and milliseconds), physiology (e.g. body temperature, pulse, blood pressure, respiration, oxygen level and electrodermal activity), kinetics (e.g. touch, gestures, posture and step count), expression (e.g. speech, gaze and mimicry), ambience (e.g. light, sound, temperature, precipitation, humidity, wind, barometric pressure, sunshine, UV radiation and pollution) and data about data (e.g. information on data object features and relations). Regarding assessment, Big Data are mainly driven by the following three technological progresses, opening up exciting new research avenues with a great potential for an idiographic behavioural personality science: social media, mobile sensing and video technology. These developments offer new possibilities for experience sampling methods (ESMs) that are suitable for implementing an idiographic approach, and contribute to identifying patterns of behaviour within an individual over time and within contexts (Conner, Tennen, Fleeson, & Barrett, 2009). In addition, Ihsan and Furnham (2018) expect the Internet of Things to lead to increased amounts of data gathered from individuals or households (Atzori, Iera, & Morabito, 2014). As many as 50 billion items are expected to be connected to the Internet of Things by 2020, making it a challenging task to process, mine and analyse this large amount of data (Mahendra, Kishore, & Prathima, 2019).
Importantly, such high volume and highly various data collected longitudinally and across different situations may be used for hypothesis testing with enough statistical power at the level of the individual person and also to move beyond the single individual by the possibility to determine similar patterns for groups of persons (Hofmans, De Clercq, Kuppens, Verbeke, & Widiger, 2019 for this reasoning regarding ambulatory assessment). In the remainder of this contribution, we will demonstrate the potential of Big (Behavioural) Data studies with regard to four idiographic research topics: (i) unique manifestation of common traits and the resurgence of personal dispositions, (ii) idiographic prediction, (iii) intraindividual consistency versus variability of personality and (iv) intraindividual personality trait change through intervention.
The first two topics may pertain to the first or second type of idiographic research as identified by Krauss (2008) depending on the set of descriptors (common or unique set), and the theoretical rationale (general principles that apply to all individuals), whereas the third and fourth topics are idiographic in the sense of intraindividual research that may also use general principles as a starting point. The questions associated with these four research topics are often addressed separately in extant research but may also be combined in one and the same study.
Unique manifestations of common traits and the resurgence of personal dispositions
In discussing how Big Data can advance personality theory, Bleidorn et al. (2017, p. 81) have asked the question: ‘When different (trait) indicators are needed across two cultures, does this mean that the same latent traits are expressed differently, or that personality fundamentally differs across cultures?’ In our view, it could also advance personality theory if this question is asked in an idiographic way by replacing ‘cultures’ by ‘individuals’. Thus, we would ask whether the need for different trait indicators across two individuals means that the same latent traits are expressed differently across individuals. This would be an idiographic study of single persons in terms of what Krauss (2008) calls unique manifestation research that conceptualizes idiographic as the unique manifestation of general principles in the individual person. In this kind of idiographic approach, the integration of the general (nomothetic) and the unique (idiographic) is most obvious. Unique manifestation with regard to broad traits like the Big Five may then be determined in terms of a unique profile at the facet level: one and the same score, for example for extraversion, may result from different scores at the facet level that may again manifest in different behaviours. Furthermore, the facets of the Big Five dimensions may show different relations at the level of the individual person (Beck & Jackson, 2020a), for example assertiveness (an E facet) may be related with competence (a C facet) for one person, but not for another person where assertiveness may for example be associated with altruism.
We can go one step further by reviving Allport's (1937) concept of personal dispositions using Big Data (see also Beck and Jackson, 2020b for a similar suggestion, but without reference to Big Data). In doing so, we would apply the term idiography as assuming uniqueness and denying general laws (Krauss, 2008), because personal dispositions are conceived of as unique traits or characteristics that only apply to a single individual (Allport, 1937). It is also possible that some common traits emerge or are applicable for all persons, and some additional traits that are unique for only one individual. This possibility would resemble what was found in the course of the development of the Chinese Personality Assessment Inventory (Cheung et al., 1996). Using the lexical approach, traits unique to the Chinese culture like Harmony, Ren Qin (Relationship) Orientation, Face and Thrift Extravagance emerged in addition to common traits like Emotionality and Introversion–Extraversion. In fact, Grice (2004) has already shown that personal constructs idiographically assessed with the Repertory Grid only partly match with the Big Five dimensions. According to Grice (2004), individuals move far beyond the Big Five if they are allowed to describe themselves in an unrestricted way. It also turned out that discrepancies between the real and ideal ratings on unique personal constructs predicted emotionality better than discrepancies on common personality–related adjectives (Watson & Watts, 2001). Given the large amount of narrative accounts (written language) on social media (or other sources like daily diaries) that is only analysed at the group level in extant studies (Supporting Information), the lexical approach could also be used to extract common traits and more or less unique personal dispositions at the level of the individual person.
Because the person must not be equated with a narrative (Renner, 2010) and because idiographic approaches aim to describe the whole person in terms of the complex intraindividual organization or patterning of many variables (structures and processes) in constant interaction with the environment, another approach to tackle the general and the unique in personality science would demand assessing and analysing what we term ABCDE patterns in the next but one paragraph in which we also provide examples of such patterns. ABCDE patterns extend the ABCDs of personality (Affect, Behaviour, Cognition and Desire; Wilt & Revelle, 2015) by environmental conditions. These ABCDEs may be longitudinally assessed with new technologies like ESM, mobile sensing, google glass and the Internet at the level of individual persons. This would be an example of the third type of idiographic research in terms of intraindividual variation or change across situations and/or time as identified by Krauss (2008). All kind of micro and macro behaviours could be considered, not only written language. Again, common patterns that are applicable for certain groups or even all persons, and additional patterns that are unique for only one individual, may emerge using this ABCDE–framework. Such a Big Data approach to individual persons in their natural habitats would also revive and extend Barker and Wright's (1951) ecological approach that aimed at describing the stream of behaviours of children in their everyday lives as detailed as possible by trained human observers. In their book One boy's day, Barker and Wright (1951) meticulously describe on 435 pages every word and movement of a 7–year–old boy in a mid–western town of the United States for a time span of 14 hours. Because the observers ‘only’ registered the behaviours of the children, affects, cognitions and desires that could be assessed via ESM (and in part also biological indicators) would extend this approach.
Idiographic prediction of behaviour
The prediction of consequential outcomes is an important, probably the most important challenge of personality science (Cattell, 1965). For example, using the Five–Factor–Model as a framework, Ozer and Benet–Martinez (2006) have reviewed the predictive validity of personality traits regarding such outcomes as happiness, physical and psychological health, quality of relationships, occupational choice, performance and criminal activity. A lot of Big Data studies in personality psychology predict personality traits and other personal characteristics like age, gender or political and sexual orientation that were assessed with traditional self–report questionnaires by patterns of Facebook likes (e.g. Kosinski, Stillwell, & Graepel, 2013, Supporting Information). In these studies, the Facebook likes—iconic behaviour according to our definition (Supporting Information)—were used to predict personal attributes of for example 58,466 participants in Kosinski et al.'s (2013) study. Strictly speaking, it is not a prediction to correlate already existing, manifest and partly organismic variables with iconic behaviour that was extracted and registered long after these variables have been developed. It would, however, also be possible to establish a real predictive design by using personal attributes like age, gender, sexual orientation and also personality traits to predict Facebook Likes, for example using multidimensional regression techniques (e.g. support vector regression; Smola & Schölkopf, 2004). Such a predictive design was realized in the study by Matz, Kosinski, Nave, and Stillwell (2017), in which advertisements targeted at high or low extraversion of Facebook users predicted clicks and conversions.
The studies reviewed by Ozer and Benet–Martinez (2006), and most of the Big Data studies, are based on a nomothetic approach, that is between–person or variable–centred predictions (e.g. high Extraversion predicts more clicks and conversions regarding specifically targeted ads or better health). According to Runyan (1983), ‘Idiographic prediction may be defined as prediction made about a case based on data from that particular case and no other cases.’ (p. 429). When it comes to this kind of purely idiographic prediction of behaviour, longitudinal and contextualized cognitive, emotional, motivational and behavioural data assessed by smartphone–based mobile sensing methods and/or collected on the internet are available, for example for training machine learning algorithms. Using the new possibilities of Big Data assessment and analysis, it is now possible to establish idiographic models that predict such important outcomes at the level of the individual. Big Behavioural Data may be used as predictors and/or outcomes in these idiographic prediction models. For example, in a study by Cheung et al. (2017), physical activity and exercise behaviours were predicted as outcomes by ecological momentary assessments of subjective stress states, expected stress, exercise behaviour for the day, exercise behaviour on previous days and external as well as environmental variables including temperature, daylight time, precipitation and day of week. They used random forests and classification trees for data analyses (Cheung et al., 2017). Exercise behaviour that can be unobtrusively assessed using accelerometer data provided by for example Fitbit wristbands or ‘talking to others’ (as an indicator of extraversion) may also be used as predictors of outcomes like well–being. In the study by Cheung et al. (2017), it turned out that the idiographic prediction models were more accurate than a nomothetic prediction model (also established using the same machine learning algorithms). Similar procedures have already been applied in preventive medicine to idiographically predict drug use (Boyer et al., 2012), and also in Clinical and Health Psychology for the idiographic prediction of smoking behaviour (Fisher & Soyster, under review). Lindquist et al. (2017) demonstrated that machine learning algorithms are also applicable for the idiographic prediction of pain reports from functional magnetic resonance imaging brain activity data.
Idiographic prediction can also be used to test whether theories that are usually validated within a nomothetic framework also apply at the level of the single person. Hobbs, Dixon, Johnston and Howie (2013) tested whether the theory of planned behaviour (Ajzen, 1991) can predict walking, gym workout and a personally defined physical activity in six individuals. It turned out that the TBP variables showed different predictive validity at the individual level and across behaviours: at least one physical activity behaviour was predicted by time series analyses for five participants, but none for one participant (Hobbs et al., 2013). Thus, Big (Behavioural) Data and Machine Learning algorithms can be used to (i) establish predictive models at the level of the individual (idiographic prediction), (ii) compare whether nomothetic or idiographic prediction models are more accurate and (iii) whether predictions of theories are also valid on the individual level. If the behaviour of different individuals is differentially predicted by different configurations or patterns of variables (ABCDEs in our framework), then the question arises whether similar predictive patterns may be assigned to clusters that indicate groups of persons that ‘function’ in similar ways (Schmitz & Skinner, 1993). The studies described above are examples of idiographic research in terms of unique manifestation research because the same variables or theoretical derived constructs were assessed for each individual but it would also be possible to identify unique predictors that only apply to a single individual.
Furthermore, the exemplary studies described and cited in the previous paragraphs applied different analytic strategies for idiographic prediction: random forests and classification trees (Cheung et al., 2017), elastic net regularization and naïve Bayes classification (Fisher & Soyster, under review), group–regularized individual prediction, shrinkage estimators, empirical Bayes approach (Lindquist et al., 2017) and time series analyses (Hobbs et al., 2013). These methods that were mostly developed for Big Data may be used for both nomothetic and for idiographic data analyses. Furthermore, a wide variety of machine learning methods (from the data mining field) is available to analyse single–person data and to describe idiographic models. Such idiographic data analysis methods are already extensively used in neuroscience (e.g. Garrett, Epp, Perry, & Lindenberger, 2018), in particular in brain–computer interfaces (Lotte et al., 2018), cognitive domains (Karch et al., 2015), sleep research (Wrzus et al., 2012), in political sciences (Meyer et al., 2019) and many other areas of or related to psychology. These methods are usually separated in supervised and unsupervised techniques (e.g. Bishop, 2006).
Supervised algorithms start with a set of data vectors that are correctly labelled in several, usually two, categories and identify patterns in the data that allow the algorithm to correctly classify new vectors. Such techniques are particularly helpful to automatically label data (e.g. movement data, to identify which type of movement the participant did at any specific time) but also to identify differences between groups in the prelabelled data (Kim & Von Oertzen, 2017). For example, in the analysis of a specific person, a researcher might be interested whether this person displays different behaviours when in the presence of female participants than with male participants. A classifier (e.g. support vector machines and decision forests) may then be trained using ‘male context’ or ‘female context’ as target classes. If the classifier based on the behavioural data statistically outperforms simple guessing of the gender, then, the participant acts differently under both contexts.
Unsupervised algorithms typically also cluster a set of data vectors into one of several classes; however, no initial training set with correct labels is provided for those algorithms. Again, such methods can be very helpful at different stages of the analysis process for Big Data. Within one person, sometimes specific labels are not present. For example, assume a researcher investigates specific personality–related items on a traffic plane pilot during a long–distance flight. Depending on situational contexts, or experience of the pilot, different patterns of states for these items may occur, even though the contexts themselves are either not available to the research (e.g. whether the flight situation is standard or the radar picks up another plane dangerously close) or not even objective to begin with (e.g. if the pilot has a vague gut feeling that a problem may occur). Clustering algorithms may then help to identify these different periods, and potentially subsequent analyses may identify which clusters have lower or higher risks of mistakes by the pilot. In addition, clustering algorithms can be beneficial to bridge within–person and between–person analysis, for example by identifying subclusters or participants which are heterogeneous between each other, but homogeneous within a cluster. Clustering algorithms, which can be used to measure consistency of variability in the first place, can then also be used to remedy the situation and find a compromise between the two analysis foci. If Big Data can be separated into specific groups of participants which have low entropy, that is which are very consistent, it is then possible to describe these groups with classical between–person procedures.
Intraindividual consistency versus variability of behaviour
The consistency versus variability of cognitions, emotions, motivations and behaviour has been a pervasive topic and contentious issue in personality science (e.g. Beckmann & Wood, 2017). Related to this issue are the dichotomies of person versus situation and structure versus process approaches to personality. Following Mischel's (1968) book on personality and assessment several approaches and models have been suggested to reconcile this consistency versus variability issue. Mischel himself has introduced the idiographic concept of personality signatures, that is more or less stable if–then–situation–behaviour profiles (Mischel & Shoda, 2008; Shoda et al., 1994). Beck and Jackson (2020a) have recently argued that idiographic approaches provide both temporal and context–specific data on individual persons (through, e.g. ESMs) and are thus better able to examine if … then contingent patterns as proposed by Mischel and Shoda (1995) and idiosyncratic patterns of person–situation transactions. In a similar vein and already in 1958, Rosenzweig proposed the term Idiodynamics to highlight that the ‘… essential starting point in personality theory must be the unique interrelatedness of the individual universe of events, i.e. the idioverse, which conceptually embraces all the foregoing paradoxical disparities’ (p. 6).
The consistency versus variability of personality was tackled in studies using ESM that conceptualize traits as density distributions of states (Fleeson, 2001) or that applied the network perspective on personality dimensions (Cramer et al., 2012) to investigate idiographic personality development (Beck & Jackson, 2020a). ESMs, as used in these studies, usually consider self–reports regarding experiences and behaviours in daily life. Mobile sensing methods offer additional possibilities to unobtrusively assess many different behaviours (Harari, Müller, Aung, & Rentfrow, 2017), for example movement behaviours (physical activity and mobility patterns), social behaviours (face–to–face encounters and computer–mediated communications) and other daily activities (nonmediated and mediated activities, like playing computer games on the smartphone). As mentioned above, Big Data are characterized by volume, variety and velocity and thus capture behavioural records that are exceptionally numerous, highly heterogeneous and generated at high rate. Regarding heterogeneity, it is possible to simultaneously consider different kinds of longitudinal behavioural data via mobile sensing and from the Internet (e.g. language and iconic behaviour) for individual persons. Because personality is not only characterized by behaviours, additional nonbehavioural data that reflect cognition, motivation and emotions could be included. Robinson (2009) has argued that we do not always need behaviour to answer relevant questions in personality psychology, especially those questions that are related to cognition, emotion, motivation, the self–concept or trait–structure. ‘There is more to personality than behavior’, Robinson (2009, p. 428) points out and we indeed wholeheartedly agree that personality psychology should be an integrative science which, however, also means that behaviour needs to be considered and integrated in addition to cognition, emotion and motivation. There is less to personality without behaviour!
Different modalities of individual differences were nicely termed the ABCDs of personality (Affect, Behaviour, Cognition and Desire; Wilt & Revelle, 2015). Furthermore, it is also possible to assess information on situational features via mobile sensing or ESM. As already mentioned above, we may therefore continue the ABCD by an E for environment = situation. These partly unobtrusively collected ABCDE data thus reflect contextualized cognitive, emotional, motivational and behavioural states and thus a much richer and much more complex data set for analysing consistency and variability than ESM studies reported in the literature as yet.
Figure 1 integrates Big Data in a transactional framework that assumes dynamic interactions between (i) situational or context features (E), (ii) cognitive, emotional and motivational or ACD states and (iii) macro or micro behavioural states (B). Note that contrary to other models, like mechanistic or dynamical interactionism as well as reciprocal determinism (Bandura, 1978), personality (traits) is (are) not explicitly depicted in this model as a component by its own. Rather, based on the network or other systemic perspectives, personality (traits) are conceptualized as more or less stable contextualized patterns of cognitive, emotional, motivational and behavioural states that evolve as attractors or idiodynamic figures over time.
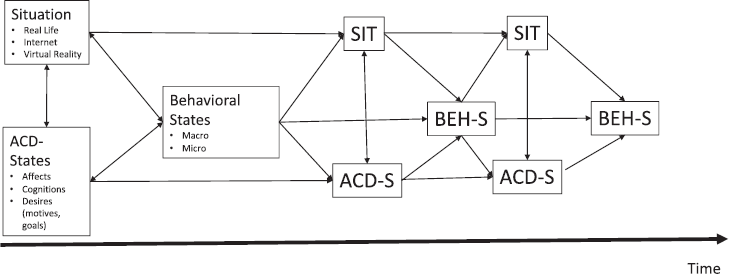
Big Data in a transactional framework.
In terms of the data modalities related to this framework, we propose a pure idiographic version of Cattell's (1952) covariation chart that combines profiles of ABCD–states, several situational, contextual or environmental features (=E) and measurement points over time that refer to specific ABCDE–patterns for an individual person (Figure 2).
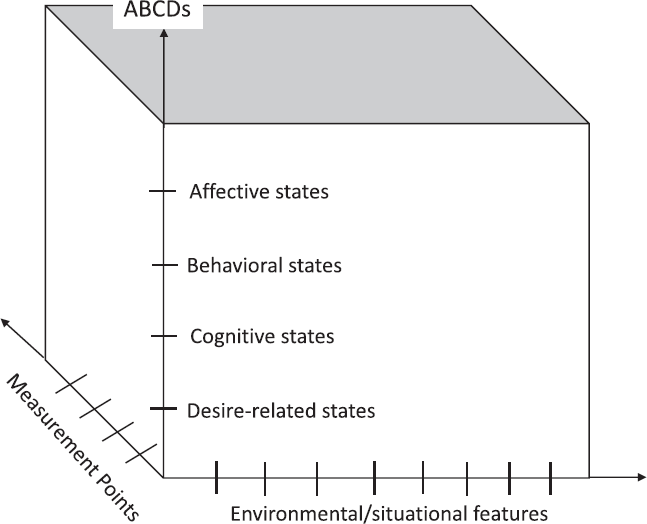
An idiographic contextualized version of Cattell's (1952) covariation chart.
Note that in Cattell's (1952) original covariation chart, three referents (as Cattell calls it) are crossed: circumstances (or occasions), persons and attributes. Situational or environmental features and measurement points are not explicitly separated in the circumstances/occasions referent by Cattell (1952) but rather merged: ‘… the circumstance (or “occasion”) referent is restricted to whatever in the situation varies from occasion to occasion’ (Cattell, 1952, p. 500). The two idiographic designs in Cattell's (1952) covariation chart either correlate attributes assessed over a series of occasions within one person (P–Technique) or the similarity of a test profile (several attributes) of one person on two occasions (O–Technique). Both designs are decontextualized because it is not determined whether the same or other environmental/situational features are present at the different occasions, that is measurement points. Furthermore, Cattell's (1952) covariation chart is primarily focused on traits, but not on states. Thus, Cattell's (1952) covariation chart does not consider the possibility of stability in variability, that is more or less stable ‘If … then situation/environment –ABCD patterns, meaning that different situations/environments X, Y and Z may be associated with different ABCD patterns (ABCDX, ABCDY, ABCDZ), that is the ABCD patterns are variable across different situations but this variability may be more or less stable over time (measurement points).
The five components in our idiographic covariation chart may differ in kind and in degree, that is different affects, behaviours, cognitions and desires (motives/goals) can occur with different intensities in different situations. Whereas affects, cognitions and desires are usually conceptualized and measured as continuous variables, situations and behaviours may also be included as categorial variables meaning that a certain situation/environment and also a given behaviour is present or not. It is, of course, also possible to measure certain attributes of an environment, for example temperature, and of a given behaviour, for example duration and/or number of words in a phone call as continuous variables. For the sake of simplicity, let us consider three different kinds of each component: anxiety, joy and sadness (affect); preparing a final exam, watching a TV series and talking with friends (macro behaviours); worrying, focusing on learning matters in thoughts and expecting being able to do what one wants to do (cognitions); need for achievement, need for affiliation and need for power (desires); working context (e.g. library), party context and ‘at home’ context (environments). Let us further assume that we are able to measure these affects, cognitions and desires as continuous variables and the situations and behaviours as categorial variables at about 500 measurement points using a combination of the assessment methods described above. In the three environmental contexts, one of the three different kinds of each A, C and D may occur in different degrees (from zero to high intensity) and also one of the three behaviours (present vs. not present). Theoretically, 15! permutations of the three kinds of the ABCDEs are possible across the different measurement points. In addition, even more possibilities emerge when we consider different intensities of the continuously measured affects, cognitions and desires over time. Empirically, we would expect that only a smaller number of the theoretically possible permutations or patterns will emerge and recur. For example, in the at home context, the pattern above average joy, watching TV series, high expectations regarding being able to do what one wants and zero needs for achievement and affiliation, but low need for power might occur at different measurement points. By contrast, medium–level anxiety and worry, preparing for a final exam and high need for achievement may be a recurring pattern in the library (working context). Furthermore, the pattern joy, talking with friends, high expectations, high need for affiliation and party context may occur at different points in time. Of course, other ABCD patterns are possible and also plausible in the three environmental contexts, for example ‘joy, preparing a final exam, focusing on learning matters, high need for achievement and working context’ or ‘sadness, talking with friends, worrying, need for power and party context’. What we are proposing here is an extension of Shoda et al.'s (1994) summer camp study, in which ‘only’ the varying intensity of aggressive behaviour was observed in five different environmental/situational contexts. Shoda et al. (1994) found that aggressive behaviour varies with the five contexts, but this variation can be more or less stable across different measurement points within an individual person (idiographic stability in variability). Our extension pertains to (i) more than one behaviour and (ii) the inclusion of ACDs. Similar to Shoda et al. (1994), we will most likely find that the intensity of different ABCDs varies with different contexts (E's) for an individual person. What we will probably also find is a more or less pronounced stability of this variability within an individual person. This is an empirical question and also a question of the appropriate mathematical model for this complex data constellation. In fact, any Big Data method can be applied to analyse such situations by using the situations as covariates. For example, assume we are interested in the dynamics between different ABCD–states in different situational contexts (E), for example during work, during a party and during relaxation at home. Second–order differential equation systems, which for example describe pendulums in physics, are well suited to describe the dynamic dependencies, oscillations and damping processes in the ABCD variables described above. A latent differential equations (LDEs) model can be used to estimate the parameters of the differential equation and thus describe the stability/variability of these variable patterns over time (Boker, Neale, & Rausch, 2004). Given our theoretical assumptions, the parameters of the system themselves are constant over time but are modelled to be varying between different situations. That is, the LDE parameter describing oscillation, damping and interaction of the ABCD variables is different between the party, work or home environment. To continue our example above, it may be a possible outcome of such an analysis that participants have stronger damping of anxiety when being at home compared with a situation in the library. That is, even though participants may experience some anxiety at home, say because of an upcoming exam, the environment allows them to calm down faster with the help of family members around or potential distractions. In contrast, the exclusive engagement in the learning context in the library may result in a reduced dampening of anxiety or, in the worst case, even an acceleration of anxiety. In a party context with high excitement one may find a third pattern in which the anxiety about the upcoming exam may oscillate from phases of very low levels to sudden outbursts of high anxiety. For such oscillatory data situations, von Oertzen and Boker (2010) showed that 1000 observations are already well suited to estimate parameters in second–order differential equations, and using time delayed embedding of the data, this number comes down to even 200 or less time points per participant. If the situation variables are continuous, for example a scale that expresses the weather condition during a walk, then these variables can be modelled to moderate the dynamic system parameters. The LDE is just one possible way to approach individual data with differential equations (for a great modern example, see Burger et al., 2020), and differential equations in turn are just one example of possible models. Despite the first–glance complexity of the data situation, it is possible to apply a lot of methods, depending on the data within each situational context, using the situations as grouping parameters. For example, one could as well consider different covariance structures over different situations in a hierarchical structural equation model or different classifier models in a classification analysis.
Intraindividual personality trait change through intervention
Throughout the history of psychology, personality and personality traits are typically defined as characteristic, enduring, consistent or relatively stable patterns of emotion, motivation, cognition and behaviour (Allport, 1962; DeYoung, 2015; Funder, 2001; Johnson, 1997; Mischel & Shoda, 1995). In the last two centuries, it was even believed that personality is set like plaster by age of 30 (Costa & McCrae, 1994; James, 1890). There is, however, clear evidence from longitudinal studies that personality traits do not only change in young adulthood (e.g. Neyer & Asendorpf, 2001), but also in middle (e.g. Hill, Turiano, Mroczek, & Roberts, 2012) and old age (e.g. Kandler, Kornadt, Hagemeyer, & Neyer, 2015). Furthermore, these changes are in a positive direction: people become more emotionally stable, agreeable and conscientious with age. These changes are, however, moderate and slow, that is they occur over years and decades (e.g. Roberts, Walton, & Viechtbauer, 2006). Because personality traits predict meaningful outcomes such as economic and relationship success, health and longevity, the question arises whether personality traits can be changed through interventions like psychotherapy, training and coaching. In a recent meta–analysis, Roberts et al. (2017) have shown that both clinical and nonclinical interventions lead to lasting personality trait changes especially with regard to emotional stability but also extraversion by 0.52 and 0.72 standard deviations. These intervention–based personality trait changes pertain to young, middle–aged and old populations as well. The authors concluded that personality traits can and do change more quickly than commonly thought. Similarly, it turned out that most people want to change their personality traits and are able to so with regard to their self–reported traits and trait–relevant daily behaviour through an intervention that instructed them how to generate corresponding implementation intentions (Hudson & Fraley, 2015).
Again, these results are solely based on nomothetic analyses and thus the average effect of these interventions at the group level. These average group level effects tell us only little about responses to interventions at the individual level (McDonald et al., 2017). The opportunities and possibilities of new technologies regarding mobile sensing for so–called ‘n–of–1’ intervention studies have already been acknowledged in medicine (e.g. Lillie et al., 2011), Health Psychology (McDonald et al., 2017) and Clinical Psychology (Burns et al., 2011). Since 2004, a journal called Personalized Medicine aims at promoting at personalizing interventions to each person's unique biology and to treat the individual causes rather than the symptoms of a disease (Flores, Glusman, Brogaard, Price, & Hood, 2013) and likewise a very recent review thoroughly argues for personalized models of psychopathology (Wright & Woods, 2020).
McDonald et al. (2017) point out that n–of–1 methods can aim to identify individual responses to interventions and also to personalize interventions to the individuals. Already in 1989, Ellgring has showcased the importance to consider the idiosyncratic meaning of behavioural indicators when it comes to changing behavioural response patterns through interventions. In his respective study (Ellgring, 1989), it turned out that an increase in subjective well–being of depressed patients at the end of a psychotherapy was associated with different change patterns of behavioural indicators for depression. Although smiling and gaze increased for most of the participants together with better well–being, speech activity and gestures were associated with increases in well–being for only a few patients. In sharp contrast to the hypotheses, such increases in subjective well–being were associated with decreases of specific behavioural indicators, for example smiling that should actually increase with increases in well–being, for these individuals (Ellgring, 1989). Again, such person–specific or idiosyncratic meanings of behaviour clearly require an idiographic research strategy. Furthermore, if unique predictors of an individual's behaviour are identified as shown in the section on idiographic prediction, a personalized intervention may be tailored which targets those predictors (McDonald, Araujo–Soares, & Sniehotta, 2016; O'Brien, Philpott–Morgan, & Dixon, 2016; Wright & Woods, 2020). Because most choices about health are made in everyday activities, real–time behavioural monitoring seems a powerful tool to observe and modify an individual patients’ behaviour (Asch, Muller, & Volpp, 2012; Dallery, Kurti, & Erb, 2014). For example, using ecological momentary assessment, behaviours associated with mood and anxiety disorders (Forbes et al., 2012) have been assessed. Sampling in a naturalistic environment and over long periods of time allows researchers and practitioners to investigate and monitor contextual and temporal behavioural variations and changes (Dallery et al., 2014). There are, indeed, a lot of studies that combined wearables (passive data collection) and active user input to capture antecedents of unhealthy behaviour (Ali et al., 2012; Crowley–Koch & Van Houten, 2013; Ertin et al., 2011; Kaplan & Stone, 2013; Kumar, Nilsen, Pavel, & Srivastava, 2013; Plarre et al., 2011).
These ideas were implemented in a study that aimed at treating major depressive disorder with Mobilyze!, a mobile phone–based and Internet–based intervention including ecological momentary intervention and context sensing (Burns et al., 2011). Contextual data were collected by 38 mobile phone sensors. Each of the eight participants was asked to self–report the following states five times per day on his or her mobile phone: overall mood, intensity of emotional states (e.g. happiness, sadness and anxiety), fatigue, pleasure, sense of accomplishment, concentration and engagement, and perceived control over current activities as well as physical exertion. In addition, each participant provided information on his or her location (e.g. at home, in the office and in a bus/train) as well as interactions and relationships with others. These self–reported data were sent to a backend server together with the data from the mobile phone sensors. Individualized prediction models were generated using regression trees and J48 classifiers, an adaption of c4.5 decision trees. For every state, these machine learning algorithms generated an individualized model to predict that state from sensed data in the future. Based on these idiographic predictions, each participant received a tailored and personalized intervention that consisted of the following components: (i) tailored feedback, that is sending messages to the phone to reinforce improvement whenever a participant's mood was above his or her typical range or suggesting a tool from the intervention website when a participant's mood was below his or her typical range. (ii) Personalized reminders in order to improve adherence to the suggested therapeutic activities as well as follow–up questions when a scheduled task was not completed. (iii) Individualized guidance how to overcome, for example lack of motivation to complete a task. (iv) Interactive graphical feedback tools on the intervention website that aimed at helping each participant to better understand how he or she spend their time and identify which behaviours he or she would like to do more or less. (v) Individualized emails from a human coach based on the mobile phone and website usage pattern. This personalized intervention led to significant improvements regarding self–reported depressive symptoms, and participants were less likely to meet criteria for major depressive disorder.
We would like to highlight that the personalized interventions tailored for the eight participants by the Mobilyze!–System are an example for an idiographic study of the unique manifestation type because the treatment model was based on the general principles of the behavioural activation (Addis & Martell, 2004) approach to reduce depression that is based on positive activities and the use of behavioural coping strategies whereas the concrete timing and feedback regarding these general intervention principles were personalized based on the prediction models determined with the Big Data for each individual participant. Thus, personalized interventions for individual persons may be informed by general principles that turned out to be true, that is effective on average for aggregates of patients suffering from major depressive disorder. Inversely, it is often assumed that the results of idiographic n–of–1 studies can provide working hypotheses that have to be tested in nomothetic studies (e.g. Falk, 1956). In fact, most clinical interventions are clearly based on intensive work with single cases that were later tested nomothetically in randomized controlled trials. As stated above, there are different levels of generalization according to Kluckhohn and Murray (1949) that are semi–independent (Runyan, 1983). On the one hand, this means that general (intervention) principles that are true for most/some individuals are not necessarily true for the individual person but can suggest hypotheses of what might work for the individual when it comes to changing depression or personality traits. On the other hand, a single case might afford unique and probably new kinds of treatment methods that have to be invented or developed for this single case and this new knowledge may turn out to be applicable for other future patients as well. Thus, it is possible and makes sense to move between these different levels of generalization and to integrate idiographic and nomothetic knowledge.
Similar personalized procedures based on idiographic prediction of ABCDE–patterns derived from mobile sensing and ESM data using machine learning algorithms would, of course, also be possible to investigate intraindividual personality trait change through intervention. The velocity feature of Big Data, that is the speed with which analogue phenomena of interest are digitized and made available for further analysis and action may be a decisive advantage for such interventions in order to automatically instruct a subject what he or she could do to become, for example more conscientious or to foster well–being.
Possible Pitfalls and Countermeasures in Big Data Research with Individual Persons
Psychometric and methodological issues and especially legal and ethical considerations are discussed in this last section. Big Data are sometimes termed a double–edged sword because, on the one hand, it has the potential to open up exciting new research avenues and help individual persons to lead a better and healthier life (e.g. 4P medicine). On the other hand, this more fine–grained and deeper knowledge, especially on within–individual patterns, may also be abused to manipulate persons (Matz et al., 2017) for economic and political reasons. Many other professions, and within the field of psychology especially industrial and organizational (I–O) psychologists (Guzzo, Fink, King, Tonidandel, & Landis, 2015; Whelan & DuVernet, 2015), have already discussed Big Data and its pitfalls, but mostly with a more global focus, thus overlooking the ‘individual–level–perspective on big data’ (Karim, Willford, & Behrend, 2015, p. 527). Therefore, we would like to provide some guidance and recommendations to cope with the methodological, legal and ethical challenges of doing Big Data research especially with an idiographic focus.
Psychometric and methodological issues
For investigating behaviour at the level of the individual person, sufficient reliability of data needs to be ensured. This reliability depends on high effect and relative stability of data. Grandy, Lindenberger and Werkle–Bergner (2017) suggest increasing data density by using repeated measurements as a possibility to enhance reliability. However, the reliability gain is not necessarily proportional to the density increase. Several preconditions (van Drongelen, 2006) may, if not met, reduce reliability or even validity. Grandy et al. (2017) presume some of these often are not met when using repeated measurement in psychology (Danziger, 1990; Gigerenzer, 1987). Especially the assumption of independence of errors is often violated when using repeated measurements as learning, practice, or memory effects might occur (Grandy et al., 2017). One possible way of reducing this problem is to develop larger sets of items for measuring the same construct, so items can be varied in repeated measurements. Also, it is worth considering if, for example in ecological momentary assessment studies, exactly the same construct needs to be assessed every day or if it is possible to replace them by constructs correlated with the constructs of interest, (i.e. proxies), or even biodata at some measurement occasions.
In Big Data research, there is an inherent risk to overemphasize spurious relationships (Wenzel & Van Quaquebeke, 2018), that is discovering effects that do not really exist. With traditional statistical analyses, Type I error will occur increasingly in large data sets (Ioannidis, 2005), thus putting researchers at risk of discovering effects (e.g. correlations, group differences and others) by chance (Wenzel & Van Quaquebeke, 2018). Wenzel and van Quaquebeke (2018) illustrate their point by giving the example that with 100 parameters at a significance level of 0.05, approximately 247 of all possible correlations will be significant by chance. The Type I error problem increases with fewer data, as for example in n–of–1 studies, even if that person has been measured frequently. Of course, a possible countermeasure is to collect even more data over longer periods of time. In the past, researchers were advised to correct their p value (i.e. adapting the significance level); in modern data analysis, the outdated method of null hypothesis significance testing is usually replaced by Bayesian techniques, flanked by cross–validation methods to detect and avoid spurious results. Most importantly, researchers should always question the plausibility of their results and interpret findings with caution. Doing thorough replications and discussing potential limitations and alternative explications should go without saying. Such replications are also possible with regard to n–of–1 studies (Kratochwill et al., 2013; Manolov, Gast, Perdices, & Evans, 2014).
When collecting individual data from social media platforms such as Facebook (but not only then), we need to keep in mind that large parts of social media information are self–reported, and some parts can even be selectively removed or deleted, making it susceptible to ‘social desirability and intentional misrepresentation’ (Kosinski, Matz, Gosling, Popov, & Stillwell, 2015, p. 548). Also, lots of online data appearing to be human might in fact have been produced by automated systems (‘bots’) which can in many ways ‘systematically distort data and the subsequent inferences about human activity’ (Wenzel & Van Quaquebeke, 2018, p. 6). Even though it is not solely the younger generation that uses social media, there still is the risk of Big Data research with ‘modern’ technology is overly focused on young samples. In the same line, other groups may be underrepresented in social media data: rural or low–income–area residences, residences in developing countries and (digitally) illiterate groups are at risk of being overlooked in (online) Big Data research (Ihsan & Furnham, 2018; Sprague, Ester, & Serences, 2014; Wenzel & Van Quaquebeke, 2018). Additionally, political orientations, technological attitudes and religious beliefs (Hargittai & Hinnant, 2008) might explain why some ‘people may not engage in activities that ultimately produce Big Data’ (Wenzel & Van Quaquebeke, 2018, p. 6). In order to counteract these problems, it is important that researchers critically discuss and evaluate the quality of their data sources, ensure their designs do not underrepresent or even discriminate against groups that typically are not used to electronic devices that might produce Big Data or do not have access to the Internet (e.g. designing offline Big Data studies), and/or very specifically address groups that are up to now underrepresented in behavioural Big Data research. Also, a variety of potentially confounding variables should be assessed and statistically controlled for. In our view, idiographic personality research using Big Data may be advantageous regarding these problems because a few single cases that may have not used Internet and or mobile phones as yet may be equipped with such technologies and their ABCDE–patterns would be accessible as well.
With tools frequently used to collect Big Data, several analytical dilemmas might occur. For example, sensors produce high dimensionality data (i.e. they assess many data points per case) that often originate from fewer sources, so researchers often might not be able to identify to what extent these data are distinct from each other. Statistically, it is more difficult to work with high–dimensional raw data, for example when estimating parameters in large data sets. When estimating many parameters, there is the danger of errors of estimation accumulating to a point where it is impossible to disentangle error–induced noise from true effects (Fan, Han, & Liu, 2014; Silver, 2012; Wenzel & Van Quaquebeke, 2018). Also, missing data can be a problem because when assessing a large set of variables in several different subjects, some of these subjects might just not experience the variables of interest, thereby producing a large amount of missing data (Wenzel & Van Quaquebeke, 2018). For many wearables and apps using sensors, their exact reliability or sensitivity is unknown, which potentially leads to drawing false conclusions from obtained data (Guzzo et al., 2015). Especially in idiographic Big Data research, assumptions of statistical tests could be violated, and participants may show reactivity as a result of feeling constantly monitored (Whelan & DuVernet, 2015). Some may alter their naturally occurring behaviour (e.g. go jogging more often than they normally would when being equipped with a fitness tracker) to present themselves in a more favourable manner. Whelan and DuVernet (2015) think of these kinds of responses as inevitable, so it is a major task to make their effects on our research quantifiable and (statistically) controllable. Especially in n–of–1–studies or idiographic studies with only few participants, best practice would be to get to know the exact technical details of all devices used for data collection, processing and storing, to test their quality criteria in advance, to conduct several trial runs under adverse circumstances in order to identify weaknesses and limitations of the devices used, and also to test the designs on oneself to get a better idea of how demanding or aversive data collection might be for participants. We also suggest working in close cooperation with technical and statistical experts, operationalizing constructs of interest in different ways, using multi–method–designs, and trying to make data collection the least obtrusive possible, not putting unnecessary strain on participants.
Conceptualizing, conducting and statistically analysing idiographic Big Data research in high quality requires in–depth knowledge and lots of special skills and expertise in quite diverse fields, which necessitates cooperating with other researchers, specialists from other disciplines (computational science, statistics and law specialists), and/or working together in larger research teams with more manpower. As this type of research is time–consuming and resource–consuming and sometimes associated with need for special funding, it may not be attractive to researchers working at universities and pursuing the classical pre–post–PhD–career track. Therefore, in order to facilitate idiographic behavioural Big Data research, critically reflecting and reorganizing traditional research conditions, thinking out of the box, and pushing the boundaries of a sometimes rigid university environment will be necessary.
Legal and ethical considerations
The first and most substantial concern of researchers working with Big Data needs to be the risk of privacy breach (Wenzel & Van Quaquebeke, 2018). When using social media for participant acquisition (Kern et al., 2016) and when conducting n–of–1 or small sample idiographic studies, it is almost impossible to completely anonymize participants. Kern et al. (2016) therefore highlight the importance of storing such data safely in order to avoid unauthorized access (Wheatley, Maillart, & Sornette, 2016), which has happened in the past (e.g. Cambridge Analytica data scandal). This problem is especially relevant within the context of big data as the amount of data available dramatically increases the risk of reidentifying participants (Wenzel & Van Quaquebeke, 2018).
From an ethical point of view, idiographic Big Data research, especially in combination with the features and functions of social media applications such as Facebook or Instagram, can be considered a powerful double–edged sword: Scientifically powerful for advancing knowledge and understanding of the human psyche, but also potentially powerful in a manipulative and unethical way. Matz et al. (2017) warn researchers that using psychological targeting paves the way for influencing behaviour by tailoring news, videos or adverts exactly to people's psychological needs. Kosinski et al. (2015) even fear ‘the repercussions of misconduct in online human subjects research could be far greater than ever imagined’ (p. 551). As an example, they mention a study in which together with the Facebook News Feed and the Facebook Core Data Science teams, Kramer, Guillory, and Hancock (2014) manipulated users’ Facebook news feeds (updates from friends either expressing positive or negative emotions were selectively removed from the news feed for 1 week), in order to investigate emotional contagion (Kosinski et al., 2015). Users who had positive content reduced in their news feed posted status updates containing a larger percentage of negative and a smaller percentage of positive words (Kramer et al., 2014). This effect changed direction when negative content was reduced in the news feed (more positive and less negative words in status updates), indicating that emotional contagion occurred without requiring the physical presence of a significant other or nonverbal behaviour (Kramer et al., 2014). After Kramer et al.'s (2014) article had been published in PNAS, the editor wrote an expression of concern (Verma, 2014). Kramer et al.'s (2014) approach was fully consistent with Facebook's Data Use Policy to which all users must agree when creating an account, but participants did not give informed consent and had no possibility to opt out of the experiment, so it was definitely not in line with best practice in psychological research (Verma, 2014). It is important that already during studies professors teach ethical and responsible behaviour to their students, raise their awareness of researchers’ responsibilities, and—most importantly—serve as role models for students and research assistants. Guidelines for conducting ethical idiographic Big Data research and data privacy protection need to be developed. Courses and trainings could help educate researchers, reviewers, editors and institutional review board members.
Especially online and wearables–based Big Data research is usually associated with low participant burden (Park et al., 2015), but the distance inherent in these data collection methods holds the danger of researchers not knowing whether the questions asked, the tasks demanded, or simply just being in contact with a psychologist has triggered emotions, memories or deeper underlying psychological problems in participants (Kern et al., 2016). It should be every responsible psychologist's most crucial concern that participants are not being negatively affected by the research conducted (Karim et al., 2015) and to ensure participants feel well and know who to contact in case this might change. Even though we can and should provide participants with contact information, in remote big data research, it is nearly impossible to reliably ensure participants’ well–being as basic information that can easily be obtained in face–to–face interactions (especially nonverbal behaviour) is missing and cannot be replaced by chats or other remote communication forms. Transparently informing participants about the research and its possible effects, as well as building a trustful relationship and providing them with low threshold contact details in case they feel unwell or unsure could be first protective measures. In n–of–1 studies, researchers should use their closer relationships to the participants for recognizing arising problems early and intervening before potential negative effects occur.
Kosinski et al. (2015) deplore the lack of clear guidelines for digital research with human subjects. However, it appears to us as if especially I–O psychologists have already discussed this issue more profoundly (Guzzo et al., 2015; Wenzel & Van Quaquebeke, 2018; Whelan & DuVernet, 2015). For example, an ‘ad hoc committee recognized by the Executive Board of the Society for Industrial and Organizational Psychology’ (Guzzo et al., 2015, p. 491f) has developed recommendations concerning big data in I–O psychology. These recommendations intended to raise awareness (Guzzo et al., 2015) have been published as a focal article in Industrial and Organizational Psychology: Perspectives on Science and Practice, triggering a wide variety of valuable comment articles. For example, Guzzo et al. (2015) recommend adhering to a ‘data privacy protection plan’ (p. 495), as modern data management strategies can be vulnerable and error–prone. However, as in most recommendations regarding Big Data research, the idiographic perspective is missing.
It is important to keep in mind that data privacy laws are complex and differ significantly between countries (Guzzo et al., 2015). Therefore, big data research calls for a careful preparation and consideration of all relevant laws and standards in the countries where the data are being stored, collected and analysed (Guzzo et al., 2015). Guzzo et al. (2015) do not consider anonymization sufficiently protective and suggest pseudonymization, perturbation, encryption and key coding as alternatives applicable to big data research especially within the idiographic context. Regarding storage of data, ‘local, firewalled, physically protected servers’ (Guzzo et al., 2015, p. 499) seem to be the best available option.
No matter how promising the advantages—we feel we must emphasize at this point that conducting idiographic big data research carries enormous responsibility for the researchers and existing frame conditions and laws can only be considered minimum standard and not best practice. We want to remind psychologists and also other researchers that it is their duty and responsibility to ensure that all participants are fully informed, give their written consent, have the chance to ask all questions they have, can drop out of the study and demand their data to be deleted at any point in time without fearing consequences, and most importantly that no single participants’ well–being or privacy is negatively affected by their research in the slightest way.
Conclusion
On the basis of the fact that both behaviour and the individual person are important but relatively rare topics in personality studies, we have demonstrated that new technologies to collect and new methods to analyse Big (Behavioural) Data have the potential to bring back both more behaviour and the individual person into personality science. We have briefly reviewed the call for studying the individual person in the history of personality science, the related idiographic/nomothetic divide, attempts to reconcile these two approaches, as well as some unique selling points that underscore the importance of idiographic personality research. Based on a preliminary definition of the contested concept of Big Data, a nonexhaustive review revealed that wealth of behaviours are considered in extant personality studies using such Big Data. We have demonstrated the potential of Big Data for an idiographic personality science with regard to four research topics: (i) the possibility of identifying unique patterns of contextualized affects, behaviours, cognitions and behaviours (ABCDEs) that may be interpreted as personal dispositions, and (ii) to foster idiographic prediction. Furthermore, we have proposed (iii) a new model for analysing consistency and variability using Big Data in a transactional framework that assumes dynamic interactions between ABCDEs and a related pure idiographic version of Cattell's covariation chart, and (iv) new and exciting possibilities of personalized interventions in the emerging field of personality change through intervention. These new avenues of idiographic research in personality science are complicated by methodological, ethical and legal challenges for which we have provided preliminary recommendations. In sum, we are convinced that Big (Behavioural) Data will boost an idiographic personality science!
Acknowledgement
Open access funding enabled and organized by Projekt DEAL.
Supporting Information
Supporting Information, per2303-sup-0001 - Bringing Back the Person into Behavioural Personality Science Using Big Data
Data S1. Supporting information
Supporting Information, per2303-sup-0001 for Bringing Back the Person into Behavioural Personality Science Using Big Data by KARL-HEINZ RENNER, STEPHANIE KLEE and TIMO VON OERTZEN, in European Journal of Personality
Data S1. Supporting information
Footnotes
Supporting Information
Additional supporting information may be found online in the Supporting Information section at the end of the article.