
Abstract
Estimating psychological constructs from natural language has the potential to expand the reach and applicability of personality science. Research on the Big Five has produced methods to reliably assess personality traits from text, but the development of comparable tools for personal values is still in the early stages. Based on the Schwartz theory of basic human values, we developed a dictionary for the automatic assessment of references to personal values in text. To refine and validate the dictionary, we used Facebook updates, blog posts, essays, and book chapters authored by over 180 000 individuals. The results show high reliability for the dictionary and a pattern of correlations between the value types in line with the circumplex structure. We found small to moderate (rs = .1–.4) but consistent correlations between dictionary scores and self–reported scores for 7 out of 10 values. Correlations between the dictionary scores and age, gender, and political orientation of the author and scores for other established dictionaries mostly followed theoretical predictions. The Personal Values Dictionary can be used to assess references to value orientations in textual data, such as tweets, blog posts, or status updates, and will stimulate further research in methods to assess human basic values from text.
Introduction
Conceptually, personal values have been situated at the core of personality science since Gordon Allport. However, the prominence of values research in personality psychology has traditionally been linked to the popularity of specific measurement instruments and historically driven by the introduction of specific, theory–grounded self–report questionnaires, such as the Rokeach Value Survey (Rokeach, 1973) and the Schwartz Value Survey (SVS; Schwartz, 1994). The surge of empirical research on values in the past two decades is easily attributable to the theory of basic human values by Shalom H. Schwartz (1992) and the survey instruments derived from it: the SVS (Schwartz, 1994) and the Portrait Values Questionnaire (PVQ; Schwartz et al., 2012; Schwartz et al., 2001). The broad applicability of the theory and the frequent use of Schwartz's measures build upon the assumption that only a few abstract values underlie thousands of more specific attitudes and behaviours. In the past decade alone, hundreds of studies stemming from Schwartz's operationalization of personal values have consistently found systematic relationships between values and a variety of psychological constructs such as personality traits (Fischer & Boer, 2015; Parks–Leduc, Feldman, & Bardi, 2015), morality (Boer & Fischer, 2013; Feldman, in press), and political preferences (Schwartz, Caprara, & Vecchione, 2010).
As the analysis of digital user–generated data such as tweets, blog posts, or status updates gains popularity, the benefits of analysing such behavioural traces are becoming harder to ignore. The volume and accessibility of textual data allow working with previously inaccessible populations and research questions. Additionally, such data allow the sidestepping of many known problems associated with self–reports: response biases, experimenter effects, participant fatigue, and costly data collection and hence often inadequate sample sizes (Paulhus & Vazire, 2007).
Recent attempts to measure personality traits from user data produced promising results (e.g. Hall & Caton, 2017; Kosinski, Stillwell, & Graepel, 2013; Park et al., 2015; Schwartz et al., 2013), demonstrating that personality can be reliably measured from behavioural traces. Values are arguably lagging behind with relatively few published ‘Big Data’ approaches appearing just recently (Boyd et al., 2015; Chen, Hsieh, Mahmud, & Nichols, 2014; Christen, Narvaez, Tanner, & Ott, 2016; Gou, Zhou, & Yang, 2014; Mukta, Ali, & Mahmud, 2016; Sun, Zhang, Zhao, & Shang, 2014; Wilson, Shen, & Mihalcea, 2018).
In this paper, we describe the development and validation of a theory–driven dictionary for automatic assessment of references to personal values in everyday language. Such a tool can complement self–report assessments in research on personal values by facilitating the use of big data—extremely large datasets that often include authored textual data—and improving the feasibility of more diverse and robust research designs.
Values are theorized to predict behaviour, but the body of research linking values to direct records of behaviours remains modest. The popular, cost–effective cross–sectional survey designs rely instead on self–reports of behaviour—proxies that are subject to consistency, self–presentation, and memory biases (e.g. Araujo, Wonneberger, Neijens, & de Vreese, 2017; Short et al., 2009). Big data approaches, on the other hand, allow utilizing data that link texts to direct records of behaviour: device use, geolocation data, online purchases, or attendance of events. Textual data are often produced over a period of months or even years—such is the case with social network status updates, blogs, or app data. These data can be analysed with longitudinal methods, allowing answers to research questions about causality and change of values over time without the need to set up a costly longitudinal survey and avoiding the issue of participant attrition. Utilizing available big data can also improve the replicability of values research. Sheer sizes of the datasets (such as the ones used in the present study) help avoid the problem of insufficient statistical power that is prevalent in mainstream psychological research (Stanley, Carter, & Doucouliagos, 2018). In addition, relying on existing data removes a major barrier to replicating past studies—the costly collection of new data. As long as there exists more than one dataset that satisfies the requirements of the study, a replication project may involve little more than running the existing analysis on new data. Finally, a method for assessing values from text would allow answering research questions in settings where self–reported measures are impossible to obtain, for example, examining values in different historic periods.
Our approach is grounded in the assumptions that text is a behaviour performed by its author and that references to values in text are behavioural expressions of corresponding values. We base our analysis on a corpus of social media posts, essays, and works of literary fiction containing 525 901 609 words authored by 182 197 individuals. The Personal Values Dictionary (PVD) comprises more than 1000 value–laden terms and demonstrates the reliability of measurement comparable with that of recent language–based personality assessment tools.
The theory of basic human values
In the current study, we rely on the theory of basic human values (Schwartz, 1992; Schwartz et al., 2012). Schwartz defines values as desirable, trans–situational goals that serve as guiding principles in people's lives (Schwartz, 1992). The theory specifies a universal typology of 10 values: security, conformity, tradition, benevolence, universalism, self–direction, stimulation, hedonism, achievement, and power, 1 which are theoretically derived from three universal requirements of human existence: ‘needs of individuals as biological organisms, requisites of coordinated social interaction, and survival and welfare needs of groups’ (Schwartz, 1992, p. 4). The ten values are ordered by relative importance: while most people see all the value types as desirable, there are individual differences in the degree to which they are upheld. Basic human values theory specifies a circular structure of relations between the values based on their motivational congruence (Schwartz, 1992), which is presented in Figure 1.
The refined theory of basic human values (Schwartz et al., 2012) introduced finer distinctions to discriminate between 19 value types. However, the 10–value typology is still used most frequently.
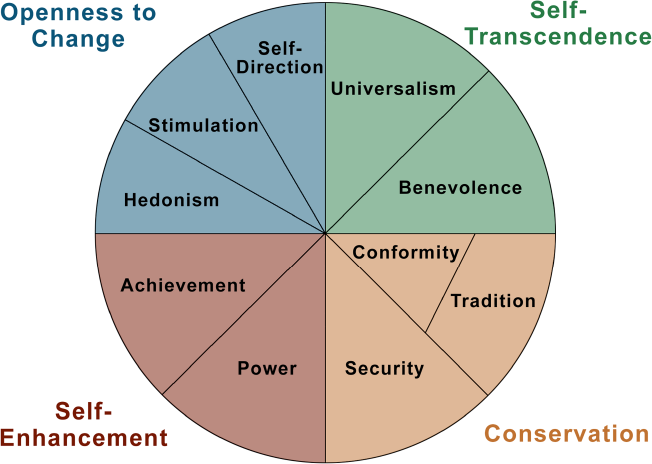
The theoretical model of relations among the 10 value types and the four higher order values. [Colour figure can be viewed at wileyonlinelibrary.com]
Values that hold an adjacent location in the structure express similar motivational goals are conceptually and functionally similar and are more likely to be pursued together. In contrast, values that express conflicting motivational goals are oppositionally situated and are less likely to be pursued together (Schwartz & Bilsky, 1990). Empirically, Schwartz identified two motivational conflicts defining the higher order dimensions of conservation versus openness to change (C–O) and self–transcendence versus self–enhancement (SE–ST): conservation values (security, conformity, and tradition) reflect the need for control, order, and protection, whereas openness to change values (self–direction, stimulation, and hedonism) reflect the need for exploration, novelty, and new opportunities. Similarly, self–transcendence values (benevolence and universalism) focus on the outcomes of one's actions for others—goals that are incompatible with self–enhancement values (achievement and power), which focus on the outcomes for oneself.
Within the five–factor theory of personality, personal values are described as characteristic adaptations that are formed through the interaction of personality traits with the environment (McCrae & Costa, 1999). Recent studies on values, however, place them at the level of dispositional traits, similar to the Big Five (see Fischer, 2017, for a review). Values are at least as accessible by direct observation as personality traits (Dobewall, Aavik, Konstabel, Schwartz, & Realo, 2014).
In the next two sections, we will discuss previous data–driven and theory–driven approaches to the extraction of information on value orientations from text. Data–driven approach implies in this context that the dimensionality of value orientations was empirically derived from co–occurrences of value–related terms in textual data (i.e. theory–free); theory–driven approach describes attempts to apply a specific value theory—most often, Schwartz's theory of basic human values—to textual data as a means of extracting information on individuals’ value orientations.
Studies on the dimensionality of verbal references to value orientations
Aavik and Allik (2002) employed the lexical method in the tradition of Galton, 1949 and Allport's (e.g. Allport & Odbert, 1936) seminal studies on the dimensionality of personality traits in a study on dimensions of value orientations. In the first step, they developed the Estonian Value Inventory (EVI) by starting with 560 words from an Estonian dictionary that referred to value orientations, according to expert judgements. In several revisions, this list was reduced to 78 words. In the second step, 294 Estonian participants filled in the SVS and rated the personal importance of the values that were expressed in the 78 words of the EVI. The resulting data favoured a six–factor solution, with authors labelling the resulting factors benevolence, self–enhancement, broadmindedness, hedonism, conservatism, and self–realization, together accounting for 45.3% of the variance of the ratings of the 78 EVI words. Correlations between SVS scales and EVI scales were moderate (rs = .20–.50).
A similar approach was used to identify a common taxonomy of values in Spanish, Austrian/German, and Dutch value expressions (De Raad et al., 2016). Participants from each country rated pairwise similarities between 496 (Austrian/German) and 641 (Dutch) value terms that were previously identified by experts as reflecting values. Various factor analytic approaches were then used to identify a common factorial structure. The authors arrived at a five–factor solution, differentiating between values of interpersonal relatedness, status and respect, commitment and tradition, competence, and autonomy. The participants did not answer any Schwartz values measure for a direct comparison.
Such data–driven lexical approaches often arrive at very different conclusions, depending on the methods employed and specific language under study. An extensive analysis of verbal expressions of value orientations in English and German languages (Christen et al., 2016) revealed a structure that did not resemble any of the existing taxonomies or value theories. The authors began with 448 value–relevant words identified through a literature review of value concepts in psychological as well as philosophical texts. To capture the use of the concepts more broadly, each of the 448 ‘seed’ words was represented as a ‘word bag’ or a set of semantically similar words, identified via online synonym databases such as www.thesaurus.com. After extensive cleaning, 3749 English and 4775 distinct German terms remained across all word bags. They then used an iterative process of automatic classification and expert annotation to classify value word bags and to create a value map based on a dissimilarity matrix. Rather than linking their findings to existing theories or taxonomies, the authors argue that their results highlight the importance of value pluralism.
Machine learning is another approach used to identify the taxonomy of values in language. Wilson et al. (2018) compiled a substantial list of value–related seed words based on suggestions from participants in an online survey, words that were generated by crowdworkers, and words from value questionnaires and similar sources. Crowdworkers were then used to train an algorithm to sort the words into a hierarchical tree–like structure. This approach resulted in a taxonomy of 100 value categories, yet the authors did not attempt to relate these categories to existing value theories.
Unlike studies that only aimed at describing taxonomies of values, Boyd et al. (2015) compared the predictive power of an empirically derived framework for verbal references to value orientations with the predictive power of SVS scores. In the first study, they asked more than 700 participants via Amazon Mechanical Turk (MTurk) to write one essay on their value orientation and one essay on their typical everyday behaviours during the last 7 days. Participants also filled in the SVS. They then used a topic modelling approach (Meaning Extraction Method; Chung & Pennebaker, 2008) to automatically extract 16 themes from the values essays and 26 themes from the behaviour essays. Although there were correlations (R2s ∼.01–.04) between the values essay themes and corresponding SVS dimensions, the automatically derived themes from the values essays could explain more variance in the prevalence of the themes in the behaviours essays than participants’ SVS scores. In the second study, the authors measured the frequencies of words referring to the themes identified in the first study, using a dataset of status updates of approximately 140 000 Facebook users. About 1200 of these users had also filled in the SVS questionnaire via the myPersonality app (cf. Kosinski et al., 2013). Again, the theory–free generated values themes captured more variance in the prevalence of the behaviours themes than the users’ SVS scores.
The core strength of the data–driven approaches described above is the accuracy with which they account for variance in the use of value–related words. Not surprisingly, data structures derived directly from the studied texts outperformed theory–based structures (i.e. Schwartz motivational continuum) in the amount of variance explained. However, the structures discovered with such a theory–free approach are hardly generalizable. The findings of these studies are difficult to reconcile—the revealed data structures are dissimilar, as they mix the features of the latent construct they are examining and the features of the specific texts under examination. At the same time, relatively little theoretical insight is gained by examining the specific configurations derived from such lexical approaches, as the general data structure broadly aligns with the structure defined by Schwartz's four higher order values (Borg, Dobewall, & Aavik, 2016; Schwartz, 2017). To be able to generate findings that are comparable and generalizable, that is to accumulate knowledge, theory–driven (or knowledge–based; de Maat, Krabben, & Winkels, 2010) approaches are more promising.
Previous attempts to estimate individuals’ value orientations from textual data
Whereas the studies above employed a data–driven approach to analyses of the dimensionality of personal value orientations, other research has adopted a theory–driven approach. Here, the research focus is on estimating authors’ value orientations from texts according to established theories of personal values.
Bardi, Calogero, and Mullen (2008) developed a brief value lexicon (three words per value, 30 words in total) based on Schwartz's theory (1992) and applied it to American newspaper content from 1900 to 2000. They showed that the value words for each respective value co–occur in large corpora more frequently with each other than with words referring to other values; they also found that value words co–occur more frequently with words indicating corresponding value–expressive behaviours, that is, behaviours that had been found to correspond to value categories in questionnaire studies (e.g. Bardi & Schwartz, 2003).
Portman (2014) took a more qualitative approach and hand–coded value expressions in speeches in the Finnish parliament between 1809 and 2000. In addition to Schwartz's 10 values, Portman included ‘spiritual’ and ‘work–related’ values as means of capturing central dimensions of the political discourse in Finland (see also Helkama & Seppälä, 2006). She found that relative frequencies of references to certain values mirrored macro–level events such as economic or societal crises.
Several studies focused on testing the overlap between values assessed from text and self–reported values. Chen et al. (2014) analysed the 1000 most recent Reddit contributions of 799 users, who had also completed a short PVQ version (Schwartz, 2003). They used the Linguistic Inquiry and Word Count (LIWC; Pennebaker, Chung, Ireland, Gonzales, & Booth, 2007) dictionary to predict individuals’ PVQ scores from their postings. Although no individual correlation between a LIWC measure and a PVQ measure was higher than r = .18, 13.8% to 18.2% of the variance in PVQ scores could be explained via the LIWC measures in total. Mukta et al. (2016) used LIWC measures as well to predict the PVQ scores of 567 Facebook users from their status updates; they were able to explain between 13.3% and 21.1% of the variance in the PVQ measures. Gou et al. (2014) used a linguistic model that was trained on texts created by Amazon MTurk workers to predict value orientations from tweets. They analysed 200 latest tweets collected from 256 Twitter users and were able to find only small correlations (rv = .026) between values as measured with the PVQ and the text–based value scores. Sun et al. (2014) analysed the 400 most recent contributions of 101 Chinese graduate students on Chinese social media sites (e.g. Weibo) who had also filled in, among other measures, the PVQ. A classifier was trained with one–half of the social media messages to estimate value scores. Sun and colleagues report comparable levels of concurrent validity between the PVQ and their linguistic model as could be found for the PVQ and other value questionnaires such as the Pairwise Comparison Values Survey (Oishi, Schimmack, Diener, & Suh, 1998).
Recently, commercial applications such as IBM Watson Personality Insights have become available and widely accessible (IBM Watson, 2018). The service offers to compute scores based on text input for five dimensions related to Schwartz's values theory: self–transcendence/helping others, conservation/tradition, and hedonism/taking pleasure in life, self–enhancement/achieving success, and openness to change/excitement. These scores are supposedly based on an algorithm that was trained by survey responses of thousands of users in combination with their Twitter feeds. The tool has the advantage that it supports various languages and provides an estimate of the quality of predictions based on the entered text. While the obtained values scores are tempting, the validity of such tools for both research and applied purposes has been recently called into question (e.g. Boyd & Pennebaker, 2017; Hickman, Tay, & Woo, 2019).
The approaches described above provide various degrees of generalizability but are limited in several ways. Manual coding methodologies are ill–suited to use for large bodies of text (Portman, 2014), while most others to date are extremely brief and thus unable to capture most references to values (Bardi et al., 2008). Much research to date is not specifically designed to align with a theory (LIWC–based approaches; Chen et al., 2014; Christen et al., 2016; Mukta et al., 2016) or, in more extreme cases, use machine–learning approaches where results strongly depend on the specific texts used for training the algorithm (Gou et al., 2014; Sun et al., 2014) and therefore have limited generalizability. Finally, some are impossible to validate independently (IBM Watson, 2018). In consequence, there is still a strong need for a thoroughly validated theory–driven instrument to detect references to value orientations in large bodies of text.
Present study
We set out to develop an instrument for assessing individual value priorities via references to values in natural language. Our approach is based on the assumption that values that are held more important to the author are referred to more often (Bardi et al., 2008; Boyd, Pasca, & Conroy–Beam, 2019; Tausczik & Pennebaker, 2010). By reference to a value, we understand an utterance that invokes the content of the value in describing an object, event, state, evaluation, and so on. For example, for the value of security, such utterances can include words ‘warning’, ‘danger’, or ‘safe’. Note that the valence of the relationship of the words to the content of the value can be positive or negative, so we expect authors that consider the value of security more important to use both words ‘dangerous’ and ‘safe’ more often.
To detect and quantify the references to values we constructed a broad, theoretically grounded dictionary for use with word–counting software. To overcome the limitations of past research, we aimed to create a solution that is (i) grounded in the widely used theory of basic human values (Schwartz, 1992), thereby offering generalizability and compatibility with the large existing body of research on values, (ii) readily automated and thus suitable for application to large bodies of text, (iii) sensitive to the variety of ways in which values can be referenced, (iv) applicable across types of texts, and (v) convenient and resource–efficient.
The procedure we used to develop and validate the PVD builds upon and advances procedures used in earlier approaches to extracting information on psychological constructs from text data, such as personality traits, moral foundations, or sentiments (Graham, Haidt, & Nosek, 2009; Pietraszkiewicz et al., 2018; Tausczik & Pennebaker, 2010). In the development stage, a group of experts agreed on a list of candidate words representing the 10 value types proposed by Schwartz (1992) (content validity). Candidate words were obtained from established values questionnaires, synonym networks of value–laden terms, and most common words in online searches. This candidate list was then refined using multiple methods including psycholinguistic techniques and exploratory factor analysis (EFA; see Figure 2).
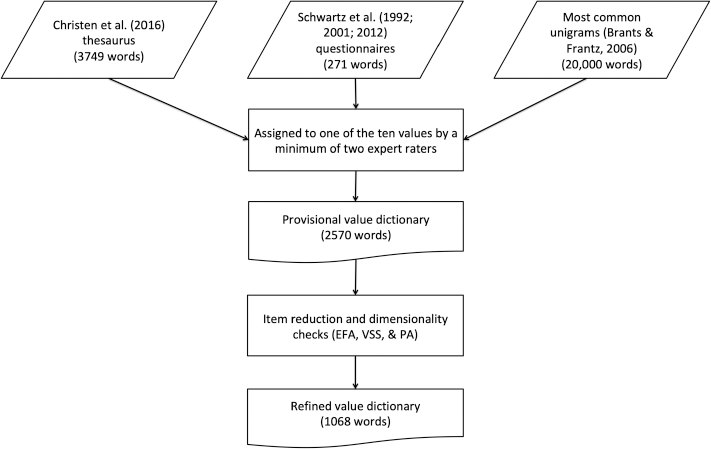
Diagram summarizing the workflow of the development stage. EFA, exploratory factor analysis; PA, parallel analysis; VSS, very simple structure.
We followed Cronbach and Meehl's (1955) classification of validity in psychological tests that distinguishes between content validity, construct validity (including convergent and discriminant validity), and criterion validity (including concurrent validity and predictive validity). In the validation stage, after assessing the internal consistency of the PVD, we examined the validity of the refined dictionary by comparing the pattern of correlations between the 10 value types against the theoretically expected circumplex. Further, we examined the correlations between values as measured by the PVD with relevant LIWC categories as well as the Moral Foundations Dictionary (MFD; Graham et al., 2009) (convergent and discriminant validity). Finally, we tested the criterion validity of the PVD by examining (i) correlations between the PVD value scores and value scores obtained with questionnaire measures (concurrent validity) and (ii) correlations of PVD value scores with gender, age, and political orientation of the authors (predictive validity).
Method
We first describe the corpora that were used in the development of the PVD and then describe the development and validation procedures step–by–step. The study is exploratory in nature and did not include preregistered hypotheses. All study materials, including the dictionaries, instructions for data access, and syntax to reproduce our analyses, and supporting information are available on the Open Science Framework (OSF): https://osf.io/vt8nf.
Data
A robust, data–driven approach to measurement through behaviour requires significantly greater volumes of data than questionnaire–based measures. Particularly for multidimensional and/or relatively sparse data types—both of which typify verbal behavioural data (Boyd, Pasca, & Lanning, 2020)—the learning of reliable associations and rules that link behaviours to underlying latent psychological processes, such as values, requires higher volumes of data than would be found in traditional studies to pass minimally acceptable thresholds of validity (Kessler et al., 2019).
In total, we used five different text corpora for the refinement and validation of the PVD. The corpora were selected based on three criteria: all texts should be single–authored, self–expressive, and together, provide a diverse set of contexts for language use. 2 The selected corpora represent texts created both online and offline, directed at different audiences, and created over the span of 27 years (1990–2017).
During the revision of this article, the sixth corpus was added to the analysis. This corpus (Manifesto project database) does not satisfy the selection criteria outlined here, that is why we do not report it together with other corpora. The inclusion of the corpus was justified by the need to test the robustness of some unexpected findings from the Political Blog Corpus, and the description of the corpus is provided in the relevant section of the Results.
Corpus of Contemporary American English (COCA, 1990–2012 and 2016–2017). This corpus (Davies, 2009) features over 560 million words in total. The texts are categorized into spoken, fiction, popular magazines, newspapers, and academic. We analysed only texts from the category fiction, as these were single–authored and most likely to be self–expressive and value–expressive. This subset was composed of 19 276 individual documents and 112 018 482 words for the years 1990–2012 and 1422 individual texts and 5,190,616 words for the years 2016–2017. For the subset of texts from 2016 to 2017, we also manually coded the authors’ gender and age for validation purposes (59% female; aged 28–99, MDage = 61). The Blog Authorship Corpus (personal blogs). This openly available corpus (Schler, Koppel, Argamon, & Pennebaker, 2006) consists of blog posts published on the website blogger.com in August 2004. It is composed of blog posts by 19 320 authors and consists of 64 523 071 words. The texts are supplemented with the authors’ gender and age (50% female; aged 13–48, MDage = 23). The CMU 2008 Political Blog Corpus (political blogs). This open–access corpus (Eisenstein & Xing, 2010) incorporates posts from six American political blogs, gathered during the 2008 election campaign. The data are composed of 13 246 posts and 6 918 235 words. The texts are coded as coming from either Republican–leaning (57%) or Democrat–leaning (43%) blogs. Essays on values and behaviours (essays). This corpus includes two essays each written by 767 individuals in a study conducted by Boyd et al. (2015) using the Amazon MTurk platform. In the first essay, participants were asked to write about their values; the second essay focused on the behaviours of the participants in the last 7 days before taking the survey (SVS). The essays included 158 223 words and were combined for the purposes of this study. The data were obtained from the authors (see Boyd et al., 2015). The texts are supplemented with participants’ gender and age (64.5% female, median age group: 35–54) and their responses to the SVS. Facebook status updates (Facebook). This corpus contains Facebook status updates of 141 408 individuals from the myPersonality project (Kosinski et al., 2013) and includes 337 092 982 words. A subset of this corpus (1521 individuals, 5 149 464 words) additionally contains participants’ responses to the SVS questionnaire, which we used in the validation stage. Participants from this subset were required to have a minimum of 200 words used across all status updates to be included in the analysis (participants meeting criteria: N = 1339). This dataset has previously been used in Boyd et al. (2015) and was kindly provided to us by the authors in the form of LIWC output for relevant categories; a detailed description of the dataset can be found in the original publication.
Procedure
Step 1: Development of the provisional dictionary
We compiled a list of candidate words from three sources: the English version of the heuristic map of values (and their synonyms) by Christen et al. (2016) containing 3749 words, the 271 words used in the value items of the three Schwartz's questionnaires (Schwartz, 1992; Schwartz et al., 2001; Schwartz et al., 2012), and the 20 000 most common unigrams in the Google Web 1T database (Brants & Franz, 2006). All words were coded into the 10 value types by a minimum of two expert raters. Words were excluded if they were considered irrelevant to values by both judges or when no agreement was reached on which value type that word represents. Every word was assigned to only one value category. We made this decision to eliminate the possibility of creating built–in correlations between value categories that would affect the tests of construct and criterion validity. In the provisional dictionary, 2570 value–laden words were included.
Step 2: Dictionary refinement
The aim of this stage was to test whether the words assigned by experts to each of the 10 values tend to co–occur in natural language. We randomly split four of the corpora (COCA 1990–2012, personal blogs, political blogs, and essays) into two halves: The first halves were used for dictionary refinement and the second halves for validation. The subsamples were selected randomly but were balanced on key variables (see Supporting information for details). Facebook updates and COCA 2016–2017 were used only at the validation stage. All data were trimmed to exclude extremely rare and extremely frequent words (words appearing in less than.05% and more than 99% of texts, respectively).
We first applied EFA with weighted least squares extraction and oblique rotation to the raw word counts for each value category. The EFAs were supplemented by very simple structure (Revelle & Rocklin, 1979) and parallel analysis (Horn, 1965). 3 Irrespective of the number of factors identified, we kept all words loading on identified factors (factor loadings ≥.1) if the factor made theoretical sense (i.e. represented a component of the respective value; Schwartz et al., 2012) and had an eigenvalue of ≥1. We then integrated the word lists obtained from all four corpora. A word was included in the refined version of the dictionary if it loaded on the respective value in at least two of the corpora. Thus, the refined dictionary includes only those words that both theoretically represent the underlying value and consistently co–occur in natural language. The refined dictionary, PVD, consists of 1068 value–laden words.
Parallel analysis is a method used to determine the number of factors to keep in exploratory factor analysis. The principle is based on the comparison between the empirically determined eigenvalues and randomly formed eigenvalues of simulated data with the same number of observations. Very simple structure analysis provides a criterion to assess the fit of a simple factor structure versus a multifactor structure by estimating the explanatory gain achieved by the increased number of factors.
Step 3: Validation
For this stage, we used the second halves of the corpora, plus the Facebook corpus. We first evaluated the internal consistency and temporal stability of the refined value dictionary. Internal consistency was estimated using the binary (one hot) scoring method. This method uses a binary count of the presence/absence of a word in a text; the reliability is calculated based on tetrachoric correlations of this binary data. We also report the internal consistency coefficients based on the standard scoring method with Spearman–Brown adjustment in the Supporting Information. Temporal stability (test–retest reliability was evaluated by correlating dictionary scores available for the same person for multiple points in time.
Second, we calculated PVD scores for 10 values for each text by calculating the rate at which words from each PVD category were used in a specific text. The resulting PVD scores were ipsatized, similarly to scores for questionnaire–based value surveys (Schwartz, 2009). The final value score is calculated as the frequency of the words representing the given value, minus frequency of all value–related words in the text. Theoretically, values are ordered by importance, relative to one another (Schwartz, 1992); ipsatization reflects this ordering in value scores.
Third, as a first test of the construct validity of the PVD, we analysed the interrelations between values. We used multidimensional scaling (MDS) to assess whether the theoretically proposed circumplex structure of values replicated with the PVD. Here, validation was done by graphical inspection of the location of the 10 values (and the four higher order value types) in two–dimensional MDS plots.
Fourth, we calculated correlations between the PVD categories and relevant LIWC dictionaries (Pennebaker, Boyd, Jordan, & Blackburn, 2015) as well as the MFD (Graham et al., 2009) to test for convergent and discriminant validity. Correlations with conceptually related constructs are expected to be significantly higher than correlations with conceptually unrelated constructs.
Fifth, we tested the concurrent validity of the PVD by correlating questionnaire responses with references to values in natural language samples from the same individual, using Pearson product moment correlations (r). To estimate how well the PVD captures the relative importance of different values to an individual, we additionally examined profile correlations. A profile correlation (q) is a person–focused measure of relatedness estimated at the between–item level of analysis (Furr, 2008; Rogers, Wood, & Furr, 2018). The overall profile similarity for an individual's hierarchy of values, however, might be inflated because any two profiles are similar to the degree they both reflect the average profile (i.e. profile normativeness). To estimate the extent to which this is the case in the current data, we additionally reported distinctive profile correlations that eliminate the effects of profile normativeness in the similarity estimates (Furr, 2008; Rogers et al., 2018). In line with the Richard, Bond, and Stokes–Zoota (2003) review, we consider 0.1 ≥ r ≥ 0.2 small effects and r ≥ 0.2 as moderate. A typical correlation found between linguistic measures and self–reports is in the range of 0.1–0.2 (Boyd et al., 2015; Chen et al., 2014; Gou et al., 2014; Kosinski et al., 2013; Pennebaker et al., 2015); hence, we consider correlations of this magnitude as adequate evidence for concurrent validity.
Finally, the predictive validity of the PVD was tested by relating the counts of value–related words to the socio–demographic characteristics of the authors, such as gender, age, and political orientation. Here, we do not specify numerical criteria but expect to find conceptual replication in the form of associations in the same direction as previously found in survey data.
Results and Discussion
The provisional dictionary is available on the OSF repository; the refined dictionary and the results from the EFA are presented in the Supporting Information. Table 1 shows the number of words assigned to each of the 10 values in the refined dictionary as well as their internal consistency scores, averaged across four corpora (scores based on the standard scoring method are reported in Table S2). The dictionaries for all value types show high internal consistency, with scores ranging between .80 and .99, M = .94.
Internal consistency of each value type in Personal Values Dictionary (averaged across four corpora)
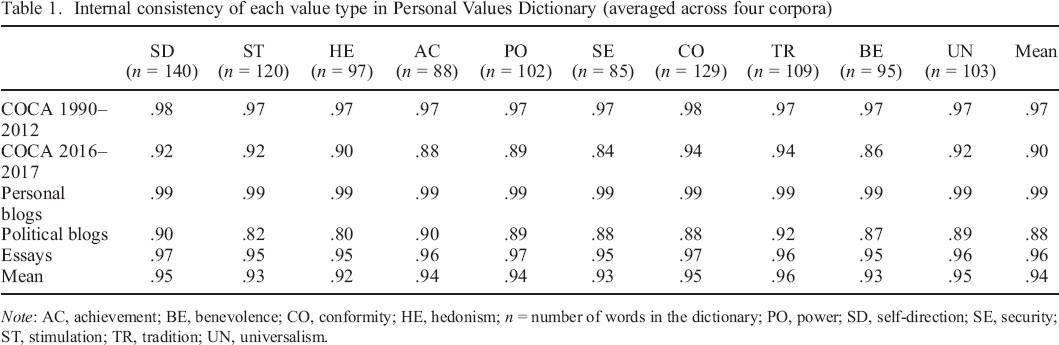
Note: AC, achievement; BE, benevolence; CO, conformity; HE, hedonism; n = number of words in the dictionary; PO, power; SD, self–direction; SE, security; ST, stimulation; TR, tradition; UN, universalism.
We calculated test–retest reliability for the dictionary using the personal blogs corpus. The majority (94.7%) of entries in the blog corpus were made in 2003 and 2004, and 1235 unique bloggers made entries in both years. The average correlation of word counts for PVD categories ranged from .43 (benevolence) to .79 (tradition), M = .52, with the difference in median post time of 8 months. To account for shared method variance such as the general tendency to use value–laden words and the average length of texts, we repeated the analysis with weighted and ipsatized PVD scores. The correlations ranged from .16 (power) to .63 (tradition), M = .32.
Convergent and discriminant validity
The 10 Schwartz values are interrelated (Schwartz et al., 2012; Schwartz & Bilsky, 1990). The first indication of convergent validity would be that interrelations between references to values align with the theoretical motivational continuum proposed by Schwartz.
Interrelations between values
The adjacent values in the motivational circle were interrelated; we found high internal consistency also for the higher order values: openness to change (.97), conservation (.97), self–transcendence (.96), and self–enhancement (.96). The results of the MDS 4 indicate that the positions of specific values resemble the theoretically expected pattern, yet some deviations occurred. Figure 3 shows the MDS results for the COCA 1990–2012 and the Facebook corpus (the remaining MDS results are presented in the Supporting information). These deviations could be related to the nature of the texts and their intended audiences: power and achievement values are located closer to the centre in Facebook and personal blogs and universalism and hedonism in literary fiction. The two underlying motivational conflicts, the SE–ST dimension and the C–O dimension, replicated in all corpora; however, the position of the higher order values in relation to each other in some corpora deviated from what is typically found with survey data. For example, self–enhancement values were closer to conservation than to openness values in three out of five corpora, and conservation values were closer to self–enhancement than to self–transcendence values in three out of five corpora. These deviations may reflect the gap between self–reported values and their behavioural manifestations in text. Value expression is only one of the many functions of a written text, and the way authors’ values are reflected in a text depends on its communicative functions and intended audience. Overall, the MDS results provide some support for the construct validity of PVD, but cannot be considered conclusive evidence without additional tests of convergent and discriminant validity.
We conducted MDS on each corpus except the essays because of the small sample size. As every word was assigned to only one value category, correlations between frequencies of value categories cannot be explained by overlapping dictionaries.
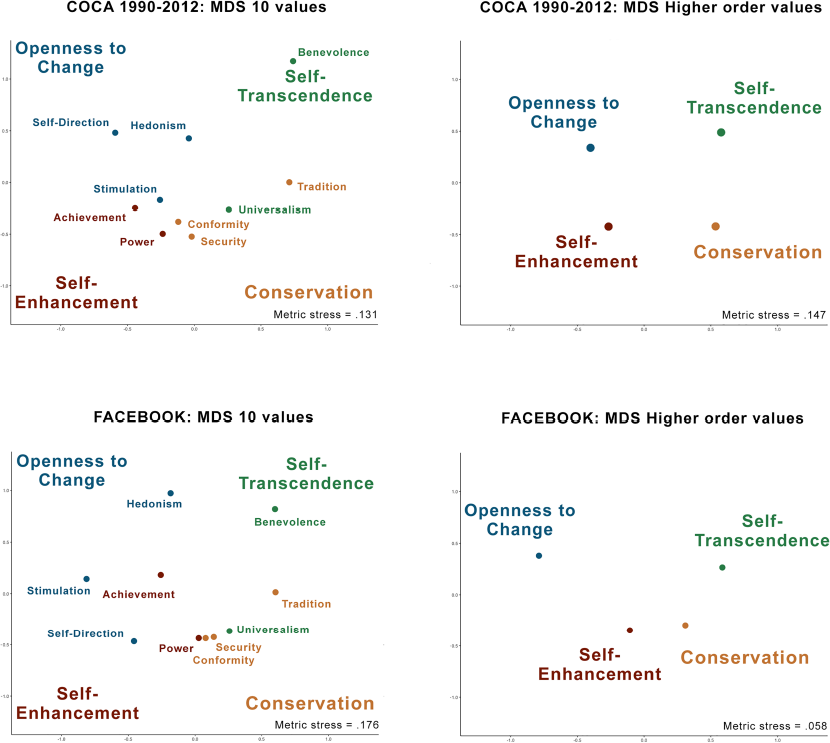
Two–dimensional multidimensional scaling (MDS) of references to values in text measured by the Personal Values Dictionary (PVD). [Colour figure can be viewed at wileyonlinelibrary.com]
Interrelations of values with other constructs
To estimate the PVD's performance in catching relevant references to values in text, we correlated values as measured by the PVD with word counts of other constructs for which dictionaries are available. We selected seven LIWC categories measuring constructs that are theoretically associated with specific values. These were ‘insight’ (self–direction), ‘perceptual processes’ (stimulation), ‘sexuality’ (hedonism), ‘achievement’ (achievement), ‘power’ (power), ‘risk’ (security; both dictionaries focus on danger and safety), ‘religion’ (tradition), and ‘family’ (benevolence). Positive correlations between these pairs of constructs would indicate convergent validity; weaker or negative correlations with other constructs would indicate discriminant validity. The average correlations 5 across all corpora are reported in Table 2. For transparency, we report correlations with all 10 value types, irrespective of whether we had theoretical arguments for the relationships or not.
We calculated average correlations without weighting to give each corpus equal weight, as it allows us to account for the diversity of contexts for language use that our corpora provide.
Average correlations of references to values (Personal Values Dictionary) with theoretically related psychological constructs (as measured by the Linguistic Inquiry and Word Count tool) across four corpora
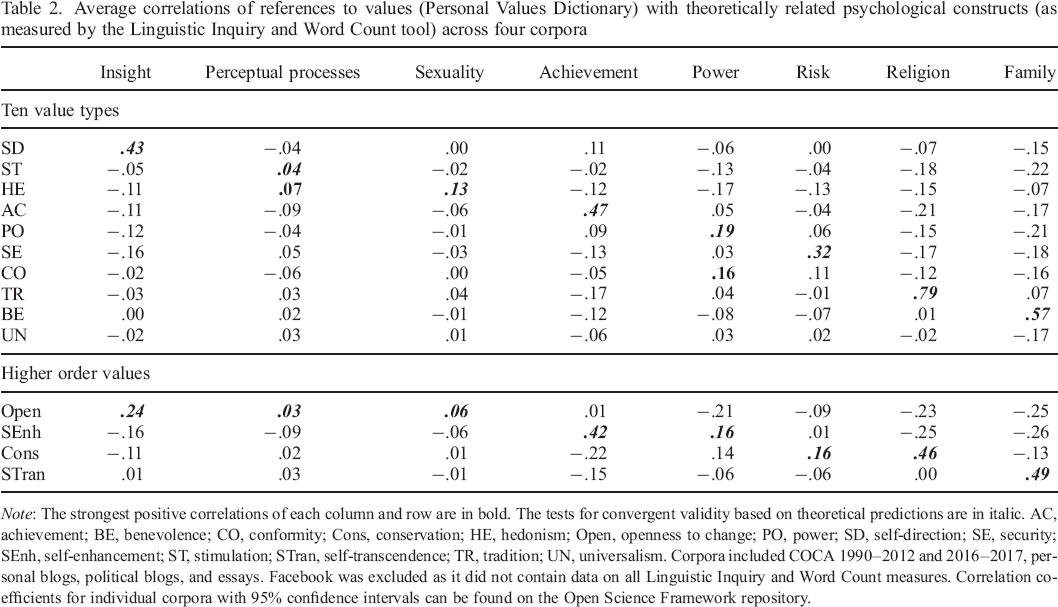
Note: The strongest positive correlations of each column and row are in bold. The tests for convergent validity based on theoretical predictions are in italic. AC, achievement; BE, benevolence; CO, conformity; Cons, conservation; HE, hedonism; Open, openness to change; PO, power; SD, self–direction; SE, security; SEnh, self–enhancement; ST, stimulation; STran, self–transcendence; TR, tradition; UN, universalism. Corpora included COCA 1990–2012 and 2016–2017, personal blogs, political blogs, and essays. Facebook was excluded as it did not contain data on all Linguistic Inquiry and Word Count measures. Correlation coefficients for individual corpora with 95% confidence intervals can be found on the Open Science Framework repository.
We found all the expected correlations. ‘Insight’ correlated with self–direction, ‘sexuality’ with hedonism, ‘family’ with benevolence, and so forth. The pattern of negative correlations was also in line with the theory, with constructs showing positive correlations with openness values having negative or zero correlations with conservation values (‘insight’ and ‘sexuality’), and those with positive correlations with self–enhancement values having negative correlations with self–transcendence values (‘achievement’ and ‘power’). Each value correlated with the corresponding construct stronger than with all other constructs, supporting the discriminant validity of the measures. Overall, these results demonstrate a satisfactory degree of convergent and discriminant validity.
We supplemented the list of related constructs from the LIWC dictionaries with the five moral domains from the MFD (Graham et al., 2009). As two recent meta–analyses of survey data show, moral foundations relate to values in predictable ways (Boer & Fischer, 2013; Feldman, in press): Harm–care and fairness–reciprocity dimensions relate positively to universalism and benevolence and negatively to power, achievement, and hedonism (SE–ST dimension); Authority–respect and purity–sanctity dimensions relate positively to tradition, conformity, and security values, and negatively to hedonism, stimulation, and self–direction values (C–O dimension). The evidence for ingroup–loyalty is mixed (Boer & Fischer, 2013; Feldman, in press). As PVD includes both positive and negative words for each value, we combined the ‘vice’ and ‘virtue’ dictionaries for each of the MFD domains into a single word list before running the analysis. Table 3 reports correlations between references to values as measured by PVD and moral foundations as measured by MFD, averaged across corpora.
Correlations of references to values (Personal Values Dictionary) with moral foundations (Moral Foundations Dictionary), averaged across four corpora
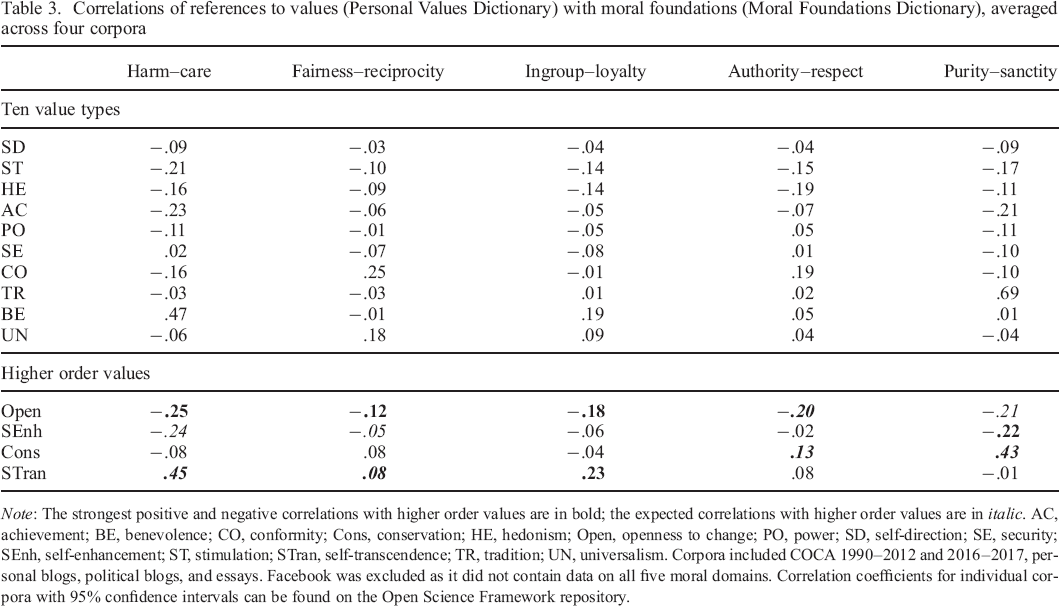
Note: The strongest positive and negative correlations with higher order values are in bold; the expected correlations with higher order values are in italic. AC, achievement; BE, benevolence; CO, conformity; Cons, conservation; HE, hedonism; Open, openness to change; PO, power; SD, self–direction; SE, security; SEnh, self–enhancement; ST, stimulation; STran, self–transcendence; TR, tradition; UN, universalism. Corpora included COCA 1990–2012 and 2016–2017, personal blogs, political blogs, and essays. Facebook was excluded as it did not contain data on all five moral domains. Correlation coefficients for individual corpora with 95% confidence intervals can be found on the Open Science Framework repository.
The results indicate a partial overlap but also largely unique content of these two dictionaries. Harm–care and fairness–reciprocity correlated positively with self–transcendence and negatively with self–enhancement values. Authority–respect and purity–sanctity correlated positively with conservation, specifically with tradition, and negatively with openness values. We found ingroup–loyalty to be associated mainly with self–transcendence values, specifically with benevolence. Feldman (in press) found ingroup–loyalty to be associated with the C–O dimension, whereas Boer and Fischer (2013) reported that it is not consistently associated with value dimensions.
It is worth noting that all five domains of the MFD had strong negative correlations with openness values, even when theoretically the strongest negative link was expected for self–enhancement values (harm–care and fairness–reciprocity). This suggests that people who frequently use words reflecting openness to change values also use fewer words that relate to morality.
Criterion validity
We tested the concurrent validity of the PVD by analysing correlations between references to values in text (measured with PVD) and self–reported values of the authors of these texts (measured with SVS). To assess the predictive validity of the PVD, we analysed correlations of references to values in text with the author's gender, age, and political orientation.
Correlations between self–reported values and references to values in text
A subset of Facebook corpus and the essays corpus contained both texts produced by the participants and their self–reported value scores. Both PVD and SVS scores were ipsatized (Schwartz, 2009). Correlations between the value scores as measured by PVD and as measured by SVS are reported in Table 4.
Correlations between references to values in text and self–reported values
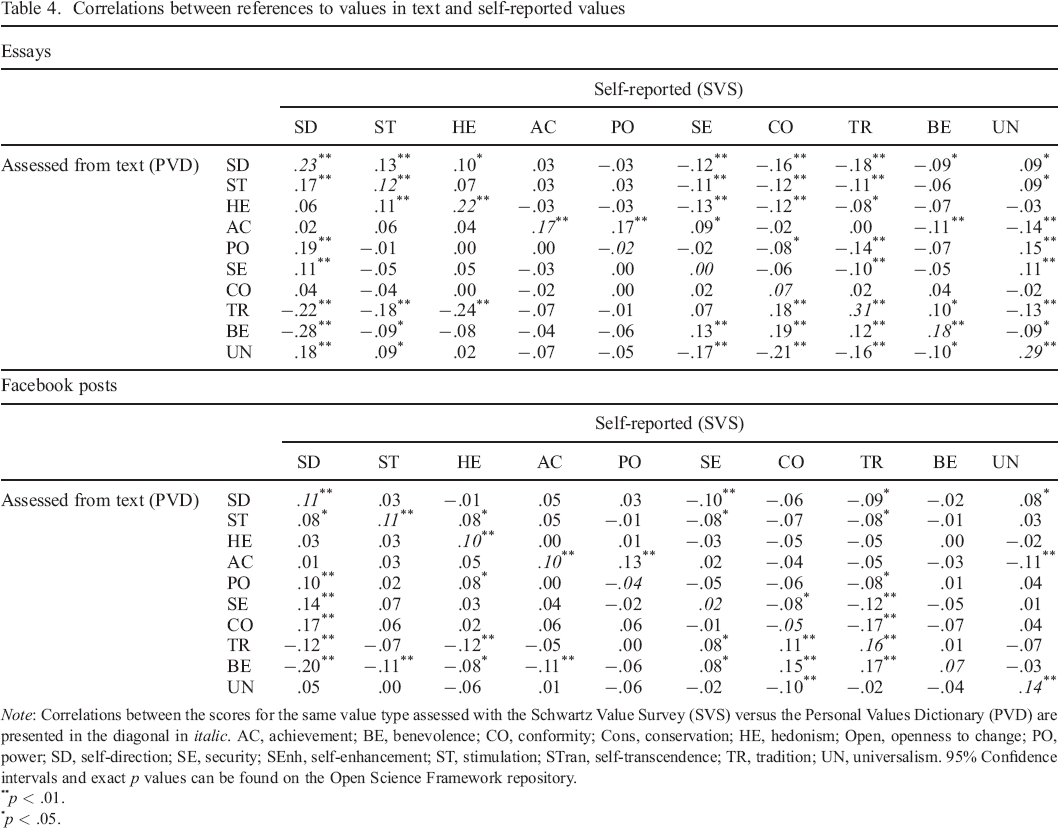
Note: Correlations between the scores for the same value type assessed with the Schwartz Value Survey (SVS) versus the Personal Values Dictionary (PVD) are presented in the diagonal in italic. AC, achievement; BE, benevolence; CO, conformity; Cons, conservation; HE, hedonism; Open, openness to change; PO, power; SD, self–direction; SE, security; SEnh, self–enhancement; ST, stimulation; STran, self–transcendence; TR, tradition; UN, universalism. 95% Confidence intervals and exact p values can be found on the Open Science Framework repository.
p < .01.
p < .05.
We examined correlations between the scores for the same value as measured by PVD and SVS (the leading diagonal in Table 4), as well as correlations with adjacent and opposing values. In both datasets, we observed significant positive correlations between references to the same value across the methods of measurement. In addition, the correlations with other values followed the sinusoidal pattern characteristic of Schwartz's values (Schwartz, 1992).
In the essays data, the positive correlations between scores for the same value were significant in 7 out of 10 cases. The effect sizes varied between .12 and .31, which is larger than typically observed when correlating linguistic measures with self–reports (Boyd et al., 2015; Chen et al., 2014; Gou et al., 2014). These comparatively strong correlations are not surprising, given that participants were explicitly asked to write about their values. The three values that did not correlate significantly with survey scores were power, security, and conformity. Moreover, although benevolence did correlate with the respective value, the correlation was even stronger with the value of conformity. We speculate that public expression of certain values is considered undesirable (e.g. power), whereas the expression of others is encouraged (benevolence), leading to discrepancies between values and their verbal expressions (Schwartz, Verkasalo, Antonovsky, & Sagiv, 1997). This speculation is partially supported by evidence that expressions of security and power values in text showed the strongest positive correlations with self–reported value of self–direction, and expressions of benevolence in text—with self–reported value of conformity. Therefore, expressing power and security values seems to be a sign of independence, whereas expressing benevolence is a sign of conformity. This is consistent with prior results indicating that conformity moderates value expression (Lönnqvist, Leikas, Paunonen, Nissinen, & Verkasalo, 2006).
In the Facebook dataset, 6 out of 10 correlations were significant, with effect sizes varying between .10 and .16. Although in this case the posts were not explicitly aimed at expressing values, the effect sizes were comparable with the essays dataset and similar to typical effect sizes identified in earlier studies (Boyd et al., 2015; Chen et al., 2014; Gou et al., 2014). Converging with the results from essays, power, conformity, and security did not correlate with the respective survey scores, but all three values correlated most strongly with the value of self–direction. Similarly, benevolence correlated with the values of tradition and conformity.
All four higher order values correlated positively with the respective SVS measures in the essays dataset, with effect sizes varying between .12 for self–transcendence and .33 for openness. In the Facebook dataset, all correlations were positive and statistically significant for openness to change (r = .16) and self–enhancement values (r = .10) and not significant for conservation (r = .05) and self–transcendence values (r = .05). Table 5 reports the correlations between the higher order values.
Correlations between references to higher order values in text and self–assessed values
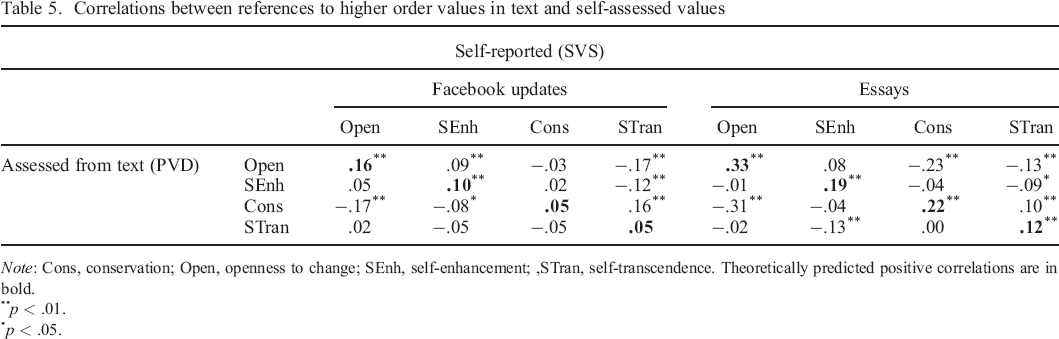
Note: Cons, conservation; Open, openness to change; SEnh, self–enhancement;, STran, self–transcendence. Theoretically predicted positive correlations are in bold.
p < .01.
p < .05.
Finally, we also estimated how accurately the PVD predicted a person's hierarchy of the 10 value types in self–reports and found an overall similarity of q = .41 (SD = .30) in the essays corpus and of q = .33 (SD = .31) in the Facebook corpus (distribution of the profile correlations can be found in the Supporting information). t–Tests indicated, in both cases, that the overall profile correlations are indeed significantly different from zero (95% confidence interval [CI] [.39, .44], t (632) = 33.567, p < .001; 95% CI [.31, .36], t (751) = 28.432, respectively) (see Rogers et al., 2018). Next, we accounted for the degree to which profile normativeness might have inflated the observed correlations. We found a distinctive similarity of q = .20 (SD = .35) in the essays corpus and of q = .10 (SD = .38) in the Facebook corpus. Both are significantly different from zero (95% CI [.18, .23], t (632) = 13.86; 95% CI [.07, .13] t (751) = 6.61, p < .001, respectively). A recent study evaluating similarity of self–reported and other–reported (close other) value profiles found an overall similarity of q = .80 and a distinctive similarity of q = .66. (Dobewall et al., 2014). This indicates that the PVD is able to predict the value hierarchy of a person, but it is clearly outperformed by an informant who knows the target well.
Gender, age, and political orientation differences in expressions of values
Research on individual values identified robust differences between groups along these socio–demographic lines. Men tend to attribute more importance to power, achievement, hedonism, stimulation, and self–direction values, whereas women tend to attribute more importance to benevolence, universalism, and security values (Schwartz & Rubel, 2005; Schwartz & Rubel–Lifschitz, 2009). For age, most evidence is at the level of higher order values, suggesting that self–transcendence and conservation values (social focus; communion) increase in importance with age, whereas self–enhancement and openness values (personal focus; agency) decrease with age (Datler, Jagodzinski, & Schmidt, 2013; Fung et al., 2016; Robinson, 2013). For political preferences, studies conducted in democratic countries (Piurko, Schwartz, & Davidov, 2011; Schwartz et al., 2010) suggest that the preference for the political left is consistently associated with universalism and benevolence and less consistently with self–direction. The preference for the political right, in contrast, is consistently associated with conformity and tradition and less consistently with security, power, and achievement. We expected to find similar differences in references to values in text.
Three corpora included the authors’ gender and age: COCA 2016–2017, personal blogs, and essays. The political blogs corpus included information about whether the text was posted on a Democratic–leaning (a proxy for political left) or a Republican–leaning (a proxy for political right) blog. Table 6 summarizes correlations between authors’ gender, age, political orientation, and references to values in their texts.
Correlations of references to values in text with the author's gender, age, and political orientation
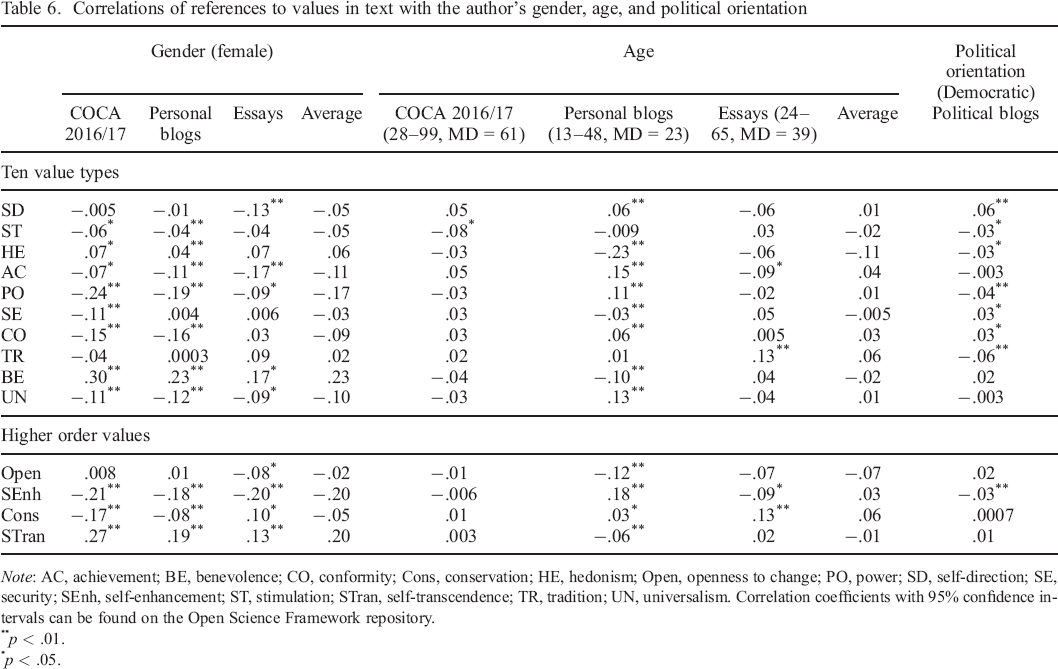
Note: AC, achievement; BE, benevolence; CO, conformity; Cons, conservation; HE, hedonism; Open, openness to change; PO, power; SD, self–direction; SE, security; SEnh, self–enhancement; ST, stimulation; STran, self–transcendence; TR, tradition; UN, universalism. Correlation coefficients with 95% confidence intervals can be found on the Open Science Framework repository.
p < .01.
p < .05.
We found the expected gender differences across the three corpora analysed. Women scored higher on self–transcendence values, specifically benevolence, and lower on self–enhancement values, specifically power and achievement. Notably, women also scored consistently lower on references to universalism values, which is not in line with the literature on gender differences in self–reported values. We speculate that one possible driver of this result is that, in the data examined, the discussions around broad societal issues that typically use references to universalism are not as welcoming to women as they are to men. These results might reflect how normative constraints linked to gender roles might regulate expressions of values (see Bardi & Schwartz, 2003).
Differences in references to values in text between age groups are in the expected directions for openness to change and conservation values: older participants refer more to conservation values (particularly tradition and conformity) and less to openness values (particularly hedonism and stimulation). Given differences in the distribution of age in the three corpora, interpretation of averages could be misleading. Although the relationships of openness and conservation values with age were consistent across all corpora, the relationships between self–enhancement and self–transcendence values with age were less so. In the ‘youngest’ corpus of personal blogs (13–48 years old), we observed more references to self–enhancement and fewer references to self–transcendence values among older participants. However, in the more balanced corpus of essays (24–65 years old), the opposite was true: references to self–enhancement decreased with age, while references to self–transcendence increased. Finally, in the more ‘mature’ corpus of literary fiction (median age = 61), no differences were observed. These results might point to cohort effects and nonlinearity of the relationship between age and values, at least when it comes to the self–enhancement versus self–transcendence value dimension.
Results pertaining to political orientation were mixed. Consistent with earlier findings based on self–reports, posts published on Democratic–leaning blogs referred more to self–direction values and referred less to tradition and power values compared with those on Republican–leaning blogs. However, these blogs also referred more frequently to security and conformity values and less frequently to stimulation and hedonism values, which is inconsistent with findings from studies with self–report measures.
Given the mixed nature of these results, we decided to test their robustness using a different dataset. The Manifesto Project (Krause et al., 2019) provides a dataset of manifestos of more than 1000 political parties around the world from 1945 until today. We selected a set of party manifestos that corresponded to our previous analysis: our corpus includes every manifesto published by the Republican and Democratic parties in the USA from 1960 to 2016. The manifestos were split by chapters, and the correlations are based on 416 observations with a total of 703 542 words.
Replicating the results of the political blogs analysis, we found fewer references to the value of tradition in the Democratic compared with the Republican manifestos (r = −.16, p < .001). We also observed significantly more references to universalism (r = .30, p < .001) and, overall, more references to self–transcendence values (r = .23, p < .001). Unlike the political blogs, the Democratic manifestos contained fewer references to self–direction (r = −.17, p < .001), and overall, openness to change values were less emphasized (r = −.18, p < .001).
The results from these two corpora highlight some robust differences in references to values between the left–wing and right–wing political discourse. In line with earlier survey studies, we found more references to self–transcendence (especially universalism) and fewer references to self–enhancement (especially power) values in the left–wing discourse. Also in line with earlier studies, tradition is more emphasized in the right–wing discourse. Interestingly, we also found a stronger emphasis on openness values in the right–wing discourse, which contradicts some of the earlier findings.
As we are examining manifestos of US political parties, it is important to consider the declared values of the Republican party when we interpret these results. One of the most important and long–held positions of the party is the support for individual freedom: individual responsibility, free market economy, and small government. In this particular case, the content of tradition that has to be preserved is individual freedom. If that is the case, words like ‘freedom’ and ‘liberty’ can be used when outlining positions on specific topics, such as gun ownership or environmental regulation, that are supportive of the preservation of the status quo (i.e. fulfil the motivational goal of conservation values). And whereas the supporters of the Republican party tend to value openness less than the supporters of the Democratic party, the language used by the Republican party itself contains more references to these values.
Overall, we find meaningful differences in references to specific values in texts authored by participants of different gender, age, and political views. We also find some discrepancies that point to normative constraints in expressions of values.
General Discussion
We developed and extensively tested the PVD, a dictionary for detecting references to personal values in text. Content validity was obtained by using experts to select candidate words for inclusion. The dictionary showed favourable internal consistency. A pattern of correlations between the value types that largely followed the theory–based circumplex structure of Schwartz (1992) was taken as the first evidence for the overall acceptable construct validity of the PVD. We found expected correlations between dictionary scores and scores for other dictionary–based methods (LIWC and MFD) indicating an acceptable degree of convergent and discriminant validity. While the concurrent validity of the PVD was limited by consistent but only small to moderate correlations between dictionary scores and correspondence to self–reported value score (SVS), associations with external variables were in the expected direction. Converging results indicate that the PVD reliably captures references to personal values in natural language and that such references are an original indicator of personal value priorities.
While the PVD scores and the self–reports of basic human values were related, it could be claimed that the overlap was not as strong as one would expect if the two measures are designed to measure the same psychological constructs. We found correlations between the counts of references to values in texts and the self–ratings of the same person in the range of rs = .10–.33 and of qs = .10–.40, which is indicative for small to moderate effect sizes relative to most social psychological research (Richard et al., 2003). Even though we were trying to capture a very complex construct across two wholly different modalities, only a few of the reviewed studies on the overlap between linguistic measures and self–reports found larger effect sizes (e.g. Kosinski et al., 2013). According to Cortina and Landis (2009), small effects, such as most correlations between PVD scores and other measures of personal values, can still be of importance whenever (i) they occur in the context of an intentionally inauspicious design (i.e. not designed to facilitate the emergence of an effect), (ii) the results are of theoretical importance, and (iii) have cumulative consequences (i.e. small effects accumulate into a meaningful effect over a number of instances; cf. Abelson, 1985). In our study, we analysed natural language; hence, differences in word frequencies are the consequence of innumerable factors outside of our control and condition (i) is met. With regard to condition (ii), we would like to refer to the theoretical debates that we referenced in the introduction. Condition (iii), the demand for cumulative consequences, is fulfilled through the huge amount of easily accessible digital text data that can be analysed with the PVD: even small to moderate correlations will allow for solid estimates of, for example, cultural differences between two social groups given enough analysis material. These estimates of concurrent validity were further not confounded by common method variance as the PVD scores were assessed with natural language processing and as the SVS was self–reported by the participants.
While the PVD performs on par or better than previously developed text–based measures of values, we acknowledge that we were unable to find correspondence between self–reported scores and references to values in text for several value types: such was the case with security, conformity, and power. We suggest evaluating references to values in text as an indicator on its own merit, complementing, but not identical to self–reported values. Supporting this view, the correlations between PVD scores and other text–based scores, in our case, the LIWC and MFD dictionaries, were significantly larger, and scores for security, conformity, and power displayed theoretically predicted correlations. In analogy to the established use of informant reports in personality assessment, dictionary–based methods have the potential to provide a more complete picture of a person and can be used to address new research questions that cannot be studied with self–reports alone (Vazire, 2006).
We argue that the unprompted expression of values in language is a behavioural indicator of personal value priorities that is qualitatively different from answering questionnaire items. Values conceptually refer to motivation and not action (Schwartz, 1992), and behaviours have a diverse range of other predictors beyond their corresponding values (Ajzen & Fishbein, 1977). It might not be easy to identify references to values in text because each value may be expressed in a variety of corresponding behaviours, and likewise, any single behaviour is an expression of the interplay of multiple values (Schwartz, 1992). It is therefore not surprising that others have previously found a discrepancy between self–reports of values and corresponding behaviours (Bardi & Schwartz, 2003). References to values in text are further subject to unique constraints and affordances. In the case of power, for instance, the social undesirability of this value may affect its expression in text. Values, even when assessed by self–reported instruments, are subject to desirability bias (Lönnqvist et al., 2006; Schwartz et al., 1997). It was argued that in case of user–generated texts, larger intended audiences make self–presentation concerns especially salient (Fox & Vendemia, 2016). If socially desirable responding differs between self–report and user–generated text, then this would naturally decrease the correlation we can find between these two forms of assessment. In support of this view, the difference between overall and distinctive profile correlations, which partially correct for social desirability by accounting for the sample mean (see Furr, 2008), was remarkably larger in Facebook than in the essay corpus.
We designed the PVD as a broadly applicable and convenient research tool. The theoretically grounded creation of this large dictionary and its rigorous validation ensures that it is applicable to a large variety of texts. The PVD can be readily applied by other researchers through widely used software such as LIWC (Pennebaker et al., 2015) or the respective r packages. The dictionary, extensive information on the validation procedures, as well as all r scripts that we used in our analyses are available on our OSF repository, making it easy to adapt, improve, and extend.
There are several considerations to keep in mind when applying the PVD. First, unlike questionnaire–based methods, its applicability depends on the value–expressiveness of studied texts: personal diaries, for example, are more likely to contain references to values than warehouse logbooks. Illustrating this point, in our analyses, the correlations between PVD scores and questionnaire scores were substantially higher for texts in which authors explicitly were asked to describe what is important to them than for general Facebook status updates. Second, specific terms from the dictionary could be misleading in specific contexts as a result of ambiguity. For instance, an analysis of dramatic texts can be tainted by the word ‘act’ being placed in the self–direction category of the dictionary. We suggest reading through the dictionary before using it in research, examining it for words that may be problematic in a specific application. While we believe the breadth of the dictionary should be sufficient to compensate for such noise in most use cases, a researcher may also start with the provisional dictionary and redo the EFA step on their own before applying the dictionary to a new corpus. This will ensure that the words representing values also co–occur in the corpus under study.
The PVQ was developed and validated based on the original 10 value typology. The most recently validated framework of Schwartz's values, the refined theory of basic human values (Schwartz et al., 2012), introduced finer distinctions to discriminate between 19 value types. Based on our analyses, we cannot say whether greater value specificity adds to the validity of the values dictionary (see Cieciuch, Schwartz, & Vecchione, 2013) or whether the consequently smaller number of words per value type would subtract from it. In most situations, however, the four higher order values performed better than the 10 value types, and the value typology captured with the PVD is to date still used most frequently.
Future work can extend the applicability and accuracy of the dictionary. In our analyses, we rely on word frequencies. The accuracy of the dictionary could potentially be further improved by accounting for word embeddings, such as negation, text sentiment, 6 and collocations. The dictionary can also easily be used to select features for machine learning.
We conducted a preliminary sentiment analysis on the essays corpus to test whether accounting for negations (e.g. ‘not’) and boost (e.g. ‘very’) and ignore (e.g. ‘but’) words would improve the correlations between PVD and self–reported values. Overall, sentiment analysis did not improve the concurrent validity of the PVD: average correlation dropped from r = .16 to r = .14. There was, however, a slight improvement in correlations for the three values that showed lowest criterion validity: power (r = .04 vs. r = −.02), security (r = .02 vs. r = .00), and conformity (r = .09 vs. r = .07).
We are looking forward to other researchers employing our dictionary and code in a wide variety of contexts. Whereas we focused in our analysis mainly on social media posts, works of fiction, and other self–expressive texts, it could also be worthwhile to use our approach for the analysis of political texts such as parliament speeches (Portman, 2014) and political propaganda material. The dictionary was developed on American English, which might limit its generalizability to other cultures. We are also hoping that the PVD gets widely translated into other languages. A German version of the PVD is currently being developed and validated by the authors.
Ethics statement
All data were anonymized and managed in accordance with the German Research Foundation's Guidelines for good scientific practice. Ethical approval was not required for the use of secondary data as per national and institutional regulations.
Acknowledgements
This research project originated from the “BIGSSS Summer Schools in Computational Social Science: Research Incubators on Data–driven Modeling of Conflicts, Migration, and Social Cohesion” (Volkswagen Foundation grant No. 92145). Peter Holtz's work benefited from EU grant No. 687916 (AFEL – Analytics for Everyday Learning). The authors would like to thank Tyler Amos, Sanja Hajdinjak, Marcella Morris for their contributions in the preparatory stages of the project. Open access funding enabled and organized by Projekt DEAL.
Author Contributions
HD and PH conceived of the project. HD, PH, LG, VP, and MMA devised the analytic strategy and the method of the study. HD, LG, VP, and MMA acted as expert raters for the provisional dictionary. MMA, PH, RB, and VP prepared the data for analysis. MMA conducted most analyses, with contributions from PH, RB, and VP. All six authors contributed to the preparation and revision of the final manuscript. MMA and VP prepared the supplementary information and managed the project's OSF storage. VP and PH supervised the project. [Correction added on 25 August 2020, after online publication: Author contribution section has been added in this version.]
Supporting Information
Supporting Information, per2294-sup-0001 - Development and Validation of the Personal Values Dictionary: A Theory–Driven Tool for Investigating References to Basic Human Values in Text
Table S1. Personal values dictionary
Table S2.1. Factors extracted for Self-Direction
Table S2.2. Factors extracted for Stimulation
Table S2.3. Factors extracted for Hedonism
Table S2.4. Factors extracted for Achievement
Table S2.5. Factors extracted for Power
Table S2.6. Factors extracted for Security
Table S2.7. Factors extracted for Conformity
Table S2.8. Factors extracted for Tradition
Table S2.9. Factors extracted for Benevolence
Table S2.10. Factors extracted for Universalism
Table S2.11. Words excluded after integration (after applying the “word is included if it appears in 2 corpora rule”)
Table S3. Internal consistency of each value type in PVD using standard scoring method with Spearman-Brown adjustment
Supporting Information, per2294-sup-0001 for Development and Validation of the Personal Values Dictionary: A Theory–Driven Tool for Investigating References to Basic Human Values in Text by VLADIMIR PONIZOVSKIY, MURAT ARDAG, LUSINE GRIGORYAN, RYAN BOYD, HENRIK DOBEWALL and PETER HOLTZ, in European Journal of Personality
Table S1. Personal values dictionary
Table S2.1. Factors extracted for Self-Direction
Table S2.2. Factors extracted for Stimulation
Table S2.3. Factors extracted for Hedonism
Table S2.4. Factors extracted for Achievement
Table S2.5. Factors extracted for Power
Table S2.6. Factors extracted for Security
Table S2.7. Factors extracted for Conformity
Table S2.8. Factors extracted for Tradition
Table S2.9. Factors extracted for Benevolence
Table S2.10. Factors extracted for Universalism
Table S2.11. Words excluded after integration (after applying the “word is included if it appears in 2 corpora rule”)
Table S3. Internal consistency of each value type in PVD using standard scoring method with Spearman-Brown adjustment
Supporting Information
Supporting Information, per2294-sup-0002 - Development and Validation of the Personal Values Dictionary: A Theory–Driven Tool for Investigating References to Basic Human Values in Text
Supporting info item
Supporting Information, per2294-sup-0002 for Development and Validation of the Personal Values Dictionary: A Theory–Driven Tool for Investigating References to Basic Human Values in Text by VLADIMIR PONIZOVSKIY, MURAT ARDAG, LUSINE GRIGORYAN, RYAN BOYD, HENRIK DOBEWALL and PETER HOLTZ, in European Journal of Personality
Supporting info item
Footnotes
Supporting Information
Additional supporting information may be found online in the Supporting Information section at the end of the article.