
Abstract
An approach of cooperative hunting for multiple mobile targets by multi-robot is presented, which divides the pursuit process into forming the pursuit teams and capturing the targets. The data sets of attribute relationship is built by consulting all of factors about capturing evaders, then the interesting rules can be found by data mining from the data sets to build the pursuit teams. Through doping out the positions of targets, the pursuit game can be transformed into multi-robot path planning. Reinforcement learning is used to find the best path. The simulation results show that the mobile evaders can be captured effectively and efficiently, and prove the feasibility and validity of the given algorithm under a dynamic environment.
Introduction
In multiagent systems it is quite an important and interesting endeavor to study the development of cooperative behavior among agents. Multi-robot cooperative pursuit is a popular multiagent problem. Based on the same conditions between predators and evaders, the pursuit game can be sorted into single object pursuit and multi-object pursuit. For the first part, this game has also been considered in many references (Yamaguchi, H., 1991; Swastik, K. & Chinya, V., 2005; Kok, J. K. & Vlassis, N., 2004; Yuko, I.; Sato, T. & Kakazu, Y. 2003; Vidal, R.; Shakernia, O.; Kim, H. J.; Shim, D. H. & Sastry, S. 2002); for the other part, Grinton, C. (1996) made use of Commitments & Conventions cooperative mechanism to explore the algorithm including the consistent commitments among predators to capture many static evaders. Schenato, L. et al. (2005) proposed a general framework for the design of a hierarchical control architecture that exploits the advantages of a sensor network by combining both centralized and decentralized real-time control algorithms to complete multi-object pursuit. Based on dynamic role assignment, a method for forming coordination multi-robot teams in the multiple mobile targets capturing has been proposed (Li, S. Q.; Wang, H.; Li, W. & Yang, J. Y. 2006). Cai et al. (2008) proposed a kind of multi-robot cooperative pursuit algorithm that allows fault injection dynamic alliance based task bundle auction. Based on these researches, in this paper we propose an approach of cooperative hunting for multiple mobile targets by multi-robot. In the present approach, there are two parts: one in which the sample data set by the attribute relationship between predators and evaders is created, association rule data mining technology is used to find out the interesting rules, then to build the pursuit team to every evader according to these rules; the other in which every pursuit team forecasts the position of its object in order to make sure of the predators' aim positions, consequently, we can transform the pursuit problem into the path planning problem and then use multi-robot reinforcement learning to choose the pursuit teams optimal actions strategies to capture evaders in the shortest time.
Description of pursuit problems
In this section, we concentrate on a collaborative problem in which n predators in a limitary toroidal grid environment X have to capture m different kinds of evaders. The expression of P={P1,…,P
n
} and E={E1,…,E
m
} stands for the collection of n predators and m evaders respectively. Predators and evaders are called for agents. Evaders have their styles R
Ej
, j∈m, R
Ej
∈ {I, II, III, IV} shows how many predators evaders could be captured by. Here we think that predators can judge evaders' styles. There are the fixed obstacles whose shape and size are random in X. The position could be destined for the mapping m:χ→{0,1}, such as ∀x∈χ, m(x)=1, well then x is an obstacle. If two grids have a same side, they are bordered upon. We mark the neighbor grid of x as A(x) and we can see |A(x)|⩽4 in the rectangle plane. We denote the positions of predators and evaders by X
P
(t)=(xP1(t),…,x
Pn
(t)) and X
E
(t)=(xE1(t),…,x
Em
(t)) respectively at time t, t∈T={1,2,…}. Any two agents can't stay in the same cell and each agent can only take one action which includes to stay the origin place or move to its neighbor grid that is not taken up at time t, that is X
k
(t+1)=A(X
k
(t))∪{X
k
(t)}, k∈P∪E. In this paper we formally assume that all agents know the environment map, however they don't know the objects' positions and styles at t=0 and thus all predators begin to search the pursuit area at that time. Here we adopt the circular searching, that is, the predators do their best to get to grids that haven't been scouted. With increasing the time, there is more and more probability of coming back to search. Hence we give every grid of the pursuit area a value, called searching expectation. For any grid x∈X at time t, its searching expectation is v(x,t). For predators when they are searching, v(x,t) of those grids is zero, which are occupied by obstacles or in the perceptive area of predators, but for other grids, their v(x,t) is updated by

where ΔNRi(t) denotes the difference of the number of grids that the predator can see at the neighbor time spot and N
X
is the sum of grids of the searching area. We assume that P
i
is at the grid x, the sum of v(x,t) for all grids in the perceptive area of P
i
is denoted by G(y,t) when it moves to the target grid y. In this paper we adopt local-max search strategy, that is, P
i
chooses the grid as the next step position whose G(y,t) is the maximal value. So, let NA(xRi(t)) denote the accessible grids set at time t, obviously we can conclude that NA(xRi(t))={x|x∈A(x) and m(x)=0} and let N
Ri
(y) be the set of all grids that can be apperceived by P
i
when it is at the grid y. Well then, when P
i
moves to y from x, its G(y,t) is updated as the following:

P i can choose the grid from NA(xRi(t)) as its expectation target position at time t+1 whose G(y,t) is the maximal value. We discuss two final successful capturing configurations: one in which the total number of predators in neighbor grids of the evader is more than the value of its style, the other in which evaders are surrounded by predators or blocked up in the border of X or the gap of obstacles. We show the initial and final circs of the second one as that seven predators hunt two evaders in Fig.1. The cooperative team can gain the reward S Ej after they capture the evader E j .
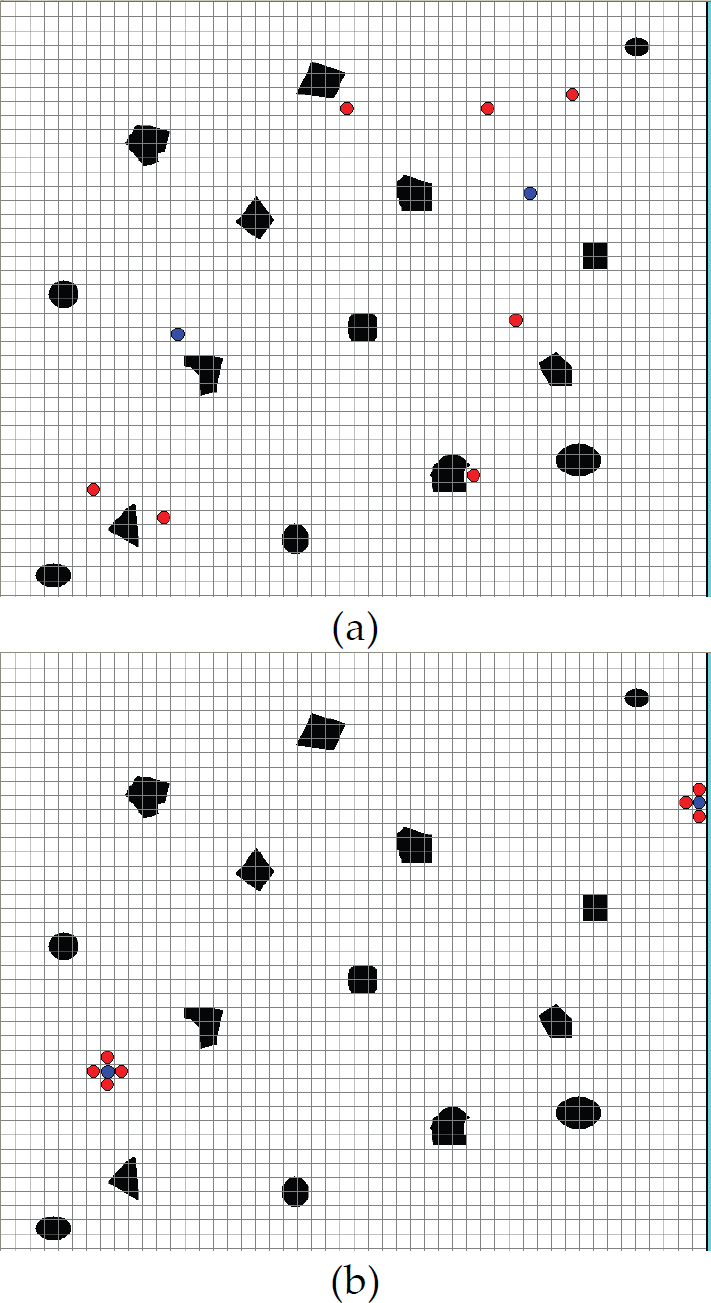
Sketch map of muli-robot successfully capturing the evaders (a) is an initial state before capture (b) is goal state where evaders were captured
There are many predators and evaders in the pursuit area. When some predator finds the evader, it will inform other predators. In this section, we use association rule data mining technology to distribute these predators to hunt different evaders effectively, which creates many pursuit teams. Then the members of each team work together to hunt their goals.
Definitions of association rule data mining with pursuit problems
Association rule was originally proposed by Agrawal and Srikant in 1993. They generalized it again (Agrawal, R. & Srikant, R. 1995; 1996). The aim of association rule is to find out the contact with different commodity (set) in the trade data base, that is, to look for the interesting contact in the appointed data collection. Through describing the potential relation rules between data sets in the data base, we can discover the dependence relations between many domains which are satisfied with the preconcerted threshold value of support and confidence. For discussing problems conveniently, we give several definitions of association rule with pursuit problems.
Definition 1
Let D j , D j ={P1,P2,…,P i ,…P n } be association rule mining data collection denoting that predators P i (i⩽n) hunt evaders E j (j⩽m), where P i is a pursuit robot. As an affair P i ={k1,k2,…,k r ,…k p }(i=1,2,…,n), the element in P i is called by an Item which is the description of the correlative attribute relation between P i and E j .
Definition 2
We assume that I={k1,k2,…,k
q
} (p⩽q) is composed of all items in D
j
. Any subset X of I is called item set. Association rule is the implication formula such as
Definition 3
The number of affairs including item X in D
j
is modeled as the support number of item X, namely σ
x
. The support rate of item X is figured as support(X),
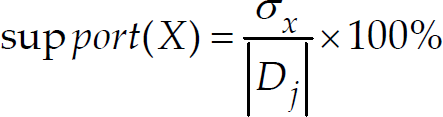
where |D
j
| denotes the affair number of D
j
. If support(X) is not smaller than the appointed smallest support, called minsupport, we can reckon X as a big item, conversely a small item. The support rate of X∪Y is the support rate of association rule

The smallest confidence which is designated by the user could be figured as minconfidence.
The process of creating pursuit teams is categorized into the followings: (1) finding out all of big items; (2) coming into being association rules through big items; (3) building the pursuit teams.
(1) Finding out all of big items: According to definitions, the frequency that these big items appear is at least as same as the appointed smallest support number. Firstly, we create the sample data set D Ej of hunting E j in Table 1.
Pursuit sample data set D
Ej

Pursuit sample data set D Ej
where k
r
(r⩽q) is the item of D
Ej
. In this paper, we assume that k1 is the resultant force F
ij
of P
i
who is pulled by E
j
and pushed by obstacles, F
ij
=F
x
+F
c
. According to the literature (Rimon, E. 1992), the function of gravitation potential is U
x
(P
i
)=1/2ξd
m
(P
i
,E
j
), where ξ is the coefficient of position plus, m=2 and d(P
i
,E
j
) is the distance between P
i
and E
j
. The minus grads direction of gravitation potential influences F
x
, that is, F
x
=-▽U
x
(P
i
)=-ξd(P
i
,E
j
). The function of repulsion potential is Eq.(5)
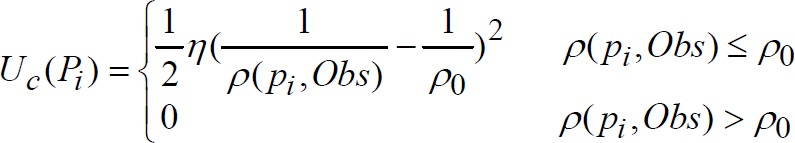
where ρ(P
i
,Obs) is the shortest distance between P
i
and obstacles Obs, ρ0 is the effect threshold of obstacles distance, in a general way, ρ0⩽min(d1,d2), d1 is a half of the shortest distance between obstacles, d2 is the shortest distance between E
j
and obstacles, and η is the coefficient of position plus. The corresponding repulsion is Eq.(6)

k2 is Cre
ij
which shows the degree of other predators dependability that P
i
hunts E
j
, if P
i
doesn't complete its task because of some reasons, its Cre
ij
would be lowered which straightly affects other predators decisions. So, we complete its updating rule of the following terms:

where C
s
is the times of P
i
capturing E
j
. C
f
is the times of failure, C
t
is the times of being in for hunting E
j
. ɛ1 and ɛ2 are updating thresholds. k3 is Pro
ij
which shows the probability of P
i
capturing E
j
, here we choose the frequency and actual effect of P
i
capturing E
j
in the latest time to depict its value, it is defined by Eq.(8)

where t is the currently time, t0 is the latest time which E
j
is captured, T is the longest actual effect after capturing E
j
and C
a
is the times of P
i
hunting different evaders. k4 is Rev
ij
that is the retained profits of P
i
after capturing E
j
, which denotes the margin of the reward (Rew
ij
) and the cost (Cos
ij
), that is, Rev
ij
=Rew
ij
−Cos
ij
, where Cos
ij
is the sum of communication cost, resource consumption, punishment about hunting failure or exiting to pursuit teams and so on. k5 is Eli
ij
which denotes the estimate whether P
i
have the ability to capture E
j
, here Eli
ij
=α·Cab
ij
+β, where Cab
ij
is the ability value of P
i
hunting E
j
, α and β is the corresponding coefficient. k6 is the current load state Pur_s
i
, if P
i
doesn't have any task, the value of Pur_s
i
is spare, then β>0; if P
i
is hunting one goal, the value of Pur_s
i
is busy, then β<0. P
i
stands for predator i. V
ir
is the corresponding value of P
i
and k
r
. We can conclude from the definition of k
r
that there are two types in V
ir
, continuous and discrete value. In this paper, we use Apriori algorithm to mine the Boolean association rules so that the value of classificatory and quantitative attribute should be transformed to Boolean values. We will introduce the transformation means as following:
Dispersing the value of quantitative attribute. “k1∼k5” are quantitative attributes, for the consistency of record amounts in every group, we disperse the five quantitative attribute based on same length or same distance method:
k1 is categorized into the followings: a1{Vi1∈[0,∞)}, a2 {Vi1∈ (−∞, 0)} k2 is categorized into the followings: b1{Vi2∈ [0.9,1)}, b2{Vi2∈ [0.5,0.9)}, b3{Vi2∈ [0.1,0.5)} k3 is categorized into the followings: c1{Vi3∈ [0,0.3)}, c2{Vi3∈ [0.3,0.6)}, c3{Vi3∈ [0.6,1)} k4 is categorized into the followings: d1{Vi4∈ (−∞,0]}, d2{Vi4∈ (0,200]}, d3{Vi4∈ (200,1000]} k5 is categorized into the followings: e1{Vi5∈ [0.5,1]}, e2{Vi5∈ [0,0.5)} Transforming the value of classificatory attribute. Pur_si is a classificatory attribute, which should be transformed to the Boolean type, then Pur_si is categorized into the followings: f1{Vi6=“spare”}, f2{Vi6=“busy”}.
For p i , if Vi1>0, Vi2=0.63, Vi3=0.35, Vi4=500, Vi5=0.61, Vi6=“spare”, then Table 1 could be transformed to Table 2 after above disposal.
Affair data transformed from

We can obtain the affair data base of all predator states through the homologous process.
(2) Coming into being association rules through big items: Here we employ conventional Apriori algorithm, and we note minsupport by the type of evaders in order that the pursuit team can not capture its goal because its scale is too small, that is, if the type of some evader R Ej is IV, it could be captured by four predators at least. Note that our affair data base has twelve sample records, minsupport=4/12≈33%. To make sure of the confident degree of the gained rules, minconfidence should be larger than the maximum of C ij . And C ij is updated constantly, if C ij is too low, we can gain so many uninteresting rules, which leads to be hard to build the pursuit teams. So the lowest threshold of minconfidence is destined for 0.5, that is, minconfidence=max(0.5, maxC ij ). We make the assumption any frequency item l and its nonempty subset s, if there is the following formula:
(3) Building the pursuit teams: We can judge whether P i choose E j as its goal or not from the gained association rules. In this paper, we therefore assume that k1, k2, k5 are the former attribute, k3, k4 are the back attribute for which should be in {c2,c3,d2,d3} theoretically, and k6 is the reference attribute. If this results in interesting rules such as A: a1^b2^e1^c3^d2[35%,72%], we can explain it: there are 35% of predators whose force pulled by E j is more than pushed by obstacles, who have the abilities to hunt the goal, whose dependability degree is good, if it will hunt E j , the probability of success more than 0.6 and the value of its reward over 0∼200 is 72%. We should scan the origin sample data item D Ej in the light of these association rules, then pick up 35% of predators who is satisfied with a1,b2,e1. For the above case, 12times0.35≈4, then the cooperative team can be made of these four eligible predators to hunt the same goal. However, if the amount of appropriate predators is more than R Ej , it is preconditions of choosing partners that we should keep the stability of system. Some predator has priority whose Pur_si is spare. If their Pur_si is same, we should think about Pro ij and Rev ij . Assuming V ij =ω1·Pro ij +ω2·Rev ij , where ω1 and ω2 are scale coefficients respectively, the predator with bigger V ij will be chosen firstly; provided that the same predator is fit for different teams, it will be compartmentalized to the team that its confidence of the corresponding association rule is higher. It is one perfect condition of A. If we mine rules that there are items which are not in our assumptive bound, such as B: a2^b2^e1^c1^d2[40%,72%], we also scan the data item D Ej and find out those predators which are fit for B, then ignore them. Furthermore, we make use of the same support and confidence to mine interesting rules which is satisfied with hypothesis condition from the leaving predators (12-12times0.4≈8). If we find C: a1^b2^e2^c2^d2[37%,75%], we choose the predators which is satisfied with C to join the pursuit team. We can conclude that there are about 3 (8times0.4≈3) predators. If R Ej =IV, we let U ij =ω3·F ij +ω4·Cre ij +ω5·E ij , where ω3 and ω4 and ω5 are scale coefficients respectively. Well then, we choose the leaving predators in D Ej whose U ij is the highest value to join the pursuit team. And circulating the process, we can build the cooperative team to E j , called CG(E j ).
Forecasting the mobile positions of pursuit objects
In this part we propose a multi-robot cooperative pursuit algorithm. When the dynamic evaders appear, we use the association rule mining data technology to build cooperative teams to different evaders. The members of CG(E
j
) coordinate their actions to hunt E
j
. We assume that evaders can move randomly without pursuit threat, contrarily evade intellectively. To capture the intelligent evaders, predators must forecast the positions of goals. It is the aim of P
i
∈CG(E
j
) that P
i
gets to the neighbor grid of the goal, which makes the distance d(x
Pi
(t),x
Ej
(t)) from itself to the goal shortest. E
j
does its best to evade the predators. According to the pursuit definition, the contribution probability of every predator in A(x
Ej
(t)) is 1/R
Ej
. We assume that the distance, obstruction and surrounding contribution of pursuit members are DC=∑1/d(x
Pi
(t),x
Ej
(t)), OC=1/NA(xEj(t)), EC=∑θi,i+1(t)/2 respectively in the alert range of E
j
, where NA(xEj(t)) is the number of neighbor grids that E
j
can get to and θi,i+1(t) is the anticlockwise angle between neighbor predators and E
j
at time t. So, we can compute the probability of capturing E
j
as following:
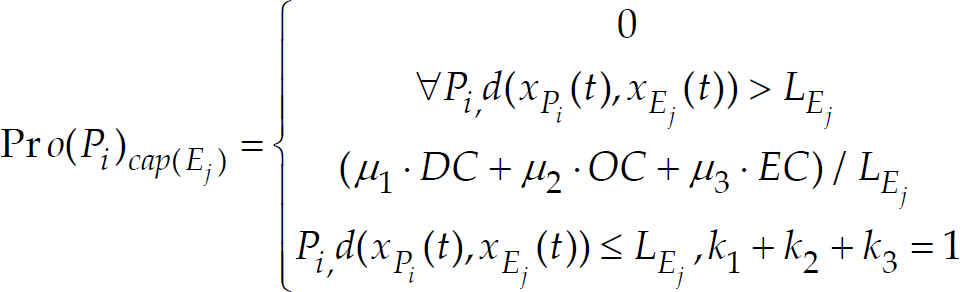
P i anticipates that the intelligent E j will choose the cell as its position from A(X Ej (t))∪{X Ej (t)}, which makes Pro(P i )cap(Ej) smallest at time t+1. So, P i moves to the goal position from A(X Pi (t))∪{X Pi (t)} whose d(x Pi (t+1), x Ej (t+1)) is the shortest.
To avoid the conflict with predators, if different predators who are in the same team choose the same grid as its target position, the predator who is near to the evader has the priority to hold its target position next t. If members who belong to the different teams choose the same cell as its target position, the predator who is in the evader's alert range has the priority. We assume that P=k1·ΔDC+k2·ΔOC+k3·ΔEC is the predator's each action contribution to capture the evader. If any two predators who are in the different teams are all in the alert range of their objects, the predator whose P is higher has the choice priority. On the contrary, the predator that is near to its object has it. After confirming the aim position, we can transform the pursuit problem into the multi-robot path planning problem based the known environment. One of the key problems for pursuit teams is the problem of coordination: how to ensure that the individual decisions of the predators result in jointly optimal decisions for the team.
Reinforcement learning (Sutton, R. S. & Barto, A. G. 1998; Kaelbing, L. P.; Littman, M. L. & Moore, A. W. 1996) is the problem faced by an agent that must learn behavior through trial-and-error interactions with dynamic environments, and it has been applied successfully in many single agent systems for learning the policy of an agent. Learning from the environment is robust because agents are directly affected by the dynamics of the environment. In principle, it is possible to treat a multiagent system as a ‘big’ single agent and learn the optimal joint policy using standard single-agent reinforcement learning techniques and therefore in this paper we are interested in fully cooperative pursuit systems in which the predators have to learn to optimize a global performance measure. Q-learning (Watkins, C. J. & Dayan, P. 1992) is one of important reinforcement learning algorithms, which is one kind of model-free reinforcement learning algorithm that is based on dynamic programming. In essence Q-learning is a temporal-difference learning method. In this paper we are interested in using Q-learning to learn the coordinated actions of many groups of cooperative predators to find out the best path of capturing objects without collision between agents. So, we should think the pursuit team as a big agent. We can use Q-learning to directly compute the approximation of an optimal action-value function, called Q-value, by using the following update rule:

where Q
t
is an estimate of the predators' state-action pairs at time t, s
t
, a
t
, α
t
, γ, r
t
are state, action, the learning rate, discount factor and reward respectively; 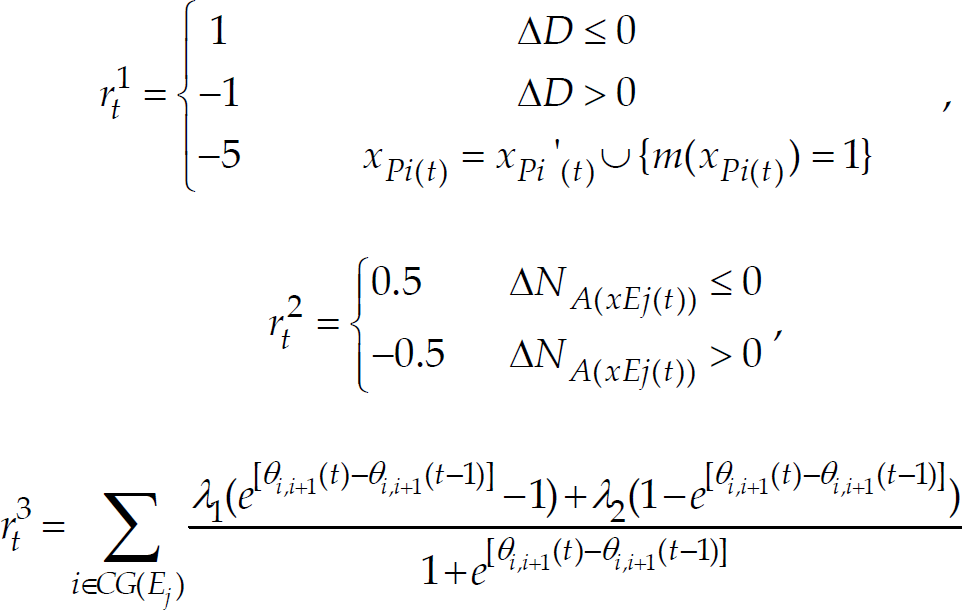
where Λ1=1, Λ2=0 if 0<θi,i+1(t)⩽/2 and Λ1=0, Λ2=1 if /2<θi,i+1(t)⩽.
To evaluate the approach proposed in this paper, we perform simulation experiments on an instance of the pursuit problem in a 360times250 rectangle area which is divided to 900 toroidal grids of 10times10. The obstacles are constant solid areas. The predators and evaders are all 10times10 cycloidal bodies. The alert radiuses of all of agents are same to be 3. We mark every agent with the ID number. If the evader is captured, then the other evader with the same style is relocated at new random positions. They have perfect communication system and same speed (move one cell distance each time). After capturing its object successfully, the cooperative team is rewarded by the third power of the evader's style, which is distributed to every member averagely, then the cooperative team is dismissed.
We use the same initial condition to compare our algorithm (after convergence) which we call it A with the algorithm proposed by Zhou, P. C.; Hong B. R. and Wang Y. H. (2005) which we call it B under above environment (ten predators hunt four evaders). A sample configuration is shown in Fig. 2(a). We take the capturing time of pursuit teams in each experiment as the evaluation index. From these results of A and B, we can find that the capturing time is little different for one algorithm of every experiment, however, the average time is much different in them. And Fig. 2(b) shows the reward comparison between them. We take one sample every ten experiments for the clear results. We can find that, there is a holistic performance increase of 18 percent of our algorithm. These can be explained as following: 1) we choose the pursuit members after contrasting the current state with the historical factors in A, which is relatively general, but case-based reasoning is used, which could lead to its adaptability worse in term of historical cases only under dynamic multi-robot environment. 2) It is assumed that evaders move randomly and predators have not learning ability in B, while in A we think about two conditions, moving randomly and evading intellectively, and reinforcement learning is used to choose the best actions which is more satisfied with the practice. So, A is better than B.

Graphs of different pursuit algorithms in the same environment
To test the effect of different decision mechanisms of building pursuit teams to capturing results, we compare the stochastic selection strategy(1) with the selection strategy based on case reasoning and assistant decision matrix(2) and the selection strategy based association rule(3) proposed in this paper. Under the same experiment environment, we increase the number of evaders incessantly from four to ten. The results for three algorithms are displayed at Fig.3. It is clear that the result based on association rule is the best which takes the least time, and the result of the stochastic selection strategy is the worst. This is because there are many factors considered such as ability, credibility, force and cost of predators, and so on, then to build reasonable cooperative teams to the special goal, which can improve the efficiency while avoiding to waste resources.

Results of different choice strategies
At last, we choose the same pursuit team to test two pursuit algorithms, one is based on reinforcement learning, and the other is the greedy actions strategy. We take the average pursuit benefit as the evaluation index, that is, how much the predator gain when it moves one grid every time. Table 3 shows the results. We see that the pursuit algorithm based reinforcement learning is better than the other. It is because that the predators are selfish agents, the greedy mechanism makes them run short of cooperation, then which cannot make the team profit most, however, our algorithm use the learning mechanism to make the pursuit members with coordination and cooperation each other, which is sure that the team reward is optimal when every predator chooses its best path.
Pursuit benefits of different learning mechanisms

In this paper, a multi-robot cooperative pursuit algorithm is proposed. Firstly, we use association rule data mining technology to choose the goals for every predator. Then the cooperative team for the appointed goal is composed of the predators whose goal is same. Secondly, the members of the cooperative team coordinate to hunt their goal. Through forecasting the position of evader, we transform the pursuit problem to the path planning problem and use multi-robot reinforcement learning to choose the best action strategies. Experimental results showed that the proposed algorithm could be used to achieve the optimal solution. However, confidence will affect the result of building teams. If it is higher, we could not find the suitable interesting rules to build pursuit teams. On the contrary, we could find the improper teams. Future work should examine more appropriate confidence. Furthermore, we use reinforcement learning to solve out the cooperative problems in the course of hunting evaders. However, both the state and action space scale exponentially with the number of predators and evaders, rendering this approach infeasible for overfull robots, which can affect the hunting efficiency. Consequently we should find out a new method to reduce the number of state and action pairs and then improve the learning speed. In addition, we will expand our algorithm ulteriorly to apply it to the unknown pursuit environment. To resolve the conundrums is a challenge.