
Abstract
The improvement of odometry systems in collective robotics remains an important challenge for several applications. Social odometry is an online social dynamics which confers the robots the possibility to learn from the others. Robots neither share any movement constraint nor access to centralized information. Each robot has an estimate of its own location and an associated confidence level that decreases with distance traveled. Social odometry guides a robot to its goal by imitating estimated locations, confidence levels and actual locations of its neighbors. This simple online social form of odometry is shown to produce a self-organized collective pattern which allows a group of robots to both increase the quality of individuals' estimates and efficiently improve their collective performance.
Introduction
The problem of exploring an unknown environment is critical to most intelligent organisms. Many robotics applications require positioning methods to carry out tasks. Several solutions to this problem have been proposed and implemented. Among these, odometry is probably the most used as it provides easy and cheap real time position information by the integration of incremental motion information over time. However, it causes an accumulation of errors during the movement of the robot which undermines the overall success of the methodology. Different approaches have been implemented to deal with odometry's errors (Chong & Klemman, 1997; Wang, 1988; Martinelli, 2002), mostly by using Kalman filters (Larsen et al., 1998; Martinelli & Siegwart, 2003). The Kalman filter estimates a vector state containing the robot position and the parameters characterizing the odometry error introduced by the designer. For instance, in (Roumeliotis & Bekey, 2002), each robot measures its relative orientation and shares the information with the rest of the group. Although the Kalman filter is an efficient recursive filter, it requires external information, introduced to the robots, that models the environment. In other implementations as in (Roumeliotis & Rekleitis, 2004), the robots are equipped with a compass which increases the efficiency of the filter, but relies on the use of an absolute orientation.
Other approaches for exploring the environment are based on map construction, which are costly in computational terms. Most of these implementations build maps incrementally by iterating localization for each new reading of each sensor on a robot. Thrun and colleagues (Thrun et al., 2000) create a map of indoor environments combining the idea of posterior estimation with incremental map construction using maximum likelihood estimators, whereas in (Sim & Dudek, 2004), the authors deal with the automatic learning of the spatial distribution given a set of images offered by all the members of the group, thanks to a centralize system which takes care of all the information.
Some applications in multirobot exploration are implemented without using odometry or dead-reckoning techniques. Some of these implementations rely on the use of static robots which are not allowed to move reducing the effectivity of the group. In (Karazume et al, 1996), a group of robots remains stationary while the other team is in motion. The moving group stops after some steps and becomes a landmark for the others that take the role of moving robots. In (Grabowski et al., 2000), only one robot is allowed to move while the others act as immobile landmarks, while in (Rekleitis et al., 2001) just one robot remains stationary when the rest of the group can navigate. These approaches either require synchronous communications between all members of the team or a central processing unit. In (Nouyan et al., 2008), a chain between two specific areas is created and the group can follow it to the goals. The robots in the chain are not able to move; consequently a direct relationship exists between the number of robots and the distance between the goals. In (Vaughan et al., 2002), each robot shares its best known path to goal based on landmarks with a central computer. The group has to be permanently in contact with the data center; therefore the environment must be properly configured before setting up the experiment.
While being successful in achieving their goals, these frameworks present several limitations: i) they are computational consuming as a result of the Kalman filters and maps, ii) some robots are not allowed to move while others are tracking distance between them, representing in this way a misuse of resources iii) robots must maintain visual contact at all times with the rest of the group, and iv) in some cases robots have to communicate with a central device to update or download maps, synchronize movements, or update positions.
In this work, we analyze and study a localization strategy, introduced in (Gutierrez et al, 2008a), in which robots neither share any movement constraint nor access to centralized information. This solution exploits self-organized cooperation in a group of robots to reduce each individual location error. In a nutshell, each robot's knowledge consists of an estimate of its own location and an associated confidence level that decreases with the distance traveled. This information is purely local and results from individual experience with the environment and other robots. In order to maximize its confidence level, each individual updates its estimates using the information available in its neighborhood. Hence, each individual will adopt the estimate of its immediate neighbors with a probability that increases with the confidence level difference. This adaptive dynamics, which we call social odometry, confers to each robot the possibility to learn from others, by imitating estimated locations that offer higher confidence levels. Estimated locations, confidence levels and actual locations of the robots dynamically change in order to guide each robot to its goal. This simple online social odometry allows the population of robots to both reduce individual's errors and efficiently reach a common objective. Moreover, to the best of our knowledge, this is the first collective navigation system in which a minimal local communication system is successfully used to promote an efficient collective performance, devoid the need of stationary robots.
The paper is organized as follows. In Section 2 we detail the dead-reckoning problem. Section 3 introduces the task used to study the social odometry, the experimental setup, and the behavior of the robots. In Section 4, we describe the experimental setup and the social odometry algorithm. Experimental results are presented in Section 5, where details of our solution and its performance are discussed. Section 6 concludes the paper and suggests future developments.
Mobile Robot Positioning
Dead reckoning is a simple mathematical procedure for determining the location of a vessel given its direction and velocity. The simplest implementation of dead reckoning in robotics is odometry, in which a travel path is derived from sensors computing the movement of the robot.
However, the accuracy of odometry measurements strongly depends on the kinematics of the robot (Klarer, 1988). Typical sensors for robots with a differential drive system are incremental encoders. Incremental encoders are mounted into the drive motors to count the wheel revolutions. A robot can perform odometry using simple geometry equations. Its estimated position will be related to the nature of the movement, as described by the following kinematics equations.
At each step the left and right wheel encoders show an increment of N
l
and N
r
pulses, respectively. The incremental travel distance for each wheel at each time k (ΔU
l
and ΔU
r
) may be written as:

where c m is the conversion factor that translates encoder pulses into linear wheel displacement, D n is the nominal wheel diameter, C e is the encoder resolution and n is the ratio of the reduction gear between the motor and the driver wheel.
After determining the displacement of each wheel, the movement of the centre point c of the platform is obtained by computing the linear (Δρ) and angular (Δθ) displacement of the center as follows (see also Figure 1):
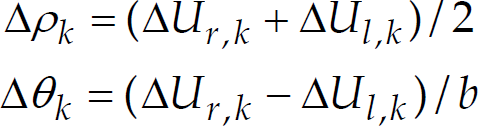
where b is the wheelbase of the robot measured as the distance between the two ideal contact points between the wheels and the floor.

Path taken by the wheels of a robot during a turn.
Then, let the location L of a robot at time k-1 be:

where (x
k-1
y
k-1
) are the Cartesian coordinates and θ
k-1
is the orientation with respect to a global reference frame. Thus, a rotation Δθ
k
and a translation Δρ
k
move the robot to a new location L
k
:

Equation 4 is not taking into account problems such as slippage, unequal wheels diameters or wheels misalignments. These errors can be classified as either systematic or non-systematic errors (Borenstein et al, 1996). Systematic errors can be modeled and corrected (Borenstein & Feng, 1996), while the non-systematic ones cannot be corrected and many classical techniques have been implemented to cope with them (Chenavier & Crowley, 1992; Chong & Kleeman, 1996).
When modeling non-systematic errors, each robot, apart from its position, also computes the distinctive error ellipse that represents a region of uncertainty in which the actual location lies (see Figure 2).
Growth of uncertainty region about localization while performing a straight line movement.
This region grows with the distance traveled, and it is reset to zero when the robot can localize itself exactly thanks to an environmental landmark (entering one of the two areas in our case). The error ellipse model is based on the covariance matrix (P) of the robot's location. We define the actual state and its covariance (Chong & Kleeman, 1996) as:

where A k and W k are the jacobians of f(·) with respect to L k-1 and U k , the latter representing the (Δρ, Δθ) vector and Q k is the covariance matrix of U k . The covariance matrix P 0 has an initial value of 0.
We have devised a task of central place foraging (Balch, 1997) in which robots need to explore the environment to find resource sites and bring items back to a central place. Experiments take place in a bounded arena with two distinctive sites: A resource site and a central one. If one considers the typically used ants' metaphors, one can imagine the first as food and the second the nest of a colony. As a final goal, robots need to go from the central place to the resource site, back and forth.
The robots can perceive the central place and the resource site only when they are closer than a threshold distance, defined by their limited sensorial capabilities. Initially, robots are randomly scattered in the arena and they explore the environment to locate both areas. Robots rely on odometry to maintain an estimate of the location of each area (central place and resource site). As soon as a robot comes back to an area, the corresponding location estimate is reset and odometry errors affecting this estimate are discarded.
In an ideal case, robots would make no mistake in guessing the location of the two areas. They could travel endlessly from one place to the other without drifting away. As soon as errors are introduced in the odometry system, estimated locations differ from true locations. A robot may not manage to go back to a given area, and may end up lost. In that case, the robot is doomed to explore again the environment to find the area.
To reduce the impact of odometry errors, robots keep in memory both estimated area locations and share this information among them. Being the communication range limited, a robot may update its estimates only when it encounters another robot.
Methods
Experimental Setup
Our experiments are carried out using simulation software based on ODE3. The arena is a bounded square area of L×L m2 (3×3m2, 3.5×3.5m2, 4×4m2 or 4.5×4.5m2) and the robots are randomly distributed in a specific area of the arena at the beginning of the experiment. The ground of the arena is white except for the two goal areas: central place is a black circle of 20 cm radius and the resource site is a grey circle of the same dimensions.
Robots are modeled as a cylindrical body of 7 cm. diameter. Motion is achieved by a differential drive system composed of two wheels with encoder sensors. Robots can perceive obstacles thanks to 8 infrared sensors distributed around the body. Robots differentiate areas using an infrared sensor directed to the ground. A specific simulated range and bearing communication board (Gutierrez et al, 2008b) allows robots to send messages to each other when their interdistance is less than 25 cm. Additionally, a robot receiving a message has also knowledge about the relative distance of the emitter (range) and its relative direction (bearing).
We introduce errors to simulate the imperfect response of the range and bearing sensor. Noise is added to the bearing

where k
l
and k
r
represent the nondeterministic parameters of the motor drive and the wheel-floor interaction. These values are randomly chosen from a uniform distribution, being limited to
The estimated location of the last visited area is more accurate than the previous one since odometry errors increase with the distance traveled. While moving from one area to the other, if a robot encounters another robot, it transmits its estimated location of the last visited area. Hence, each robot has the opportunity to adopt the estimates of other robots present in their neighborhood.
Since robots do not share a global coordinates system, they rely on the range and bearing of each other to communicate locations. Figure 3 shows how information about the estimated location of area Y is transmitted from robot i to robot j.

Robots sharing information about the estimated location of area Y.
In a first step, robot i transmits its estimate of the distance dy
i
and direction φ
i
of area Y to robot j. For the direction, the value transmitted is the angle α, obtained from φ
i
using the communication beam as reference axis: α = φ
i
− γ
i
. In a second step, robot j transforms the received data into its own coordinates system. First, it calculates the direction pointed by robot i as φ
j
= γ
j
+ α -pI, followed by the calculation of the location loc
j
= (x, y) of area Y. This computation takes into account the transformation to its own reference frame and integrates robot i information in the following way:

After receiving a communication, robot j has two different locations loci and loc
j
at hand. At this stage, robot j has the opportunity to adopt (or not) the estimate of the neighbor depending on its neighbor confidence level. Given that estimates get worse with distance traveled, the robots use the inverse of the distance traveled as a confidence level of their guess location. This confidence level, denoted by ε
i
for robot i, respectively ε
j
for robot j, is part of any communicated location and informs about the reliability and quality of the information. We consider that, in order to produce a new guess location (loc_up
j
) each robot takes into account all information available, but weights its sources in a different way. To calculate loc_up
j
, we adopt the so-called pairwise comparison rule (Traulsen et al., 2006; Traulsen et al., 2007; Santos et al., 2006) often adopted in evolutionary/social dynamics studies, to code the social learning dynamics, which makes use of the Fermi distribution (see also Figure 4):

where β measures the importance of the relative confidence levels in the decision making. For low values of β, the decision making proceeds by neglecting the confidence levels whereas for high value of β, we obtain a pure imitation dynamics commonly used in cultural evolution (Hammerstein, 2003) defined by a sharp step function. In the first case, the confidence level works as a small perturbation to a simple average between the two estimates, while in the latter, each robot is ready to completely neglect the estimate which has smaller relative confidence.
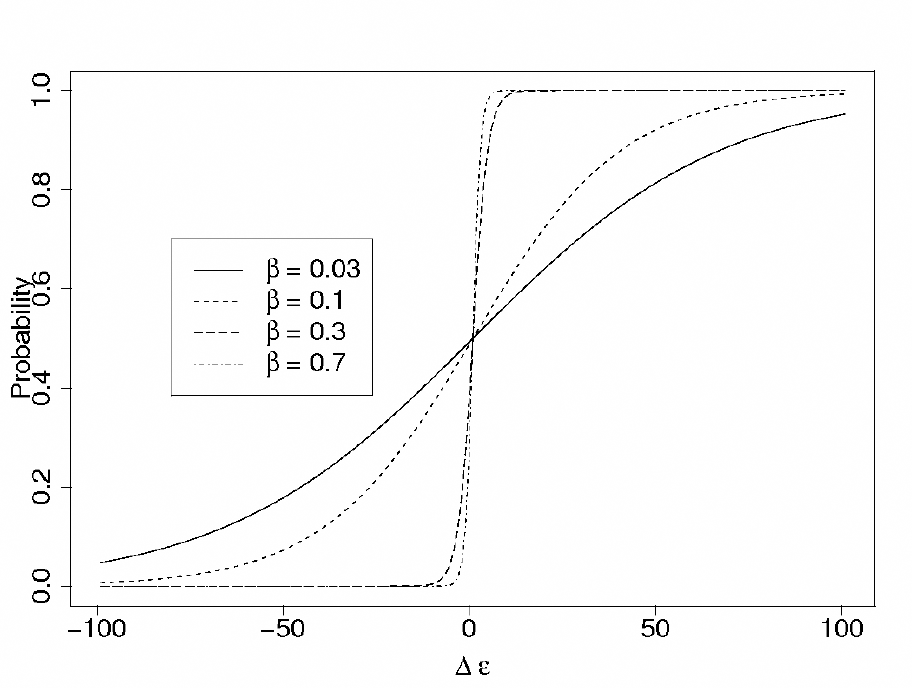
The Fermi function which allows robots to decide between their own estimate and the information provided by the others.
Hence, we use a weighted average to obtain the new location (loc_up
j
) and confidence level (e_upj) using the Fermi function as shown in Equation 9.

In the following, we report results of simulated experiments with 30 robots where the outcomes with and without imitation dynamics among robots are compared. Each situation tested was repeated 30 times. The performance of the robots in the foraging task under study is measured as the number of total round trips completed from the central place to the resource site and back during one simulated hour.
We implement 4 different scenarios (see Figure 5), where robots are located in a random initial position and orientation inside an area of 50 cm radius and targets have an area of 20 cm radius. For each configuration environment we modified i) the surface of the arena and ii) the number of robots involved in the experiment from 1 to 30 robots set.

Configuration of an arena of L2 meters area, for the 4 different scenarios.
We first study the time it takes for all the robots to locate both goals areas. Figure 6a shows this time for a set of 30 robots in a experiment of 4×4 m2 arena with imitation based on c = 0.5 (see equation 8). A comparison between a non-imitation dynamics set-up and an imitation dynamics one with a fixed c = 0.5 value is shown in figure 6b as an average of experiments in the 4 different size areas and 4 different scenarios. With few robots, the two behaviors perform equally well, which is explained by the infrequent encounters of the robots and the consequent low amount of communications. As the number of robots in the experiment increases, we clearly observe that the use of imitation allows the robots to find the areas faster. With imitation dynamics, robots are intrinsically carrying out a recruitment process which speeds up the initial exploration phase, getting a 40% reduction of time for a group of 30 robots.

(a) Comparison of the time employed for a group of 30 robots to locate both goal areas. Experiment is set up for a non-imitation dynamics set-up (blank) and imitation dynamics one with c=0.5 value (grey) algorithm in a 4×4m2 arena. Each box comprises observations ranging from the first to the third quartile. The median is indicated by a horizontal bar, dividing the box into the upper and lower part. The whiskers extend to the farthest data points that are within 1.5 times the interquartile range. Outliers are shown as dots. (b) Comparison of the average time employed for a group of 30 robots in 4 different arenas size and 4 scenarios. We compare the number of times robots make a complete travel from one goal to the other with different imitation choices.
Later we focus on the analysis of the algorithm's performance related to the non movement-error implementation. We carry out a comparison of different behaviors:
Figure 7 shows the improvement of social odometry for a set of 30 robots in 4 different arenas size in one hour experiment. Without imitation, robots rely solely on error prone odometry to find the areas. Once lost, they have to explore the environment and find the areas by chance, which explains the poor performance. In the no odometry error case, robots know accurately the location of both areas. In any of the four scenarios the best performing β for local imitation is statistically improving the results compared to the global imitation. This is because by using a global knowledge, robots take at each time step the estimate of all their partners, the ones with reliable information and the ones that are already lost. Interestingly, the covariance knowledge behavior does not show statistically different performance with social odometry using the best performing β.

Task performance for the different imitation choices with a set of 30 robots in an arena of (a) 3×3 m2, (b) 3.5×3.5 m2, (c) 4×4 m2 and (d) 4.5×4.5 m2.
Nevertheless analyzing how the area of the arena and the distance between the goals decreases the efficiency of the robot, we can notice a relationship between β and d (distance between the centre of the two goal areas).
Worst situation for the social odometry implementation is when a robot travels from the resource site to the central place and comes back without finding any other communicative robot till the end. In this case the confidence level difference is |Δε| = 2d and the best performing (3 creates a situation in which c = 0.6. This suggests robots can set up the optimal β knowing the distance between both goals. Robots could tune (3 while they are performing the task.
Finally, we show in Figure 8 how the number of robots modifies the efficiency η (related to the non movement-error implementation) in a 3×3 m2 arena with the better (3 performance. We observe a maximum η for a set of 11 robots going slightly down for higher number of robots. This is due to the amount of agents in the same path that disrupt communication between robots and makes robot navigation slow. This disruption is strongly dependant of the arena size. Results suggest that a high density of robots disrupts performance and there is most likely an optimal density to carry out the foraging task as reported in (Goldberg & Matarić, 1997). We also see that social odometry allows the robots to cope with density to some extent and have performance that scales linearly in a wide range of situations. Nevertheless the improvement with respect to the non-imitation dynamics situation doubles its performance for all the experiments.

Efficiency related to the non movement-error implementation (white) for a communication based algorithm with the best performing β (grey) and a non communication implementation (black).
In this paper we have described a social strategy in which robots use pairwise local communication to share knowledge about specific locations to improve their performance in a foraging task. By letting the robots use the estimates of others, we engineer an efficient and decentralized knowledge sharing mechanism which allows the robots to achieve their goals, both from an individual and group perspective. This simple mechanism drives the system to a successful collective pattern that none of the individuals is able to achieve independently.
Moreover, we show that local imitation is more effective than global imitation which would additionally require either more expensive devices or a central system taking care of routing robots' communications. Furthermore, decentralized systems are often associated with better scalability of the results with the number of robots.
We also compare social odometry with a fusion mechanism based on the covariance matrix, in which robots have an innate knowledge of the non-systematic errors model. Social odometry does not rely on any internal model provided to each robot, but exclusively on the self-organized nature of collective dynamics (Buchanan, 2007) and knowledge sharing. This has obvious advantages, given that less effort is needed for tuning parameters that depend on the environment. Additionally, we observe that social odometry implements an implicit recruitment process that speeds up the initial exploration phase mandatory to achieve the foraging task. Lastly, a study of the impact of robots' density on the performance indicates that social odometry is not drastically affected by overcrowding and can cope with it.
Preliminary observations suggest that the β parameter depends on the distance between the areas, suggesting that the robots can tune parameter β knowing the distance between the central place and the resource site. The tuning of the parameter can be done off-line, where the designer introduces the value, or on-line, where robots update the β parameter once they have located both areas.
In the future, we intend to implement and test this strategy on real robots, emphasizing the online tuning of the parameter β.
Finally, we would like to stress that the performance of the social odometry allows an optimistic forecast concerning the use of online self-organized methodologies in the field of collective robotics. Online methodologies, from communication to evolution, may represent the missing aspect necessary for truly adaptive populations of robots. Work along these general lines is in progress.
Footnotes
7.
A. Gutiérrez and F. Monasterio-Huelin acknowledge support from the Ministerio de Educación y Ciencia de España, within the Plan Nacional de I+D+i 2007–2010. (“Gestión de la Demanda Eléctrica Doméstica con Energía Solar Fotovoltaica”, ENE2007-66135). A. Campo, F. C. Santos and M. Dorigo acknowledge support from the F.R.S.-FNRS. This work was partially supported by the ANTS project, an Action de Recherche Concerté funded by the Scientific Research Directorate of the French Community of Belgium.