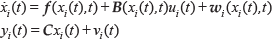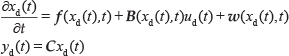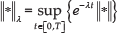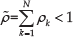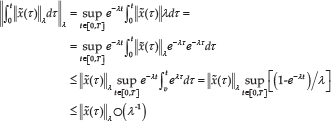In this work, we present a new iterative learning control (ILC) scheme for a class of non-linear systems with uncertain and non-repetitive disturbances, in order to achieve perfect tracking by proposing a high order feedback-feedforward ILC algorithm with a variable forgetting factor. The high order feedback-feedforward iterative learning controller can fully apply the previous control data to the system, which allows the system to track expectations more rapidly and precisely. Introducing a variable forgetting factor can weaken the former control output and its variance in the control law, while strengthening the robustness of the ILC. Through rigorous analyses, we demonstrate that uniform convergence of the state tracking error is guaranteed under this new ILC scheme. Simulation examples are also included to demonstrate the feasibility and effectiveness of the proposed learning controls.
ILC is effective for handling repeated control processes. It has been widely used in industries for the control of repetitive motion, such as robotic manipulators, hard disk drives and chemical plants, because of its structural simplicity and effective learning ability in the controller design process [1–3]. ILC algorithms can asymptotically or exponentially improve the tracking performance to achieve perfect tracking with an increasing number of iterations by utilizing the repetitive nature of the learning process. As several surveys [4–6] have discussed the novel ideas and development of ILC methodology, we refer the reader to these references for more information on the main concepts of ILC.
ILC learns from past practice and experience to construct a control function for the current iteration. Learning performance can be expected to improve more as a greater number of previous iterations are used. This is called high order ILC, which was first proposed [7] for the tracking control of repetitive systems. A class of non-linear time-varying systems without uncertainty, disturbance and initialization error was discussed in previous studies for high order ILC algorithms. To overcome this problem, feedback-feedforward high order ILC [8] was proposed in the control system, despite uncertainties and disturbances. However, the control methods often achieved a poor effect upon practical applications when the system had non-repetitive disturbances and an initial error. Therefore, in this paper, we propose a high order feedback-feedforward ILC algorithm with a variable forgetting factor.
The contribution of this paper is the combination of high order feedback-feedforward ILC and a variable forgetting factor. Feedback control [9–11] enhances the anti-interference performance and improves the robustness of the system; thus, the tracking deviation decreases during the iterative process. By adding feedforward control [12–14], the system can avoid the high gain that occurs in the feedback control method and can eliminate the actuator's saturation. By introducing a variable forgetting factor [15], this method can filter the signal toward the direction of iteration, which can weaken the convergent influence of the system caused by the uncertain part of the system and non-repetitive disturbances. The combination is capable of achieving high performance trajectory tracking in simulation results, while maintaining good disturbance rejection.
The remainder of this paper is organized as follows. The problem statement for a class of repetitive non-linear time-varying systems is described in section 2. Section 3 presents the designed controller and the designed variable forgetting factor. In section 4, the convergence condition for the non-linear system is presented and the convergence analysis is provided. In section 5, a simulation is presented to verify the effectiveness of the proposed method. Finally, conclusions are drawn in section 6.
2. Problem Statement
Let us consider repetitive non-linear time-varying systems [16–17] with uncertainty and disturbances [18–19]:
where i and t are the iteration index and continuous-time, respectively. is the control variable is the state variable, while is the output of the system at the i-th trial. and are the uncertain item and disturbance term, respectively. is a constant matrix. , and are non-linear functions
Assumption 1. Functions , and are, uniformly, globally Lipschitz with respect to x on a compact set ,
where kf, kB and kw are the Lipschitz constants.
Assumption 2. The initial error of the system at the i-th trial satisfies the criterion:
Assumption 3. For , there exist unique and , which satisfy the following equations:
where is the desired control input and is the desired state.
It is important to introduce the Lambda norm. The Lambda norm for a function is defined as:
where .
λ -norm is defined to simplify the formula as follows:
Let , , , , , , , , and . We then have:
where xd is the desired state of the system and ≜ indicates a formula that is defined as another formula.
The high order feedback-feedforward ILC algorithm with a variable forgetting factor applies to non-linear time-varying systems. The objective is to design an iterative learning controller un, such that the output tracking error between the desired output trajectory yd and system output yn is in an error bound, which can be predetermined. As , the bound of the tracking error converges to a small neighbourhood of the origin. If and bv tend towards zero, the bound of the tracking error asymptotically reaches zero by ILC.
3. Designed Controller and Variable Forgetting Factor
The high order feedback-feedforward ILC controller with a variable forgetting factor is constructed as follows:
where i indicates the iteration number, , is the variable forgetting factor, a is used instead of to simplify the formula, is the initial value of the input, and are respectively the feedforward and feedback gain matrices, and .
The tracking ability of the system is stronger for smaller values of the forgetting factor a, and vice versa. We generally use a fixed forgetting factor, but a cannot vary with changes in the system features. Therefore, a variable forgetting factor a, which can vary automatically according to changing system deviation, is introduced as follows:
where is sensitive to the gain and r is used to control the rate at which a approaches 1. If r is small, L becomes large, and the convergence speed is reduced. If r is large, the system stability decreases. When , the minimum value of a is , . When , .
4. Convergence Analysis
In this section, the convergence condition of the controllers for the non-linear systems with uncertain and non-repetitive disturbance is given and proven.
Lemma 1 [20]. Assume that there is a positive real sequence and that the condition , ; is satisfied with . If , then .
Theorem 1 [20]. The non-linear systems with uncertain and non-repetitive disturbance satisfy Assumptions 1 and 2 under the condition that:
Furthermore, there exists a sufficiently large constant λ, such that:
When i goes to infinity, the tracking error bound converges to a small neighbourhood of the origin. Meanwhile, the tracking error , initial state error and bound of the output disturbance item bv have a linear relationship.
When the conditions and are satisfied, for any prescribed tracking error tolerance , we can choose a group of parameters and to reach the conclusion of this theorem , with .
By Theorem 1, we choose a sufficiently large constant λ to satisfy and . From Lemma 1, the following inequality holds:
Inserting , we obtain . Combining (13), (14) and (15), we find that the tracking error bound converges to a small neighbourhood of the origin, as i goes to infinity. Meanwhile, the tracking error , initial state error and bound of the output disturbance item bv have a linear relationship. If and bv tend towards zero, the tracking error bound asymptotically approaches zero by ILC.
When the conditions and are satisfied, from (14), we get , from (15), we obtain . Then, as (13) gives , we have . According to the limit definition, for any prescribed tracking error tolerance , its value is related to the selection of and . We can choose a group of parameters and to reach the conclusion of this theorem: , with .
5. Simulation
To demonstrate the effectiveness of the proposed algorithm of ILC, a comparable investigation is accomplished between the proposed ILC algorithm and traditional high order feedback-feedforward ILC. We consider the two manipulators of a robot described by (16).
where is the vector of the state variables, is the inertia matrix, is the vector of the Coriolis and centripetal torques, is the gravitational term, represents the interference terms, and is the vector of the control input.
equation (16) can now be rewritten. If , , we then obtain:
Simulations are conducted on a planar direct-driven two-joint robot. The matrices for the robot arm in the state space are:
where a, b and c are three constants: a =5.76794 , b =1.473 and c =1.76794 .
The expected output trail is . The interference term is and the initial state is .
The high order feedback-feedforward ILC algorithm with a variable forgetting factor is defined as:
with .
The high order feedback-feedforward ILC algorithm is defined as
with .
According to Theorem 1 and Lemma 1, the parameters used in the simulation are chosen as:
, , , , , , , , .
By checking the convergence condition in Theorem 1 and Lemma 1, we can obtain the following:
The first algorithm:
The second algorithm:
Thus, is satisfied for any prescribed tracking error tolerance .
Desired and actual position trajectories
Maximum absolute tracking error in each iteration
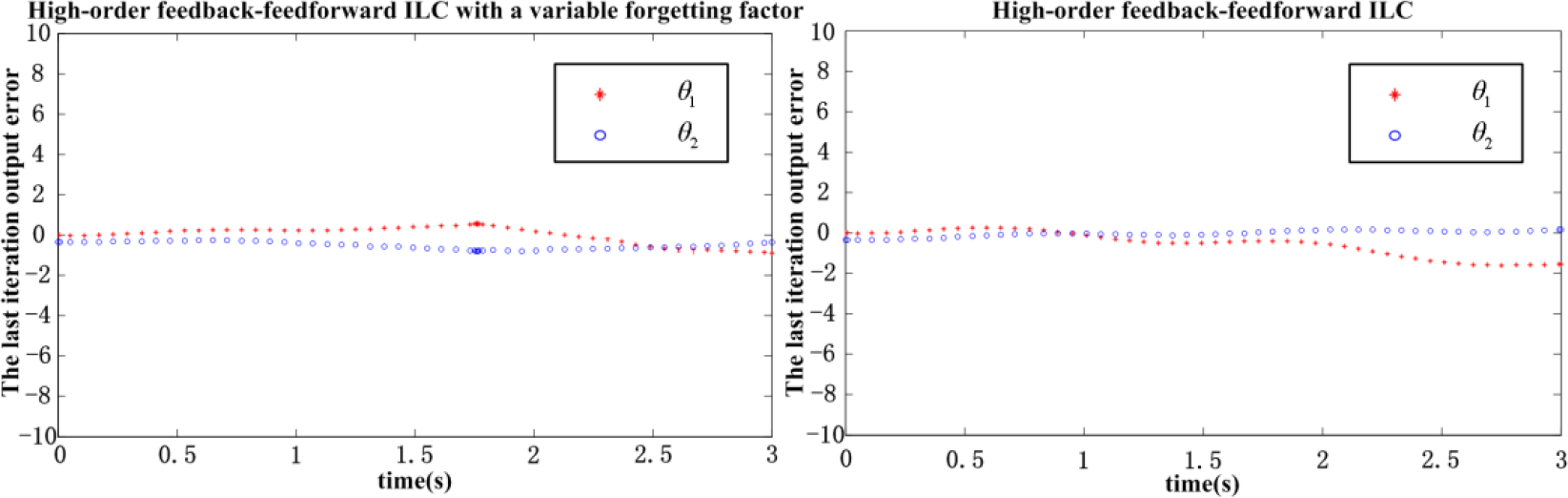
Output error in the last iteration
Figure 1 shows that the control law drives the system output through the desired trajectory as closely as possible. We show the iterative process of the formation learning error in Figure 2. The high order feedback-feedforward ILC arithmetic, with a variable forgetting factor, can significantly converge to a small neighbourhood of zero, in which the tracking error in the eighth iteration is less than and the range of error is related to the selection of and . From Figure 2 and Figure 3, in the conventional high order feedback-feedforward ILC algorithm has a small error and fast convergence rate, but has a large tracking error, which is larger than . This error is not allowable for engineering applications. Therefore, the high order feedback-feedforward ILC algorithm with a variable forgetting factor has small tracking errors, conforming to the requirements and fast convergence rate.
The system includes steady-state error due to the initial error. If the initialization error tends towards zero, then the final tracking error will also tend towards zero. From the simulation results, the high order feedback-feedforward ILC algorithm, with a variable forgetting factor, has the best performance and control effort from a practical perspective, in comparison with the conventional high order feedback-feedforward ILC algorithm, even though there are some steady-state errors, which could be neglected in practice. The results demonstrate the effectiveness of the proposed ILC scheme, as well as the design trade-off between the convergence speed and accuracy.
6. Conclusion
In this work, we propose a novel ILC scheme to address tracking problems for a class of non-linear time-varying system with an uncertain or interference component. By introducing a variable forgetting factor, this method weakens the convergent influence of the system caused by the uncertain part of the system and the non-repetitive disturbances. This algorithm is proposed to facilitate uniform tracking error convergence analysis under the effect of system uncertainties and non-repetitive disturbances. The simulation results further verify the theoretical results. Future work will aim to apply the proposed algorithm to actual robot control and biochemical reaction processes.
Footnotes
7. Acknowledgements
The authors would like to thank the anonymous reviewers for their useful comments, which have helped to improve the quality of the manuscript. This work is supported by the National Natural Science Foundation of China under Grant No. 61473248.
References
1.
LuX.FeiJ., Study of a MEMS Vibratory Gyroscope Using Adaptive Iterative Learning Control. International Journal of Advanced Robotic Systems. 2014;11:151–159.
2.
de BestJ.LiuL.van de MolengraftR., Second-Order Iterative Learning Control for Scaled Set-points. IEEE Transactions on Control Systems Technology. 2015;23:805–812.
3.
ZiB.CaoJ.ZhuZ., Dynamic Simulation of Hybrid-driven Planar Five-bar Parallel Mechanism Based on SimMechanics and Tracking Control. International Journal of Advanced Robotic Systems. 2011;8(4):28–33.
4.
SampsonP.FreemanC.CooteS., Using Functional Electrical Stimulation Mediated by Iterative Learning Control and Robotics to Improve Arm Movement for People With Multiple Sclerosis. IEEE Transactions on Neural Systems and Rehabilitation Engineering. 2015;99:1–2.
5.
SunH.AlleyneA. G., A Computationally Efficient Norm Optimal Iterative Learning Control Approach for LTV Systems. Automatica. 2014;50(1): 141–148.
6.
DinhT. V.FreemanC. T.LewinP. L., Assessment of Gradient-based Iterative Learning Controllers Using a Multivariable Test Facility with Varying Interaction. Control Engineering Practice. 2014;29:158–173.
7.
BienZ.HuhK. M., High-order Iterative Learning Control Algorithm. IEE Proceedings D. 1989;3:105–112.
8.
ZhangY.SunH.HouZ., A Feedback-feedforward High Order Iterative Learning Control. International Conference on Intelligent Control and Information Processing. 2010;8:13–15.
9.
DohT. -Y.RyooJ. R.Eui ChangD., Robust Iterative Learning Controller Design Using the Performance Weighting Function of Feedback Control Systems. International Journal of Control, Automation, and Systems. 2014;12(1):63–70.
10.
MatsuiY.AkamatsuS.KimuraT., An Application of Fictitious Reference Iterative Tuning to State Feedback Control. Electronics and Communications in Japan. 2014;97(1):1–11.
11.
ZhangJ.WeiZ.XiaoL., A Fast Adaptive Reweighted Residual-feedback Iterative Algorithm for Fractional-order Total Variation Regularized Multiplicative Noise Removal of Partly-textured Images. Signal Processing: The Official Publication of the European Association for Signal Processing (EURASIP). 2014;98:381–395.
12.
KimK. -S.ZouQ., A Modeling-Free Inversion-Based Iterative Feedforward Control for Precision Output Tracking of Linear Time-Invariant Systems. IEEE/ASME Transactions on Mechatronics: A Joint Publication of the IEEE Industrial Electronics Society and the ASME Dynamic Systems and Control Division. 2013;18(6): 1767–1777.
13.
ZhangY.ZouQ., High-speed Force Load in Force Measurement in Liquid Using Scanning Probe Microscope. Review of Scientific Instruments. 2012;83(1):0137071–0137077.
14.
HoelzleD. J.JohnsonA. J. W.AlleyneA. G., Bumpless Transfer Filter for Exogenous Feedforward Signal. IEEE Transactions on Control Systems Technology: A Publication of the IEEE Control Systems Society. 2014;22(4):1581–1588.
15.
BouakrifF., Iterative Learning Control with Forgetting Factor for Robot Manipulators with Strictly Unknown Model. International Journal of Robotics & Automation. 2011;3:35–42.
16.
XuG.ShaoC.HanY., New quasi-Newton Iterative Learning Control Scheme Based on Rank-one Update for Nonlinear Systems. Journal of Supercomputing. 2014;3:335–340.
17.
BuX.YuF.HouZ., Iterative Learning Control for a Class of Nonlinear Systems with Random Packet Losses. Nonlinear Analysis, Real World Applications. 2013;1:28–34.
18.
BouakrifF., Iterative Learning Control for Strictly Unknown Nonlinear Systems Subject to External Disturbances. International Journal of Control, Automation, and Systems. 2011;4:12–19.
19.
ChenH.XingG.SunH., Indirect Iterative Learning Control for Robot Manipulator with Non-Gaussian Disturbances. IET Control Theory & Applications. 2013;17:95–103.
20.
ChenY. C.WenC. Y.SunM. X., A Robust High-order P-type Iterative Learning Controller Using Current Iteration Tracking Error. International Journal of Control. 1997;68:331–342.