
Abstract
Global path planning is a challenging issue in the filed of mobile robotics due to its complexity and the nature of non-deterministic polynomial-time hard (NP-hard). Particle swarm optimization (PSO) has gained increasing popularity in global path planning due to its simplicity and high convergence speed. However, since the basic PSO has difficulties balancing exploration and exploitation, and suffers from stagnation, its efficiency in solving global path planning may be restricted. Aiming at overcoming these drawbacks and solving the global path planning problem efficiently, this paper proposes a hybrid PSO algorithm that hybridizes PSO and differential evolution (DE) algorithms. To dynamically adjust the exploration and exploitation abilities of the hybrid PSO, a novel PSO, the nonlinear time-varying PSO (NTVPSO), is proposed for updating the velocities and positions of particles in the hybrid PSO. In an attempt to avoid stagnation, a modified DE, the ranking-based self-adaptive DE (RBSADE), is developed to evolve the personal best experience of particles in the hybrid PSO. The proposed algorithm is compared with four state-of-the-art evolutionary algorithms. Simulation results show that the proposed algorithm is highly competitive in terms of path optimality and can be considered as a vital alternative for solving global path planning.
Keywords
Introduction
Over the past few decades, mobile robotics has been successfully applied in industry, military and security environments to perform crucial unmanned missions such as planet exploration, surveillance and landmine detection [39]. A fundamental issue of mobile robotics is path planning, which aims to find an optimal or sub-optimal obstacle-free path from a starting location to a destination location, while optimizing some performance criteria. Due to its widespread application in different areas such as computer games, animation, assembly planning and computational biology, path planning has drawn increasing research interest since the mid-1960s [36].
Generally, path planning can be categorized into global path planning (GPP) and local path planning (LPP), with respect to whether full knowledge of the environment is available or not [39]. GPP, executed offline, determines an obstacle-free path while being aware of complete information pertaining to the environment [35, 39]. LPP, also called online path planning, generates an efficient path by using no or partial information of the environment [35, 39]. This paper focuses on the GPP problem, which is good at generating an efficient path offline. For simplicity, the GPP problem is referred to as the path planning problem throughout the rest of this paper.
To date, path planning has been intensively studied in the literature and numerous path planning methods have been proposed. However, owing to its non-deterministic polynomial-time hard (NP-hard) nature, efficiently solving the path planning problem remains a challenge [5, 6, 14, 21, 35, 36, 39]. Thanks to their population-based nature and good search ability for producing high-quality solutions within a tractable time, even for complex problems [39], evolutionary algorithms (EAs) such as the genetic algorithm [1], simulated annealing [28] and artificial neural network [9] have been proposed in the field of path planning in recent years.
As one of the most powerful EAs, due to its simplicity and high convergence speed, the particle swarm optimization (PSO) algorithm has been widely implemented to solve path planning [12, 19, 32, 36]. Nevertheless, since the basic PSO algorithm cannot balance exploration and exploitation sufficiently, it is easily trapped in a local optimum [2]. Furthermore, the basic PSO may also suffer from stagnation when no particle can find a position that is better than its previous best positions [16]. In order to enhance the performance of PSO, it is essential to overcome these two shortcomings.
The differential evolution (DE) algorithm is another promising evolutionary algorithm that emerged as a highly competitive algorithm more than a decade ago [4]. Due to its simplicity, reliability, high performance and easy implementation, a considerable amount of research has been dedicated to applying DE to solve different optimization problems [8, 20, 38]. It is well-known that different generation strategies (i.e., mutation and crossover operators) and control parameters (i.e., scaling factor and crossover rate) significantly influence the performance of DE [8, 20, 38]. However, how to set generation strategies and control parameters are problem-dependent, which results in difficulties when designing an efficient DE algorithm [8, 38].
Since both PSO and DE are EAs that deal with population evolution, it is natural to mix these two algorithms together to leverage their advantages when developing an integrated method for efficiently solving optimization problems. Motivated by this idea, some research such as [11, 16, 17, 24, 33, 34] has been devoted to hybridizing PSO and DE in order to improve the performance of hybrid algorithms.
In this study, we also combine PSO with DE and propose a hybrid PSO-DE algorithm, the HNTVPSO-RBSADE, for mobile robot global path planning. In the proposed hybrid PSO algorithm, a novel PSO, called NTVPSO, is first developed to update the velocities and positions of particles. Then, after each iteration, a modified DE algorithm, called RBSADE, is proposed to evolve the personal best positions of particles in order to force particles to jump out of stagnation. In order to sufficiently balance the exploration and exploitation capabilities of particles, a new self-adaptive mechanism is proposed to adaptively adjust the three control parameters (inertia weight and cognitive and social acceleration parameters) of particles in NTVPSO. To improve the performance and easily adjust the control parameters of RBSADE, a ranking-based mutation operator and a self-adaptive strategy are developed in RBSADE.
To verify the proposed algorithm for solving mobile robot global path planning, it is compared to JADE [35], the time-varying particle swarm optimization (TVPSO) method [15], the gravitational search (GS) method [18] and the modified genetic algorithm (mGA) [25] under different simulation scenarios. For rigorous verification, path optimality and computation time are examined and compared for each algorithm. The simulation results confirm that the proposed algorithm outperforms the algorithms it is compared to in terms of path optimality. Moreover, the computation time of the proposed algorithm is also comparable with that of the other algorithms.
The remainder of the paper is organized as follows. Section 2 formulates the path planning problem and introduces the scheme for encoding the path, as well as the constraint handling technique. Section 3 presents the HNTVPSO-RBSADE algorithm and analytical investigations pertaining to this algorithm. Section 4 presents the framework for applying HNTVPSO-RBSADE to solve mobile robot global path planning. Simulations and comparisons are performed in section 5. Section 6 summarizes the paper by way of a conclusion and options for future work.
Statement of the Path Planning Problem
Modelling of the workspace
This paper focuses on finding an obstacle-free path for a mobile robot working in a 2-D complex workspace. The model presented in [13] is adopted to establish the workspace, due to its simplicity and small sensitivity to the shapes of obstacles. As shown in Fig. 1, a global coordinate system o - xy is established, where st and ta denote the start location and the destination location of a robot, respectively. The x -axis of the global coordinate system coincides with line st - ta and the y -axis of the global coordinate system is perpendicular to line st - ta. In the global coordinate system, line st - ta is equally divided into n + 1 subsections by n points, where n is a predefined parameter. After drawing n vertical lines l1, l2,…, l n , as shown in Fig. 1, a point-to-point path, denoted as ph = [st, p1, p2,…,p n , ta], is constructed by random sampling on vertical lines l1, l2,…, l n . All obstacles in the workspace are assumed to be static and are represented by polygons. The robot is considered a mass point and obstacles are enlarged according to the size of the robot to compensate [9, 39].

The illustration of the 2-D workspace
As searching for the best path is often associated with finding the shortest and safest path, as in [9, 13, 18, 36, 37], path length and path safety are considered as being two performance criteria of the path planning problem in this paper. Let p0 and pn+1 denote the start location and the destination location of a robot, respectively. The path planning problem can be mathematically formulated as [18, 37]:

where J L and J S denote path length and path safety, respectively, and w1 and w2 are two weighting parameters indicating the relative importance of J L and J S (w1 = w2 = 1 in this paper).
To generate a point-to-point path, J L is calculated as [6]:

where dis(p i , pi+1) denotes the Euclidean distance between waypoint p i and waypoint pi+1.
J L is the summation of the minimum distance of each path segment from the nearest obstacle along the path, which is calculated as [6]:

where Nob denotes the number of obstacles. Mindis(p i pi+1,O j ) represents the minimum distance between path segment p i pi+1 and obstacle O j .
As stated in section 2.1, a path is constructed by a set of waypoints p1, p2,…, p n , while a set of lines l1, l2,…, l n determines the x -axis values of these points. Since the set of lines l1, l2,…, l n is given beforehand during the construction of the workspace, values of p1,…, p n lie only with the y -axis values decided by l1, l2,…, l n . These y -axis values, denoted as (y p 1 ,y p 2 ,…,y p n ), are applied in order to encode the path [13, 36]. The following saturation strategy is used to modify y p i (i = 1,2,…,n) when y p i is outside of the workspace as follows:

where width represents the width of the workspace as shown in Fig. 1.
From (1), it can be seen that the path planning problem is a constrained optimization problem. In order to solve the constraint problem easily and efficiently, the task of how to handle the constraint must be addressed. As the constraint of the path planning problem is to generate an obstacle-free path, it is reasonable to evaluate the constraint violation degree of each candidate path by counting its collision times with obstacles [36]. Given Nob obstacles, the total constraint violation degree of candidate path m1 is calculated as [36]:

After calculating the constraint violation degree and the fitness value of each candidate path, the feasibility-based rule [7, 27] is used to evaluate and select the elite path between any two candidate paths. The feasibility-based rule is described as: (1) for any two paths with the same constraint violation degree, the path with better fitness is preferred; (2) for any two paths with different constraint violation degrees, the path with a smaller constraint violation degree is preferred.
Since the fitness and constraint violation information of each candidate path are considered separately in the feasibility-based rule, no additional parameter is needed to transform the constrained path planning problem into an unconstrained one, which decreases optimization difficulty. Additionally, although the non-feasible paths collide with some obstacles, they may also contain high-quality path segments. When these high-quality path segments are considered, the diversity of the paths and the possibility of finding high-quality paths are increased. This is one main reason why non-feasible solutions are considered in the feasibility-based rule.
Review of the basic PSO
Inspired by birds flocking and fish schooling, Kennedy and Eberhart first proposed PSO in 1995 [10]. Each particle in PSO represents a potential solution to an optimization problem and is associated with a velocity that is dynamically adjusted according to its own flight experience, as well as those of its companions. Therefore, each particle is attracted to a stochastically weighted average of its personal best position and the global best position of the swarm. In the basic PSO algorithm, from iteration k to iteration k + 1, each particle updates its velocity and position as follows [10]:
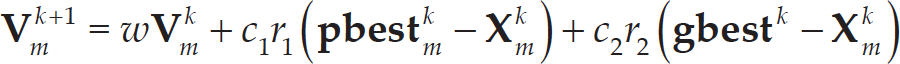

where
DE is a population-based algorithm that initializes a population of SP individuals in a D-dimensional search space. Each individual, known as either a genome or chromosome, denotes a potential solution to an optimization problem. After mutation, crossover and selection operators, an offspring is allowed to the next generation only if it improves on the fitness of the parent [23].
The mutation operator modifies an individual via random changes in order to generate a new offspring, which aims to add some diversification into the population to avoid the local optimum [23]. At iteration k, for each parent

where
The crossover operator follows a discrete recombination approach, where elements from the parent vector

where j(j = 1,2,…,D) refers to a specific dimension; x
ij
, v
ij
(k) and u
ij
(k) are the jth elements of
The selection operator is a one-to-one spawning strategy in which the new offspring

where f(
Since the proposed HNTVPSO-RBSADE algorithm incorporates NTVPSO and RBSADE, NTVPSO and RBSADE are first presented separately below. Then, the HNTVPSO-RBSADE-based framework is presented in this subsection.
Nonlinear time-varying PSO (NTVPSO)
When using PSO to solve optimization problems, it is necessary to properly control the exploration and exploitation abilities of PSO in order to efficiently find an optimal solution [2, 22]. Ideally, on the one hand, in the early stage of the evolution, the exploration ability of PSO needs to be strengthened so that particles can wander through the entire search space, rather than clustering around the current population-best solution [2, 22]. On the other hand, in the later stage of the evolution, the exploitation capability of PSO must be promoted so that particles can search carefully in a local region to find optimal solutions efficiently [2, 22].
Proverbially, the exploration and exploitation capabilities of PSO heavily depend on its three control parameters. The basic philosophies concerning how the three control parameters influence such abilities of PSO can be summarized as follows: (1) a large inertia weight enhances exploration, while a small inertia weight facilitates exploitation [22, 26]; (2) a large cognitive component, compared to the social component, results in the wandering of particles through the entire search space, which strengthens exploration [22, 26]; (3) a large social component, compared with the cognitive component, leads particles to a local search, which strengthens exploitation [22, 26].
Considering all of the concerns noted above, this paper proposes a novel PSO called NTVPSO. The main purpose of this PSO is to adaptively balance the exploration and exploitation capabilities of NTVPSO, so that the performance of the algorithm can be improved. In order to achieve this goal, a novel self-adaptive mechanism that is used to update the three control parameters of each particle in NTVPSO is proposed as follows:

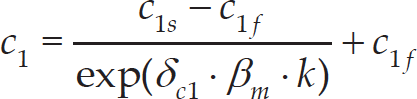
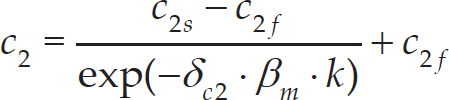




where w
max
and w
min
denote the upper and lower bounds of w; c1s and c1f denote the initial and final values of c1; c2s and c2f represent the initial and final values of c2; k
max
represents the maximum iteration number; ‖
From (11) to (13), with increasing iteration number k, it is clear that w and c1 decrease, while c2 increases in NTVPSO. Therefore, according to the aforementioned basic philosophies, NTVPSO is likely to start the search with a high exploration tendency, which will be reduced over time, so that exploitation may be favoured in the late stage of the evolution. Note that following the update rule of a fixed β m , the balance between exploration and exploitation varies only with respect to the iteration number k.
We also adapt the balance of the search in NTVPSO using an additional parameter β m . From (11) and (12), it is trivial that w and c1 decrease as β m increases. On the other hand, the variation in c2 becomes larger as β m increases, as shown in (13). This implies that, for large β m , the exploration capability of NTVPSO tends to be retained, compared to the case where there is small β m . In contrast, the exploitation ability of the algorithm takes over the exploration ability more rapidly as β m decreases.
Briefly, by utilizing the proposed self-adaptive strategy defined from (11) to (17) in NTVPSO, the three control parameters of particles are adaptively adjusted, complying with the basic philosophies of PSO improvement. Therefore, the NTVPSO algorithm is expected to improve the ability for finding high-quality solutions. Fig. 2 demonstrates the tendency of these changes in the three control parameters with respect to different values of β m . Note that w max = 0.9, w min = 0.1, c1s = c2f = 2.5, c1f = c2s = 0.5 and k max = 100 in Fig. 2.
Ranking-based self-adaptive DE (RBSADE)
In the conventional DE algorithm, the three different individuals used for the mutation operator are randomly selected from the current swarm. However, it is natural that good species always contain good genetic information, making them more likely to be utilized for mutating better offspring. Based on this consideration, this paper develops a modified DE called RBSADE, in which a ranking-based strategy is developed to select the good species. In the ranking-based strategy, all parent individuals at the current iteration are first sorted in ascending order according to their fitness values and constraint violation degrees. Then, at the current iteration, the ranking value of the i th parent individual is assigned as follows:
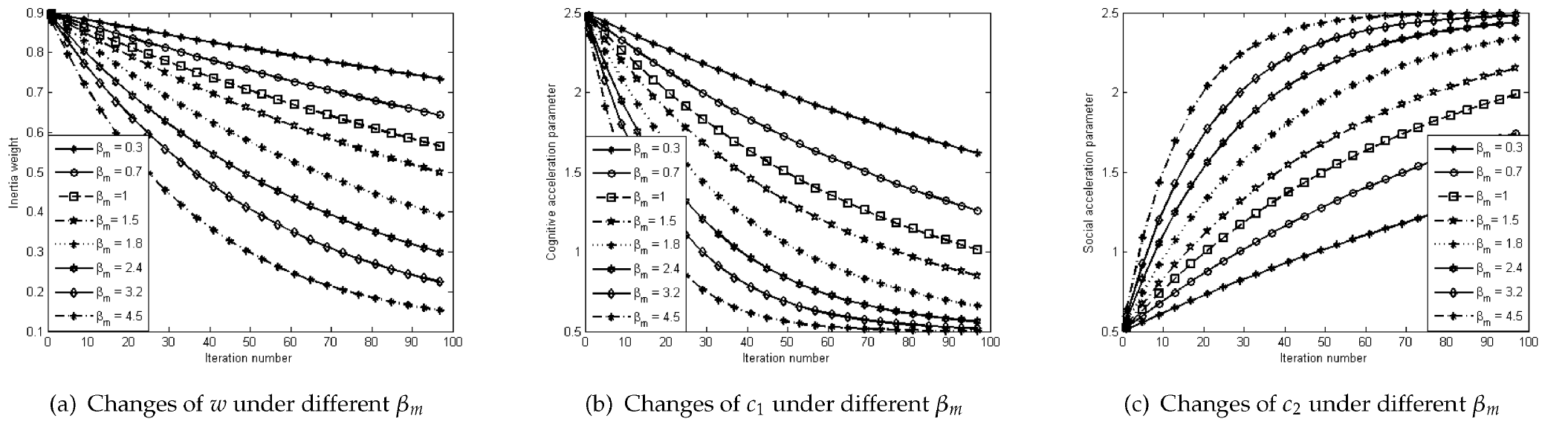
Changes of the three control parameters under different β m in NTVPSO

where i =1,2,…,SP and SP denotes the size of the swarm.
After calculating the ranking value of each parent individual, the selection probability that the ith individual is allowed to participate in the mutation operator is calculated as follows:

It is clear from the ranking-based strategy that the better genetic information a parent contains, the higher the probability that it will be selected for participating in the mutation operator and the more likely a better offspring will be produced. After calculating the selection probability of each parent individual at the current iteration, the roulette-wheel mechanism is applied to select three different individuals from the current swarm to mutate a new offspring according to the mutation operator given in (8).
In order to decrease the difficulties in controlling the crossover rate, the self-adaptive strategy proposed in [31] is applied to dynamically update the crossover rate of each individual in RBSADE as follows:

where N(0.5,0.1) is a random number generated by a normal distribution of mean 0.5 and standard deviation 0.1. When f(
To adaptively adjust the scaling vector


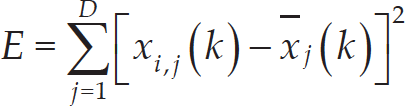

where F
i,j
is the j th element of scaling vector
Let NP denote the size of the swarm and
The algorithmic scheme of HNTVPSO-RBSADE

The algorithmic scheme of HNTVPSO-RBSADE
When designing a PSO algorithm, the convergence of the algorithm is of great importance [3, 29]. Since each dimension of the velocity and position vectors of each particle is updated independently from one another in (6) and (7), HNTVPSO-RBSADE can be simplified into a one-dimensional case in order to analyse its convergence. Without loss of generality, by omitting the subscript m in (6) and (7) for simplicity, the one-dimensional HNTVPSO-RBSADE can be rewritten into matrix form as follows:

where:

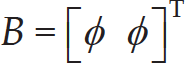

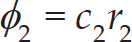
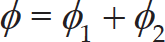
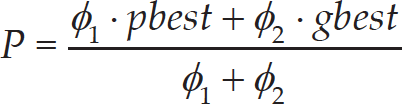
Solving |λ
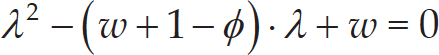
where two roots, denoted as λ1,2, are obtained as follows:

In the context of dynamic system theory, the necessary and sufficient condition for the convergence of system (25) is that magnitudes of λ1 and λ2 should be less than 1 [30]. Thus, the system (25) converges, if and only if:

Since it appears from (33) that λ1 and λ2 are two real or complex numbers, we will discuss two cases separately where λ1,2 are two real and complex numbers in order to analyse the convergence of system (25).
The case where λ1,2 are two complex numbers, denoted as λ1,2 ∈ ℂ.


Solving the right-hand side of (36) using the classic approach,
Now, let us find conditions on φ and w guaranteeing the convergence of system (25) in the case where λ1,2 ∈ ℂ. It is trivial that the system converges if and only if Max{|λ1|,|λ2|}<1.


Therefore:

In the case where λ1,2 ∈ ℂ, according to 
Fig. 3 shows the convergent region of the system (25), i.e., HNTVPSO-RBSADE, in the case where λ1,2 ∈ ℂ.
Convergent region of HNTVPSO-RBSADE in the case where λ1,2 ∈ ℂ
The case where λ1 and λ2 are two real numbers, denoted as λ1,2 ∈ ℝ.


Solving the right-hand side of (42) using the classic approach,
Now, let us find conditions on φ and w guaranteeing the convergence of the system (25) in the case where λ1,2 ∈ ℝ. According to (33) and (34), in the case where λ1,2 ∈ ℝ, Max{|λ1|, |λ2|}<1 holds, if and only if:

Hence:

As λ1,2 ∈ ℝ, it is clear that:

Solving the right-hand inequalities in (45), yields:
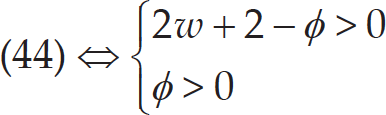
According to

Considering both cases where λ1,2 ∈ ℂ and λ1,2 ∈ ℂ together, the system (25), i.e., HNTVPSO-RBSADE, converges, if and only if:

Fig. 4 shows the convergent region of HNVPSO-RBSADE in both cases where λ1,2 ∈ ℝ and λ1,2 ∈ ℂ, which is a triangle area. Only if a parameter selection of w and φ is located in this area does HNTVPSO-RBSADE converge. Fig. 5 illustrates the 3-D representation of the value of Max{|λ1|,|λ2|}.
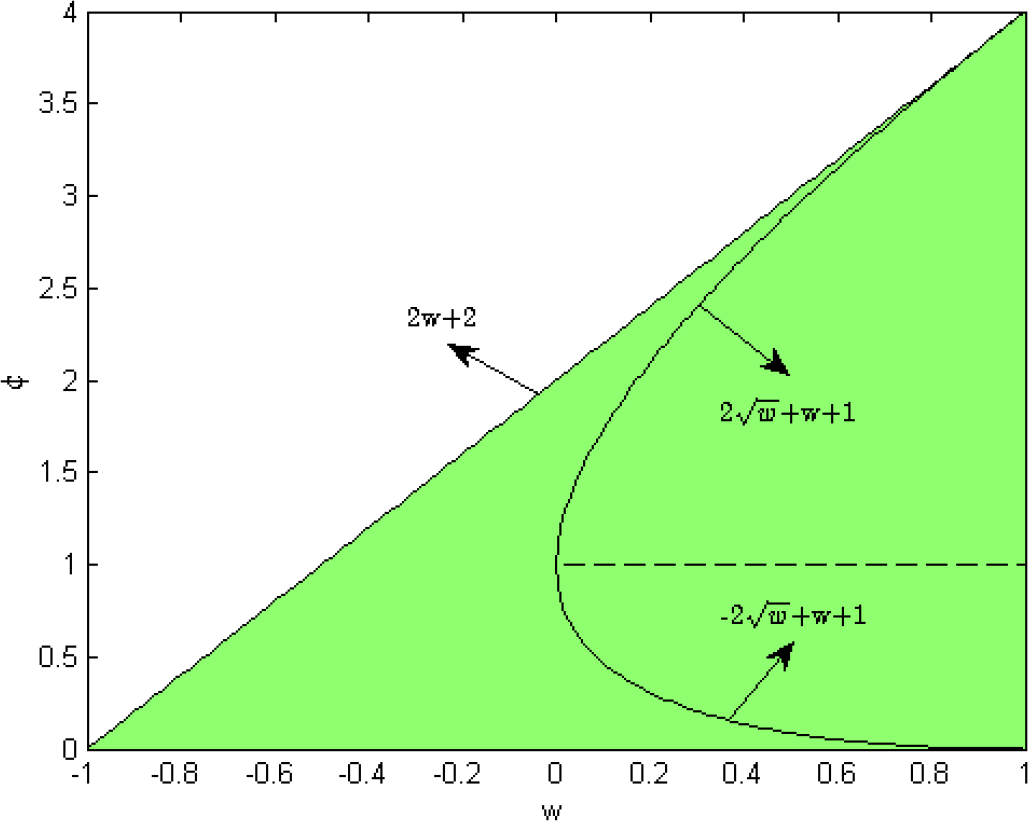
Convergent region of HNTVPSO-RBSADE
Now, let us find the equilibrium point of HNTVPSO-RBSADE. Calculating limits on both sides of (25) yields the following:

When HNTVPSO-RBSADE converges,

where φ = φ1 + φ2, φ1 = c1r1 and φ2 = c2r2. pbest denotes the personal best position of the particle and gbest represents the global best position of the swarm.

3-D representation of the value of Max{|λ1|, |λ2|}
Prior to particles converging to the equilibrium point given in (50), they may oscillate in different ways around the equilibrium point as a result of the different values of w and φ. Since different convergence oscillations may influence the quality of the final solution found by particles [29], it is necessary to investigate the different convergence oscillations of particles. Four typical oscillations of particles in HNTVPSO-RBSADE are shown in Fig. 6.
Non-oscillatory behaviour, as shown in Fig. 6(a), leads particles to only search on one side of the equilibrium point, which will be useful when the search space is bounded. Particles exhibit non-oscillatory convergence behaviour when λ1 and λ2 are two real roots and at least one of them is positive, which is equivalent to 0⩽(1 + w - φ)2-4w and 0 < 1 + w - φ. Harmonic oscillation behaviour, as shown in Fig. 6(b), may be beneficial for the exploitation stage, since particles smoothly oscillate around the equilibrium point. Harmonic oscillation behaviour occurs when two roots, λ1 and λ2 are complex, that is, (1 + w - φ)2-4w < 0. Zigzagging convergence, as shown in Fig. 6(c), may also facilitate exploitation as particles zigzag around the equilibrium point, which may be useful when the search space is rugged. Particles exhibit zigzagging convergence behaviour when at least one of λ1 and λ2 has a negative real part, i.e., w < 0 or 1 + w - φ < 0. The combined harmonic with zigzagging behaviour, as shown in Fig. 6(d), can be beneficial for the transition from exploration to exploitation, due to its mixed nature, which emerges when at least one of the two complex roots λ1 and λ2 has a negative real part, i.e., (1 + w - φ)2 - 4w < 0 ∩ w < 0 ∪ (1 + w - φ)2 - 4w < 0 ∩ 1 + w - φ < 0.
If the boundaries of coefficients associated with these oscillations are known beforehand, one may easily design an adaptive method to change the values of these coefficients, so that the convergence of PSO can be guaranteed and the quality of the final solution searched by particles can be improved.
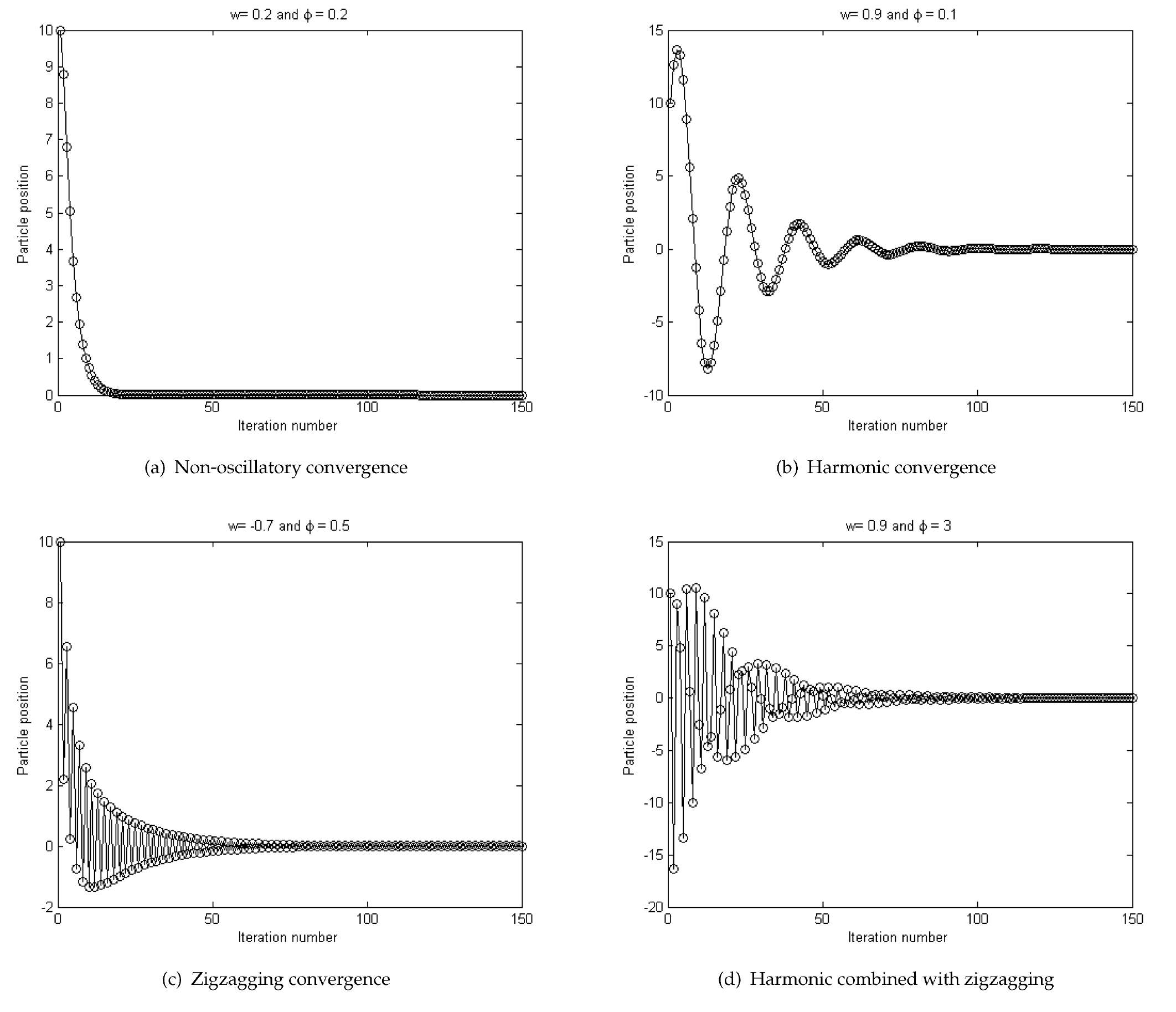
Convergence behaviour of particles in HNTVPSO-RBSADE
Due to the stochastic nature of HNTVPSO-RBSADE it is difficult to rigorously establish the exact relationship between its stochastic nature and its convergence property. Thus it is necessary to first analyse the convergence of HNTVPSO-RBSADE without considering its stochastic nature Note that the stochastic nature of HNTVPSO-RBSADE is attributed to the existence of the two random numbers r1 and r2.


Since c1 and c2 are two positive parameters, and r1 and r2 are two random numbers uniformly distributed in [0,1], we have c1 ⩾ c1r1 and c2 ⩾ c2r2. Therefore:
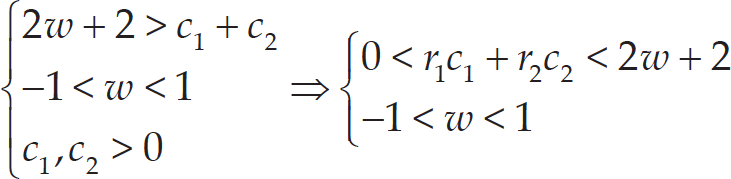
Since the right-hand side inequality in (53) is the necessary and sufficient condition for the convergence of HNTVPSO-RBSADE, it is trivial that
After analytically investigating the convergence of HNTVPSO-RBSADE, we still need to discover how to set the initial and final values of w, c1 and c2 to guarantee the convergence of HNTVPSO-RBSADE. In the following lemma, an alternative parameter selection principle for how to set the initial and final values of w, c1 and c2 to guarantee the convergence of HNTVPSO-RBSADE is provided.

Convergent position and velocity trajectories of the particle in HNTVPSO-RBSADE under the suggested parameter selection


The right-hand side inequality in (55) is the sufficient condition for the convergence of HNTVPSO-RBSADE, which is proved in
Since w max , w min , c1s, c1f, c2s and c2f are predefined parameters, the convergent condition given by (54) can be easily satisfied by setting proper values of these parameters. Fig. 7 shows the convergent position and velocity trajectories of the particle in HNTVPSO-RBSADE under the suggested parameter selection: w max = 0.9, w min = 0.4, c1s = c2f = 2 and c1f = c2s = 0.1.
The algorithmic scheme of applying HNTVPSO-RBSADE to solve mobile robot global path planning is illustrated in Table 2. Note that the evolution will not exit until the iteration number reaches the maximum iteration number. In Table 2,
The HNTVPSO-RBSADE-based framework for global path planning

The HNTVPSO-RBSADE-based framework for global path planning
In order to validate the proposed method, it is compared with JADE [35], TVPSO [15], GS [18] and mGA [25]. The simulation parameters for each method are shown in Table 3. To fully investigate the performance of the proposed method, four numerical simulations and a Monte-Carlo experiment with 50 independent runs are conducted. In each simulation, the optimal path of each method is obtained after 200 iterations of 40 particles using MATLAB 2012B software on a Windows 8 personal computer with i3-2350@2.30GHz and 2GB RAM. For rigorous comparison, the path optimality and the computation time of each method are examined and compared. Path optimality is measured by the fitness value of the optimal path. Note that this paper focuses on the numerical value of the path fitness, which is calculated by J L + 1/J S , as given in (1), where J L and J S denote the path length and path safety.
The simulation parameters for each method

The simulation parameters for each method
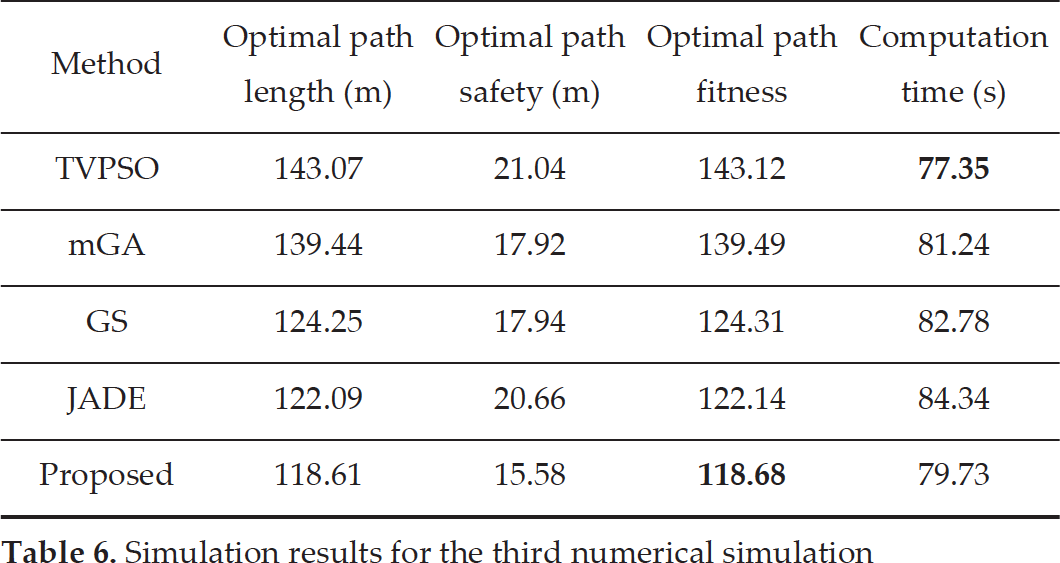
This subsection shows four numerical simulations that are all executed in a 100m x 100m workspace. From the first simulation to the last, there are, respectively, 8, 5, 17 and 11 obstacles in the workspace. Line st - ta is equally divided into 8, 12, 12 and 13 subsections from the first simulation to the last. The obtained paths of the five methods for the four simulations are demonstrated in Fig. 8. Fig. 9 displays the evolution curves of the five methods for the four simulations. The simulation results of the five methods for the four simulations are shown in Tables 4–7.
From Fig. 8, it is clear that each method is efficient at finding an obstacle-free path in each simulation. From Table 4 through to Table 7, it can be seen that Proposed method ≻ JADE ≻ GS ≻ mGA ≻ TVPSO in terms of path optimality and TVPSO ≻ Proposed method ≻ mGA ≻ GS ≻ JADE with respect to computation time. Here, “≻” denotes “dominate” or “outperform”. Although TVPSO is the fastest algorithm, it exhibits the worst performance at finding an optimal path. Though the proposed method is the second fastest algorithm, it is the best one at finding an optimal path. It is worth noting that the difference in computation time between TVPSO and the proposed method is around 2s in each simulation. Considering all of the concerns raised, it can be concluded that the proposed method performs superior to the other four methods in terms of establishing path optimality. Furthermore, the computation time of the proposed method is comparable with those of the other four methods.
From Table 4 through to Table 7, it is also interesting to note that the computation time of each method changes significantly from the first simulation to the last. For example, the computation time of the proposed method varies from 24.59s, 35.44s, 79.33s to 72.25s from the first simulation to the last. This is because the number of obstacles and the number of subsections of line st - ta are different in each simulation. Based on the computation time of a specific method from the first simulation to the last, as shown in Tables 4–7, it is found that when the workspace contains more obstacles and st - ta is divided into more subsections, the path planner will take a longer time to generate an efficient path. This is because when the workspace contains more obstacles and line st - ta is divided into more subsections, the complexity of the workspace and the number of waypoints along a candidate path are increased. Thus, the path planner will take longer to calculate the cost and the constraint violation degree of a candidate path, in addition to updating the position information of waypoints of a candidate path.
Simulation results for the first numerical simulation

Simulation results for the first numerical simulation
Simulation results for the second numerical simulation

From Fig. 9, it can be observed that the cost curves of some methods for some numerical simulations initially rise in the early part of the evolution. This happens because, in this paper, the feasibility-based rule [7, 27] is used to evaluate and select the elite path between any two candidate paths. Since the initial swarm of each method is randomly generated, the initial global best path of a method may collide with some obstacles, which implies that the initial global best path of the method is not feasible. In this case, with the evolution continuing, if any particle in the method searches for a new solution that has a smaller constraint violation degree but a larger path fitness value than those of the initial global best path, the initial global best path will be replaced by the newly-found solution, based on the feasibility-based rule. Therefore, in this case, the cost curve of the method will initially rise in the early phase of the evolution. However, with the evolution continuing, the cost curves of all methods will either keep dropping or will remain unchanged in the late phase of the evolution, as shown in Fig. 9. This is because each method can search for a feasible global best path in the late phase of the evolution. The feasible global best path can only be replaced by feasible solutions that have smaller fitness values than those of the feasible global best path, according to the feasibility-based rule.

Optimal paths of all methods for the four numerical simulations
Simulation results for the third numerical simulation
Simulation results for the fourth numerical simulation

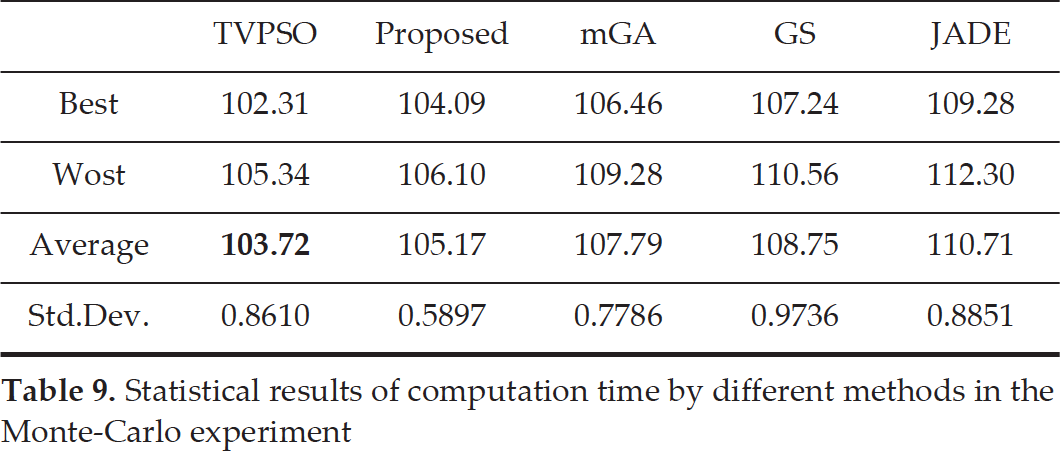
A Monte-Carlo experiment with 50 independent runs is carried out to further study the performance of the proposed method in this subsection. In each run of the Monte-Carlo experiment, the workspace is a 100mx100m area that contains 18 obstacles. Each obstacle has four vertexes that are randomly and uniformly distributed in the workspace. Line st - ta is equally divided into 15 subsections in each run of the Monte-Carlo experiment. After performing 50 independent runs, the statistical results, with respect to the fitness value of the optimal path and the computation time of each method, are reported see Table 8 and Table 9. The results corresponding to the statistical results shown in Table 8 and Table 9 are visualized in Fig. 10.

Evolution curves of all methods for the four numerical simulations
From Table 8, it is clear that Proposed method ≻ JADE ≻ GS ≻ mGA ≻ TVPSO in terms of the best, worst and average fitness value of the optimal path. Compared with TVPSO, the proposed method improves 9.75% on the average fitness value of the optimal path. From Table 9, it is obvious that TVPSO ≻ Proposed method ≻ mGA ≻ GS ≻ JADE in terms of the best, worst and average computation time. Compared to the proposed method, TVPSO improves 1.38% on the average computation time. However, despite the best performance of TVPSO concerning computation time, TVPSO has the worst performance in terms of path optimality. Although the proposed method ranks second with respect to computation time, it is the most efficient for producing optimal path. Since the difference in average computation time between the proposed method and TVPSO is less than 2s in the Monte-Carlo experiment, it can be concluded that the proposed method generally outperforms the other four methods in the context of finding the optimal path. In addition, the computation time of the proposed method is comparable with those of the other methods compared.
Statistical results of the fitness value for the optimal paths by different methods in the Monte-Carlo experiment

Statistical results of computation time by different methods in the Monte-Carlo experiment

Simulation results for the fitness value of the optimal paths and the computation time of different methods in the Monte-Carlo experiment
In this study, a hybrid PSO algorithm called HNTVPSO-RBSADE, which combines NTVPSO with RBSADE, is proposed to solve mobile robot global path planning. In the proposed algorithm, particles first follow the moving rules defined in NTVPSO to update their velocities and positions. Then, the RBSADE algorithm is developed to evolve the personal best positions of particles in order to avoid particles becoming stagnant. By fine-tuning the three control parameters, the exploration and exploitation capabilities of NTVPSO can be well-balanced. Consequently, NTVPSO promotes particles to search for high-quality paths. In order to enhance the performance and easily adjust the control parameters of RBSADE, a rank-based mutation operator and a self-adaptive strategy are developed in RBSADE. Since the convergence of HNTVPSO-RBSADE remains important, this paper first analytically investigates the convergence of HNTVPSO-RBSADE through standard results yielded by dynamic system theory. Then, a parameter selection principle is proposed to guarantee the convergence of HNTVPSO-RBSADE.
The proposed algorithm is tested using four numerical simulations and a Monte-Carlo experiment with multiple runs against four evolutionary algorithms. The simulation results reveal that the proposed algorithm outperforms the other four algorithms in terms of path optimality; furthermore, the computation time of the proposed algorithm is comparable with those of the other algorithms compared.
There are some issues that deserve future study. The first is how to theoretically analyse the optimality of the equilibrium point of HNTVPSO-RBSADE. Since the three control parameters also influence the convergence speed of the PSO algorithm, the second issue concerns the analysis of the sensitivity of the convergence speed of the proposed PSO algorithm to the three control parameters. Furthermore, since there does not exist a widely-accepted criterion for selecting an optimum number of waypoints along a candidate path [35], our work has to predefine the number of subsections that line st - ta is divided into, which remains problem-dependent. Thus, developing a strategy that can autonomously choose the number of dividing subsections for line st - ta can be considered as a future study. In order to generate a higher quality global path, more performance criteria, such as path length, path safety and the path smoothness must be considered when addressing the path planning problem in future research. Moreover, for further verifying the proposed method, we are considering comparing the proposed method with other non-evolutionary methods under more complex environments in the near future. Finally, we are also considering the possibility of extending the proposed method into 3-D path planning, since such an approach is more practical for real-world applications.
Footnotes
Acknowledgements
The authors express their sincere and heartfelt thanks to the editor and reviewers for their constructive suggestions to improve the quality of this paper. This work is financially supported by the Chinese National Science Foundation under Grant No.11472213. The authors declare that we have no conflicts of interest regarding this work.