
Abstract
Road detection is a key task for autonomous land vehicles. Monocular vision-based road-detection algorithms are mostly based on machine learning approaches and are usually cast as classification problems. However, the pixel-wise classifiers are faced with the ambiguity caused by changes in road appearance, illumination and weather. An effective way to reduce the ambiguity is to model the contextual information with structured learning and prediction. Currently, the widely used structured prediction model in road detection is the Markov random field or conditional random field. However, the random field-based methods require additional complex optimization after pixel-wise classification, making them unsuitable for real-time applications. In this paper, we present a structured random forest-based road-detection algorithm which is capable of modelling the contextual information efficiently. By mapping the structured label space to a discrete label space, the test function of each split node can be trained in a similar way to that of the classical random forests. Structured random forests make use of the contextual information of image patches as well as the structural information of the labels to get more consistent results. Besides this benefit, by predicting a batch of pixels in a single classification, the structured random forest-based road detection can be much more efficient than the conventional pixel-wise random forest. Experimental results tested on the KITTI-ROAD dataset and data collected in typical unstructured environments show that structured random forest-based road detection outperforms the classical pixel-wise random forest both in accuracy and efficiency.
1. Introduction
Road detection is a key task for outdoor mobile robots like autonomous land vehicles (ALVs), which have been studied for decades [1]. Though types of sensors like the monocular camera [2, 3], stereo camera [4] and laser scanner [5] have been employed to detect the road, the monocular camera is one of the most frequently used ones, due to its being cheap in cost and rich in information. In highly structured environments like highways with well-painted markings, one can use lane detection to find the drivable area. However, in general urban or rural areas, the roads may not be marked or the markings may be damaged. This kind of general road detection is considered to be more difficult than lane-marking detection. In addition, the variations of road types and the presence of shadows, specularities and puddles caused by changes in weather and illumination make it even more challenging.
General monocular road-detection systems mostly use the machine-learning algorithms to classify the pixels of a given image as road or background. In the literature, various machine-learning methods have been applied in road detection. However, most of these methods classify each pixel independently, ignoring the contextual interaction. Thus, the outputs are usually very noisy due to the ambiguity of the appearance of a single pixel. Although some methods take the image patch or superpixel as the classification unit, the binary label space may lead to inaccurate output boundaries. Structured prediction [6] is an effective method for modelling the interaction with the context. A commonly used structured prediction method in computer vision is the Markov random fields (MRF), or conditional random fields (CRF) [7, 8]. However, the optimization of pixel-wise random fields is often too time consuming to be used in real-time systems. In this paper, we propose employing the structured random forest method [9, 10] to classify the image patch in a structured manner. With an efficient mapping of structured labels to discrete labels, the structured random forests can be trained in a similar way to the traditional random forests [10]. The proposed structured random forest-based road detection method exploits the contextual information of the image and the structural information of the label patch to improve the performance. In addition, by predicting a batch of pixels in a single classification, the proposed method is very fast in the run time. Extensive experiments show that the structured random forest-based road detection can achieve better results than the traditional pixel-wise random forest, patch-wise random forest and the even the CRF-based method, which is much more time consuming.
The rest of this paper is organized as follows. Section 2 briefly introduces the related work regarding road detection and structured random forests. In Section 3, we briefly review the training and testing of random forest classifiers. Then, in Section 4, we introduce the structured random forest-based road detection in detail. The image-feature extraction is presented in Section 5, and in Section 6 we describe some comparative experiments that we conducted to validate the proposed method. Finally, we draw conclusions in Section 7.
2. Related Work
Road detection has been a hot research topic for decades. Many road-detection algorithms have been developed. Monocular road-detection algorithms can be roughly divided into two classes: edge-based and region-based. Edge-based methods are widely used in structured environments with clearly delineated boundaries. Usually, a road model is assumed and some low level cues are extracted to fit the parameters of the model [11–13]. A Kalman filter [12] or a particle filter [11, 13] is then employed to track the parameters. In addition, vanishing point detection can be utilized as a constraint for road edge detection [2]. In this paper, we focus on region-based methods.
Region-based road detection usually uses machine-learning approaches to learn a classifier using labelled samples and then to classify the pixels into two classes (road and background) or sometimes three classes (road, sky and others [14]). The training samples are acquired by either making the assumption that the central-lower part of the testing images always belongs to the road surface [15] or manually labelling the offline collected images [16]. After getting the training samples, the two most influential factors are the feature extraction and the classification approaches employed. For feature extraction, various kinds of image features have been investigated. Colour is the most commonly used feature, such as different colour space representation (HSI [17], LAB [14] and normalized R-G [4, 15]), colour histograms [18] and illumination invariant images [4, 19, 20]. Other frequently used features include texture filter responses [4, 21] and other texture descriptors [22]. Recently, feature learning has become a hot topic in computer vision. Various learning-based feature-extraction methods have been used in road detection, such as slow feature analysis [23], dictionary learning [24] and convolutional neural network (CNN) [3]. Currently, deep learning is popular in feature learning and has achieved great success in various computer-vision problems. In [25], Mohan proposed combining deep deconvolutional neural networks with CNNs for road scene parsing, and good performance was achieved. However, deep learning models are often complex and rely on the latest graphic processing unit (GPU) for fast computing.
For machine-learning approaches, various methods have been employed, such as mixture of Gaussian [26], support vector machines [27], boosting [21, 28], random forest [4, 29] and neural networks [30, 31]. However, these methods usually classify the pixels independently, and therefore they do not take the contextual information into consideration. Some methods take the image patch or superpixel as the classification unit, but they classify the whole patch or superpixel as road or background, leading to degraded resolution and inaccurate zigzag boundaries. The contextual information can be beneficial for the overall classification performance. In [18] and [32], the importance of contextual information in road detection is emphasized. They generate many road-probability maps according to the locations or the scene types and then use the global position system or scene classification to select a more suitable probability map for guiding the online road detection. However, these methods rely on extra sensory data or expensive online computation. In addition, they cannot adapt to new scenes. Alternatively, structured prediction is an effective approach for modelling the interaction between the pixel and its context [6]. In road detection, a widely used structured prediction method is the Markov random field or conditional random field [7, 8]. However, the inference of random field is often time consuming and unusable in real-time systems, especially for high resolution images. Considering the need for structured prediction, and the rapid training and testing of random forests, Kontschieder et al. [9] proposed a method by which the random forests can be augmented with structured labels. The structured label space poses a challenge in selecting the best test functions during the training process. In [9], the authors used a single pixel label randomly sampled from the patch to represent the label of the patch and then train the test functions in the manner of the traditional random forests. In [10], Dollár and Zitnick proposed an improved strategy for training structured random forests. They firstly map the structured label to a dimensionally reduced binary vector and then further perform K-means clustering or principal component analysis (PCA) in order to obtain the discretized label. This method was used for edge detection and achieved the state-of-the-art.
Inspired by [10], this paper proposes utilizing structured random forest for rapid road detection. With each image patch predicted using a structured label, both the contextual information and the structural information of the label can be taken into account. By formulating the road detection as a binary classification problem, the patch label can be readily rearranged into a binary vector and then mapped to a discrete label with K-means clustering or PCA. Thus, the training of structured random forests can be performed in a similar way to that of classical random forests. During testing, a batch of pixels are predicted within one classification, making the algorithm very efficient and suitable for real-time vision navigation of ALVs.
3. Random Forest Classifier
In this section, we give a brief review of the random forest classifier. Random forest [33, 34] is a ensemble of N independently trained decision trees. Each decision tree

in which k is the feature index and t is the threshold value. For each leaf node, a prediction model is attached. The most frequently used prediction model is the leaf statistics captured with the conditional distribution
3.1. Decision tree training
During the training period, for each node j and the incoming training set Sj, we sought the best split function
For classification trees, usually the maximum information gain is sought:

where
3.2. Randomness and the ensemble model
Random forest is an ensemble model of the N decision trees. Randomness plays an important role in the performance of the whole forest. Randomness can be injected via random training set sampling and randomized node optimization. Randomness helps to reduce possible overfitting and improve the generalization capabilities.
4. Structured Random Forest-based Road Detection
Random forest is popular for several reasons: 1) it is simple to implement; 2) it is fast in training and even faster in testing; 3) it is resistant to overfitting and 4) it is fully parallelizable. However, when applied in road detection, pixel-wise random forest classifiers predict each pixel independently, ignoring the interaction between the neighbouring pixels. This kind of method may thus generate inconsistent outputs, which can be extremely noisy. Some researchers tried to classify each patch or superpixel instead of individual pixels. This kind of method partially utilized the contextual information. However, these methods map each segment to a discrete label and therefore cause a reduction in the resolution of the final output, especially at the boundaries. A more effective solution to the problem is structured prediction [6]. In structured prediction, the prediction function maps the input domain X to a structured label space Y, instead of to the discrete label space C. Conditional random field (CRF) is a kind of structured prediction approach which is used widely in computer vision. However, CRF is a kind of probabilistic graphical model and the inference relies on time-consuming message passing or graph cutting. Inspired by Kontschieder's [9] and Dollar's [10] work on structured random forest, we propose employing the much more efficient structured random forest for locally consistent road detection.
4.1. Formulation
In monocular vision-based road detection, we want to classify the pixels into road (

Illustration of structured labels used in road detection. On the left is the ground-truth of a typical road image and on the right is the zoomed view of the corresponding patches, marked with boxes of the same colour used in the left image.
For a general labelled road image, we observed that the label patches are organized not randomly but in a highly structured manner. As is shown in Figure 1, the four boxes with different colours represent four typical kinds of structured labels, that is, all road, all background, partial road on the left boundary and partial road on the right boundary. This observation is usually ignored by the traditional pixel-wise classifiers. However, it can be exploited to improve the performance of road detection with structured random forests.
4.2. Structured random forest training
In random forests with discrete label spaces, we pursued the best split parameter with the maximum information gain. However, in structured random forests, the structured label spaces are highly dimensional and much more complex. This leads to two problems in the training process: one is the prohibitive complexity of evaluating the candidate splits and the other which is more critical is that the information gain over the structured labels may not be well defined [10]. These are the key problems to be solved in structured random forests. The common solution is to build a map between the structured labels and discrete labels. In [9], Kontschieder proposed two schemes to obtain the discrete label: one is to take the label of the central pixel of the patch, and the other is to take the pixel label of a position that is drawn randomly within the patch. These intuitive methods fail to make full use of the holistic information of the label patch, and the use of the randomly selected or fixed single position label makes the training less effective. To solve these problems, [10] proposed a two-stage approach for mapping the structured labels to a discrete label space. This approach firstly maps the structured labels to long binary vectors and then performs K-means clustering or principal component analysis (PCA) to obtain the discrete labels. This method is more effective because it takes the whole label patch into account.
In road detection, the structured label is a binary patch and we can readily rearrange the patch label to get a binary vector. Then, following [10], we can employ the K-means clustering or PCA to get the corresponding discrete labels. In K-means clustering, we set

Discretized labels with K-means clustering. The label patches of the samples that arrive at a certain internal node are mapped to the discrete label 1 (the left image) or 0 (the right image).
Compared to K-means clustering, PCA-based discretization is much more computationally efficient. We project the long binary vector to the first principle direction and assign a discrete label 0 or 1 according to whether or not the projection falls on the positive semi-axis. Figure 3 shows the results of discretization using PCA on the same samples as in Figure 2. We can see that there is no significant discrepancy between these two discretizing methods. Considering the computational efficiency, we employed the PCA-based discretization in this paper.

Discretized labels with PCA. The same samples and presentation scheme are used as in Figure 2.
After discretizing the structured labels, we can train each decision stump of the decision tree with the normal information-gain criterion. For the test functions, we considered the single location feature and the feature difference between a couple of locations. For a testing image with a resolution of

where

An alternative kind of test function can be the paired sites difference, i.e.,

in which
4.3. Structured label prediction
For each leaf node of the tree, we gathered a set of training patches during the training procedure. We can parametrize the leaf node with either a conditional distribution or a MAP estimation. Denote

where

In this paper, we chose to use a simpler scheme to parametrize the leaf node, in which we directly stored the marginal distribution of each pixel in the patch. This scheme is advantageous for its efficient calculation and reservation of more information. In addition, because the road detection is a binary classification problem, we only need to record the probability of being road for each pixel position in the patch.
4.4. Road detection with label fusion
After training a structured random forest using N decision trees, we need to predict the road area for a given testing image. Unlike the classical pixel-wise random forests which classify each pixel independently to obtain the whole prediction, structured random forests classify the patch and obtain the structured prediction with a

Road detection with label fusion. The upper part is the input image and the lower part is the road probability map.
5. Feature Extraction
For each image, we extracted pixel-wise channel features including, texture filter bank response, illumination invariant image and colour. We also included the location cues in the feature.
Texture Filter Bank Response. The images are converted to the CIE-LUV colour space and then a filter bank is applied to the grey-scale image or each channel of the CIE-LUV image. Concretely, Gaussian filters are applied to each channel while the horizontal and vertical Gaussian derivative filters and the Laplacian of Gaussian filters is applied to the grey-scale image. Therefore, for a given scale σ, we get a 6-dimensional feature for each pixel. In this paper, three scales are employed so we get an 18-dimensional texture filter bank response for each pixel.
Illumination Invariant Image. The presence of shadows in the image is a challenging problem for image-based road detection. To reduce the impact of illumination, we included the illumination invariant image in the feature. In [35], Finlayson et al. proposed an efficient method to recover shadow-free image representation. For the sake of simplicity, we extracted the 1D shadow-free image feature [35] and took it to be one of the feature channels. Figure 5 shows an example of shadow-free image representation.
Colour and Location. RGB channels of each pixel are included in the feature. In addition, the location of the pixel is a useful cue for road detection because the road usually appears at the central lower part of the image. Hence, the 2D normalized locations of the pixels are also used as part of the feature.

Illumination invariant image-feature channel: the upper part is the source image and the lower part is the shadow-free image
Therefore, finally, we get a 24-dimensional feature vector for each pixel in the image.
6. Experiments and Results
6.1. Experimental setting
The algorithm was implemented with C++ under Ubuntu 12.04. Experiments were tested on a standard PC with 8GB RAM and an Intel Core i5-3230 CPU @ 2.6G Hz.
There are several important parameters during the training of structured random forests: the size of the image patch d, the maximum depth
6.2. Performance evaluation
To evaluate the proposed method, we conducted some experiments on both a publicly available urban-road dataset and unstructured road data collected using our own autonomous land vehicle platform.
6.2.1. KITTI-ROAD dataset
The KITTI-ROAD benchmark dataset [16, 36] is a well-known dataset which is widely used for the evaluation of urban road-detection algorithms. According to the different scenes in which the data were collected, the KITTI-ROAD dataset is split into three subsets: urban unmarked (UU), urban marked (UM) and urban multiple-marked lanes (UMM), each of which contains about 100 training images and 100 testing images with a resolution of approximately
Firstly, we used only the training sets of KITTI-ROAD for our experiments. We randomly split each of the three training sets of different scenes into two equally numbered parts. One was used for training, and the other was used for testing. For example, we split the 95 training images of the UM subset with ground-truth provided into two sets: one with 47 images for training, and the other with 48 images for testing. For notational simplicity, we denoted these two sets as the new UM training set and the new UM testing set, and did the same for UMM and UU.
In order to verify the superiority of the proposed structured random forest (denoted the
Figure 6 shows some qualitative comparisons between these algorithms. We can see that the pixel-wise predictions of random forest are noisy, and that this can be improved by CRF optimization to a certain extent. However, when too many pixels are misclassified, as is shown in the right-hand column of Figure 6, the result after CRF optimization is also erroneous. In comparison, the patch-based methods (including PatchRF and SRF) can reduce the ambiguity by exploiting the contextual information. Additionally, because the whole patch is predicted as being either 1 or 0, the outputs of PatchRF are lower in resolution and zigzag at the boundaries, and are therefore less accurate than the proposed SRF. The results validate the contextual information, and the structural information of the label exploited by the proposed method can help to improve the performance of road detection.
For quantitative evaluation, we used the official development kit to evaluate the aforementioned methods in the perspective view on the three subsets. The results are listed in Tables 1, 2 and 3. The best ones are marked in a bold typeface. From the results, we can see that our proposed method achieves the best or near-to-best performance for all indices on the three subsets.

Results of the KITTI-ROAD dataset. The first row presents the source images; the second row is the ground-truth; the third row gives the results of the basic pixel-wise random forest; the fourth row is the results of the patch-wise random forest; the fifth row is the results of the pixel-wise random forest with CRF optimization and the last row is the results of the proposed structured random forest-based road detection.
Comparative Results on the New UM Set (Perspective View)

Comparative Results on the New UMM Set (Perspective View)
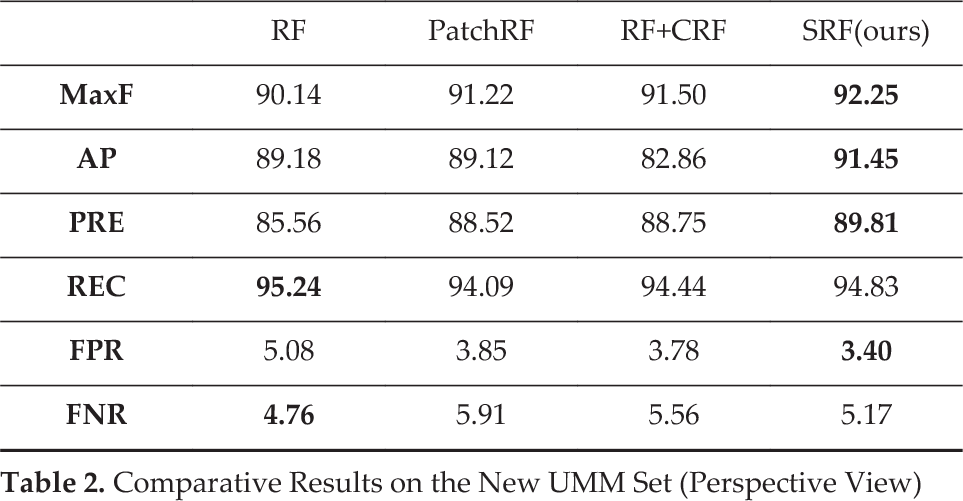
Comparative Results on the New UU Set (Perspective View)
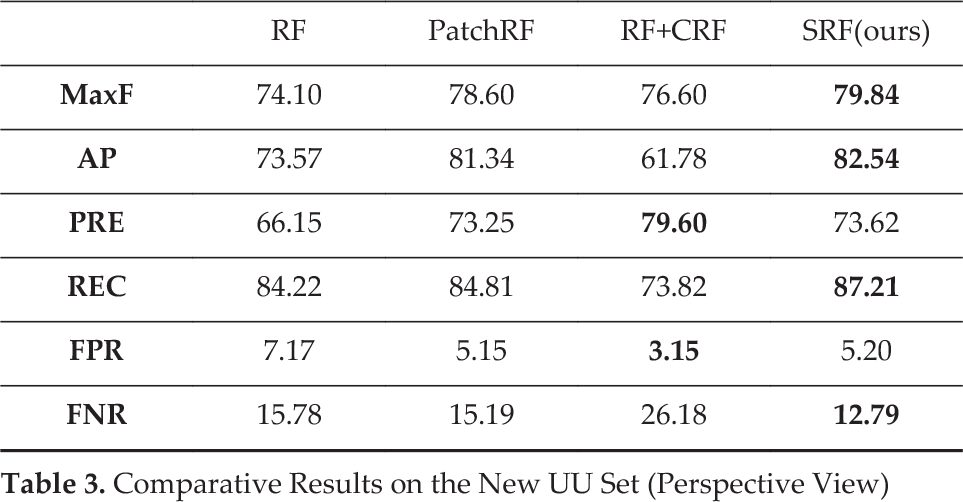
In addition, we also used the precision-recall (P-R) curves to evaluate the methods. We show the results in Figure 7. Note that the CRF outputs binary results and, therefore, it is shown as a single point in the P-R figure. From the figures, we can see that the structured random forest outperforms the pixel-wise random forest by a considerable margin. The patch-based random forest gets better results than the pixel-wise random forest by exploiting the contextual information. However, it is inferior to the structured random forest because its binary classification of the patches may cause errors at the boundaries. In addition, CRF optimization can improve the results of pixel-wise random forest via complex global optimization, but the performance is still inferior to the proposed SRF, which is even more efficient.
To further validate the effectiveness of the proposed algorithm, we evaluated it on the testing set of the KITTI-ROAD dataset. We used all of the training images of UM, UMM and UU subsets to train the models. The predictions of the testing images are transformed to a bird's-eye view (BEV) and uploaded to the website for evaluation [16]. We compared the results of our algorithm with those of several recently developed ones, including CN [3], ARSL-AMI [7], SPlane+BL [38], ANN [31] and the baseline (BL) [16] algorithm that was released with the dataset. We listed the comparative results tested on the UM, UMM, UU subsets and the average results in Table 4, Table 5, Table 6 and Table 7. From the results, we can see that the proposed method achieves better maximum F1-scores (MaxF) than the others when applied to the UMM and UU subsets. However, the results for the UM subset are not as good. We analysed the detection results and found that the proposed method obtained poor results in several scenes with different road textures and large sections of heavy shadow. Therefore, we can use more training samples and design more discriminative and illumination-invariant features for better performance. Overall, the average results of the proposed method are superior to the others. Apart from better performance, our method can be advantageous in terms of efficiency. The computational time will be further introduced in Section 6.3.

Precision-Recall curves tested on the KITTI-ROAD dataset. The top left, top right and bottom left show the results of the new UM, UMM and UU sets, respectively, and the bottom right shows the average results of the three sets.
Results of Online Evaluation on the UM (BEV)

Results of Online Evaluation on the UMM (BEV)

Results of Online Evaluation on the UU (BEV)
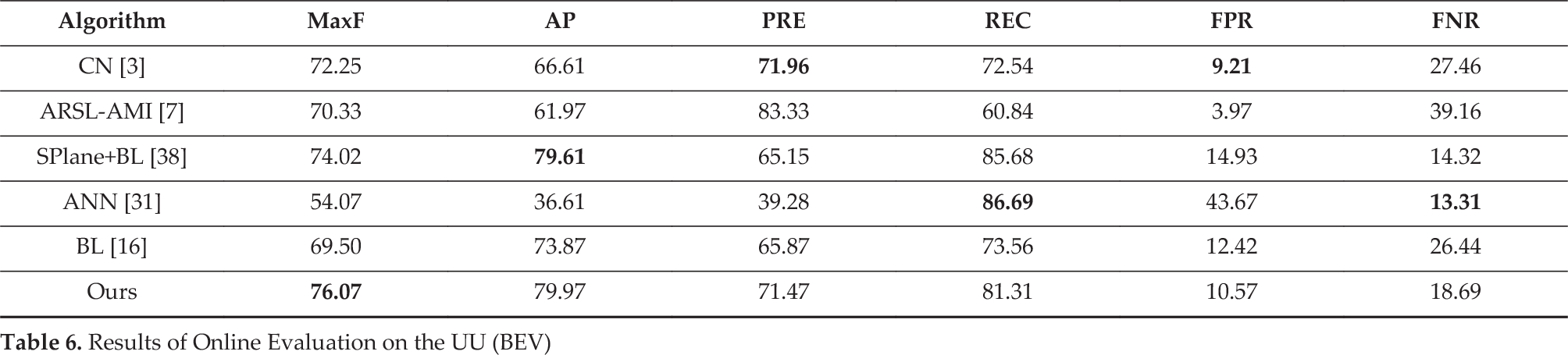
Average Results of Online Evaluation on the KITTI-ROAD Dataset (BEV)

6.2.2. Unstructured road dataset
We then tested the performance of the proposed algorithm with the actual data collected by our own autonomous land vehicle (ALV). Our ALV is a modified Toyota Land Cruiser equipped with cameras and other sensors. As is shown in Figure 8, the yellow box shows the mounting position of the camera used for road detection.
Our ALV aims to run autonomously on typical unstructured roads, using monocular vision for road detection. Here, we used two typical scenes to evaluate the proposed algorithm, namely Scene I and Scene II. Concretely, Scene I consists of 195 images which were collected on sunny days with highlights and shadows, and Scene II consists of 153 images which were collected on sunny days (some after rain) with puddles and specularities on the roads. As is shown in Figure 9, the first row shows some examples of Scene I and the second row shows some examples of Scene II. We manually labelled the images pixel-wise and split each set into two equally numbered subsets: one used for training and the other used for testing. To make the road detection run in real time, we cropped and downsampled the images to

Modified Toyota Land Cruiser platform. The yellow box indicates the camera used for road detection.

Samples of unstructured road images collected using our own ALV. The first row is Scene I and the second row is Scene II.
To validate the superiority of the proposed method for unstructured road detection, we took the vanishing point-based general road detection (denoted as
For quantitative evaluation, we again used the P-R curves. The results tested on the two scenes are shown in Figure 11. From the figures, we can see that the learning-based approaches can achieve much better results than the vanishing point-based approach, which uses no data-related prior information. For the learning-based ones, the proposed structured random forest always achieves the best results, which are comparable to or even better than the pixel-wise random forest with CRF optimization. Compared to the pixel-wise random forest, the patch-based random forest exploits the contextual information to reduce ambiguity. However, the binary prediction of the patch reduces the resolution of the output, especially at the boundaries, and this can cause degradation of performance. Therefore, the overall performance of the patch-based random forest may vary from case to case. This is shown in Figure 11. In Scene I, the PatchRF gives even slightly worse results than those of the pixel-wise RF. In Scene II, however, the results of PatchRF are better than those of the pixel-wise RF and only slightly worse than the SRF. The reason may be that the contextual information plays a more important role in Scene II, and the structural information of the label patch exploited by the SRF is less helpful due to the obscure boundaries of these images. Additionally, the question of whether a method is time consuming is another important factor for real-time applications. It can be seen that the patch-based methods save much more time. This will be introduced in detail in the following subsection.

Results of unstructured road detection. The first column presents the source images, the second row is the results of the vanishing point-based road detection and the last column is the results of the proposed method.

P-R curves of unstructured road detection with different algorithms
6.3. Computational time
The time consumed in road detection is crucial for the navigation of autonomous land vehicles. Therefore, we investigated the computational time of the proposed method in the testing phase. Since patch-based methods predict a batch of pixels within a single classification, the total times needed for classifying the whole image are reduced substantially compared to those of pixel-wise classifiers. Taking the unstructured road detection as an example, the resolution of input images is
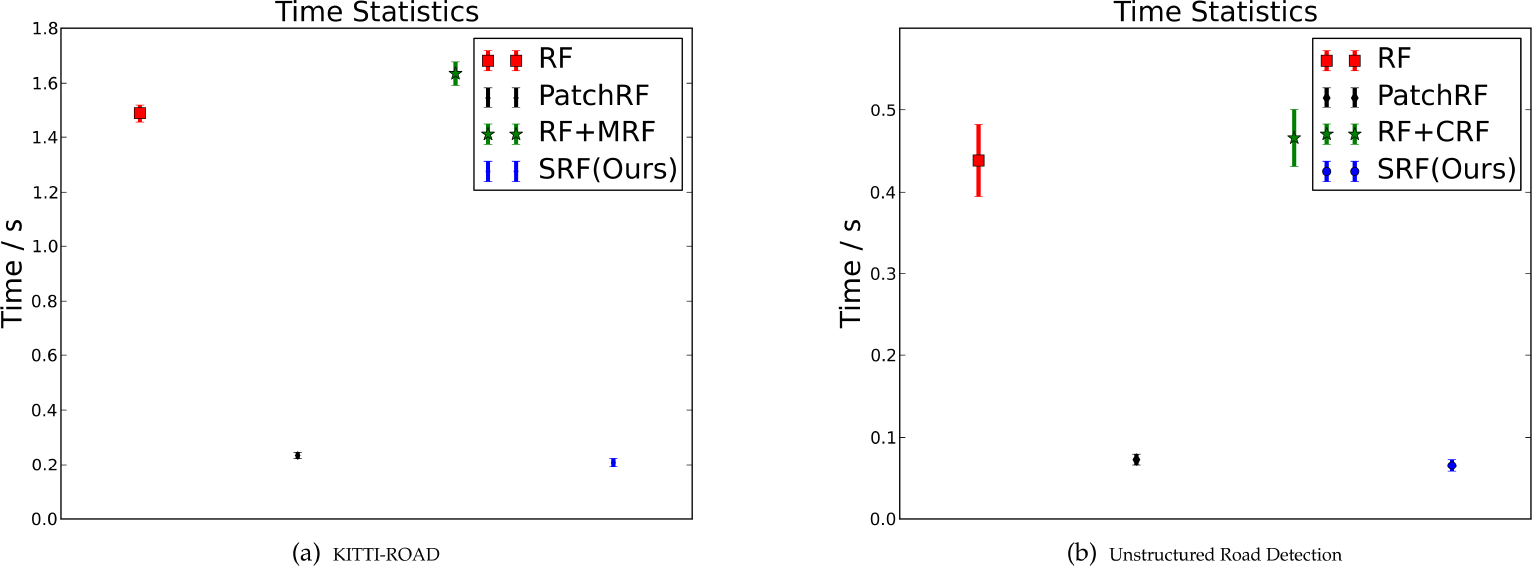
Running time statistics of different algorithms on the KITTI-ROAD dataset and the unstructured road images
7. Conclusions
Road detection is an essential task for the visual navigation of autonomous land vehicles. Most monocular road-detection algorithms employ certain machine-learning approaches to classify each pixel or patch as either road or background. However, these methods fail to make good use of the contextual information of the pixel and the structural information of the labels, which can be very helpful for reducing ambiguity and improving accuracy. In this paper, we proposed using the structured random forest for road detection. The benefits are twofold: first, the contextual information of the pixels is encoded and the structural information of the labels is exploited. Second, by predicting a batch of pixels in each classification, the computational complexity is significantly reduced compared with pixel-wise classifiers. Experiments tested on the KITTI-ROAD dataset and data collected in typical unstructured environments show that the structured random forest can substantially improve the accuracy of road detection over the classical pixel-wise and patch-wise random forest classifiers and, at the same time, be very computationally efficient.