
Abstract
Finding high quality paths within a limited time in configuration space is a challenging issue for path planning. Recently, an asymptotically optimal method called fast marching tree (FMT*) has been proposed. This method converges significantly faster than its state-of-the-art counterparts when addressing a wide range of problems. However, FMT* appears unable to solve the narrow passage problem in optimal path planning, since it is based on uniform sampling. Aiming at solving this problem, a novel region-based sampling method integrating global scenario information and local region information is proposed in this paper. First, global information related to configuration space is extracted from an initial sample set obtained via hybrid sampling. Then, local regions are constructed and local region information is captured to make intelligent decisions regarding regions that are difficult and need to be boosted. Finally, the initial sample set is sent to FMT* using a modified locally optimal one-step connection strategy in order to find an initial and feasible solution. If no solution is found and time permits, the guided hybrid sampling will be adopted in order to add more useful samples to the sample set until a solution is found or the time for doing so runs out. Simulation results for six benchmark scenarios validate that our method can achieve significantly better results than other state-of-the-art methods when applied in challenging scenarios with narrow passages.
1. Introduction
Over the past number of decades, path planning in static scenarios has been extensively studied. In terms of configuration space, the basic problem can be generally described as computing a collision-free path for an object to move in, from a given start configuration to a goal configuration. Sampling-based methods such as probabilistic roadmaps (PRM) [1], rapidly exploring random trees (RRT) [2] and the many variants of these have shown outstanding performance, especially in high-dimensional configuration space. However, traditional sampling-based methods do not pay much attention to path quality (path cost), which can be measured in terms of length, clearance, smoothness, energy consumption, etc. Hence, when considering path quality, the majority of traditional methods produce suboptimal solutions. This phenomenon has promoted the study of optimal path planning, which targets improved path quality.
Concerning path quality, recent asymptotically optimal sampling-based methods have shown promising results. Karaman and Frazzoli provide a definition of asymptotic optimality and prove that PRMstar (PRM*), rapidly-exploring random graph (RRG) and RRTstar (RRT*) can converge to an optimal solution, as the number of samples approaches infinity, with probability one [3]. Although these methods have solutions that can be improved over time, they do not guarantee a reasonable rate of convergence. To compensate for this problem, many variants of PRM* and RRT* have been proposed for improving efficiency. Building on PRM*, some works [4, 5] that provide guaranteed sub-optimality are presented, where optimality is traded for faster computation. Salzman and Halperin present the lower bound tree RRT (LBTRRT) method [6] which is also asymptotically-near optimal. In order to mitigate the greediness of RRT*, RRTsharp (RRT#) [7] and RRTx (RRT x ) [8] are developed using the idea of lifelong planning A* (LPA) [9] in a rewiring cascade. A lazy strategy is also adopted in lazy PRM* [10] and lazy RRG [11], where the core idea is to delay the collision check until it absolutely necessary. Additionally, many different heuristics for speeding up convergence are presented in [12–17].
Another asymptotically optimal method, proposed by Janson and Pavone, is fast marching trees (FMT*) [18]. To alleviate the inherently unordered search of sampling-based methods, FMT* extends graph-search methods to sampling-based methods and concurrently performs graph construction and graph search within cost-to-come space. It is faster than PRM* and RRT* in terms of converging to an optimal solution within many different scenarios. However, FMT* selects a predetermined number of samples and is not an any time method. Generally, an any time method can quickly find an initial feasible solution and then, given more computation time, improve the solution towards an optimal solution [19]. As FMT* selects a predetermined number of samples, if a lower cost path is needed, it must increase the number of samples and replan. Moreover, it is difficult to select an appropriate number of samples, which is problem-dependent. To solve these problems, an anytime version FMT (aFMT*) is adopted in [20]. It chooses a small number of samples and applies FMT*, then doubles this number and repeats the process if time permits. In addition, to speed up convergence, motion planning using lower bounds (MPLB) [20] extends aFMT* by including the lower bounds on cost, while batch informed trees (BIT*) [21] introduces an ellipsoidal heuristic. However, as a sampling-based method, FMT* with a uniform sampling strategy suffers from the notorious narrow passage problem [22], where sampling in small volumes is difficult. If a robot has to pass a narrow passage to arrive at the goal position in a scenario, it may cause significant challenges for FMT* and the above noted extended methods.
To cope with the narrow passage problem, many non-uniform sampling strategies have been proposed to increase the proportion of free configurations in some areas. These include obstacle-based PRM (OBPRM) [23] and Gaussian PRM [24] sample nodes near the surfaces of obstacles; a bridge test sampler [25] generates nodes inside narrow passages. Medial axis PRM (MAPRM) [26] retracts nodes to the medial axis of the free space. Although there exist many sampling strategies, no one outperforms all others for all problem instances. To achieve a better distribution of samples, different sampling strategies are combined in [27, 28]. In addition, region-based methods [29,30] divide the configuration space into some local regions and use local region information to decide where to boost sampling intelligently, or which sampler to apply. However, some region-based methods use only the local region information and no other global information for guiding the region classification. Concerning global information, Rantanen used the connectivity of the entire PRM roadmap to decide which regions were useful [31].
In this paper, we propose a region-based sampling method integrating global scenario information and local region information to solve the narrow passage problem in optimal path planning. The flowchart for doing so is shown in Fig.1. First, hybrid sampling is adopted to sample a small predetermined number of samples. These samples can be classified into three types: uniform (blue), Gaussian (green) and bridge (red). Second, the global scenario is characterized based on the proportion of these samples. Third, the configuration space is partitioned into regions and local region information is exploited to determine the difficulties of regions. According to the difficulties of regions, we classify the regions into three categories: easy (cyan), normal (purple) and difficult (orange). Then, more samples (yellow) are added to the difficult regions. Finally, the initial sample set is sent to FMT* with a modified locally optimal one-step connection strategy to solve the optimal path planning problem. If our method cannot find a solution on the current sample set and if extra time is available, the following process is repeated: double the number of samples using the guided hybrid sampling and apply FMT*. Since our goal is to find a low-cost solution in challenging scenarios within the shortest space of time, a novel measure of cost called harmonic mean cost is also utilized for evaluation to better describe the performance of asymptotically optimal methods.

The remainder of this paper is organized as follows. Section 2 describes some preliminaries, including FMT*, aFMT*, a modified locally optimal one-step connection strategy of FMT* and quartiles. Section 3 gives the details of our method. Experiments and discussions pertaining to six scenarios are shown in section 4. Finally, we come to conclusions and discuss possible extensions in section 5.
2. Preliminaries
Let
2.1. Fast Marching Tree
Fast marching tree is an asymptotically optimal method. Its anytime version is outlined in Alg.1 and its notations and functions are described in Tab.1. First, aFMT* samples a small number of free samples; then, these samples,
The Definitions of Notations and Functions in FMT*

As sampling-based methods, FMT* and extended methods [20, 21] employing a uniform sampling strategy meet the challenge posed by the narrow passage problem. To cope with this situation, they have to increase the number of samples until there are enough samples in narrow passages. Obviously, this is a time-consuming process. Non-uniform sampling strategies are widely used to solve the narrow passage problem and the asymptotic optimality of FMT* with a non-uniform sampling strategy has already been demonstrated in [18]. Therefore, in this paper, a novel non-uniform sampling method will be applied in FMT* to solve the narrow passage problem.

Another problem, i.e., the locally optimal one-step connection strategy of FMT* (Alg.1, line 10), makes it difficult to add a new node to the tree when the

The locally optimal one-step connection strategy of FMT* is illustrated in (a)-(c). The modified locally optimal one-step connection strategy is illustrated in (a) and (d). Obstacles are coloured grey. The edges of the tree are depicted by solid black lines. The valid and invalid connections are depicted by solid and dotted lines, respectively.
To overcome the above problem, we made a modification to the locally optimal one-step connection strategy of FMT*. Namely, if x has selected y as
2.2. Quartiles
In descriptive statistics, the quartiles of a ranked set of data values are the three points that divide the data set into four equal groups, each group comprising a quarter of the data [32]. As shown in Fig.3, the lower quartile Q1 is defined as the middle value between the smallest value and the median of the data set. The median Q2 is the median of the data set. The upper quartile Q3 is the middle value between the median and the highest value of the data set. The interquartile range

Box plot with quartiles and an interquartile range

A point beyond an inner fence on either side is considered as a mild outlier, while a point beyond an outer fence is considered as an extreme outlier. The quartiles and the fences will be used in the region classification.
3. Region-specific Hybrid Sampling Method
3.1. Hybrid Sampling
The hybrid sampling fully combines a uniform sampler, a Gaussian sampler [24] and a bridge test sampler [25], and is described in Alg.2 and Fig.4. An initial sample set V is generated by the hybrid sampling and these samples can be classified into three types: uniform (Alg.2, line 4), Gaussian (Alg.2, line 9) and bridge (Alg.2, line 13). Different from [27], our hybrid sampling does not filter out any type of free samples. Therefore, our hybrid sampling is a uniform sampling strategy and works almost as fast as a uniform sampler. Different from a uniform sampler, our hybrid sampling provides more information about global scenarios for learning.

Hybrid Sampling. From top to bottom, the number of each type of samples is on the increase, and the time cost on them is on the decrease.

3.2. Global Scenario Learning
Based on these different types of samples, we present three measures for characterizing the global scenario. The first is the ratio of free samples to all samples. It can be calculated by:

Here, # x represents the number of x. This measure can estimate the volume of
The second and third measures are the ratio of bridge samples to uniform samples and the ratio of Gaussian samples to uniform samples, which are named

The

The buRatio can characterize whether configuration space obstacles are evenly distributed. Uniform, Gaussian and bridge samples are coloured blue, green and red, respectively. Obstacles are coloured grey.
In addition, as shown in Fig.6, combining the

Combining the freeRatio and the buRatio can provide additional information about narrow passages
3.3. Local Region Learning
3.3.1. Region Construction
There are many ways in which to construct a set of regions [28–31]. Our region construction method is related to [30] but differs in two aspects. First, we only consider free samples. Second, according to the sample type, start, goal, bridge and Gaussian samples have priority in terms of deciding whether to be selected as a region centre. The region construction method is depicted in Alg.3. Each new region centre is randomly selected from the samples that are not already in other regions in the subsets of V (Alg.3, line 3). Neighbouring samples are selected from V (Alg.3, line 4). Each new region radius is the maximum distance from the region centre to the samples in this region (Alg.3, line 7), while each new region's average radius is the median distance from the region centre to the samples in this region (Alg.3, line 8). Then, the

Region construction. Uniform, Gaussian and bridge samples are coloured blue, green and red, respectively. Obstacles are coloured grey. The initial number of samples in each region k' is set to 6 in this figure.

3.3.2. Region Classification and Boosting
In [30], the entropy of the regions is used to classify the regions into four classes: free, surface, narrow and blocked. However, to achieve relatively good performance in terms of classification, several thresholds should be fine-tuned in different scenarios. Therefore, it is crucial to develop a method that is scenario-independent and requires as little as possible user intervention. In this paper, a novel method based on statistics is introduced to classify the regions.
Since only free samples are stored, the scale of the radius for different regions varies dramatically. As shown in Fig.7, the region radius is small in open areas, while large in cluttered areas. Intuitively, we can use the region radius as a measure to determine the difficulty of a region. However, maximum and mean are not robust statistics, and they may be susceptible to outliers. Therefore, we chose the average radius rather than the radius to characterize a region. Similarly, the region average radius is small in open areas and large in cluttered areas. In addition, the quartiles were adopted to define the thresholds of the region's average radius, which was in turn utilized to classify the regions. According to the difficulties of regions, we classified them into the following categories: easy, normal and difficult.
Each region average radius is pushed into a queue. For this queue, we compute the lower quartile Q1, the median Q2, the upper quartile Q3, the interquartile range
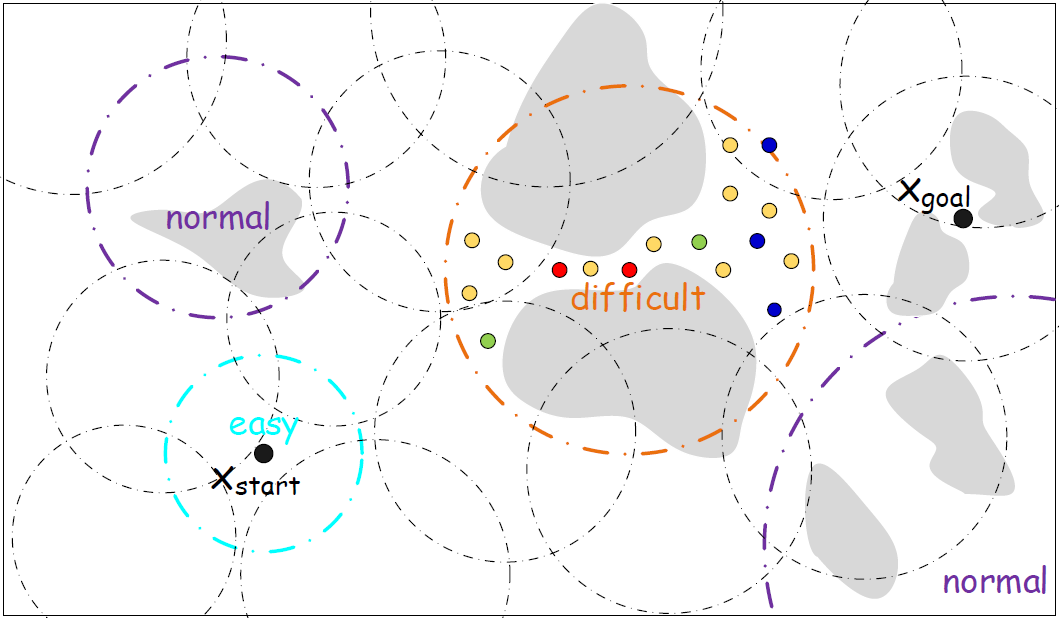
Region classification and boosting. Uniform, Gaussian and bridge samples are coloured blue, green and red, respectively. Boosted samples are coloured yellow. Obstacles are coloured grey.
Region Classification


In regions that have been classified as difficult, samples need to be increased. As shown in Alg.4, we do not set a fixed threshold for the number of increased samples. Instead, the difficult region is boosted by adding samples until the average radius of
When region boosting is finished, the sample set V is sent to FMT* to find an initial feasible path. If FMT* cannot find a feasible solution for the sample set V and extra time is available, more useful samples can be included in the sample set V. This will be presented in the following subsection.
3.4. Guided Hybrid Sampling
Like aFMT*, if FMT* cannot find a feasible path on the sample set V and time permits, our method doubles the number of samples. Compared to aFMT*, the novelty of our method lies in the use of guided hybrid sampling, rather than a uniform sampling strategy. The guided hybrid sampling makes good use of global scenario information and local region information in order to add more useful samples. The algorithm of our method is detailed in Alg.5. First, if the scenario contains large open areas, which is determined by the
Double the number of samples using the guided hybrid sampling method and apply FMT* until an initial feasible solution is found or time runs out.
4. Experiments and Discussions
The proposed method is evaluated using six scenarios: 2D bugtrap-hardest, 3D apartment, 3D abstract, 3D twistycool, 2D maze and 2D barriers, which are shown in Fig.11, respectively. The first scenario is an extension of the bugtrap in Open Motion Planning Library (OMPL 1.0.0) [34], where the area for sampling is enlarged. The final five scenarios are provided by OMPL. To investigate the advantages of our method, the first four challenging scenarios are adopted. In these scenarios, to arrive at the goal position, the robot has to pass a narrow passage, which presents a significant challenge for FMT* and extended methods. To investigate the performance of our method under the scenarios without narrow passages, the final two prototypical scenarios are also employed.

We compared our method against aFMT* and RRT*, as these two methods are state-of-the-art asymptotically optimal planners. In addition, to test our modified locally optimal one-step connection strategy of FMT* and compare with other non-uniform sampling strategies, our method was also compared with aFMT* with the modified locally optimal one-step connection strategy (aFMT*+ymin), aFMT* with a bridge test sampler (aFMT*+bridge test), as well as with a combination of the two (aFMT*+bridge test+ymin).
4.1. Experiment Settings
Simulations were run on a Linux operating system (Ubuntu 12.04) on a 3.1GHz Core i5 processor with 4GB of memory. Our methods were implemented in OMPL and the implementations of RRT*, FMT*, the uniform sampler and the Gaussian sampler were taken from OMPL. The implementation of RRT* was a k-nearest version, including delaying collision checks, as well as pruning via branch and bound and node rejection. We took the default values of RRT* parameters from OMPL, a steering parameter of 3.5% of the maximum extent of the C-space and a goal-bias probability of 5%. The implementation of FMT* was a k-nearest version and the tree was expanded in a cost-to-come+cost-to-go space. We also took the default values of FMT* parameters from OMPL and a radius multiplier of 1.1. The implementation of aFMT* was based on FMT* and we sped up this method by reusing both existing samples and connections from previous iterations. The initial number of samples n0 in aFMT* was set to 500 and other parameters were identical to FMT*. In our method, the initial number of samples n0 was also set to 500 and the
We tested the

Benchmark scenarios. In (a) (b) (c) and (d), to arrive at the goal position, the robot has to pass a narrow passage.

The freeRatio and the buRatio of different scenarios in OMPL
4.2. Self Comparisons
We tested the parameters of our method in Fig.11 and show that our method is not sensitive to parameters. Parameters were tested in the apartment scenario with 16 settings for two parameters, as well as other parameters in default values. Two parameters are shown:

The success rate of our method with different parameter settings in the apartment scenario
4.3. Comparing with State-of-the-art Asymptotically Optimal Planners
For each scenario, we show three graphs. The first shows the success rate of finding an initial feasible solution as a function of time. The second shows the mean cost of successful attempts as a function of time. The third shows the harmonic mean cost as a function of time.
It should be noted that the mean cost of successful attempts may not be able to describe the real performance of asymptotically optimal planners when the success rate is relatively low. As shown in Fig.12(b), the mean cost function is not monotonic, since it only calculates the cost of successful attempts. For example, the mean cost of RRT* increases from 9 to 12 seconds. It can be estimated that the success rate of RRT* increases during this period of time, while the cost of new solutions achieved by RRT* is larger than before. Therefore, the harmonic mean cost, namely the harmonic mean of cost, is also adopted to describe the performance of asymptotically optimal planners. This has two advantages over mean cost. First, since the harmonic mean cost can deal with the infinite cost, it considers all attempts rather than successful attempts only, which delivers a closer indication of real performance. Second, to some extent, the harmonic mean cost can reflect the success rate of algorithms. In other words, it combines two main measures of asymptotically optimal planners. If two methods have the same success rate, the harmonic mean cost only reflects the difference in terms of real cost.

Simulation results for bugtrap-hardest in 2D space
4.3.1. Numerical Experiments under Challenging Scenarios with Narrow Passages
Simulation Results


Simulation results for apartment in 3D space

Simulation results for abstract in 3D space

Simulation results for twistycool in 3D space
Some methods can achieve a higher success rate over a shorter period of time in these challenging scenarios, e.g., kinodynamic motion planning by interior-exterior cell exploration (KPIECE) [37] in the abstract scenario and RRT-connect [38] in the apartment scenario. However, since path quality is not considered by these methods, comparisons were not made to them.
4.3.2. Numerical Experiments under Scenarios without Narrow Passages

Simulation results for Maze in 2D space

Simulation results for Barriers in 2D space
The maximum, minimum and average number of states, iterations, collision checks, as well as the time utilized by each method to find an initial feasible solution in a given time (20s in the first four scenarios, 5s in the final two scenarios), are presented in Tab.3. The results show that our method performed well in all six scenarios, particularly in the challenging scenarios with narrow passages. First, the superiority of our method is revealed both in its higher success rate and lower harmonic mean cost. Second, compared to other non-uniform sampling strategies and region-based methods, our method allows for the automatic tuning of parameters and is scenario-independent.
5. Conclusions and Future Work
In this paper, a region-specific hybrid sampling method is presented, which significantly enhances the performance of FMT* in the scenarios containing narrow passages. Unlike related region-based sampling methods, the configuration space is globally characterized by the proportion of uniform, Gaussian and bridge samples, and then locally captured by regions with a different radius. Our method attempts to classify regions by integrating global scenario information and local region information, and increase the number of samples in difficult regions. Where our method is unable to find a solution for the initial sample set, more samples – which are biased to difficult regions – will be added to the previous sample set. Our method outperformed other methods, since it captures rich global scenario and local region information in a statistical manner and adjusts parameters automatically according to this information. Experimental results pertaining to six scenarios validated the efficiency of our method.
Despite our method working well in simulations, there remain approaches for enhancing it further. For example, information achieved from FMT* is not employed in our method. It may be possible to use more information for updating regions into having a new status, thus increasing the efficiency of our method.
Footnotes
6. Acknowledgements
This work is supported by the National Natural Science Foundation of China (NSFC, No.61340046, 60875050, 60675025), National High Technology Research and Development Program of China (863 Program, No.2006AA04Z247), Specialized Research Fund for the Doctoral Program of Higher Education (No. 20130001110011), Natural Science Foundation of Guangdong Province(No. 2015A030311034), Science and Technology Innovation Commission of Shenzhen Municipality (No.JCYJ20130331144631730, No.JCYJ20130331144716089).