
Abstract
In this paper we combine several image processing techniques with the depth images captured by a Kinect sensor to successfully recognize the five distinct human postures of sitting, standing, stooping, kneeling, and lying.
The proposed recognition procedure first uses background subtraction on the depth image to extract a silhouette contour of a human. Then, a horizontal projection of the silhouette contour is employed to ascertain whether or not the human is kneeling. If the figure is not kneeling, the star skeleton technique is applied to the silhouette contour to obtain its feature points. We can then use the feature points together with the centre of gravity to calculate the feature vectors and depth values of the body. Next, we input the feature vectors and the depth values into a pre-trained LVQ (learning vector quantization) neural network; the outputs of this will determine the postures of sitting (or standing), stooping, and lying. Lastly, if an output indicates sitting or standing, one further, similar feature identification technique is needed to confirm this output. Based on the results of many experiments, using the proposed method, the rate of successful recognition is higher than 97% in the test data, even though the subjects of the experiments may not have been facing the Kinect sensor and may have had different statures. The proposed method can be called a “hybrid recognition method”, as many techniques are combined in order to achieve a very high recognition rate paired with a very short processing time.
1. Introduction
In recent years, methods of human posture recognition have been studied in a range of different papers. In general, these methods can be divided into two types. The first type involves wearable sensors, which are put on the body or clothes of a human to measure certain values, such as the positions of limbs and the slope degree of the body. For instance, one study asked a participant to wear a garment with strain sensors to recognize 27 upper body postures [1]. In [2] and [3], the authors proposed a smart shirt system (SMASH) with acceleration sensors to recognize 21 human exercise postures. A waist-mounted triaxial accelerometer system was developed in [4] to classify human movement status. A wireless acceleration measuring system to monitor a human's activity volume and recognize emergent situations was built in [5]. However, a disadvantage of all five of these studies was that the wearable sensors and the accompanying batteries that the participants were required to wear can be a source of discomfort or inconvenience for them.
The other type of method used to recognize posture information is based on captured images of a human body. Some posture features can be represented by specifically coloured markers on the human torso and limbs. By recognizing the relative positions of the coloured markers, human postures can be recognized using the methods presented in [6, 7] and [8]. However, wearing coloured markers can be just as uncomfortable as wearing sensor devices.
Many studies have used image processing techniques to extract features from images of a human, using those features to identify the posture. More than 10 parameters (lengths and the largest widths of the upper and lower body, etc.) were used in [9] to recognize human postures including standing, sitting, kneeling and stooping. A 3D human-body-posture recognition method was proposed in [10] and [11] in which horizontal and vertical projections of a human body were extracted and compared to the corresponding projections of predefined 3D human posture models; this enabled the postures of standing, sitting, lying and stooping to be recognized. The human skeleton was analysed geometrically to produce posture classification results in [12, 13] and [14]. A segmentation algorithm using deformable triangulation or a set of Gaussian mixture models was proposed in [15–18] to divide the posture into different body parts. Moreover, in [19] a number of heuristic rules based on body-shape characteristics and skin-colour features were used to estimate five significant points, namely the tips of both hands, both feet, and the head of a human silhouette contour. The authors of [20] used entropy measurement as an underlying feature and a modified Hausdorff distance to evaluate the similarities between the posture which was being recognized and the posture template database. A temporal difference image sensor was used in [21] to extract the size and position of invariant line features, and then a Hausdorff distance classifier was employed to measure the similarities of those features against a library of objects. In [22], the authors extracted features using a discrete Fourier transform and then used a neural fuzzy network to classify the human body postures. In [23], the authors used a Support Vector Machine (SVM) to classify human postures from images captured by a time-of-flight sensor. The study presented in [24] applied height and width ratios and horizontal and vertical projections as fuzzy logic inputs for posture recognition. Some studies have used a Kinect sensor to recognize human postures; for instance, the authors of [25] presented a method which uses histograms of 3D joint locations from Kinect depth maps and discrete HMM (hidden Markov model) to achieve human posture recognition. To recognize the four human postures standing, sitting, lying and bending, a method was proposed in [26] based on the human skeleton captured by a Kinect sensor. The authors of [27] recognized three human gestures from the vectors of 20 body-joint positions captured by a Kinect sensor. A method was developed in [28] that was based on colour and depth information gathered from similar sensor. Implementing a multilayer framework to understand human activity, in [29] a Kinect sensor was used to acquire a D-RGB-based skeleton tracking output for human activity recognition. In [30], SVM was applied to classify different postures by nine features, including forearm and thigh, as captured by a Kinect sensor. All of the above studies extracted features from images and used various classifiers to identify the different postures. Recognition rate, number of postures successfully recognized, computation time, and cost of the devices should be of concern for all proposed recognition methods.
In this paper, a new posture recognition method is proposed. The method uses only two devices to achieve its function: a laptop computer and a Kinect sensor. The Kinect sensor consists of a depth sensor, an RGB camera, a multi-array microphone and a motorized tilt [31]. The depth sensor is composed of an infrared ray emitter and a monochrome CMOS sensor to capture depth images with a resolution of 320×240 pixels; the RGB camera is used to capture colour images with a resolution of 640×480 pixels. The multi-array microphone can be used to receive the sound signal, but it will not be used in this study. The motorized tilt can adjust the Kinect sensor's elevation angle. The USB port is used for communication between the laptop computer and the Kinect sensor. The laptop computer is an Intel i5-520 running at 2.4GHz with 4G bytes DRAM. The image processing techniques used encompass the horizontal and vertical projection, star skeleton, LVQ neural network and image processing techniques. Five human postures, standing, sitting, stooping, kneeling, and lying, will be recognized. The reason for selecting these five postures is that they are the general and basic postures of the human form. Conclusions about other postures not mentioned here may be extrapolated from the gained results.
This study contributes to research about automatic home care systems. Elderly people who live alone can often benefit from a robot to provide home care services. These robots must have an ability to recognize the person's postures in normal and dangerous situations, in order to send accurate reports to the care centre.
The main contributions of this paper are as follows. Only one Kinect sensor is used, so the participant does not need to wear any sensors on their body. Because we are using the Kinect depth sensor, the captured image is unaffected by illumination of the environment, shadows, or similarities in the colour of the participant's clothing and that of the background. Three posture recognition methods involving body width and height ratio, neural network and length ratio are combined to recognize total five postures even when the subjects are facing in different directions. Since it is the fusion of many techniques that helps the method achieve a very high recognition rate in a very short processing time, the proposed method can be called a “hybrid recognition method”. Note that this paper does not use Kinect SDK software in the recognition process; this is in contrast to the studies presented in [25–27], which all used the SDK skeleton to recognize postures. Comparisons between the results of the proposed method and those in [25–27] will be discussed in Section 4.
This paper is organized as follows. Section 2 introduces the techniques used for extracting the body posture features. Section 3 describes the training of the LVQ neural network and a final identification method for human-body-posture recognition. Then, the experimental results are shown and a discussion provided in section 4. The final section presents a conclusion.
2. Depth Image Processing
In this study, five human postures, standing, sitting, stooping, kneeling, and lying, will be recognized. Several image processing techniques will be introduced and implemented.
2.1. Human Silhouette Segmentation
First, the Kinect sensor captures a background depth image without any humans. Next, it captures one more image with a human and subtracts the current depth image from the background depth image to get the subtractive image. The subtraction result is then binarized to create a binary image in which black pixels denote background and white pixels are foreground. Then, erosion and dilation are applied several times to repair the imperfections of the human silhouette and to remove noise. The above process is demonstrated in Figures 1(a), (b) and (c). If the noise is not cleaned completely, the connected components method is applied to extract the largest region of white pixels, which is regarded as the human silhouette in the binary image as shown in Figure 1(c). The whole process of human silhouette segmentation is shown in Figure 2. Since the effective detection range of the Kinect sensor is between 2 m and 4 m, the human subject should stand inside this range. The size of the segmented human silhouette is at least 3000 pixels in our experiments, so 3000 is set as a threshold to judge whether the human subject is in the detection range or not. If the size of the segmented human silhouette is not larger than 3000 pixels, the following processes will not start.

(a) The background depth image. (b) The depth image with a human. (c) The human silhouette.
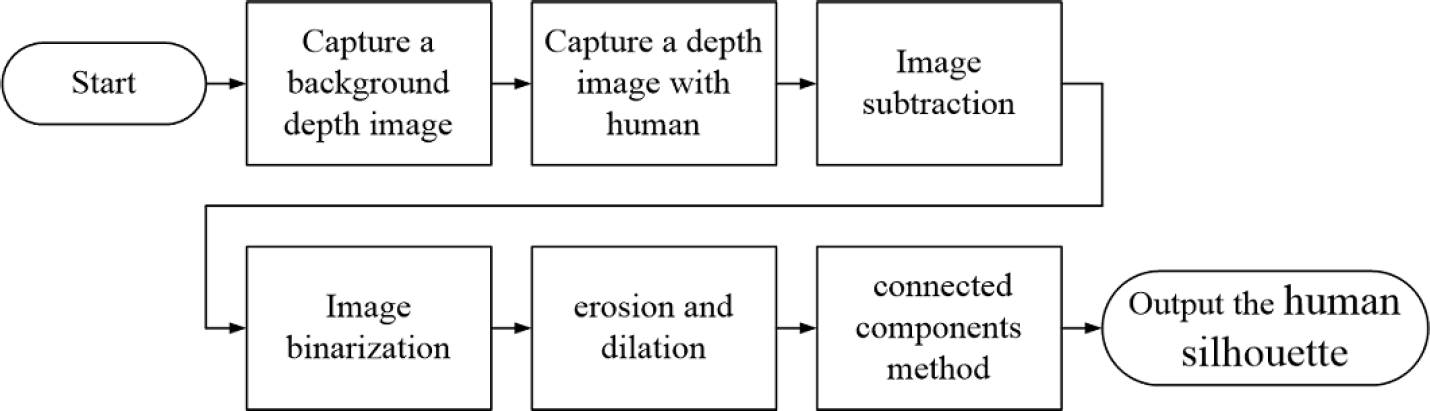
The flow chart of the human silhouette segmentation
There are two advantages to capturing the human image using the Kinect sensor. One is related to the influences of illumination. The shadow effects of the subject can be eliminated, since the Kinect sensor can be considered a distance measurement sensor. The captured depth image consists of only a set of distance values between the sensor and the measured objects in the sensing range. There is no illumination information in the depth image. The other advantage is that there is no colour information in the depth image. If there is a white object in the background, and the human wears white clothes in the image captured by a regular camera, then background subtraction will result in an incomplete silhouette contour of the human's body which cannot be used to recognize the human's postures. In order to obtain a clear and complete human silhouette, the Kinect sensor can therefore be a highly useful tool.
2.2. Feature Extraction
Since the extracted features form the entirety of the data from which the postures will be recognized, they are of great importance in this process. An overview of some of these features follows.
2.2.1. The ratio of the upper and lower human body
First, the silhouette's centre of gravity must be calculated. The silhouette is divided into the upper and lower body based on the centre of gravity, so that the upper body is the part of the silhouette above the centre of gravity and the lower body is the part below the centre of gravity. The centre of gravity can be calculated by (1).

where

The centre of gravity of a clean human silhouette
Then, the body width can be obtained by computing the horizontal projection histogram for each row of pixels inside the silhouette from top to the bottom. According to the position of the centre of gravity, the maximum values of the projection histogram on the upper and lower body can be found respectively, as shown in Figure 4. The ratio between the maximum value of the projection histogram on the upper body and that on the lower body is calculated from equation (2).
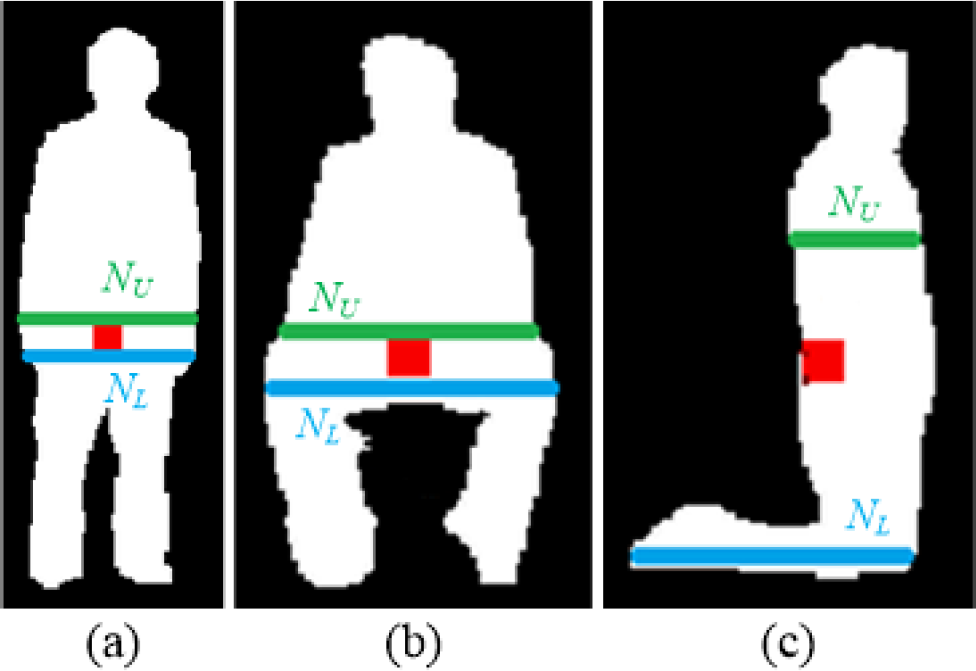
The maximum widths of upper body and lower body for different postures. (a) Standing, (b) sitting, and (c) kneeling.
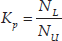
where NU is the maximum upper-body width value and NL is the maximum lower-body width value; Kp is the ratio, which can be a feature value of human posture. It should be noted that the lateral kneeling posture is very different from other postures in terms of the ratio of upper and lower body, as it is much larger. Therefore, the ratio is especially useful when recognizing the kneeling posture. Based on the experiments, it is found that when the human is kneeling, his feature value Kp is the largest among all of the postures, as shown in Figure 5. To distinguish the kneeling posture, a threshold value is given; when

The horizontal projection histogram of the lateral kneeling posture
2.2.2. The establishment of the feature vectors
Since the centre of gravity of the human silhouette is known, the distance between the centre of gravity and the edge contour of the human silhouette can be calculated by equation (3).

where di denotes the distance values between

The calculation sequence of the distance values di

The sequence curve of the distance values di
Let the curve in Figure 7 be filtered through a low-pass filter to remove the noise, thus obtaining the smoother curve denoted by
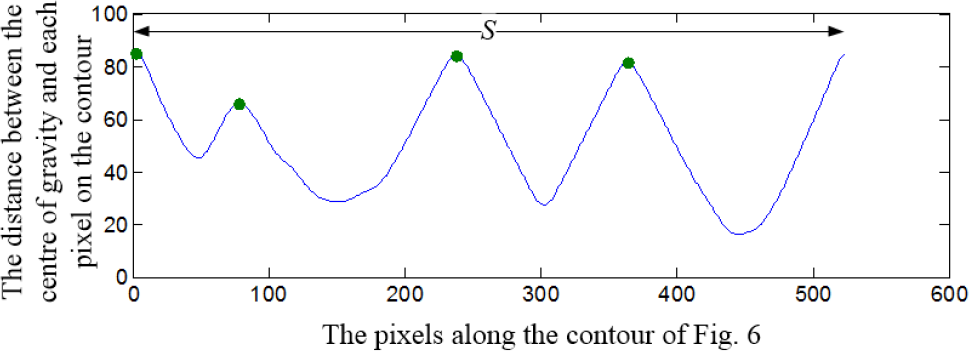
The peak points on the distance value curve
After obtaining the feature points, the next task is to acquire the feature vectors. First we let
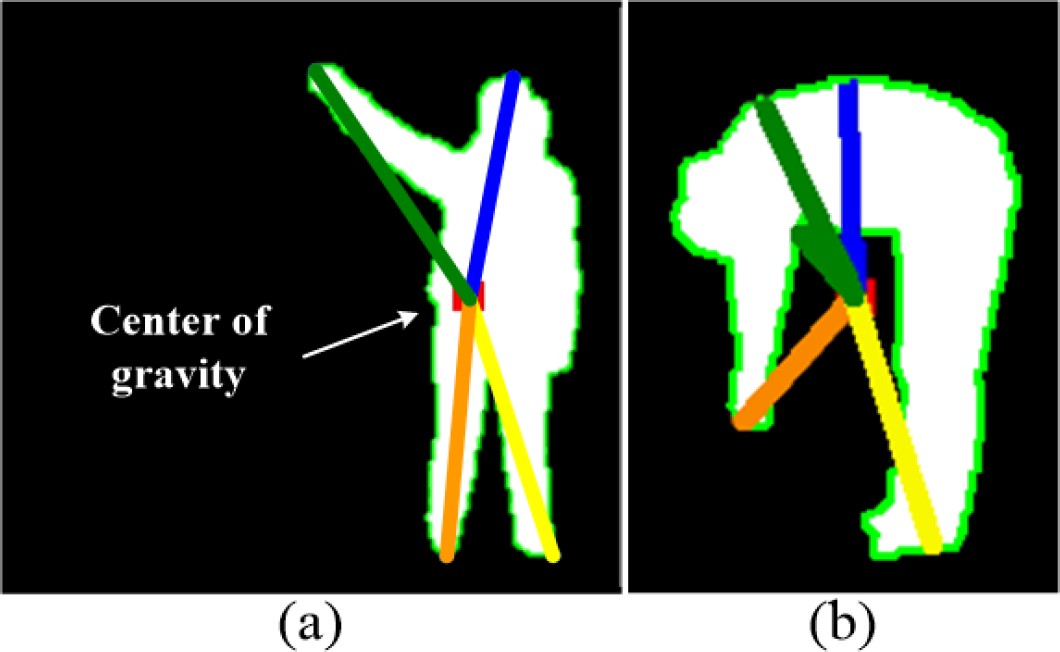
Feature skeleton when the centres of gravity are (a) inside the human silhouette and (b) outside the human silhouette

New centre of gravity on (a) a sitting posture with raised arms and (b) a stooping posture
Let each branch of the feature skeleton shown in Figure 9 be one of the human feature vectors

Then, the Cartesian coordinate

where i=1, 2,…, m, and m is the total number of branches of the feature skeleton. In general the maximum number of branches is five. The transformation is illustrated in Figure 11.

Feature vectors with (a) Cartesian coordinate and (b) polar coordinate
3. LVQ neural network and a final identification
After feature extraction, the LVQ neural network is applied to classify the postures using the extracted feature vectors. The LVQ shown in Figure 12 is a supervised neural network which is often used for pattern classification (see [32–34]). In this study, we decided to use an LVQ as the classifier of human posture recognition because of its simple structure, fast operation, and strong fault tolerance [34]. However, two things should be noted regarding the training of the LVQ neural network. First, the input arrangement of the LVQ neural network should be ordered; second, the feature vectors Vi should be normalized as

The structure of the LVQ neural network
3.1. Inputs arrangement in LVQ neural network
Let the LVQ neural network have 12 inputs which contain 10 feature vectors and the two depth values D1 and D2 (D1 and D2 will be defined later). According to experimental experience, the order of the feature vectors which are inputted into the network will affect the recognition rate. Therefore, two order arrangements of feature vectors are proposed, as shown in Table 1, in which Ui is the i-th input neuron of the LVQ neural network, and ϒj is the length and
The Order Arrangement for Input Neurons

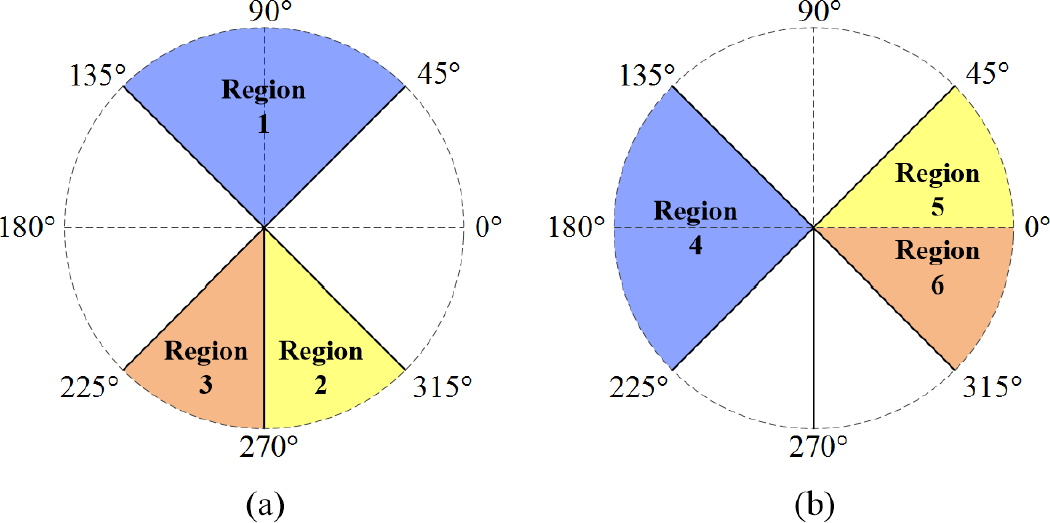
In order to arrange the inputs of the LVQ neural network, let two disks be divided into six regions with different degree ranges as shown in Figure 13. If any one feature vector is located in Region 1, which is the sector between
The region division for the inputs of the LVQ neural network. (a) Order arrangement I. (b) Order arrangement II.
(I) Order arrangement I (used if any one feature vector is located in Region 1, which is a sector between
Stage 1. There is a feature vector in Region 1 whose angle is much closer to
Stage 2. If there exist feature vectors in Region 2, the vector angle which is closest to, but does not exceed,
Stage 3. If there is a feature vector in Region 3 whose angle is much closer to
Stage 4. If there is a feature vector which does not satisfy the above three conditions, but whose angle is the closest to, and anticlockwise of,
Stage 5. If one final vector feature remains, it will be called V5. Then,
Stage 6. The remaining inputs are D1 and D2, where
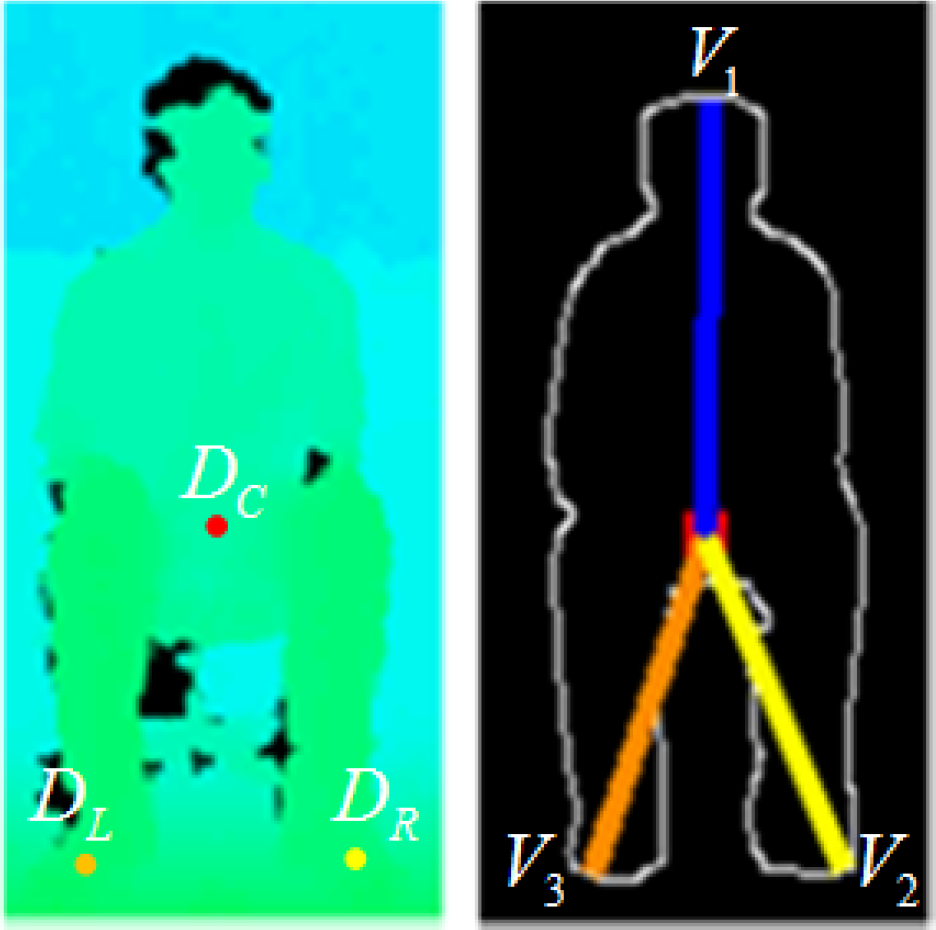
The depth values
Figure 15 shows the order of the feature vectors when using order arrangement I for the standing and lateral sitting postures. It is seen that there must be at least one feature vector in Region 1 when the order arrangement I is used; in other words, the position of the human's head is in Region 1. Therefore, by using order arrangement I for the inputs of the LVQ network, the standing and sitting postures can be recognized. Furthermore, D1 and D2 are used to establish recognition of the forward-facing sitting posture in which the centre of gravity,

The feature vector arrangement according to order arrangement I. (a) Standing. (b) Sitting.
(II) Order arrangement II (used if there is no feature vector located in Region 1).
Stage 1. If there is a feature vector in Region 4 whose angle is much closer to
Stage 2. If there exist feature vectors in Region 5, the vector angle closest to
Stage 3. If there exists a feature vector in Region 6 whose angle is closer to
Stage 4. If there is a feature vector which does not satisfy the above three conditions, but whose angle is the closest to, and anticlockwise of
Stage 5. If there is a last remaining vector feature called V5, then
Stage 6. Lastly, the remaining inputs
Figure 16 shows the lying and stooping postures with their feature vectors arranged according to order arrangement II. The order arrangement II is used for recognizing those postures in which there must be feature vectors in Region 4, Region 5, or Region 6; in other words, the human's head is considered to be in Region 4, Region 5, or Region 6. Therefore, using order arrangement II for the inputs of the LVQ neural network, the lying and stooping postures can be recognized. Furthermore, D1 and D2 are not used in order arrangement II.

The feature vector arrangement according to order arrangement II. (a) Lying. (b) Stooping.
3.2. Feature vectors normalization
Having assigned the order of the inputs of the LVQ neural network, it should be noted that if the human is far away from (or near to) the Kinect sensor, then the perceived size of the human will be smaller (or larger). This may affect the accuracy of the recognition; therefore, the values in Table 1 should be normalized in advance. Let
The Normalized Order Arrangement for Input Neurons

3.3. The operation of the LVQ network
The previous section has shown how the lateral kneeling posture is recognized by the upper and lower body ratio of a human. However, there are still many different postures to be recognized. Using an LVQ neural network is the next recognition process presented here. The used LVQ has 12 input neurons, 600 hidden neurons and four output neurons. The 12 input neurons contain five lengths and five angles of feature vectors and two depth values. There are 1105 sets of training data with which to train the LVQ neural network. Since the hidden layer needs enough hidden neurons to memorize the training data, the number of hidden neurons is 600. The four output neurons represent the four classes of posture, sitting or standing, stooping, and lying, respectively. It is noted that one of those outputs may denote non-forward sitting or standing; therefore, an extra check is needed to determine whether the posture is sitting or standing.
The training data contain 292 standing postures, 320 sitting postures, 240 stooping postures and 253 lying postures. All training data contain those postures shown in Figure 17. Figure 17(a) shows five standing postures with five orientations, respectively. Figures 17(b), (c), and (d) show the different postures with the different respective orientations. After training, the weights between the inputs and the hidden neurons will be obtained.

The postures of the training data. (a) Standing. (b) Sitting. (c) Stooping. (d) Lying.
The output weights W are set as equation (6).

where W is a 4×600 matrix. For instance, the element at position (1, 150) in W is 1 at (6), which means the weight at the link between hidden neuron X150 and output Y1 is equal to 1.
The training of the LVQ neural network is stopped when the input weight variation is less than 0.05, as shown in Figure 18. The training terminates at the 38th cycle.
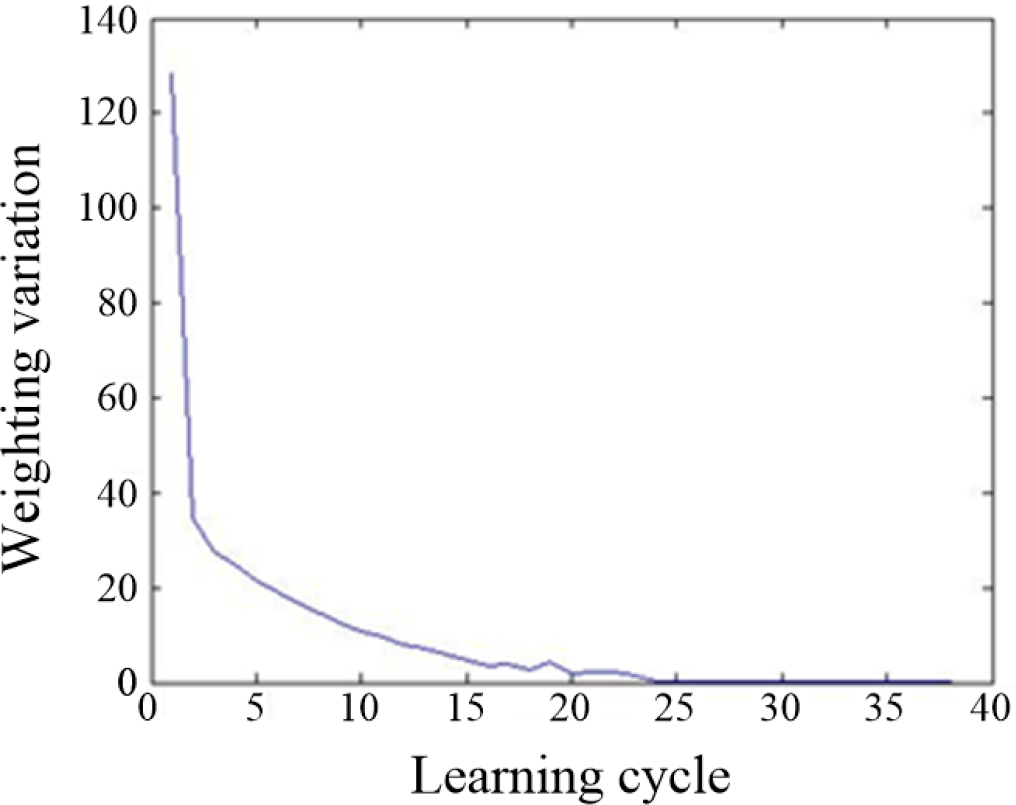
The training curve with input weight variation and training cycle
Since the LVQ is a supervised neural network, training and testing should follow order arrangement I or II when setting the inputs. The reason for using two order arrangements is that, based on the results of many experiments, a much higher recognition rate is achieved when using two different arrangements for two different cases than when only using one arrangement.
3.4. One more check
After obtaining the outputs of LVQ, one more step is necessary for posture recognition. It can be seen that the feature vector structure in Figure 19(a) is similar to that in Figure 19(b), and the vector structure in Figure 19(c) is similar to that in Figure 19(d), respectively. This causes confusion of posture recognition in the LVQ neural network. Therefore, an extra step is needed to determine the posture when the subject is standing or sitting but not facing the sensor. The two ratios are defined as follows. One is

Human feature vectors of the non-forward-facing sitting and the standing postures

Ratio of the width and height of the human silhouette contour

The hands at different positions
Here, the horizontal and vertical projection histograms are considered to obtain the height and width of the human silhouette. The human's standing posture is shown on the left side of Figure 22, and the horizontal projection histogram of this posture is shown on the right side of Figure 22. In order to exclude the possible noise above the head and below the sole of the foot, a row on the horizontal projection histogram is selected in which the number of accumulated pixels is greater than five; then, the number of all such rows will be considered to correspond to the height of the person. In other words, rows with fewer than five accumulated pixels are ignored. In Figure 22, the length of the interval

Horizontal projection of the standing posture

Vertical projection of the standing posture

when
There are two threshold values in this paper. In order to find suitable threshold values for Kp in (2) and R in (7), a lot of measurements are needed. In this study, more than 10 people were each measured more than 10 times with different distances. We then selected the threshold values for Kp and R from the average of those measurements.
All techniques for posture recognition have now been presented. Now let us summarize the above recognition techniques in the following procedure. A flow chart is also shown in Figure 24.

Flow chart of the posture recognition process
3.5. Procedure of the recognition process
4. Experiment results and discussion
In all the experiments performed for this study, the Kinect and the PC are on the same table at a height of 70 cm, and the human subject is in front of the table at a distance of 2.5 to 4.5 m. By using a Kinect sensor, the proposed method is implemented to recognize five human postures: kneeling, standing, sitting, stooping and lying. In the experiments, each posture can be oriented in five different directions:

The recognized postures with different orientations. (a) Standing. (b) Sitting. (c) Stooping. (d) Kneeling. (e) Lying.
The Posture Recognition Rates

Although the proposed posture recognition process contains several steps, in the experiments it takes less than three milliseconds to recognize a posture. Figure 26 shows all of the human postures that were successfully recognized in different environments and with different distances between the Kinect sensor and the subject, as shown in the first column of the figure. The fourth indoor environment is with low luminance. In each case the worst recognition rate is still over 97%. Figure 27 shows a breakdown of the computation time required to recognize each of the 10 postures, in which TL indicates the total computation time for recognizing a certain posture. The remaining notations T i , i=1, 2,…, 6, indicate the computation time used by each step of the posture recognition process and are defined as follows: T1 is the image processing to remove noise; T2 is the silhouette contour segmentation from the captured images; T3 is the horizontal projection and keeling posture judgment; T4 is the extraction of feature vectors; T5 is the LVQ neural network recognition of the forward-facing sitting, stooping and lying postures; and T6 is the identification of the standing or non-forward-facing sitting postures. If T i =0, then the i-process is not needed. For instance, the processes T4, T5 and T6 are not necessary to recognize posture (iii) in Figure 26. It is seen that T2 is larger than all the other values of T i, i=1, 3, 4, 5, 6, for recognition of all postures, since the segmentation process includes connected component implementation, which takes more time due to the large subject silhouettes. It is seen all the 10 postures were successfully recognized in less than three milliseconds. It can therefore be concluded that the algorithm can be applied to a real-time posture recognition application.

Illustration of the different environments and tested postures

Breakdown of the total posture recognition computation time
We compare the performance of the proposed method to that of three alternative methods proposed in [25, 26] and [27], respectively. In [25] there are 10 postures to be recognized: walking, standing up, sitting, picking up, carrying, throwing, pushing, pulling, waving hands and clapping hands. Of these 10 postures, three, standing up, sitting, and picking up, showed performance similar to that shown for the postures of standing, sitting and stooping, respectively, in our paper. Table 4 shows that our recognition rate for these three postures is much higher. The study presented in [26] used four feature extraction methods to recognize the four postures of standing, sitting, lying, and bending. We choose those two of the four methods that have the best recognition accuracy in order to make a comparison with ours. The chosen two methods used seven joint-angles with scaling and nine joint-angles with scaling to extract features, respectively. The comparison is included in Table 4. It is seen that when the test subjects are not facing the Kinect sensor, the recognition rates of some postures are very low (see Table 3 in [26]). The study presented in [27] used four classifiers – back-propagation neural network, support vector machine, decision tree and naïve Bayes – to recognize human postures, respectively. The back-propagation neural network had the highest success rates. However, the authors only recognized three postures and did not provide the recognition results of test subjects facing in different directions. The proposed method not only recognizes five postures (including the three postures recognized in [27]), it also deals with test subjects facing in different directions.
A Comparison of the Average Success Rates of Posture Recognition

Note that the recognition methods in [25–27] were based on skeletal joint positions of the subject drawn from the Kinect software development kit (SDK). If the subject's head is not at the top of the silhouette, for example in the postures of stooping or lying (see Figure 28), these methods may therefore give incorrect recognition. Even so, we find that the average recognition time for each image when using the proposed method is less than three milliseconds; in other words, the lowest recognition frame rate is 333.33 frames/per second (see Figure 27). It is clear that the proposed method achieves recognition very fast and with very high efficiency.

Skeletal maps as created by the Kinect sensor for Windows SDK 1.8 software [35]
The proposed method does, however, have limitations. For instance, when the subject is kneeling and facing the Kinect sensor, the lower legs are hidden, as shown in Figure 29(a), which may cause the recognition process to fail. In this situation, the horizontal projection cannot display the features of the kneeling posture clearly where the maximum upper-body width value NU is 67 and the maximum lower-body width value NL is 67, as shown in Figure 29(b). Then, the feature value Kp is 1<1.4. According to our experiments, the recognition of the postures of kneeling, stooping and lying may fail if the subject's orientation is not restricted the [-90°, −45°] or [45°, 90°] ranges.
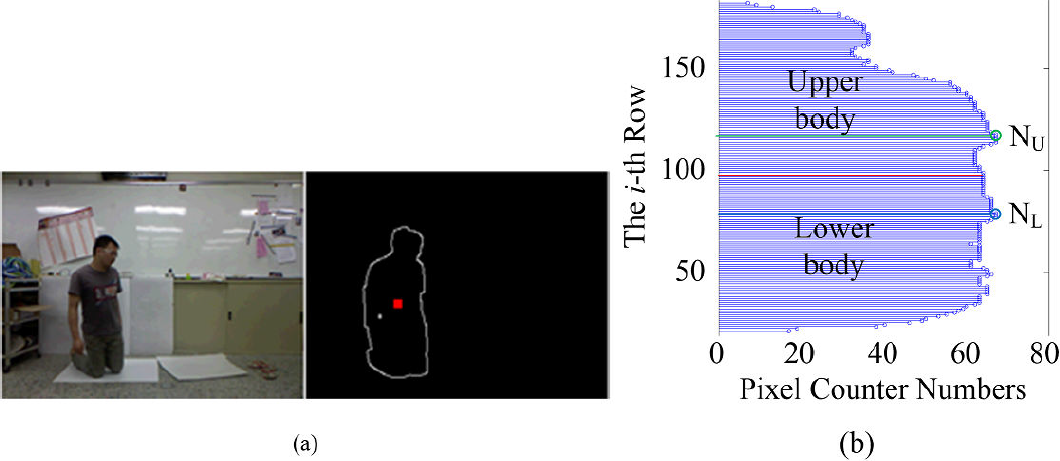
(a) Legs hidden in the kneeling posture. (b) horizontal projection of the posture in Figure 29(a).
5. Conclusion
This paper has proposed an effective procedure to recognize the five human postures of standing, sitting, stooping, kneeling and lying, even when the human subjects have different statures or orientations. In the experiments, it is found that the average success rate of the proposed posture recognition method is higher than 99%. The Kinect sensor which provides the depth information can avoid the influence of illumination and shadow in image processing. By extracting many features and using the LVQ neural network, an efficient posture recognition procedure is produced. The proposed posture recognition method has three advantages: firstly, it has a very high recognition rate; secondly, it requires fewer training data sets; and finally, it uses a more economical sensor compared to other methods. However, it must be admitted that, where part of the subject's body is hidden, some further study is required, as such situations may cause a recognition failure due to incorrect feature extraction. This issue can be considered as a subject for future studies.
It is believed that a more reliable method of posture recognition could recognize more complex postures. In our future research, we hope to develop a more reliable posture recognition technique that could prove extremely useful as part of a homecare system for monitoring elderly people who live alone. The system will be able to detect abnormal postures produced by a fall or a medical emergency, and then immediately alert the emergency services.
Footnotes
6. Acknowledgements
The authors would like to thank the Ministry of Science and Technology of Taiwan for its support under Contracts NSC102-2221-E-008-085-MY3.