
Abstract
The introduction of computationally efficient binary feature descriptors has raised new opportunities for real-world robot vision applications. However, brute force feature matching of binary descriptors is only practical for smaller datasets. In the literature, there has therefore been an increasing interest in representing and matching binary descriptors more efficiently. In this article, we follow this trend and present a method for efficiently and dynamically quantizing binary descriptors through a summarized frequency count into compact representations (called fsum) for improved feature matching of binary point-features. With the motivation that real-world robot applications must adapt to a changing environment, we further present an overview of the field of algorithms, which concerns the efficient matching of binary descriptors and which are able to incorporate changes over time, such as clustered search trees and bag-of-features improved by vocabulary adaptation. The focus for this article is on evaluation, particularly large scale evaluation, compared to alternatives that exist within the field. Throughout this evaluation it is shown that the fsum approach is both efficient in terms of computational cost and memory requirements, while retaining adequate retrieval accuracy. It is further shown that the presented algorithm is equally suited to binary descriptors of arbitrary type and that the algorithm is therefore a valid option for several types of vision applications.
1. Introduction
An important issue in computer vision is the use of compact and computationally efficient binary-valued visual feature descriptors. This is especially true for large-scale robotic vision applications, for several reasons. First, a compact representation can enable efficient real-time matching of a large variety of objects and scenes found in real-world environments. Second, an efficient representation can relieve internal memory and processor to complete other tasks (particularly useful in robotics). In the literature, there has been an increasing interest in quantizing visual descriptors more efficiently, as well as improving the overall computation of training and the matching of visual descriptors. However, an improvement in computational efficiency is often made at the cost of a reduced retrieval accuracy (and vice versa) and a general trend is therefore to use computationally efficient approximated solutions supported by additional learning (either supervised or unsupervised) via a demanding off-line training phase. Yet while off-line training is acceptable for creating a reference space of objects and scenes for recognition tasks, a real time system such as an operating robot platform must also maintain a dynamic representation of recognized objects and/or scenes [1]. For this purpose, the representation of features must not only be compact but also dynamic, so that the algorithm can adapt and incorporate new features without repeating elaborate off-line training.
The work presented in this paper introduces a summative approach known as
The paper is organized as follows: an overview of the state-of-art in adaptable solutions for training and matching binary descriptors is presented in section 2; our suggested
2. Related Work
Feature matching of vector-based local visual features such as SIFT [2] and SURF [3, 4] have successfully been used for over a decade. However, vector-based visual features are computationally costly and can therefore become a bottleneck when used for vision applications (especially when used for real-time applications and together with larger datasets). As an alternative to vector-based visual features, a number of more computationally efficient binary-valued visual features, such as BRIEF [5], ORB [6], BRISK [7] and FREAK [8], have recently been proposed.
Common for all local visual features (both vector-based and binary) is that feature point descriptors are computed for image patches around distinct image keypoints and feature descriptors are therefore often coupled with a keypoint detector. Calonder et al. suggest the use of the CenSurE [9] or FAST [10] detector for detecting the keypoints over which intensity difference tests over randomly selected pixel pairs are computed in order to represent image patches for the BRIEF descriptor [5]. However, a shortcoming of the BRIEF descriptor is that it is sensitive to in-plane rotations and scaling. As an improvement, Rublee et al. suggest the ORB detector (Oriented FAST and Rotated BRIEF) [6], which extended FAST by intensity centroids [11] for orientation alongside introducing a greedy search algorithm for selecting the most uncorrelated BRIEF binary tests (those of high variance) for improving rotation invariance. Inspired by the AGAST extension to FAST [12], Leutenegger et al. suggest a scale-space detector for identifying keypoints across scale dimensions using a saliency criterion for their binary robust invariant scalable keypoints. (BRISK) [7]. A binary string for each keypoint is calculated over a rotation invariant sample pattern consisting of uniformly appropriately-scaled concentric patches around each keypoint. Similar to BRISK, [8] presented their human retinal inspired fast retina keypoint (FREAK) [8], in which a cascade of binary strings is computed as the intensities over the retinal sampling patterns of a keypoint patch. It is worth noting that, even though feature descriptors re often coupled with suggested keypoint detectors, there is no strict bound between descriptors and detectors.
In reality, feature descriptors and keypoint detectors can be combined arbitrarily, and hence customized for specific applications. Regardless of the combination of keypoint detector and descriptor extractor, the resulting feature descriptor set, c, is a set of individual binary strings of dimensionality l bytes, e.g., 32 or 64 bytes, which have been extracted for n keypoints detected in the same image. Hence and for forthcoming sections, a training dataset of descriptor sets extracted from a collection of m images are denoted by:

The main benefit of binary descriptors (compared to vector-based descriptors) is the support of fast brute-force matching (or linear search) by calculating the Hamming distance between features, which for binary strings is the number of bits set to 1 in the result of XOR between two strings. This can today be computed extremely efficiently with the use of the POPCNT instruction in x86_64 architectures. Here, the Hamming distance between a binary string i of a query descriptor set x and a binary string j of trained descriptor set

However, a brute-force matching is only practical for smaller datasets. In the literature (and specifically in the community of large-scale feature matching), the use of hashing techniques has been considered best practice for improving the matching of binary feature descriptors. Together with the ORB algorithm [6], locality sensitive hashing (LSH) [13] has been suggested as a nearest neighbour search strategy, where features are stored in different buckets over several hash tables. Salakhutdinov & Hinton presented the concept of semantic hashing in [14], where features are mapped to much smaller binary codes. However, semantic hashing is largely practical only for searching for nearest neighbours that differ by only a couple of bits. Another prominent approach in the use of hashing techniques is multi-index hashing, presented in [15] and which showed results on datasets with binary strings of lengths up to 128 bits. In general, however, it is also the length of the binary strings and the amount of memory required to store all the buckets for a hashing approach that often serves as the limitation of a hashing approach. To date, no efficient method for handling binary codes of lengths of 32 or 64 bytes (which are the lengths of the binary strings used in this paper) has been presented. For a complete review of binary hash codes for large-scale image search, see [16].
In summary, there are currently two prominent approaches for efficient matching of visual features that are directly (or with minimal alteration) applicable to binary feature descriptors and hence, comparable to our approach: 1) clustered search trees; 2) bag-of-features, with improvement of vectors of aggregated local descriptors (VLAD) and vocabulary adaptation. The prior is computationally efficient with respect to the training of descriptor sets. The latter approach is a summarized approach and hence, a memory efficient approach. Contrarily, the prior approach is associated with a high cost of memory requirements, while the latter approach requires extensive training in order to reduce memory requirements. The novelty of our
3. A Summative Approach for Fast Training and Matching of Binary Descriptors
The principal idea behind the proposed approach is to maintain a byte frequency count for each byte and for each binary string of a descriptor set. Specifically, the approach transforms a binary descriptor set into a histogram that maintains the byte value distribution of the binary strings, which constitute a descriptor set [17]. The inspiration for this approach stems from two core questions: 1) is it possible to reduce the total search space prior to matching individual descriptor strings?; 2) is it possible to reduce the memory requirements for representing a binary descriptor set?
3.1. Summarize binary descriptors by frequency count
The procedure for creating a
The frequency count is a weighted frequency count depending on the size of n so that the larger the n, the less significance each individual byte has on frequency occurrence. Thus, frequency occurrence is multiplied by
Figure 1 graphically depicts this process of summarizing a binary descriptor set c, firstly, into a two-dimensional array a and subsequently, a one-dimensional array b.

Example of translating a binary descriptor set (c) from a two-dimensional array (a) to a one-dimensional array (b). The left most table is the binary feature set of dimension
3.2. Matching of summarized representations
Matching is done by measuring the similarities between an unknown descriptor set x and each training descriptor set

Subsequently, a new one-dimensional array

The winning matching binary descriptor set c will be the one with the highest similarity r (or lowest L1 distance) for a match against the corresponding arrays a and b. Moreover, the resulting similarity score r is also given for the entire descriptor set c (in opposition to traditional feature matching, where a similarity score is given for a individual descriptor string of descriptor set c).
3.3. Maintaining summarized representations
For a feature matching algorithm to be beneficial for real-world robot vision applications, the algorithm must be dynamic and adapt to changes as new data are collected. Based on the suggested summary of binary descriptor sets (presented in section 3.1), it is obvious that sets of binary descriptors are trained (summarized) independently of one another. The same is true for matching an unknown binary descriptor set, x, against a summarized representation. As a result, adding a binary descriptor set c and extending the total dataset C to
4. Evaluation
The proposed algorithm was implemented on top of the OpenCV library
1
. The oriented FAST keypoint detector [6] was used as a keypoint detector. Since our approach is based on a frequency count, we have further adopted Harris corner measures [18] for ordering the FAST keypoints, as suggested by [6]; the
ORB descriptors (of 32 bytes).
BRISK descriptors (of 64 bytes).
FREAK descriptors (of 64 bytes).
The BRIEF descriptor is also supported in the current version of OpenCV. However, since the ORB (oriented FAST and rotated BRIEF) algorithm is based on the BRIEF algorithm and because BRIEF is known for having a weak rotational invariance, it was not considered in this evaluation.
4.1. Notes on datasets for evaluation
The datasets used in the literature for evaluating algorithms for feature matching are commonly based on images collected from the web, e.g., Flickr, Google search, Bing search, etc. These datasets consist therefore of the top ranked results of searches for famous landmarks or buildings, or normalized representations of groups of objects, e.g., cars, faces, etc. While such datasets are suitable for learning about general representations of concepts for searching k-nearest neighbours for a 1:N result, an algorithm for real-world robot applications is more concerned with searching for the uttermost unambiguous 1:1 matching result, e.g., recognizing one specific object among other objects. Another fundamental difference between images collected from the web and real-world sensory data is that web images have, for the most part, been taken under good conditions and different viewpoints of the same object are available (e.g., of the same landmark), while real-world sensory data is affected by many types of distortions (e.g., motion blur, different light conditions, etc.).
For evaluation of the work presented in this paper, the Oxford Affine Covariant Features dataset was used (for short referred to as oxford throughout the rest of this paper) 2 . This dataset was introduced by [19] for the performance evaluation of local descriptors and has been commonly used for the evaluation of keypoint-based feature matching. This dataset contains eight distinct training samples (named bark1, bikes1, boat1, graf1, leuven1, trees1, ubc1 and wall1) of different real-world scenes. For each training image there exists five corresponding query images that are distorted to some extent. This dataset covers the following types of distortions: zoom and rotation changes (boat and bark); viewpoint changes (graf and wall) various degrees of image blur (bikes and trees); different degree of JPEG compression (ubc); changes in light conditions (leuven). Examples of used training images (left image colum), together with corresponding distorted query images (middle and right image column), are illustrated in Figure 2.

Examples of images used for evaluation of this work. Left image column: training images of different real-world scenes, middle and right column: corresponding distorted query images.
For evaluation at a larger scale, the Oxford Flickr 100k dataset has also been used (in short referred to as flickr100k throughout the rest of this paper) 3 . This dataset has been used together with the Oxford Buildings 5k dataset for large-scale object retrieval, as presented in [20]. This dataset was collected by crawling Flickr's 145 most popular tags and consists of 100,146 high resolution images. For the purpose of large-scale evaluation in the following subsections, this dataset was used so that efficiency and accuracy were evaluated while concurrently introducing a growing set of “distracting” feature descriptors to the prior oxford dataset.
A complete summary of all features available for this evaluation can be seen in Table 1, where all descriptor sets were extracted and stored off-line in advance. Therefore, keypoints in the order of 2,500 were detected and used for feature-point descriptor extraction, and each of the extracted descriptor sets were subsequently down-sampled to a desired maximum of
Summary of features used for evaluation. For each type of feature descriptor, both the total number of extracted binary strings and the average number of binary strings for each descriptor set is listed.

4.2. Efficiency and accuracy compared to the state-of-art
The overall purpose of the evaluation presented in this section was to compare our summative approach to the current state-of-art processes in the efficient matching and dynamic learning of binary feature descriptors. The following algorithms were used for comparison:
Clustered search trees (described further in 6.1).
Bags-of-features improved by VLAD and vocabulary adaptation (described further in 6.2).
The parameters used for the clustered search trees were
In this evaluation, both the oxford and flickr100k datasets were used so that scalability could be evaluated by extending the training dataset of descriptor sets (from the oxford dataset) with a growing number of descriptor sets (from the flickr100k dataset). The evaluation presented in this paper was carried out on an Ubuntu server with an Intel Core i7-3770 CPU of 3.40GHz and 8GB RAM.
4.2.1. Computational efficiency
Efficiency was in this case measured as the computational cost for both training (computational time for building a model for a training dataset C) and matching (computational time for matching an unknown descriptor set x against the model built for a training dataset C). Rather than focus on particular types of binary features (e.g,. ORB descriptors), the efficiency of training and matching for arbitrary sets of binary strings of lengths

Training (building) efficiency measured as computational cost with respect to growing training dataset C. Above: computational time for training different models with 32 bytes binary strings, below: computational time for training different models with 64 bytes binary strings.

Matching efficiency measured as the computational cost with respect to growing training dataset C. Above: computational time for matching descriptor set x against different models trained with 32 bytes binary strings, below: computational time for matching descriptor set x against different models trained with 64 bytes binary strings.
From Figure 3 it can be seen that all methods had a training cost proportional to the size of the training dataset C, both for binary descriptors of length
Furthermore, the results of computational time for matching, shown in Figure 4, revealed that both suggested
4.2.2. Matching accuracy
Matching accuracy was measured as the average precision in percentage on the oxford dataset. To evaluate accuracy at a larger scale, the evaluation was repeated while adding a growing number of “distracting” images to the training set (randomly extracted as a subset of the flickr100k dataset). Rather than measuring average precision for individual binary strings, a match in this case was measured using a “winner takes it all” approach for the entire query feature descriptor set x. Hence, matching was performed between entire feature descriptor sets (rather than between individual binary feature strings). However, for this evaluation to be comparable, several requirements were established for the search tree approach in order to classify a set of matches as “a match” for the entire descriptor set.
A common issue when working with keypoint-based feature matching is to establish a threshold for distinguish true matches from false matches. In the case of binary point-features, a Hamming distance threshold value for filtering the matches has to be established. Rublee et al. reported a threshold value of 64 for ORB features [6], while [7] suggested a distance threshold of 90 for BRISK [7]. However, no such threshold value has been reported for FREAK and this type of filtering method was therefore not considered in this evaluation. Instead, a distance ratio test was utilized in this case for filtering feature matches of the search tree approach, a method initially presented by [2], together with the initial reported work on SIFT features [2]. A ratio test filtered matches according to the distance ratio between the best match to the second best match for each query string, where only the best match was kept as the true match in cases where this ratio was less than a threshold value set to 0.8 (a threshold value commonly found in the literature [2, 23]).
Another issue when working with keypoint-based feature matching is to determine the minimum number of matches that are required for defining a true match between a full query descriptor set x and a matching training descriptor set c. [2] reported that three correct matches may be enough for a reliable true match in [2]. A recently published work on the evaluation of binary keypoint-based features further addressed this issue in [24], where it was established that a higher number of best matches results in better robustness. However, results with a low number of best matches should not be discarded and in the results given in Figure 5, we have therefore used the average precision for the minimum number of correct best matches of at least 3 matches for the clustered search trees.

Matching accuracy for suggested
The results presented in Figure 5 shows a matching accuracy for the
4.2.3. Adaptability
Adaptability determines how well different approaches are able to adapt a new descriptor set c and extend dataset C to
Moreover, Figure 3 indicates that the computational cost is proportional to length l of the binary strings of the training dataset. Therefore, only descriptors of
The results in Figure 6 show that the computational cost for the suggested

The adaptability measured as the computational time with respect to growing training dataset C. Above: computational time for adding an additional descriptor set c to an already trained dataset C, below: computational time for removing a descriptor set c from an already trained dataset C.
4.2.4. Notes on memory usage
Real-world robot vision applications are limited to the robot's internal memory. It is therefore important to quantize visual features into compact and memory efficient representations. The evaluation presented in this section is an attempt to shed some light on this particular problem.
Before proceeding with this section, we need to approximate how much additional memory each approach allocates as a result of training. This is important for the search tree approach, which includes a random and hierarchical decomposition of the training dataset; hence it is not possible to estimate the exact memory requirement. To overcome this problem, we have in this case measured the average extra memory requirement for training search trees with respect to a growing training dataset C. The extra memory requirement was measured as “extra” binary strings for training the search tree (as a result of the k-medians algorithm, described in section 6.1). The parameters used in this evaluation were
Figure 7 shows a graph representing the resulting measurements, where an equation for a power regression curve was fitted to the measurement series (note the logarithmic scale). Furthermore, with the assumption that floating point numbers are represented by

Estimation of extra binary strings required (as a result of training) for the search tree approach with respect to a growing number of total binary strings in training dataset C




Now, given Eq. 5, 6, 7 and 8, consider the following examples.
From the examples provided above, it is evident that a bag-of-features approach is best for quantizing features into compact representations (which is also the recognized strength for bag-of-features). However, the suggested
Furthermore, in the examples above we have only considered raw feature data. In reality, there is a number of memory related issues and requirements involved in comparing the different approaches.
A bag-of-features approach with dynamic vocabulary adaptation needs to store the original training data in order to re-cluster the vocabulary (neither the suggested
A search tree approach handles binary strings individually and therefore requires an identifier associated with each individual binary string (both a
A search tree approach must be trained and maintained within the working memory (both of the proposed
4.3. Efficiency and accuracy in real-world scenarios
As stated in section 3.1, the motivation behind our approach is to reduce the total search space prior to matching individual descriptor strings. This section presents the experimental results of a combined approach in which the
4.3.1. Ranked results
This section presents the detailed rank of the results in terms of how far the true match is from the best given match. A true match in this context refers to one of the training samples (bark1, bikes1, boat1, graf1, leuven1, trees1, ubc1 or wall1) in the oxford dataset. Table 2 shows the average ranked results for each type of feature descriptor and for each of our suggested representations. All results represent the average result for a training dataset of
Ranked results for each descriptor type and for each query descriptor set (used in this evaluation) after matching against the suggested fsum 1d and fsum 2d representations
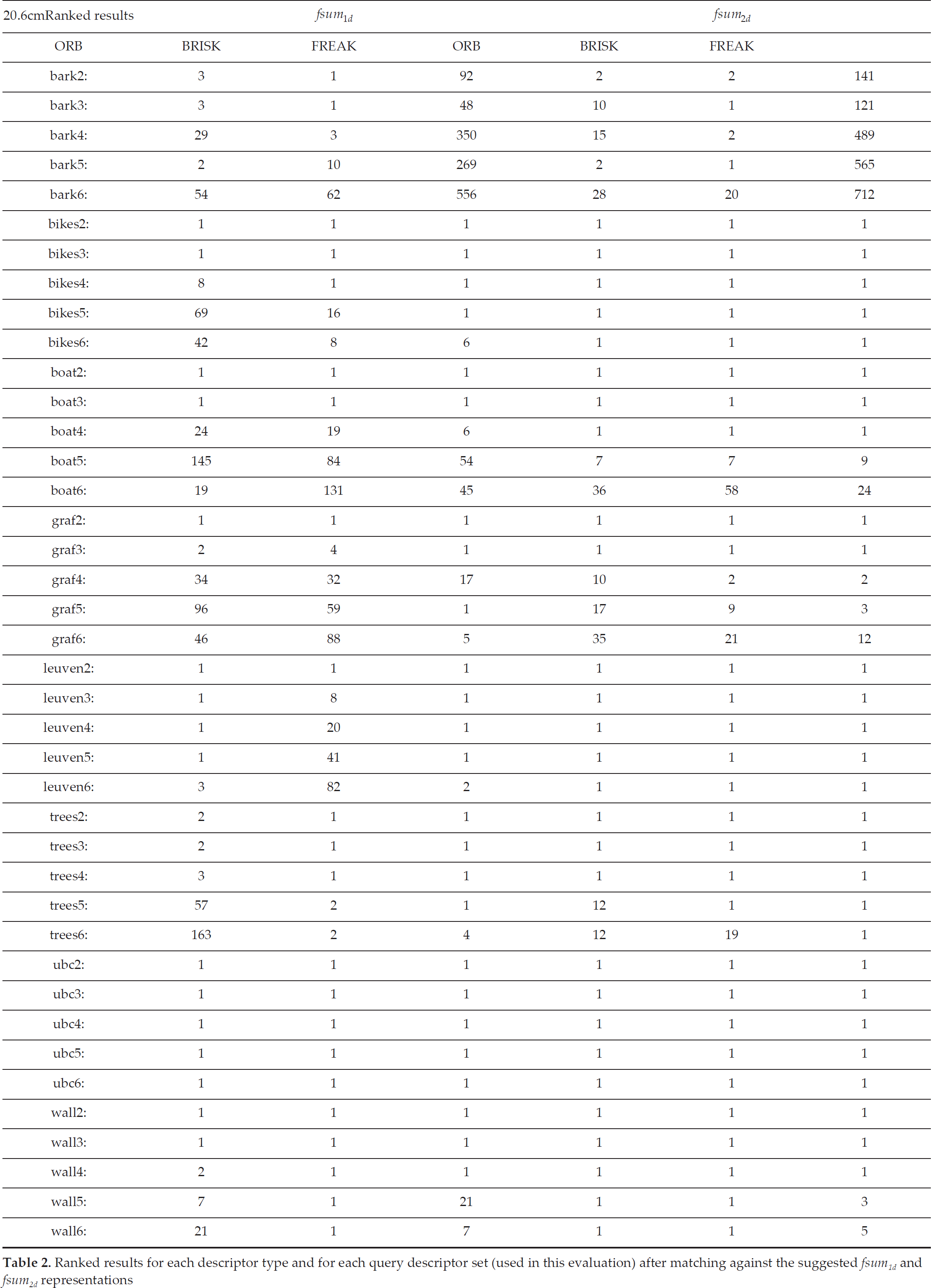
Table 2 shows that (with the exception of FREAK descriptors) the true match is within the top
4.3.2. Combined matching performance and accuracy
The procedure for combining both of the
Depending on the application, we further suggest either using the top ranked result of the
The results shown in Figure 8 show that by taking an approach that combines

Results for a combined approach of using: 1)
5. Conclusions
In this paper we have presented a method that summarizes binary visual descriptor sets into compact representations or an
Another aspect that has been addressed in this paper is the issue of memory requirements for training and maintaining a model for the matching of binary descriptors in the computer's working memory. Since the suggested
Finally, in the context of the performance of feature matching, we would like to point out that the evaluation presented in this paper was carried out using an experimental set-up that employed a single process (for comparison and consistency). However, since descriptor sets are handled individually in the suggested