
Abstract
This paper presents an optimized scheme of monocular ego-motion estimation to provide location and pose information for mobile robots with one fixed camera. First, a multi-scale hyper-complex wavelet phase-derived optical flow is applied to estimate micro motion of image blocks. Optical flow computation overcomes the difficulties of unreliable feature selection and feature matching of outdoor scenes; at the same time, the multi-scale strategy overcomes the problem of road surface self-similarity and local occlusions. Secondly, a support probability of flow vector is defined to evaluate the validity of the candidate image motions, and a Maximum Likelihood Estimation (MLE) optical flow model is constructed based not only on image motion residuals but also their distribution of inliers and outliers, together with their support probabilities, to evaluate a given transform. This yields an optimized estimation of inlier parts of optical flow. Thirdly, a sampling and consensus strategy is designed to estimate the ego-motion parameters. Our model and algorithms are tested on real datasets collected from an intelligent vehicle. The experimental results demonstrate the estimated ego-motion parameters closely follow the GPS/INS ground truth in complex outdoor road scenarios.
1. Introduction
Visual odometry involves the estimation of camera motion and the motion of the vehicle the camera is attached to, using a sequence of camera images. Ego-motion is one of the most important areas of visual odometry, in which the instantaneous relative motion of the camera is estimated. It has been applied in many areas, such as scene reconstruction by structure-from-motion (SFM), autonomous navigation, computer-vision-based driving assistance [1, 2, 3, 4, 5], obstacle avoidance, and short-term control (steering and braking) [6, 7]. Typically, visual ego-motion is used in those cases where GPS is denied, is insufficiently accurate with signal attenuation, or is too heavy to carry [8, 9]; it is always complementary to wheel odometry because of its advantage of robustness to wheel slippage, which can cause serious errors in wheel odometry. Most visual ego-motion research has been produced based on stereo cameras [10]. Moravec [11] presented the first motion-estimation pipeline for stereo-vision-based ego-motion, and tested it on a planetary rover. A completely different approach was proposed in 2004 by Nister et al. [12]. Their paper presents a 3D to 2D camera-pose estimation problem and a real-time long-run implementation with a robust outlier rejection scheme. Recent developments show significant progress in stereo visual odometry, such as combining a dense probabilistic 5D ego-motion estimation with a sparse key-point-based stereo approach [13]. However, the use of stereo cameras reduces the field of view because only features lying in the intersection of the two cameras' fields of view are used, and the accuracy is dependent on inter-camera calibration, which can be hard to ensure if the cameras are separated significantly. Finally, the cost of components, interfacing, synchronization, and computing are higher for stereo cameras compared to a monocular camera [8, 14].
In recent decades, monocular ego-motion has attracted more attention. Here, only a monocular image sequence is taken as input, a method that is inexpensive and easy to calibrate relative to stereo vision. Successful results with a single camera over long distances have been obtained in the last decade using both perspective and omnidirectional cameras [15, 16].
Related works can be divided into two categories: feature-based methods [14, 17] and appearance-based methods [15]. Feature-based methods [18, 19] are based on salient and repeatable features that are tracked over the frames; appearance-based methods use the intensity information of all the pixels in the image or sub-regions of it. Recently, Choi [20] presented a feature initialization and monocular EKF method for indoor-environment SLAM, and Milford and Wyeth [21] presented an appearance-based method to extract approximate rotational and translational velocity information from a single-perspective camera mounted on a car, which was then used in a RatSLAM scheme. They used template tracking at the centre of the scene.
Most feature-based algorithms deal only with regular or structured environments, such as indoor scenes or outdoor scenes in urban environments [15, 22, 20, 27, 30], where corners and segments are salient. Appearance-based approaches are suitable for most environments; however, a major drawback of these methods is that they are not robust to occlusions. These methods can increase the error of the ego-motion, and even lead to an unreliable estimation. Many algorithms implement some form of the RANdom Sampling and Consensus (RANSAC) outlier-rejection method to augment the image correspondence process [14, 23, 24], since these visual ego-motion algorithms are sensitive to incorrect matches. The basic random sampling method starts with successive minimal sets of correspondences being used to derive hypothesized solutions; the remaining correspondences are used to assess the quality of each hypothesis. However, while basic sampling algorithms assess the quality by counting the number of matches which support the current hypothesis, the error distribution is not considered. There are other similar algorithms in which prior probabilistic [28] or estimated ego-motion information is used to guide the search for matches.
In this paper, we describe the case of a single forward camera mounted on a mobile robot. We design a Maximum Likelihood Estimation (MLE) optical flow model and algorithms for monocular ego-motion, which achieve good performance in real-world tests. First, a multi-scale hyper-complex wavelet phase-derived optical flow without feature matching is designed to estimate image micro motion. This is a multi-scale signal correlation algorithm and does not involve any detection of feature points, so it overcomes the difficulties of unreliable feature selection and feature matching of outdoor scenes; at the same time, the multi-scale strategy overcomes the problem of road surface self-similarity and local occlusions. An MLE ego-motion model is constructed to describe the error distribution between the estimated image optical flow and hypothetical robot-motion-induced pixel motion, which is an optimized estimation of inlier parts of the optical flow. Then, a sampling and consensus strategy is designed to estimate the ego-motion parameters. In a development of RANSAC, we evaluate the likelihood of the hypothesis by representing the error distribution as a mixture model. Validity of optical flow vector is used as the support probability of inliers. All of these merits make our method suitable for outdoor mobile robot ego-motion estimation.
The remainder of this paper is organized as follows. Firstly, the basic theory and methods including multi-scale optical flow estimation and monocular ego-motion are described. Secondly, the support probability of the optical flow vectors and maximum-likelihood optical flow model are presented. Thirdly, the monocular ego-motion estimation algorithm using the MLE optical flow model is provided together with the sampling and consensus strategy. Fourthly, experimental results and analysis are given. Finally, some concluding remarks are provided.
2. Basic Theory and Methods
2.1. Hyper-complex Wavelet (HCW)-based optical flow field
An image sequence of the environment is always achieved when we fix a camera on a moving vehicle, and vehicle motion induces movement of image pixels. Pixel movements in an image sequence reflect vehicle motion in the physical world. Phase-based optical flow vectors and support score estimation are introduced in this section for monocular ego-motion.
The phase localizes the frequency components of an image in space (a spatial structure); it is insensitive to luminance variance. Phase difference in HCW space describes the motion of image blocks [25, 29]. HCW is based on the definition of the 2-D Hilbert Transform (HT) and analytic signal [25] according to the theory of quaternion. It is composed of a discrete-wavelet-transform tensor wavelet plus three real wavelets obtained by 1D HTs along either or both coordinates. Given a real tensor product wavelet
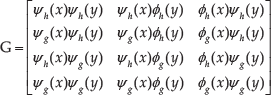
Each column of G is a sub-band of HCW, and four components of every column compose a quaternion wavelet. The diagonal sub-band quaternion wavelet is shown in Equation (2):

where g -indexed wavelet filters are HTs of h -indexed filters. Furthermore, a quaternion
Assume two blocks Ot and Or in the image pair

That is to say,

where W is the search region, within which the disparities are assumed to be smoothly varied.
2.2. Monocular ego-motion based on optical flow
First, the coordinate system and some parameters are defined.
Definition 1: For the camera coordinate system in
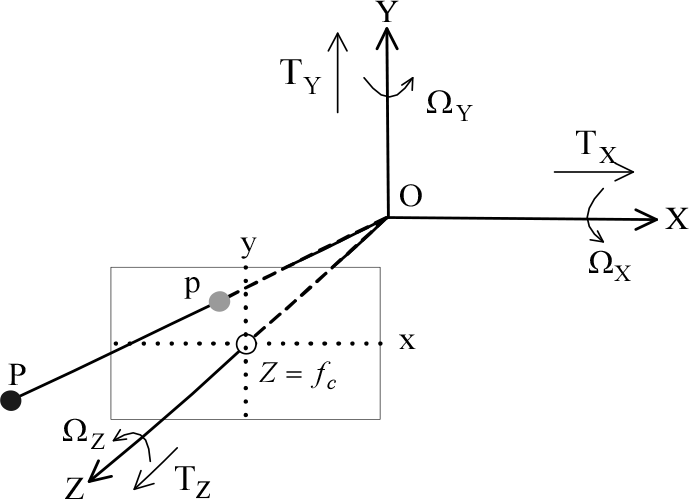
Coordinate system
Definition 2: For the image coordinate system in
Definition 3: The camera motion Γ is modelled as a rigid motion: a translation
Then, according to perspective transform theory,

The basic problem for monocular ego-motion is to estimate the rigid body transformation
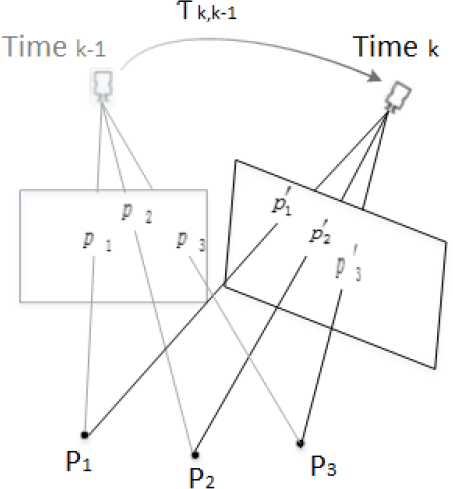
Projection of pixels in a translation
When the robot is running on relatively flat ground, the model can be simplified. Statistical analysis on gravel roads finds that the translation TY along the Y axis is faint and can be neglected; however,

We can also notice that the translational and rotational components are separable, and a partition strategy can be used because larger

exhibits such small amounts that those measurements would be overwhelmed by tracking noise; therefore, the optical flow vectors in the upper image region mainly describe the rotation. Then, the rotations can be estimated according to Equation (8) and the optical flow vectors in the upper image region [16].

The estimated rotation parameters Ω and the optical flow field in the lower region of the image are then used to estimate translation parameters according to Equation (6).
Given optical flow vectors in the image space, we can estimate translation parameters T and rotation parameters Ω according to Equation (6) and Equation (8).
3. Maximum-likelihood Optical-flow-model-based Ego-motion Estimation
3.1. Support probability and estimation
In the present paper, an improved method to describe image motion and the probability of its correctness is developed. Image motion is small between consecutive image pairs for high-frequency shooting, and phases in the HCW field are multi-scale; therefore, large-scale estimations guide those on a smaller scale. However, many incorrect image motion vectors are also found (Figure 3(c)). If the probability of optical flow correctness is estimated, the error distribution induced by the motion model will be described effectively. The similarity of image blocks corresponding to the optical flow vector is then used to describe the correctness probability.

Phase used in optical flow vector and support probability estimation
The local phase difference corresponds to the local translation of the image, and the same image blocks have the same phase structure; therefore, the score of optical flow vector

where Ws is the support window, which is an image region around
The optical flow vector estimated in the HCW space on a larger scale only guides candidate image motions on a smaller scale. Therefore, a probability function is introduced to describe the validity of the candidate image motions. First, it is found that optical flow error of inliers always obeys Gaussian distribution [28], and there are
We use

At the same time, there is only one inlier optical flow for index

Then,

The candidate with the highest
Finally,
3.2. Maximum-likelihood optical flow model
In general, estimation is done analytically according to the optical flow between two consecutive images; however, noise and outliers can disturb the estimation. An optimized method is always used to estimate more accurate and robust
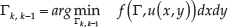
where
Many studies use the image intensity

In the following, without loss of generality it is assumed that the noise in the optical flow of two consecutive images is Gaussian with zero mean and uniform standard deviation σ. Thus, the conditional probability density function of the disturbed motion is
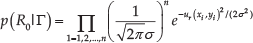
where n is the number of optical flow vectors and R0 indicates the observing residuals.

where
In visual ego-motion the image sequence is shot with very high frequency, which means little motion between two shots. The noise of optical flow estimation therefore always lies in a limited range and the uniform distribution parameters can be determined. The uniform standard deviation σ can be estimated through measured residuals for valid matches of a sample, which indeed are well-fitted by a Rayleigh distribution, therefore σ can be induced accordingly. The negative log maximum likelihood of P is shown in Equation (17), which is called the MLE optical flow model:
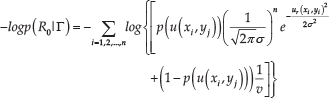
In particular,
4. Monocular Ego-motion Using MLE on Optical Flow
Based on the above MLE optical flow model, an ego-motion parameters estimation method for autonomous vehicles is introduced in this section. A block diagram of the proposed approach is shown in Figure 4. The system is composed of three main parts: optical flow computation and support probability estimation, MLE optical flow model construction, and ego-motion computation.

Block diagram of the monocular ego-motion framework
The first block, “optical flow computation and support probability estimation”, receives as input the rectified images and provides as output a list of optical flow vectors and support probabilities. Then, the MLE optical flow model is constructed according to image motion residuals and their distribution of inliers and outliers together with their support probabilities. Finally, the ego-motion block receives as input the image motion optical flow vectors together with the MLE optical flow model and provides as output the translation and rotation of the camera platform between current and previous iterations. A sampling and consensus strategy is adopted to estimate the ego-motion parameters of this moment relative to the previous moment based on the proposed MLE optical flow model. The parameters are estimated which minimize the MLE optical flow model Equation (17). Then, a motion step stores the rotation and translation of the camera between two consecutive frames.
A sampling and consensus strategy similar to RANSAC is adopted, whose samples are labelled with the support probability to estimate Γ, avoiding minimizing Equation (17). Then, the minimal set samples are selected to pre-estimate the model parameters, guided by the probabilities; this is not random. The steps are as follows:
In the beginning of each iteration, the minimal optical flow set with the higher support probability is chosen according to the Monte-Carlo method.
A hypothesis Th is estimated according to the pinhole imaging theory [7] using the chosen minimal optical flow set.
All other observed optical flows are observed with those induced by Th; then, the residuals
The likelihood
Return to step 1) to choose another minimal optical flow set. The process is repeated until the loop termination, when we find optimized Γ.
5. Experiment Results and Discussion
This section presents our experimental results for the framework and algorithms validation on a real vehicle equipped with a CMOS camera for computing the monocular ego-motion on a country road. Our monocular ego-motion output is compared to the integrated GPS/INS system, which is treated as ground truth. It is shown that the ego-motion estimations are accurate and reliable in realistic ground-vehicle scenarios without a priori knowledge of the motion.
The frame rate of the achieved video is set to 30 frames per second, and each frame has 256 × 256 pixels. In our experiment, the road is covered with clay, gravel, sand, weed, or asphalt and concrete. A GPS/INS joint system, whose angular accuracy is 0.05°, absolute localization accuracy is 0.1 m, and relative localization accumulative error is lower than 0.5% of the mileage, is used to validate the accuracy of the recovered vehicle ego-motion.
5.1. MLE optical flow computation
Figure 5 illustrates the results of our MLE optical flow estimation for two scenarios from the image sequence shot by a single on-robot camera with the vehicle moving along a country road. The figure shows the optical flow estimated through phase coherence and the MLE optical flow, respectively. The optical flow vectors with lower probability of being inliers are discarded in Figures 5(b, d), from which it is found that some motion noises are eliminated by MLE optical flow estimation, especially visible in the lower left and lower right of frame 1. From Figure 5(c), we find that there is a lot of noise in the road surface optical flow estimated by phase coherence because of the texture similarity in the wave window. However, when we estimate support probability of optical flows, according to Equations (10) and (11), then the optical flow with lower probability is discarded, as shown in Figure 5(d). We find that support probability of obvious noise, i.e., the likelihood of optical flow vectors being inliers, is low.

Comparison of optical flow and MLE optical flow
5.2. Ego-motion estimation and performance analysis
The ego-motion including instantaneous steering increment, pitch increment, roll increment and translation of the vehicle between consecutive frames estimated through the MLE optical flow model is shown in Figures 6∼9. Comparisons of these incremental motions among MLE optical flow ego-motion estimation, phase coherence with RANSAC, and GPS/INS as the ground truth are shown in the following to test the instantaneous relative motion measuring accuracy.
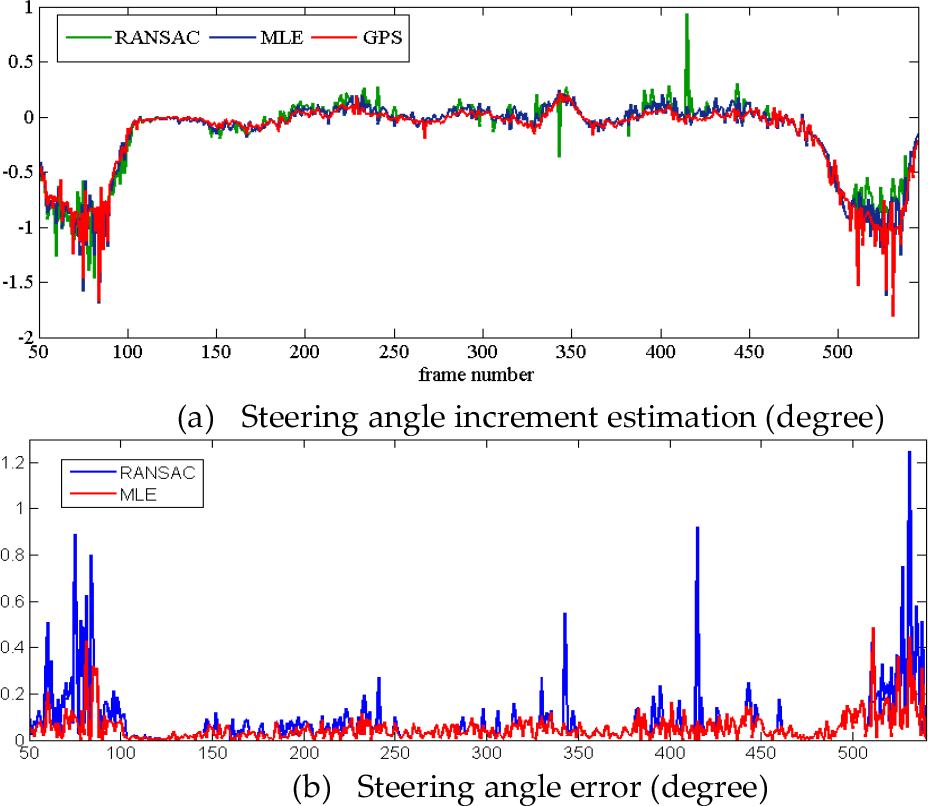
Steering angle estimation of MLE optical flow method and RANSAC method
The vehicle is running on a road with two apparent bends; one of them corresponds to the frames around the 50th frame and another corresponds to the frames around 520th frame. In order to express the estimation clearly we show frames from the 50th to the 545th. From Figure 6, it can be seen that the steering increment estimations of MLE and RANSAC closely follow the ground truth. However, we find that the MLE method improves estimation accuracy because there is more noise in optical flow vectors, which disturbs the estimation of the RANSAC method remarkably compared to MLE. It is also found that some obvious errors are restrained, such as in frames 60, 78, 343, 415, 516, and 531, where we find many optical flows are misestimated and disturbed because of texture self-similarity. Figure 6(b) also shows that at the two bands around frames 60 and 520 the errors in the MLE-based method are more obvious than in the other frames. We analyse these scenes as corresponding to substantial motion, which means deformation of the local image and therefore more errors in the support probability estimation.
Figure 7 and Figure 8 show the pitch and roll increment estimation, respectively. It is found that pitch increment estimation of our MLE method is close to the ground truth. The increment around frame 450 is larger because of a bumpy road, which corresponds to a wide crossroads with few features. We also find larger luminance change between images around frame 450; it is a rugged environment for the monocular ego-motion method, and will induce more error in image motion estimation. Our MLE-based method estimates the pitch and roll more accurately and robustly than the RANSAC-based method, as shown in Figure 7(b) and Figure 8(b).

Pitch angle estimation of MLE optical flow and RANSAC methods
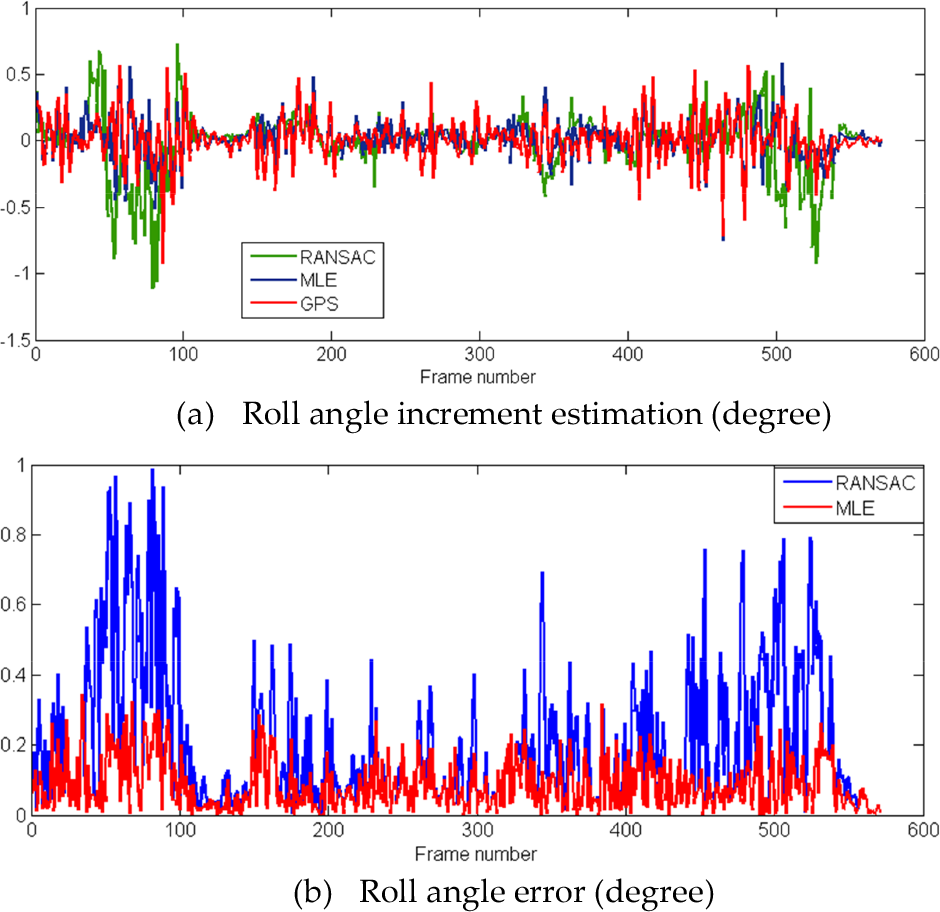
Roll angle estimation of MLE optical flow and RANSAC methods
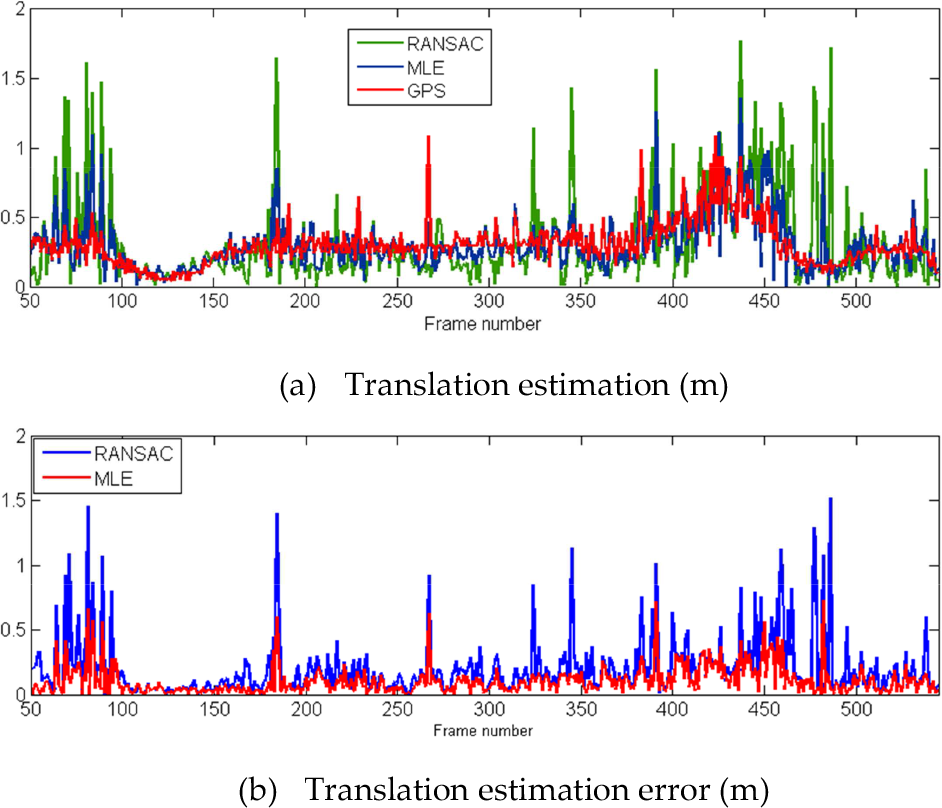
Translation estimation of MLE optical flow and RANSAC method
Figure 9(a) shows that our translation estimations closely follow the ground truth, and greater errors are restrained. Figure 9(b) shows that the error of our method was almost uniformly distributed during the test; however, there were greater errors in the translation estimation of the RANSAC-based method, especially around frame 90 and frame 490. After analysing the road scene, it is found that the road around frames 90 and 490 is bumpy. The roll angle error or pitch angle error of the RANSAC-based method is notable, inducing more errors of translation estimation. However, we use the optimized model to describe the error distribution and estimate the steering angle, pitching angle, roll angle and translation more accurately.
Table 1 shows a comparison of the statistical ego-motion estimation error between our method and a RANSAC-based method [29]. It can be seen that both the estimated maximum error and the standard deviation of our method are smaller than for the RANSAC-based method. That is to say, compared to the RANSAC-based method, our method obtains higher accuracy and higher precision using the MLE optical flow model and corresponding methods.
Ego-motion estimation error comparison

From the above experiments, we can conclude that the MLE optical flow model and the sampling and consensus parameter estimation algorithms represent an optimized scheme for ego-motion estimation of outdoor unstructured road, even though some bumps are encountered. Furthermore, it overcomes the difficulties of salient feature absence and road scene self-similarity. All in all, the ego-motion estimations of our method closely follow the ground truth in most frames.
6. Conclusions
This paper has presented a monocular ego-motion estimation method based on an MLE optical flow model and sampling and consensus parameter estimation algorithms for mobile robots. Our algorithms use as input only those images provided by a single forward-looking camera and the output of the system is the instantaneous relative steering, pitch, roll and translation increment on the road.
The proposed scheme includes three main parts. Firstly, the multi-scale optical flow field is estimated through HCW, and then the support probability of optical flow vectors being inliers is estimated according to the phase structure to describe the image motion and estimation errors more accurately. Secondly, an MLE optical flow model is constructed based not only on image motion residuals but also their distribution of inliers and outliers, together with their support probabilities, to evaluate a given transform. At last, a sampling and consensus strategy guided by the support probability is used to estimate the ego-motion parameters.
The proposed method is tested on videos from a mobile robot platform. From experimental results using a sequence of more than 500 images, the estimated error of ego-motion parameters closely follows the high-precision GPS/INS joint system. Moreover, steering angle increment, pitch angle increment, roll angle increment, and translational increment with MLE optical flow are smaller than with RANSAC-based methods.
In future research, we will improve the scheme and algorithm to estimate 6-DOF ego-motion parameters for large-scale and rugged terrain.
Footnotes
7. Acknowledgements
This work was partially supported by a fund from the National 863 High Technology Research Fund (2015AA8106043), the National Science Foundation of China (Grant No.61402237, 61302156) and the Jiangsu Key Laboratory of Image and Video Understanding for Social Safety (Nanjing University of Science and Technology - Grant No. 30920140122007).