
Abstract
This paper describes an autonomous robot's method of dressing a subject in clothing. Our target task is to dress a person in the sitting pose. We especially focus on the action whereby a robot automatically pulls a pair of trousers up the subject's legs, an action frequently needed in dressing assistance. To avoid injuring the subject's legs, the robot should be able to recognize the state of the manipulated clothing. Therefore, while handling the clothing, the robot is supplied with both visual and tactile sensory information. A dressing failure is detected by the visual sensing of the behaviour of optical flows extracted from the clothing's movements. The effectiveness of the proposed approach is implemented and validated in a life-sized humanoid robot.
1. Introduction
Everyday clothing exists in various forms, and dressing is an essential part of humans' daily routines. Since clothing is changed to suit appropriate times and circumstances, we can also regard dressing as an important social activity. However, elderly individuals or those with physical disabilities frequently require assistance while dressing. Automated dressing would improve the quality of life for these groups of people [3].
In this study, we focus on a dressing action that is particularly problematic for disabled people, i.e., the pulling of clothing items such as trousers along the legs. The main contribution of this study is to show a full system for achieving this dressing motion by using an autonomous robot. The system requires recognition functions and motion-planning functions, as well as close cooperation with each other. We designed functions that were suitable for clothing manipulation, and coordinated them to form another important function: failure detection and recovery.
With respect to recognition, the estimation of clothing states is challenging because clothes are soft objects whose shapes change greatly when they are handled. The robot must understand the condition of fabrics in order to avoid injuring the subject's legs. To achieve this recognition, we extracted optical flows from two consecutive images that were captured during dressing, and used them to estimate the clothing's present state. Incorrect situations were detected by supplementary force sensors mounted on the wrists of the robot.
The robot must also create an end-effector trajectory for pulling up a pair of trousers. Because leg length differs among individuals, the trajectory planning should be adjustable on site. To accommodate leg differences, we created a set of trajectory segments corresponding to the standard leg size in advance. These trajectory segments were then fitted to the size and position of the subject's legs using depth information captured by a range camera just before dressing. Modifications were based on a statistical human model.
Collectively, estimation of clothing state and on-site trajectory modification enables failure detection and a recovery function. In other words, if the estimation function detects an unforeseen situation, such as the snagging of the toe on cloth, the original trajectory changes to another trajectory in order to restore the previous trouble-free condition. Once the failure is corrected, the dressing procedure continues. The effectiveness of the function was confirmed in experiments on a real humanoid robot.
This paper is organized as follows: In the next section, related work is introduced. Section 3 describes our approaches. Sections 4 and 5 describe the clothing's state and estimations based on optical flows. Section 6 describes the end-effector trajectory planning. Sections 7 and 8 introduce experimental results, and Section 9 concludes this paper.
2. Related Work
2.1. Dressing Assistance by an Automated Machine
Dressing assistance has received little attention in robotics research. Among the few relevant studies, Matsubara et al. [12] proposed the use of reinforcement learning in putting on a t-shirt. They found a feasible end-effector trajectory after dozens of trials. Several machines that provide daily assistance relevant to clothing have also been developed. In the case of a support machine for the toilet, the subject needs only to stand at the centre of the machine, and their body is manipulated by mechanical arms equipped with custom-designed actuators.
Dressing actions using these systems are based on grasping points and motion trajectories. Manipulation failures during dressing are not considered, and recognition functions that provide information about the dressing state are lacking. However, these functions are crucial in practical applications because of the difficulty inherent in controlling the fluid motions of clothing.
2.2. Clothing-state Estimation
Unlike dressing assistance, recognition methods for clothing manipulation have been widely reported in the literature [6,19]. Because objects made of cloth are so flexible, observing their motions during manipulation is essential. Previous research has represented clothing items via contours and deformable models.
Ono et al. [15] estimated the state of a rectangular piece of cloth from its contour information. Data were provided as groups of planar states, some of which had bent corners. Other researchers used silhouette information to estimate the state of a piece of cloth hung up by a robot [11,16]. Kita et al. [7] converted images captured by a trinocular stereo camera to a cloud of input points, which were fitted to a three-dimensional deformable model.
Three-dimensional databases can also be created by a physical engine. Kita et al. [8] fitted the three-dimensional cloth model to a three-dimensional point cloud. Maitin-Shepard et al. [11] proposed action selection for manipulating deformable planar objects. By implementing a physical model, they achieved the straightening of a square-shaped cloth by a robot.
These previous studies assumed static conditions for the cloth during the recognition process. Almost all of the studies above use prohibitively time-consuming methods (requiring several tens of seconds for a single estimation [13]). For practical application, the efficiency of state estimation must be markedly improved.
3. Issues and Approaches
3.1. Assumed Dressing Procedure
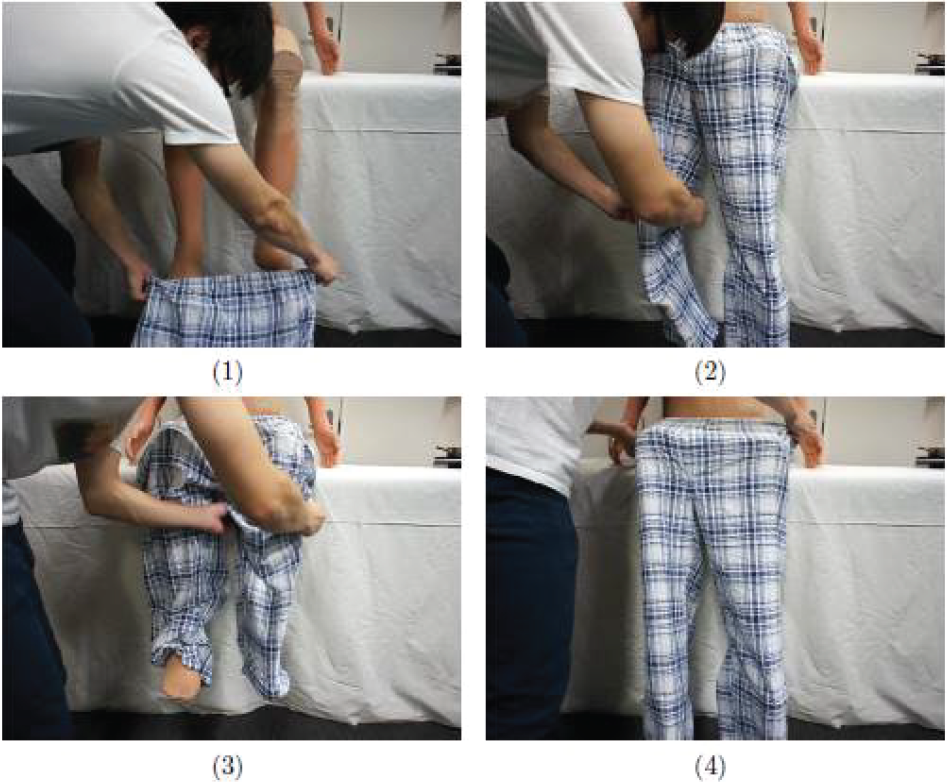
The purpose of this study is to dress a person seated at a bedside. The person is presumed to possess partial control over his limbs. Figure 1 shows the sequence of dressing a mannequin. As shown in the mannequin's poses, we assume that our target person can lift one leg and pull himself into a standing position.

A dressing procedure
We assume that the dressing task is divided into several phases: (i) insert both feet into the trousers' legs (Figure 1, (1)), (ii) pull the item up to cover the knees (Figure 1, (2)), (iii) pull up the dangling hem on one side (Figure 1, (3) and (4)), (iv) repeat (iii) for the other side (Figure 1, (5) and (6)) and (v) pull the item up over the hips (Figure 1, (7) and (8)). In this study, the robot performs motion sequences (i)-(iv). We focus, especially, on sequences (i) and (ii).

Failure cases. Top left: neither leg is successfully inserted. Top right and middle left: only one leg is successfully inserted. Middle right, lower left and lower right: both legs are inserted into one trouser leg.

A framework for the estimation of dressing

An example of an optical flow when only the lower left part was manipulated. Left: original image, centre: detected flows depicted by colour segments, right: the distribution of the flow magnitude.

Relationship between overall flows and local flows
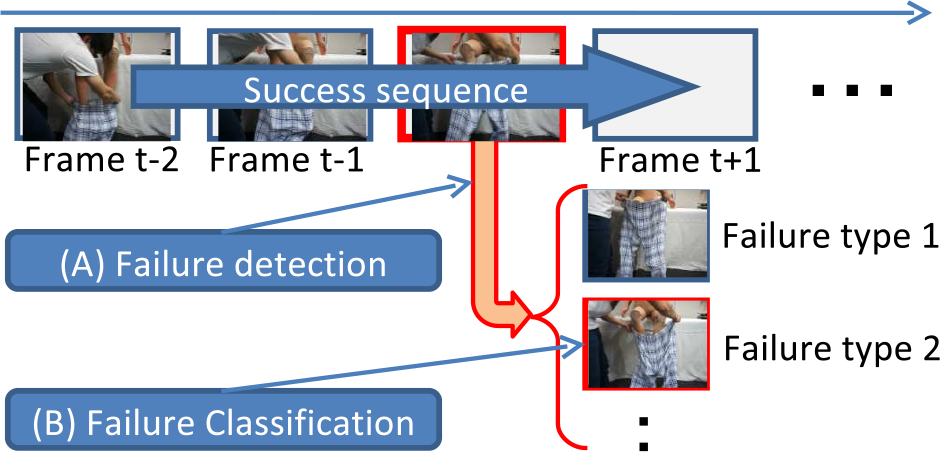
Online classification of a clothing sequence
State transition model

An example of leg detection. Upper left and right images: colour image and depth image captured using an Xtion sensor. Lower left: a region-growing result. Pixels of the same colour represent the fact that they belong to the same cluster. Lower right: a legs-detection result. Two clusters regarded as legs are extracted using the region-growing result. Yellow points show the gravity centre of each cluster.
Another procedure is possible. For instance, in order to reduce the difficulty of leg insertion into the deformable trousers, one method is to roll the trousers' legs before inserting the subject's feet. However, one issue with this method is the difficulty of the rolling manipulation for the robot, so the manipulation must be done by the person getting dressed. On the other hand, in our procedure described above, what the person should do is to let the robot grasp both ends of the trouser legs, which is more practical.
3.2. Dressing Problems
During the dressing action outlined above, some undesirable situations may occur while inserting the subject's legs into the clothing item and pulling it up the body. For example, as shown in the lower left and right-hand panels of Figure 2, the feet may snag on the cloth, or a leg may not enter the desired opening. To avoid these undesirable situations, the progress of the dressing action should be monitored and managed by external sensors.
Previous researchers have used image sensors to figure out the state of clothing. Because images provide a wide variety of information, this approach show promise for our proposed application. From past research, we can find various options for how to create knowledge about cloth in advance, and how to extract useful information from image data. Past researchers have modelled clothing via three-dimensional deformable models [8], three-dimensional mesh models [7] and two-dimensional contours [11].
These models are then matched with processed sensory data, such as three-dimensional point clouds and image contours. Previously proposed matching methods are based on position alignment between the model and sensor data. However, the alignment approach has always been time-consuming when applied to flexible objects such as clothes. Thus, an effective matching process is imperative in order to realize a practical robotic dressing system.
From the discussion above, we identify the following problems relating to dressing:
3.3. Approach
To resolve the issues above, we adopt the following approaches:
To construct prior knowledge, a series of optical flows measured from various dressing patterns are preregistered and labelled according to their dressing phase. In the state-estimation process, the current optical flow is compared with the registered optical flow, and the label of the most similar situation is used to represent a present clothing state. The method presented is the main contribution of this paper; it is described in detail in Sections 4 and 5.
If the robot dresses another person's body with trousers, an end-effector trajectory is created by modifying the basic trajectory. Because the result of item (b) provides an approximated position of a convex body shape, its difference from the original subject is used for the modification. The details of this are described in Subsection 6.2.
Section 4 is dedicated to determining whether the robot adopts an appropriate dressing behaviour (item (a), above). The input to the proposed method is an image stream of the dressing sequence. Section 5 details the state estimation of the legs and the planning of the end-effector trajectory (items (b) and (c), above). In these steps, the input is a depth image captured immediately before the dressing action occurs.
We will also discuss the correction of dressing failures. Failures are detected by vision functions described in the next section, supplemented by force sensors embedded in the robot's wrists. Because our vision function returns the type of failure, the result is used to decide the next end-effector trajectory that will address the failure.
4. Description of an Optical Flow-based Clothing State
Optical flow is calculated from two consecutive images. Using the flow distribution, the present clothing state is then matched to the optical flow extracted from the training dataset. Therefore, we describe the clothing's condition in terms of three feature types. The method outputs the status of the present act of dressing, i.e., successful or otherwise. If the dressing is unsuccessful, the method outputs the specific type of failure. To improve the discrimination process, a transition graph is utilized.
4.1. Framework Overview
Figure 3 is a flowchart of the proposed method. The major procedures are outlined below:
4.2. Pre-processing the State Description of Dressing
Pre-processing 1: Domain segmentation
Before description of the state, the image region of the target clothing item is extracted via a dynamic graph cut method [9]. This procedure minimizes the following cost function [1]:

where V is a group of image pixels and
Optimization by graph cut usually requires pre-specified seed points. In our case, the points are automatically detected using three-dimensional information because we use a 3D-range image sensor. After specifying the pose of the subject's legs via the method introduced in Section 6.1, pixels satisfying the following items are used as foreground seed points:
Arranged in the lower half of the legs in 3D space,
a colour different from that of the skin and
a certain level of a large optical flow is detected from the pixels.
Once the seed points are given, the first graph cut is performed. After that, the dynamic graph cut uses the resulting region in the next frame.
Pre-processing 2: Optical flow calculation
The optical flow is calculated from the consecutive clothes region in an image stream. We require methods that do not need a distinctive texture to work since clothing does not necessarily have such a texture. Therefore, we apply a method proposed by Farneback [4], which compares two local image windows

where
Because this method outputs high-density flows, even from less textured regions, it highly expresses the detailed shape changes of clothes.
4.3. Three descriptive Features of Optical-flow Information
Flow magnitude Fm
When a piece of cloth is manipulated, the extent of its motion can vary depending on the situation, because it is a soft object. The global motion characteristics of a piece of fabric can be expressed by the magnitude of the flows.
Our first descriptive feature is calculated via the following procedure. Unnecessary flows of excessively large or small magnitudes are removed by threshold processing. The remaining flows are normalized by their average magnitude. The normalization step allows flows to be matched regardless of the dressing speed.
In the central panel of Figure 4, the flows are colour-coded according to their directions. The right panel distinguishes the flow magnitudes (motion speeds) by their brightness. Fm is generated by calculating the density histogram from the greyscale image.
Mutual relationship between flow pairs Fr
The second feature describes the positional and directional relationships between a pair of flows. This feature quantifies the complexity of flows, i.e., whether a group of flows is well aligned or disturbed.
Let
The distance between two flows

The angle between one flow direction and the position vector between two flows.
The angle between one flow and another
These calculations are performed for many randomly sampled flow pairs, and the results are voted into the three-dimensional parameter space whose axes correspond to items 1)-3) above. Fr is generated by calculating a frequency histogram from the voted space. In this calculation, the space is divided into small voxels, and the number of points in each voxel is counted. Each number is assigned to one bin of the histogram. In our experiments, the frequency histogram was composed of
Local flow movement Fl
A flexible material such as cloth develops many wrinkles and stretched areas. Thus, when a part of the target cloth is manipulated, the cloth is frequently reformed around the manipulated part. Such a partial movement is represented by extracting possible flows in local areas.
In preparation for feature description, the central position of the clothing region is calculated from the image-segmentation result. Meanwhile, only regions of dense flows are selected as descriptive features. RANSAC [5] is used for this process. Fl is generated by calculating the relationships between the central position and the local flows, as shown in Figure 5. This feature is specified by two criteria: (i) the direction from the local flows to the central position, and (ii) the area ratio of the local flow and clothing regions.
5. Clothing State Estimation Using the State Transition Model
The clothing state is determined from three estimation targets.
The dressing is successful or unsuccessful (Figure 6, (A)),
if successful, return the present state,
if unsuccessful, return the type of failure (Figure 6, (B)).
To construct a state classification, we prepare a database of feature vectors calculated from a set of training data. Several image streams of successful and unsuccessful clothes dressing are captured. The optical flow and the three features Fm, Fr and Fl are calculated from each image stream. The database contains a list of the features, appended by information of dressing states.
The database serves the following main purposes:
Phase estimation: One dressing sequence is divided into several phases. The database is accessed in order to identify switching events.
One-on-one matching: A pair of consecutive images produces a set of optical flows. The result is used for frame-to-frame matching by which the present dressing condition is recognized.
Based on this information, we implement two types of feature set, illustrated in Figure 2 (6), (7).
5.1. Evaluation Formula
The activity of dressing is estimated by searching for the feature set calculated from current image pairs. Let
Because we specify three feature descriptions, the similarity calculation should integrate these three features. To this end, we express the similarity as follows:

where
Let k be a serial number of phases, and

where
Meanwhile, the Euclidean distance is used for

where
5.2. Improving the Effectiveness and Robustness of State Matching
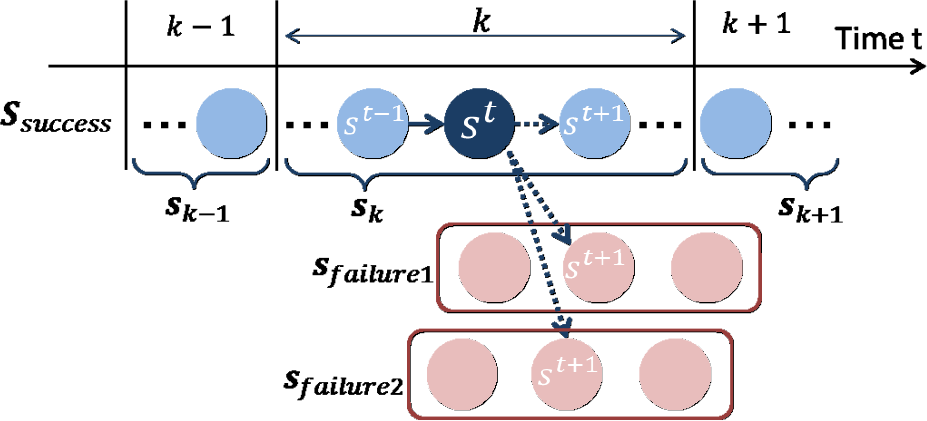
A state that is similar to the current one can be found by matching the current state to all states in the database. However, this approach is time-consuming and prone to producing mismatches. Therefore, we improve the efficiency and robustness of the search by employing a state transition model.
The transition model is based on dressing phases. For instance, if the present phase describes a situation in which both legs are inserted into a pair of trousers pulled up by both hands, the next phase can be limited to a manipulation that inserts one foot into one of the trouser legs. If such a transition is not detected, the present manipulation is regarded as a failure.
A transition from one phase
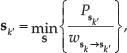
where
Figure 7 is a conceptual diagram of the state transition model. Normally, a transition occurs from one successful phase to the next, but unsuccessful phases transition to failure states such as
6. End-effector Trajectory Generation
As mentioned in Section 2, our approach assumes a basic end-effector trajectory, and this trajectory is adaptively modified to fit individual subjects. This section explains how the state of the subject's legs is measured, and introduces a strategy for modifying the end-effector trajectory.
6.1. The Estimation of the Joint Positions of Legs
The state of the legs is evaluated from images acquired by a three-dimensional range camera, Xtion PRO LIVE. Immediately before the dressing action, the robot stands before the subject and acquires a depth image of the two legs. The subject's legs, captured by the sensor and the pre-processing result, are shown in Figure 8.
The depth image is shown in the upper-right panel. Applying the region-growing algorithm to this image, we obtained dozens of three-dimensional clusters (lower-left panel).
6.1.1. The Legs' Extraction by the Region Growing Algorithm
The region-growing algorithm first selects an initial point
In this process, the normal vectors of all points should be calculated in advance. The input to the following procedure is a depth image of pixels with a depth value of d. Let the pixel of interest be p. The vector normal to p is calculated from the three-dimensional positions of p and its neighbours. After calculating the positional average and covariance matrix from these points, the directions and lengths of three orthogonal axes are obtained by eigenvalue decomposition. The normal vector is the axis of the shortest length among the three axes. Thus, each pixel is assigned four variables, i.e., depth d, and the components of a normal vector
In the region-growing algorithm, pixels are connected if they satisfy the following rule:

where
An example of leg detection via this procedure is shown in the lower-left panel of Figure 8. Each coloured region indicates one cluster, and the legs are revealed as two long regions of contiguous clusters.
6.1.2. Estimating the Joints' Positions
The two leg regions extracted by the region-growing algorithm are obtained as a three-dimensional point cloud. The next step is to estimate two characteristic parts, i.e., the knee joint and the ankle. Both parts provide essential information for modifying the end-effector trajectory. First, a point cloud corresponding to a leg is divided into two sections by the kneecap, which is characterized by a large bend when the subject sits on a chair or at a bedside. The region-growing algorithm is applied to the point cloud with a smaller
Note that further division between the knee and toes is unstable because these parts are joined by a gradual curve. In addition, the angle made by the ankle joint depends on the situation and an individual's posture; thus, these regions will not be well modelled by a region-growing algorithm with a static threshold.
To overcome this problem, we use statistical human-body data [20]. The point cloud of a leg is divided into two parts by a second region growing as described above, with the kneecap regarded as the division point. The lower point cloud comprises the area between the shin and the toes. Here, the length proportion between the two parts, from the kneecap to the ankle and from the ankle to the toes, is assumed to be a human anatomical attribute and is retained as a constant. Similarly, the distance between the ankle joint and heel follows anatomical proportions. Consequently, we represent the leg model by three variables, as shown in Figure 9. Based on the leg dimensions of average men and women, we set

Three parameters to estimate the shape of a leg
6.2. End-effector Trajectory Generation
To dress the bottom-half of a subject, we must avoid failures such as snagging the legs on the cloth of trousers. Our approach defines the basic trajectory in advance, and modifies it to fit the point cloud representing the kneecap-to-toe region of the lower legs. In the modification step, 10 regularly spaced anchoring points are first extracted from the point cloud. The interval between the points is
Let

Waypoint generation. First, the two point lists
To prevent the leg parts from becoming entangled with the clothes, we must consider the positions of the kneecap and heel. Let
6.3. Dressing-failure Detection and Recovery
By combining clothing state estimation with waypoint-based trajectory generation, we can detect failures and recover proper actions. In practical dressing actions, the end-effectors track waypoints
Because a failed action also means that clothing must be disentangled, the failure can be resolved by repeating a past dressing action. This recovery process was validated in experiments using a real robot.
Aside from vision function, we also use the force sensors mounted on the robot's wrists. If a force sensor detects a force exceeding the predefined threshold while dressing, the action is regarded as a failure. However, the sensing plays a secondary role because it indicates that the subject may experience pain as a result of the pulled clothing. Ideally, dressing failures should be detected visually before the force reaches this level. Therefore, vision-based failure detection plays the primary role.
7. Experimental Assessment of Vision Function
7.1. Settings
A mannequin was sat on a horizontal board with a height of 700 mm. Image streams were captured by a camera placed 750 mm high and 1500 mm distant from the mannequin. Each image stream was VGA sized (640 pixels × 480 pixels) and captured at 30 fps. Under this set-up, a person dressed the mannequin in a pair of trousers.
Before the state-matching experiments, we captured six different image streams of successful dressing. To represent state transitions between successful dressing actions, each image stream was divided into four phases named No. 1 to No. 4 (the starting frames of the four phases are shown in Figure 11). Seven image streams of failed dressing states were also captured, and named No. 5 to No. 11. The database was constructed from feature descriptions based on the optical flows calculated from these 11 image streams.
Four phases of dressing the bottom-half of a subject
The purpose of this experiment was to evaluate whether or not the robot completed the dressing procedure. If the dressing succeeds, the state matching will proceed sequentially through phases 1–4. Otherwise, the type of failure is identified from phases 5–11 in the database.
7.2. Success-failure Classification and the Estimation of Failure Type
Figure 12 shows an example of state matching. The current state is consistently matched to the flows in the database (Figure 3 (6)). The main image corresponds to the current optical flow; the inset on the lower right corresponds to the matched features in the database. These images show a failure state in which both legs enter the same hole while the trousers were being pulled up.

Current state estimation
The effectiveness of the three feature descriptions was investigated in a second experiment. The results are summarized in Table 1. The test data in this experiment were 19 series of image streams. The second and third columns of Table 1 show the success-failure patterns of the input image streams and the matching results, respectively. The fourth column (headed Avg. score) shows the average similarity value of the matching results. The matching failed in two out of six successful trials, whereas all of the failed cases were correctly estimated as failures. However, failure-type estimation failed in four out of the 13 trials. Therefore, the overall success rate was 73 %.
Estimate state and calculate scores

A third experiment investigated the effectiveness of the three feature descriptions. Table 2 summarizes the results of several feature combinations. Each combination was tried four times. The ranges in the cells are the ranges of success rates. The success rate was much lower when combining only two feature types than when combining three features. This indicates that the three feature descriptions proposed in this paper have different expressive powers, and that all are needed for estimating the dressing behaviour.
Compare to trial without one feature

8. Experimental Results of Dressing Assistance
8.1. Settings
When evaluating the vision function, a subject (human or mannequin) was sat on a horizontal board with a height of 700 mm. Dressing was performed by a life-sized humanoid robot named HRP2-JSK [14], equipped with seven degrees of freedom (DoFs) in both arms, 2 DoFs in the torso and 7 DoFs in both legs. The clothing state was measured by a three-dimensional range camera, Xtion Pro Live, mounted on the head of the robot. Colour images and VGA-sized (640 pixels × 480 pixels) depth images were captured at 30 fps. Under this set-up, the robot dressed the subject in a pair of trousers. In this experiment, a desktop computer that was connected separately to the robot was used to perform all of the recognition and motion-generation processes. The performance of the computer was 2.4 GHz, with an 8-core CPU. In this condition, one dressing experiment took about 240 seconds. For one state-estimation process consisting of a dynamic graph cut, optical-flow detection, feature description and similarity calculation, two or three seconds were needed. The most time-consuming part was the optical-flow detection.
Figure 13 shows the three pairs of trousers used in these experiments. Item (A) is constructed from stretchable fabric, which exerts a high degree of inward friction during dressing. Item (B) is composed of inelastic fabric with a high degree of inward friction, and item (C) is constructed from stretchable fabric with a low degree of inward friction.

Three types of trousers used in dressing experiments
8.2. Results of Dressing the Bottom-half of a Subject Using a Life-sized Robot
Figures 14 and 15 show the images of one dressing experiment using the life-sized humanoid robot. As explained in Section 3, the dressing procedure was divided into four phases. The images in Figure 14, which illustrate these phases in sequence, are part of the images captured by the Xtion sensor and the state-estimation results. To the right of each image are the dressing phases ordered in a temporal sequence. The green-filled blue rectangles indicate successful present phases. In other instances, the dressing has failed. Throughout the experiment, the dressing procedure was temporarily classified as a failure because the trouser leg became entangled with the left toes (Figure 14, (5)). However, the dressing motion was retried based on the estimation result, and continued until the trousers were pulled up over the knees.

Online experiment

A dressing experiment using a life-sized humanoid robot. The procedure was: (i) insert both feet into the legs of trousers (Figures (1) to (4)), (ii) pull up the trousers until they are over the knees (Figures (4) to (6)), (iii) pull up a hanging-down hem on one side of the trousers (Figures (7) and (8)), (iv) pull up the other side of the hem (Figures (9) and (10)), (v) pull the trousers up over the hips (Figures (10) to (12)).
Dozens of similar experiments were performed with various pairs of trousers. The results are summarized in Table 3. Although the legs frequently became snagged in parts of the cloth, our sensory functions detected failure in almost all cases. After detection, the failure states were resolved by the recovery action described in Subsection 6.3. In these experiments, “success” was achieved when the robot pulled the trousers over the subject's knees. The success rate of 30 trials was 83 %.
The success rate of dressing the bottom-half of a subject

As shown in Table 3, the number of successes during the dressing procedure was rather low for item (A), which was constructed from highly stretchable fabric exerting a high degree of friction.
Because the optical flow was stably extracted from image streams, recognition performance was not so different for different trousers. On the other hand, the recovery action was impeded by the combination of elasticity and a high degree of inward friction. Despite the high number of recovery motions, the robot could not proceed with the dressing procedure.
9. Conclusions
In this paper, we proposed methods for dressing a person using an autonomous robot. We focused on the actions by which the robot can pull a pair of trousers along the subject's legs. These actions are frequently demanded by humans requiring dressing assistance and which are potentially automatable. To avoid injuring the subject's legs during dressing, the robot should be programmed with recognition functions, enabling it to determine the state of the manipulated clothing. We decided that dressing failures were best detected by vision sensing, and could be predicted from the behaviour of optical flows extracted from image streams. The recognition function was designed to estimate dressing success or failure. If a failure occurred, the type of failure was also specified. In experiments of practical dressing by a person, we verified that the success rate of the method was 73 %.
To demonstrate the applicability of the method, we implemented the dressing procedure using a life-sized humanoid robot. Estimating the shape of the legs from images captured by a three-dimensional range camera, we proposed a method of modifying the trajectory from the basic trajectory estimated from statistical human-body data. When programmed with the proposed methods, the robot performed the dressing of human-like subjects with trousers with a success rate of 83 %.
In future, we will refine our method to improve the success rate. For instance, feature descriptions using optical flow can be combined with 3D information. The state-estimation model might be improved from our deterministic model into probabilistic method; e.g., the Hidden Markov Model.
More constructive use of force sensors has the effect of sensitizing failure detection. For instance, feature description combining optical flow with force data should be studied. Because significant relationships between force data and optical-flow data are likely, the combination will improve the success rate and accuracy of failure detection and recovery. From another viewpoint, force data should be used actively. Because the robot manipulates a highly-deformable object, it is difficult to predict force data during clothing manipulation. However, the level of the force might be estimated from the results of image-based recognition. Since we defined some dressing phases using optical-flow information, this might help the estimation of force-sensor data. The reliability of such estimations enables us to generate an end-effector trajectory by using a feedback control scheme.
Based on these improvements, the effectiveness of our approach must also be verified further in other dressing tasks.
Footnotes
10. Acknowledgements
This work was partly supported by the JST PRESTO programme and JSPS KAKENHI Grant Number 26700024.