
Abstract
The multi-AUV hunting problem is one of the key issues in multi-robot system research. In order to hunt the target efficiently a new hunting algorithm based on a bio-inspired neural network has been proposed in this paper. Firstly, the AUV's working environment can be represented, based on the biological-inspired neural network model. There is one-to-one correspondence between each neuron in the neural network and the position of the grid map in the underwater environment. The activity values of biological neurons then guide the AUV's sailing path and finally the target is surrounded by AUVs. In addition, a method called negotiation is used to solve the AUV's allocation of hunting points. The simulation results show that the algorithm used in the paper can provide rapid and highly efficient path planning in the unknown environment with obstacles and non-obstacles.
Keywords
Introduction
An autonomous underwater vehicle (AUV) is a type of intelligent robot that can travel in the underwater environment without requiring input from an operator [1–2]. AUVs have been studied by many scientists and applied in a variety of tasks such as underwater rescue, detection, location, etc. Many achievements in single AUV research have been made. However, many complicated tasks nowadays go beyond the single AUV's capability. Multi-AUV systems, in recent years, have been studied in areas such as formation [3–4], localization [5], cooperative hunting [6–8], cooperation searching [9], path planning [10–11], task assignment and cooperation [12–15], due to their outstanding robustness and high efficiency of coordination and collaboration. Among the areas mentioned above, the multi-AUV hunting problem has attracted much attention, because it can be applied in military tasks and is a good verification of cooperation and coordination of a multi-AUV system.
Much research has been carried out recently on the multi-robot hunting issue and some approaches are proposed in this paper. The hunting algorithm can essentially be classified into two categories: centralized control methodology and distributed control methodology. The difference is whether or not there is a supervisor. Various methods have been proposed, which include behaviour based, virtual structure based, leader-follower, artificial potential based and graph theory based methods. Grinton [16] presented a mechanism of commitments and conventions to guide the multi-robots’ cooperation in a hunting task. Sauter [17] used a reinforcement learning method with animal behaviour to conduct research on the hunting problem. Cai [18] proposed an improved auction algorithm for multi-robot hunting cooperative behaviour.
However, all of the above articles concentrate on the known environment for a cooperative robot hunting task. In reality, the working environment for robots is often unknown. In order to deal with a multi-robot hunting task in the unknown environment, Nighot [19] proposed a hunting strategy with swarm intelligence for hunting robots to encircle the target. Feng [20] presented an input-output feedback linearization algorithm to calculate the velocity of hunting robots in order to execute a hunting task. Sheng [21] has proposed a method based on diffusion adaptation over networks to conduct research on intelligent predators hunting for schools of fish. However, the previous four papers did not consider map-building comprehensively and obstacle avoidance was not usually considered in the literature.
Recently, some researchers have approached the hunting process with simple obstacles. Yamaguchi [22] proposed a method based on making troop formations for enclosing the target and presented a smooth time-varying feedback control law for coordinating the motions of multi-robots. Pan [23] applied the improved reinforcement algorithm to the multi-robot hunting problem. However, in these studies the hunting target is often static and it is not fully consistent with the real environment.
To tackle the shortcomings discussed above, Ma [24] proposed a cooperative hunting strategy with dynamic alliance to chase a moving target. This method can shorten the completion time to some extent. Wang [25] proposed a new hunting method with new definition concepts of occupy and overlapping angle and finally calculated an optimized path for multi-robot hunting but the environment is too open and the initial location of the hunting robots is too close to the moving target. Next, Ni and Yang [26] proposed an algorithm based on a bio-inspired neural network model with formation strategy that was applied in a hunting task with good communication among several neurons; good coordination can be viewed during the whole hunting task. However, in the catching stage, the robots depend on the formation strategy and do not need the guidance of the neural network. Therefore, although there have been many approaches applied to the multi-robot hunting problem, the limitations in terms of coordination, robustness and effectiveness of a robot team mean that these methods cannot be fully applicable for a multi-AUV cooperative hunting problem in underwater circumstances.
This paper focuses on the situation in which the environment is unknown and the target is intelligent, with unpredictable and irregular motions. The multi-AUV hunting algorithm based on the bio-inspired neural network is presented. The hunting AUVs’ paths are guided through the bio-inspired neural network and the results show that it can achieve the desired hunting result efficiency.
This paper is organized as follows: Section 2 describes the map of the hunting process and four kinds of hunting final states are given. In Section 3, the bio-inspired neural network algorithm is designed. The strategy of path planning and the whole hunting process are described in detail. Simulations are conducted in Section 4 and Section 5 concludes the whole paper.
Problem Statement
In this paper, a cooperative hunting task of multi-AUV in an unknown environment is studied. The multi-AUV system has no information about the underwater environment. The hunting task will be accomplished when the target is encircled by hunting AUVs. The underwater environment model is presented by using a discrete grid map. The grid map divides the working condition into cells of the same size, while every cell has two states - obstacles and free space, as shown in Figure 1.
The two-dimension grid map is labelled as V. The space and the time of the hunting region is also discretized. Thus, the hunting area can be defined as a set of grid maps. The number of AUVs is denoted as

Two dimension map
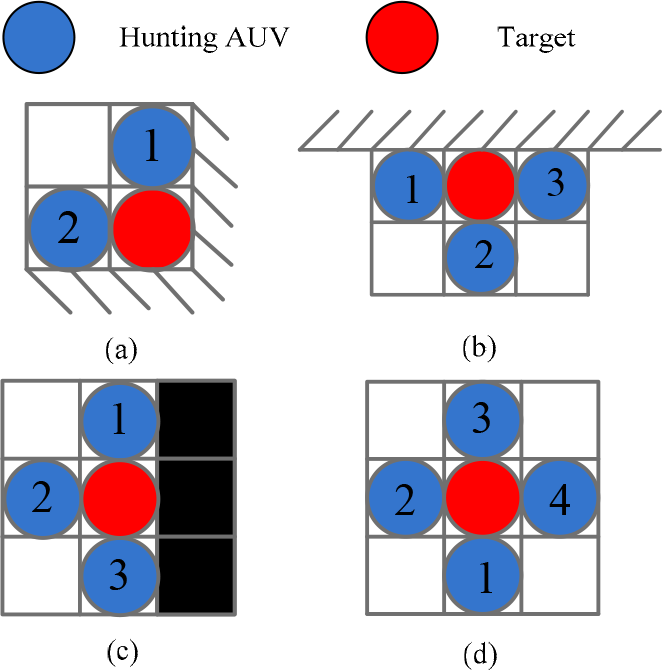
Target is hunted by AUVs in four conditions (a) Hunted state in corner (b) Hunted state in boundary (c) Hunted state with help of obstacles (d) Hunted state by four hunting AUVs
When the hunting process begins, the hunting AUVs will move towards the moving target. During the process, the hunting AUVs can avoid the obstacles and find a short path to catch the target. The target will judge whether there are any AUVs lying in the neighbouring cells. If so, then the target will try to modify its moving direction and run to the free space. Figure 2 shows the conditions where the target is successfully surrounded by hunting AUVs. The final hunting state can be divided into four situations, which are, respectively: the target surrounded by AUVs at a corner, at a boundary, with help of obstacles and without any help.
The neural network model, as a highly parallel distributed system, has shown its superiority in the mobile robot path planning and trajectory tracking research. On the whole, the study process is the essential part when a neural network is applied, but timeliness and efficiency cannot be guaranteed. The bio-inspired neural network model was proposed by Hodgkin and Huxley in 1952, by using a circuit element to describe the electric current of membrane [27]. Grossberg [28] summarized and improved this model into a “shunting model”, which is based on the Hodgkin-Huxley model. The bio-inspired neural network model was applied to complete coverage path planning by Yang and Luo [29]. Pichevar and Rouat applied the approach to solve the sound source segregation problem [30]. The bio-inspired network model applied in the multi-robot cooperative hunting area does not need any learning process and the external excitation and inhibition will lead the robot to select every step to reach the goal.
In his 2011 paper [26], Ni used the bio-inspired neural network model with a formation and dynamic alliance algorithm to chase targets. Unusually, in this paper, the bio-inspired neural network is directly used in an AUV hunting task without the assistance of any other algorithm. This means that the hunting process can be completed with the proposed bio-inspired neural network algorithm and the negotiation method, without a further synchronization method. The synchronization strategy will be considered in the further multi-AUV hunting research, in order to improve the hunting efficiency.
The hunting problem for AUVs and mobile robots is theoretically the same, so this work is a preliminary study for the multi-AUV hunting problem. In this paper, our starting point is to try to apply this method to the AUV system, which has not been considered in previous work. Unlike the mobile robot or an Unmanned Aerial Vehicle (UAV), due to the complicated underwater environment, the obstacles are assumed to be unknown and will be detected by underwater sensors, especially sonar, which is very different from mobile robots or UAVs. The work of underwater map building has been examined in the author's former work [31]; therefore in this paper only a simple conclusion is given as a fundamental part of the AUV hunting problem. Here, the target is assumed to be moving on a set path; when it detects the risk of hunting AUVs, it will move to avoid the hunting. In this paper, since studies have already been carried out on map building and localization, we have concentrated on the hunting process.
Bio-inspired Neural Network Algorithm
The “shunting model” proposed by Grossberg is shown in the following formulation:
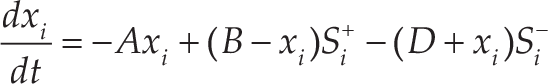
This function is called the shunting equation. In this equation, xi is the neural activity of the i-th neuron; A, B and D represent the passive decay rate and the upper and lower bounds of the neural activity respectively, which are nonnegative constants; S i + and S i − are the excitatory and inhibitory inputs to the neuron. In the hunting process, the hunting AUVs’ motions are guided by the dynamic landscape of the neural network. The excitatory input Si+ results from the target and its neighbouring AUVs and the input Si− only results from the obstacles. In this context, the dynamic of the i-th neuron in the neural network can be characterized by a shunting equation as

where k is the number of neural connections of the i-th neuron to its neighbouring neurons. The terms
The term [a]+ is a linear-above-threshold function defined as [a]+ = max{a, 0} similarly the term [a]− = min{-a, 0}. [Ii]+ and [Ii]− are the variables that represent the input to the i-th neuron from the target and obstacle, respectively. They are defined as

where E > > B, which is a very large positive constant. In equation (2), the term wij is defined as

where qk and ql are two vectors and | q k - q l | is the Euclidean distance between them. The function f(a) is a monotonically decreasing function, which is defined as

where μ and R n are positive constants. Obviously, the weight connection coefficients are symmetrical, that is, w ij = w ji . Figure 3 shows the neural network model in a 2-D environment [32].

2-D model of neural network
In this structure, each neuron is connected by adjacent neurons, which form the whole network for transmission of activity.
An AUV's moving path is guided by the activity of the neural network. Let us assume that an AUV's current position is k and the constant m represents the number of neighbouring neural cells. Thus, there are m selections for the AUV to move. Under the neural network guidance, the AUV's moving strategy can be followed as

where x k represents the activity value of neighbouring cells for the AUV's current position. m is the number of neighbouring cells. P c , P n and P p represent the AUV's current position, next position and previous position respectively. In the AUV's moving process, the neighbouring cell of maximum activity value will be chosen as the next position. Simultaneously, the activity value of the whole neural network will be refreshed.
On the basis of the mechanism of the bio-inspired neural network model in the multi-AUV hunting process, the target's motion is also limited by the control of the neuron's value. As mentioned above, the target is intelligent and the escape runaway choice for the target is random. To put it simply, the moving target will run to an open space with few obstacles or hunting AUVs. When the hunting AUVs block or impede its route, the escape direction will be immediately affected. If the hunting AUV occupies one of the grids around the target, the movement direction will be limited. When the surrounding grids are all occupied by hunting AUVs, the target will stop moving. Generally, the maximum speed of the moving target is less than that of the hunting AUV.
Hunting Process
When the hunting process begins, all the AUVs will pursue the moving target together. In order to show clear results of hunting, a matrix Trace (k × 2) is defined to memorize the position of the AUV for path planning. The k represents the number of hunting steps for each AUV. The hunting task of the AUVs is to move towards encircling the target in a few steps. The whole process of the hunting behaviour can be summarized with the following procedures:
Step 1: Initialize the whole activity values of cells to zero.
Step 2: Set the initial position of each AUV to the current location.
Step 3: AUV will find the next step by choosing the maximum activity value of eight neighbouring cells.
Step 4: Store the current AUV position to matrix Trace.
Step 5: Set the activity value of the cells that the AUV has travelled through to zero.
Step 6: Judge whether the current position is the neighbouring cell of the target. If it is, set the activity value of the current position to -E in order to prevent other AUVs from moving to the same cell by mistake; otherwise go to Step 3.
Method of negotiation
Step 7: If the target continues to move, the AUV will follow the target until the up, down, left and right positions of the target are occupied by hunting AUVs. Then it will stop moving.
The hunting process will show that the AUV can encircle the target until it cannot escape. The AUV will move towards the target directly and will avoid the various obstacles.
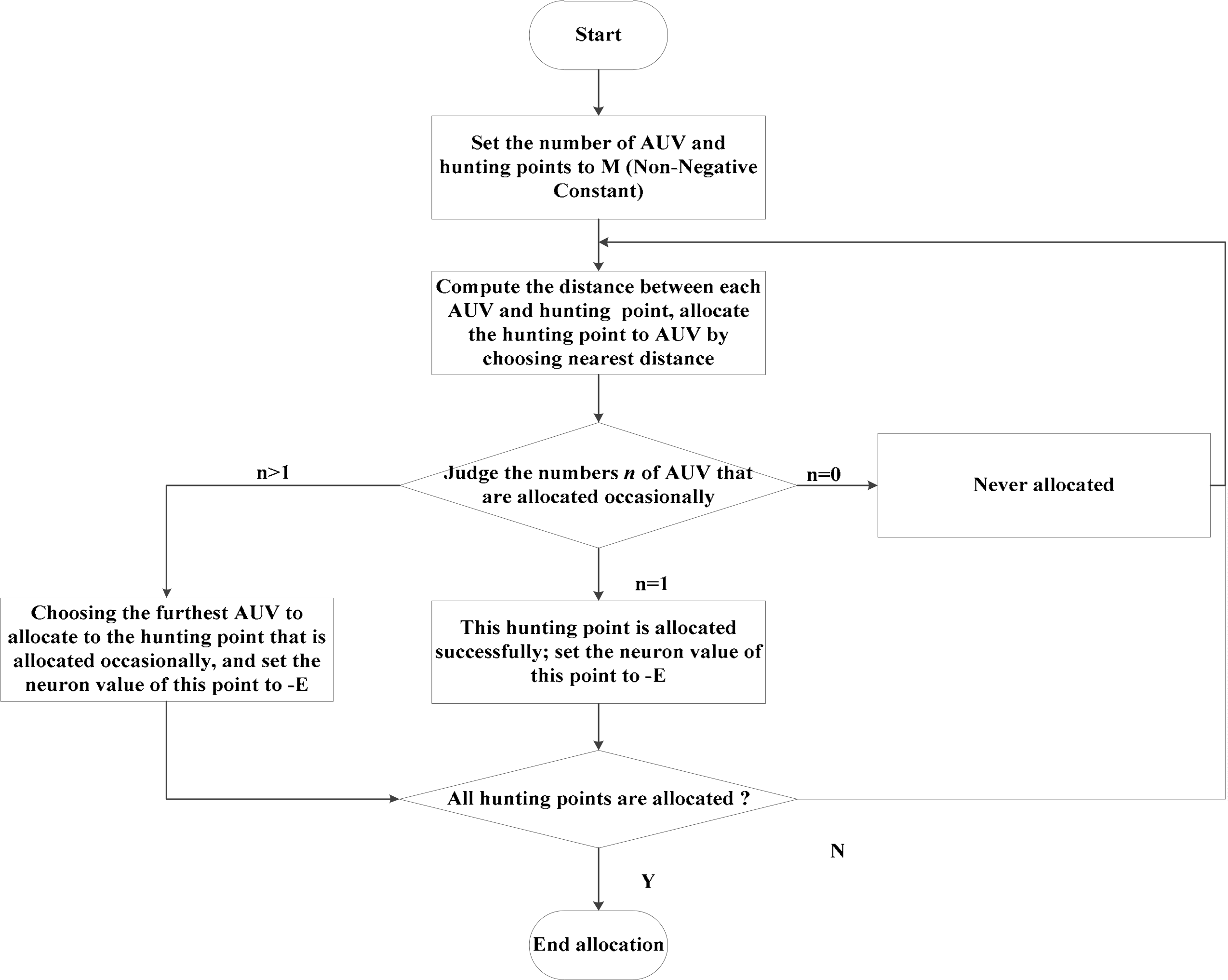
In the hunting process, due to the attraction of the maximum neuron value, the hunting AUVs will occupy the hunting points randomly. However, without a mechanism for allocating the hunting point for each AUV in balance, the effectiveness of the hunting task will be weakened. Thus, a method called negotiation is presented in this paper to solve the problem that is mentioned above. The whole method can be summarized as Figure 4.
Under the guidance of the negotiation method, the hunting points will be allocated by AUVs automatically; hence it can make the AUV finish the hunting task quickly and shorten an unnecessary sailing path. As shown in Figure 5, the four AUVs run to the moving target respectively and the four hunting points marked as 1 to 4 are allocated with the negotiation method. The AUV can then finish the hunting task successfully.
If the hunting AUVs are more than needed (4 AUVs shown in Figure 5), the task assignment can be conducted first. The task allocation can be given according to the distance and the AUVs that are not assigned a task will stand still. Some work on task allocation has been carried out by the authors in [33]. It will be a separate work, which needs further research.

The schematic diagram of the negotiation method
To demonstrate the feasibility and effectiveness of the proposed algorithm, some simulation experiments have been conducted. In this section, the simulation can be divided into two parts. Hunting with and without obstacles in an unknown environment is simulated and compared with another approach. In addition, the growth in activity value of each AUV will be displayed in a chart. The simulation environment used is Windows 7, Intel(R)Core(TM)2 Duo CPU E8400 3.00GHz, 4G memory. The compilation tool is MATLAB 2011a.
Simulation Design
In these experiments, a task is given for a team of AUVs PC = {P C 1 , P C 1 , … P C r } with only one target, Ev. The environment of the hunting area is a NS × NS = 20 × 20 grid map. The hunting task can be divided into two conditions: hunting without obstacles and with different shapes of obstacles. The boundaries of the area are known to the AUVs as well as to the target, while the environmental information of the whole area is unknown to both.
The number of AUVs is set at four and their movement is based on the bio-inspired neural network model in the sections above. The target is intelligent and moves randomly until it is surrounded by hunting AUVs. The speed of the hunting AUVs is set at 1 second / grid and the target speed is 4 second / grid. The parameters are set at A = 2, B = 1, D = 1, μ = 0.6, E = 100, R n = 2.
Hunting Simulation Experiment without Obstacles
The first simulation is conducted to test the cooperative hunting process without obstacles. For easy discussion, it is assumed that there are four hunting AUVs with only one target. The initial location of the target is (11,6). The hunting AUVs are PC1,PC2,PC3,PC4 and the initial positions of them are PC = {(1, 20), (1, 0), (20, 1), (20, 20)}, respectively. Figure 4(a) shows the initial locations and state of the hunting condition. Figure 6(b) shows the hunting process for the first seven steps. The target has already found the hunting AUVs moving towards it and it starts to escape from its initial location.
Figure 6(c) shows that in the final state of the hunting process, the moving target is surrounded by hunting AUVs in (11,9) and, through the hunting task, it is easy to see that the AUVs are moving directly to the target and do not collide with each other.
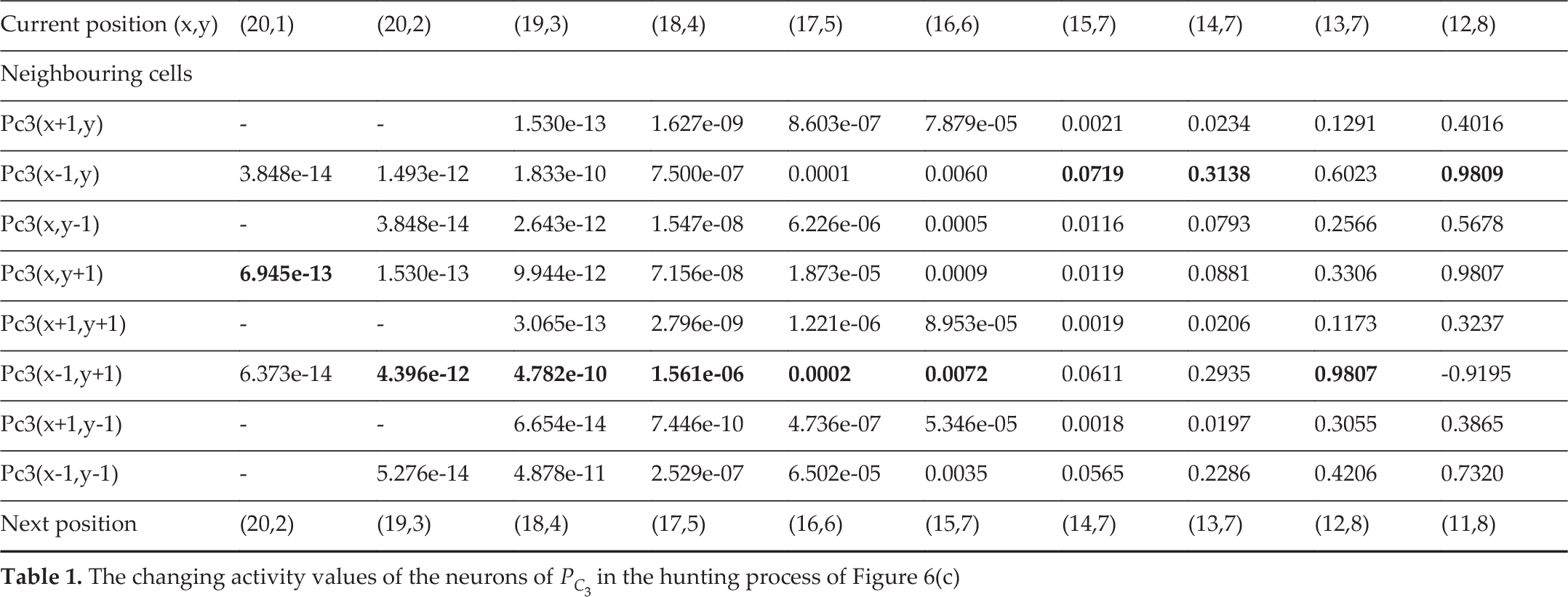
Table 1 lists the activity value of the neuron at each step in the hunting process of AUV PC3 under the circumstance with obstacles. The red data show the value corresponding to the next position that the AUV chooses. Obviously, the AUV selects the cell with the biggest activity value from the neighbouring eight cells.
In Table 1, in the initial stage of the hunting process, P C 3 is located in the position (20,1), which is adjacent to the corner and boundary, so the number of neighbouring neurons does not equal eight. P C 3 then chooses Pc3(x,y+1) to be the next position, corresponding to (20,2), because the activity value of the neuron in this position is 6.945e-13, which is the largest of the neighbouring cells.
After the AUV runs one step, the whole system of the neural network will be refreshed immediately; then P C 3 will judge whether the next position is the neighbouring cell of the target or not. Obviously, the answer is no. Therefore it chooses Pc3(x-1, y+1), which corresponds to (19,3). The activity value in that position is 4.396e-12, which is the largest of five neighbouring values. Similarly, P C 3 chooses the next position (18,4) by the same mechanism of path planning. Now the number of neurons is eight, because the position of P C 3 is not close to the boundary. With the same method of choosing the maximum activity value of neighbouring neurons, when P C 3 sails to (11,8), it finds that the position is next to the moving target and the other positions of neighbouring cells of the target are occupied by other AUVs. It then stops hunting and finishes its hunting task. The results shown in Table 1 correspond to the hunting process in Figure 6 and confirm that it is effective to apply the bio-inspired neural network algorithm to the multi-AUV hunting task.
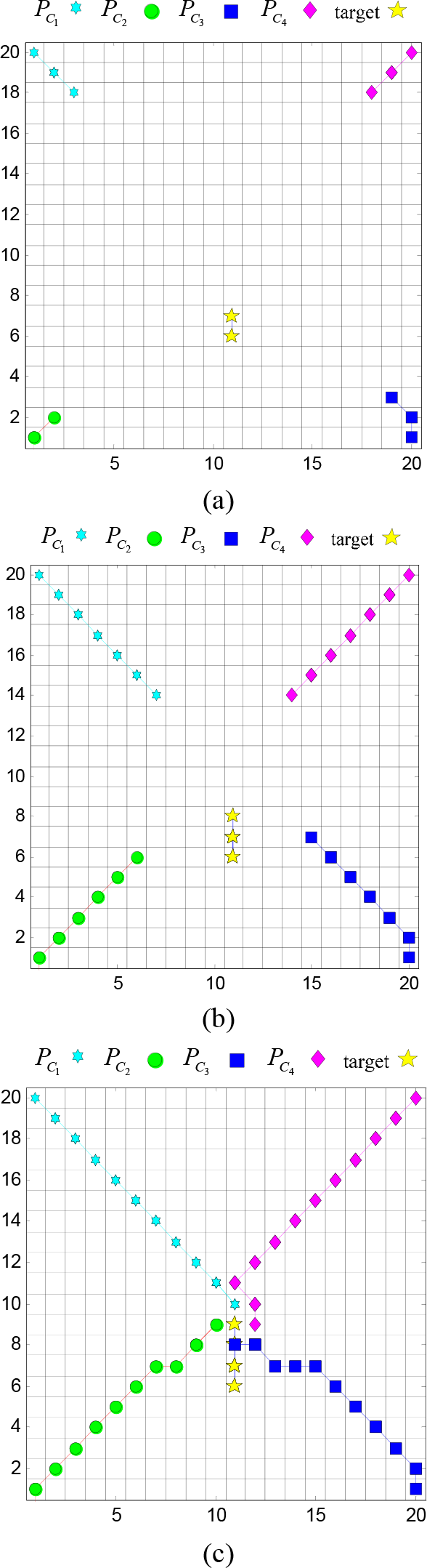
Hunting process of the simulation (a) initial locations and the state of hunting condition (b) hunting process - first seven steps (c) final locations with trajectories of AUVs
The changing activity values of the neurons of P C 3 in the hunting process of Figure 6(c)
To prove the robustness of the proposed approach, some obstacles are added to this part of the simulation. The shapes of the obstacles are varied, comprising U-shape, polygon-shape, square-shape and rectangle-shape, in order to increase the difficulty of the hunting task. In Figure 5, the yellow pentagram represents the target and the black blocks are the static obstacles in the simulation. The hunting AUVs are P C 1 , P C 2 , P C 3 , P C 4 , which still start moving from the location of P C = {(1, 20), (1, 0), (20, 1), (20, 20)} respectively. With the guidance of the neural network, the AUVs will move directly to the target and avoid the obstacles. Figure 7(a) shows the initial state of the hunting process. Figure 7(b) shows the hunting process of each AUV and moving target and Figure 7(c) shows the final state and the whole trajectories of the target and AUVs. Figure 7(d) shows that the AUVs can complete the hunting task with different shapes of obstacles.
Table 2 reflects the whole hunting process of one of the hunting AUVs (P C 3 ). The dynamic changing values of the neurons also show the mechanism of path planning for each hunting AUV. The sign “−” represents a cell that is out of boundary and whose activity value does not exist. The data that are marked in a red colour represent the maximum value of the neighbouring eight cells of the current position.
In order to further prove the robustness of the proposed approach, the hunting process with a wider U-shaped obstacle has been simulated in Figure 8. It can be clearly seen that when the AUV is inside a U-shaped obstacle and the target is on the other side, the hunting AUV can navigate back and move around the obstacle to reach the target successfully.
Comparison with Different Method
To further test the priority of the proposed method applied to the hunting process, this paper conducts a comparison with the artificial potential field method [34–35] applied in the hunting process. The potential fieldwork was proposed 15 years ago and has been applied in many areas. However, the application in a multi-agent system is still a new area, especially for the multi-AUV system, and a number of research papers on this topic are being published every year. In the artificial potential field method, a gravitational field to a target and a repulsive field to obstacles are built to work together, to lead the AUVs to move towards the target step by step. The direction of the hunting AUV is decided by a composition of forces, which include the gravitational pull from the target and the repulsion from the other hunting AUVs.
A brief description of the artificial potential field method can be summarized as follows: first, construct a distance function between the AUV and the target:

The generated gravitational field can then be given as:
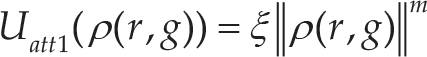
where m is a positive constant.
The attractive force of the target is:

The distance function between the AUVs can be given as:


Hunting task with obstacles (a) initial location (b) hunting process of first six steps (c) final locations with trajectories of AUVs (d) hunting with different types of obstacles

Hunting task with U-shaped obstacle
The repulsive force is generated between the hunting AUVs themselves:

The hunting AUVs will then be guided by the total forces of attraction and repulsion.
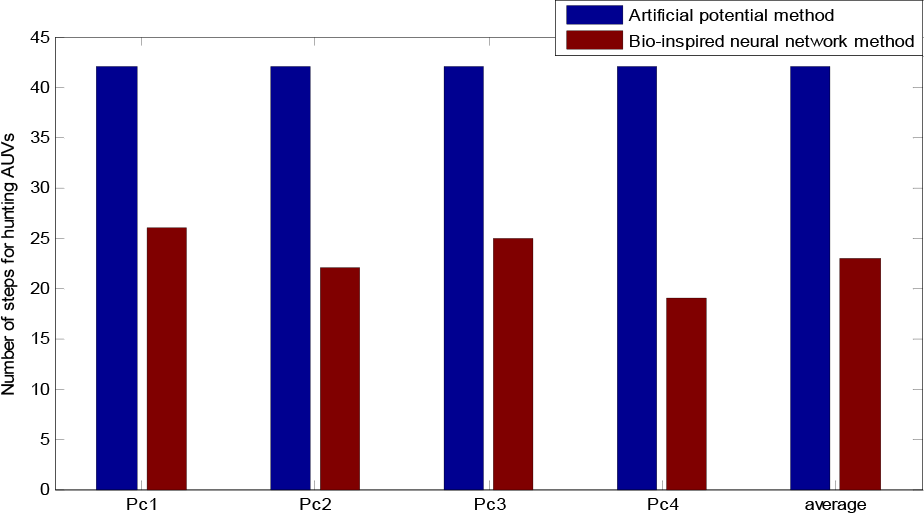
Figure 9 shows the simulation result of the artificial potential field method in a hunting experiment. Four AUVs labelled as {1,2,3,4} start from locations {(25,25), (1,25), (25,1),(1,1)} respectively and hunt the red moving target, which starts from (13,13) simultaneously. The target is finally caught in (13,24). Figure 10 shows the simulation result based on the method proposed in this paper. Four hunting AUVs start from locations {(25,25), (1,25),(25,1), (1,1)} respectively and the target escapes from (13,13), which is finally hunted in (13,25). The number of step for each AUV in the hunting process under the proposed method is shown in Figure 11. The result shows that the average number of steps for the hunting process is reduced by 45%. Therefore the method proposed in this paper applied to the hunting process is much more efficient.
The reason for the superior performance can be explained as follows: the potential field method is basically designed on the modelling of a gravitational field and a repulsive field. Different designs of the gravitational field and the repulsive field will affect the hunting performance, but cannot directly move to the target like the proposed bio-inspired neural network method. Furthermore, one important issue that has not been discussed is that the potential field method has a shortage of local minimization (called deadlock); hence, for the U-shaped obstacle, it may fall into the obstacle inside without any other strategy, while the bio-inspired neural network method can solve it very well, as shown in Figure 9.
The changing activity values of the neurons of P C 3 in the hunting process of Figure 6(c)

For the power consumption problem, since this work is based on the design of path planning, the power consumption can simply be in linear correlation with the hunting path length. From this point of view, it is easy to conclude that the bio-inspired neural network method is superior to potential fieldwork.
In order to further show the priority of the proposed method used in the hunting process, a chart describing the comparison of the two methods is shown in Table 3.
The comparison of step numbers between the two methods

In this section, some preliminary work on multi-AUV hunting in the three-dimensional (3-D) environment is introduced. The proposed hunting algorithm based on the bio-inspired neural network is extended to the 3-D case, while the basic idea is essentially the same. In the 3-D simulation experiment, the hunting map is also selected as the discretization grid map. Six AUVs are selected for the dynamic hunting of an escapee. It should be noted that the complex current situation in the actual three-dimensional environment is not considered.
In this simulation experiment, static obstacles are added to the 3-D map, as shown in Figure 12(a), where a blue cube represents an obstacle. The six AUVs are labelled as P C 1 , P C 2 , P C 3 , P C 4 , P C 5 , P C 6 and they start from the initial position {(1,1,0),(10,0,2),(10,10,10),(3,10,10),(1,10,0),(10,1,10)}. The AUVs approach the target according to the maximum neuron's activity selection mechanism and perform obstacle avoidance. The hunting task is finally completed at the point (5,5,5). It should be noted that when the target is surrounded by six hunting AUVs, the successful hunting state can be accomplished. Figure 12(b) shows the final state of successful hunting and the moving trajectory of each AUV. The target is rounded up by six AUVs, which are all in the red cube. In order to show the final state clearly, an enlarged view of the hunting AUVs and the target at the point of being caught is demonstrated in Figure 12(b).

Hunting process in artificial potential field method

Hunting process in method proposed in this paper
Hunting efficiency comparison between the two methods
Cooperative hunting by multi-AUVs in an unknown environment is investigated and a bio-inspired neural network is proposed for application to the whole hunting process. By choosing the maximum activity value of the neural network of neighbouring cells, the hunting AUV will select a direct path to the moving target and finish the hunting task. The proposed approach can deal with various situations automatically and catch the moving target effectively. In addition, it can deal with hunting tasks in the environment with different shapes of obstacles. The parameters in the hunting experiment are decided by real-world applications. However, from simulation results, it can be seen that sometimes there will be a collision between AUVs. This indicates that the cooperative and collaborative mechanism among AUV team members is not built properly. Thus, further study will continue to focus on how to avoid collision between hunting AUV team members and how to complete the hunting task in a 3-D environment under the proposed method. In addition, a further important problem that needs to be discussed is the ocean current effect in the underwater environment.

The multi-AUV hunting simulation experiment under static obstacles
Footnotes
6.
This project is supported by the National Natural Science Foundation of China (51279098, 51575336, 61503239), Creative Activity Plan for Science and Technology Commission of Shanghai (14JC1402800).