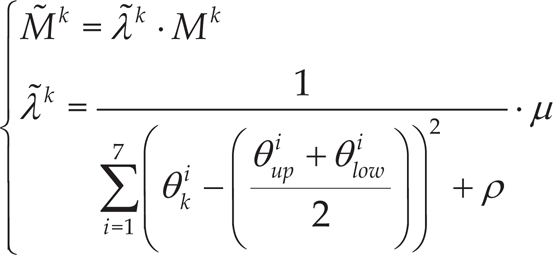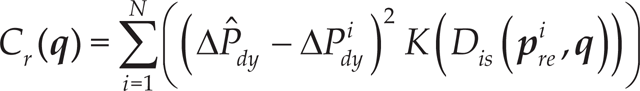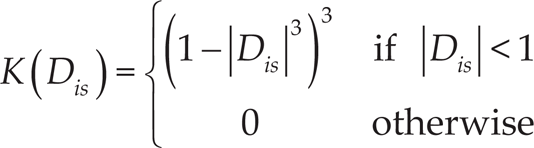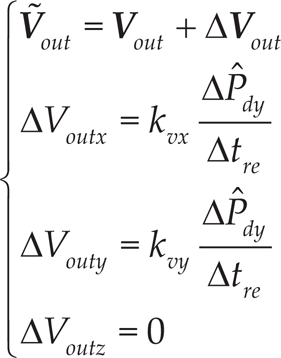Competitive robotic table tennis involves many topics such as smart ball returning strategy, precise motion control, etc. It remains a quite challenging task due to the unpredictable, uncooperative incoming ball and the requirement of a smart strategy to defeat the opponent. Designation and control of landing points is one basic aspect of ball returning strategies in competitive robotic table tennis because different landing points require the opponent to make different efforts to return the ball. In this paper, we present a method to designate desired landing points based on competitiveness level. We also propose a learning based landing point control approach to minimize the error of the actual landing points with respect to the designated landing points. The proposed methods have been verified through experiments on a humanoid table tennis robot.
Robotic table tennis is an excellent but challenging task. It involves many research topics such as visual servo, trajectory generation, ball returning strategy, etc. Robot table tennis can be divided into cooperative table tennis and competitive table tennis. Cooperative table tennis means that the ball is returned in a way such that the ball will be suitable for the opponent to hit. Here the word “suitable” means a robot player could return a ball without large changes of the joint angles. On the other hand, competitive table tennis targets at returning the ball in a way such that the ball will be unsuitable for the opponent to hit, which makes the opponent fail in the competition. Although cooperative playing is not difficult any more, competitive robotic table tennis remains quite challenging because most of the incoming ball is much faster and much further, and ball returning is more strategic and challenging. This paper addresses the landing point designation and control problems for competitive robotic table tennis.
Robot table tennis has attracted much attention since the early studies ([1, 2, 3]). Some studies have made many explorations on hardware design. Other studies have paid much attention to robust vision perception algorithms and generation of anthropomorphic ball hitting motions. During the last decades, the persistent interests in robotic table tennis studies still attracted researchers from all over the world. Acosta et al. [4] constructed a PC based low-cost ping-pong robot. Using an improved version of a learning method in paper [5], Miyazaki et al. [6, 7] presented a kind of robotic learning approach for robot table tennis. Studies on visual perception and prediction of table tennis balls were presented in [8,9,10]. Mulling and her group focused on anthropomorphic striking movement generation for a table tennis robot [11,12]. As far as humanoid table tennis robot is concerned, the balance maintenance was discussed in paper [13]. We have also developed a humanoid robot which is able to rally with human players or another robot player, and the best record of cooperative playing (robot vs robot) is more than 200 rounds [14,15,16,17,18,19,8]. Most of the proposed robots were designed for cooperative table tennis playing, and have achieved a great success. However, competitive robotic table tennis is not deeply investigated yet.
A landing point is the position where the returned ball lands on the opponent's table. It is important for competitive robotic table tennis. Since different landing points usually require the opponent players to make quite different efforts, choosing a specific landing point in each round is one of the most effective strategies to win the game. As shown in Figure 1, it will be more and more competitive when the landing point moves from A → B and B → C. A is most suitable for cooperative ball returning, while C is most suitable for competitive ball returning. Once we have designated a landing point, we should control the emergent velocity of the ball so as to return the ball to the desired landing point. Although designation and control of landing points is such a basic and important issue in competitive robotic table tennis, to our knowledge, however, only a tiny amount of the previous studies have addressed the problem. Paper [4] designed an expert control or game strategy planning approach for landing point determination of a ping-pong player prototype. However, this study did not discuss how to improve the accuracy of landing point control. Huang et al. [20] proposed an effective controller based on active and lazy learning for a ping-pong playing robot to return the incoming ball to a desired position. A recent study [21], from a biological viewpoint, modelled human strategies in table tennis playing using inverse reinforcement learning and provided discussions on some relevant features, such as landing point of the ball and velocity of the ball which are not ignorable in ball returning. In order to explore the basic issues of competitive robotic table tennis, a method to designate landing points for ball returning, and a learning control method to reduce errors between the actual and desired landing points will be presented in this paper. We will prove that our approach is effective for competitive robot table tennis.
Different landing points during robotic table tennis playing
The rest of the paper is organized as follows. In Section 2, an optimized waiting posture is introduced to maximize the manipulability of a robot when it is waiting for an incoming ball. A landing point designation method for competitive ball returning is given in Section 3. Section 4 proposes the landing point error reduction control method to return the ball to the desired landing point. After the proposed methods are verified through experiments on a humanoid robot in Section 5, the paper is concluded finally in Section 6.
Waiting posture optimization
A waiting posture is an state of a robotic arm in the waiting stage [22, 23] when the robot is waiting for the opponent to return a ball back. The waiting posture should be optimized so that the robot could return a ball with shortest distance and least efforts in average. This section proposes a method to choose an optimal waiting posture using manipulability indexes and joint limits.
In the waiting stage, human or robot players usually place a racket with “comfortable” joint configurations so that the arm consumes only a little energy and is convenient to move the racket. Especially, this configuration is called a waiting posture of a robot. In order to maximize the quick response capability to the incoming ball, the manipulability index [24] can be used to optimize the waiting posture of a robot. Let be the kth joint angle configuration of the 7-Dof (Degree of freedom) robotic arm of our humanoid robot, given the upper and lower limits of these joint angles, the kth manipulability Mk with respect to the kth joint configuration, can be calculated using , where Jk and (Jk)T are the Jacobian and the transpose of the Jacobian of the kth joint configuration. The optimal waiting posture for the robot is determined by the configuration of joints which maximizes the manipulability Mk.
On the other hand, joint angle limits and collision avoidance constraints should also be taken into consideration. So the extended manipulability, or the manipulability penalized by the joint angle limits and collision conditions [25], is used instead. The extended manipulability can be calculated by the augmented Jacobian , where L k and Ok are joint limit penalization matrix and collision penalization matrix of the kth joint configuration.
In our application, the workspace is fairly free and so the collision constraints is ignored. For simplification, the manipulability can be updated as
Where is the updated manipulability considering joint angle limits, is the evaluating factor of the joint limits on manipulability, is the ith joint angle of the kth configuration, and are the ith upper and lower joint angle limits, μ is an adjustable coefficient, and ρ >0 is an adjustable coefficient with small norm. When any joint angle is close to its limits, i.e. or , will be penalized.
Figure 2 illustrates the exemplified manipulability measurement of each arm configuration in the chosen workspace. The workspace is defined under the shoulder frame. An arm configuration is formed by the value of all the joint angles, . All the joint configurations of the robot have a common shoulder position with respect to the table tennis table. (The table's position, or the origin of frame Ow1XYZ in Figure 5, is [−2.963m,-0.325m,-0.765m]T under the shoulder coordinate frame.) The upper and lower limits of each joint angle can be given to choose the workspace where the optimized waiting posture will be produced. The upper limits of the joint angles are (60°,-30°,100°,100°,100°,10°,45°). The lower limits of the joint angles are (30°,-60°,80°,60°,80°,-10°,25°). The step (interval) of the optimization procedure is set as 5° for each joint for simplification. By calculation, the optimized waiting posture without joint limits is at the arm configuration of (55°,-60°,100°,75°,80°,10°,25°). The optimized waiting posture with joint limits is at the arm configuration of (45° −60°,90°,80°,100°,-10°,35°).
Manipulability with different joint configurations. For each end-effector position, the optimal manipulability index based on the joint configuration space is calculated.
Designation of Landing points
The ball returning strategy is the way the robot returns the ball to the opponent's court with the aim of defeating the opponent. The desired position where the ball will landing on the opponent's court, which is called a landing point, is one of the key factors of the ball returning strategy. Actually, the position of the landing point with respect to the opponent's racket has a great impact on the difficulty of returning the ball back. This section will focus on the evaluation of the competitiveness of an arbitrary landing point and the designation of landing points in each round with a given competitiveness level.
Competitiveness index: evaluation of the competitiveness level of a landing point
In order to evaluate the competitiveness of an arbitrary landing point, we presents competitiveness index based on the position of the landing point.
We use Cid as an index to describe the competitiveness of an incoming ball. A larger possibility for competitive playing of a designated landing point leads to a larger competitiveness index Cid. In order to obtain the competitiveness of an arbitrary landing point on the opponent's table, we introduce a polyhedron to illustrate our method in detail. In Figure 3, all the points are under the shoulder coordinate frame with Os as its origin. The robot is in the waiting stage with elbow pose Pe and racket pose P1. In the figure, we have a polyhedron POABCD. The polygon ABCD on the opponent's table represents the potential landing area which is obtained by experimental trials. A smallest polygon ABCD that contains most of the experimental samples will be chosen as the potential landing area. Inside the polygon ABCD, there is a landing point POO which is most suitable for the player to return the incoming ball. This landing point has the largest possibility for cooperative playing and the smallest possibility for competitive playing. If the ball lands outwards to the points in the boundary lines, e.g. the lines AB, BC, CD and DA of the polygon ABCD, the possibility for cooperative playing will decrease and the possibility for competitive playing will increase. The arbitrary point PO of the polyhedron POABCD is on the top of POO. We should point out that the height of the point PO represents a highest cooperative level or a lowest competitive level. The points' height on the surface of the polyhedron (other than polygon ABCD) relative with the height of PO is meaningful. But the absolute height of these points, including PO, has no meaning at all. For each point in the polygon ABCD, there will be a corresponding point, which has the same Y and Z coordinate value, on the surface of the polyhedron POABCD. Actually, the corresponding point is the inverse projection of that point along X axis. The height of the corresponding point could be used to calculate the competitive level. We define f as the function that maps the points in the surfaces POAB, POBC, POCD, and PODA to their vertical projective points in the polygon ABCD along the X axis, and f−1 as the inverse mapping. That is to say, f(PO)→POO, and f−1(POO)→PO. Then, we define the function x that denotes the x component of a point. A simple way to express Cid is
Landing point planning of the returning ball
Where Parb is a potential landing point in the polygon ABCD, F is a bounded function. One possible form of F is
Note that the arbitrary PO is located above the table, which means that X(PO)>X(A).
Given any landing point in the polygon ABCD, the competitiveness index Cid can be obtained according to Equation (2) and (3). Cid will have a range of 1/e<Cid<1.
Landing point designation based on competitiveness index
Given an arbitrary landing point P, we can calculate its competitiveness level according to Equation (2). On the other hand, given a competitiveness value C, we should also designate a landing point P satisfying Cid = C.
However, there are many landing points sharing the same competitiveness value. Actually, the points whose inverse projective points have the same height on the surface of the polyhedron POABCD excluding the polygon ABCD have the same competitiveness value. For example, In Figure 3, points aa, bb, cc, dd are in the polygon ABCD, points a, b, c and d are inverse projective points of aa, bb, cc and dd. Points in the lines ab, be, cd, da are inverse projection along X axis of the points in the lines aabb, bbcc, ccdd, and ddaa. a, b, c, d are points in the lines POA, POB, POC, and POD. ab, bc, cd, and da are lines in the surfaces POAB, POBC, POCD and PODA. The points in the polygon abcd have the same height, e.g., X(b). It is obvious that points in the lines of aabb, bbcc, ccdd, ddaa, produce the same competitiveness index F(X(b)) = C.
In order to remove ambiguity, we can choose a point in lines aabb, bbcc, ccdd, and ddaa that maximizes the distance to the point POO as the landing point corresponding to the competitiveness level C. So the procedures for designating the landing point with a given competitiveness index C are summarized as below.
Find the x value that produces the expected competitiveness index C using the Equation (2) and (3).
Find the original candidate points in the polyhedron POABCD that share the same x value, e.g., we will obtain points in the lines ab, bc, cd, and da.
Calculate the candidate landing points by projection of the original candidate points using f function, e.g., we will obtain points in the lines aabb, bbcc, ccdd, and ddaa.
Choose the landing point that has the maximal distance to POO as the optimized landing point. If there are several landing points meeting this requirement, the landing point that has the maximal distance to the end-effector's waiting position is chosen as the optimized landing point. If there are still many landing points meeting the second requirement, randomly choose a point from them as the optimized landing point.
Learning based landing point control
Once we have got an optimized landing point according to the competitiveness index C, we should calculate the emergent velocity command of the returning ball. Due to the perception error, the motion error and the system error, the actual landing point is not the same as the desired landing point. This section presents a learning based landing point control method to adjust the velocity command of the returning ball so as to minimize the error between the desired landing point and the actual landing point.
The structure of the learning method
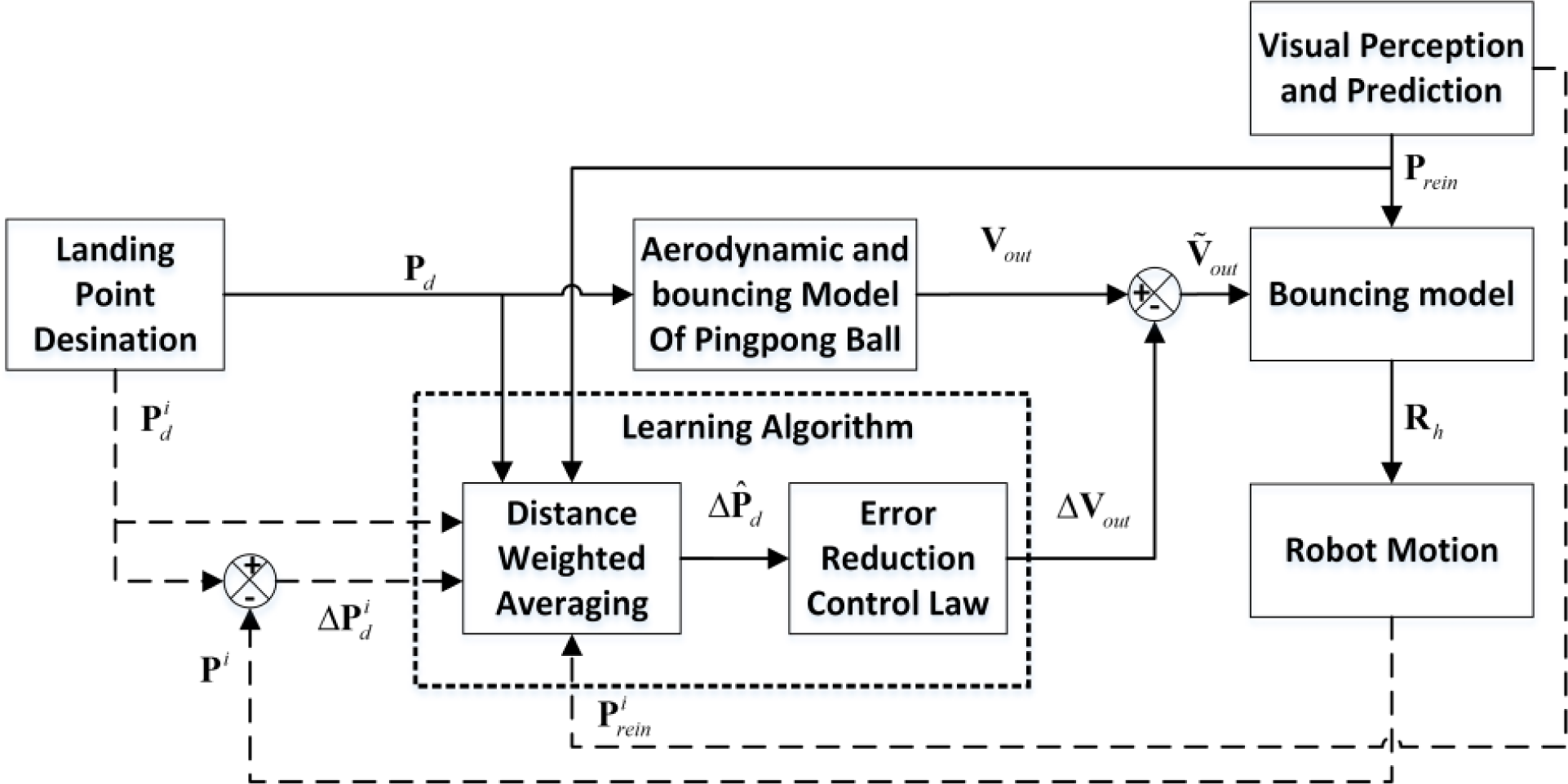
Figure 4 illustrates the structure of our learning based landing point control method. Pd = [0,Pdy,Pdz]T is the desired landing point. P is the actual landing point. ΔPd is the landing error. is the weighted landing error using Distance Weighted Averaging [26]. Vout =[Voutx,Vouty,Voutz]T is the desired velocity command of the returning ball just after ball-racket impact. ΔVout =[ΔVoutx,ΔVouty,ΔVoutz]T is the compensative delta velocity command of the returning ball obtained by the learning based landing point control method. is the adjusted velocity command of the returning ball. Prein=[Pinx,Pinz,Vinx,Viny,Vinz]T is the predicted position and velocity of the incoming ball just before ball-racket impact. Here Piny is neglected because it is always of the value yh, which means that position and velocity of the incoming ball at the plane y = yh is predicted. is the velocity and attitude of the racket when the incoming ball is returned. In the figure, the data with a top-right superscript i means that they are obtained off-line WITHOUT a learning method.
Structure of the learning based landing point control method. The dashed arrows mean that the data with a top-right superscript i is the off-line data obtained WITHOUT a learning method. The solid arrows mean that the modules are running on-line WITH the learning method.
Given a desired landing point Pd, the returning velocity command Vout of the ball can be derived by the aerodynamic model and the bouncing model of the ball [8,12] or by the mapping method [6, 7]. However, due to the aerodynamic model [8] errors, the bouncing model [8] errors, robot motion errors and perception errors, the returning velocity command Vout itself is not enough to return the ball precisely without compensation. An overall system error should be compensated to improve the landing point control precision. In this paper, a delta velocity command of the returning ball ΔVout, which is optimized by our learning based control method, is added to the returning velocity command Vout to minimize the error between the actual land points and the desired landing points. They are applied to obtain the compensative velocity command. Then, the desired racket motion Rh is derived based on the ball-racket bouncing model [8], the incident velocity Vin=[Vinx,Viny,Vinz]T and the emergent velocity command . Finally, once Rh is known, motion planing and servoing of the robot arm could be carried out to return the incoming ball.
The learning method is composed of a Distance Weighted Averaging method [26] and an error reduction control law. In the off-line stage, The robot returns the ball without the learning method. The data with a top-right superscript is saved. In the on-line stage, the learning method uses the off-line data and current designated landing point command to estimate a potential landing error based on Distance Weighted Averaging, and then an error reduction control law is applied to generate the compensative the emergent velocity command ΔVout. This command is added to the original Vout to reduce the landing point error.
Learning based landing point control
The learning method is to optimize the current compensative delta velocity ΔVout to minimize the potential error between the designated landing point and the future landing point based on historic ball returning records.
Estimation of landing point errors
Considering that a desired landing point is variable in each ball returning round, the potential landing error (the error between the designated landing point and the future landing point in the current round) is estimated in advance, and a compensative delta velocity ΔVout is optimized to reduce this potential landing error.
For simplification, the error estimation in the Y axis is analyzed in detail. Suppose that when the ith incoming ball arrives at the predefined hitting plane y = yh (yh is constant, and the impact of the ball and racket occurs in the hitting plane), the detected position and velocity vector is . Under this condition, the desired landing point will lead to error . We define as the ith group of measured data, where . N groups of measured data (N should be greater than 100.) with many different landing points are collected and employed to estimate the error using Distance Weighted Averaging [27, 26, 28], if the information of the new incoming ball and the desired landing point is given. Here, Distance Weighted Averaging, the key elements of which were presented in paper [26], is not a new learning method, but it is first applied in the challenging competitive robotic table tennis.
The cost function Cr(q) weighting the discrepancy between the estimated error and the actual error resulted from each group of the measured historic data is expressed as
Where K(·) is the weighting function and is the Euclidean distance from q to . In fact, the estimation is obtained through memory-based learning method, and a high relevance is given to the nearby measured data.
The estimation of ΔPdy should minimize the cost Cr(q), and this estimation is derived by solving the function .
Since each component of q or may play a different role in determining the error, i.e., the detected positions and velocities of the incoming ball and the desired landing point contribute to error occurrence with varying degrees, a diagonally weighted Euclidean distance is chosen.
where nj is the scaling factor for the jth component and N is the diagonal matrix with Njj=nj.
Although there are many different kernel functions available, we choose the Tricube kernel [28] (see (7)) because this kernel has a bounded extent, continuous first-order and second-order derivatives, which ensures continuous first-order and second-order derivatives of the estimation.
Error reduction control Law
So, the landing error can be reduced by compensating the velocity command of the returning ball using the following equation
Where is the compensated returning ball velocity command with error reduction method, kvy and kvx are adjustable coefficients, Δtre is the time of the returning ball required to land on the table, and the time can be calculated in advance.
Experiments
In order to verify our proposed method for competitive table tennis playing, the humanoid robot BHR-5[15] is used as the table tennis robot. The humanoid table tennis system is illustrated in Figure 5, where P is the racket fixed on the robot (under the shoulder coordinate frame OsXYZ), CA and CB are cameras used to detect the trajectories of the ball from the opponent to the robot (under the coordinate frame Ow1XYZ) and CC and CD are cameras used to detect the trajectories of the ball returned by the robot (under the coordinate frame Ow2XYZ). All the cameras are connected to a PC, which communicates with the robot using CAN-Open and WIFI and produces Prein and the actual landing point information for the robot.
System of the robotic table tennis playing
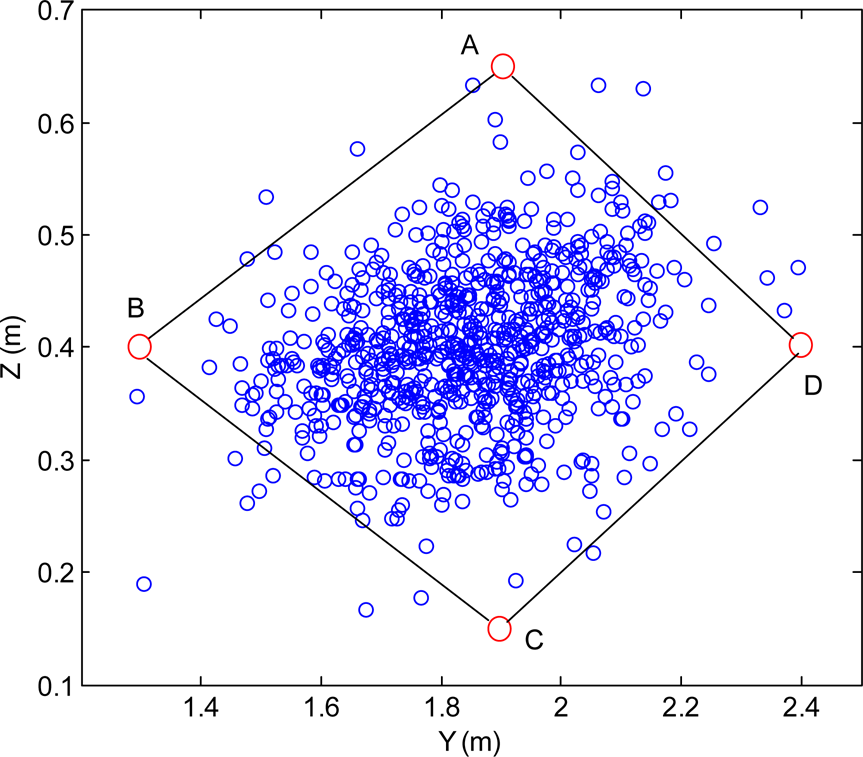
To determine the potential region of the landing points, more than 1000 rounds of ball playing have been tried. The distribution of the landing points under Ow2XYZ is shown in Figure 6. We will find a polygon ABCD that contains more than 97 percent of the experimental samples while keeping a maximal landing point density. The approximated boundary points for the region are A = [0m,1.9m,0.65m]T, B=[0m,1.3m,0.4m]T, C=[0m,1.9m,0.15m]T and D=[0m,2.4m,0.4m]T. In the table tennis playing experiments, the point [0m,1.9m,0.4m]T is found most suitable for the opponent player to hit the ball, and this point is set as POO. (The point POO may be different in real applications when the robot and the opponent stands in different places.) In the experiments, X(PO) is set as 0.6, and the landing point position can be derived once the competitiveness index is given. The competitiveness indexes are given as , , and , which correspond to the desired landing points of [0m,1.7m,0.4m]T, [0m,1.65m,0.4m]T, [0m,1.6m,0.4m]T, and [0m,1.55m,0.4m]T under frame Ow2XYZ, are used for experiments. Here we only presents experimental results with index in detail. The error estimation and landing point control results in Y axis are presented for simplification.
Potential landing point region with 1000 landing points
Firstly, we record the results of a human player rallies with the robot without landing point control. Figure 7 shows that the actual landing points distribute around the desired position for the designated Cid. The mathematical average of the actual landing points in the Y axis is 1.8827m, and the standard deviation of the landing points is 0.148m. The average error without landing point control is 0.2827m.
Landing point distribution without error control
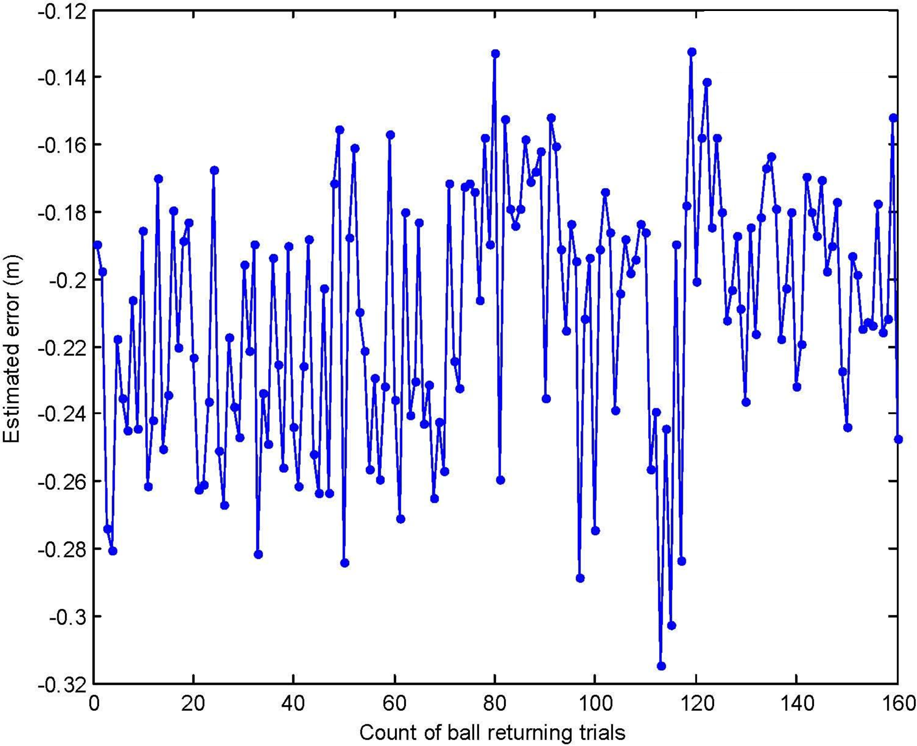
Secondly, error estimation is carried out to obtain landing point error. Figure 8 and Figure 9 illustrate the estimated error of the two groups of ball playing data between a human player and the robot.
Estimated error for landing point control in Y axis
Estimated error for landing point control in Y and X axes
Thirdly, after error estimation results have been obtained, the landing point control method is applied to the robot for competitive table tennis playing. In the first group of ball playing experiments (with the error estimation in Figure 8), the error reduction control in Y axis is applied. The experimental results in Figure 10 show that the mathematical average in Y axis of the landing points in Figure 10 is 1.7795m, and the standard deviation in Y axis is 0.1304m. We can see that the average is 0.1032m less than that in Figure 7, which means that the landing point control method is effective in reducing landing error.
Landing points distribution when error control in Y axis is used
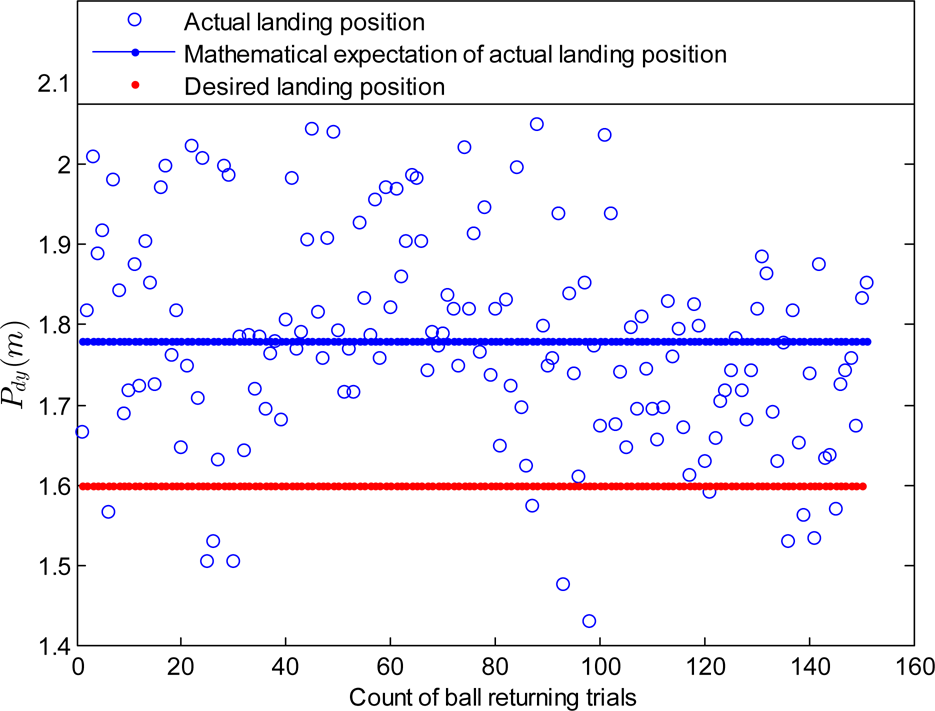
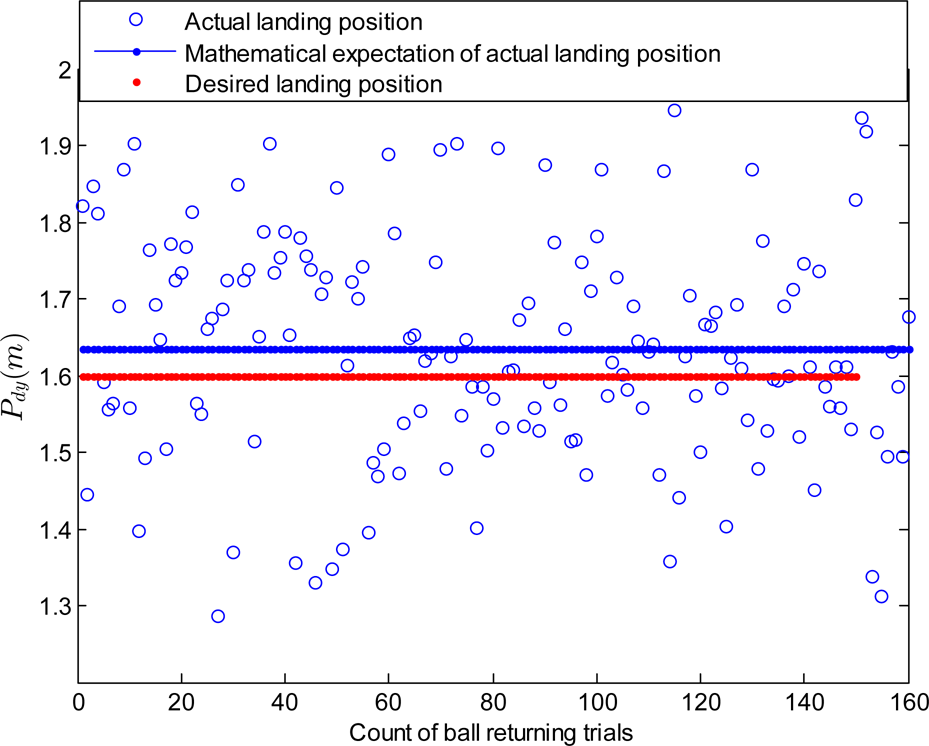
Fourthly, it is clearly that landing point control in Y axis only is not enough to land the ball with a small error. This can be attributed partly that there is a limit for the error reduction control method along each axis. Considering that the velocity Voutx also exerts effects on the flying distance of the returning ball, it can not be neglected in the velocity compensation procedure. In the second group of the ball playing experiments (with the error estimation in Figure 9), ΔVoutx is generated to reduce the landing error of the returning ball. Figure 11 illustrates the actual landing point positions after the error reduction based landing point control in both Y and X axes is used. The results show that the mathematical average of the landing points of the returning ball is 1.6338m, and the standard deviation is 0.1446m. We can see that the average of the landing points has approached the desired position 1.6m with an error of 0.0338m, which is much smaller than the error 0.2827m when there is no landing point control.
Landing points distribution when error control in Y and X axes is used
Through the experiments, we can see that our methods are effective in reducing the average error between the desired landing points and the actual landing points. However, we should also point out that our method has paid no attention to reducing the standard deviation.
Conclusion
This paper has discussed two basic but important issues for competitive table tennis playing, including designation of a landing point and precise landing point control. The work can be summarized as follows.
A landing point designation method is proposed to decide the various desired position of the returning ball according to an expected competitiveness index.
A learning based landing point error control method using the historic playing records is proposed to reduce the error between the actual and desired landing points of the returned balls.
Experiments on the physical humanoid robot have demonstrated the effectiveness of the proposed methods.
Footnotes
7.
This work was supported by the fundamental research fund of Beijing Institute of Technology under Grant 20140242014, the National High Technology Research and Development Program under Grant 2015AA042305, the National Natural Science Foundation of China under Grant No. 61273348, 61375103, 61320106012, and the Programme of Introducing Talents of Discipline to Universities under Grant No. B08043.
References
1.
BillingsleyJ (1983) Robot ping pong, Practical Computing. Cambridge: MIT press.
2.
AnderssonRL (1989) Aggressive trajectory generator for a robot ping-pong player. IEEE Control System Magazine.9:15–21.
3.
FasslerHBeyerHA, and WenJT (1990) A robot ping pong player: optimized mechanics, high performance 3d vision, and intelligent sensor control. Robotersysteme.6:161–170.
4.
AcostaLRodrigoJJMendezJA. (2003) Ping-pong player prototype: a PC-based, low-cost, ping-pong robot. IEEE Robotics and Automation Magazine.10:44–52.
5.
KawamuraSMiyazakiFArimotoS (1988) Realization of robot motion based on a learning method. IEEE Transactions on Systems, Man and Cybernetics.18:126–134.
6.
MatsushimaMHashimotoTTakeuchiM. (2005) A learning approach to robotic table tennis. IEEE Transactions on Robotics.21:767–771.
7.
MiyazakiFMatsushimaM, and TakeuchiM (2006) Learning to dynamically manipulate: a table tennis robot controls a ball and rallies with a human being. Advances in Robot Control. Heidelberg: Springer, pp. 317–341.
8.
ChenXTianYHuangQ. (2010) Dynamic model based ball trajectory prediction for a robot ping-pong player. Proceedings of the 2010 IEEE International Conference on Robotics and Biomimetics. 2010 Dec 14–18; Tianjin, China. New York: IEEE. pp. 603–608.
9.
ZhangZXuD, and TanM (2010) Visual measurement and prediction of ball trajectory for table tennis robot. IEEE Transactions on Instrumentation and Measurement.59:3195–3205.
10.
ZhangYWeiWYuD. (2011) A tracking and predicting scheme for ping pong robot. Journal of Zhengjiang University-Science C.12:110–115.
11.
KoberJMullingKKromerO. (2014) Movement templates for learning of hitting and batting. Learning Motor Skills.97:69–82.
12.
MullingKKoberJ, and PetersJ (2011) A biomimetic approach to robot table tennis. Adaptive Behavior.19:359–376.
13.
XiongRSunYZhuQ. (2012) Impedance control and its effects on a humanoid robot playing table tennis. International Journal of Advanced Robotic Systems.9:1–11.
14.
ChenXHuangQWanW. (2015) A robust vision module for humanoid robotic ping-pong game. International Journal of Advanced Robotic Systems.12:1–14.
15.
YuZHuangQMaG. (2014) Design and Development of the Humanoid Robot BHR-5. Advances in Mechanical Engineering.6:1–11.
16.
YuZHuangQChenX. (2014) Design of a Redundant Manipulator for Playing Table Tennis towards Human-Like Stroke Patterns. Advances in Mechanical Engineering.6:1–11.
17.
YuZLiuYHuangQ. (2013) Design of a humanoid ping-pong player robot with redundant Joints. Proceedings of the IEEE International Conference on Robotics and Biomimetics. 2013 Dec 12–14; ShenZhen, China. New York: IEEE. pp. 911–916.
18.
YuZHuangQChenX. (2011) System design of an Anthropomorphic arm robot for dynamic interaction task. Proceedings of the Chinese Control and Decision Conference. 2011 May 23–25; Mianyang, China. New York: IEEE. pp. 4204–209.
19.
ChenXHuangQZhangW. (2011) Ping-pong trajectory perception and prediction by a PC based High speed four-camera vision system. The 9th World Congress on Intelligent Control and Automation. 2011 June 21–25; Taipei, China. New York: IEEE, pp.1087–1092.
20.
HuangYLXuDTanM. (2013) Adding active learning to LWR for ping-pong playing robot. IEEE Transactions on Control System Technology.21:1489–1494.
21.
MullingKBoulariasAMohlerB. (2014) Learning strategies in table tennis using inverse reinforcement learning. Biological Cybernetics.108:603–619.
22.
RamanantsoaM, and DureyA (1994) Towards a stroke construction model. International Journal of Table Tennis Science.2:97–114.
23.
MullingKKoberJ, and PetersJ (2010) A biomimetic approach to robot table tennis. Proceedings of the 2010 IEEE International Conference on Intelligent Robots and Systems. 2010 Oct 18–22; Taipei, China. New York: IEEE. pp. 1921–1926.
24.
YoshikawaT (1985) Dynamic manipulability of robot manipulators. Proceedings of the 1985 IEEE International Conference on Robotics and Automation. 1985 Mar. St. Louis, USA. New York: IEEE. pp. 1033–1038.
25.
VahrenkampNAsfourTMettaG. (2012) Manipulability analysis. Proceedings of the IEEE International Conference on Humanoid Robots. 2012 Nov 29-Dec 1. Osaka, Japan. New York: IEEE. pp. 568–573.
26.
AtkesonCGMooreAW, and SchaalS (1997) Locally weighted learning. Artificial Intelligence Review.11:11–73.
27.
AhaDW, and GoldstoneRL (1990) Learning attribute relevance in context in instance-based learning algorithms. In 12th Annual Conference of the Cognitive Science Society. 1990; Cambridge, UK. Hillsdale NJ: Lawrence Earlbaum. pp. 141–148.
28.
GamsA, and UdeA (2009) Generalization of example movements with dynamic systems. Proceedings of the 9th IEEE-RAS International Conference on Humanoid Robots. 2009 Dec 10; Paris, France. New York: IEEE. pp. 28–33.