
Abstract
Gesture recognition is essential for human and robot collaboration. Within an industrial hybrid assembly cell, the performance of such a system significantly affects the safety of human workers. This work presents an approach to recognizing hand gestures accurately during an assembly task while in collaboration with a robot co-worker. We have designed and developed a sensor system for measuring natural human-robot interactions. The position and rotation information of a human worker's hands and fingertips are tracked in 3D space while completing a task. A modified chain-code method is proposed to describe the motion trajectory of the measured hands and fingertips. The Hidden Markov Model (HMM) method is adopted to recognize patterns via data streams and identify workers' gesture patterns and assembly intentions. The effectiveness of the proposed system is verified by experimental results. The outcome demonstrates that the proposed system is able to automatically segment the data streams and recognize the gesture patterns thus represented with a reasonable accuracy ratio.
1. Introduction
There is exceptional demand within the manufacturing industry to meet the high-mix, low-volume requirements for changing consumer-market demands. These demands are also met with an ever-increasing number of product variants and smaller lot-sizes [1, 2]. A fully robotic manufacturing cell has already been designed and adopted for this purpose [3]. However, a fully robotic manufacturing process cannot obtain sufficient flexibility with a highly variable product line. At the same time, it must also aim towards complimentary cost-effectiveness in order to support this demand. By taking advantage of a human's adaptability and flexibility, we can exploit the concept of a hybrid assembly system for medium-sized manufacturing processes. Hybrid assembly creates a modern assembly mode whereby the robot works as a co-worker to collaborate with the human and share the same working space and time [1, 4, 5]. Within this scenario, the advantages of human-robot collaboration are exploited through an optimized task-scheduling system while the shortcomings are avoided. The realization of a hybrid system can also have positive impact in society [6]. In previous work, it is shown that effective collaboration between human and robot can achieve cost-effective performance, and reduce the total assembly time (i.e., makespan) and cost of production [6].
The importance of hybrid assembly systems has become increasingly apparent both in industry and academia as regards improving production efficiency in manufacturing processes [7–10]. The main objective of this system is to make use of an individual's intelligence, expertise and flexibility. In this way, the robotic system is also able to take advantage of the human operator's sense, sensibility and resourcefulness to complete a required task. On the other hand, the human can utilize the high-precision, strength and repeatability of the robotic system, and thus reduce fatigue and the risk of injury as well as increase overall work safety [1, 11].
A hybrid assembly cell (HAC), where human and robot collaboratively work within a limited space, is commonly agreed as one realization of hybrid assembly systems [1, 12]. Compared with human and robot collaboration in an open environment, a cell-based assembly can concentrate much more on multi-functional modular manufacturing with small-volume requirements. This task-oriented assembly can be quickly deployed and allocated between human and robot co-workers [6]. However, despite carefully examining the research regarding this issue, it is always difficult to model such cooperation in a quantitative way. It is hard to identify any effective models describing the interaction between human and robots from recent research papers. However, when addressing industrial issues it is always very important to evaluate the cooperation performance quantitatively for industrial assembly in terms of the time span or errors which will directly affect the profits that the company can make. We study the mathematical model for human and robot cooperation by building a stochastic petri-net system, as in [13]. It is an event-driven system, whereby the robot detects certain ‘trigger’ events in order to carry out corresponding reactions.
Similar works can be found in [14], where a HAC called ‘multi-modal assembly-support system’ (MASS) is developed. MASS is equipped with physical support and information support, guaranteeing human workers' safety as well as the assembly task-flow. However, MASS mainly focuses on the safety rules category within the hybrid assembly and disregards any collaboration between the human and the robot co-worker. The recent research in [11] addresses a safety-control strategy for a robot co-worker by monitoring the position of the robot end-effector. Speed control for the end-effector is categorized into different stages within the working space. However, this configuration method has profoundly restricted the performance of the robot and lowered collaboration levels. Another platform called ‘joint-action for humans and industrial robots' (JAHIR, within the CoTeSys Project) is introduced in [15]. JAHIR focuses on monitoring the status of human workers and the assembly work-flow. Two cameras mounted on top of the working area are used to determine the 3D position of the human operator's hands. Tracking of the hands is achieved based on a 3D occupancy-map generated by the cameras. This configuration of a sensor system can only obtain the raw information of the hand's position, and therefore it cannot achieve accurate pattern recognition. This method is also time-consuming for online 3D occupancy-map generation, and makes it difficult for the robot co-worker to respond quickly.
Within a HAC system, the human action-pattern recognition and intention estimation are the key issues that must be addressed [16]. The assembly tasks assigned to the human and the robot are defined in advance based on a selection of optimal rules [6, 13]. According to this task-flow, the human worker can easily perceive and understand what his partner is doing, while the robot co-worker is limited and unable to perceive and react accordingly. A vision-based sensor system is already widely applied for non-contact environment-awareness in human-robot interaction (HRI) [17, 18]. However, the recognition of static and dynamic gestures within dynamic environments is difficult. It is essential to isolate the objects from complex and dynamic scenes with cluttered backgrounds. Consequently, pattern recognition on RGB image data combined with depth information (RGB-D data) has been introduced in recent years [19, 20]. Aligned with this research, the following techniques have also presented methods for addressing static and dynamic gestures. Single-frame data-based human gesture recognition [21], object recognition [22] and 3D environment reconstruction [23] have been reported. There are already a number of commercial RGB-D cameras available in the market at prices ranging from 200 USD to 50,000 USD and capture speeds from 0.033 seconds to three seconds. These features have restricted the wider usage of RGB-D cameras in industry. Among these cameras, Microsoft Kinect costs less than 200 USD with the frame rate 30FPS [24]. One drawback of Kinect is its inaccurate measurement output. Subtle movements of the human hand and fingertips are difficult to measure. In [25], the authors developed algorithms to detect the human palm and fingertips, and in [26] the authors developed an algorithm based on flocking in order to interact with computers more naturally. In [27], the pose of a human was computed from the fusion of data from a gypsy-giro suit based on accelerometers and UWB sensors for assembly and disassembly tasks in collaboration between humans and industrial robots. In the present research, we assume that the illumination within the assembly cell is always stable. When a human worker is collaborating with a robot, his hands are tracked only when they are completely exposed to Kinect and the light source. Supporting sensor data are sometimes provided for recognizing such actions.
The HMM is widely applied to pattern recognition, including speech recognition [28], handwriting recognition [29, 30], human behaviour recognition [31] and trajectorylearning [32]. It can also be applied to human-action pattern recognition via sensor-data streams. Related works demonstrate pattern recognition [33] and prediction [34, 35]. One of the challenges surrounding the use of HMM for online applications is the issue of a method for dealing with data segmentation via data streams and recognizing patterns via short segments.
The original contribution of this work is in the design of an intelligent human-robot collaborative hybrid assembly (iHRCHA) cell. In this, a sensor system serves as a natural interface between a human and a robot co-worker. Via this interface, the robot co-worker is able to identify a human worker's hand gestures accurately and rapidly. This mechanism utilizes an RGB-D camera and a supportive glove to produce the position data and rotation information of the humans palm and fingertips in 3D space. An algorithm is developed to obtain accurate information from the raw data streams of the sensor system. The HMM is combined with this interface for online hand-gesture recognition using a segmentation technique. This system is cheap and can be deployed quickly. It demonstrates an improvement in the current setup of HACs by providing a robot co-worker with the capability of carrying-out collaborative tasks rapidly, effectively and safely.
The remainder of this paper is organized as follows: Section II introduces the basic assumption, problems and challenges in iHRCHA. Section III describes the experimental setup, including the sensor system and the algorithm to process the sensor information and obtain the featured data. A trajectory descriptor is introduced to encode the human's palm and fingertip movement trajectories. Section IV describes a task scenario which assesses the presented system. Section V and Section VI explain the experimental results, discussion and conclusion respectively.
2. An intelligent human and robot collaborative hybrid assembly cell
2.1 Basic problem
In iHRCHA cells, human workers and robot co-workers must work closely with each other. In [1], the author describes several typical human and robot coordination models:
The human alternately collaborates with a robot co-worker in performing a task. In this case, the human and the robot perform the assembly sequentially (Fig. 1-(a)). The human and the robot do not share the working time but they do share the working space.
The human collaborates with the robot co-worker in performing a task. In this case, the human and the robot collaboratively perform the assembly task simultaneously (Fig. 1-(b)). The human and the robot share both the working time and the working space.
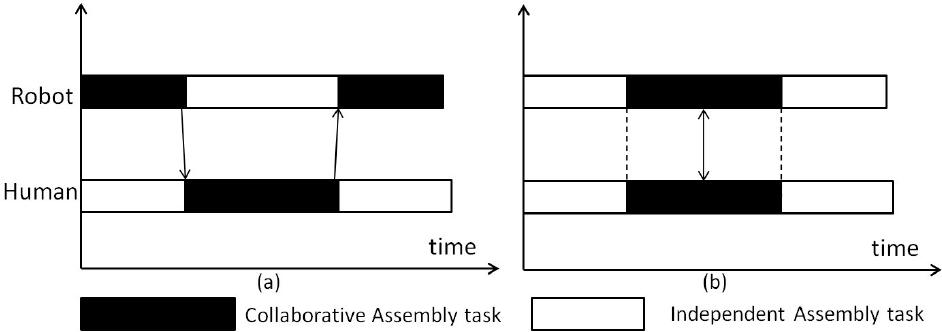
Gantti diagram for a “human/robot tasks shift”
When the human worker is performing the assembly task, the robot monitors, detects and estimates his actions and intentions. Being aware of the predefined scheduled assembly tasks, the robot co-worker can assist the human and carry out its own assembly task. The human cannot send explicit or implicit commands using a traditional human-machine interface, such as a keyboard or a mouse. He has to concentrate and focus on more urgent tasks. As a consequence, it is reasonable to design a human-robot interface in a natural way, using gestures and a language. Languages are the most natural way in which humans communicate. Despite the last decade of development, natural language process technology is still incapable of wide adoption for mutual applications due to the complicated processing involved. Human gestures - alternatively - are believed to be the most convincing natural interface while still retaining the rich information of human-robot communication.
Human gestures usually refer to those gestures represented via the body, arm or hands of a human. In iHRCHA, human and robot co-workers mainly perform electronic manufacturing assembly tasks on a bench. It is unwise to monitor human body gestures because these will not change very often or obviously during the assembly task. It is also not practical to monitor human arm gestures because it is difficult to capture sufficient information to describe them. Hand gestures are appropriate to describe a human worker's working status during manual assembly. The posture of a human worker's hands varies due to the different requirements of the current assembly task. Therefore, it is of interest to examine the relationship between a human worker's hand gestures and the actual assembly actions. Human intentions, as associated with assembly work, are defined as the assembly action that a given human worker is performing or intending to perform.
2.2 Hand gesture analysis in iHRCHA
In electronic manufacturing systems, assembly requires a human to perform accurate and quick assembly operations. In current manufacturing systems, human operators carry out most operations by hand. Therefore, we look to identify human assembly actions by monitoring hand gestures. Previous visual-object recognition technologies cannot provide an effective method for tracking and identifying complex palm and fingertip gestures in complex environments. In this research, a human-robot interface based on human hand gestures is designed and an effective algorithm for palm and fingertip recognition is proposed by analysing the RGB-D data of hands. Although it is possible to analyse palm rotation information based on such RGBD data, it is still not reliably accuracy. Therefore, we design a simple glove for a human with a three-axis acceleration sensor and a gyro-sensor attached for accurate palm movement and rotation information collection.
There are two types of hand gestures in iHRHAC (Fig. 2). One is the static gesture, which takes place immediately, and the other is the dynamical gesture which takes place over a time. The former can be described using a single frame of data from the data streams, while the latter can be described using sequential frames of data from the data streams.

Human hand gesture using OpenSim [36]
For a static gesture, a single frame of data includes not only the 3D position of the palm and fingertips but also the rotation information. For a dynamical gesture, besides the static gesture data for each frame, it also contains the hand movement trajectory.
In this research, the sensor system for the human-robot interface is built by two sets of sensors: a vision system using Kinect, and a data glove using a three-axis acceleration sensor and gyro. The information acquired by this sensor system is represented in two respects: the position of the human hands and fingertips, and the rotation information of the hands (including 3D acceleration and the angular velocity). Therefore, the action of a human's hand can be uniquely described by the combination of these two types of information.
2.3 Challenges for pattern recognition via data streams
In [37, 38], the authors list some particularly challenging issues for pattern recognition in data streams. Our iHA-CHA is designed based on the following considerations:
Cost-effectiveness: The sensor should be cheap for practical deployment while providing promising results.
Naturalness: This interface system should not require the human to wear additional heavy devices or else cause physical or psychological stress for the human [39]. Therefore, a conventional - i.e., complicated - data glove is not acceptable[40].
Interaction space: Traditionally, the system requires a human standing within a fixed environment without moving. However, the noisy background associated with a HAC can greatly affect the output of the system (irrespective of considerations of retrieving 3D position information).
Outlier point detection on data streams: Data streams-based pattern recognition requires that the system can automatically detect outlier points and segment data streams. Therefore, the cue study for detecting the segment containing potential human action is important [41].
Responsiveness: When a human performs an action, the robotic system should respond in near real-time. 45ms [42] is thought to be the threshold value for a real-time response, as with a human. After we determine the start point, the length of the data segment should be not too long in order that the robot can analyse that data segment and respond in real-time.
3. Experimental setup and methodology
3.1 Experimental environment setup
A concept of human-robot coordinated assembly is shown in Fig. 3, and the control diagram for this whole system is shown in Fig.4.

Concept of human-robot coordinated assembly. (a) Sensor system configuration. (b) Process human-hand movement and rotation information

Control chart of human-robot coordinated assembly. If we treat it as a robotic system, the human worker could be viewed as a disturbance which can cause the robot co-worker to change its work flow. A “human intention estimation module” is used to recognize the human worker's actions based on the information from the sensor system.
The 3D region where the human and robot collaboration takes place is called the ‘hazard zone’. A Kinect camera is used to detect this hazard area. The detection and tracking are only triggered when the human worker moves his hands into the “human/robot coordinated working area”, as in Fig.3-(a). There are two types of cameras mounted in a Kinect - a normal camera and an infrared camera. By combining these two cameras, one can get the depth image of an interested area, as shown in Fig. 3-(a). Based on the depth image, Algorithm 4 is developed to calculate the position of human hands and fingers in 2D. In Fig. 3-(b), we can see that Algorithm 4 can effectively detect the human operator's palm and fingertips when performing different actions. We are mostly interested in the fingertip position of the thumb, index finger and middle finger. However, in the algorithms, we tried to detect all five fingertips within each 20 ms sampling time. Sometimes, it becomes more difficult to detect the third finger or the little finger when the human worker is grabbing or holding as compared with the moving case. However, we still use the five fingertips data when training the HMMs. Moreover, we do not consider occlusion by the robotic manipulator. The robot is supposed to stay in the standby zone and monitor the human worker. When a cooperation decision is made by the central control module, the robot will carry out the task; afterwards, it goes back to standby status once again.
A human gesture is represented in two ways, as described in Sect. II: (1) in a static frame, and (2) via sequential frames. The former contains the information about human hands, while the latter contains information about the movement trajectory.
Based on the binary image, determinhe the polygon of the hand
Based on the polygon, we determine the convex hull (Sklansky algorithm)
Determine the convex hull vertices where θ<160° as the fingertips
Determine the centre point of the region (shown in Fig. 3-(b)) as the palm position
The vertices points above the centre point are the fingertips.
Use the Lukas-Kanade tracking algorithm to track the points of interest in 2D
Map the depth data of each detected point into height data
A hand information descriptor for a static frame
The rotation information of a human's hand is as important as position information. It is assumed that human static gestures include palm rotation information. A three-axis accelerometer and gyro-sensor mounted on the human's glove is constructed to meet this objective. Although there are several data gloves that can help collect hand information, these are inconvenient to use and intrusive for sensing. In this study, we only attach a sensor chip on the working glove. It is a non-intrusive sensor method, never interfering with the human's assembly actions. The measurement range of the three-axis acceleration sensor is from −3.6g to 3.6g (g: acceleration of gravity), and the measurement range of the gyro-sensor is from −110°/s to 110°/s. As shown in Fig. 3-a, the human and the robot are working on opposite sides of the work bench.
A movement trajectory descriptor for sequential frames
A major element of the motion information is contained in the motion trajectory. Accordingly, a trajectory descriptor is designed. The chain code method [43] (Fig. 5-(a)) has been widely used in describing the boundary of the region in image processing. The basic principle of chain codes is to separately encode each connected component in the image. For each such region, a point on the boundary is selected and its coordinates are transmitted. The encoder then moves along the boundary of the image and at each step, transmitting a symbol representing the direction of this movement. Compared to conventional freeman chain code descriptors, a modified chain code (Fig. 5-(b)) is used in this study. In this method, the neighbour points Ppre and Pcurr within the human movement trajectory are stored and compared. If Pcurr is within a limited range (such as where the range is smaller than r) of Ppre, the chain code for Pcurr is set as 0. If Pcurr is within any of the 8 directions from Ppre, as shown in Fig. 5-(b), the chain code for Pcurr will be given a the corresponding value.

Traditional eight-directional Freeman chain code
3.2 A human intention estimation module
In order to study the cooperation language using hand gestures for a robot to understand human workers' assembly intentions implicitly, as shown in Fig. 4, a “human intention estimation module” is developed to act as the connection between the human worker and the robot co-worker. Because only a segment of the data streams can be used for HMM, an automatic sliding window method is used to choose these segments. There are three steps to move the window via the data streams (details can be found in Section IV).
Find out the outlier points based on the data streams.
From each outlier point, continuously choose 10 samples, like O ={oi,oi+1,…,oi+9}, where oi denotes an outlier point.
Input O to the HMM classifier to determine which action the human is performing by comparing the output likelihood.
3.3 HMM: feature vector construction
The HMM definition is listed as follows:
The number of states of the model is N.
The number of observation symbols in the alphabet is M. If the observations are continuous, then M is infinite, O={v1,v2,…,vm}.
A set of hidden state transition probabilities is denoted A={aij}:
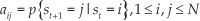
where st denotes the current hidden state at time t.
A probability distribution of the observation is denoted B={bj(k)}:

vk denotes the k-th observation symbol and ot denotes the current parameter vector at time t.
If the observations are continuous, then we must use a continuous probability density function instead of a set of discrete probabilities. In this case, we specify the parameters of the probability density function. Usually, the probability density is approximated by a weighted sum of M Gaussian distributions N, whereby:

and where:
cjm: weighting coefficients
μ jm : mean vectors
Σ jm : covariance matrices and the initial state distribution, Π={π i }, is such that:
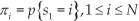
Therefore, we can use the compact notation:

to denote an HMM with continuous probability distributions. Define
Define
The feature vector for gesture identification is o = {of,oh}.
The task is to compute the probability of a particular output sequence given the parameters of the model. This requires summation over all possible state-sequences.
The probability of observing a sequence:

of a length l is given by:

where S ={s(0),s(1),…,s(l-1)}.
This problem can be handled efficiently using a forward algorithm.
Later we determine the likelihood for a sequence O related to a HMM Λ.
For a sequence O, we define the log-likelihood:

For a sample of observed sequences On, we define:

Here, L (Λ) is the log-likelihood of observing this sample given the model Λ, which can be calculated recursively. The likelihood approach is frequently used to find which HMM is most likely to be generated for a given data sequence in comparison to a threshold value or other HMM.
4. Gesture pattern recognition via data streams
4.1 Task scenario
The assembly task is predefined in order to study the human ‘fetch’ and ‘grasp’ patterns (Fig. 6). In the assembly area, there are two pairs of connectors (C1 and C2), each of which has two connector heads (C1-1, C1-2 and C2-1 C2-2) connected with a single cable. In the assembly area, there are two connector slots, called P1 and P2, respectively. The objective of this assembly work is to insert the connector C1 or C2 to P. The restriction is that C1-1(C2-1) should be inserted on P1 and that C1-2(C2-2) should be inserted on P2. Because it is human-robot coordinated work, the human worker will choose and insert C1-1(C2-1) while the robot will choose and insert C1-2(C2-2). Both the human's and the robot's actions occur simultaneously.
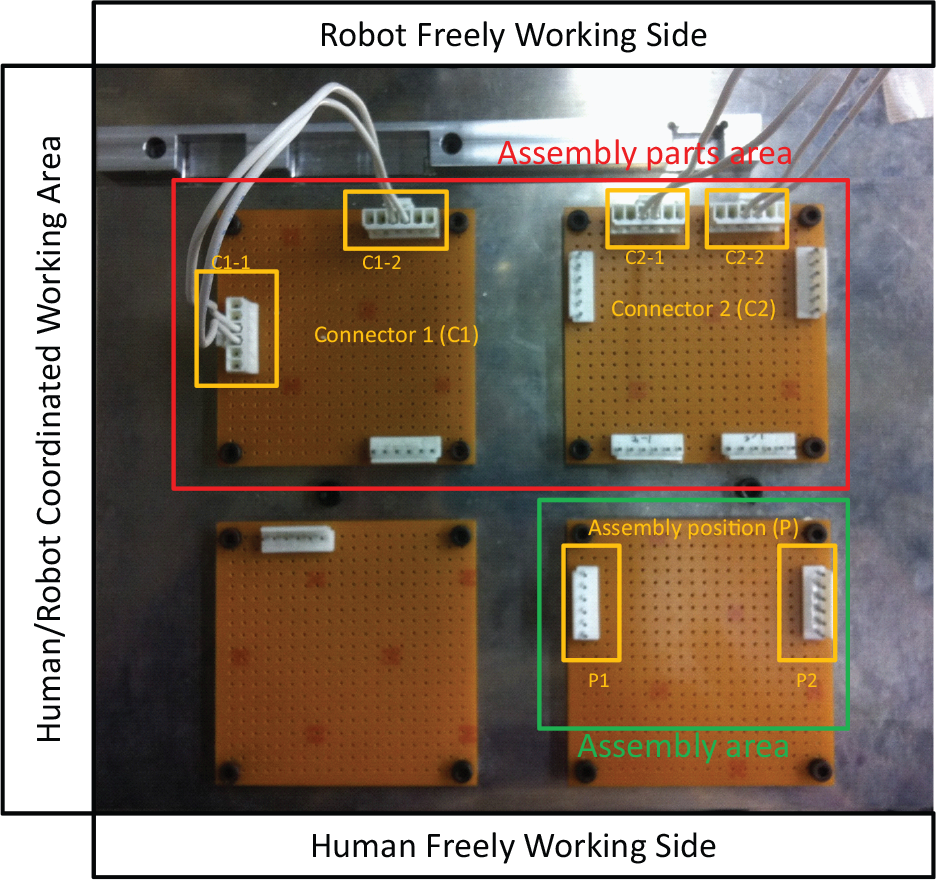
Task scenario
4.2 Possible human intention
It is a human-conducted, robot-supported assembly task; therefore, the robot moves after it successfully identifies the human worker's action. Only when the robot knows what the human worker is doing will the robot estimate the human's movement trajectory and coordinate itself correspondingly in safe mode.
However, due to human nature, the human's intentions may change during assembly, as categorized according to four types (Table 1).
Action description within this task scenario

Subject to different intentions, the robot co-worker performs its actions correspondingly, as shown in Table 2. The problem is that the robot needs to know when the human will carry out the “move and grab” action and the “move and hold” action, which together comprise the most basic human gesture patterns in this assembly process (Fig. 8).
Robot action corresponding to different human intentions

According to the intention described in Table 1, the human movement trajectory is shown in Fig. 7.

Human hand movement trajectory in an XY 2D panel. “Micro-slip” describes the phenomenon whereby the human is carrying out an action and then hesitates or changes his mind. In an assembly system, this phenomenon is widespread due to the fact that humans are non-controllable.

Data streams from the sensor system (y-axis) for the “move and grab” action (A1) and the “move and hold” action (A2) versus the length of the samples (x-axis) with 100 sampling steps. The former 50 and the latter 50 contain the “move and grab” action and the “move and hold” action twice, respectively. (a) Acceleration of the palm via the x-axis, the y-axis and the z-axis, respectively. (b) Rotation information of the palm around the x-axis and the y-axis, respectively. (c) Number of detected fingertips. (d) Area of the detected palm in a 2D panel. (e) and (f) represent two criteria: palm movement acceleration and rotational energy for sample segmentation.
Modified eight-directional chain code is adopted to describe the trajectory shown in Fig. 7.
4.3 Segment start point detection
A segment start point detection method involves finding out the outlier point via the data streams. It is assumed that when a human wants to carry out an action, his hands will move in an obvious manner. This movement can be represented by the change in data via acceleration in a 3D space. We can use the following C1 (combined acceleration) to detect the start point of the significant action segment by comparing it with a certain threshold value. Similarly, for the rotation movement, we can observe the movement action represented by the gyro-data change, as shown in C2 (rotational energy).

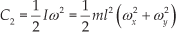
where a denotes the movement speed acceleration, (ax,ay,az) denotes the three-axis speed acceleration (all acquired from the data glove), and (ωx,ωy) denotes the angular velocity. m is the mass of the hand and l is the distance between the mass point and the rotational axis. ml2 is the moment of inertia (which is treated as a constant value in this study), and so we have the following equation:

4.4 Segment start point decision
The segment should not be too long or too short. If the length is set too long, the robot cannot react to the human worker quickly. If the length is set too short, the data segment cannot represent any meaningful information. In this study, we suppose that all the meaningful human actions are completed by 1s. According to our experimental setup, it utilizes 50 time-intervals.
5. Experiment and discussion
5.1 Segment start point and length:
When a human worker collaborates with a robot on assembly tasks, the robot must be aware of the task sequence that has been predefined. The only issue here is that the human worker cannot guarantee stable performance in time domain. Accordingly, the robot must constantly monitor the human in order to know what to do next. In this case, the robot must detect some “trigger” action so that it can estimate which task the human is performing or else is going to perform by checking the task sequence defined in the database. We assume that grasping (move and grab) and handling (move and hold) are the two most typical “trigger” actions. In this section, two actions including “move and grab” and “move and hold” for a human worker's left hand are recognized by the HMM model.
We use the movement acceleration C1 and the rotational energy C2 by comparing them with a certain threshold value in order to detect the start point of a meaningful action. In this experiment, we observe the action samples (Fig. 8 - (e) and (f)) via time (the time for each sample interval is 20ms). From the observation, the length of the segment for these two actions is chosen as 10 and 10 in order to form a 0.2s length data segment, respectively (Table 4).
Chain code to describe the trajectory in Fig. 7

Start point detection and segment length decision

5.2 Feature vector for HMM
“Move and grab” action
In this experiment, we assume that the rotation action usually occurs without any rotation in the 3D axis; therefore, the feature vector for training is just the data vector from the data glove and the Kinect sensor.
We define fh ={xa,ya, za, xh,yh,zh}, where a denotes the acceleration and xh,yh,zh denotes the hand position in 3D.
“Move and hold” action
In this experiment, we assume that the rotation action usually occurs without any coordination shifts in the 3D axis; therefore, the feature vector for training is just the data vector from the data glove.
We define fh = {ax, ay, az, ωx, ωy}, where a denotes the acceleration and ω denotes the angular velocity.
We sampled the data segment (Fig. 8 - (a)(b)(c)(d)) for training based on the start-point detection and segment-length decision method described in the previous subsection.
5.3 HMM for the identification of two actions in Fig. 7
We acquire the sample segments using the segmentation method introduced in the previous section and use the Baum-Welch algorithm to train the HMM based on these samples for each action respectively. 50 sets of experiments are performed for the “move and grab” action and another 50 for the “move and hold” action. In each 30 sets are used as the training data and 20 sets are used to validate the HMM model that is being trained. The created HMM is denoted Λ = (A,B,Π), as shown in Fig. 9. Each action only lasts for less than 0.2s (the sample interval length is 10 at most). After we train the HMM with more (>3) hidden states, we discover that there is no obvious physical meaning for some hidden states. Therefore, we choose a three-hidden state HMM to model a given action. On the other hand, because the length of the sample is short, we should avoid over-fitting during the training process. Three hidden states are chosen as the most appropriate to model this hand-movement action.

HMM construction with three hidden states for “move and grab” and “move and hold” actions. For each hidden state, it represents a single frame of a gesture.
For each of the hidden states, it actually represents a frame of the action for “move and grab” and “move and hold”. In Fig. 9, it shows the representative action within, b move and grab” and “move and hold”, as described in Fig. 8.
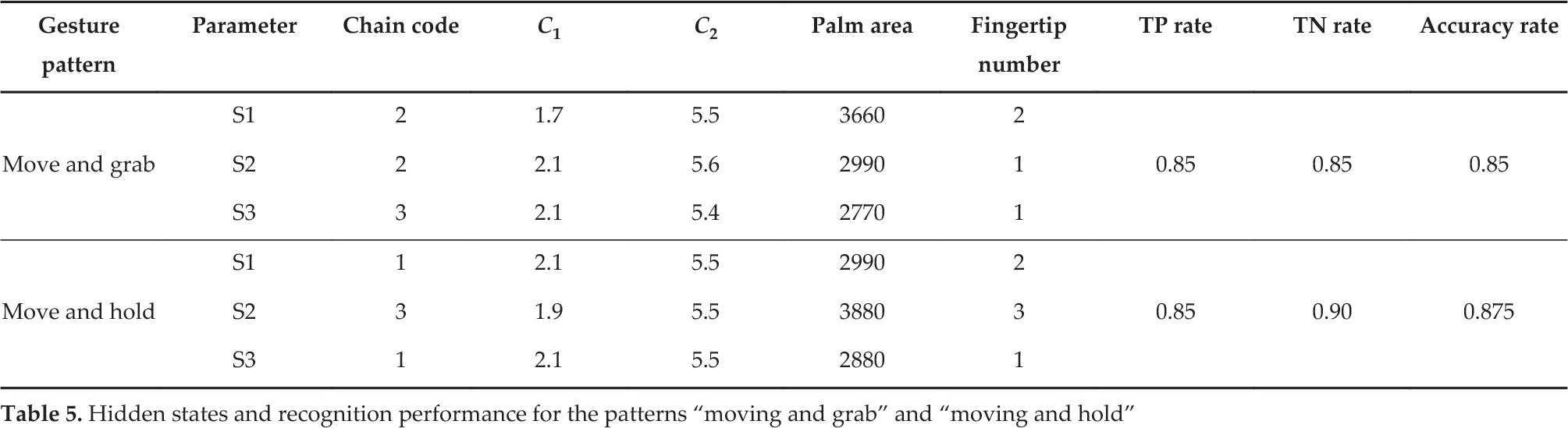
In Table 5 can be seen that the performance of the trained HMM in identifying the “move and grab” action and the “move and hold” action. The log likelihood (Equation 9) is the main criterion for evaluating the possibility of a given datum generated by the HMM model. We define an experiment from P positive instances and N negative instances for a given condition. According to the experimental setup, both P and N are equal to 20. We use the true-positive (TP) rate to evaluate the sensitivity (Equation 13) and the true-negative (TN) rate to evaluate the specificity (Equation 14) of the trained classifier - TP gives the number of successful identifications when the sample data contain the pattern requiring identification, while TN gives the number of failure identifications when the sample data does not contain the pattern requiring identification. Moreover, the identification accuracy rate γ accuracy is calculated according to Equation 15 [44].
Hidden states and recognition performance for the patterns “moving and grab” and “moving and hold”



where P denotes the number of samples containing the movement pattern to be detected and N denotes the number of samples which do not contain the movement pattern to be detected.
It is noted that the classifier generated by this method has a high TP rate as well as relatively high FP rate, yielding an accuracy rate greater than 85%. This suggests that the robot co-worker makes the right decision most of the time. It should also be pointed out that, because the pattern recognition is based on a 0.2s-long segment, the robot is capable of responding to the human worker's actions in near real-time. This feature is significant, not only for carrying out effective and efficient assembly tasks by a human and a robot but also for safety.
6. Conclusion
The design, development and evaluation of the novel natural human-robot interface for human gesture recognition within a HRC have been presented. A RGB-D camera is used to detect the human operator's palm and fingertip positions, and an accelerometer and gyro-sensor attached to a glove are used to detect the rotation and movement of the hand. This offers a novel research element for pattern recognition via data streams in a hybrid manufacturing environment. Based on this technology, a HMM-based method is adopted to identify human workers' gestures automatically. This shows that the proposed system can automatically segment the data streams and recognize the action patterns represented with an acceptable accuracy ratio.
The main contribution of this paper lies in the design of an iHRCHA cell within which a sensor system serves as a natural interface between a human and a robot co-worker. With the help of this system, several challenges in realizing human-robot collaboration in HRC are fulfilled. In particular, this system is affordable while not violating the naturalness, it can effectively monitor hazardous areas where collaboration occurs, and it can automatically detect the outlier point, segment the data streams and reduce time to process the data. Therefore, the robot co-worker can respond to an action within around 0.2s. This short response-time can also eliminate the potential danger that a robot co-worker may hurt the human worker.
From the illustrated example, when recognizing the gesture patterns “move and grab” and “move and hold”, our approach yields a high true-positive rate and a high accuracy rate. It demonstrates that our interface performs better than the previous, ordinary vision-based HRC interfaces, since we consider more information in describing the gesture of the human's hand and fingertips while improving the processing algorithms. This system can be easily extended to more action patterns in recognition situations. Future research will focus on human intention estimation by testing with various stream-pattern recognition methods. One direction would be to consider the reconstruction of the data in subsequent frames based on the current recognized action patterns.
Footnotes
7. Acknowledgements
This material is based upon work funded by the Natural Science Foundation of China under Grant No. 61203360, Zhejiang Provincial Natural Science Foundation of China under Grant Nos. LQ12F03001, LQ12D01001 and LY12F01002, Ningbo City Natural Science Foundation of China under Grant Nos.2012A610009 and 2012A610043, the State Key Laboratory of Robotics and Systems (HIT) Foundation of China under Grant No. SKLRS-2012-MS-06, and the China Post-doctoral Science Foundation under Grant No. 2013M531022.