
Abstract
The highly efficient and robust stitching of aerial video captured by unmanned aerial vehicles (UAVs) is a challenging problem in the field of robot vision. Existing commercial image stitching systems have seen success with offline stitching tasks, but they cannot guarantee high-speed performance when dealing with online aerial video sequences. In this paper, we present a novel system which has an unique ability to stitch high-frame rate aerial video at a speed of 150 frames per second (FPS). In addition, rather than using a high-speed vision platform such as FPGA or CUDA, our system is running on a normal personal computer. To achieve this, after the careful comparison of the existing invariant features, we choose the FAST corner and binary descriptor for efficient feature extraction and representation, and present a spatial and temporal coherent filter to fuse the UAV motion information into the feature matching. The proposed filter can remove the majority of feature correspondence outliers and significantly increase the speed of robust feature matching by up to 20 times. To achieve a balance between robustness and efficiency, a dynamic key frame-based stitching framework is used to reduce the accumulation errors. Extensive experiments on challenging UAV datasets demonstrate that our approach can break through the speed limitation and generate an accurate stitching image for aerial video stitching tasks.
Introduction
Stitching is the process of generating a larger image that joints the entirety of the overlapping images of an input video [1, 2]. Focusing on the special kind of video captured from an aerial platform, aerial video stitching [3–17] is a key component in various application fields, including disaster monitoring, aerial surveillance, remote sensing and UAV navigation, etc.
Objective and Challenge
In many aerial applications, real-time performance is the key challenge to decide whether or not the system can be practical. Although numerous stitching systems have been proposed, most of them are designed to produce offline, globally optimal mosaics rather than high frame rate online stitching.
The objective of this work is to design a pure computer vision system for high-speed aerial video stitching. Instead of fusing information from other airborne sensors, such as an inertial navigation system, the only input of our system is the high frame rate video captured from an airborne platform.
Our Contributions
The main contributions of this work include: (1) We present a highly efficient stitching system which has the unique ability to stitch aerial images together and generate a seamless wide-angle view of the surveillance area at over 150 FPS with an image size of 320×240 on a normal personal computer. (2) Our system contains a novel spatial and temporal coherent filter which breaks through the speed limitation of aerial video stitching. By embedding this filter into the image feature-matching module, a majority of outliers are accurately removed and the speed of the robust feature matching is increased 20-fold. (3) A dynamic key frame-based video stitching module is adopted to reduce the accumulation errors of image transformation estimation and maintain the balance between robustness and efficiency for a long time sequence. Experiments with simulation data and real UAV video demonstrate the robustness and efficiency of our system.
The remainder of this paper is structured as follows. Section II explores the related literature and analyses their advantages and limitations. Section III presents both the entire framework and the details of our stitching algorithm. We describe the experiments in Section IV, including a set of quantitative and qualitative evaluations of the proposed algorithm with the publicly available VIVID [18] and VSAM [19] UAV datasets. Final conclusions and future work are pointed out in Section V.
Related Work
Over the last few decades, enormous research efforts have been carried out on video stitching. Szeliski [1] summarizes the literature in detail. However, as mentioned in the introduction above, the characteristics of aerial video are different from those of other kinds of video; therefore, the problems, assumptions and solutions considered by many existing video stitching methods are not suitable for aerial video. In this section, we will focus on the related works that can be used for high-speed, low accumulative error and high quality aerial video stitching.
Broadly speaking, video stitching mainly involves four key components: (1) feature representation, (2) feature matching, (3) robust estimation and outlier removal, and (4) global image transform estimation.
Feature Representation
The goal of feature representation is to detect and describe image patches with high distinctiveness and repeatability. The most popular methods used are invariant feature-based approaches [20], which are robust given large geometry and illumination changes.
Typical invariant feature-based approaches include SIFT [21], ASIFT [22], SURF [23], Ferns[24], BRIEF [25], ORB [26] and BING [27], etc. Performance evaluation on local descriptors [28] shows that SIFT and SIFT-like features outperform others in terms o distinctiveness and robustness in solving real geometric and photometric transformations. Due to their good performance, SIFT-like features have been adopted in commercial image stitching systems, such as Autostitch [29]. A major drawback of SIFT-like features is that these methods usually have high computational costs in relation to scale-invariant key point detection and spatial histogram feature description.
Besides the complicated SIFT-like float descriptors, recently binary features (such as Ferns[24], BRIEF [25] and ORB [26], etc.) have become popular because the involve less storage spafe while allowing faster computations. Although performance evaluation results show that the distinctiveness of binary features is relative slight compared to SIFT-like features, the high speed of the binary features is still attractive in many real-time application fields.
Feature Matching
Feature matching looks to find the candidate correspondences between features from different images. It usually contains two classes of methods: tree-based methods and brute-force searching methods.
Tree-based methods (such as K-D tree [30], Best Bin First [21] and Bag-of-Words [31, 32], etc.) need to set up an indexing tree before feature searching. Although it is highly efficient to find the k nearest neighbours in the indexing tree, the training required to build a tree is still time-consuming and may not be suitable for real-time applications. Hence, tree-based indexing methods are often used in applications involving large image dataset retrieval, in which the training process can be performed offline.
Brute-force searching is a straightforward way to find the most similar feature correspondences. Given a certain feature, its search time is computed by the similarity measure time between two features multiplied by the total number of feature candidates in another image. For real value features such as SIFT [21], the Euclidean distance is usually selected as the similarity metric, which needs to do 255 subtractions and 128 multiplications for a pair of SIFT features. Obviously, the real value features cannot satisfy the requirement of high-speed processing. In contrast, the binary features [25, 32] adopt the Hamming distance as a similarity metric, which can be calculated highly efficiently with a bit operator.
Thus, in this paper, rather than using the SIFT-like features, we select the brute-force searching of binary features for high-speed feature matching and propose an effective coherent filter to maintain the balance of robustness and real-time capacity for the aerial video stitching system.
Robust Estimation and Outlier Removal
Robust outlier removal from initial feature correspondences is an essential problem in video stitching. Among significant efforts to solve this problem, random sample and consensus (RANSAC)[33–35] is probably the most widely used technique, applying random sampling techniques to search for the maximal consensus set from the input data. Although RANSAC is robust in handling over 50% outliers, its processing speed is controlled by the sampling time, which is determined by the percentage of outliers inside the input data.
Our experiment shows that outlier removal from noisy data constitutes the speed bottleneck of the entire video stitching system. In this work, we break through this speed limitation via our spatial and temporal coherent filter, which can effectively remove the majority of outliers during feature matching and significantly reduces the RANSAC time from 20 milliseconds to less than one millisecond.
Image Transform Estimation
The last key component for real-time aerial video stitching is the global image transformation estimation. The objective of this component is to find the optimal transformation matrix from a certain frame to the global reference image. To achieve this, frame-to-frame alignment constitutes the most common method in the stitching literature. Although this scheme is very efficient, it has a major downside - even though the local image transformation produces a small inter-frame error, a huge accumulation error may appear when dealing with a lengthy aerial sequence. Our experiments show that, usually, when the image sequence is longer than 1,000 frames, distinct errors may appear in the stitching image. In this work, we propose a dynamic key frame selection approach to reduce the accumulation errors in a long time sequence.
High Speed Aerial Video Stitching System
System Framework
Figure 1 shows the framework of our system, which broadly contains five modules: feature detection, feature description, feature matching, robust estimation and image transform estimation.

Framework of the proposed aerial video stitching algorithm. The dotted box at the top shows the related methods of each component and the solid box at the bottom shows our method.
In the middle dotted circles of Figure 1, the existing state-of-the-art algorithms of each module are grouped together in several algorithm pools. The detector pool contains enormous detectors, such as Harris, difference-of-Gaussian (DOG) as used by SIFT [21], difference-of-Hessian (DOH) as used by SURF [23], and FAST corner [26], etc., and the descriptor pool includes both real value descriptors (such as SIFT and SURF) and binary descriptors (such as BRIEF and Ferns). The matching strategies pool contains tree-based indexing (such as K-D Tree, Best Bin First, BOW and Vocabulary Tree) and brute-force searching. Meanwhile, the robust estimation pool mainly includes algorithms from the RANSAC family [35]. The image transformation pool includes the local optimal frame-to-frame methods and global optimal frame-to-mosaic approaches.
Although numerous stitching methods have been proposed by different combinations of features or algorithms under the scheme of Figure 1, most of them are designed to produce offline globally optimal mosaics rather than real-time online processing. In this system, after the careful analysis of the effectiveness and efficiency of the features and methods in the algorithm pools, we adopt the FAST corner and BRIEF binary descriptors for image feature detection and description, and we present a novel spatial-temporal coherent filter for high-speed robust matching. Besides this, we dynamically select key frames to reduce the accumulation error while maintaining high-speed processing (as shown in the bottom solid boxes of Figure 1).
SIFT [21] has been popular in image stitching, and it has shown remarkable matching performance. However, the SIFT algorithm imposes a huge computational burden in the key point location and the description in the image-scale space, which is not suitable for real-time aerial video stitching.
Partly inspired by the SIFT descriptor, SURF [23] was first presented in 2006. It uses the integral image to compute the approximate determinant of the Hessian blob detector efficiently. Again, it also adopts the integral image to calculate the sum of the Haar wavelet response around the point of interest as the descriptor. The standard version of SURF is several times faster than SIFT.
For aerial images captured by a downwards pointing camera, the predominant changes between two consecutive frames are translation and rotation, and the changes in scale and perspective are usually small. As a result, it is not necessary to select the relatively complicated SIFT or SURF, both of which involve significant computation costs in handling the large-scale and perspective image transforms.
To extract key point features in real-time, in this work we adopt ORB [26], which is built on the well-known FAST key point detector [36] and the BRIEF descriptor [25].
FAST [36] and its variants are famous for their marked efficiency in finding reasonable key points, and it has been popular in many real-time systems such as parallel tracking and mapping [37] and mobile augmented reality. FAST only uses one parameter, the intensity threshold between the centre pixel and its neighbouring pixels on a circular ring. A major limitation of FAST [36] is that it does not include an orientation operator - for instance, the histograms of the gradient in SIFT and SURF. Another limitation is that FAST gives large responses along edges.
BRIEF [25] is a bit string description of an image patch constructed from a set of binary intensity tests. Experiments show that it is still, with reasonable discrimination. More importantly, instead of the L2 norm (as is usually done by SIFT or SURF), the similarity of the ORB descriptor can be evaluated using the Hamming distance, which is very efficient in computing a binary string. A major problem with BRIEF is that it is not invariant to rotation.
To handle the rotation problem, ORB [26] uses the intensity centroid to compute an orientation for each FAST corner and then adopts the Harris corner response to remove the points along the edges. In addition, since FAST corner does not produce multi-scale features, we extract ORB features in five scale images separately, with a scaling factor of
Spatial-Temporal Coherent Filter
After feature extraction, we need to find the candidate feature correspondences. Because it is highly efficient to match binary features through bit operation, instead of using indexing-based similarity search methods we directly apply the brute-force method to find the candidate feature correspondences between two images. Experiments show that the matching time of the binary descriptors between two aerial images is about one millisecond.
Ideally, given at least four point correspondences, we can calculate a homography transform via a direct linear transform. However, the least-squares solution can easily fail due to the incorrect feature correspondences or outliers. To overcome this problem, RANSAC [33] is often used as a standard outlier removal method. The standard RANSAC mainly contains two components: a hypothesis and testing. In the hypothesis step, RANSAC uniformly selects a subset of feature correspondences to generate a candidate solution of homography. Next, in the testing step, the entire feature correspondence dataset will be verified by the selected solution. With repeated hypothesizing and testing, RANSAC can find a good enough model with the largest number of inlier correspondences.
A major problem for standard RANSAC [33] is that its processing time quickly increases with additional outliers. However, the number of outliers in a aerial video is often large, due to the following reasons: First, matching the less distinctive binary features can generate many false feature correspondences. Second, considering moving objects (such as vehicles on the ground) and depth variations (such as trees and buildings), even a correct feature correspondence can still be an outlier for the global motion model of the image transform.
In our experiment, traditional RANSAC [33] costed over 95% of the processing time given significant outliers, and it obviously became the speed bottleneck of the entire stitching system.
As mentioned above, the output of this work is a highly efficient stitching algorithm at a speed of over 150 fps, whereby the time interval between two frames is only 6.67 milliseconds and a strong spatial and temporal relation exists between two frames. Thus, we design an appearance- and motion-based spatial and temporal filter to remove the majority of outliers before RANSAC.
Let Kt = {xt, yt, St} denotes a key point at time t, and (xt, yt) and St represent the key point position and scale in the image, respectively. We use the following filter

in which
Due to the tiny time interval between two neighbouring frames, a pair of correct feature correspondences should have a highly similar appearance in terms of the local intensity distribution, orientation and image size.
Among the above three appearance characteristics, the local intensity distribution and orientation of the feature points have already been used to acquire the initial feature correspondences. Thus, in this work we take advantage of the scale of the key point as the appearance coherence in the filter:
Φappearance(Kt, K′ ref )
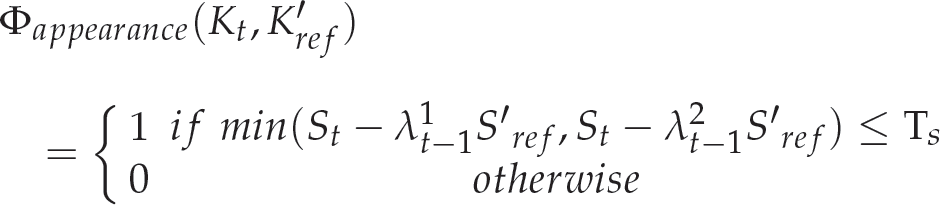
where Ts denotes the maximal scale difference between the key point K and
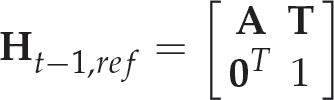

where T represents the translation matrix,
• Motion Coherence
Similarly, as above, the image transform matrix

where
Instead of using the improved algorithms from the RANSAC family, our work shows that by integrating the above appearance and motion constraints in Equation (1), Equation (2) and Equation (5), we can significantly reduce the average outlier removal time from 24 milliseconds to less than one millisecond with the standard RANSAC. For more details, please see the time consumption experiments and discussions in the experiment section.
After outlier removal, we can estimate the local image transform matrix

where

Aerial video stitching at frame t
System and Datasets
In order to evaluate the speed and robustness of our approach, we developed a C++ implementation of the algorithm with VC++2010 and OpenCV 2.4.2. The algorithm runs in real-time on a PC with a Core i7 950 (2.66 GHz) CPU, and its processing speed achieves 150 fps with an aerial image size of 320×240.
The datasets we used in our experiments mainly consist of two parts: simulation UAV videos and real UAV videos. In the first part, we manually download aerial images from Google Earth, which contains typical ground objects such as buildings, mountains, forests, roads and bodies of water. In the second part, we use the publicly available VIVID UAV dataset and the VSAM UAV dataset to evaluate performance in real challenging conditions.
Since the key objective of our work is to develop a high-speed aerial video mosaicing system, in the following subsections we first provide the comparison and analysis details of our processing speed and then give the video mosaicing results for both the simulation and the real UAV dataset.
Processing Speed Analysis
Our algorithm is capable of performing real-time aerial video stitching at over 150 fps. Although we appreciate the benefits of a high-speed computing platform, for the real-time analysis of this article we focus on the analysis of the algorithm itself and do not use FPGA or CUDA programming.
Average Processing Time
We use over 12,000 aerial images with a size of 320×240 to estimate the average processing time of the components detailed above. Figure 2 visualizes the processing time of each component using our approach.
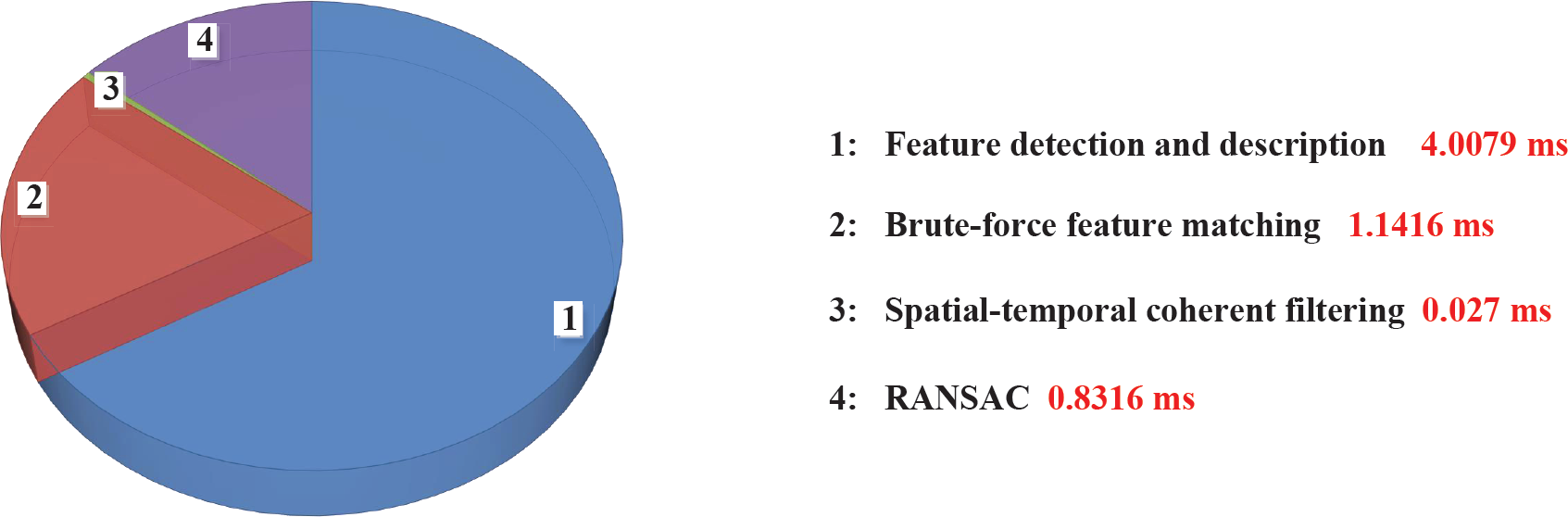
Processing time for each individual step of our high-speed aerial video stitching algorithm
When we calculate the processing speed of our algorithm, we exclude the image acquisition time. The reason for this is that our system contains two independent parallel processes: data acquisition and data processing. After capturing the image data from a camera or other image sources, the data acquisition process will copy the original image data value to the shared memory. Meanwhile, once it has finished stitching a previous frame, the date processing process will access the shared memory for the latest image. Based on the above parallel processing framework, we have separated the image data acquisition and processing. Figure 2 shows the processing time of each module in the data processing process; since it is highly efficient to copy the image data from the shared memory, we do not include the image acquisition time in Figure 2.
Feature Extraction Because we adopt the efficient FAST corner detector and the compact BRIEF descriptor, our feature detection and description time for a 320×240 image only takes 4.0079 milliseconds (as shown in Figure 2). Although the SIFT and SURF algorithms are frequently used in the field of image stitching, we have done experiments with their C++ source codes from the original authors, the results showing that their average feature extraction time is 1,000 milliseconds and 120 milliseconds, respectively, using the same system hardware, which is clearly unsuitable for real-time processing.
Feature Matching Although many mosaicing algorithms adopt indexing methods to speed up the feature matching, such as KD-tree, BBF and BOW, they still impose additional time costs in building and updating the indexing tree online. Since the BRIEF descriptor that we used in our approach is a binary vector (which is comparatively highly efficient via a single and operation), instead of using a feature indexing method we directly compute the Hamming distance of each pair of binary BRIEF descriptors. The experimental results show that our feature time only takes 1.1416 milliseconds (as shown in Figure 2) for each frame.
Spatial and Temporal Filtering and Outlier Removal Because the aerial video contains similar image patches and moving objects, the feature matching results often include many outliers (which will significantly increase the computation time of traditional RANSAC).
Figure 3 shows the comparison results of the processing times with and without spatial and temporal filtering. Please note that, without our spatial and temporal filtering, the average processing time for outlier removal is 24.5 milliseconds (as shown in Figure 3 - red bar). Clearly, outlier removal has become the speed bottleneck of the entire stitching system.

Comparison results of the average processing time with and without a spatial and temporal coherent filter
To confront this challenge, we embed a highly efficient spatial and temporal coherent filter, which only takes 0.027 milliseconds to remove the majority of the outliers and which significantly reduces the RANSAC time from 24.5 milliseconds to 0.8316 milliseconds (as shown in Figure 3).
One possible issue that may influence the speed of the system is that Windows is not a real-time operating system. However, because our calculation is the average processing speed, the random Windows latencies can influence the processing fluency temporally but they will not affect the overall performance of the entire stitching system.
Figure 4 displays the dynamic processing time for each component in an aerial video sequence. The test data that we used in shown in Figure 6, which contains 629 aerial images. It can be seen that the spatial and temporal coherent filter always takes the minimum time (Figure 4 - red curve), which is less than 0.1 milliseconds. The processing time of RANSAC (Figure 4 - blue curve) is similar to the feature matching module (Figure 4 - blue curve), which is around one millisecond in most frames. Compared to the other modules, the feature extraction is the most time consuming module in our system. However, its processing time is still around four milliseconds for the entire sequence, which is fast enough for high-speed processing.
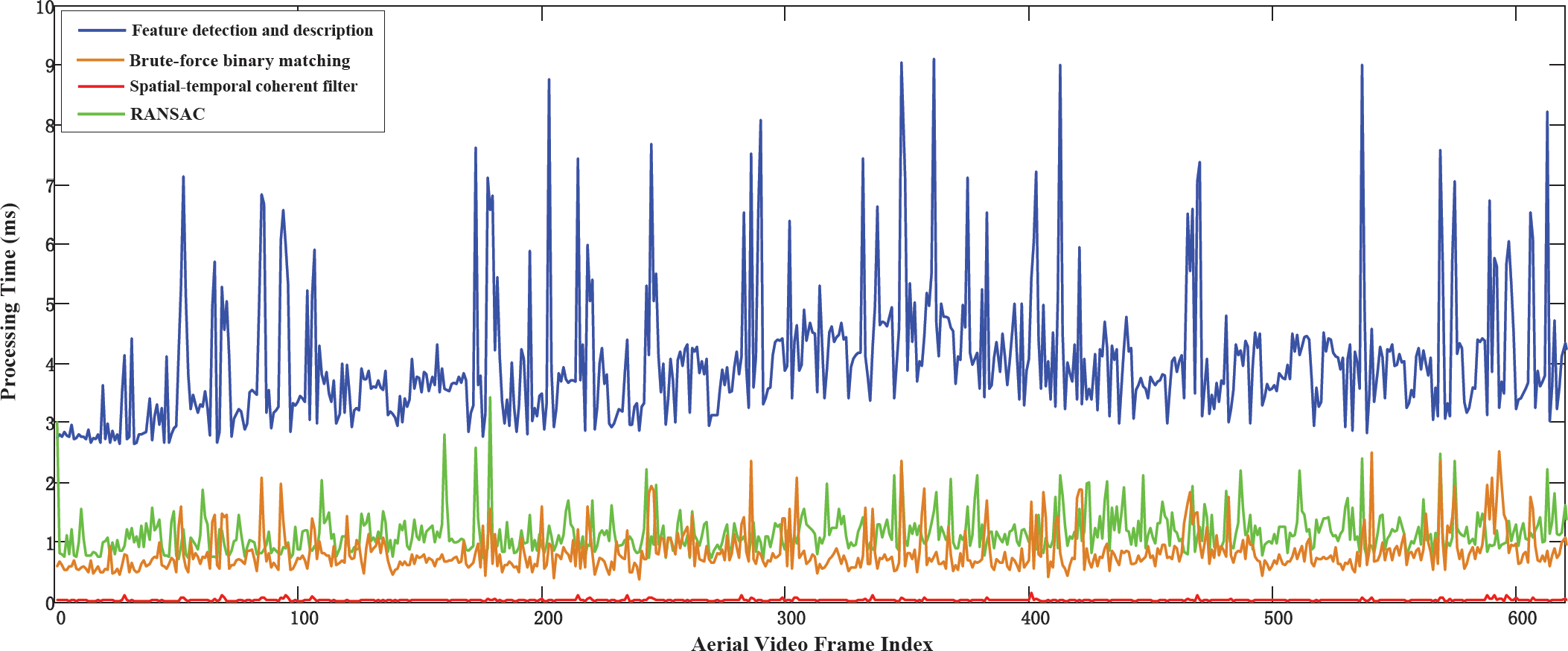
Dynamic processing time for feature extraction, matching, spatial-temporal coherent filtering and outlier removal
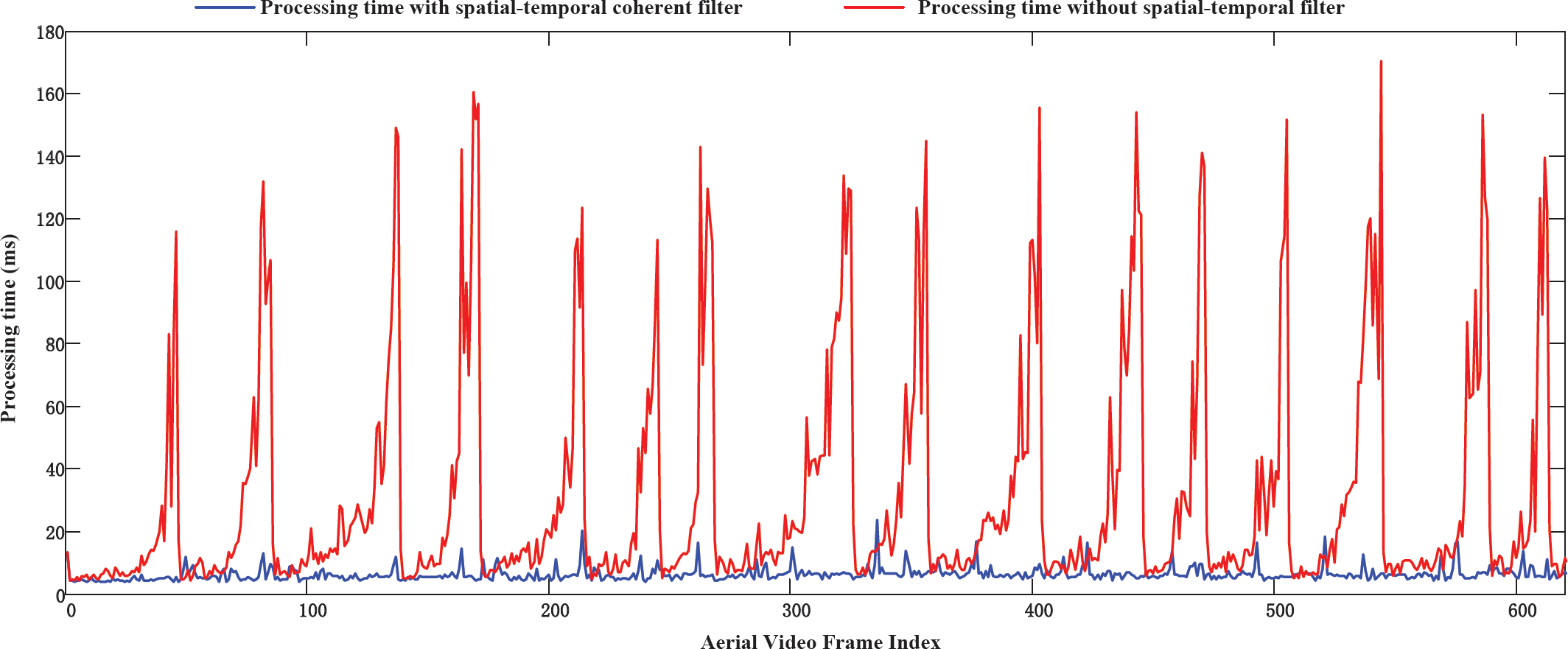
Comparison of the dynamic processing time with and without a spatial-temporal coherent filter

Dynamic aerial video stitching results and comparison of occlusion errors
To further demonstrate the superiority of our spatial and temporal coherent filter in online stitching, in Figure 5 we compare the overall processing time both with and without filtering. It can be clearly seen that the processing time without a spatial and temporal filter changes periodically (Figure 5 - red curve), with a mean processing time of 24.5 milliseconds and a maximal processing time over 160 milliseconds. In contrast, the overall processing time of our approach is stable across the entire sequence, with a mean processing time of 6.7 milliseconds and a maximal processing time of 11.7 milliseconds.
The reason behind this is that our algorithm generates the key frame dynamically to reduce the accumulation error. When the overlapping area between the current frame and the key frame is reduced, the ratio of the outlier is usually increased. As a result, the processing time of RANSAC without a filter will quickly increase. By embedding the spatial and temporal coherent filter, our approach removes the majority of the outliers and greatly speeds up the RANSAC outlier removal which follows. The experimental results demonstrate the effectiveness and efficiency of our method.
To test our approach to accumulation error with a long time sequence, we first download an image from Google Earth with a size of 10,000×10,000 pixels. Next, we simulate a virtual UAV flying around the area in a circle, and record the virtual downwards-view UAV aerial images. Afterwards, the simulated 629 aerial images are used as input in our stitching system. Figure 6(a) displays the dynamic stitching results under our approach. Figure 6(b) shows the stitching result under naive stitching without dynamic key frame generation. It can be clearly seen that Figure 6(d) contains significant errors, especially in the partially enlarged view of the “closed loop” (Figure 6(b) and Figure 6(d) - green box). In contrast, and with the help of dynamic key frame generation, our approach successfully handles the accumulation problem and the stitching result has good accuracy even in the area of the “closed loop” (Figure 6(c) and Figure 6(e) - red box).
Stitching with Real UAV Data
In the end, we use real UAV videos from the VIVID [18] and VSAM datasets [19] to demonstrate the performance of our approach. Figure 7(a) shows the stitching result of a thermal IR sequence. Figure 7(b) displays the stitching result with a building and trees. Figure 7(c) shows the stitching result along a dirt road in a wooded area, and Figure 7(d) displays the stitching result of bridge and road. Many challenges, such as sudden illumination changes (as shown in Figure 7(a)), camera rotation (as shown in Figure 7(a-d)), buildings and trees (as shown in Figure 7(b) and Figure 7(c)) and moving ground objects (as shown in Figure 7(b-c)) appear frequently in the real aerial videos. Moreover, the test data includes a large number of images, which is a challenge for accumulation error removal. The results demonstrate that our approach handles the above challenges and that it generates satisfactory mosaics successfully.

Aerial video stitching results of the VIVID CCD/IR UAV datasets and the CMU VSAM datasets
A high-speed aerial video stitching system is presented in this paper. Rather than using an advanced vision platform, such as FPGA or CUDA, our system runs on a normal personal computer at a speed of 150 FPS. This system is constructed using several key parts, including fast feature detection and binary feature description, a spatial and temporal coherent filter, and dynamic key frame updating. We demonstrate that the proposed coherent filter can significantly increase the speed of feature matching 20-fold while maintaining the robustness of the entire stitching system. Furthermore, based on the high-speed image matching, a dynamic key frame scheme is proposed in our system to handle the accumulation error. Experimental results with qualitative and quantitative analysis demonstrated the high speed and robustness of this system under difficult conditions in real UAV videos, including accumulation error, and motion and illumination changes. We believe that this approach has great potential for many applications in the field of robot vision. Considering the problem of Windows latencies, we would like to implement and evaluate our work in other real-time systems in future.
Acknowledgements
We would like to thank the anonymous reviewers for their valuable comments and detailed suggestions. The research of this paper is supported by the National Natural Science Foundation of China under Grant Numbers 61272288 and 60903126, the Foundation of ZTE under Grant Number 2014ZTE06-06, the Foundation of China Scholarship Council under Grant Numbers 201206965020 and 201303070083, the NSF grants IIS-CAREER-0845268 and IIS-1218156, and the Fundamental Research Foundation for the Central Universities under Grant Number K50510010007.