
Abstract
Multi-Agent systems have generated lots of excitement in recent years because of its promise as a new paradigm for conceptualizing, designing, and implementing software systems. One of the most important aspects of agent design in AI is the way agent acts or responds to the environment that the agent is acting upon. An effective action selection and behavioral method gives a powerful advantage in overall agent performance. We define a new method of action selection based on probability/priority models, we thereby introduce two efficient ways to determine probabilities using neuro-fuzzy systems and bidirectional neural networks and a new priority based system which maps the human knowledge to the action selection method. Furthermore, a behavior model is introduced to make the model more flexible.
Keywords
Introduction
The main aspect of complex MAS domains is the way agents cooperate to achieve a common goal based on their decisions. The more thoroughly agents select their actions; the better reward will be received. Action selection plays a powerful role in agent coordination and collaboration in complex domains such as RoboCup Simulation League [Kitano, H., et. al, 1997]. Previous work done on action selection models have mainly focused on the heuristic action selection utilities which resulted in stochastic and vague decision making in particular world states [Jinyi, Y., et. al, 2003; Lubbers, J., et. al, 1998; Stone, P., et. al, 2000b]. Probabilistic modeling leads to modeling the uncertainty of noisy MAS domains such as RoboCup soccer server [Chen, M., et. al, 2001] to logical decision making such as an action being selected. A priority based action selection method is described in [Lubbers, J., et. al, 1998], which focuses mainly on the action selection method but the probability and priority function were derived using heuristic knowledge (e.g. the game will get 0.6 offensive by such a pass). In [Stone, P., et. al, 2000b], the authors presented a technique of action selection using soft fuzzy functions and the respected formula of psvs ×(1 – ps)vf where ps is the probability of success and vs and vf are the values of succeeding and failing of an action respectively. In [Jinyi, Y., et. al, 2003], the authors used the same method, but in a more technical and analyzed way.
The main difficulty in action selection is calculating the probabilities of success of actions (ps) in an efficient way and assigning comparable priorities to different actions. We introduce four main approaches (two new techniques) that could be used in determining the action's probability of success and a goal based approach for the priority model, which generates comparable priorities based on flexible goals. Furthermore, opponent modeling is considered so that the best action for the current opponent is selected.
Probability/Priority Architecture Information
The model's block diagram is shown in Fig. 1. Basic actions are stored in agent's action repository. Based on the activation rules, some of the actions are activated for further analysis and are fetched in each cycle by the action generator. The action generator generates different possible types of each action. Each generated action is evaluated using the probability model. The actions with lower probability than the success threshold are not taken into consideration. The remaining actions are evaluated using the priority model. The action selector method combines the priority/probability results and will select the action with the highest reward.

Priority/Probability Model data block diagram
Model's action selection is based on analysis of several possible actions which are generated by the agent in each given cycle. As shown in the block diagram of the architecture, the agent has an action repository. Based on his current situation, a set of actions are activated for further consideration (e.g. clear the ball, pass, dribble… when ball is kickable).
Actions are activated using an action activation method. We define an action ACTIVE when the action's activation method is executed in the current situation. The activation method of an action is executed if all of the action's prerequisites are met in the current situation. For example, the dribble action's activation method is executed whenever the ball is kickable (which is one of the dribble action's prerequisites). Situations are defined by a trigger based definition of soccer scenarios as described in [Ajdari Rad, A., et. al, 2003] and Locker Room Agreement [Stone, P., et. al, 1998]. Here, we describe the situations as a combination of triggers. Each trigger can be defined as the following:
Therefore, the ball kickable situation sets pass, dribble, hold ball, clear ball, shot on goal,… ACTIVE since they all need the ball to be kickable, and the Kick In situation sets pass, clear,… ACTIVE. Dribble is not activated in the Kick In situation since it is considered as a foul.
We first define non-overlapping situations which are able to cover all of the possible game states (e.g. ball kickable and ball not kickable in different play modes). An agent selects one of them based on the current situation, therefore a unique set of action activation methods is selected and several actions are activated. For each activated action the action generator generates possible ways to perform the action (e.g. dribble 100, dribble 90,…). Simple heuristics can be implemented here to quicken the action generation process.
Probability Model
The probability of action's success is returned for each generated action. The main problem in determining an action's success probability is the actions generated being so different from each other in nature (e.g. hold ball and pass). To simplify the probability mining procedure we define each action as a number of independent actions so that the probabilities could be found separately and the whole probability could be calculated from a multiplication of several independent ones. Each action's accomplishment can be divided to n independent stages, each stage with an probability of success pn, therefore the whole probability of success can be calculated using:
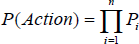
Assume a player decides to pass from vector x to vector y with a speed of v0, the probability of success can be introduced as bellow:

To simplify the procedure of probability mining from different actions in total, we could simply define several actions that happen in common in these actions (e.g. a ball being dribbled can be defined as a ball passed to oneself). To find out the probability of successfulness of a dribble you certainly need the probability that the ball is not intercepted in the midway which is also used in the passing skill. After each action was decomposed to several independent actions, a list of common independent actions and uncommon ones, which are rarely found (mostly in rigidly defined actions like the different actions performed by the goalie), are gathered and for each action, the probability is found. This technique speeds up the probability mining process and makes the probabilities of success comparable too, since they are all made of several mostly common actions which are extracted from a unique test bed. One of the most common probabilities needed is the probability of ball moving from vector X to vector y with a starting velocity v0 and a set of opponents and teammates without being intercepted. En fact, it is used in pass, dribble, clear ball, and moving the ball around the body.
Thus, we focus on this probability as the main example. We first overview two of the previous methods for this problem (Using Bayesian Learning and NN Approach). Finally, we introduce two methods which are based on ANFIS [Jang, J-S.R., 1992], which is a Neuro-Fuzzy network, and bidirectional Neural Networks which can be applied to this problem. A new bidirectional Neural Network is also designed for this problem. Further more, the results of correct classification for each method are discussed.
We start with our previous example (ball moving from vector x to vector y with the initial speed (v0)). To find out the probability of an action using this method we assume that a simple action's probability of success is dependent on several factors. We can assume that for the ball moving example, the probability of success is dependent on the distance which ball travels and the minimum angle which the opponents make with the ball trajectory from x to y. The worst case for the opponents positioning and location is selected on the field (they are all on the minimum angle line with the ball in this example). The parameters of the action are discreted in a way that doesn't have any effect on the further results that should be obtained. We divided the ball distance to the target point and the minimum angle from 1 to 32m (one meter segments each) and 5 to 180 (in 5 degrees each) respectively. The action is carried out several times for each discreted value and each time the success or fail is saved. The probability can be determined by the simple formula of:
P(action) = Number of Successes / Total Number of Tests
The probability table is then set for each discreted action and the probability derived from the above formula is inserted in the right cell of that table. During an online game based on the player's action decisions, the probability is fetched from the table values which were extracted before (during the test phase) and saved as heuristic knowledge table (i.e. Bayesian network [Neopolitan, R., 2004]).
There are several heuristics that should be taken into consideration to make the probability more reliable.
The main problem of this approach is being too much time consuming (the test took about four weeks), and the test parameters which can not be defined exactly since its not obvious for us what parameters are currently having the most effect on the test results. Discretion can not be done in large distances, because the behavior of probability function can not be described in the points between which we actually have little knowledge about. As the parameters grow, the discretion forces us to perform several more training sessions and collect more test data. Therefore, all the environmental space should be mapped and tested, e.g. the discretion in ball distance can not be done in large distances like 10 meters. Only 65 percent of correct classification was reported using the Bayesian learning method.
Artificial Neural Network Approach
This approach is described in two different methods. MatLab's NNTOOL was used as the software to carry out our experiments in here.
Straight method
We define a simple Feed forward network which acts as a world model data entry for the action which is to be done. The target is set to the success or fail output of the training test case. For our example of ball movement, a
Curve fitting
The problem with the first NN approach was having binary targets which led to an artificial neural network that responded semi-binary outputs. As we have mentioned before, a heuristic method for extracting the probability of an action discreted in large values is impossible, since the function behavior is not predictable. Therefore, we use NNs to predict the unknown probabilities based on the ones we know. The NN entries are large discreted values as inputs and the extracted probability (using the Bayesian method) as target. The network finds the best fitting curve to the probability function with a good estimate for unknown entries. This led to a performance rate of around 82.37 percent of correct classification which shows an 8 percent improvement in the results.
Neuro Fuzzy Approach based on ANFIS
In the NN approach we used the variables that seem to be responsible for the probability extracted. This leads to a kind of uncertainty about the data extracted. Hence, it is better to design the network by the maximum set of responsible values on the action being evaluated using adaptive Neuro fuzzy network approaches. Fuzzy Inference Systems such as ANFIS [Jang, J-S.R., 1992] are used in our experiments. Our ANFIS architecture applied to our problem is mentioned bellow.
We used the Fuzzy inference under consideration for a new example (ball moving from x to y with the starting speed of BallMax-Speed (2.7)). The network has 48 inputs (x1, x2, x3,…, x48). The inputs are X and y coordinates of 11 players and 11 opponents, the target vector and initial vector coordinates. The network had one output (Y). For our architecture which was a first-order Sugeno fuzzy model, for the sake of simplicity a common rule set with two fuzzy if-then rules is as following(five rules were used in our test):
If x1 is A1,1 and x2 is A2,1 and … and x48 is A48,1, then f1 = P1,1 x1 + P1,2 x2 +…+ P1,48 x48 + R1
If x1 is A1,2 and x2 is A2,2 and … and x48 is A48,2, then f1 = P2,1 x1 + P2,2 x2 +…+ P2,48 x48 + R2
The corresponding equivalent ANFIS architecture is as shown in Fig. 2.

ANFIS Architecture for extracting value of success
The figure can be described as follows:
Node with a node function:

Here the membership function for A can be any appropriate parameterized membership function such as the generalized bell function (gbell):
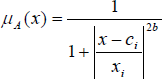



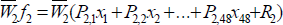

A Hybrid learning rule which combines Steepest Descent (SD) and the Least-Squares Estimator (LSE) for fast identification of parameters is applied. For the complete process see [Jang J-S.R., 1997]. Using ANFIS, the membership functions are extracted. The convergence time was not as fast as the NNs. Five membership functions were selected for each input (field is divided into five areas in each direction(x, y)).
The output resulted in around 85.6 of correct classification over the test data, which seems reasonable enough to depend on.
Since the neural networks we are using are finding patterns between the data and the probability of success, therefore pattern recognition systems are useful in extracting the probability of success. Up to now multi-layer feed-forward neural networks, have been vastly used in pattern recognition. It has been shown that the structure of unidirectional feed forward neural networks is not capable enough in pattern recognition systems where patterns are affected by noise [Seyyed Salehi, S. A., 2004]. On the other hand, empirical results show that brain uses a bidirectional process for pattern recognition [Koerner, E., et. al, 1999]. For enhancing the performance, bidirecting the process in neural networks seems a reasonable solution. The robust way of pattern recognition in human mind, especially in various pattern situations in inputs, represents the capability of this method in clustering signals in brain [Seyyed Salehi, S. A., 2004]. Latest Neuroscience researches show that bidirectional connections and interactions exist between the lower parts and the upper sensory processors in the cortex. It seems that brain, in response to sensory inputs, in addition to bottom up processes, adds knowledge to sense inputs using up down processes to reduce the difference between assumptions and imaginations to the reality of objects in the real world [Koerner, E., et. al, 1999; Koerner, E., et. al, 1997; Koerner, E., et. al, 2002]. The formation of attractors in the depth of basin of attractions is one of the characteristics of bidirectional neural networks, which creates the possibility to design more useful models when it is combined with feed-forward networks' characteristics [Seyyed Salehi, S. A., 2004]. Formation of attractors for pattern completion has been applied to different applications such as completion of hand written numbers [Seung, H. S., et. al, 1997]. It was shown by this method that appropriate training of a feed forward neural network with up down connections for correcting the input, can effectively rebuild the missed blocks in incomplete patterns.
Because of the desirable capabilities in bidirectional neural networks and their advantages over unidirectional neural networks in creation of attractors and pattern completion, we thereby design a unique bidirectional neural network and its train algorithm. In the NN approach we used the variables that seem to be responsible for the probability extracted. This leads to a kind of uncertainty about the data extracted. Hence, it is better to design the network by the most set of responsible values on the action being evaluated using bidirectional network approaches.
We used the bidirectional neural network approach for the same example and the same structure of ANFIS (ball moving from x to y with the starting speed of BallMax Speed (2.7)). The network has 48 inputs (x1, x2, x3,…, x48), the inputs are x and y coordinates of 11 players and 11 opponents, the target vector and initial vector coordinates. The network had one output (Y). The convergence time was even slower than the ANFIS network. The output resulted in around 84.1 of correct classification over the test data, which is a little lower than ANFIS. We will now briefly overview the designed bidirectional neural network.
Neural Network Structure
This network is a MLP with two recurrent connections, an output layer with nonlinear hyperbolic tangent functions and an input layer with linear functions.
The recurrent connection from the hidden layer to itself is for the purpose of long term memory, and the connection between the hidden layer to the input layer is for the reason of correcting the input in the next step.
This network is capable of correcting the incomplete patterns in several steps1
Respecting the data used in test and train data, the network can be defined as a
Fig. 3 shows the networks structure.

Neural network structure in the model
After applying the inputs to the network (the input can contain some missed blocks (players data or x, y coordinates) too), based on the formulas bellow the output is calculated in the nth iteration and the input is corrected in the (

In the above formula, γ will specify the completeness speed of the incomplete patterns, this coefficient is determined empirically in test and train phases. Setting and selecting a non proper value for this coefficient can lead to divergence in this neural network.
The initial values in the network are set by formula (11). The network is trained, by a certain technique which is derived from gradient based and back propagation based methods.

Formula Formula (10) shows the error calculation in the last iteration. Errors in previous iterations are calculated recursively based on formula (11).
Priority of actions is one of the most important parts of this model. The main particular aspect of the priority model is that priority of actions should be set up in a way so that they could be compared, e.g. a pass with priority of 6 has a real advantage over a dribble with a priority of 4 and results in a better overall team performance. Heuristic functions lack the comparability factor which blocks us from reasoning logically and leads to stochastic decision making. To maintain the priority model, we define a goal oriented approach for our priority model. A goal is the final state in every agent's decision layer, therefore each action which gets closer to the goal, receives the higher priority. A goal could be declared with several parameters such as distance ball travels, time that takes the ball to travel a distance, disorganization of defense, offensive moves, defensive actions, and etc.

where n = N0 − 1,…,1
To simplify the definition, three major parameters are selected, which gives us the capability of defining different goals:
By this way we can define many soccer goals based on different situations. For example a defensive game can be defined as {T: high, D: low, C: low} and similarly an offensive play with {T: low, D: high, C: high}, and {T: low, D: high, C: low} will imply long passes in the field.
To improve the results, we can generate fuzzy variables for each parameter of T, C, D between [0, 1] to make obvious changes between goals like super defensive mode, which the agent probably prefers to clear the ball rather than a normal defensive mode which a pass is selected as the first action. By this way, we can show which parameter is more important than the others, e.g. by {T: 0.1, D: 0.9, C: 0.05} we will show that an offensive mode is needed but we should not try to get close to the opponents' goal too much.
Since each action has an effect on the above goal values (e.g. dribbles consume more time (T) and passes less), each action can be assigned a priority based on the effect it has on the goal parameters. The action's effect values for each parameter T, D, C is calculated. Thus the priority can be assigned from a simple sum function in the form of below:
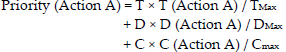
where T, D and C are the goal parameters and the variables TMax, DMax, Cmax are used to normalize the results and can be set to some simple constants like 40 cycles, 40m, and 40m respectively.
Since we have extracted the priorities based on a unique goal, which makes them comparable, and all the probabilities which were extracted show the probability of success, thus they can be combined by a simple multiplication rule (a simple utility function is used, although more complex utility functions can be used here).
In our example, assume we've got a player with the probability of success of 0.88 for the highest pass option generated and 0.96 for the highest dribble option generated. The goal is described as {T: 0.9, D: 0.6, C: 0.9}.
The Goal data extracted from the actions can be described as in Table 1. Thus, based on the action's reward, the pass will be selected.
T, D and C variables of an example pass and dribble. The final reward function is calculated by the priority based function.

T, D and C variables of an example pass and dribble. The final reward function is calculated by the priority based function.
As we have described throughout this stage a system of action selection is introduced. The system lacks flexibility due to the test environment on which the model is based. Since probabilistic modelings are usually based on fixed opponents, the system responds the best to the opponent which was used in the training sessions. We described that powerful opponents were selected to help the probability extracted converge to the real probability with the least error. Thereby we introduced the need of thresholding (i.e. using a Threshold). The opponent behavior model can be described in two major bases:
Thresholding
The online coach can model the opponents' response to different actions. Suppose that there is fixed threshold for a successful pass. The teammates can start decrementing the pass threshold by a percentage each time a successful pass is recognized with the current threshold, and adding an amount of percentage by each failure they recognize in their passes. Hence the threshold will eventually converge to the success threshold for the current opponent. The agents could use a simple memory and updating process model like the one used in [Stone, P., et. al, 1995] to find out different thresholds of success for the current match. The online coach will be used to coordinate between different thresholds found by players, and will announce each player the threshold which the coach has obtained by analysis and using the mean threshold that the players have extracted (which is sent to coach by players) up to the current time. For the increment/decrement method, Reinforcement Learning [Riedmiller, M., et. al, 2001] can be useful here since it can be defined as a matter of reward/punishment process.
Goal Designing and Goal Exchange
In each cycle the goal attributes define the priority assigned to each action. An efficient goal leads us to play better during the game. Therefore a thorough goal selection method results in better team performance. Deciding a goal by agents themselves will result in chaotic plays since the data they receive has the kind of uncertainty which blocks them from selecting a global goal for the game. The coach agent can help a lot in this state by using statistical functions and defining simple scenarios which our team is going to obey. Moreover a simple but powerful behavior modeling can be defined.
Suppose that the coach is keeping track of certain successful actions. The mean time of these actions could be a good replacement for the T variable in our next goal. The C and D variable can be changed by the same formula respectively. This will result in more successful actions generated since the successful actions will be assigned an average of higher priority than others. The coach can keep track of successful actions in an amount of time which the results are reliable enough to depend on, (say 1000 cycles), and send the new goals to the players based on the analyzed data.
Experimental Results
To test the quality of the model, several actions were generated, and fixed goals were defined. The goals were defined in a way that the results were understood without ambiguity by human knowledge.
We used {T=0.9, C=0.9, D=0.9} which implies getting to the opponent goal with long passes. Player's actions were recorded and the successful ones (long passes and action which ball moved long distances) were considered among the whole number of actions.
The results showed that more than 91 percent of the actions selected by players were actions which the ball moved more than 20 meters (which was the threshold for considering an action as large distance covering one). Therefore, clear balls were sometimes given the higher priority over simple dribbles or holding ball actions. The results were taken in 10 simulated games with the above fixed goal. Table 2 has the complete test result's data.
Results of actions performed by player in ten 6000 cycle game with the fixed goal of long distance passes
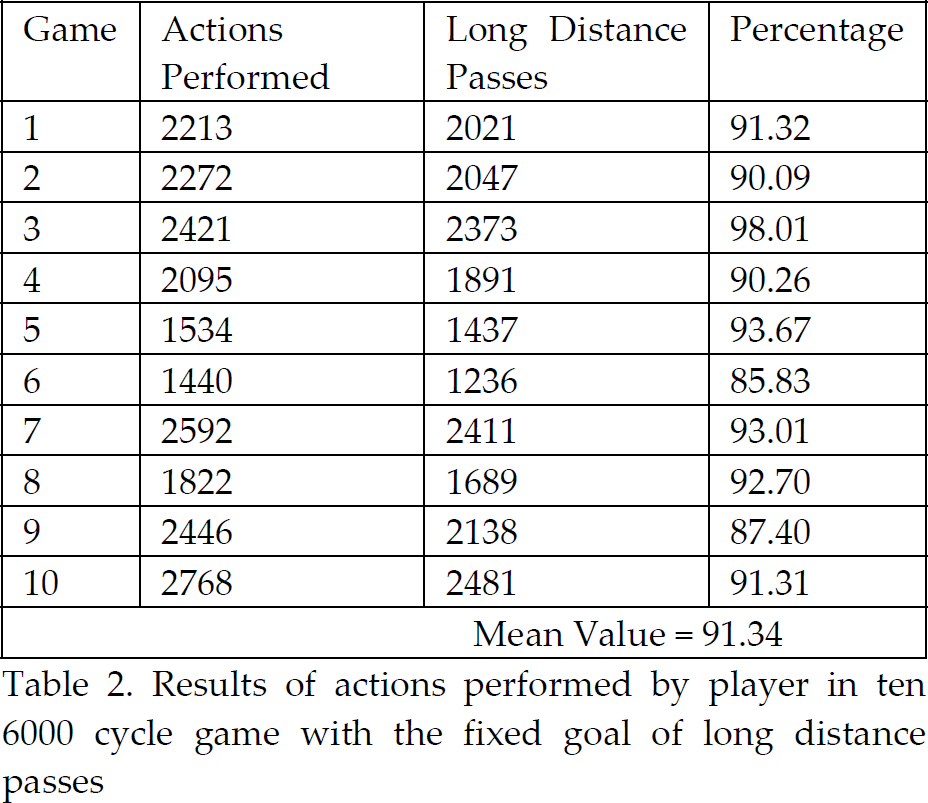
Results of actions performed by player in ten 6000 cycle game with the fixed goal of long distance passes
To test the model's robustness to different goals, 60 different goals were selected. For each goal, the mean correction percentage of 10 full games was recorded (the test took more than 1 month). The results showed that as much as the goal definition is clear and more understandable for human knowledge the percentage of correct actions were higher. A vague goal, which is not clearly understood by human knowledge, was defined. The results for this goal were around average and about 75 percents. The complete results showed that more than 88.9 results were accepted as successful decision making. More work is currently ongoing to derive more accurate results.
Results of Model's Robustness Test

As we have mentioned before the new methods classify correct actions more than the other methods. Table 4 shows a comparison of the classifications in these methods.
Probability Model and Classification Results with Different Methods

Probability Model and Classification Results with Different Methods
A new architecture of action selection in agent based systems was introduced in this paper. Most parts of the technique were dedicated to the reduction of uncertainty effect and the creation of a robust team against stochastic agent world. The new architecture provides new ways of determining action's probability of success and a new method of priority based selecting by defining goal functions.
Currently, goal function assignments define the way team acts on the field. Analysis showed that by changing goal parameters the game could actually change a lot. Therefore adaptive filters and reinforcement learning method could be applied for finding out the optimum value of goal parameters in a RoboCup soccer simulation game.
Future work is currently based on optimizing and quickening different methods established in the paper. Some parts of the architecture like the action generation model consumes lots of time during a soccer simulation game, therefore based on several game situations removal functions and methods are needed. Moreover, works on the behavior model or the goal exchange part can be expanded based on opponent modeling systems such as IMBBOP [Stone, P., et. al, 2000a] or online probabilistic opponent model recognition systems [Riley, P., et. al, 2002].
RoboCup simulated soccer presents many challenges to reinforcement learning methods[Stone, P., et. al, 2001], including a large state space, hidden and uncertain state, multiple agents, and long and variable delays in the effects of actions. Comparison with reinforcement learning methods, which considers delayed rewards, is one of our major future works.
Footnotes
1
The number of steps is dependent on the data and will be determined empirically in the train phase