
Abstract
Current robotic systems are expected to interact with unknown environment where controlling the interaction forces becomes an important issue. We propose a new control technique for force control on unknown environments that tunes the force controller based on online estimation of the environment parameters. However, the proposed approach overcomes the need for precise estimation of environment parameters, which are needed in many system identification-based force control approaches. This framework uses an artificial neural network (ANN)-based proportional-integral (PI)-gain scheduling force controller to track the desired force by adjusting control gains such that error in parameter estimation can be accommodated. Experimental results are presented to demonstrate the efficacy of the proposed control framework. Finally, the advantages and limitations of the proposed controller are discussed.
Keywords
Introduction
Robots are no longer confined to the structured factory environments to work on well-designed automation tasks such as welding, machining and assembly operations. They are now expected to function, preferably in a largely autonomous manner, in unstructured, dynamic and uncertain environments. Examples of such tasks include but are not limited to mine diffusion, cleaning-up of hazardous material, space exploration, sample collection in geological exploration, search and rescue, assistance in rehabilitation and so on. In most of these applications, a robot, which could be, for example, a robotic manipulator or a walking robot dynamically interacts with an unknown environment that could be time-varying. In order to ensure a smooth and precise interaction with the environment, it is necessary to develop effective force control strategies that can function well even when the robot does not know its environment.
Historical perspective and state-of-the-art in robot force control has been presented in (Whitney, D.E., 1985). An overview of the recent advances in force control of robot manipulators has been presented in (Yoshikawa, T., 2000). Previous work on force control techniques on unknown environments can be summarized as follows. Neural network has been used with impedance force controller to compensate for uncertainties in robot dynamics and environment stiffness (Jung, S. & Hsia, T.C., 1995, Jung, S. & Hsia, T.C., 1998, Jung, S. & Hsia, T.C., 2000, Jung, S., Yim, S.B. & Hsia, T.C., 2001, Katic, D. & Vukobratovic, M., 1998). Fuzzy neural position/force controller (Kiguchi, K. & Fukuda, T., 2000) has been developed to apply desired force to an unknown environment by adjusting the force control direction using a fuzzy vector method. Adaptive control is another technique used to regulate the contact force on an unknown and changing environment. Parallel force/position control with an adaptive mechanism on the stiffness coefficient is developed to allow force tracking (Chiaverini, S., Siciliano, B. & Villani, L., 1998). Self-tuning adaptive controllers are used to update PID gains based on the estimated dynamic model of the environment (Wang, Q. & Broome, D.R., 1991, Wang, Q., Broome, D.R. & Daycock, I.T.W., 1991). Several controllers with stiffness adaptation have been proposed to achieve precise force control on unknown environments (Carelli, R., Kelly, R. & Ortega, R., 1990, Canudas de Wit, C. & Brogliato, B., 1994, Yao, B., Chan, S.P. & Wang, D., 1994, Singh, S.K. & Popa, D.O., 1995, Villani, L., Canudas de Wit, C. & Brogliato, B., 1996). An adaptive impedance controller with the capability of compensating for uncertainties in environment stiffness as well as the robot dynamic model has been proposed (Jung, S., Hsia, T.C. & Bonitz, R., 2004). Adaptive fuzzy control scheme adjusts the membership functions of the fuzzy controller by learning the environment parameters and adapting the control mechanism (Tarokh, M. & Bailey, S., 1996).
In adaptive and neural network-based control approaches, unknown environment has been modeled as a linear spring. Force control assuming just a spring-like environment may give an underdamped or overdamped response, since all mechanical systems inherently possess some form of damping. The negligence of the damping property of the environment is likely to be detrimental towards developing an effective force controller. This problem is partly resolved by a force control technique that integrates system identification methods with impedance control.
This is an effective strategy when real time estimation of environment parameters is possible (Love, L.J. & Book, W.J., 1995). Good force tracking is achieved with an impedance controller if stiffness and damping parameters can be estimated precisely. A weighted recursive least square (WRLS) scheme has been implemented to estimate the environment parameters in (Love, L.J. & Book, W.J., 1995). The above technique gives reasonably accurate stiffness estimates without persistent excitation of the reference signal. However, reliable damping estimates are possible only with persistent excitation (Vre, T.L., Xiao, J., Brunyninckx, H. & Gersem, G.D., 2005, Erickson, D., Weber, M. & Sharf, I., 2003). In many practical situations, giving a persistently exciting force reference to estimate damping is infeasible. For instance, persistent excitation may cause permanent damage when the manipulator is in contact with a fragile environment. When the environment is continuously changing, using a persistently exciting reference signal to probe for environment parameters does not result in good force tracking.
The focus of this paper is to advance the technique of integrating system identification methods with force control in such a manner that it does not require persistent force excitation and consequently, precise estimation of environment parameters. The proposed control framework uses an artificial neural network (ANN) based PI gain scheduling direct force controller that has the ability to track the desired force by adjusting control gains. The control gains are determined based on online estimation of the environmental parameters (i.e., stiffness and damping) that is performed in parallel with the control computation, and thus does not introduce any destabilizing effect on the control performance. The ANN, which is trained offline, adjusts the control gain online. The new control framework for force tracking on unknown environments combines the benefit of system identification technique with the robustness of neural network-based methods. In this framework the ANN is not used to compensate for uncertainties in the robot model or to classify the impedance of the unknown environment as presented in (Jung, S. & Hsia, T.C., 1998, Katie, D. & Vukobratovic, M., 1998). A WRLS scheme is used to estimate the impedance parameters of the environment. The ANN is used as a gain scheduler for predicting the best control gains depending on the environment parameter estimates. The presented method overcomes two major limitations in this field: 1) it does not ignore environmental damping, and 2) it does not require persistent force excitation for environmental parameter estimation.
This paper is organized as follows: Section II discusses the most relevant previous work on using impedance control with system identification methods. Section III presents our control approach that includes the overall control framework, system identification technique, ANN for predicting control gains, and the gain switching strategy. Section IV describes the experimental setup and the results obtained with the real-time implementation of the proposed controller. Section V presents a brief discussion on the performance of the controller. Section VI concludes the work with some remarks on the efficacy of the proposed controller.
Background and Motivation
We first discuss how an environment parameter estimation technique based force control scheme works as has been presented in (Love, L.J. & Book, W.J., 1995, Erickson, D., Weber, M. & Sharf, I., 2003). (Love, L.J. & Book, W.J., 1995) specifically deals with an impedance control approach using environment parameter estimates. Recently, the authors in (Erickson, D., Weber, M. Sharf, I., 2003) compare four different algorithms (indirect adaptive control, model reference adaptive control, impedance control and an offline signal processing approach) for estimating contact stiffness and damping during robot constrained motion.
An impedance controller specifies the dynamic relationship between position and force at the robot end-effector.

M
t
, B
t
and K
t
are the target mass, damping and stiffness parameters, respectively. x is the robot position and F is the contact force. x0 is the initial position of the robot end-effector. For a single degree of freedom contact geometry, robot's natural frequency and damping ratio are functions of the target impedance parameters:

When the robot is in contact with a known environment, selection of the impedance parameters is straight forward. But, when the environment is unknown the natural frequency and damping ratio are given by

where K
e
is the stiffness of the environment. The target damping is specified assuming that damping is a linear combination of mass and stiffness (Raleigh damping)
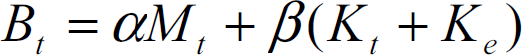
where α and β are the damping coefficients. Instead of assuming a specific form of damping, the authors in (Erickson, D., Weber, M. Sharf, I., 2003) explicitly estimate environment damping. Hence, the natural frequency and the damping ratio are given by

where B e is the environment damping. In such a case, selection of the robot target impedance parameters requires precise estimation of the environment stiffness and damping. While accurate stiffness estimates without persistent excitation of the reference signal are possible (Love, L.J. & Book, W.J., 1995), precise estimation of damping requires persistent excitation of the force reference signal (Erickson, D., Weber, M. Sharf, I., 2003).
As observed before, using persistent excitation is infeasible in many practical applications. On the other hand, neglecting the damping property of the environment or estimating it inaccurately does not result in precise force control within the current environment parameter estimation technique based force control scheme. In order to address the above conflicting requirement, i.e., we need precise force control but we cannot apply persistent excitation, we propose a new control technique that does not require persistent excitation and hence precise estimation of stiffness and damping for accurate force control.
Control Architecture
In order to achieve good performance with a force controller for different environments, it is necessary to adjust control gains in accordance with changes in the environment parameters. This is accomplished using the control architecture as shown in Fig.1. Force (F) and position (x) sensor data is given to the system identification block which estimates the environment parameters. The ANN is first trained offline using a training data set consisting of system parameters (e.g., stiffness and damping coefficients) as inputs and PI control grains for desired force control performance as outputs. Afterwards it is used in conjunction with the system identification module to predict the best gains for the environment based on the estimated parameters in real-time. Precise environment parameter estimates are not required by the ANN to predict the control gains. As a result, no persistent excitation of the reference force signal is necessary in this scheme. A gain switching mechanism is used to provide smooth control input for bumpless transfer of control gains.
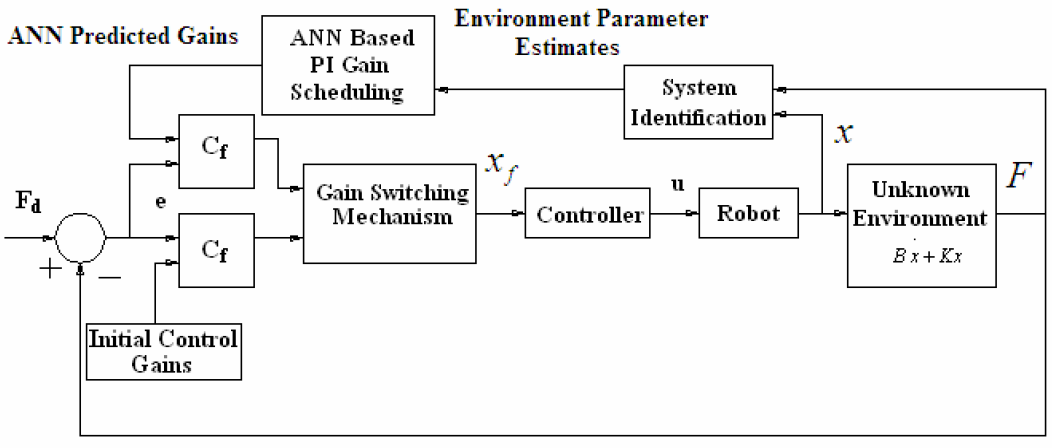
Block Diagram of Control Architecture
In what follows, we present the environment parameter estimation technique, design of the ANN-based Pi-gain scheduling module and the force controller with a gain switching mechanism.
The robot environment is represented as a linear spring-damper system, which is similar to the work done in (Erickson, Weber & Sharf, 2003):

where B is the damping coefficient, K is the stiffness. An auto regressive exogenous (ARX) model is used to estimate the stiffness and damping parameters of the environment (Ljung, L., 1999, Soderstrom, T. & Stoica, P., 1989, Norton, J.P., 1986, Juang, J.N., 1994). ARX model is one of the simplest parametric structures and is chosen as the first estimation technique for our problem. The parameters of the ARX model are estimated using a recursive least-squares (RLS) method. RLS method is one of the most well-known algorithms used in adaptive filtering, system identification and adaptive control. Its popularity is mainly due to its fast convergence speed (Wang, Q., He, Q.P., Qin, S.J., Bode, C.A. & Purdy, M.A., 2005).
By defining δ
x
= x – xo and noting that the environment is initially stationary, equation (1) can be rewritten as

equation (2) is discretized using a bilinear transformation. equation (3) shows the environment dynamics in the discrete-time domain.

T is the sampling period and z−1 represents a shift of one step in the time domain. Let k describe the time-step index. equation (3) can then be represented as a difference equation:

where

equation (4) can be cast into the regressor form as follows:

where θ[k] represents the parameter matrix, φ[k] is the regression vector, and y[k] is the output vector. The RLS solution to find parameters A1 and A2 is found using equation (7).

where the gain factor G[k] determines how the current prediction error affects the update of parameter estimation. G[k] is determined using Equation(8):

where Λ is the forgetting factor, which influences the weightage given to earlier data relative to the newly acquired data. P[k] is the covariance matrix of estimated parameters, which is calculated using Equation(17).

The initial guess for the covariance matrix P and the forgetting factor Λ are specified by the user. For our application, Λ is chosen to be 0.999. Once the parameters A1 and A2 are estimated, the estimates of environment parameters B and K are obtained by solving the set of linear equations (5).

An ANN based PI gain scheduling direct force controller is expected to provide better performance than a traditional PI force controller because of its ability to adjust the control gains for different environment parameters. The advantage of neural networks lies in their ability to map complex relationships between input and output data using patterns learned during training. There have been some successful implementations of ANN based PI gain scheduling in aircraft control, robot control, and speed control of D.C. motors (Xinmin, D., Zhigou, Z. & Gin, L., 2003, Jonckheere, E.A., Yu, G.R. & Chen, C.C., 1997, Wang, D. & Broome, D.R., 1994, Kulic, F., Kukolj, D. & Levi, E., 2000). It has been found that a multi-layer ANN with back-propagation method works well in most control applications. In this work, we use environment parameters
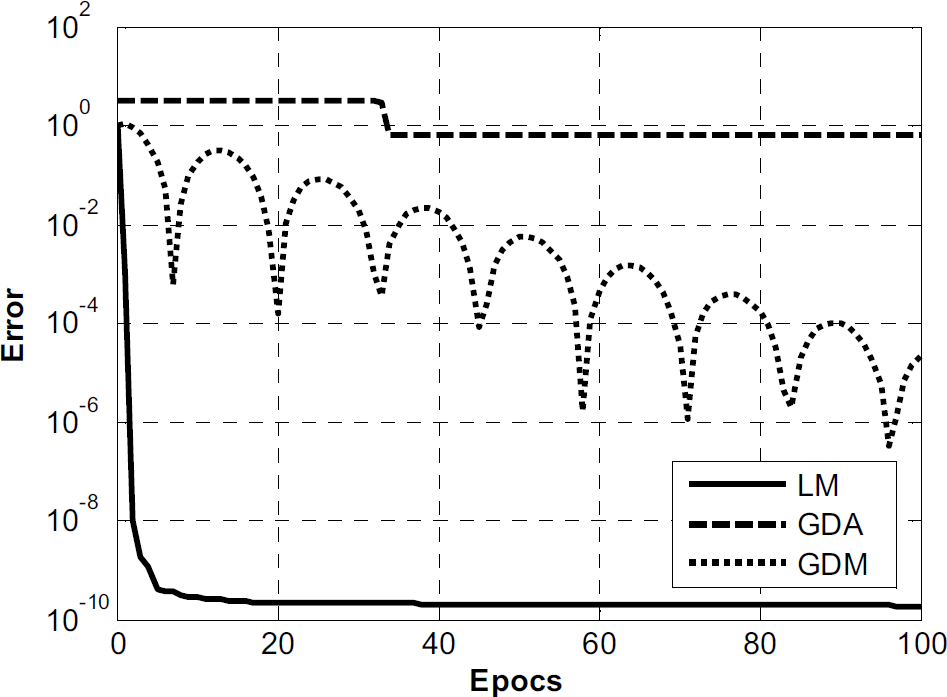
Learning Curves for Different Neural Network Methods for P Gain

Learning Curves for Different Neural Network Methods for I Gain
LM backpropagation method showed minimum error for both Proportional (P) and Integral (I) gains compared to other neural network methods. Hence, LM backpropagation method is selected for our application.
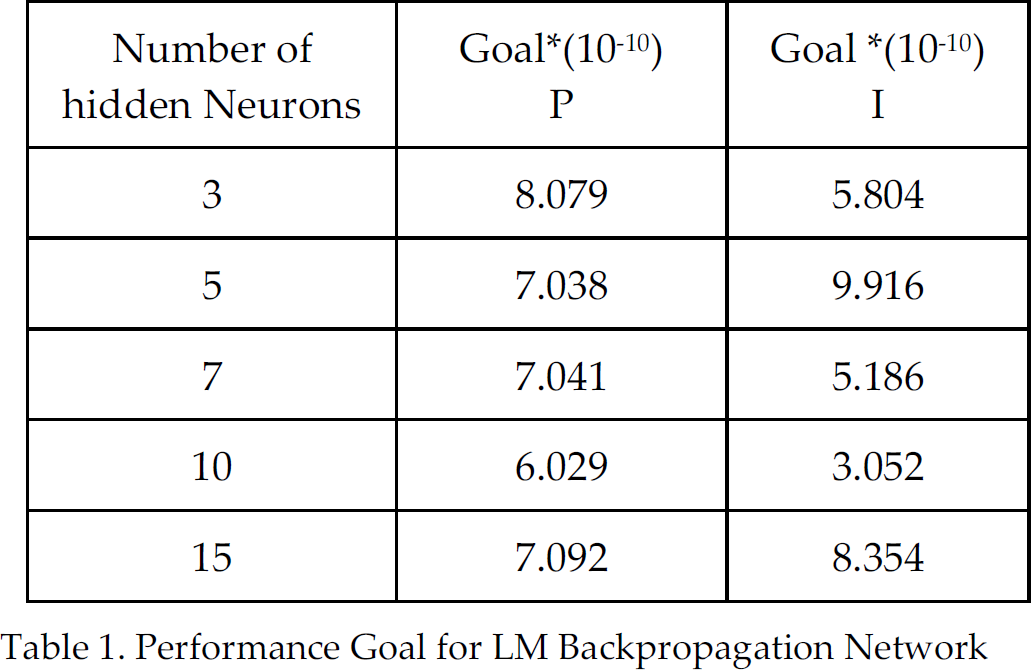
To determine the appropriate number of hidden neurons for LM backpropagation, a performance evaluation is done with different hidden layer sizes. LM backpropagation networks with 3, 5, 7 10 and 15 hidden neurons are evaluated. The performance goal is selected as 10−10. All of these networks achieved performance error close to 10−10 but networks with 10 neurons for Proportional (P) gain and 10 neurons for Integral (I) gain show the best performance (Table I). Thus, a two-layer feed-forward network with 10 neurons for P gain and 10 neurons for I gain and one hidden-layer for each gain is currently sufficient for our application.
Performance Goal for LM Backpropagation Network
We use a controller that allows us to directly specify the desired force as shown in Fig.1. This controller uses an inner position loop for force control similar to what is described in (Sciavicco, L. & Siciliano, B., 1996). Using inverse dynamics control, manipulator dynamics are linearized and decoupled via feedback.
The dynamic equation of the robotic manipulator can be written in the form

where u is the input to the manipulator, J is the Jacobian matrix and F is the contact force at the end effector. M(q) is the mass matrix of the manipulator, 
which leads to the system of double integrators

In Equation (13), y represents a new input where system (11) is linear and decoupled. The new control input y is designed so as to allow tracking of the desired force F
d
. To this purpose, the control law is selected as follows:
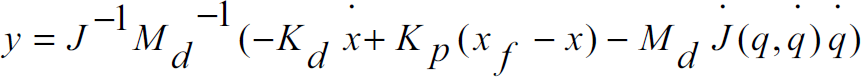
where x
f
is a suitable reference to be related to force error. M
d
(mass), K
d
, (damping), and K
p
(stiffness) matrices specify the target impedance of the robot, x and 
By substituting (14) into (15), we obtain

Equation (16) shows the position control tracking of x with dynamics specified by the choices K
d
, K
p
and M
d
matrices. The matrices M
d
, K
d
and K
p
are chosen to be positive, hence the controller is stable. Impedance is attributed to a mechanical system characterized by these matrices which allows specifying the dynamic behavior. Let F
d
, be the desired force reference. The relationship between x
f
and the force error is expressed in (17) as:


where P and I are the proportional and integral gains, respectively, e is the force error and F
h
, is the actual applied force. Equations (16)–(18) are combined to obtain the following equation:

We can observe from (19) that the desired force is achieved by controlling the position of the manipulator.
Initial PI gains for the force controller are chosen arbitrarily. When the performance of the initial PI gains is found to be unsatisfactory, control gains are switched to the values predicted by the ANN. Instantaneous switching of control gains, however, may sometimes destabilize the system or cause undesired transients in the force response. Hence, to achieve satisfactory force response, a smooth control signal has to be retained during switching. Therefore, gain switching can be viewed as a bumpless transfer between two PI controllers with different gains. A Bumpless transfer strategy for switching between a manual controller and an automatic PI controller for a simple first order linear system is presented in (Graebe, S.F. & Ahlèn, A., 1995). This strategy is modified to achieve bumpless transfer between two PI controllers.
The PI control action in equation (17) can be modified as

where x
fi
(t) is the position reference determined using the initial gains Pi and Ii. Xi(t) represents the integral action and Xio is the initial condition of the error integrator. If ts is the time of switching, then equation (20) can be used to find the position reference just before the time of switching
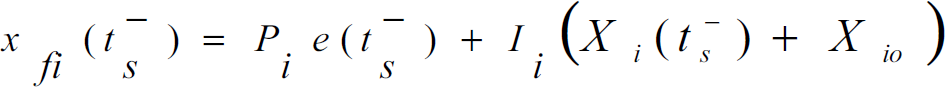
Let the gains predicted by the ANN be represented as Pa and Ia. The position reference just after switching is given by

where Xa(t) represents the integral action and Xao the initial condition of the error integrator associated with the ANN gains. Note that the force error does not change significantly during the switching procedure since the sample time for the controller is very small (0.001 seconds). Hence,

The integral action associated with the ANN gains is reset during switching so that

If the initial condition of the error integrator associated with the ANN gains is defined as
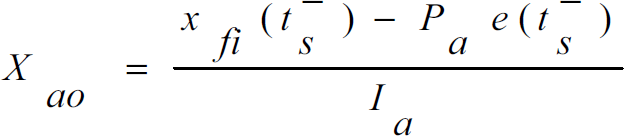
then substituting the relations (23)–(25) into (22) we can observe that

This relation ensures that the position reference is indeed continuous during switching which guarantees bumpless transfer.
Experimental Setup
To evaluate the performance of the proposed controller, a test bed is developed as shown in Fig. 3 and Fig. 4.

PUMA in contact with a mass-spring-damper system

Mass-spring-damper system
The test bed is a PUMA 560 robotic manipulator in contact with a mass-spring-damper system. The experiments presented here will likely indicate the efficacy of the robotic controller in applying contact forces in several application domains such as environment exploration using a robotic arm, walking on different terrains by a walking robot and so on.
In our test-bed, the PUMA controller has been modified into an open architecture system to allow implementation of advanced controllers. In addition, PUMA is interfaced with Matlab and Real-time Workshop to allow fast and easy system development. The PUMA's capability is augmented by instrumenting it with a force/torque sensor (ATI Gamma six axis force/torque sensor) to obtain force feedback. Position data is obtained using encoders which measure the joint angles of the robot. The position of the end-effector is determined using the forward kinematic relations for the robot. These encoders cannot be seen in Figures 3 and 4 since they are embedded inside the robot. The mass-spring-damper system consists of compression springs (McMaster-Carr) in parallel with an adjustable shock absorber (Misumi, USA) sandwiched between two aluminum plates. The stiffness of the system can be changed by using different springs or by changing the number of springs. The damping of the system can be altered by adjusting a control knob on the shock absorber. Thus different environments with varying stiffness and damping characteristics can be created.
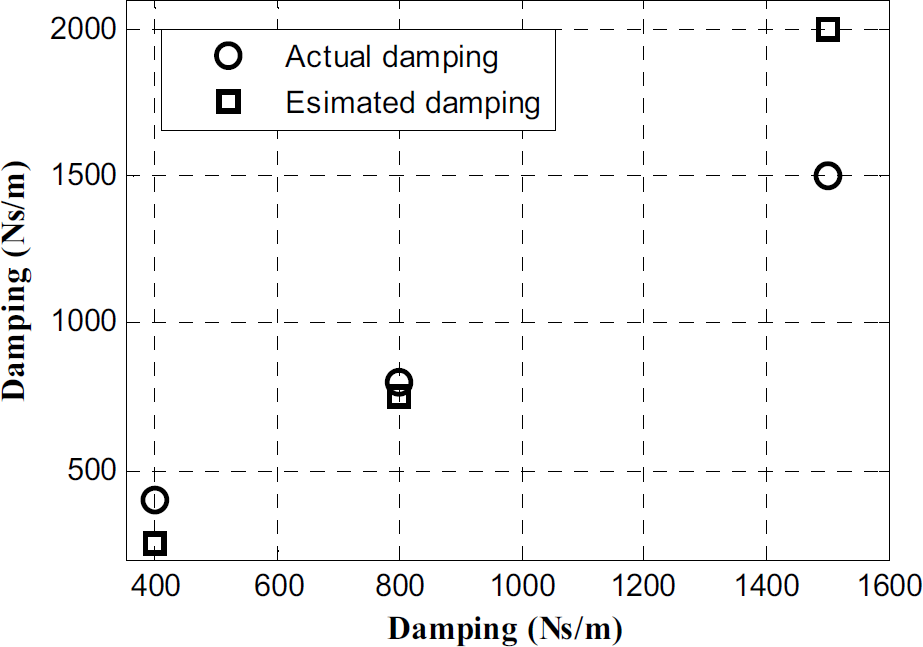
To test the efficacy of the system identification technique, a series of experiments were conducted with 15 different environments. Stiffness range of the environments was from 2200N/m to 14600N/m and damping ranges from 400Ns/m to 1500Ns/m. A traditional PI based direct force controller was used to generate a constant contact force on each environment. For each environment, PI gains were tuned to have a settling time less than 5 seconds without any overshoot. During the experiment, force and position data was recorded. ARX model was used to estimate environment parameters from position and force data. Estimated stiffness and damping coefficients for each environment were compared with the actual values. Fig. 5 shows a plot of the actual and estimated stiffness values for five different environments and Fig. 6 shows a plot of the actual and estimated damping coefficients for three distinct damper settings. It can be observed from Fig. 5 and Fig. 6 that the estimated environment parameters are not very accurate. Clearly the estimated values of the damping coefficients are significantly different than the actual values. This is because a constant force reference was used without persistent excitation during the experiment. As a result, the earlier work in this field could not use this data obtained from a constant force reference in an impedance force controller – they needed persistent excitation for their schemes.
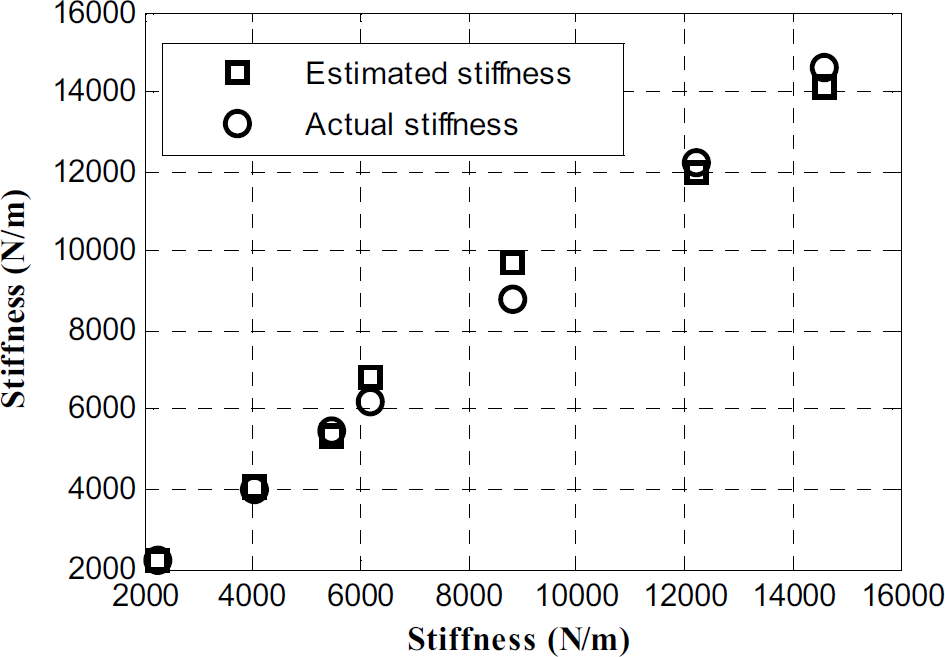
Comparison of Actual and Estimated Stiffness
Comparison of Actual and Estimated Damping
We observe from Fig. 5 and Fig.6 that the estimates from a constant force reference, even though differ from the actual values, follow the same trend as the actual values. In other words, when the actual value of stiffness or damping increase for different environments, so do their constant force reference based estimates. Also note that the estimates are repeatable for all the environments.
As a result, we can conclude that the constant force reference based estimates of the environment have the ability to discriminate among environments with different stiffness and damping coefficients, even though they do not provide the correct absolute values. We utilize this discriminating property to train an ANN to predict control gains based on these estimated stiffness and damping parameters.
Three experiments were performed to demonstrate the efficiency of the proposed controller. Environments which were not used for neural network training were selected for all three experiments.
In the first experiment, we demonstrate how the initial unsatisfactory control gains can be autonomously modified by the proposed controller when contacting an unknown environment. The stiffness and damping coefficients of the environment were 5450 N/m and 400 Ns/m, respectively. Initial PI gains for the controller were chosen so that the actual force did not reach the desired reference. This could be a scenario when the robot contacts an unknown environment with control gains that are not large enough to achieve the desired force control objectives. When the desired force was not tracked, the controller switched the PI gains to the values predicted by the ANN through the gain switching mechanism. In Fig. 7, initial PI gains were used for the controller between points A and B. When the controller realized that the initial gains were too small to reach 15N, the ANN gain scheduler used online estimates of the environment parameters from the ARX model to predict optimal gains. At point B, the estimated values of the environment stiffness and damping were 6800 N/m and 215 Ns/m. From point B, ANN predicted gains were used by the controller to track the reference force. As can be seen from Fig. 7, force tracking was good when the ANN predicted gains were used for the controller. All of the above processes were performed autonomously and in real-time.

Force response for stable initial gain
In the second experiment, we demonstrate how the proposed controller can autonomously recover from an unstable situation. The stiffness and damping coefficients of the environment were 6625 N/m and 1500 Ns/m, respectively. Initial PI gains were chosen so that the force response was unstable. This could be the case when the robot contacts an unknown environment with unstable control gains. As in the first experiment, the same technique for estimating environment parameters, predicting and switching control gains was used. It can be observed from Fig.8 that when the controller realized that contact was unstable, the ANN predicted stable gains based on online environment parameter estimation (environment parameter estimates at the time of switching were 6200 N/m and 2000 Ns/m) that stabilized the controller and allowed it to track the desired force trajectory. All of the above processes were performed autonomously and in real-time.
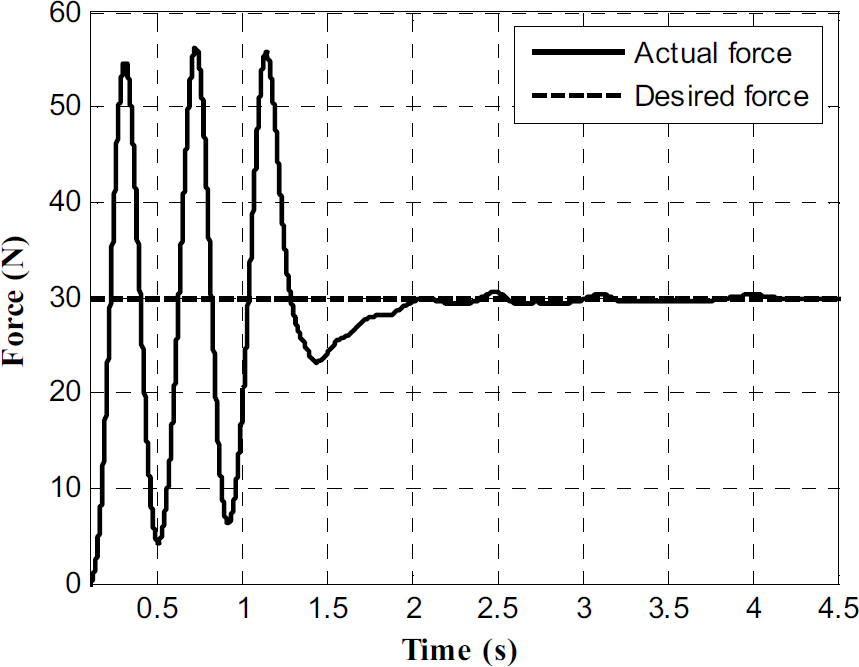
Force response for unstable initial gains
In the third experiment, we create a situation where the environment parameters suddenly change during the application of force. This experiment has two parts. In the first part, a traditional fixed gain force controller is used to apply a force of 20 N on a spring (stiffness 2240 N/m). The gains of the controller are tuned to achieve satisfactory force response. Fig. 9 shows a plot of the desired and actual forces.
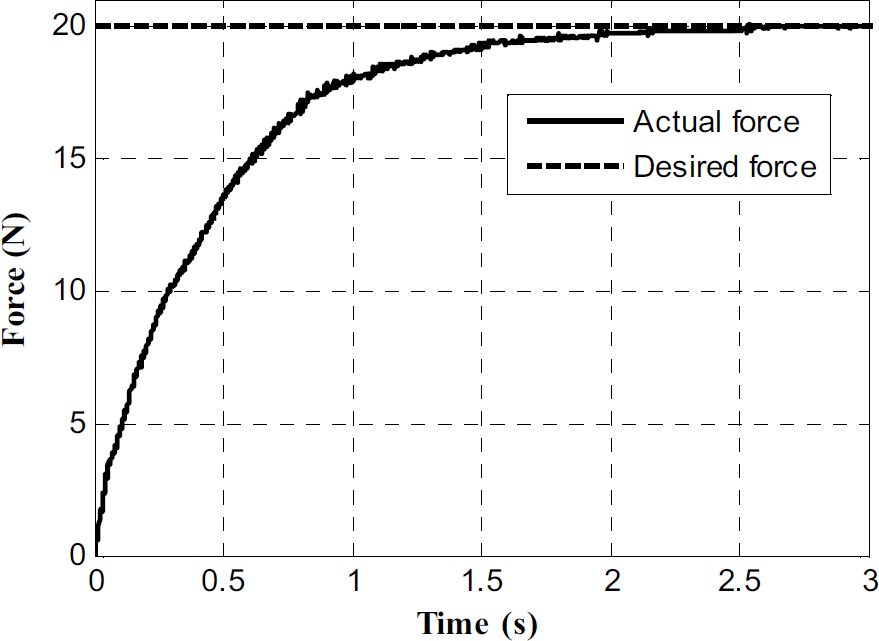
Force response for a spring
In the second part of the experiment, another spring and damper (shown as Spring 2 and Damper in Fig. 10, stiffness 8800 N/m and damping 1500 Ns/m) are added to the spring used in the first part of the experiment (shown as Spring 1 in Fig. 10) such that when the robot compresses the first spring to a certain distance, it contacts the new spring and the damper. This change of environment was unknown to the robot.

Schematic of experimental setup
The desired force to be applied on the environment is set at 70N. Initially the robot is in contact with just Spring 1, but as the end effector moves to apply the desired force, it contacts Spring 2 and the Damper. Thus the environment stiffness and damping change during the control task. The proposed ANN based gain scheduling controller is used in this experiment with the initial gains selected from the first part of the experiment. Fig. 11 shows a plot of the force response for this system using the proposed controller.

Force response for variable environment parameters
It can be observed from Fig. 11 that the system will be stable as long as the robot is in contact with Spring 1 (point A to B). But as the robot moves forward to reach the desired force, it becomes unstable when it contacts Spring 2 and damper (point B). This is because the initial gains are tuned for Spring 1. This can be observed from the plot of the force response (point B to C). During this time, however, the gain scheduling controller estimates the environment parameters (stiffness and damping estimates are 13000 N/m and 2200 Ns/m respectively), selects suitable PI gains and subsequently stabilizes the system (point C).
Most of the work related to control of contact force on an unknown environment focuses on developing control algorithms that require accurate estimation of environment parameters. To achieve effective force control using these methods, stiffness and damping parameters of the environment have to be estimated precisely. Precise estimation of both stiffness and damping parameters requires persistent excitation of the force reference. In many practical applications, it is infeasible to use such a reference signal. To overcome this limitation, we used a step input to estimate environment parameters. Response to a step input can be used to estimate reasonably accurate stiffness values, but damping estimates tend to be erroneous (7% − 33% error). Damping estimates are inaccurate with a step input, but the trend in the estimates is consistent with the actual damping variation, i.e., as the damping increases, the estimated damping values also increase. The time taken by the WRLS algorithm to converge to the estimates is dependant on the forgetting factor. A low forgetting factor quickens the convergence, but is more susceptible to noise whereas a higher forgetting factor takes longer to converge but is less susceptible to noise.
Effective force control using inaccurate parameter estimates was achieved by training an ANN to map the relationship between environment parameter estimates and the suitable control gains. The environment parameters are estimated continuously, but the control gains are switched based on performance. Since the ANN was trained on estimated values of the environment parameters (as opposed to their actual values), inaccuracies in estimation did not cause problems.
However, it must be pointed out that the proposed control approach overcomes the need for persistent excitation at the expense of training a neural network. There could be situations where such training data may not be readily available or developed, and consequently the presented method will not be applicable. However, with the widespread use of robotic systems in a variety of real-world applications, obtaining training data may not be difficult. In this work, 15 different environments were used for obtaining the training data. The time for neural network (offline) training was 6.915 seconds in Matlab using a 1.6GHz PC. As the robot interacts with a wide variety of environments, the training base can be increased to improve the accuracy of the neural network.
Conclusion
In this paper, a new control framework for force tracking on unknown environments has been presented that combines the benefit of system identification technique with the robustness of neural network-based methods. The presented method overcomes two major limitations in this field: 1) it does not ignore environmental damping, and 2) it does not require persistent force excitation for environmental parameter estimation. The presented method uses an ARX model to estimate the parameters without persistent excitation. However, any inaccuracy in this type of estimate is overcome by using the parameters' relative magnitude to train a neural network-based gain scheduler to determine optimal gains for a given environment. In other words, as long as estimates of the environment parameters are repeatable, and follow the actual trend of parameter variation, the presented controller can track a force trajectory on an unknown environment. This property allows this method to be robust and broadly applicable to a large set of environments. Robustness of the ANN based gain scheduling module to tolerate errors in environment estimates has been confirmed with three real-time experiments. It has also been shown that the proposed direct force controller tracks the desired force using the ANN predicted gains. The results demonstrate the efficacy and adaptability of the proposed controller when interacting with unknown and changing environments.