
Abstract
This work presents the effect, in terms of travel distance and material handling time reductions, of an optimal rather than a uniform item allocation in one-block picking warehouses, both with and without the use of a simple picking heuristic. Since developing efficient product-location strategies represents a critical issue in Operations Management, due to the impact on warehouse performance in terms of both service level and operation costs, this paper focuses on an effective quantification of obtainable travel time reductions, obtaining a significant result for manufacturing companies aiming to determine the most appropriate material handling resource configuration. Building on previous work on the effect of slot-code optimization on travel times in single/dual command cycles, the authors broaden the scope to include the most general picking case, thus widening the range of applicability and realising former suggestions for future research.
Keywords
1. Introduction
According to several reports, about 23% of logistics costs in the US [1] and 39% in Europe [2] are due to warehouse capital and operating costs. Given the extent of this impact on companies' supply chains, cost-effective management of warehouses has always been considered as critical to the success of businesses [3, 4, 5, 6, 7, 8]. It has been suggested that an efficient layout configuration and material handling system are, from the warehouse perspective, mainly detectable at the organizational stage [9, 10, 11, 12]. The linked costs seem to be mostly induced by the use of tracing technologies [13, 14, 15] besides appropriate item allocation [16, 17, 18, 19, 20, 21, 22].
Order picking is the most labour-intensive and time-consuming task in most warehouses [23], and improving its performance can generally involve huge investments. Indeed, up to 55% of total warehouse operating costs results from order picking operations [24]. Correct management of warehouse storage and picking actions can instantly impact the success of logistics operations in most manufacturing companies and play a vital role in their survival [25]. Each picking order contains a subset of items stored in a warehouse; a picking tour specifies the sequence in which items will be picked. Thus, an order picking cycle means that workers travel from a common pickup/deposit (P/D) or input/output (I/O) point to a specific location on the picking list, pick the required items and move them back to the I/O point. As Christofides underlined in 1975 [26], the routing of manual pickers within the aisles of a warehouse can be considered as a special case of the well-known travelling salesman problem, based on the hypothesis that forklifts move following a “Manhattan” (i.e., “rectilinear”, “right-angle” or “L1”) metric [27]. From an organizational perspective, performances of a storage area are based on two variables: the space required for item allocation and the time needed for their handling [28, 29]. Considering the aforementioned warehouse typology, three key factors mainly influence the overall travelled distance: warehouse space, layout and picking list size [30], based on the assumption that workers process only one order at a time and that each order does not exceed the forklift's capacity. Due to the great relevance of warehouse operations cost savings, this paper focuses on the estimation of material handling distance reductions for order picking cycles in one-block warehouses; to this end, the results of several simulations carried out assuming a variable picking list size with optimal item allocation and a uniform distribution of storing and picking positions, with and without use of a picking heuristic, will be shown and analysed.
2. Previous research
In pursuit of savings on order pickers and equipment optimizing order picking routes – thus choosing the best sequence for the order picker to visit specific locations, minimizing the distance travelled – several studies have been carried out over the past years. Given that the order picker has to collect a number of products in specific quantities at known locations, the problem offinding the shortest order picking route for warehouses with a central depot can be solved in running time as linear in the number of aisles and the number of pick locations [31].
Many authors have focused on modelling approaches to improve the efficiency of material handling times to gain better performance in the supply chain; several scientific contributions have aimed to minimize material handling costs or picking operations, evaluating new optimization criteria [32, 33, 34, 35, 36, 37, 38]. Lots of studies have centred on the general case of the order picking cycle due to its importance in increasing operation efficiency and decreasing labour workload [39]. The main aims of many publications have been the determination of the shortest travel distance and the optimal pick tour for a given set of pick locations in warehouses with two cross aisles [31] or more [40] with a dynamic programming approach. Roodbergen and De Koster [41] applied the Ratliff/Rosenthal algorithm to warehouses with middle cross-aisle warehouses. Focusing on the non-random storage policy perspective instead, Hwang et al. [442] and Caron et al. [43] modelled an analytical expression assuming turnover-based storage policies. Comparisons on the optimal routing and heuristics for picking problems, however, have rarely been presented [44, 45, 46].
In 1994, Gelders and Heeremans [47] solved the order picking problem by using the branch-and-bound algorithm of Little et al. [48] for a simplified warehouse layout: reductions gained in terms of total walking distance varied between 9% and 40%, depending on the number of products to be picked. The problem of finding order picking routes in a storage area is often solved by the so-called S-shape heuristic, in which order pickers move in an S-shaped curve along the pick locations, skipping the aisles where nothing has to be picked. More advanced heuristics can be found, however, in Hall [49].
Roodbergen and De Koster [50] later applied the Ratliff and Rosenthal's algorithm considering warehouses with middle cross aisles. Hwang et al. [42] and Caron et al. [43], on the other hand, modelled an analytical expression assuming a non-random storage policy. Petersen [44] and De Koster and Van der Poort [45] made an important contribution by providing some comparisons on the optimal picking tour and heuristics for picking problems. As Pohl, Meller and Gue underlined [51], however, a closed-form equation to estimate the optimal tour for a general number of picks seems not to be available in the literature. To forecast an optimal picking tour length, simulations using routing heuristics based on the hypothesis of a random storage policy have been performed [52, 53, 54]. Some authors have also developed a procedure for reducing order picking travel distance through an order batching optimization heuristic based on integer programming. This methodology combines several orders into batches to reduce the overall travel time [55, 56, 58, 59] but implies high-level computation efforts [59].
Based on an integer programming approach, a possible mechanism for reducing order picking travel distance through a class-based storage method was developed by Muppani and Adil [60]. In 2008 the same authors [61] presented a possible way to reduce order picking operations for class-based storage arrangement, developing a nonlinear integer programming method using the branch and bound algorithm. In the same year, Ho et al. [62] proposed an additional methodology aiming at the development of distance or area-based rules to minimize the travel distance of pickers; this technique is based on order batching procedures for an order-picking warehouse. In the last two years, Burinskiene [63] has proposed the volume-based storage method and the usage of correlation between order picking efficiency and stock accuracy to achieve an optimization of order picking processes; Ene and O˝ztu˝rk [64] have instead used both the batching and routing problems to minimize travel costs in warehouse operations.
A brief summary of some of the main complete papers on travel distance for stacking and picking procedures inside warehouses is presented below.
Generally speaking, optimal routing algorithms are infrequently used. Indeed, it seems that the application of the algorithm to layouts different to the model containing parallel aisles and a central depot has not been considered at all in the literature. The savings produced by using optimal algorithms are not clear in advance. It is also to be underlined that there are extra expenses and risks related to the implementation of the optimal algorithm, mainly because of its complexity.
Without any loss of generality, it seems that no closed-form evaluation technique is yet available to estimate the optimal tour length for a general number of picks [51] and that so far, the simulation required to forecast this length has been performed using routing heuristics while assuming a random storage policy [52, 53, 54]. It is well known that, in most contexts, different heuristics may lead to extremely different results [82].
This paper seems to be the first to contribute to the estimation of material handling time reduction for picking operations, using optimal item allocation rather than a uniform distribution of picking and storage locations. Results are calculated through simulations, based on a variable picking list size, with the aim of underlining the effect of different slot-code optimization levels on the reduction of average distances travelled. The comparison is carried out both with and without the most commonly used heuristic.
3. Warehouse layout design and routing methodologies
A warehouse is usually organized with a number of aisles of equal length with products stored on both sides; in most cases, forklifts or trucks can traverse the aisles in both directions. Each order consists of a number of products; these may be located in different aisles. In this paper we assume that the items of each order must be picked in a single route, that the warehouse has a single I/O point and that the picking area has a cross aisle both at the front and the rear to enable aisle changes: these are generic assumptions that fit most industrial cases.
Generally speaking, an order is received from the company and transformed into a picking list. This arrives at the warehouse and an order picker is sent into the picking area with the list to retrieve the requested items from storage. The process of picking products consists of a series of actions, ranging from positioning the vehicle to putting the picked items on a product carrier; most of the efforts to improve the operational efficiency of order picking are focused on routing, batching, and storage assignment: usually, however, a large part of an order picker's time is spent travelling.
Research regarding storage assignment is mainly concerned with rules for the assignment of products to storage locations. Existing rules vary from random policies, where storage locations are randomly assigned to products, to fast/slow-movers storage, where items with the highest pick frequency are assigned to the most accessible locations. Products may be divided into A, B, C classes according to their picking frequency, in order to simplify the slot-code allocation [81].
In this work, we consider a manual order picking operation where the order picker travels through a picking area to retrieve items from storage. In the literature, as stated above, a uniformly distributed item location is usually assumed. However, random storage is seldom used in practice: it may only occur in situations where the product assortment changes too fast to produce reliable statistics about demand frequency [57].
In this paper, travel times under a uniform distribution assumption are compared with those obtained under the hypothesis of an optimal allocation. The maximum level of optimality is reached when the items with the highest picking frequency (“fast-movers”) are located nearer to the I/O point. Three levels of “optimality” are assumed, i.e., “low”, “medium” and “high” optimization, and are formalized in the following paragraphs. The estimates presented in this work may provide an easy-to-use criterion to obtain a rough evaluation for the expected picking travel distance and time in practical cases.
Different warehouse layouts have been analysed in the literature, by Gu, Goetschalckx, and McGinnis [83] as well as by Meller and Gue [84], showing different aisle designs such as “Flying-V”, “Fishbone” and “Chevron”. Due to their widespread use in industry, this paper concentrates on one-block unit-load warehouses (Figure 1).

One-block warehouse vs. two-block warehouse
A detailed description of order-picker routing policies, such as the “s-shape”, “return”, “mid-point”, “largest gap”, “combined” and “optimal” methods, was presented by De Koster, Le-Duc, and Roodbergen [24].
All of these techniques were originally developed for one-block warehouses but can be used in a multiple-block context by implementing specific changes. According to Vaughan and Petersen [40] and Roodbergen and De Koster [30, 41], the combined heuristic returns the best results in 93% of analysed instances. According to this methodology, a decision whether to entirely traverse an aisle with at least one pick, or enter and leave the aisle from the same side, should be computed using dynamic programming [41].
Despite using complex dynamic programming algorithms, industrial companies prefer to solve their picking routing problem with simple and easily manageable heuristics. Usually, the heuristic involves a preordination of the picks required by the picking list, starting from one side of the warehouse and proceeding on the basis of nearer picks. Thus, starting from the selected I/O point of the warehouse, unloaded material handling vehicles first horizontally and vertically move to the leftmost (or rightmost) location of the picking list; then, once they have reached this location and performed the picking operation, they horizontally and vertically move to the next nearest location for the second pick, accessing it from the front or the back cross aisle, depending on the minimum travel distance (Figure 2). After having performed all the picks of the picking list, they exit from the output point. Obviously, the vehicle does not enter aisles without picks. This heuristic is the one most commonly adopted in real contexts due to its simplicity: it is therefore also the heuristic considered in this analysis.
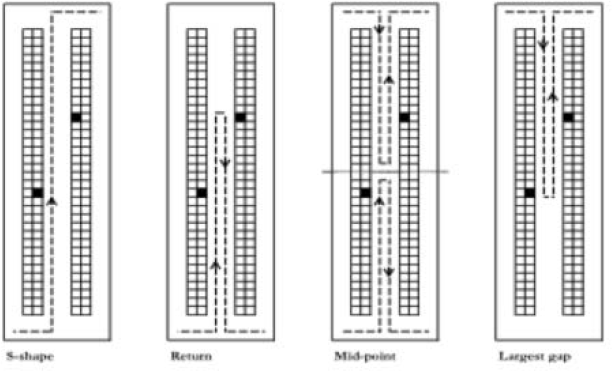
Order picking routing policies
4. Simulation technique
The main purpose of this work is to analyse the differences, in terms of picking distances and times, between three optimized slot-code location (OPT) scenarios and a random location (RAN) inside a warehouse. Warehouse management systems are currently used to gain an optimization of slot-code allocation, which clearly reduces stacking/picking travel times. Nevertheless, an exact estimation of this time reduction is considered to be of great significance for manufacturing, distribution and retailing companies, because it can help in the design of the warehouse as well as in determining the right type and number of handling vehicles. The comparison will be carried out through simulation over 100,000 runs, offering an original contribution to estimate the effects of picking heuristics on the reduction of picking average distances, varying the warehouse slot-code optimization level together with its I/O position and shape simulation.
A generic stacking warehouse was considered. According to the literature, the rectangular shape is the optimal geometric shape to store pallets [85]; the initial storage area was therefore assumed to be rectangular, with one input and one output point:
Xthe storage area longitudinal width;
Y the storage area lateral depth;
(xout; yout)the output coordinates;
(xin; yin)the input coordinates.
where xout ≤ X and yout ≤ Y, xin ≤ X and yin ≤ Y.
All these variables are independent and could be varied to perform multiple what-if analyses. In order to consider the most common warehouse case, all simulation runs have been performed assuming a single input/output point located in the middle of the warehouse's long side: this choice is also supported by evidence shown by Bassan, Roll, and Rosenblatt [70]: indeed. These authors show how this configuration represents the best solution to minimize storage/retrieval travel times in warehouses with a longitudinal width twice the lateral depth.
The 2-D coordinates of a single storage location in the warehouse can thus be identified by a pair (x;y). Forklifts are assumed to move following the “Manhattan” (i.e., “rectilinear”, “right-angle” or “l1”) metric [27]; thus, workers are able to travel along the two main orthogonal aisles at the front and back of the storage area as well as along cross aisles.
4.1 Random generation of input variables
Depending on the number of picks considered, one or more picking (xpick; ypick) points inside the warehouse are randomly identified for each run. The random generation rule, as performed by Hall [49] in the development of a heuristic to estimate a shortest tour length lower bound, followed a uniform distribution for the case in which no slot-code allocation optimization was performed; correspondingly, a specific custom distribution was used for the case with fast-mover items located near the input/output point. Thus, for the random case, for each pick point i:

In the second case, in order to represent an optimized slot-code allocation, the x and y coordinates of the picking points were generated with a random inverse transform sampling from Normal distribution. Considering that simulations assumed a single input/output point located on the warehouse front side (xin = xout; yin = yout = 0), we have:
x pick1 results from

y pick1 results from
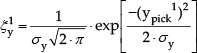
and analogously, for each pick point i, x picki results from
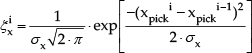
y picki results from

The user-specified input parameters σx and σy measure the spreading of products all over the storage area. Thus, the condition



4.2 Hypotheses on routing paths
In the designed warehouse, picking operations were simulated using the following approach. A forklift truck was assumed to:
start at the input point (xin; yin), unladen; horizontally and vertically move to the first (xpicki; ypicki) picking location, with i = 1; perform the picking operation after reaching the picking location; horizontally and vertically move to the next (xpicki+1; ypicki+1) picking location; continue going to step 3 until the pick points are finished; horizontally and vertically move to the location (xout; yout); exit from the output point.
According to the previously cited simple heuristic, the first pick will be the leftmost one on the picking list; when moving to the next pick point, the picker is assumed to always choose the best alternative (shorter distance) between reaching the front or rear longitudinal aisle. Thus, the overall distance OD travels to perform a cycle on n picks is equal to:

An overall number of more than 100,000 runs have been simulated, considering 2-pick, 6-pick and 10-pick cases varying the optimality of the warehouse slot-code allocation. When calculating picking distances in the best optimized slot-code location case, a high percentage of the 100,000 samples was discarded in each simulation run, due to picking coordinates outside warehouse boundaries. As a consequence, the relative picking distances were calculated basing on acceptable values only.
5. Simulation results
The presented results refer to simulations performed under the hypothesis of a unique input/output point located in the middle of the warehouse's rear side, assuming a longitudinal width twice the lateral depth, thus:
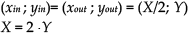
The generation rule followed a uniform distribution for the random case, while a random inverse transform sampling from the Normal distribution was used to represent the optimal slot-code allocation case. Results of the forklift's travel distance simulations are summarized in the following tables, comparing the optimized slot-code allocation case (OPT) and the random case (RAN). In the former, three scenarios were considered, according to the methodology presented in Fumi et al. [38].
A first scenario (LOW) characterized by a “low effective” slot-code optimization (e.g., fast-mover items turnover ratio similar to slow-movers) represented by σx = σy = 26.6; A second scenario (MED) characterized by a “medium effective” slot-code optimization, represented by a σx = σy = 30.0 value; A third scenario (HI) characterized by a “high effective” slot-code optimization (e.g., fast-mover item turnover ratio deeply different from slow-mover ratio), represented by σx = σy = 16.0 value.
Despite the fact that this paper does not focus on picking techniques but on the effect of slot-code optimization, for the sake of completeness the consequences of the heuristic adoption are presented in Table 2 and Table 3. Table 2 shows the average distances per pick considering an 80×40–metres rectangular storage area for a 2-pick, 6-pick and 10-pick case, analysing either when the pick sequence is random or when it follows the described heuristic, both for optimized and un-optimized slot-code allocations.
Literature review of travel distance models for different warehouse systems

Simulation results of average travelled distance in metres on an 80×40 m area

Reduction of average travelled distance as a result of heuristic adoption

The effects of the adoption of this simple picking heuristic following a higher or lower slot-code optimization are summarized in Table 3 as the:
percentage decrease from RAN to OPT (LOW) case; percentage decrease from RAN to OPT (MED) case; percentage decrease from RAN to OPT (HI) case.
As expected, simulation results display greater improvements as the number of picks in the picking list increases. Clearly, the percentage reduction of average distance per pick decreases if using effective slot-code allocation criteria, because improvement margins become narrower. Figure 4 and Figure 5 show this effect, representing the average distance per pick on the 80×40 m area.
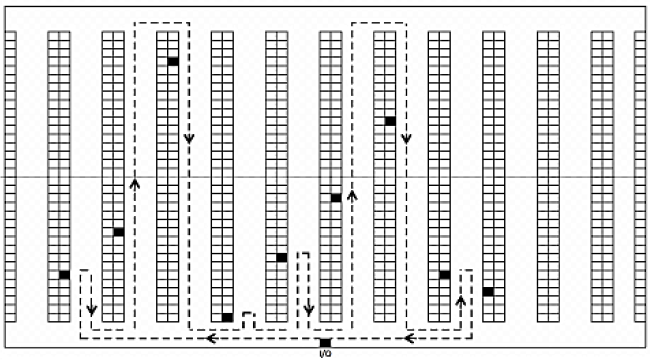
Example of paths for selected picking cycle

Average distance per pick (80×40 m area), random pick case

Average distance per pick (80×40 m area), heuristic case
The following figures present the breakdown of the slot-code optimization effects, in terms of percentage decrease of the average distance per pick from the random case to each optimization degree case (LOW, AVG, HI), respectively in 2-, 6- and 10-pick cases, both with and without the use of a picking heuristic. These numeric results are highly useful for manufacturing companies wishing to determine the right type and number of material handling resources, according to their capabilities in optimizing their warehouse.
In the 2-pick case, a highly effective slot-code optimization can lead to up to a 36.4% reduction of the average distance per pick compared to a randomized item location in the warehouse. Clearly, the heuristic adoption does not change these results, because no improvement is possible to change the sequence of two picks only.
Figure 7 and Figure 8 show that a further reduction of the average distance per pick is achieved as the number of picks increases, due to a higher pick-point density within the warehouse area. At the same time, it is possible to see that improvements due to a better slot-code optimization are reduced when the heuristic is used: this is because these percentages are computed comparing the optimized cases with the random allocation scenarios, where the heuristic has already managed to reduce the average distance per pick (as evident from the comparison of Figure 4 and Figure 5).
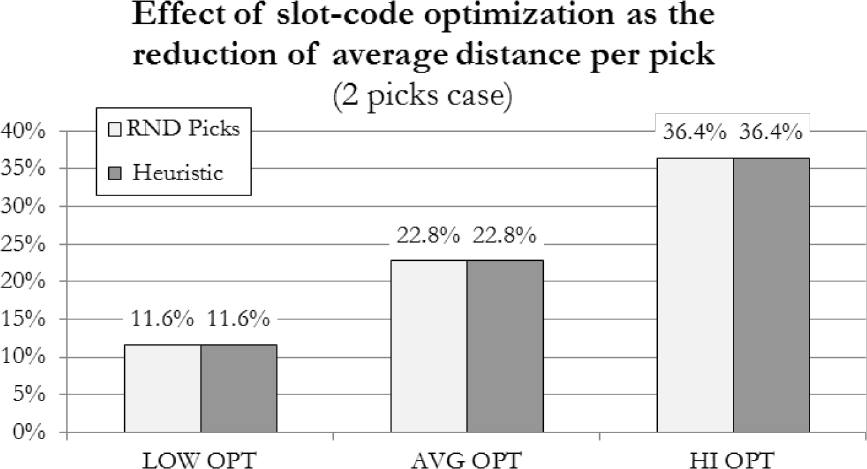
Reduction of average distance per pick (2-pick case)

Reduction of average distance per pick (6-pick case)

Reduction of average distance per pick (10-pick case)
6. Limitations of the study
The research limitations include the assumptions of a unique size of storage locations (single shelf type) and of two-way aisles, which may not be valid for every industrial warehouse; however, these hypotheses have often been assumed in similar studies [36]. As well as removing the single shelf assumption and evaluating the influence of one-way aisles presence, future research should include simulations performed varying the shape of the storage area, the location and number of orthogonal aisles, the positions of the input and of the output point and, eventually, include material handling vehicles with different performance characteristics.
7. Conclusion
While the scientific literature mainly focuses on random slot-code allocations for traditional unit-load warehouses, the majority of companies are looking for a methodology to achieve optimal SKU placement without the need for expensive information systems. Furthermore, current research has mainly aimed to reduce warehouse operation costs through the minimization of material handling average travel distance by optimizing item location, instead of concentrating on picking operations. Given that over 50% of a warehouse's overall expenses results from order picking operations, this paper, through multiple simulations, has aimed to be the first to address a precise and measurable estimation of picking material handling distances varying the slot-code assignment optimality – both when a simple picking heuristic is used and when it is not. Overcoming the single/dual command hypothesis of the authors' original work, the main purpose of this paper is thus to underline and quantify the advantages that emerge from using a slot-code optimization rather than a random one, comparing material handling systems performance for 2, 6 and 10-picking cycles. Each comparison was carried out considering three different scenarios, respectively representing a null, low, medium and high level of slot-code optimization. Notwithstanding an expectable decrement of travel distances from the random scenario to the optimal one, simulations helped in an exact determination of these reductions. The importance of these results is crucial, especially for manufacturing, distribution and retailing companies seeking both an efficient design for their warehouse and the most appropriate type and number of material handling vehicle [82].