
Abstract
An office delivery robot receives a large amount of sensory data and there is uncertainty in its action outcomes. The robot should not only accomplish its goals using environmental information, but also consider various exceptions simultaneously. In this paper, we propose a hybrid system using hierarchical planning of modular behaviour selection networks to generate autonomous behaviour in the office delivery robot. Behaviour selection networks, one of the well-known behaviour-based methods suitable for goal-oriented tasks, are made up of several smaller behaviour modules. Planning is attached to the construct and adjust sequences of the modules by considering the sub-goals, the priority in each task and the user feedback. This helps the robot to quickly react in dynamic situations as well as achieve global goals efficiently. The proposed system is verified with both the Webot simulator and a Khepera II robot that runs in a real office environment carrying out delivery tasks. Experimental results have shown that a robot can achieve goals and generate module sequences successfully even in unpredictable situations. Additionally, the proposed planning method reduced the elapsed time during tasks by 17.5% since it adjusts the behaviour module sequences more effectively.
Introduction
Advances in robot technology have resulted in service robots that support people in their daily activities [1]. A mobile robot, which runs in an office environment, can help users by performing routine tasks. However, under the conditions of insufficient environmental information and uncertainties in the real situations of an office or a house, high-level functions including perception or planning are required to generate autonomous behaviour [2]. Several researchers have tried to devise appropriate control structures for office delivery robots using various approaches [3–9].
In order to generate behaviours in mobile robots, conventional planning techniques have been applied to controlling them in well-designed environments. These approaches can generate behaviour sequences optimized in predefined environments, but unfortunately they have their own weakness of low flexibility in complex environments. Contrary to conventional planning-based systems, reactive systems can generate behaviours quickly according to environmental conditions [10]. Even though the systems work well in various and complex domains, it is difficult to generate behaviours robustly in situations of consistency or stability. These limitations encourage the necessity of hybrid behaviour generation approaches that combine the deliberative and reactive systems, which is the main motivation of this paper. Many researchers have studied hybrid architectures to control mobile service robots. Most of them used simple rule or description logic to generate a robot's behaviours in the reactive layer. However, these methods cannot guarantee sufficient decisions because the sensory information is too uncertain and the computational resources of mobile robots are limited. A behaviour selection network can select appropriate behaviours for unpredictable and changing situations by considering both goal and sensory information [11].
In this paper, we propose a hybrid system based on behaviour selection networks [11], which is a behaviour -based method. It is known for its robust performance even in insufficient environments [12]. This method can generate behaviours autonomously to achieve goals, but it is hard to perform well in the complex problems that some plans are required to solve since it was designed to run reactively. The contribution of the proposed method lies in that it overcomes this limitation by combining the behaviour network with a planning mechanism that plans the sequences of modules and adjusts the plans according to exceptions.
The rest of the paper is organized as follows. Section 2 presents background and related works for hybrid systems and applications of office delivery robots. Section 3 describes in detail the hybrid behaviour network module proposed. Section 4 reports the experiments conducted to show the usefulness of the proposed method. The experimental environments were designed in both a simulator and the real world. The final section presents a summary and future works.
Related Works
Hybrid Control Systems
Traditional AI techniques have the limitation that they usually work only in given environments and problems, and a lot of pre-processing steps are required. On the other hand, behaviour-based AI techniques mainly based on reactive behaviour selection are not easy to apply to complex problems; a hybrid technique of them is required to generate flexible behaviour [13].
Hybrid means a combined structure of two or more things, which have different functions. In the domain of a mobile robot's behaviour generation, the hybrid systems have two levels, the reactive and deliberative levels. The reactive level contains sensors and actuators that perceive environments and perform the chosen behaviours, respectively. The deliberative level contains information about maps of environments and the modules, which generate plans to control the reactive level [14, 15].
Hybrid systems have the merit that they take only the strengths of components and complement the weaknesses by exploiting each other. Recently, the hybrid systems have been applied to various problems with diverse approaches. Bayesian networks and behaviour networks are combined to generate robot's behaviours [16] and a planning function was attached to the reactive system for the same purpose [17].
One of the important issues for the hybrid system is the way it combines the deliberative and the reactive systems. The deliberative approach to generating the paths optimized for a specific map is useful for localization problems, but it is hard to respond to the environmental changes and requires plenty of information to plan in the domain of performing tasks [18].
Nevertheless, for a service robot, it is better to use the behaviour-based method mainly since it is more important to achieve the robot's goal and maintain autonomy. For this reason, we propose to mainly use the behaviour networks, one of the behaviour-based approaches, for autonomous behaviours of an office delivery robot, since it is known for its usefulness in goal-oriented problems [19–22]. Since we use modularized behaviour network modules in the proposed system, the planning method is attached hierarchically in order to generate and adjust sequences of them according to situations. In the proposed system, the behaviour network and the planning are regarded as the reactive and deliberative levels, respectively.
Mobile Service Robots
Since sensors on the mobile robot cannot recognize environments perfectly, different algorithms are needed according to the domain to which the robot belongs. Especially in real-world environments, including an office, delivery robots interact with environments and there are chances to face various new circumstances during their tasks. To deal with these points, many researchers have tried to devise structures of office delivery robots with several different approaches, as shown in Table 1.
Previous studies on mobile service robots

Previous studies on mobile service robots
Simmons et al. proposed a hierarchical architecture, which consists of four steps: avoiding obstacles, navigating, planning routes, planning tasks and dealing with uncertain sensory inputs and environmental information [3]. Beetz et al. designed a plan-based logic system that regards an exception as one of the adjustable plans [4]. However, these planning-based methods have their own limitations, such as that they must control lots of information about the environments and cannot respond flexibly to dynamically changing situations and exceptions. Breuer et al. developed an autonomous service robot named Johnny [23]. The control approach of the robot is based on hybrid deliberative layer (HDL), which extends the planning component with a description logic reasoning system. They also provide multimodal human machine interactions like gesture, speech and emotion detection. Liu et al. proposed a comprehensive urban search and rescue robotic system and intelligent control architecture [24]. The intelligent control architecture provided the robot system with the ability to make decisions.
On the other hand, Gardiol and Kaelbling used the partially observable Markov decision process (POMDP) to design the reactive architecture [5]. Additionally, Chung and Williams divided the original problem into several sub-problems to generate plans by reducing the complexity of the problem [6] and Theocharous and Kaelbling represented the environment in grids and used reinforcement learning to perform temporal plans [7]. Ramachandran and Gupta proposed POMDP-based reinforcement learning for a delivery robot [8].
Reactive methods adopt similar approaches to our method, which enable the robot to deal with changes robustly without environmental information. These are highly likely to show poor performance in the domain of performing tasks, since they usually only consider achieving local goals and reacting to current exceptions without maintaining global goals.
To prevent this, some hybrid architectures have been proposed [35]. Milford and Wyeth used different obstacle and experience maps for local and global navigation, respectively [9]. Ferasoli-Filho et al. developed a mobile robot, which can be controlled by myoelectric and movement sensors [25]. It can provide disabled children with a certain degree of independency in the exploration of the environment. The robot has control architecture with three layers, which are deliberative, intermediate and reactive layers. The intermediate layer accepts commands from the deliberative layer and it activates or inhibits the basic behaviours of the reactive layer.
Lyons et al. presented an autonomous platform that searches or traverses a building to observe unstable masonry or rubble [26]. In these situations, a reactive approach may produce behaviour that works against the robots' long-term goals, such as taking the quickest or safest route to a disaster victim. They used a hybrid reactive-deliberative approach to overcome the limitations of an entirely reactive approach. Yun et al. presented a robot platform named CIROS for proactive human searches in an undiscovered indoor environment [27]. They classified the control architecture with three layers including a deliberative layer using a task manager, a sequencing layer based on a configuration manager and a reactive layer. It provides human registration and identification in different places and it also provides efficient autonomous exploration and indoor modelling.
Mendoca et al. developed an autonomous navigation system using fuzzy cognitive maps (FCM) [28]. They used the model to represent the robot's dynamic behaviour in both reactive and deliberative layers. Sgorbissa and Zaccaria developed a two-level navigation architecture with deliberative and reactive agents for the navigation of a mobile robot [29]. Palomeras et al. presented a control architecture for an autonomous underwater vehicle [24]. They implemented a component-oriented, layer-based control architecture structured in three layers: reactive, execution and mission layers. They used a discrete event system based on Petri nets to implement an execution layer. Wang et al. used a deliberation-reaction hybrid control architecture to deal with motion control and mobile robot path planning [31].
The method used low-level controls for reactive actions that were managed by high-level controls. As an extension of the hybrid approaches, the proposed method is based on reactive approaches since it mainly uses behaviour networks but the planning is externally placed at a higher level to control them dynamically and consider the global goals in order to overcome the limitations of the conventional reactive methods.
The proposed system to generate behaviours in an autonomous office delivery robot consists of two levels. The low level contains behaviour selection networks, which can reflect temporary environmental changes and the high level controls the goals and plans flexibly according to the situation. Figure 1 shows the proposed system. The low level includes the specific and common behaviour selection network modules, which are selected by deliberative control plans. To generate plans flexibly according to the situations around the robot, the queue for module sequences and the database for basic behaviour sequences are used. Feedback from the users can be used to determine priorities in the queue at the deliberative control.

Architecture of the proposed hybrid behaviour network system
Contrary to conventional reactive systems, the behaviour network not only generates behaviours instantly but also has goals so as to solve some simple planning problems. However, as the problem gets more complex, it is difficult to select behaviours accurately with only a flat network [36, 37]. In order to overcome this limitation, the behaviour selection network is divided into several behaviour network modules.
The purposes of the usage of the modularized behaviour networks are as follows.
Each behaviour network module in the proposed method includes a behaviour network oriented to a single corresponding goal. The behaviour network is used as the method for selecting the most natural and suitable behaviours for the situations. The behaviour networks are a model that consists of relationships between behaviours, goals and external environments, and selects the most suitable behaviour for the current situation.
In the behaviour network, behaviours, external environments and internal goals are connected with each other through links. Each behaviour contains preconditions, an add list, a delete list and activation. The preconditions are a set of conditions that must be true in order to execute behaviours. The add list is a set of conditions that are highly likely to be true when behaviours are executed. The delete list is a set of conditions that are likely to be false when the behavioural entities are executed. The activation represents to what extent the behavioural entity is activated.
The activation energies of behaviours are first induced from external environments and the goal. The activation of the ith behaviour Ai can be presented as follows:

where we and wg are the weights needed to induce activation energies from environments and goals respectively. Ei,n and Gi,m represent whether the nth environment element and the mth goal are connected with the ith behaviour or not, respectively.
After the first induction, behaviours exchange their activation energies with other behaviours considering the types of their links. The behaviour exchange can be presented as follows:

where w p , w s and w c are the weights needed to exchange activation energies through predecessor, successor and conflictor links, respectively, and Pi,j, Si,j and Ci,j represent whether the ith and jth behaviours are connected by each type of link, respectively.
The behaviour networks have a threshold to decide which behaviours are executable. Using this, the behaviour networks select the behaviour where all the preconditions are true and the activation energy is larger than the threshold. Unless any behaviour is selected, the behaviour selection system constantly reduces the threshold until the behaviour is selected. Figure 2 shows how the behaviour network generates behaviour.

The process of the behaviour network
A behaviour network module consists of one goal, external environments and behaviour nodes. Each module is mapped to a sub-goal from the planning system. If the planning system chooses a single sub-goal to achieve, the corresponding behaviour network module is activated and generates behaviour sequences.
In this paper, we have designed two behaviour network modules – go to a room and find objects and two common modules – navigate and avoid obstacles. Figure 3 shows the designed behaviour network modules.
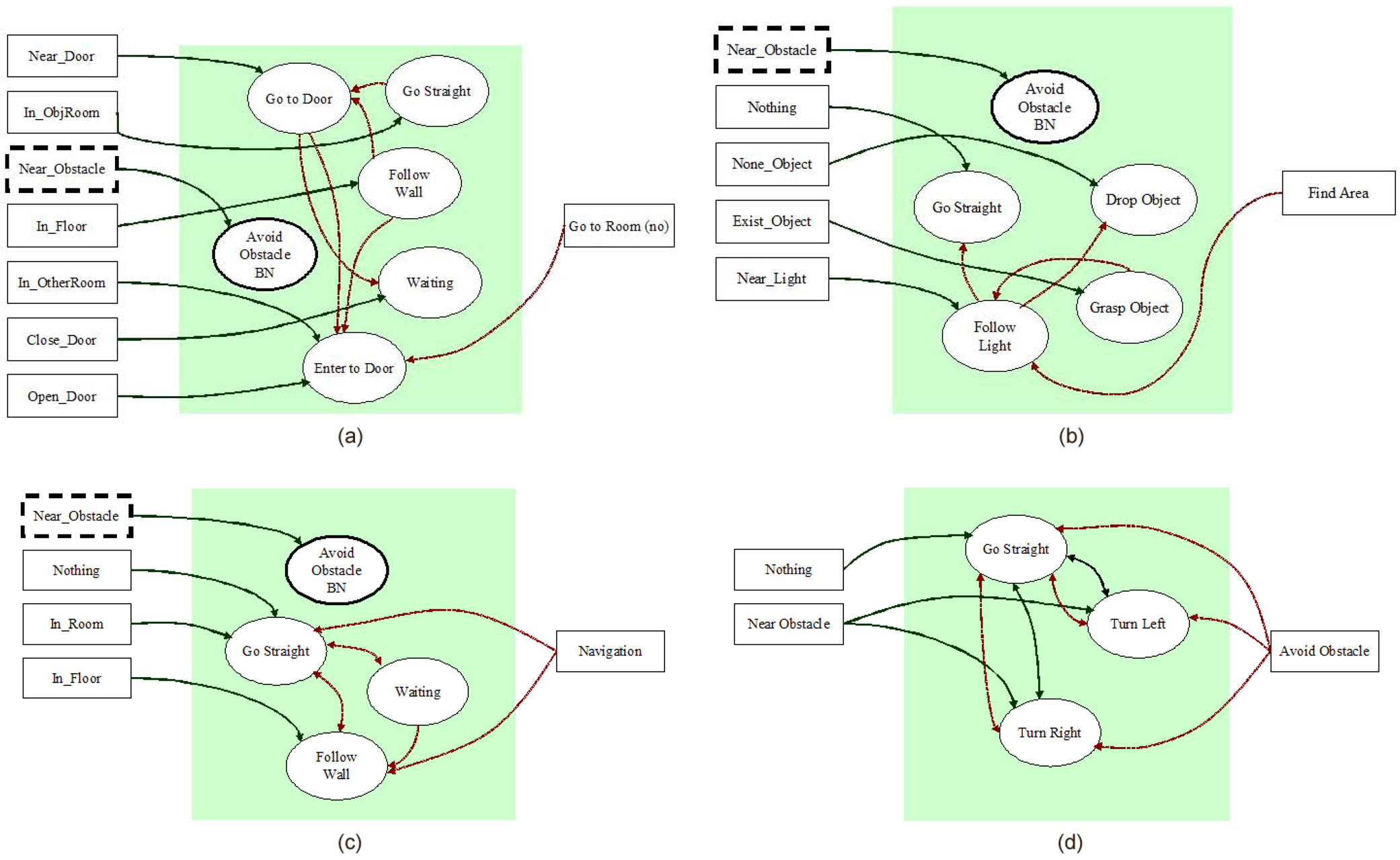
Designed behaviour networks (a: go to a room, b: find objects, c: navigate, d: avoid obstacles)
The deliberative control system does not plan the sequences of all primitive behaviours or trajectories, but plans sequences of sub-goals to control the behaviour network modules. Since we designed several small separate behaviour modules with sub-goals, they should be controlled explicitly to achieve the global goal. To plan goal sequences, the deliberative module and the behaviour network-based modules are connected as shown in Figure 4.

Architecture of the goal sequences planning for behaviour modules
Since the behaviour modules do not have any information about the map of the environment, it is difficult to perform plans correctly in complex environments. To deal with this, the deliberative module checks the accomplishments of the sub-goals and controls plans when situations are changed and the plan in each behaviour network module controls only partial behaviour sequences to achieve the sub-goal of the corresponding module.
The deliberative control module makes plan by deciding priorities of goal sequences to achieve the global goal and adjusting priorities when exceptions or feedbacks occur. The module uses the basic behaviour library that includes the basic sequences of behaviours required to perform when tasks are given. The library is defined before the usage and can be modified by the feedbacks of the user. When the user gives tasks the sequences are planned using the library and inserted into the queue. At the ‘Check event’ stage, the robot checks for changes of situations and adjusts the sequences.
To plan and adjust the sequences, the priorities of tasks are used. In this paper, the priority is defined as the deadline of the delivery required by the user. For this process, we define several parameters as follows.
C = {ci}: a command set D = {{di}: {di} ∊ C}: a decomposed command set Q = {qi: q
i
= d1, …, d
k
, i < maxqueue}: the command queue X = {Wait, Critical, Minor}: a user feedback set
Firstly, priorities are determined according to the requested deadline and the order of tasks as shown below:

where ti and Oi indicate the remaining time and the order of the ith task, respectively. Max means the possible maximum value of the corresponding variable.
Secondly, priorities are adjusted by additionally considering the position of the robot as follows:

where S is the current state of the robot, From(i) indicates the starting point of the ith task and f(S) is the priority decided by the feedback.
The sequence queue contains feedbacks from the user. Each of them consists of an index of the user, a type of command, a deadline, a point of departure and a destination. When the feedback is given, the robot seeks sequences for the corresponding command and puts the sequences into the queue. If there is no relevant sequence in the library, the robot requests feedback to the user.
The priorities of behaviour modules in the sequence are computed with the order of the task and the deadline by using Eq (3) and (4) in Section 3.2.1. Each module is sorted by priority in the sequence queue. For this job, the queue contains information as shown in Figure 5. The front four fields are input by the user and the next five fields are used to manage the plan flexibly.

Information for each item in the sequence queue
Each task has a segmented sequence with subtasks. For example, a single delivery task is split into the subtask to bring the object from the point of departure and another subtask to move the object to the destination. Each task has a checkpoint that indicates which subtask is performed last. The checkpoint enables the plan to be adjusted flexibly according to the change of situation. The subtask has a sequence of several behaviour modules. Figure 6 shows examples of the sequence queue, which manages the tasks and sequences of behaviour modules activated by the task.

Examples of the sequence queue and sequences of behaviour modules
Task adjustments are preceded according to the position of the robot as follows:

where Seq(q i ) indicates the target command to be placed instead of q i , Pos i is a set of positions that qi contains and qi→d l is the lth behaviour in qi. For example, the robot may pass another room not required for the task during its movement from the starting point to the destination. In this case, it searches for the task, which the robot should fulfil at its current location. If the deadline of the task in progress is greater than the threshold, it changes the plan to execute the task found in advance. Otherwise, it ignores the task found and continues its previous job.
In order to show the feasibility and the usefulness of the proposed system, we conducted experiments for the office delivery tasks of the mobile robot.
Experimental Setup
The hybrid behaviour generation system was applied to the mobile robot, Khepera II, which has a wireless camera sensor, eight infrared sensors, eight light sensors, one gripper and two motors, as shown in Figure 7. Each proximity sensor value is between 0 and 1023. The experiments were performed in both the Webot simulation environment and a real-world environment.

Khepera II mobile robot. (a: a snapshot with one gripper and camera, b: the infra-red proximity sensors in Khepera II).
For the office delivery tasks, we designed an office environment that includes four rooms and one aisle. The colours of each pair of a door and a room were coloured identically and the robot could recognize each room by referring to the colour of the corresponding door. If some doors were closed, we changed colour of them to black. Since the robot does not have any information about the environment, it should navigate using only recognized colours of rooms. Figure 8(a) and (b) show the experimental environment constructed in the simulator and real world, respectively.

The experimental environment with four rooms and a corridor. (a: the environment implemented in a simulator, b: the environment built in real-world.)
In order to analyse the results, the elapsed time measured by running steps, trajectories, sequences of modules and the behaviour of the robot were obtained. Infrared camera-based tracking was used to obtain the trajectories and a light was placed where the object was so that the robot could find the object by following the light.
In this section, we analysed the planned goal sequences from various tasks. We obtained the rates of success and failure after performing all the tasks and analysed changing the sequences according to errors and feedback from the user.
The task of delivering the object from a specific room (A) to another room (B) was given in the experiments. First of all, we obtained the trajectories of the robot during the task. Figure 9(a) and (b) show the results from the simulation environment. They are the trajectories for the delivering task from Room 2 to Room 1 and the task from Room 4 to Room 3, respectively. If the robot was located in the room or in the corridor, it started the behaviour module for searching the destination and used the camera for sensing since it did not have map information of the environment. When the robot reached the destination room, it followed the light to find the object.

Trajectories of the robot (a: delivering the object from Room 2 to Room 1, b: delivering the object from Room 4 to Room 3, the red circle and rectangle indicate a point of departure and a destination, respectively).
Additionally, we obtained the results of behaviour selection for the task as shown in Figure 10. Figure 10(a) and (b) show the sequence of chosen behaviour modules and behaviours, respectively.

Sequences of chosen behaviour modules (a) and chosen behaviours (b) during the task of delivering the object from Room 2 to Room 1.
Additionally, in order to verify the usefulness of the sequence adjusting process (see Section 3.2.2), we designed seven delivery tasks, shown in Table 2. Experiments were conducted both with and without sequence adjustments for the tasks. The sequences of the chosen modules and the robot's location were obtained as shown in Figure 11.

Sequences of chosen behaviour modules (a) and robot's location (b) during given seven tasks (a: without sequence adjustments, b: with sequence adjustments)
Seven delivery tasks given

Using sequence adjustment processes, the robot modified its behaviour sequence according to its location. If the robot had achieved its goal in a certain room, it sought the task that could be started in that room. As a result, it reduced the steps wasted in the corridor. The robot finished all the tasks within 3956 steps without sequence adjustments, whereas it completed them within 3264 steps, a 17.4% reduction, with adjustment processes.
Additionally, we compared the proposed method with a reactive approach. The reactive approach only has rules without a deliberative method. The rule-based reactive system can generate behaviours quickly according to environmental conditions, but the reactive behaviour selections are not easy to apply to a changing environment. Figure 12 (a), (b), (c) and (d) show the trajectories of the reactive method and the proposed method in a changing environment, which is different from previous experiment. The size and location of the doors in rooms were changed. In Figure 12 (a) and (b), the robots are in Room 1 and the door is closed. The reactive method tries to find the exit continuously, but the proposed method waits in front of the door of Room 1. Figure 12 (c) and (d) show the trajectories from Room 2 to Room 4. Because the door of Room 2 is opened after a fixed time, the robot with only a reactive approach conducts useless trials for the closed time, but the robot with the proposed method waits in front of the door and goes to Room 4 immediately after the door to Room 2 is opened. This reduces the battery usage and the delivery time. The experiments show that the proposed method is suitable for controlling a mobile service robot for effective services.
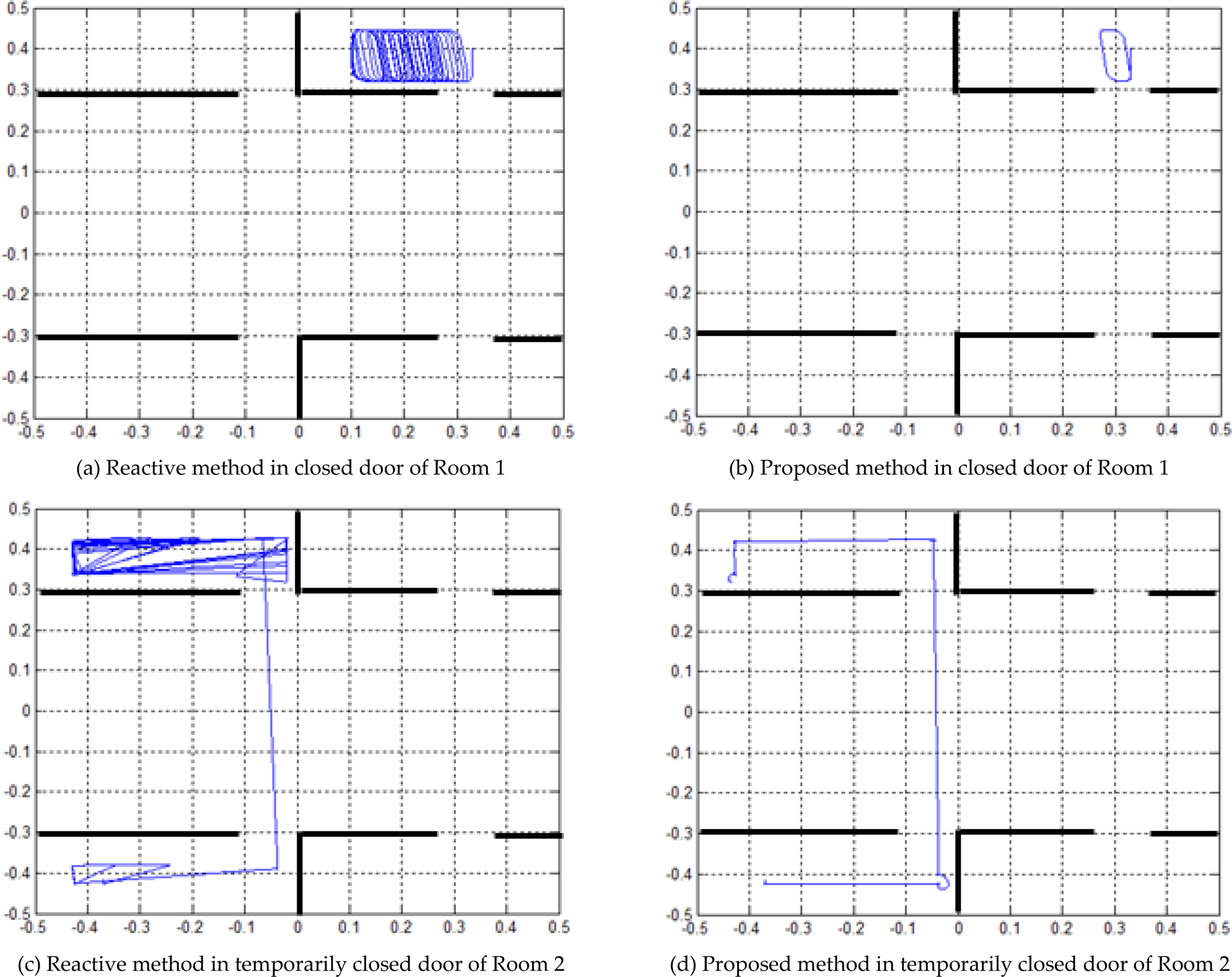
Comparison between reactive and proposed method in changing environments
For quantitative analysis, we obtained the elapsed time during tasks. We initially located the robot randomly and made it repeat random delivery tasks 30 times. Table 3 shows the minimum, average, and maximum number of steps after 30 tasks.
Minimum, average, and maximum steps after 30 tasks
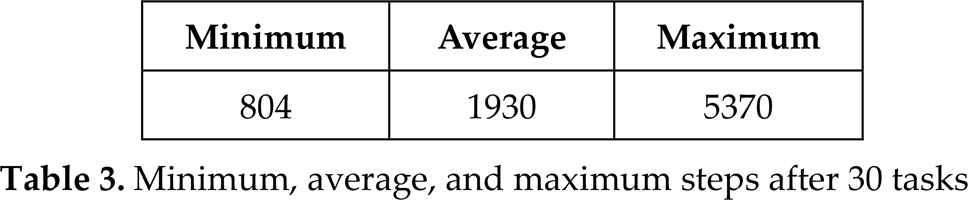
Minimum, average, and maximum steps after 30 tasks
Figure 13(a) and (b) show the trajectories obtained from results with the maximum and minimum steps, respectively. The task from Room 4 to Room 2 took the smallest number of steps. The maximum number of steps were taken in the case where the robot was initially located in the corridor because it took a long time to find the target room according to the state of the sensors. Even though the robot started the task in the corridor, differences between results were shown in accordance with the distance between the room and the sensory states.

Trajectories from results with (a) maximum and (b) minimum steps
We have proposed a hybrid behaviour system for an autonomous mobile robot for office delivery tasks. The system is oriented to behaviour network modules, which is useful for performing tasks in real-world environments. Moreover, a method for planning is attached to supplement them. The planning system generates and manages the overall sequences of behaviour modules and the behaviour modules achieve several sub-goals and generate autonomous behaviours quickly. This approach enables independent environmental modules to be designed and solves ambiguities among behaviour selection in one complex behaviour network. Additionally, controlling behaviour modules via planning accomplished maintenance of the global goal even though each module only concerns its sub-goal.
Experiments were conducted to verify the feasibility and the usefulness of the proposed method. We implemented a simple office environment in both a simulation and the real world with the Khepera II mobile robot and designed several delivery tasks. As the result, it is confirmed that the robot can achieve the goal even though there are temporary exceptions and it changes its plan when adjustments are required to complete tasks more efficiently.
Since we focused only on modelling the hybrid architecture and implementing a workable system, there are still many experimental and analytical issues to be considered in future work, such as validating the suitability of the proposed method and comparing the proposed method with conventional approaches. Though the behaviour network modules can be applied independently to various environments, it should be designed by experts in a manual way. For future work the method for learning structures of networks and controlling them automatically should be investigated. Moreover, the proposed method should be tested on more complex environments.
Footnotes
6.
This research was supported by the Original Technology Research Program for Brain Science through the National Research Foundation of Korea (NRF) funded by the Ministry of Education, Science and Technology (2010–0018948). We express our personal appreciation of the valuable assistance given by Hyeon-Jeong Min and Jong-Won Yoon who were members of Soft Computing Laboratory, Yonsei University.