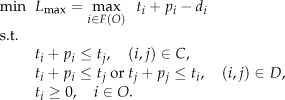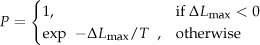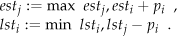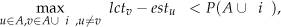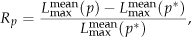A decomposition-based optimization algorithm is proposed for solving large job shop scheduling problems with the objective of minimizing the maximum lateness. First, we use the constraint propagation theory to derive the orientation of a portion of disjunctive arcs. Then we use a simulated annealing algorithm to find a decomposition policy which satisfies the maximum number of oriented disjunctive arcs. Subsequently, each subproblem (corresponding to a subset of operations as determined by the decomposition policy) is successively solved with a simulated annealing algorithm, which leads to a feasible solution to the original job shop scheduling problem. Computational experiments are carried out for adapted benchmark problems, and the results show the proposed algorithm is effective and efficient in terms of solution quality and time performance.
Scheduling has been an important research field in robotics and computer-integrated manufacturing [22, 8]. The job shop scheduling problem (JSSP) is one of the most frequently adopted models in the area of scheduling research [15, 2, 16, 11]. However, most variants of JSSP are -hard in the strong sense and thus defy ordinary solution methods. Enumerative approaches, such as the branch-and-bound algorithm [7], can only conquer small-scale problem instances. The most common heuristic methods devised in the early days include dispatching rules [17, 10, 3] and shifting bottleneck [1, 4, 12]. In recent years, meta-heuristic algorithms, such as simulated annealing (SA) [26], genetic algorithms (GA) [28], scatter search (SS) [18], tabu search (TS) [27] and particle swarm optimization (PSO) [25], have clearly become the research focus in practical optimization methods for solving ordinary-scale JSSPs.
However, the size of JSSPs in practical manufacturing environments is much larger than in theoretical research. In this case, the solution space is too large to be searched effectively by simple meta-heuristics. To address this difficulty, several decomposition-based algorithms have been proposed [19, 5, 21, 20, 23], which decompose the original large-scale problem into a series of smaller problems (subproblems) and finally obtain a solution to the original problem after these subproblems are solved respectively. But there are some drawbacks with these existing approaches. The decomposition algorithm proposed in [19, 20] has exponential complexity and thus cannot be directly applied to large-scale problems; the algorithm in [5] encounters deterioration in solution quality because it adds extra constraints to each subproblem; the method presented in [21] does not guarantee the feasibility of subproblem solutions for the original problem and relies on a heuristic coordination algorithm to construct a feasible solution for the original problem.
In this paper, we propose a decomposition-optimization algorithm based on simulated annealing (DOASA) to solve large-scale JSSPs with the objective of minimizing maximum lateness. In DOASA, the original problem will be divided into several subproblems, each of which corresponds to a subset of operations. The subproblems are first determined and then successively solved by two optimization processes, both of which are implemented with simulated annealing in order to save computational time. Before decomposition, the constraint propagation technique is applied as a preprocessor on the original problem so that some disjunctive arcs can be resolved. This information provides guidance for the determination of decomposition policy and subproblems.
The paper is organized as follows. The discussed job shop scheduling problem is formulated in Section 2. Section 3 introduces the important tools that are used by our algorithm. Section 4 describes the DOASA in detail. The computational results are provided in Section 5. Finally, some conclusions are given in Section 6.
2. Problem formulation
In a JSSP instance, a set of n jobs are to be processed on a set of m machines such that each machine can process only one job at a time, and each job may be processed by only one machine at a time. Each job has a fixed processing route which traverses all the machines in a predetermined order. A preset due date is given for each job. Since due date related criteria are of much greater concern in practical scheduling, maximum lateness is adopted as the optimization objective.
JSSP can be described by a disjunctive graph [23]. is the set of nodes where are associated with the operations of the JSSP instance. 0 and ∗ denote the dummy source node and the dummy sink node, respectively. C is the set of conjunctive arcs which connect successive operations of the same job. Thus, C models the technological constraints in the JSSP instance. is the set of disjunctive arcs if is used to denote the disjunctive arcs that correspond to the operations on machine k. contains the arcs that connect each pair of operations to be processed by machine k and require that these operations cannot be processed simultaneously. Therefore, the directions of the disjunctive arcs are yet to be determined. Finding a feasible schedule for JSSP is equivalent to orienting all the disjunctive arcs without causing any directed cycles in the resulting graph. The weight of each arc equals the processing time of the operation that is associated with the tail of the arc.
The discussed JSSP can be formulated as follows:
In this formulation, is the set of the last operations of each job; is the due date of the job which operation i belongs to; and are the processing time and the starting time of operation i, respectively. The lateness of job j is defined as where equals the completion time of the last operation of job j. The scheduling objective considered in this paper is to determine the processing sequence of operations on each machine such that the maximum lateness (i.e. ) is minimized. The problem is noted as in accordance with the three-field notation.
3. Theoretical background
3.1. Simulated Annealing (SA)
The SA algorithm is commonly used for solving combinatorial optimization problems. It starts from an initial basic solution and randomly generates a neighbour solution from its neighbourhood. is accepted as a new basic solution with probability P, which is calculated as
where is the difference in objective value between the two solutions, and T is the temperature which decreases with iterations. The searching process keeps generating a neighbour solution and accepting it with the above probability until some stopping criterion is met. The framework of the standard SA algorithm can be described as follows.
Step 1. Produce an initial solution . Set .
Step 2. For
Randomly generate a neighbour solution from the neighbourhood of .
If , set .
Set with probability .
Reduce the temperature by setting , where is the cooling rate.
Step 3. Return x∗.
3.2. Constraint Propagation (CP)
In this part, we will introduce the basic application of CP theory to job shop scheduling.
We use to denote a specific JSSP instance. As introduced above, is the set of operations; C is the set of conjunctive arcs and indicates operation i must be processed before operation j; D is the set of disjunctive arcs and indicates operation i cannot overlap with operation j in processing; is the set of operation processing times.
In order to apply CP to JSSP, it is required to first give an upper bound for the optimal of the instance. Therefore, if we use to denote the feasible domain of starting times of each operation , we must have . Normally, the tighter the upper bound, the more information will be derived by CP.
The earliest starting time and the latest starting time of operation i are respectively defined as , . Thus, can also be expressed as . Meanwhile, we define the earliest completion time and the latest completion time of operation i respectively as and .
For a subset of operations (which need to be processed on the same machine), we define the following functions: , and .
In the following, some of the most important principles for applying CP to JSSP are presented [9].
Theorem 1 (Conjunctive consistency test)If and , then the following domain reduction rule is effective:
Clearly, the time complexity of revising the earliest/latest starting times is .
Theorem 2 (Input/output sequence consistency test)Assumeand, if the following “input condition” is satisfied:
then operation i must be completed before every operation in A. Similarly, if the following “output condition” is satisfied:
then operation i must be processed after every operation in A.
When , the above theorem can be stated as: if and , then the disjunctive arc direction can be fixed. Such a “pair-wise test” can be performed in time.
Theorem 3 (Output domain consistency test)If there existandwhich satisfy the output condition, then the earliest starting time of operationi can be adjusted as
Naturally, a dual conclusion exists for describing the input condition.
Theorem 4 (Input/output negation sequence consistency test)Assumeand, if the following “input negation condition” is satisfied:
then operation i cannot be completed before every operation in A. Similarly, if the following “output negation condition” is satisfied:
then operation i cannot be processed after every operation in A.
Theorem 5 (Input negation domain consistency test)If there existandwhich satisfy the input negation condition, then the earliest starting time of operationican be adjusted as
Naturally, a dual conclusion exists for describing the output negation condition.
Besides the listed theorems, there are some others, such as the input-or-output consistency test. In the subsequent part of the paper, the application of CP to JSSP is regarded as an independent module, the procedure of which can be found in [14].
4. The algorithm
4.1. The decomposition method
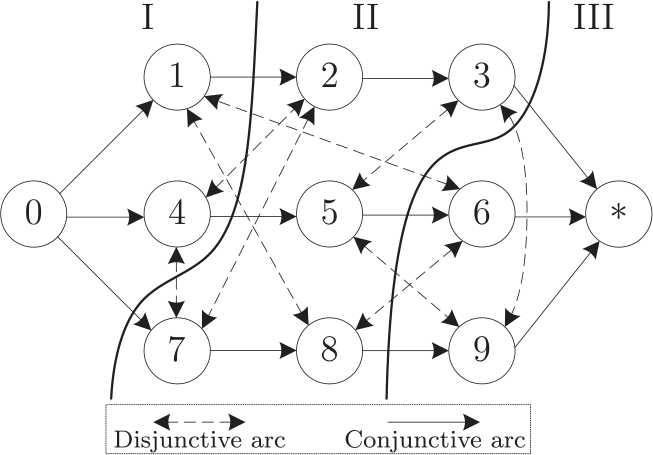
The decomposition scheme used in this paper can be intuitively illustrated using a disjunctive graph like Figure 1, in which nine operations of three jobs are to be processed on three machines. According to the conjunctive arcs, operations 1-3 belong to job 1, operations 4-6 belong to job 2 and operations 7-9 belong to job 3. According to the disjunctive arcs, operations 1, 6 and 8 are to be processed by machine 1, operations 2, 4 and 7 are to be processed by machine 2, and operations 3, 5 and 9 are to be processed by machine 3. The dividing curves representing a decomposition policy divide the operation set into three sequential subsets: I, II and III, each of which corresponds to a subproblem.
An illustration of the decomposition method
To be precise, the decomposition method has the following properties: (1) If the original operation set is divided into p subsets , then , and , ; (2) For any two operations i and j, if and , , then .
4.2. Using CP as a preprocessor for JSSP
From Section 3.2, we see that CP can derive the correct direction of some disjunctive arcs by alternating sequence consistency tests and domain consistency tests. The following algorithm is designed by combining CP with local search in an iterative fashion so that a tight upper bound can be used to orient a sufficient number of disjunctive arcs.
Input: The problem instance .
Step 1. Construct the initial solution based on the EDD (earliest due date) dispatching rule. Let , where denotes the objective value of a solution. Let the initial set of directed disjunctive arcs and .
Step 2. Perform a stochastic local search starting from (employing w iterations) in order to find a new best-so-far solution and update the upper bound . If no improvement is found within the w iterations, then output .
Step 3. Add a set of new constraints “ , ” and then call the CP module to derive as much information as possible. The disjunctive arc directions newly obtained in this step are denoted as . If for some operation or contains cycles, output . Otherwise, let and .
Step 4. Taking as the precedence constraints, construct a new solution based on the EDD rule. If , let . Go back to Step 2.
The above algorithm can be used as a preprocessor which is applied to a JSSP instance before we start to solve it. The two parameters involved in this procedure are w (the number of iterations in each run of local search) and Δ (the step size when lowering the upper bound). The resolved disjunctive arcs will be used to determine a decomposition policy for the JSSP instance.
4.3. Finding a decomposition policy
A decomposition policy determines the structures of all the subproblems at a time and thus it directly affects the subsequent optimization process. In this paper, a simulated annealing (SA) approach is designed to search for a satisfactory decomposition policy based on the previously derived disjunctive arc directions.
SA searches among all possible decomposition policies and outputs a promising policy, which divides the operation set into p successive subsets by satisfying the maximum number of derived disjunctive arcs. The input parameters include the desired number of operations in each produced subset, i.e., .
A directed disjunctive arc is “satisfied” if the subset containing operation i is not preceded by the subset containing operation j. With respect to the previous example (see Figure 2 here), if the disjunctive arcs and have been oriented by CP, then the illustrated decomposition policy satisfies (because operation 1 is in subset I and operation 8 is in subset II), but does not satisfy (because subset II, which includes operation 8, precedes subset III which includes operation 6). To be precise, suppose and the considered decomposition policy (dividing the original operation set into p successive subsets ) indicates , , then is satisfied only if .
An illustration of satisfied and dissatisfied arcs
4.3.1. Encoding
A matrix is used to encode a solution, where the element denotes the number of operations that belong to job j and have been assigned to subset . According to this definition, B has to satisfy:
In the above equations, m is exactly the number of operations included by each job. Besides, since the operations of each job are decomposed according to their technological order, a matrix in the form of B is sufficient for encoding a solution in the SA.
For example, the decomposition policy shown in Figure 2 should be encoded as
where the first row means the 1st operation of job 1 is assigned to the subset I, the next two operations of job 1 are assigned to subset II, while no operation of job 1 is assigned to subset III.
4.3.2. Initialization
A heuristic rule similar to EDD is used to produce the initial solution. For each operation i in O, we define the modified due date as:
where is the due date of the job to which operation i belongs. Just like , the newly defined also describes the urgency level of operation i, but in a more strict manner than the original due date.
Then, all the operations are sorted in a non-decreasing order of , yielding an operation sequence . After that, the p subsets are successively assigned with operations in the order specified by this sequence.
According to the encoding scheme, the value of (the number of job j's operations that have been assigned to subset ) can now be acquired, and thus, the encoding matrix for this initial decomposition policy is obtained.
4.3.3. New solution generation
In order to generate a new solution from the current solution, the algorithm randomly selects an element from B and sets where ξ is a two-value random variable in with probability . For keeping the row sum and the column sum of B constant, the algorithm randomly selects another three elements and () from B and sets , and . Notably, it must be ensured that the resulting matrix elements satisfy .
4.3.4. Evaluation
The number of satisfied disjunctive arcs is adopted as the objective function of SA in this stage. Therefore, the evaluation of a solution is formally described as
where if the derived arc is satisfied and otherwise.
For example, the decomposition policy shown in Figure 2 has an objective value of
because the directed disjunctive arcs are all satisfied except .
4.4. Solving each subproblem
In this paper, the process of solving each subproblem is equivalent to optimizing the sequence of the operations involved in this subproblem (). To this end, a simulated annealing algorithm is designed. The main steps to solve the l -th subproblem are described as follows.
4.4.1. Encoding
The encoding scheme is based on operation priority lists. A solution relates each machine with a priority list of the operations (from ) to be processed on this machine. Note that after the decoding process, the actual processing order of the operations in the final feasible schedule may differ from the priority lists.
4.4.2. Initialization
The initial solution is provided by the EDD dispatching rule, where the due date of each operation is taken as .
4.4.3. New solution generation
In order to generate a new solution from the current solution, we must first identify a machine and then somehow alter the operation list related with the selected machine. Hence, machine selection is a key step in this process. We hope to select the machines which are scheduled not very well and therefore have relatively larger room for further improvement.
To achieve this aim, we define an index for each machine k to evaluate the scheduling efficiency of this machine:
where is the set of operations to be processed by machine k in ; is the completion time of operation i in the current schedule; . reflects the scheduling performance of machine k, and a larger value of suggests machine k is currently scheduled less satisfactorily. Therefore, if we focus more of the subsequent optimization efforts on those machines with higher Ψ values, it is more likely to obtain improvement. So the proportional method (a.k.a. roulette wheel selection) is adopted here for the selection of a machine, i.e., machine k is selected with probability .
Finally, the “SWAP” operator is used to exchange the positions of two randomly chosen operations in the selected machine's priority list, and then a new solution is produced.
4.4.4. Evaluation
The decoding process iteratively schedules the ready operations in the current subproblem according to their priority order indicated by the solution and as early as possible, on the basis of the partial schedule obtained in the previous subproblems (a data structure similar to the Gantt chart is used to record the partial schedules obtained in previous subproblems).
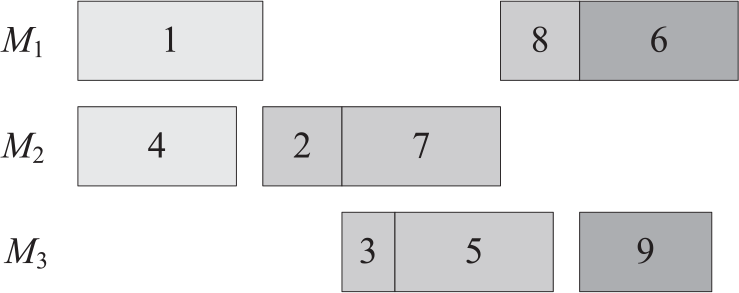
Taking the instance shown in Figure 2 as an example, we can see the incremental process of solving each subproblem. After subproblem 1 is solved, the positions of operations 1 and 4 (light grey) should be fixed, which form the basis for solving subproblem 2. After subproblem 2 is solved, the positions of operations 8, 2, 7, 3 and 5 (medium grey) should be fixed, which, together with the previously fixed operations 1 and 4, form the basis for solving subproblem 3. Once subproblem 3 has been solved, the positions of operations 6 and 9 (dark grey) should be fixed. Now, we could obtain a complete solution to the original problem, as shown in Figure 3.
Solving the three subproblems successively
The evaluation of a solution is based on the local objective function defined as
where denotes the last operation in the technological route of job j that belongs to the current subproblem . Taking the case described in Figure 3 as an example, when we are solving subproblem 2, the local objective function should be evaluated based on operations 3, 5 and 8, that is, , , .
5. Computational experiments
In this section, some JSSP benchmark instances from the OR-Library [6] are used to evaluate the performance of DOASA. Since this research is aimed at large-scale problems, only the instances that include no less than 300 operations are tested. These 27 instances belong to the LA, ABZ, SWV and YN classes. Moreover, in order to adapt the instances for the objective function considered here, the due date of each job is set based on its total processing time as , where is the sum of processing times of all the operations that constitute job j, and is the due date tightness factor.
In the computational experiments, the parameters for SA are set as: the initial acceptance probability ; the temperature reduction ratio ; the number of inner iterations (number of samples obtained at each temperature) ; the number of outer iterations (number of temperature stages) . The parameters for the CP-based preprocessor is set as: the local search iteration number ; the step size for locating upper bound . Meanwhile, the number of subproblems for each instance is fixed according to some preliminary computational results: for the instances with 500 operations (SWV11–SWV20), is adopted; for the remaining instances with 300 or 400 operations, is adopted. Once p is fixed, the number of operations in each subproblem is
The last subproblem contains more operations in order to facilitate the final adjustment of the schedule for improving the objective value.
In order to examine the effectiveness of the presented approach, DOASA is compared with the following methods:
The genetic algorithm (GA) applying operation-based encoding scheme and heuristic initialization;
The fast TS/SA hybrid algorithm which combines the advantages of tabu search and simulated annealing [24];
In the GA, the initial population is generated by applying various effective dispatching rules, including SPT, EDD, MDD, etc. [13]. The parameters of GA are set as: the population size is 100, the maximum generation number is 500 (or determined by the exogenous limit on computational time), the crossover probability is 0.8 and the mutation probability is 0.1. The parameters of TS/SA are determined according to the original literature [24].
All the algorithms are implemented in Visual C++ 7 and tested on an Intel Core i5-750 / 3GB RAM / Windows 7 platform. To make the comparison meaningful, we keep the running time of each algorithm identical. In each trial, we run DOASA first and record its computational time as , and then run GA and TS/SA under the time limit of (which controls the realized number of iterations for each algorithm).
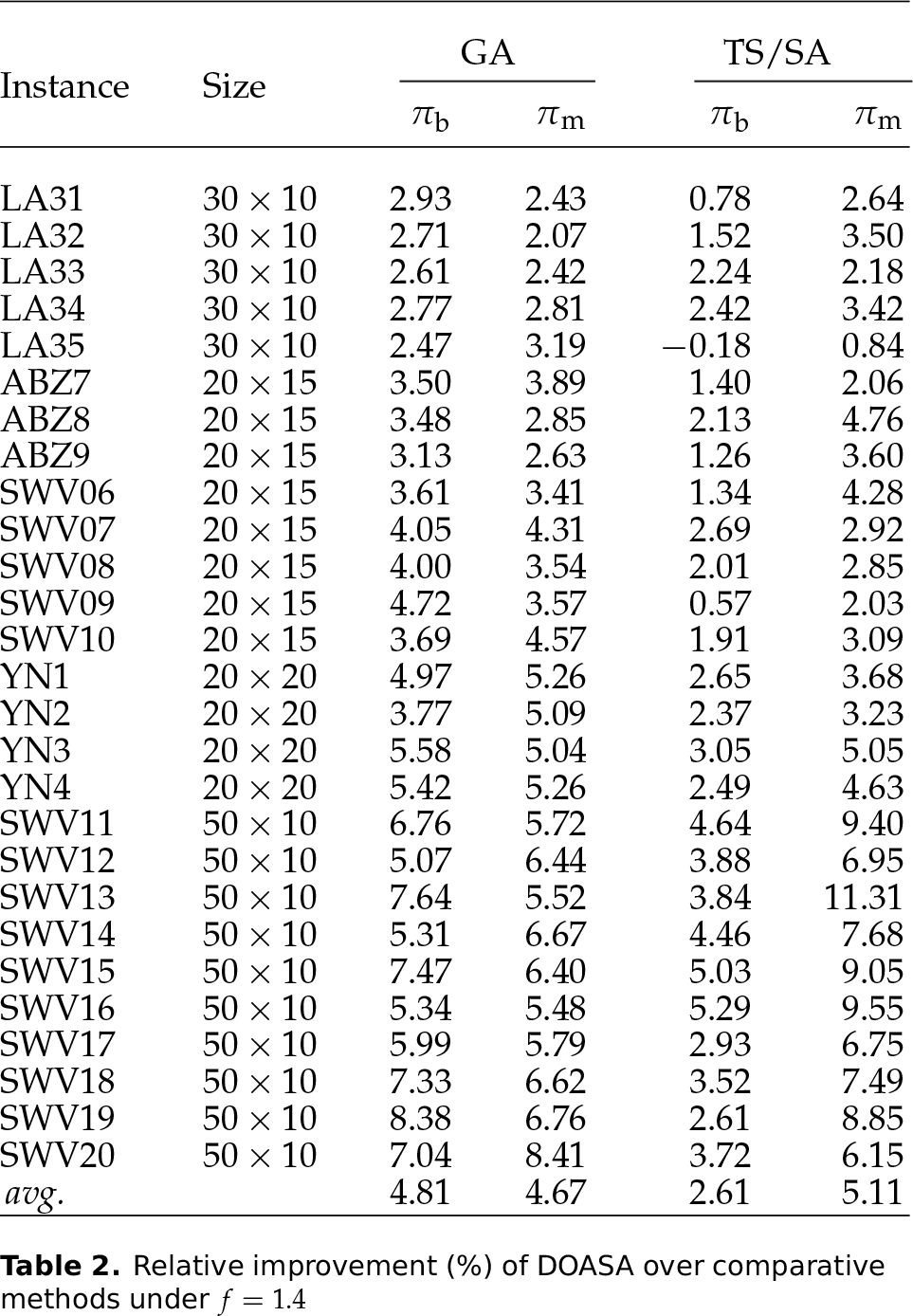
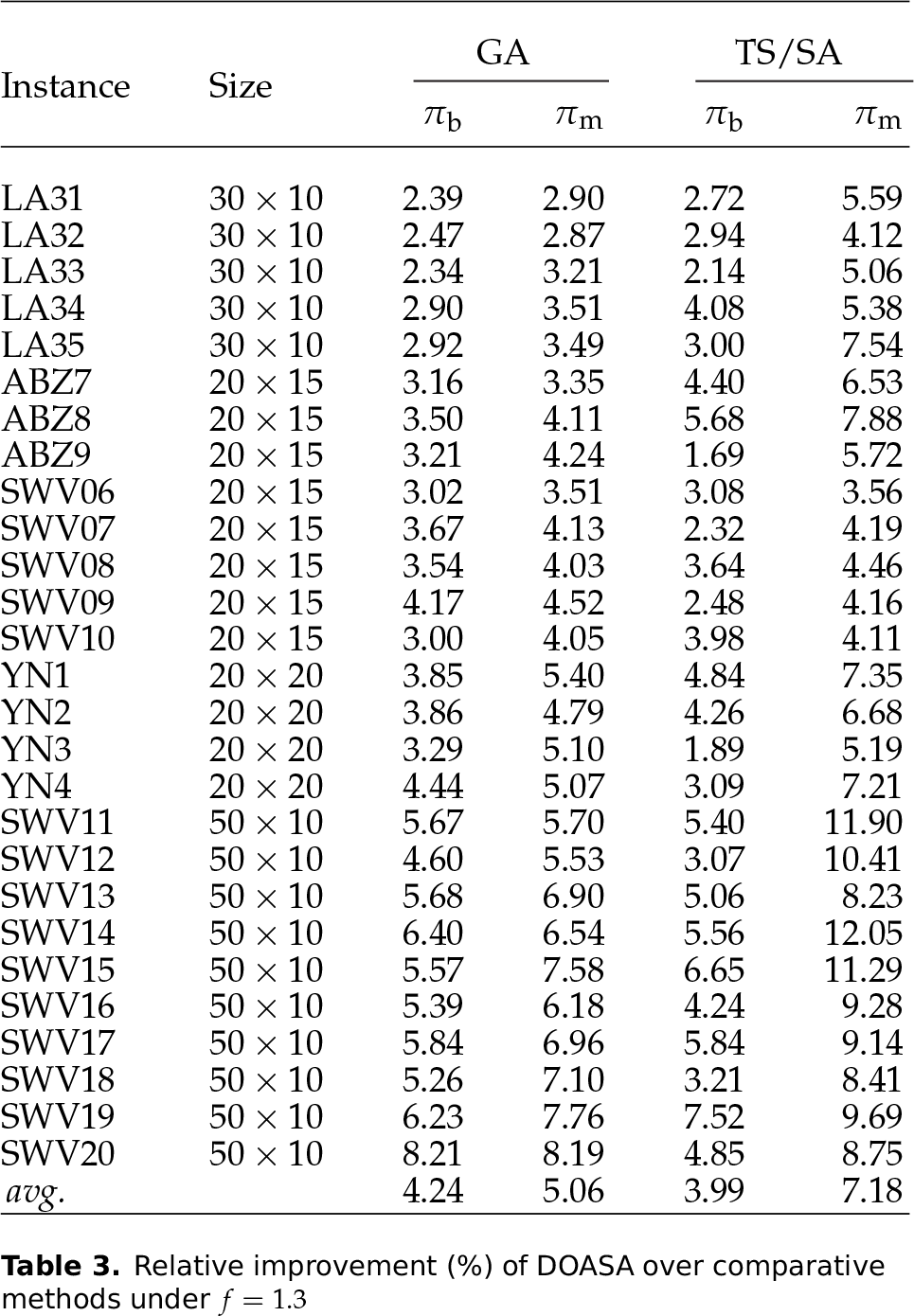
Table 1 presents the results for wide due date settings (), Table 2 presents the results for moderate due date settings (), and Table 3 presents the results for tight due date settings (). In the tables, the first two columns list the instance names and their sizes in the format of . For each instance, all the algorithms are allowed to run 10 independent times. Since absolute objective values are unimportant for comparison purposes, the focus here is put on relative values. is used to characterize the improvement (in percentage) of the best solution obtained by DOASA during the 10 runs over the best solution by the comparative method. Formally, we define
where is the best objective value for instance obtained by the algorithm a () in the 10 runs. Defined similarly, denotes the percentage improvement of the mean objective value obtained by DOASA during the 10 runs over the mean objective value by the comparative method (detailed formula omitted here). The maximum lateness remains positive even under so that the relative values (, ) are meaningful and comparable.
Relative improvement (%) of DOASA over comparative methods under
Instance
Size
GA
TS/SA
πb
πm
πb
πm
LA31
30 × 10
2.13
1.99
0.65
1.91
LA32
30 × 10
1.80
1.92
1.40
2.73
LA33
30 × 10
2.27
2.16
1.84
2.16
LA34
30 × 10
2.12
2.33
1.99
2.71
LA35
30 × 10
2.17
2.44
0.22
0.56
ABZ7
20 × 15
2.31
2.93
1.36
1.82
ABZ8
20 × 15
2.35
2.96
1.94
3.96
ABZ9
20 × 15
2.06
2.41
1.12
3.13
SWV06
20 × 15
2.46
2.73
1.14
3.50
SWV07
20 × 15
2.87
3.66
2.08
2.06
SWV08
20 × 15
3.22
3.06
1.74
2.34
SWV09
20 × 15
3.58
3.76
−0.51
1.73
SWV10
20 × 15
3.07
4.04
1.43
2.54
YN1
20 × 20
3.76
3.63
2.08
3.16
YN2
20 × 20
3.43
4.18
1.74
2.66
YN3
20 × 20
4.15
3.73
2.66
4.01
YN4
20 × 20
4.23
3.79
2.53
3.29
SWV11
50 × 10
4.14
4.67
3.97
6.62
SWV12
50 × 10
3.91
5.14
3.19
5.84
SWV13
50 × 10
4.46
4.93
3.62
9.38
SWV14
50 × 10
4.98
5.26
3.88
6.21
SWV15
50 × 10
5.29
5.29
4.35
7.92
SWV16
50 × 10
3.80
5.06
4.48
8.24
SWV17
50 × 10
5.20
5.82
2.59
5.67
SWV18
50 × 10
5.13
5.65
3.17
6.46
SWV19
50 × 10
5.57
6.68
2.42
6.34
SWV20
50 × 10
5.45
6.29
3.55
5.76
avg.
3.55
3.94
2.25
4.17
Relative improvement (%) of DOASA over comparative methods under
Instance
Size
GA
TS/SA
πb
πm
πb
πm
LA31
30 × 10
2.93
2.43
0.78
2.64
LA32
30 × 10
2.71
2.07
1.52
3.50
LA33
30 × 10
2.61
2.42
2.24
2.18
LA34
30 × 10
2.77
2.81
2.42
3.42
LA35
30 × 10
2.47
3.19
−0.18
0.84
ABZ7
20 × 15
3.50
3.89
1.40
2.06
ABZ8
20 × 15
3.48
2.85
2.13
4.76
ABZ9
20 × 15
3.13
2.63
1.26
3.60
SWV06
20 × 15
3.61
3.41
1.34
4.28
SWV07
20 × 15
4.05
4.31
2.69
2.92
SWV08
20 × 15
4.00
3.54
2.01
2.85
SWV09
20 × 15
4.72
3.57
0.57
2.03
SWV10
20 × 15
3.69
4.57
1.91
3.09
YN1
20 × 20
4.97
5.26
2.65
3.68
YN2
20 × 20
3.77
5.09
2.37
3.23
YN3
20 × 20
5.58
5.04
3.05
5.05
YN4
20 × 20
5.42
5.26
2.49
4.63
SWV11
50 × 10
6.76
5.72
4.64
9.40
SWV12
50 × 10
5.07
6.44
3.88
6.95
SWV13
50 × 10
7.64
5.52
3.84
11.31
SWV14
50 × 10
5.31
6.67
4.46
7.68
SWV15
50 × 10
7.47
6.40
5.03
9.05
SWV16
50 × 10
5.34
5.48
5.29
9.55
SWV17
50 × 10
5.99
5.79
2.93
6.75
SWV18
50 × 10
7.33
6.62
3.52
7.49
SWV19
50 × 10
8.38
6.76
2.61
8.85
SWV20
50 × 10
7.04
8.41
3.72
6.15
avg.
4.81
4.67
2.61
5.11
Relative improvement (%) of DOASA over comparative methods under
Instance
Size
GA
TS/SA
πb
πm
πb
πb
LA31
30 × 10
2.39
2.90
2.72
5.59
LA32
30 × 10
2.47
2.87
2.94
4.12
LA33
30 × 10
2.34
3.21
2.14
5.06
LA34
30 × 10
2.90
3.51
4.08
5.38
LA35
30 × 10
2.92
3.49
3.00
7.54
ABZ7
20 × 15
3.16
3.35
4.40
6.53
ABZ8
20 × 15
3.50
4.11
5.68
7.88
ABZ9
20 × 15
3.21
4.24
1.69
5.72
SWV06
20 × 15
3.02
3.51
3.08
3.56
SWV07
20 × 15
3.67
4.13
2.32
4.19
SWV08
20 × 15
3.54
4.03
3.64
4.46
SWV09
20 × 15
4.17
4.52
2.48
4.16
SWV10
20 × 15
3.00
4.05
3.98
4.11
YN1
20 × 20
3.85
5.40
4.84
7.35
YN2
20 × 20
3.86
4.79
4.26
6.68
YN3
20 × 20
3.29
5.10
1.89
5.19
YN4
20 × 20
4.44
5.07
3.09
7.21
SWV11
50 × 10
5.67
5.70
5.40
11.90
SWV12
50 × 10
4.60
5.53
3.07
10.41
SWV13
50 × 10
5.68
6.90
5.06
8.23
SWV14
50 × 10
6.40
6.54
5.56
12.05
SWV15
50 × 10
5.57
7.58
6.65
11.29
SWV16
50 × 10
5.39
6.18
4.24
9.28
SWV17
50 × 10
5.84
6.96
5.84
9.14
SWV18
50 × 10
5.26
7.10
3.21
8.41
SWV19
50 × 10
6.23
7.76
7.52
9.69
SWV20
50 × 10
8.21
8.19
4.85
8.75
avg.
4.24
5.06
3.99
7.18
The results in Tables 1–3 reveal the effectiveness of DOASA. The following remarks can be made regarding the algorithm's performance.
At each due date level, the superiority of DOASA over the comparative methods is more significant for the larger instances (SWV11–SWV20 with ) than for the smaller instances (with ). This can be interpreted as evidence that decomposing a large JSSP instance into smaller subproblems will make the search process more efficient during optimization.
It is observed that for most instances, holds, which means the improvement on mean objective value is usually greater than the improvement on best objective value. So it is reasonable to conclude that the stability of DOASA in different executions is considerably stronger than the comparative algorithms. The robustness is an advantage brought by the decomposition-based optimization framework which builds the final schedule in an incremental way.
By comparing the average of GA and TS/SA, we may find that TS/SA performs better than GA in terms of the best solution quality. This can be explained by the fact that the combination of TS and SA significantly enhances the exploitation ability of the search algorithm. Then, if we compare the average of GA and TS/SA, we find that GA outperforms TS/SA in terms of the mean solution quality. Therefore, in spite of its weakness in intensified search, GA performs more stably in different runs due to its population-based searching behaviour.
By comparing the three tables, it is apparent that the relative improvement of DOASA over the comparative algorithms is larger in the case of a tighter due date (i.e., smaller f). Such a difference in due date robustness also reflects the effectiveness of the decomposition procedure based on constraint propagation. When the due dates are tighter (i.e., is smaller), more disjunctive arc directions can be derived by constraint propagation, which helps to generate a more useful and reliable decomposition policy.
The computational time consumed by DOASA when solving the four representative instances is shown in Figure 4. The due date tightness affects the process of constraint propagation and operation decomposition, so the time needed for handling tight due dates is higher than for wide due dates.
The computational time consumed by DOASA
To test the impact of subproblem number (p) on the final solution quality, the results obtained by DOASA under different p values for two selected instances (SWV06 and SWV11) are recorded and shown as relative percentage values in Figure 5. In this figure, we define
The impact of p on solution quality
where denotes the obtained mean objective value in 10 runs when the subproblem number is set as p, and is the optimal subproblem number within the considered range () of possible p values.
Figure 5 suggests the subproblem number in DOASA can affect the solution quality to a noticeable extent. We have for the instance SWV06 and for the instance SWV11. When the actual subproblem number is far less than , the optimization result is much poorer because the benefit of decomposition has not been fully utilized. On the other extreme, if the adopted subproblem number is unduly large, the solution quality also deteriorates because the additional preferential order imposed by the decomposition procedure can reduce the potential search space, thus limiting the subsequent optimization process for each subproblem.
6. Conclusion
A decomposition-based optimization algorithm is proposed in this paper for large-sized job shop scheduling problems with the maximum lateness criterion. The theory of constraint propagation is utilized as a preprocessor for the pending problem instance so that a number of disjunctive arcs can be correctly oriented. Simulated annealing is adopted as the main framework in the two optimization procedures, i.e., the search for a promising decomposition policy and the solving of each subproblem. Experiments have been carried out for adapted JSSP benchmark instances. The performance of the proposed algorithm surpasses the competing methods (under the same computational time limit), especially for larger instances and under tighter due date settings. The results verify the effectiveness and efficiency of both the decomposition procedure and the subproblem solution procedure. In the future research, parallel computing (e.g., based on GPU) techniques may be considered as a method for accelerating the execution of the proposed algorithm. In this way, the subproblems can be solved in parallel once they have been determined by the decomposition procedure, which will shorten the running time considerably.
Footnotes
7. Acknowledgements
The paper is supported by the National Natural Science Foundation of China (61104176), the Science and Technology Project of Jiangxi Provincial Education Department (GJJ12131), the Social Sciences Research Project of Jiangxi Provincial Education Department (GL1236), and the Educational Science Research Project of Jiangxi Province (12YB114).
References
1.
VinodV. and SridharanR.Scheduling a dynamic job shop production system with sequence-dependent setups: An experimental study. Robotics and Computer-Integrated Manufacturing, 24(3):435–449, 2008.
2.
ÇakarT.KökerR., and SariY.Parallel robot scheduling to minimize mean tardiness with unequal release date and precedence constraints using a hybrid intelligent system. International Journal of Advanced Robotic Systems, 9, 2012.
3.
RamaseshR.Dynamic job shop scheduling: a survey of simulation research. Omega – The International Journal of Management Science, 18(1):43–57, 1990.
4.
AhmedI. and FisherW. W.Due date assignment, job order release, and sequencing interaction in job shop scheduling. Decision Sciences, 23(3):633–647, 1992.
5.
SabuncuogluI. and ComlekciA.Operation-based flowtime estimation in a dynamic job shop. Omega – The International Journal of Management Science, 30(6):423–442, 2002.
6.
LiuS. Q. and KozanE.Scheduling trains with priorities: a no-wait blocking parallel-machine job-shop scheduling model. Transportation Science, 45(2):175–198, 2011.
7.
CarlierJ. and PinsonE.An algorithm for solving the job shop problem. Management Science, 35:164–176, 1989.
8.
SculliD.Priority dispatching rules in job shops with assembly operations and random delays. Omega – The International Journal of Management Science, 8(2):227–234, 1980.
9.
KanetJ. J. and HayyaJ. C.Priority dispatching with operation due dates in a job shop. Journal of Operations Management, 2(3):167–175, 1982.
10.
BakerK. R.Sequencing rules and due-date assignments in a job shop. Management Science, 30(9):1093–1104, 1984.
11.
AdamsJ.BalasE., and ZawackD.The shifting bottleneck procedure for job shop scheduling. Management Science, 34(3):391–401, 1988.
12.
BalasE. and VazacopoulosA.Guided local search with shifting bottleneck for job shop scheduling. Management Science, 44(2):262–275, 1998.
13.
LiuS. Q. and KozanE.A hybrid shifting bottleneck procedure algorithm for the parallel-machine job-shop scheduling problem. Journal of the Operational Research Society, 63(2):168–182, 2012.
14.
ZhangR. and WuC.A simulated annealing algorithm based on block properties for the job shop scheduling problem with total weighted tardiness objective. Computers & Operations Research, 38(5):854–867, 2011.
15.
ZobolasG. I.TarantilisC. D., and IoannouG.A hybrid evolutionary algorithm for the job shop scheduling problem. Journal of the Operational Research Society, 60(2):221–235, 2009.
16.
SelsV.CraeymeerschK., and VanhouckeM.A hybrid single and dual population search procedure for the job shop scheduling problem. European Journal of Operational Research, 215(3):512–523, 2011.
17.
ZhuZ. C.NgK. M., and OngH. L.A modified tabu search algorithm for cost-based job shop problem. Journal of the Operational Research Society, 61(4):611–619, 2010.
18.
ZhangR.SongS., and WuC.A two-stage hybrid particle swarm optimization algorithm for the stochastic job shop scheduling problem. Knowledge-Based Systems, 27:393–406, 2012.
19.
SidneyJ. B.Decomposition algorithms for single machine sequencing with precedence relations and deferral costs. Operations Research, 23(2):283–298, 1975.
20.
BassettM. H.PeknyJ. F., and ReklaitisG. V.Decomposition techniques for the solution of large-scale scheduling problems. AIChE Journal, 42(12):3373–3387, 1996.
21.
SunD. and BattaR.Scheduling larger job shops: a decomposition approach. International Journal of Production Research, 34(7):2019–2033, 1996.
22.
SingerM.Decomposition methods for large job shops. Computers & Operations Research, 28(3):193–207, 2001.
23.
WuS. D.ByeonE. S., and StorerR. H.A graph-theoretic decomposition of the job shop scheduling problem to achieve scheduling robustness. Operations Research, 47(1):113–124, 1999.
24.
DorndorfU.PeschE., and Phan-HuyT.Constraint propagation techniques for the disjunctive scheduling problem. Artificial Intelligence, 122(1):189–240, 2000.
25.
Phan-HuyT.Constraint propagation in flexible manufacturing.Springer, 2000.
26.
BeasleyJ. E.OR-library: distributing test problems by electronic mail. Journal of the Operational Research Society, 41(11):1069–1072, 1990.
27.
ZhangC. Y.LiP. G.RaoY. Q., and GuanZ. L.A very fast TS/SA algorithm for the job shop scheduling problem. Computers & Operations Research, 35(1):282–294, 2008.
28.
PanwalkarS. and IskanderW.A survey of scheduling rules. Operations Research, 25(1):45–61, 1977.