
Abstract
To improve the natural human-avoidance skills of service robots, a human motion predictive navigation method is proposed, namely PN-POMDP. A human-robot motion co-occurrence estimation algorithm is proposed which incorporates long-term and short-term human motion prediction. To improve the reliability of probabilistic and predictive navigation, the POMDP model is utilized to generate navigation control policies through theoretically optimal decisions. A layered motion control structure is proposed that combines global path planning and reactive avoidance. Multiple comity policies are integrated with a decision-making module that generates efficient and human-compliant navigational behaviours for robots. Experimental results illustrate the effectiveness and reliability of the predictive navigation method.
1. Introduction
As service robots have been designed to provide interactive tasks in domestic and office environments, they must reliably navigate around a populated room. When robots and people encounter each other, human-aware motion planners[1] help robots treat people as social entities and aim to endow robots with safe and human-friendly navigational behaviours[2][3].
Predicting the motion of moving people is an effective way for compliant robot navigation in dynamic environments[4]. Many researchers[5][6][7][8] have developed efficient replanning algorithms to cope with the environmental dynamic and satisfy the real-time requirement by feeding the updated information to a grid map and optimizing the robot's path to minimize the expected time to its destination. Although reactive motion planners[9][10][11][12] are able to rapidly query the next appropriate action, they are prone to getting robots blocked in complex environments because of their greedy property and the uncertainty of human motion. According to research on human indoor motion modelling and understanding, a human's daily motions in a specific room environment presents certain long-term patterns. Nevertheless, uncertainties are pervasive in the velocity and heading direction of people's movement. Several studies have exploited the spatial-temporal nature of human motion using a chain of Gaussian distributions[13], clustering the trajectories with K-means[14], and learning human motion patterns from tracking data using an EM algorithm[6]. However, most past research ignores the combination of human motion uncertainty prediction with motion pattern prediction.
Another key factor of predictive navigation is inherent uncertainties[15][16], which typically necessitate intelligently reacting to unknown moving people. Due to the non-linear nature of human and robot motion, as well as sensor noise, the popular robot localization and people-tracking algorithm based on Bayes filtering can only estimate position distributions. The probabilistic human motion prediction algorithm is also likely to produce larger errors when making motion prediction.
Many researchers have already pointed out that probabilistic representation and reasoning is appropriate and very effective for navigating in noisy environments in the real world. In situations of probabilistic decisionmaking, Partially Observable Markov Decision Processes (POMDPs)[17][18] have already been widely used in robot navigation and interacting with people. Robots such as Flo[19] or Pearl[20] use POMDPs at all levels of decisionmaking, and not only in low-level navigation routines. But since finding optimal control strategies in POMDP cases is computationally intractable due to the continuous and high-dimensional beliefs space, POMDPs have usually been applied to topological navigation. For example, Foka[16] proposes a method for combining the prediction of the destination of a moving obstacle and its one-step-ahead positions. However, the proposed method relies on complex hierarchical decomposition of the environment and has only been implemented and successfully tested in a simulation application.
In this paper, a novel approach called POMDPs for Predictive Navigation (PN-POMDP) is proposed. The idea of predictive navigation is largely inspired by Sisbot's[1] human-aware planner, which focuses on providing human-friendly robot behaviours that imitate human motion habits. However, the human-aware planner does not take into account uncertainties when robots work in unstructured environments. This paper deals with the robustness and reliability requirements of a navigation system using the probabilistic reasoning (POMDP) method. We compute the uncertainties of human motion in two parts: the ambiguity in path selection and the motion uncertainty along each path. Then, the human-robot co-occurrence probability is estimated by analysing two situations: conflict and obstruction. Our major contribution is the PN-POMDP framework that coordinates the global path planner, the motion reactor and the speed controller in the context of probabilistic decision-making under conditions of multiple uncertainties. The control framework combines the objectives of goal-guiding reducing the probability of human-robot conflict. More importantly, by considering high perceptual aliasing and other uncertainty factors, it combines the probabilistic robot localization, people-tracking and human motion prediction in a natural probabilistic decision-making framework to generate robot control policies resulting in efficient and polite navigation behaviours.
This paper is organized as follows. After an overview of the navigation system framework in Section 2, Section 3 describes the human motion prediction method and Section 4 introduces the human-robot co-occurrence estimation in the spatial-temporal aspect. Section 5 describes the decision-making mechanism of predictive navigation and the POMDP. Finally, some experimental results are reported in Section 6, followed by a final discussion and conclusion that summarizes the paper.
2. Navigation System Architecture
2.1 Uncertainties in predictive navigation
Firstly, the trajectories of human motion are uncertain; velocity and direction usually vary within a range when they are engaged in specific motion patterns. Secondly, the localization errors are pervasive. A Simultaneous robot Localization And People-tracking (SLAP) system using global cameras and an onboard laser range finder has been developed in our previous work[21]. This jointly estimates a robot's pose rt and people's ground-plane position
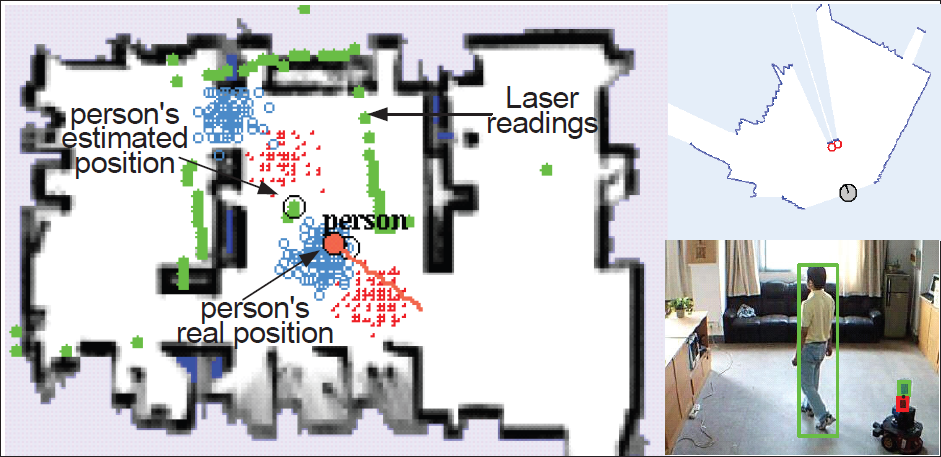
Uncertainty of robot localization and people-tracking
2.2 PN-POMDP control framework
The navigation system uses the robot's abstracted positional relation with the human as the states of the decision-making subsystem. The PN-POMDP system is modelled by a sextuple,
In the Control module, the POMDP-based decisionmaking sub-module generates a suitable predictive navigational (PN) policy that minimizes the risk of conflict with humans. We have designed four types of action: detour, slow-down, speed-up, and halt, which will be explained in Section 5. In order to ensure goal-directed and predictive navigation performance, the motion controller is constructed with a two-layered architecture augmented by policies generated from the POMDP controller. The wavefront-based global path planner calculates the optimal path and the reference points along the path based on mapped obstacles. The Nearness Diagram[12] based local reactive obstacle avoidance controller computes actual translational velocity v and rotational velocity ω based on the reference points and real-time sensory data.
Finding optimal policies in the POMDP case is computationally intractable because the beliefs space is continuous and high-dimensional. The solution adopted in this work is a hybrid control structure that combines the reactive motion control and the probabilistic strategy selection for generating optimal navigational behaviours, as shown in Figure 2. In the system, sensory data obtained from laser, global cameras and other sensors are processed by the SLAP module and fed to the Perception module. Human motion patterns learned by the Modelling module are also inputted to the Perception module, in which the future motion tendencies of people are predicted in both their long-term and short-term aspects. Then, the human and robot motion states are abstracted and three types of abstracted observations are formatted, namely People's Action Observation (PAO), People-robot Relation Observation (PRO) and Robot State Observation (RSO). These abstracted observations are inputted to the Control module.
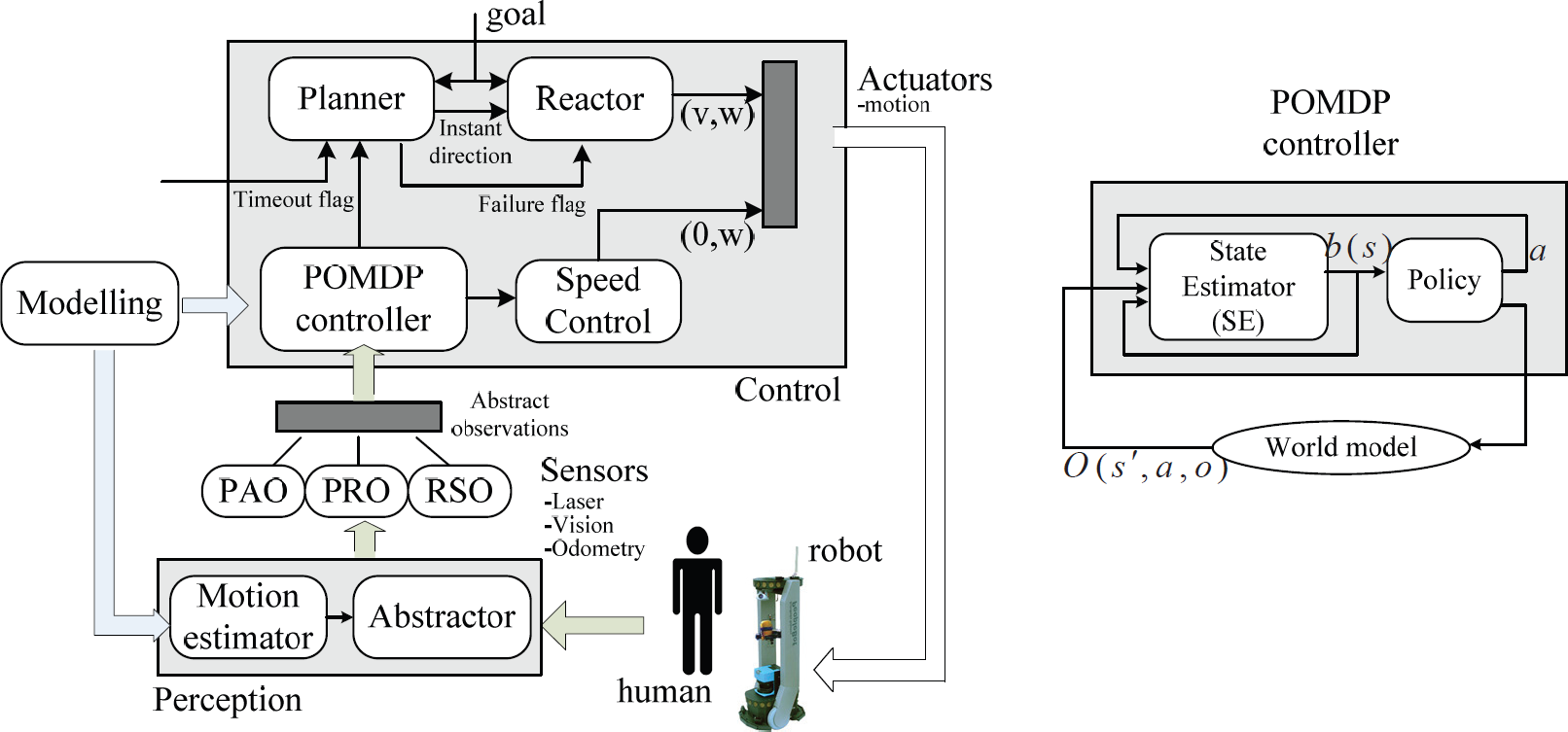
PN-POMDP system framework
A more detailed illustration of the POMDP controller structure is depicted in the right part of Figure 2. The POMDP controller contains a state estimator (SE) and a policy generator. The state estimator computes probabilistic distributions upon the belief bt according to o, a and bt-1. Meanwhile the policy generator maps the belief onto an optimal behaviour of the robot, i.e., a = ∂(bel).
3. Human motion prediction
3.1 Long-term modelling of motion pattern
Based on the collection of the tracking trajectories, a set of motion patterns of people are clustered hierarchically using a fuzzy K-means algorithm based on the spatial and temporal information. This algorithm results in a set Ψ of M different motion patterns Ψ = {Ψ1,…,ΨM}. Each motion pattern Ψm with 1 ≤ m ≤ M, is approximated by a mixture of K Gaussian distributions Ψ1m,…, Ψkm. Spatial probability of the person located at ht given step k of the motion pattern Ψm is computed according to the Gaussian distribution and denoted as p(ht | Ψkm):
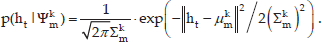
Without considering the uncertainty of the velocity and heading orientation during the person's motion, the robot's belief that the motion of the person is engaged in a motion pattern Ψ m is computed by the person's position ht at time t, given the history of his/her motion z1:t :

The probability p(ht | Ψm, k,k', z1:t) evaluates the probability of the person that covers the point ht at time t, given a sequence of observations z1:t and given that z1:t starts at ψkm and ends at ψk'm. The probability p(Ψm,k,k' | z1:t) can be decomposed according to the Bayes rule: (3)
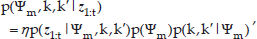
where e˜ is a normalizer, p(z1:t | Ψm,k,k') is the observation likelihood of z1:t and p(Ψm) and p(k,k' | Ψm) are two prior probability distributions.
Examples of learned human motion patterns are shown in Figure 3, which indicates that people typically move between places with important objects to manipulate: fridge, a printer, a washing machine, etc.

Human motion patterns learned from tracking data
3.2 Short-term motion prediction
To account for the short-term uncertainty of the movement along the path of Ψ m , the variation in velocity and heading orientation of the person are modelled.
We assume the following on the movement of a person[7]: δT is the time step in which a person keeps to a certain velocity and heading direction; the possible ranges of his/her motion velocity and orientation are represented as [Vmin, Vmax] and [θmin, θmax], respectively; he/she changes the velocity and orientation only at every time step δT. In this sense, the velocity (orientation) of a time step is constant, and is randomly and independently selected within the above range. According to these assumptions, the sequence of velocity (orientation) along time contains a list of velocities (orientations) that are independently distributed random variables. This assumption describes a common indoor motion style where people move smoothly between two places.
Firstly, the orientation variance is modelled by a fan-shaped area called the field of view, as shown in Figure 4. The field of view defines a coordinate system originated at the current position of the person, h0 = (x0,y0, θ0), and takes the Person's Instantaneous Orientation (PIO) as the symmetry axis. The maximum angular distance from the PIO is Λ = θmax and is defined by the size of the field of view. Within the field of view area, a point h = (r, α) has a probability of

Instantaneous heading direction of movement uncertainty estimation

to be the goal of movement in the next time step. Eq. 4 indicates that the higher the value of α, the less likely it is that the person will head in that direction.
Secondly, the velocity variance is modelled by a distribution pvel(ht;t) that calculates the probability of reaching a point

Motion velocity uncertainty estimation


Since each vi (i = 0,…,t) follows the same but independent uniform distribution of vi ∼ U(vmin,vmax), the variance σ2step of the movement (i.e., the velocity variance) added by one time step is calculated as:

Let Evi = μi and Dvi = σ2i be the mathematical expectation and variance of vi, respectively. According t to the central limit theorem,

where

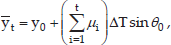
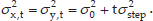
Moreover, according to the assumption that vi (i = 0,…,t) follows the same but independent uniform distribution, the sequence of variables v0,…,vt have the same mean and variance. This indicates that Evi = μi = V̄ = (vmax + vmin)/2, Dvi = σ2i = σ2 and
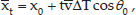

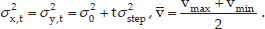
To combine the long-term and short-term prediction, the heading orientation probability Porien(

4. Human-robot Co-occurrence Estimation
The probability of human and robot co-occurrence is estimated in the spatial-temporal aspect according to the robot's travelling route obtained from the global path planner and the human motion prediction. In the PN-POMDP system, situations of human-robot co-occurrence are classified into two types.
The first type is human-robot motion conflict, which is denoted as θ = | θh – θr |, where θr and θh are the orientation of robot and human, respectively. In wide open indoor areas, a situation that satisfies θth1 θ< ∂ indicates that the robot's movement along its planned path and the person's future movement are likely to encounter both spatial and temporal factors. Let Lsafe be a safe distance between person and robot, and Pc denote the intersection point of the robot's path and the person's predicted motion trajectory. At current time t0, the predicted human-robot motion conflict at a future time has to satisfy the condition that the person is now at a position within
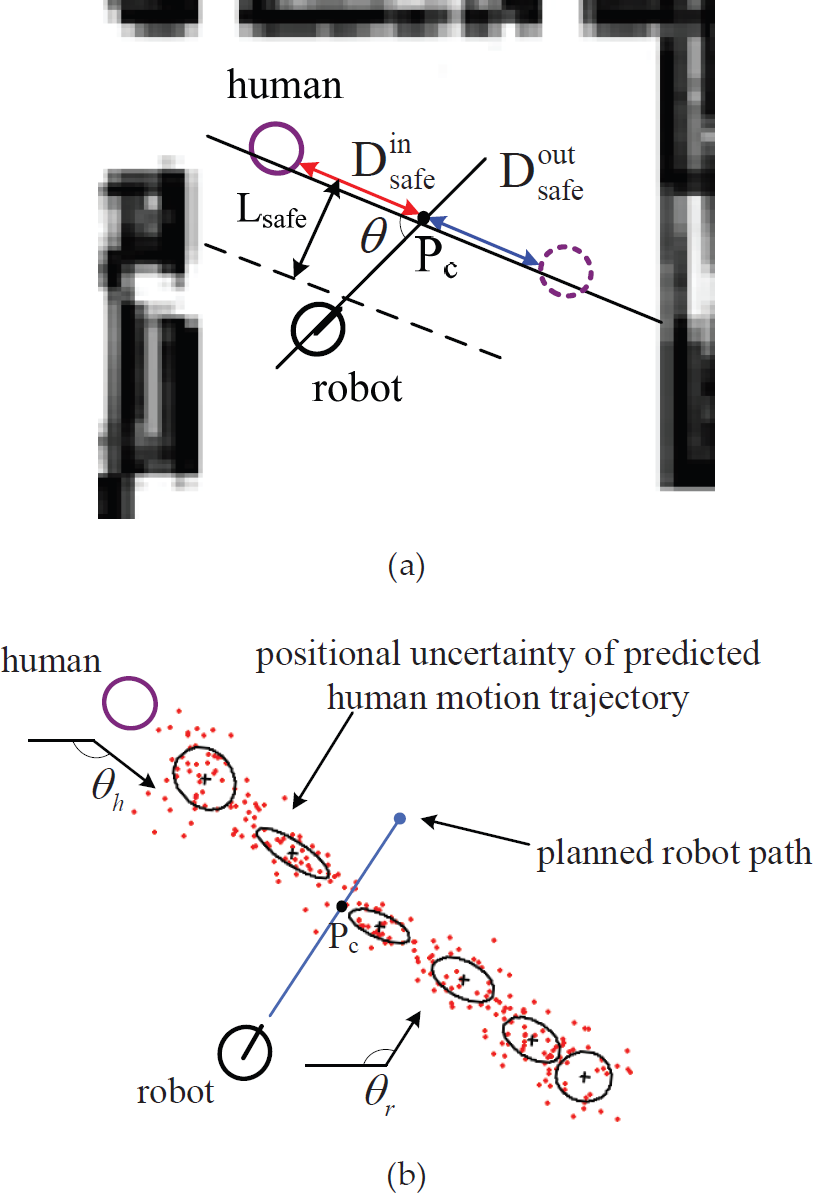
Human-robot motion conflict
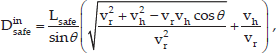
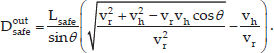
This is because if the person and the robot are moving along their respective paths at constant speeds of vh and vr, the robot will arrive at the place Pc at time t = t0 + Dinsafe/vh, and then its distance to the person will be less than Lsafe. If the motion uncertainty of the person is taken into account, the probability that he/she will arrive at place Pc at a future time t is computed according to Eq. 18:

where t = (Lsafe/sin θ)/vr. Moreover, in a special situation where θ = ∂, which indicates that the robot is moving towards the person, it will be impossible to calculate variables Pc, Dinsafe and Doutsafe. In this case, a face-to-face human-robot motion conflict is accounted.
The second situation is human-robot motion obstruction (as shown in Figure 7). This represents a situation where the robot's path will block a human's intentional trajectory, which happens to traverse a narrow passage. In this type of situation, a detected θ < θth2 event indicates that the paths of robot and human are generally parallel in opposite directions. To calculate possible spatial-temporal obstruction, the first and the last point along the robot's planned path that satisfies the condition of Eq. 19 and Eq. 20 are computed:

Human-robot motion obstruction
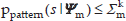
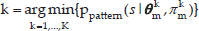
These two points are denoted as the InPoint sin and the OutPoint sout of their path intersection, respectively. Suppose that human and robot are moving along their corresponding path at constant speeds of vh and vr, respectively. The person will then arrive at the points sin and sout at future moments tinh, touth, respectively. Similarly, the robot will arrive at the points sin and sout at future moments tinh and touth, respectively.
If |tinh-touth| < θth3 and the motion uncertainty of the person is taken into account, the probability of human-robot motion conflict obstruction at point sin is computed as:

Similarly, if tinh – touth < θ th4 and the motion uncertainty of the person is taken into account, the probability of human-robot motion conflict obstruction at point sout is computed as:
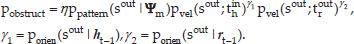
5. POMDP-based decision-making for polite avoidance
5.1 The Elements: States, Actions and Observations
To automatically compile the POMDP model
In this case, the states of the POMDP model are defined based on the abstraction of a set of variables.
Human motion state, which takes values of move(PM) and stay(PS);
Human motion tendency, which takes values of move(GM) and stay(GS);
Human-robot distance, which is obtained by discretization of metric distance between human and robot, taking values of safe(DS), minor danger(DB), major danger(DJ) and high danger(DE);
Robot motion state, which takes values of normal path following(RN), accelerating along path(RF), decelerating along path(RS), and dynamic replanning(RR).
A number of 64 states s1,…, s64 can be composited; in analysis, 32 of these seldom appear, and the remaining 32 situations are selected as system states for the POMDP model.
Observations (O) in our model are the abstractions of the movements and positional relation between human and robot. In each state, the robot makes three kinds of observation:
People's Action Observation (PAO), which can be abstracted as {Move,Stay}.
People-robot Relation Observation (PRO), which can be classified as eight possible values {PRO1,…, PRO8) according to the abstraction of relative position between human and robot.
Robot State Observation (RSO), which can be abstracted as {Path-following Accelerating, Decelerating, Replanning}.
Actions (
Normal path following an;
Accelerating along path au;
Decelerating along path as;
Dynamic replanning for detour ar.
The first three actions indicate that the robot follows the planned path with only velocity changes. These actions are usually more efficient for avoiding conflict with or obstruction of humans. The fourth action indicates that the robot replans a new path according to the updated environmental map by incorporating the probability distribution function (PDF) of p(
The reward (ℛ) defines the reward function that determines the immediate utility of executing action a at state s. In our system, the reward matrix is manually specified based on a criterion that behaviours ensuring more safety and politeness receive higher rewards. Nevertheless, the optimum choice of settable parameters can be adjusted through a user-supervised learning system when a robot is installed in a new environment and performs a daily room exploration task, as suggested by Lopez [22].
5.2 POMDP Compilation
The transition model T(s',a,s) specifies the conditional probability distribution of transiting from state s to s' by executing action a. O(s',a,o) is the observation model that computes the probability of obtaining observation o in state s' when executing action a. Usually, the transition model and observation model can be rewritten as T(s',a,s) = p(s' | s,a), O(s',a,o) = P(o | s',a) where
To automatically learn the observation model and the observation model, initial values are given (examples are shown in Figure 8) and the EM algorithm is employed for learning from collected data until the output parameter converges. The Randomized Point-based Value Iteration algorithm[18] is utilized to solve the above-defined POMDP model. In our system, 32 iterations and 63.578 seconds are required for offline model compiling. Figure 9 shows the errors during the iteration. The error between two successive iterations is plotted in the y-axis, with higher value indicating faster convergence rate.

Rules for constructing the POMDP model from empirical uncertainties

The converge of learning error change
6. Experimental Results
The proposed approach was validated in a real office environment of size 12 m × 7 m. An ActivMedia Peoplebot was used in the experiments. We assumed that participants in the experiment walked at a smooth speed and intended to follow certain motion patterns. The sensory system for robot localization and people-tracking consists of five stationary CCD cameras mounted on each side of the room above head level and the robot's onboard laser range finder. The environmental grid map was previously built by a SLAM algorithm with a resolution of 0.1 m. Based on the collection of tracking trajectories, typical indoor motion patterns of humans are learned, as presented in our previous work[23][24].
6.1 Predictive Navigation
During online predictive navigation, the robot collected laser scan data with a time period of 200 ms, and updated the local map gridlocal with a time period of 80 ms, according to the positions of detected human legs. In the PN-POMDP algorithm, θth1, θth2, θth3 and θth4 are the threshold values that can be set and adjusted in the experiment.
In the first three testing scenarios, the robot and the human were initially located in the same room area within a short distance of each other (less than 5 m). In the first case, where the robot was moving towards the human, the system predicted human motion 5 seconds ahead of time. Figure 10(a) shows that the robot began to avoid possible human-robot conflict using the detour policy when it was still about 3 m away from the human. In the second scenario (Figure 10(b)), when the robot had predicted that its path would intersect with the predicted human trajectory from one side, it selected the slow down action as. This policy was efficient because frequent replanning was avoided and the robot would continue to move along the path with normal speed when the human had passed the predicted intersection point. To test the reliability of the algorithm, in the third scenario (Figure 10(c)) the robot was following a person through a narrow corridor. In this case, the robot made the prediction that it would not interfere with the human's motion if it did not overtake him/her. Thus the robot followed its planned path with regular speed.

Predictive navigation in three experimental scenarios
The fourth testing scenario involved predictive navigation. The robot and the human were initially positioned in two different rooms and global cameras were utilized for people-tracking. In the experiment, the robot was initially positioned at place A as in Figure 11(a), and it planned to navigate through a narrow passage (passage II) to place B. In the meantime, a person intended to walk through the same passage in the opposite direction.

Comparison in predictive navigation scenario
Before the robot approached the passage entrance, the probability of human-robot motion confliction at the entrance of the passage (place C in Figure 11 (b)) was estimated. More specifically, the tendency likelihood of the person's temporary motion to be engaged in the motion pattern ending at place C was estimated at as high as 97.5%. However, since the predicted occupancy probability of the grid cells within the passage was volatile, the traditional replanning method caused the robot to switch paths between two candidate routes (plan1, detour via passage I and plan2, continue via passage II). This method guided the robot to unnecessarily move back and forth at the passage entrance and finally reach the goal, requiring as long as 633 time periods. In comparison, the PN-POMDP method supporting multiple comity policies generated a highly efficient and human-friendly behaviour. When the human-robot conflict probability within the passage II was predicted, the robot consequently drove to a free space outside the entrance of the passage and waited. After the person had passed through the passage, the robot proceeded to cross the doorway and continued on its route. The resulting behaviour of the robot improved the navigation efficiency (only 342 time periods for reaching the goal) by avoiding unnecessary repeated zigzagging and wandering before entering the passage. The pose and translational velocity of the robot during the navigation test is shown in Figure 12. As shown in Figure 12(a), the replanning method caused the robot to switch between the two candidate paths during the interval (2) to (5). In contrast, Figure 12(b) shows that the PN-POMDP method ensures smooth and efficient robot navigation. More importantly, the polite navigation behaviour is comprehensible to humans and shows full respect to the human.
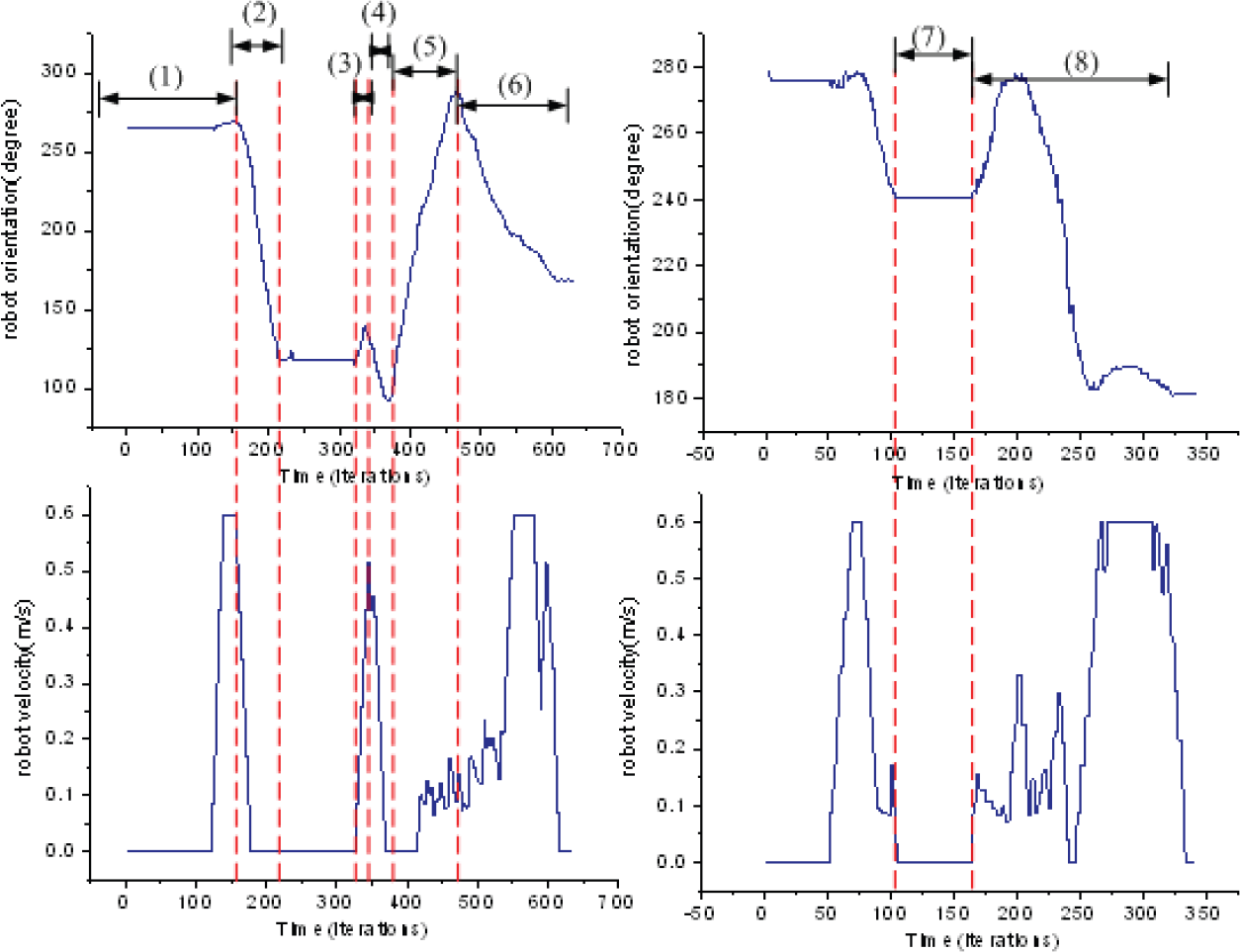
Robot pose and velocity change during the navigation scenario
6.2 Predictive navigation in highly populated areas
Figure 13 shows the experimental result in crowded environments with three participants walking around the robot. Since the PN-POMDP method supports multiple policies of predictive navigation, the robot frequently adjusted the policy according the predicted human-robot co-occurrence situations. In fact, after raising the reward function of the deceleration action as, the robot tended to slow down for the human to pass first. This indicates that the PN-POMDP method is feasible to be applied to service robots that work in crowded environments such as exhibition halls and museums.

Slow movement of robot in crowded environment
6.3 Trial study
A statistical trial study was also conducted to verify the success rate of the PN-POMDP method. We invited 12 participants (eight male and four female), ranged in age between 21 and 34. 33% of them were from non-technological fields, while 67% worked in technology-related areas. The trial tests involved different types of situation as described above. In the trial tests, the following situations were treated as “failure”: (i) The robot blocked the human's intended route of movement (subjective scoring); (ii) The robot failed to reach the goal because of getting trapped or localization failure; (iii) The robot reached the goal with time consumption as high as four times that needed in situations without humans moving around. Figure 14 shows that the PN-POMDP method achieved a higher success rate than the traditional real-time replanning method.

Comparison of success rate
7. Conclusion
In this paper, we have presented a predictive navigation method for service robots in the POMDP framework. By learning human motion patterns and combining long-term and short-term human motion prediction, space-time estimation of human-robot co-occurrence is achieved. In order to execute tasks in typical partially observable environments, POMDP-based probabilistic decision-making is incorporated to generate a theoretically optimal policy that allows the robot to behave in an efficient and polite manner. Thus the risk of conflict with human motion is minimized. The feasibility of the proposed methodology is validated by navigation experiments as well as user trials, in which the robot's navigational behaviour is interpreted by humans as safe, comprehensible and polite.
Although the system makes use of external cameras for human tracking, the proposed methodology framework does not rely on specific means for the acquisition of human motion. In situations where robots are not close to people, we suggest the utilization of global cameras to ensure seamless and reliable human-tracking, which improves the performance of predictive navigation.
Footnotes
8. Acknowledgements
This work was supported by the National Natural Science Foundation of China (grant no. 61105094, No. 61075090, No.61005092 and No. 60805032) and the open fund of Key Laboratory of Measurement and Control of Complex Systems of Engineering, Ministry of Education (no. MCCSE2012B02).