
Abstract
In this paper, weextensively investigate symmetrical two-dimensional principal component analysis (S2DPCA) and introduce two image measures for S2DPCA-based face recognition, volume measure (VM) and subspace distance measure (SM). Although symmetrical featuresare an obviously but not absolutely facial characteristic, they have been successfully applied to PCA and 2DPCA. The paper gives detailed evidence that even and odd subspaces in S2DPCA are mutually orthogonal, and particularly that S2DPCA can be constructed using a quarter of the conventional S2DPCA even/odd covariance matrix. Based on these theories, we investigate the time and memory complexities of S2PDCA further, and find that S2DPCA can in fact be computed using a quarter of the time and memory compared to conventional S2DPCA. Finally, VM and SM are introduced to S2DPCA for final classification. Our experiments compare S2DPCA with 2DPCA on YALE, AR and FERET face databases, and the results indicate that S2DPCA+VM generally outperforms other algorithms.
Keywords
1. Introduction
Face recognition is now becoming a very popular subject for research. It can be applied in many fields[1], including mobile robots, information security, and entertainment. Over the past two decades, many face recognition approaches have been proposed. Typical approaches include principal component analysis (PCA), linear discriminant analysis (LDA), independent component analysis (ICA), neural network (NN), support vector machine (SVM), and kernel PCA/LDA [1–3]. On the whole, these approaches are based on appearance image and have some statistical significance. Recently, 3D-based face recognition has also been a hot research area[4].
There are many approaches, including those cited above, to improve recognition performance from a statistical point of view whilst combating the “dimensionality curse” problem [5]. However, theseapproaches barely consider characters of image itself. Local binary patterns (LBP), elastic graph matching (EGM), and so on [6] consider the topologic or local characters of images, and have also been applied in face recognition.
Appearance-based statistical face recognition algorithms usually use vector-based face samplesobtained from two-dimensional (2D) face images by techniques such as concatenation [7]. Vector-based face samples usually have a large number of dimensions. However, the number of the samples is small, so the “dimensionality curse” problem is always bred. 2DPCA, which is founded on a 2D face data format rather than 1D vector-based face images, shows high performance in dealing with the “dimensionality curse” problem. Why does the 2DPCA work? The row or column of the 2D face image has a low dimensionality, so the covariance matrix in 2DPCA is more precise than thatin PCA. This is the key to solving the impact of the “dimensionality curse” problem in 2DPCA-based face recognition[4,8]. (The covariance matrix in face recognition based on PCA is not so precise, because the sample is of high dimensionality while the number of samples is small.) Other algorithms based on 2D face data and which use 2DPCA are also proposed, e.g., two-dimensional LDA (2DLDA) [9], two-dimensional Laplacianfaces [10], and diagonal PCA [11]. In [12], Gao et al. proved that 2DPCA is not equivalent to a special case of block-based PCA, where each block is a column (or row) of the image. Moreover, from the view of tensor analysis, 2DPCA or 2DLDA can be considered as the variant of the second rank tensor decomposition [13,14]. The typical classification measure used in 2DPCA is the sum of the Euclidean distance between two feature vectors in a feature matrix [7] and is called distance measure (DM) or Yang distance. Zuo et al. furthermore proposed a generalized Yang distance [15]. Volume measure (VM) [16] based on the volume of matrix has also been proposed for 2DPCA in face recognition. Recently, another rule, subspace distance measure (SM) [17,18], has also been proposed to measure the similarity between two images.
In fact, 2DPCA(2DLDA)-based approaches do not acknowledge the characters of the face image itself, and solve the impact of the “dimensionality curse” problem based on pure statistics. Symmetrical principal component analysis (SPCA) [19], an approach obtained by the even-odd decomposition principle, expands samples from the facial symmetry [19,20]. In essence, this approach improves recognition performance by exploiting priorknowledge, i.e., the symmetrical characters of the face image. Good performance has also been obtained by SKPCA [21]. However, these approaches are all based on 1D vectorized face images. Recently, a new facial symmetry approach called symmetry two-dimensional PCA (S2DPCA), has been proposed [22]. S2DPCA utilizes even and odd decompositions based on the 2D original and mirror face samples. On the one hand, S2DPCA can exploit more priorknowledge than SPCA, producing more new samples. It can also obtain a more precise covariance matrix, just like 2DPCA, using more samples than PCA or SPCA.
Although S2DPCA has been proposed in [22], the theories of S2DPCA, e.g., even/odd subspace orthogonality and computational cost, remain open, and the classifier was unique. Motivated by the conclusions on SPCA [5,19], we give more proofs of the corresponding theories on S2DPCA here. We offer further proof and clarify the pointthat even and odd subspaces in S2DPCA are mutually orthogonal [23] and in particular give a theoretical foundation to the observation that the even or odd subspace can be founded on a quarter of the conventional S2DPCA's even/odd covariance matrix. The time and memory space complexities of 2DPCA, conventional S2DPCA, and our S2DPCA are also compared. S2DPCA based on our theories requires the least time and memory space among these algorithms, with a quarter of the time and memory costs compared to conventional S2DPCA.
VM, mentioned above, is directly based on matrix data, i.e., a 2D image format [16]; it can therefore be regarded as a kind of image measure like SM. From the point of view of data format, image measures fit better for 2DPCA or S2DPCA-based face recognition, as compared to DM. We therefore investigate 2DPCA and S2DPCA with DM, VM and SM separately through experiments using a variety of face databases, and find that S2DPCA with VM generally gives better performance than others.
The remainder of this paper is organized in the following way. Ideas on S2DPCA and classification measures are developed in Section 2. Section 3 shows our experimental results. The last section concludes this paper and discusses future work.
2. Symmetrical two-dimensional PCA
Compared with PCA, 2DPCA gives better performance by computing the covariance matrix more accurately. SPCA exploits the original face training samples and the mirror samples, as well as even and odd decompositions, thus making use of more discriminative information [21]; S2DPCA, on the other hand, can use a pure statistical mathematical technique, as well as the characters of face image, to improve the recognition performance.
2.1 Principles
S2DPCA combines the idea of SPCA with that of 2DPCA. Suppose the set {

Here,



In equations (2) and (3),
2.2 Theorems on S2DPCA
In fact, if we set each even and odd training sample as
Theorem 1: Set
Proof: Since the mean sample matrices of even, odd and all samples are all 0 mean matrices, from the definition of

Theorem 2: Let
Proofs: 1. Set
Since
Therefore,
2. From conclusion 1, we have


That is to say, [

Theorem 3: The covariance matrices
Proof: When the w is even, and

For
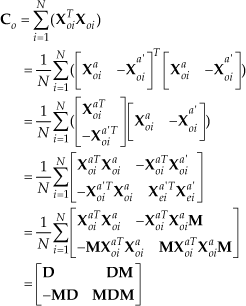
From the proofs of Theorem 2, we know

Note that when

Therefore,
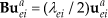
So, we can obtain
In a similar way,

Therefore:
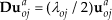
We can thus obtain
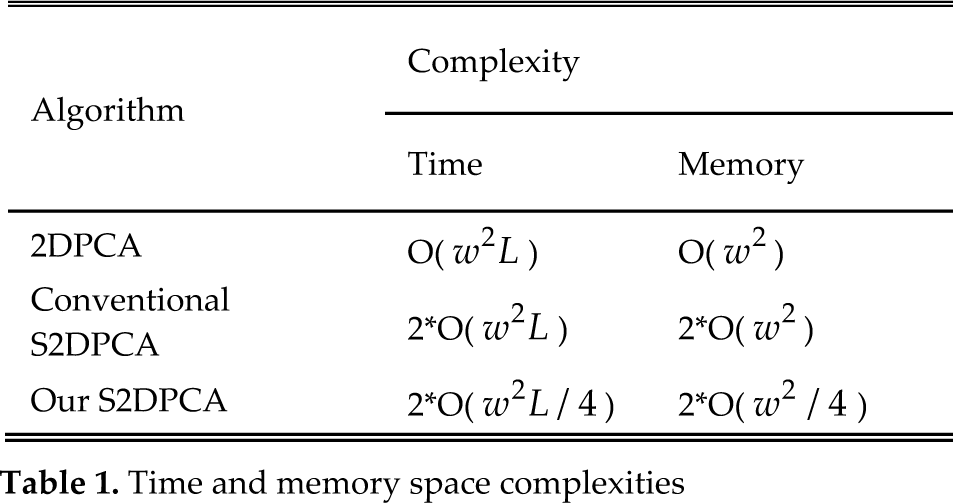
2.3 Time and Memory Space Complexities
The time and memory space complexities of 2DPCA, conventional S2DPCA and our S2DPCA are shown in Table 1. Here, w is the number of columns of face image, and L is the number of the projection vectors. Note that we only give the training time and memory space complexities; the testing time(memory space) complexities of these algorithms are the same if we suppose the projection vectors selected. In Table 1, it is very clear that the time and memory space complexities of 2DPCA[11], conventional S2DPCA and our S2DPCA, from the point of view of the computational complexity theory, are the same. The time and memory costs of our S2DPCA, however, can both be reduced to a quarter of that of conventional S2DPCA. Note that the time and memory costs of conventional S2DPCA are double those of 2DPCA, while the costs of our S2DPCA are less than 2DPCA. In fact, the computational cost and memory space cost of our S2DPCA are least among these algorithms. To make this more straightforward, the computing (CPU) time and memory costs of conventional S2DPCA and our S2DPCA on YALE will be given in Section 4.1.
Time and memory space complexities
2.4 Classification
A feature matrix
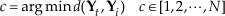
The distance between 
For the sake of brevity, these procedures are called S2DPCA+DM and 2DPCA+DM. Two other similarity measures are:

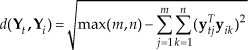
In equation (15), we give the VM [16]. SM is defined in equation (16), m is the rank of
Similarly, for simplicity, we call these algorithms S2DPCA+VM, 2DPCA+VM, S2DPCA+SM, and 2DPCA+SM. In contrast to traditional DM, VM and SM are regarded as image measures. The steps of S2DPCA-based algorithms in our paper are depicted as follows.
Decompose each training face sample into an even symmetrical sample and an odd symmetrical one to get the even/odd symmetrical training sets.
Apply 2DPCA to the even/odd symmetrical training sets separately to get even/odd subspaces. Combine features in even and odd subspaces based on eigenvalues.
Extract low dimension features by projecting the face sample to the even/odd subspace for final classification.
Apply nearest neighbour classifier with DM, VM and SM.
3. Experimental results
Many studies (see [7], [13], [16]), have shown that the performance of 2DPCA is better than that of PCA, so we only compare S2DPCA with 2DPCA using different similarity measures on three well-known face databases, i.e., YALE [26], AR [27], and FERET face databases [28] [29]. On YALE and AR face databases, we investigate the algorithms performance when facial expressions, illumination, etc., are varied. The algorithms performance by cumulative match score (CMS) [28] is also investigated on FERET face database. The experiments are performed using Matlab 7.0 on a Pentium IV 3.0GHz processor and a total RAM memory of 1GB.
3.1 Results on YALE Database
The YALE database includes 11 different images of each of 15 individuals, in which the face images vary in different expressions and light conditions [2] [16]. All grey-scaled images were cropped and normalized to a resolution of 66×56 pixels in the experiments.
Our experiments are performed using two and three random face samples per person for training, and the remaining images for testing. Here, training samples are randomly selected in one person's samples, but the ordinal of samples for different people is the same. The average recognition rates (ARR), which are calculated over ten runs, are shown in Fig. 1 and Fig. 2.
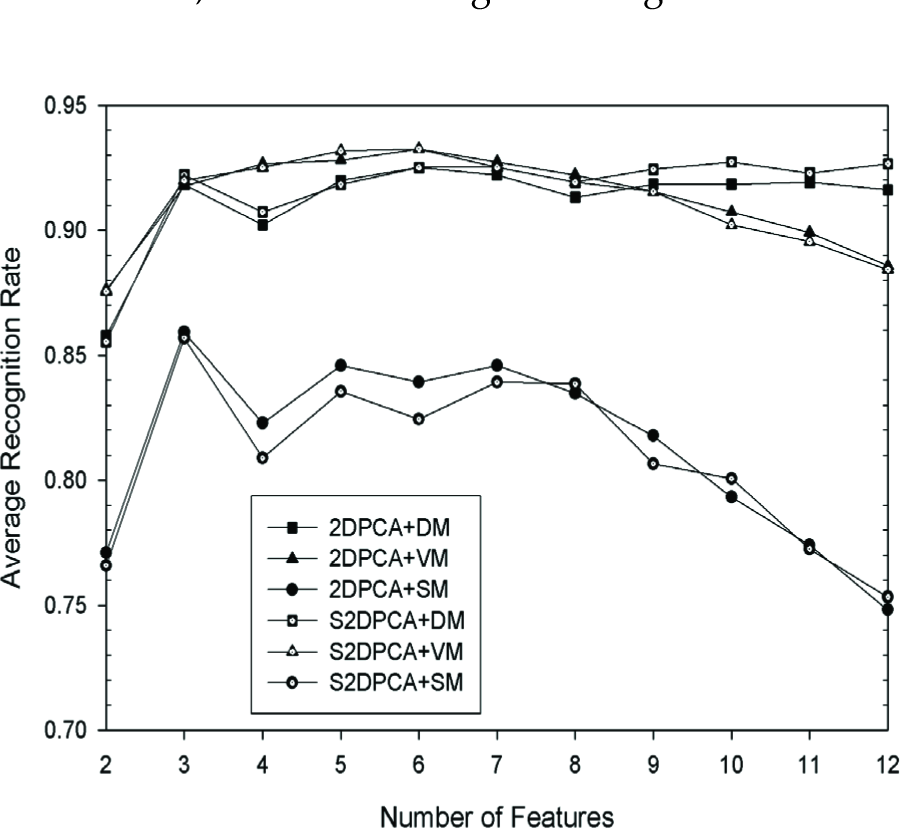
ARR on YALE database with 2 samples per person.
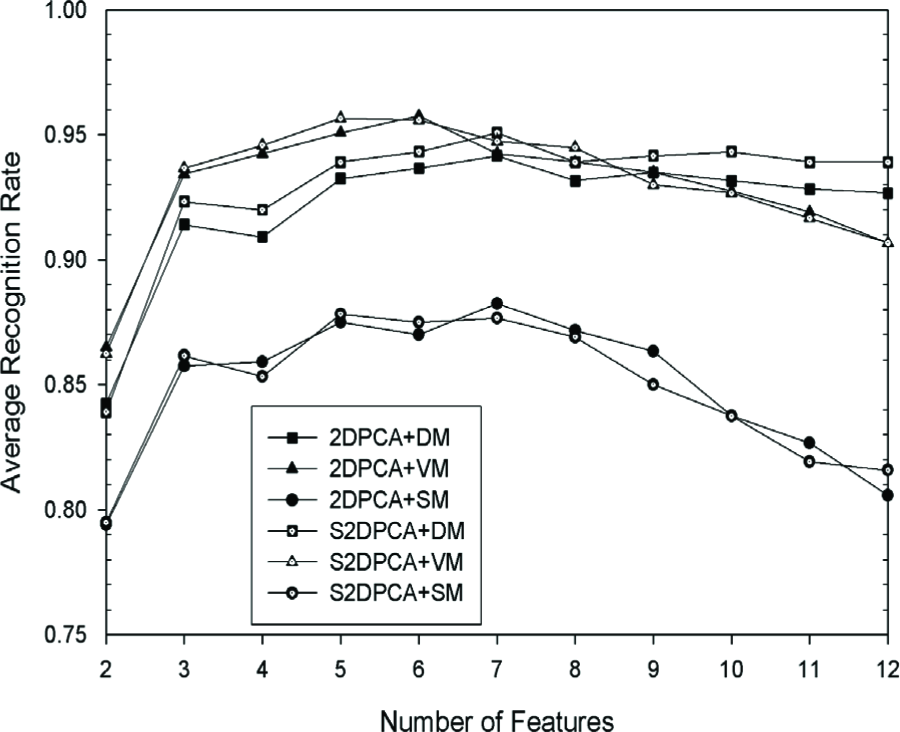
ARR on YALE database with 3 samples per person
The corresponding standard deviations (σ) are described in Fig. 3 and Fig. 4. We illustrate the performance with the first two and three face samples per person for training (others for testing) in Fig. 5 and Fig. 6. Comparing Fig. 1 and Fig. 2 with Fig. 5 and Fig. 6, the ARRs are smooth, while the recognition rates show marked fluctuations. It can be seen that S2DPCA+VM generally outperforms others. Particularly with four to six features selected, the best ARRs can be obtained by S2DCPA+VM. The standard deviation of these algorithms is about 2% when the number of features is bigger than two. S2DPCA-based algorithms have the potential to outperform 2DPCA-based ones. S2DPCA and 2DPCA with SM could not obtain a good performance.

Standard deviation on YALE database with 2 samples per person.
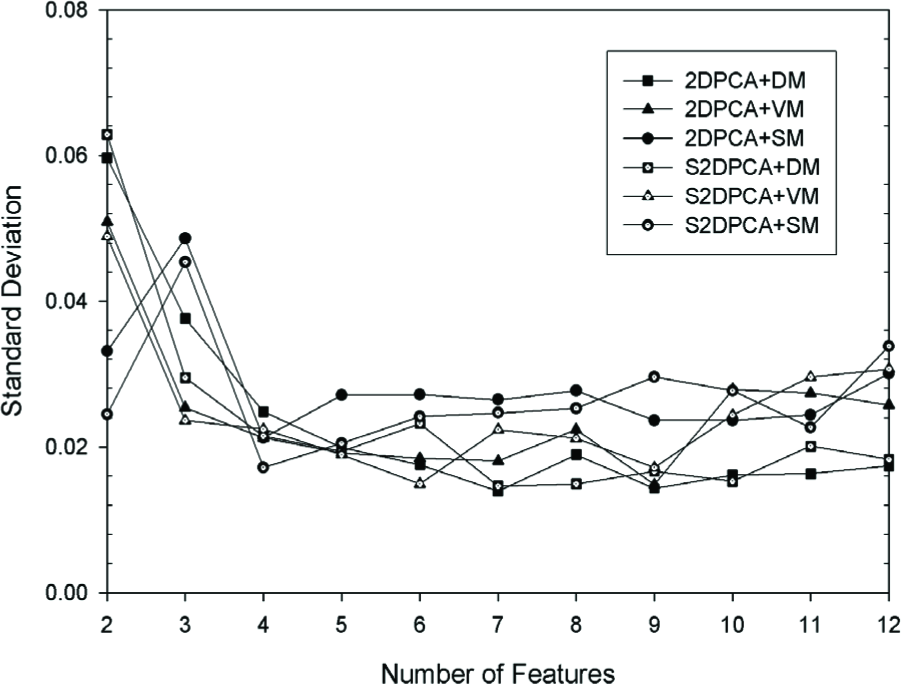
Standard deviation on YALE database with 3 samples per person.
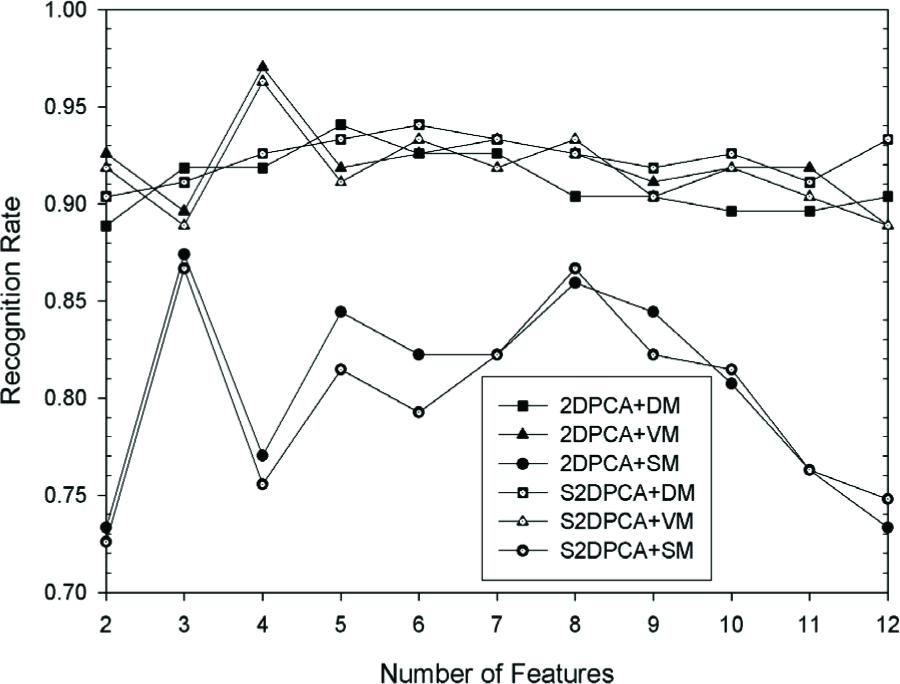
Recognition rate on YALE database with the first 2 samples per person

Recognition rate on YALE database with the first 3 samples per person
We compare the computing (CPU) time and the size of the covariance matrices for our S2DPCA and conventional S2DPCA in Table 2. The classifier based on the nearest neighbour with DM is applied (the first two face samples per person for training, others for testing). The number of features selected is nine.
CPU time and memory space cost

In Table 2, our S2DPCA takes only about 203.0ms for training, while conventional S2DPCA takes about 531.0ms. The size of matrix is reduced from 56*56 to 28*28. Here, the time cost of our S2DPCA can be reduced to about 203/531 compared to the conventional S2DPCA. Like the theory analysis mentioned above, it is not distinct (1/4), for the CPU time involves other requested operations, such as reading images, constructing sample matrices, etc. Testing data by Conventional S2DPCA and our S2DPCA takes about the same time for 135 samples, which means less than 6.0 ms per sample.
3.2 Results on AR Database
The AR database consists of over 4,000 colour face images, and the images vary in different lighting conditions, facial expressions and occlusions, etc. [27]. The images of most persons were taken in two sessions, separated by two weeks, each section consisting of 13 colour face images for one person. The face portion of the images is cropped, grey-scaled and normalized to a resolution of 66×56 pixels. The face images of 119 persons are used in the experiments. The histogram equalization is used in preprocessing. The images of one person used in our experiments are shown in Fig. 7.

Sample images for one person on AR database
We select the first five images per person in every two sessions as the training and testing samples. The experiments are performed using five random face samples per person for training, and the remaining images for testing. The average recognition rates and standard deviation, calculated over ten runs, are shown in Fig. 8 and Fig. 9. S2DPCA-based algorithms have the potential to outperform 2DPCA-based ones. The standard deviations of these algorithms are about 1.6%. S2DPCA+VM generally outperform others. S2DPCA and 2DPCA with SM still could not obtain good performance.

ARR on AR database with 5 samples per person
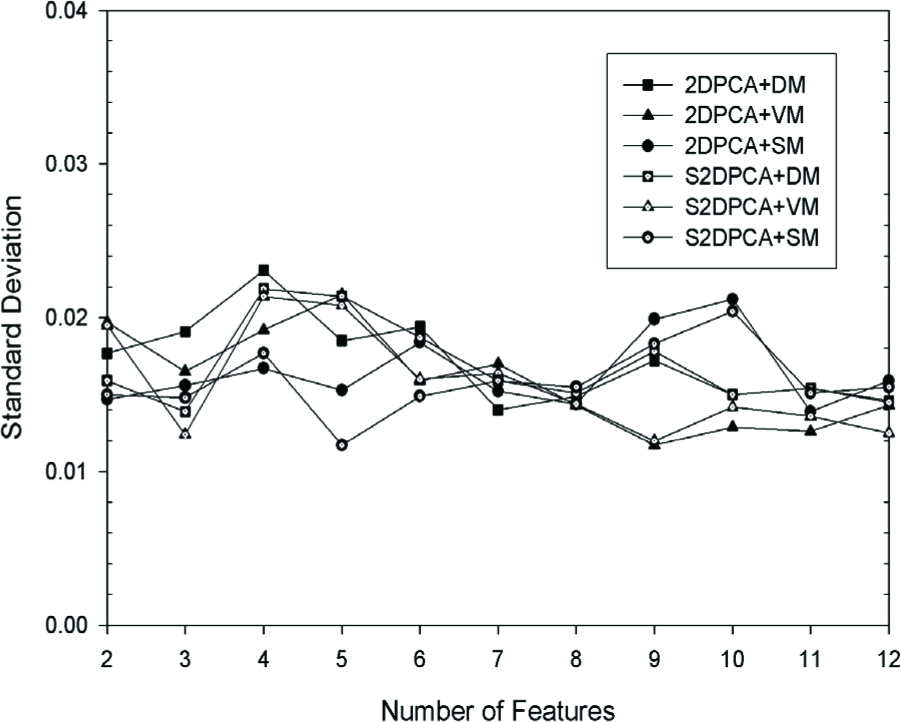
Standard deviation on AR database with five samples per person person.
3.3 Results on FERET Database
For the purpose of some applications, e.g., verification from biometric signatures stored on smart cards [28], we validate S2DPCA on the FERET face database [29], which has been widely used to evaluate face recognition approaches. Details on this database and the terms used in the experiments can be found in [28]. Two FERET image sets are used in the experiments. FA is a regular frontal face library used as the gallery set, including frontal images of 1196 individuals. FB, including frontal images of 1195 individualsused as the probe set, is an alternative frontal face library, with images taken seconds after the corresponding images inFA [16]. 998 face images are selected as the training set, which includes samples from FA and FB.
Before performing the experiments, all images in the FA and FB sets are rectified using the positions of the eyes, provided by FERET, and are cropped and standardized to the 60×50 face images. To further reduce the effect of illumination, the histograms of these images are equalized for preprocessing. The recognition rate with varying number of features is given in Table 3. CMS is the performance statistics, which are shown in Fig. 10. The number of features is that where algorithms can obtain the best recognition rates, that is, the number for 2DPCA+DM is 10, the number for both 2DPCA+VM and S2DPCA+VM is 8, and for S2DPCA+DM it is 12. The performances of 2DPCA+SM and S2DPCA+SM were so poor they have not been presented in Fig. 10. As can be seen from Table 3 and Fig. 10, of these algorithms S2DPCA+VM can obtain the best recognition rates with eight features. The CMS of S2DPCA+VM generally outperform those of the other algorithms, though this difference is not marked.
Recognition rates (%) with varying number of features


CMS on FERET database
4. Conclusions
In this paper, we have investigated the orthogonality of the even and odd subspaces in S2DPCA in detail, and, in particular, have proved that S2DPCA can be constructedon a quarter of conventional S2DPCA' seven/odd covariance matrix. Moreover, based on these theories, we find that S2DPCA can be computed using a quarter of the time and memory costs compared to conventional S2DPCA from the point of the view of the computational complexity theory. Furthermore, two image measures, volume measure (VM) and subspace distance measure (SM), are introduced to S2DPCA-based face recognition.
S2DPCA can explore more prior-knowledge, i.e., facial symmetry, based on even and odd decompositions, as well as obtain a more precise covariance matrix in the same way as 2DPCA. Therefore, S2DPCA-based algorithms are able to achieve better performance in general. Nevertheless, theoretically, the time and memory space costs of conventional S2DPCA are doubled compared to those of 2DPCA, which is an annoying issue. We solve this problem successfully with the S2DPCA theories proved in this paper. The experimental results on YALE, AR, and FERET databases show that, generally, S2DPCA+VM outperform some other relevant algorithms. Most importantly, the computational cost and memory space needed for our S2DPCA are less compared to 2DPCA and conventional S2DPCA.
Finally, we should point out that there are still two aspects in S2DPCA worthy of further investigation. How many even and odd features should be selected in order to achieve better performance?From the experimental results, the number of features with which good performance can be obtained strongly depends on face database selection. In addition, VM is not satisfied by the triangle inequality, which means VM is not ametric. With constraints, could VM be a metric? S2DPCA+VM would be applied widely when both aspects have been worked out successfully.
Footnotes
5. Acknowledgements
This work is supported in part by the National Natural Science Foundation for Distinguished Young Scholars of China under Grant No.60905011.