
Abstract
We propose a robust face recognition method under illumination variation. By using shadow compensation methods, we restore the image of a facial image taken under arbitrary illumination into an image that is similar to the image taken with frontal illumination. Then we apply a pixel selection method to these restored images in order to reduce the noise components, which can interfere with the extraction of discriminant features for face recognition. The experimental results for the CMU-PIE, Yale B and Multi-PIE databases show that the proposed method results in the improvement of recognition performance under illumination variation.
Keywords
1. Introduction
Face recognition is used to identify individuals from facial images by using face databases containing people's identities. Compared to other types of biometric recognition, such as fingerprint, retinal or iris recognition, face recognition is less invasive and does not require a subject to be in proximity to or in contact with a sensor, which makes it widely applicable in user identification, e-commerce, access control, surveillance and human-computer interaction.
Numerous methods have been developed for face recognition over the last few decades. Most of them are capable of achieving high recognition rates in well-controlled environments. However, the accuracy of face recognition can deteriorate significantly when the images used for enrolment (gallery) and recognition (probe) are taken under different environmental conditions.
Illumination variation is one of the challenging problems to be solved for robust face recognition systems. The changes induced by illumination, such as cast shadows or attached shadows, can be larger than the innate differences between individuals. The methods used to solve the problems caused by illumination variation can be roughly classified into three categories [1], [2], [3]: face modelling, invariant feature extraction and pre-processing and normalization. Face model-based methods construct a generative 3D face model that can be used to render facial images under various illumination conditions. Most of these methods require several images of the subject using light from different directions or 3D shape information for training [4], [5]. The methods belonging to the second category extract features, such as edge maps [6], gradientfaces [7], Gabor features [8] or local binary patterns (LBP) [9], which are invariant to illumination variation. In pre-processing and normalization, various image processing techniques are used to compensate for the illumination variation [10], [12], [11], [13]. These methods [10], [12], [13] modify a facial image taken under arbitrary illumination conditions into an image that is similar to one taken under frontal illumination. The method in [13] restored a frontal illumination image from an image captured under arbitrary lighting conditions by using the ratio-image between a test image and a reference image, and iterated the process to obtain a visually better restored image. The quotient image (QI) [14], which is defined as the ratio between a test image and a linear combination of three noncoplanar illumination images, depends only on the albedo information and is free of illumination. The method in [11] used the ratio between a test image and its smoothed image to obtain a self-quotient image (SQI).
From human perception, facial images with frontal illumination have a good visual effect and are natural for the investigation of discriminant information for face recognition. In addition, the compensated images can be applied to well-known appearance-based face recognition methods such as Fisherface [15], DCV [16] or ERE [17]. In this paper, we focus on the methods belonging to the third category for handling illumination variation in face recognition.
We first present two state of the art methods [12], [19] for shadow compensation, which are simple and give good recognition performance compared to other methods. The method in [12] decomposes a facial image into magnitude components and phase components in the frequency domain using the Fourier transform. The facial image that was deteriorated by shadow was restored using the auxiliary magnitude, which compensates for the magnitude components distorted due to the illumination variation. In [19], the illumination variation was compensated for by adding an adequate average difference image depending on the light direction, under the assumption that the shadow on a facial image created by a similar light direction has common characteristics. However, the resultant compensated images of both the above methods still have many noisy pixels, which are likely to interfere in extracting discriminant features for face recognition. Thus, we can expect to obtain better discriminant features by eliminating noisy pixels in the compensated images, which will lead to improved face recognition performance. Even though various pixel selection methods can be used to remove noisy pixels [20], [21], [18], we modify the pixel selection method in [20] based on discriminant analysis and apply it to remove those noisy pixels. Experimental results show that the proposed method improves recognition performance in the presence of illumination variations.
The rest of this paper is organized as follows. Section 2 and 3 present how to compensate for the shadow in a facial image and how to remove noisy pixels in the compensated images, respectively. Section IV consists of the experimental results, followed by the conclusion in Section V.
2. Shadow Compensation Methods
2.1 Shadow Compensation Based on Fourier Analysis (SCFA)
In [12], a shadow compensation method was performed using Fourier analysis to deal with illumination variation. The image signal in the spatial domain can be represented in the frequency domain using the Fourier transform [21]. Let us denote an image of M × N pixels as I(x, y) ∈
The shadows in a facial image due to illumination variations change the magnitude components of the image in the frequency domain. In contrast, the phase components are less prone to the effects of illumination variations [12]. In order to restore a facial image that had been deteriorated by shadows, the method in [12] compensated for the distorted magnitude components using the auxiliary magnitude |FIAux(u,v)|, which represents the characteristic of the magnitude for general human faces. If letting an arbitrary facial image with shadows and its Fourier representation be IA and |FIA(u,v)|ej∅IA(u,v), respectively, the restored image I
Re
can be obtained from the compensated magnitude |FC(u, v)| and its own phase ∅IA(u,v) as follows:

where |Fc(u,v)| = 1/2(|FIA(u,v)|+|FIAux(u,v)|), ∅C(u,v) = ∅IA(u,v),x = M – 1 and y = 0,1,..n – 1.
Figures 1(a) and 1(b) show the raw images and their restored images using (1), respectively.

2.2 Shadow Compensation Using Weighted Average Difference (SCWAD)
Generally, human faces are similar in shape in that they are comprised of two eyes and two eyebrows, a nose and a mouth [10]. Each of these components makes a shadow on the face, thereby showing distinctive characteristics depending on the direction of light. If a facial image taken under frontal illumination is set as a reference image for a given facial image that is taken under an arbitrary illumination, the information about the shadow characteristics of the given facial image is contained in the difference image between the facial image and the reference image. Thus, if the light direction of a given facial image can be estimated, we can compensate for the shadow in the facial image using the average difference images DAl, which is an average of the individual difference images for the same light direction.
First, L light direction categories {CI|l = 1,..,L} are defined from the left side to the right side. For a given facial image IA, the binary image B(IA) of IA is produced in order to estimate the light direction. Then, the distances between B(IA) and the binary images in each category Cl are calculated using a classification rule [19]. From the three nearest distances (distNN, i = 1,2,3) and their corresponding categories Cl, i = 1,2,3, the weight ωIi, is defined as

The value ωIi, indicates how well the shadow of the given facial image can be characterized by DAli. Finally, the shadow compensated image, IC of IA, is obtained with the average differences as follows.

Figure 1(c) shows the images compensated using (2).
3. Pixel Selection Based on Discriminant Analysis
It is shown in the compensated images of Figs. 1(b) and 1(c) that noise components, which were generated in the process of compensating magnitude components or adding average difference images, are distributed over a whole facial image. This is because the average operations in the compensation procedures dilute the unique features of an individual in a facial image. In addition, the remaining cast shadows after shadow compensation can affect the extraction of discriminant features for face recognition. Therefore, in order to improve the performance of face recognition using these compensated images, we modify the pixel selection method based on discriminant analysis [20] and apply it to distinguish informative pixels from all pixels in the image. By eliminating the noisy pixels that have less discriminative information, we can expect to extract better discriminant features for face recognition, which will result in improved recognition performance.
The projection matrix W to be used for pixel selection is obtained using DCV [16]. The k-th image sample Ik can be represented as a vector
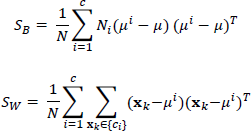
where μ is the total mean of the whole training set, μi is the mean of the class ci, and

The projection matrix W consists of projection vectors
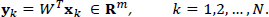
Each feature yki(k) in (3) is computed by projecting

Finally, ns pixels corresponding to larger Ml s are selected to use in extracting the final features for face recognition.
The pixel selection method can be summarized as follows:
Obtain the projection vectors Produce the measure vector Select ns pixels based on Mls, (l = 1,..,m). Extract the final features with only the selected pixels for face recognition.
4. Experimental Results
In order to show the effectiveness of the proposed method, we have applied it to the CMU-PIE [24], Yale B [4] and Multi-PIE databases [26]. All the facial images were cropped in proportion to the distance between the eyes, which were manually detected, and were downscaled to a size of 120(pixels) x 100(pixels). The measure vector
The CMU-PIE database contains images of 68 subjects with 21 illumination variations. Among them, we selected the images of only 65 subjects, because the images of the other subjects had some defects or did not include all types of illumination variations. Three images for each subject, which were taken with left side, right side and frontal illumination, were used for training, while the other 18 images not used for training were tested. Among the test images, one image under frontal illumination was used as a gallery image and the other 17 images were used as probe images.
Figure 2(a) shows the recognition rates for different number of features. Performing only histogram equalization (HIST) gave 27.9% better recognition rate than that of the raw images (RAW). The recognition rates for the shadow compensated images (SCFA [12] and SCWAD [19]) increased by 4.0% and 0.3%, respectively. As shown in Fig. 3(a), the SCFA-PS images gave the best recognition rates of 97.0%. Table 1 shows the comparisons of the proposed methods (SCFA-PS and SCWAD-PS) and various methods that deal with illumination variation for face recognition. The SCFA-PS and SCWAD-PS images are obtained by selecting 7000 and 8000 pixels, which were only 58.3% and 66.7% of the total pixels, from the SCFA and SCWAD images, respectively, using the pixel selection method. As can be seen in Table I, the proposed methods were better than other methods, showing that SCFA-PS and SCWAD-PS gave recognition rates of 97.0% and 93.6%, which were 1.0% and 1.3% better than SCFA and SCWAD respectively.
Recognition rates for different methods on the cmu-pie database (%).

: No. Feature of Eigenfaces w/o 1st 2

Recognition rates on the CMU-PIE and Yale B databases.
The Yale B database contains images of 10 individuals in nine poses and with 64 illuminations per pose. We used 45 facial images for each subject in the frontal pose (YaleB/Pose00) which were further subdivided into four subsets (Subset i, i=1,2,3,4) depending on the direction of light as in [4]. The index of the subset increases as the light source moves away from the front in taking the pictures. The images in Subset 1 were selected as a training set and the other images in Subsets 2, 3 and 4 were used as the test set.
Figure 2(b) shows the recognition rates for a different number of features which are based on the RAW, HIST, SCFA and SCWAD images. Similar to the cases of the CMU-PIE database, the histogram equalization alone gave 4.9% improvement in recognition rates compared to the RAW image, and the SCFA and SCWAD images additionally gave 3.8% and 9.3% increases, respectively. The SCFA-PS images gave the best recognition rates of 97.1 %.
In Table 2, the recognition performances of the proposed methods are compared with those of various methods. The SCFA-PS and SCWAD-PS images are obtained by selecting 2000 and 9000 pixels, which were only 16.7% and 75.3% of the total pixels, from the SCFA and SCWAD images, respectively. As can be seen in Table 2, the proposed methods gave higher recognition rates compared to the other methods, showing that SCFA-PS and SCWAD-PS gave the recognition rates of 95.3% and 97.1%, which were 5.5% and 1.8% better than SCFA and SCWAD, respectively. In particular, the performance of SCWAD-PS images is most notable for Subset 4, where images are severely affected by shadows.
Recognition rates for the yale b database (%).

The Multi-PIE database is recorded during four sessions over the course of six months. It contains a total 755,370 images from 337 different subjects. Individual session attendance varied between a minimum of 203 and a maximum 249 subjects. We used the 4,233 images of 249 subjects with 17 illumination variations from the first session. The recognition rates for the Multi-PIE database are shown in Table 3. The both SCFA-PS and SCWAD-PS images are obtained by selecting 7000 pixels, which were only 58.3% of the total pixels, from the SCFA and SCWAD images, respectively. As in the previous two databases, the proposed method also gave better recognition rates for the Multi-PIE database, which is the larger database, than the other methods. The recognition rates of SCFA-PS and SCWAD-PS were improved by 3.3% and 1.1% compared to SCFA and SCWAD, respectively.
Recognition rates for the multi-pie database (%).

: No. Feature of Eigenfaces w/o 1st 2
5. Conclusions
Shadows caused by illumination variation can change the appearance of a face and degrade the face recognition performance. In order to alleviate the influence of shadow on face recognition, we compensated for the illumination variation by restoring the facial image deteriorated by shadow to the image similar to an image under frontal illumination using state of the art methods [12], [19]. In addition, we improved the face recognition performance by applying a pixel selection method based on discriminant analysis, which removed noisy pixels that were generated in the shadow compensation process. The experimental results for the CMU-PIE, Yale B and Multi-PIE databases showed that the proposed method improved the face recognition performance in the presence of illumination variation.