
Abstract
Sparse sensors that recognize full-body human motion and that control the motion of virtual humans have emerged as valuable research tools in the field of human–computer interactions. Here we propose a method for motion recognition and prolonged, continuous generation of motion data based on the recognition results. The only inputs required are the directional accelerations collected by four Wii remotes, which are attached on the four limbs of a human. The extended and continuous signal sequences are separated into small segments that can be described by particular motion content. Use of a fused hidden Markov model (FHMM) during the recognition process ensures the accuracy and efficiency with which independent motion segments are recognized. A graph model enhances the capacity of classification when dealing with a signal sequence associated with a prolonged motion. During the reconstruction and generation processes, an efficient state-based motion graph generates the extended and continuous virtual human motion data, which accurately reflects variation in the movement of the actors. Our method has a strong capacity to classify types of motion upon their recognition and the control process can be applied to a range of applications involving interaction.
1. Introduction
Virtual human motion control is currently the subject of considerable research interest among those studying virtual reality and computer animation. An increased interest in ensuring the interaction of users with the virtual environment and in enhancing efficient, convenient and inexpensive interactions with virtual humans has emerged with the development of motion capture devices and the three important specialties of virtual reality.
As a representative interaction with virtual humans, motion control effectively acquires the control signal information of manipulators and combines this with the motion data of a virtual human. Motion control can be applied to many applications that call for an immersed user experience, such as industrial robot control, combat training or simulation, maintenance of virtual equipment and interactive computer games. For these types of applications, researchers have devoted the most attention to the use of sparse sensors such as accelerometers or magnetometers and low-dimension input signals to reconstruct complex virtual human motion. Use of sparse sensors can be more flexible than abundant sensors for applications when users control the motion of a virtual human.
The Wii remote (Wiimote) is the controller provided with Nintendo's Wii console that ensures user interaction with a virtual human and the environment via motion recognition. The universality and cheapness of the device render its use attractive for a wide range of applications. The Wiimote contains an acceleration sensor that can acquire acceleration data in three dimensions, although the accelerometer has limited capacity to distinguish between different types of motion involving simultaneous rotation and acceleration. Owing to this limitation of the accelerometer, it is difficult to use the Wiimote to generate motion based only on the input of accelerations, without calculation of each joint position in a virtual human.
Others have used three-dimensional (3D) acceleration sensors to synthesize realistic human motion [1]. However, the signals and motion data must be mapped temporally in a frame-by-frame manner, which requires that 3D acceleration data and motion data be collected simultaneously. Therefore, a simple method needs to be proposed to realize motion control without calculation of each joint position.
To address the challenges mentioned above, we propose a motion control method based on both the recognition and reconstruction of motion, which can deal with a continuous motion sequence. Our decision to use four Wiimote controllers as input devices attached to the four limbs of the user was based on both the convenience of their use and the integrity of the full-body information obtained. In our method, a motion signal segmentation method based on the combination of the Root Mean Squared (RMS) and Zero-Velocity Crossing (ZVC) states is presented primarily to separate the continuous motion into motion segments, which have a certain type of motion such as a cycle of walking or a split kick. Each motion segment is then recognized. To ensure accurate recognition, several recognition models are trained for each motion segment and the probabilities of similarities for each type of motion are calculated when new signals are generated. The hierarchical probabilistic model used in the recognition process is modified by a previously proposed FHMM [2] and is restrained by graph constraint by virtue of the naturalness of the motion transition blending. The ability of the method to generate an early recognition result ensures the efficiency of motion control. When the recognition for each motion segment is finished, a high-quality connective state-based motion graph method is rapidly proposed to generate a variant continuous motion, which is affected by user control.
The contribution of our paper can be summarized as follows:
The proposed flexible motion control method can deal with a long continuous motion exerted by the actors. The motion control process consists of a continuous signal segmentation process, a fast and accurate motion segment recognition process, and a variant motion reconstruction process.
Sparse, low-cost Wiimote controllers are applied to motion control. The only input signal of the motion control process is the magnitude of the acceleration of the four limbs without any calculation of position information. This provides a more convenient application platform than the current options, with a greater likelihood of finding broad utility.
2. Related Research
In many areas of research related to computer animation, various kinds of input devices are applied to motion control of virtual humans. Given that the signals collected by different devices are of different magnitudes and physical significance, such as force, acceleration or velocity, and that different control processes are characterized by different limitations, control results can vary widely.
Advantages of using basic computer input devices, such as the mouse or keyboard, for motion control include that they are cheap and intuitive and convenient to use. However, the mismatch of dimensions poses a common challenge to the use of these input devices. Researchers who used a mouse to realize motion control controlled a high degree-of-freedom model with a low degree of freedom input through the use of correlation maps that employed a 2D mouse input to modify a set of expressively relevant character parameters [3]. This study demonstrated that it is possible to drive high-dimension signals by low-dimension signals. Another study proposed the use of control bins to map the input signals of joysticks to a discrete space, formulate the control strategy for each discrete space and organize the motion fragments into long motions by a motion graph [4]. The discretization idea is important for dealing with continuous motion data. A different group of researchers proposed a system that can allow users to define a character and draw lines that control the movement of a character in a preferred direction [5]. The line drawn by the user is separated into small segments that correspond to different semantic actions. The research mentioned in these papers can be applied to 2D virtual human motion control. However, it is difficult to extend the findings to 3D control of virtual human motion.
To be a convenient input device for the actors themselves, camera and computer vision technology can also be widely used to track virtual human motion, especially for applications requiring motion recognition. Advances in camera-related technologies have improved the efficiency of motion-recognition methods based on computer vision and these vision-based methods are increasingly being applied to applications involving motion control. An animation-generating approach that employs video cameras and a small set of retro-reflective markers was described recently [6]. These researchers built a local model using the motion database to assist online identification and then generate the most similar motion. Another study proposed a method to build a deformable motion model that contains both geometric and temporal properties, and uses these to map the features of input image signals captured by cameras [7]. This method suggests the feasibility of mapping signal features to motion features. A controller-free, highly interactive exploration of an image database, which uses the motion-sensing Microsoft Xbox kinect sensor to interact at a distance through hand and arm gestures, was also proposed [8]. This enabled recognition of some simple hand gestures and controlled movement of images. A different system enables a virtual character to be controlled by an actor in real-time by allowing a motion-capture system to acquire the information generated by kinects [9].
Collectively, these studies [6-9] above show that use of a camera to realize motion control has the advantage of reflecting the naturalness of the user when they perform particular actions. However, given that the information related to the input signal is acquired by images or video, the influences of light and shading are relatively large. Another problem is the large number of capture devices needed for applications involving movement over large spaces. Accordingly, there is considerable interest in sensors that enable motion control while addressing the problems mentioned above.
Sensors attached directly to the significant joints of actors, such as limbs, can draw support from the real motion of the user to control a virtual human. One study involved the use of magnetic sensors to control a virtual human [10]. The approach involved swinging two sticks, each bearing a magnetic sensor, to simulate the motion of virtual human legs. Given that only discrete, single signals are generated, relatively few actions of virtual humans can be acquired in this way. A pressure sensor has also been used to recognize and reconstruct a virtual human [11]. These researchers mapped the pressure signals of actors' feet to each motion and reconstructed the motion when the recognition process was finished. This method is limited by the range of the motion involved and the need for considerable computational effort to ensure high efficiency. Another study used two Wiimote to realize motion control [12]. These authors define the different phases of each Wiimote as different motion types, however, the actors cannot perform the actions that they want the virtual human to follow. An integrated framework for tracking motion, which involved grasping two Wiimotes (one in each hand), supports 2D, 3D and motion gesture interactions, and was used to create two game applications [13]. Interactive control of a full-body human character that employs a small number of motion sensors was also reported [14]. These researchers constructed several online local dynamic models and used them to construct full-body human motion in a maximum posteriori framework. A related study introduced a novel framework for generating full-body animations controlled by four 3D accelerometers attached to the extremities of a human actor [15]. A lazy neighbourhood graph was used to ensure real-time control with input from sparse accelerometers.
Together, these studies [10-15] above show that the earliest sensor-based methods of motion control are incapable of mapping the full range of body motions. These approaches always define some special semantics for different signal sequences that correspond to a particular motion. More recently, full-body motion control has received more attention and the methods have focused on reconstructing the information obtained from movement at each joint by acquiring the position of the significant joints. Therefore, using only sparse acceleration input to control the motion of a virtual human is still meaningful.
Based on the related work presented above, we set out to use a FHMM to ensure that the full-body motion information can be expressed independently of different body parts. This can deal with situations that arise when one of two HMMs fails. At the same time, use of a motion graph structure as the constraint between two continuous motion segments can enhance the ability to recognize different types of motion. We propose a state-based motion graph that can rapidly reconstruct the continuous motion based on variant motion segments reconstructed by the recognition result. This ensures that the virtual human can act as the motion we recognized efficiently.
3. Method Overview
The method we propose maps the training signal sequence generated by sparse accelerometers by segmenting the continuous signal sequence and constructing a series of recognition models for each kind of motion segment. It then separates and recognizes the input motion signals and reconstructs the continuous motion data using a graph structure based on a motion segments database. The method comprises three main modules (Figure 1):

Structure of the motion control method.
4. Signal Segmentation
The goal of motion signal segmentation is to distinguish motion segments that contain a single motion type from a long continuous motion acceleration signal sequence detected by the Wiimote. Methods such as RMS in [16], ZVC in [17], Recursive Least Squares (RLS) in [18] and Piecewise Linear Representation (PLR) in [19] have been used for signal segmentation.
The basic idea of the segmentation method we propose is to detect the acceleration registered by each Wiimote at each sampling time. The feature we adopt is the RMS value of accelerations and the form of RMS value can be defined as:

where
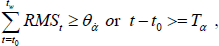
where t0 represents the start point and
Given that the amount of transition data differs between any two motion segments, the starting point and ending point of each motion segment needs to be defined by an additional constraint. The radius of signal curvature can be an important reference point, which indirectly represents the state of motion. Regarding the assessment of curvature, the ZVC state defines the beginning and ending points of each segment. The ZVC state can be defined as a positive and negative speed conversion point in one dimension. When a ZVC state approaches the assigned threshold TH, we define this ZVC state point as an alternative segmentation point.
The ideas used to define the segmentation process described above are summarized in Figure 2. The method judges whether the current state is a ZVC state at each sampling time and recodes the frames which keep a ZVC state until the accumulated RMS value exceeds the threshold.

The segmentation method dealing with acceleration signal sequence.
Owing to limitations in the efficiency with which acceleration signal sequences can be collected, signals are recoded with noise that introduces errors in the segmentation process. A weighted-average smoothing process reduces signal noise by comparison of neighbouring frames.
The method generates independent signal segments for each motion and the signals can recognize the motion of the user.
5. Motion Recognition
In order to recognize the motion segment generated by the segmentation process, models for each motion segment class need to be trained to compute the similarities between each motion and the input signal sequence. If the similarity to each motion exceeds a threshold, the sequence can be classified as the motion that it most resembles. As mentioned above, the graph constraint and hierarchical recognition model will be built during the process of motion recognition.
5.1 Graph Constraint
Given that the motion of the user is both long and continuous, a motion graph can be implemented to restrain the type of motion segments at the current time t. After segmentation of the signal sequence, different types of motion are classified. Similar signal segments, such as walking with different step lengths or jumping to different heights, are classified as belonging to a class of the same type of motion. Based on the classes produced above, a motion graph is established to restrict the sequence of signal segments. This can aid recognition of the current signal segment when the motion type of the last segment is known.
Figure 3 shows the constraint of motion graph generated for a signal sequence involving continuous motion. The motion graph describes the relationship between the input signal segments. As the last signal segment is recognized and classified as a motion type, such as Node 1, the possibility that the current signal segment belongs to Node 3 or Node 5 will be ruled out, and the transition probability from Node 1 to other nodes is taken into account when determining the entire similarity probability.
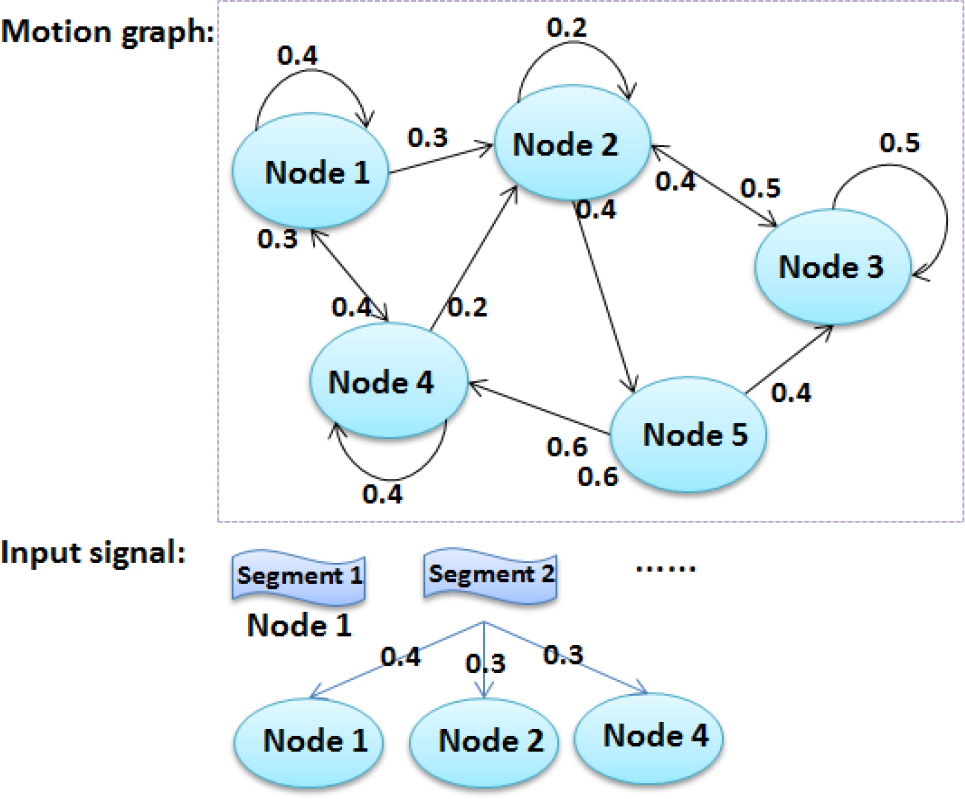
The probabilistic transition condition from graph structure in recognition.
5.2 Recognition Model
For each node of the motion graph, recognition models are also necessary to classify the correct motion from the remaining motion type. We used HMM for this purpose owing to its capacity to deal with long continuous sequential data. Given that use of a general HMM always fails to acquire statistical dependence between different features expressed by different parts of the body, we adopted FHMM to join different parts of the body, which can also be referenced when reconstructing variant motion segments in Section 6.
The observations O1 and O2 of the two HMMs in our experiment are accelerations of different body parts, such as hands and ankles, collected from the four Wiimotes. The key feature of using FHMM centres on an ability to construct the connection between HMMs, which can optimally estimate p(O1,O2). To capture the statistical dependence between two observations O1 and O2, a maximum entropy principle can be used:

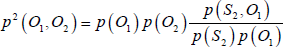
The structure presented above defines the model parameters, {π1, A1, B1, π2, A2, B2, B12, B21}, consisting of two standard HMM parameters: the initial probability π, the state transition probability A and observation probability B, and also the dependencies parameter B12 or B21. The training process for the model we built differs slightly from the original HMM learning process in three fundamental ways:
We use the Expectation Maximization (EM) algorithm to calculate the parameters of the two original HMMs. The training process is described in detail elsewhere [20]. In our experiment, the observations of the model are three-dimensional acceleration vectors from each accelerometer. The discrete observations are clustered using the K-means method.
We select one HMM as the primary HMM based on the accumulated RMS values for acceleration and calculate the hidden state sequence for the primary HMM using the Viterbi algorithm. In our model, we consider the different weights of the two HMMs, with the primary HMM playing a dominant role. Equation (3) expresses the relationship between S1 and O2, which indicates that the observations of HMM2 rely on the hidden states S1 and S2. Given that each of the two observation sequences are determined by S1, HMM1 proves to be the primary one. For different motions, the primary HMM will be chosen based on the accumulated RMS value for the upper and lower limbs, and the probability acquired can be quantified based on the relative weights for each part:

We determine the parameters used to fuse the two HMMs. Given that the observation probability B12 is determined by the hidden state sequence of HMM1 and the observation sequence of HMM2, the training process of fused parameters can be treated as an additional HMM and the equation can be defined as follows:
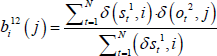
where N is the total hidden state number, j is the clustering number and δ is the impulse function.
Once a training process has finished, the recognition model can be used to deal with signal segments. The purpose of this step is that the training database is comprised of M motion types that map the M nodes of motion graph, and the amount of variant motion for each type is ki. We then construct Σki fused models and calculate the probability at each sampling time to evaluate the similarity of the current input signal sequence and each trained signal sequences by these models. The probability can be represented as:

where j represents a motion from Σki kinds of motions and i is the last recognized motion type.
The recognition process is completed depending on the situation: if the input signal segment comes to an end, the recognition process terminates, and the recognition result is the maximal probability of Pj(t). In other cases, if Pj(t) exceeds a threshold over a period of time and the probability proportion of motion j is large enough to be distinguish from other motion types, the motion type of j defines the recognition result, and the motion data can be reconstructed from the kj variant motions of this type on the basis of similar probabilities.
Based on the ideas presented above, an efficient recognition model was implemented to construct the connections between two HMMs describing different body parts. If one of the two were to fail for some reasons, information from the other parts of the body would be unaffected, and the other HMM would still function properly. The classifier ability of the model is sufficient to provide fast recognition before the signal sequence is completely presented. The method may be applied to low-cost sparse accelerometer applications resulting from the instabilities associated with the signal input and the high efficiency for real-time motion control.
6. Motion Reconstruction
Once the motion signal sequence recognition process has finished, the reconstruction of motion data needs to be conducted in order to ensure a fast reaction in response to the signal input. An efficient state-based motion graph structure is built to ensure the continuous generation of motion data and an interpolated motion reconstruction process for each segment of motion data is implemented to generate the variant motions that correspond to the input signal segments.
6.1 Variant Motion Interpolation
The variance of the signal sequence input each time needs to be described when generating motion data segments. Considering the structure in Section 5, variant motions for each motion type are organized in one node. We represent the motion, M'(t), that we are trying to synthesize as an interpolation of two different time-scaled variant motions using the general interpolation method:
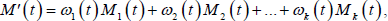
where M1(t) … Mk(t) indicate several variant motion data segments for the same motion type and ω i (t) is a weight value to measure the contribution of each variant motion at the time t.
Two main problems need to be considered when interpolating variant motions. Given that the lengths of variant motions are not uniform, the interpolation cannot be handled to locate the corresponding two frames. A normalization process can be used to map variant motion data segments. Feature points of motion data segments can be located by reducing the threshold of the segmentation process which applies to motion data by measuring the velocities of the corresponding four joints.
By mapping feature points between different variant motions, a linear interpolation process to normalize the motion data can be implemented, and the normalized motion data segments are presented to generate the target motion.
Another problem concerns determination of the weights. The weights are affected by the similarity probabilities provided by the recognition result:

where Pj(t) defines the recognition probabilities. The process of the interpolation is presented in Figure 4.
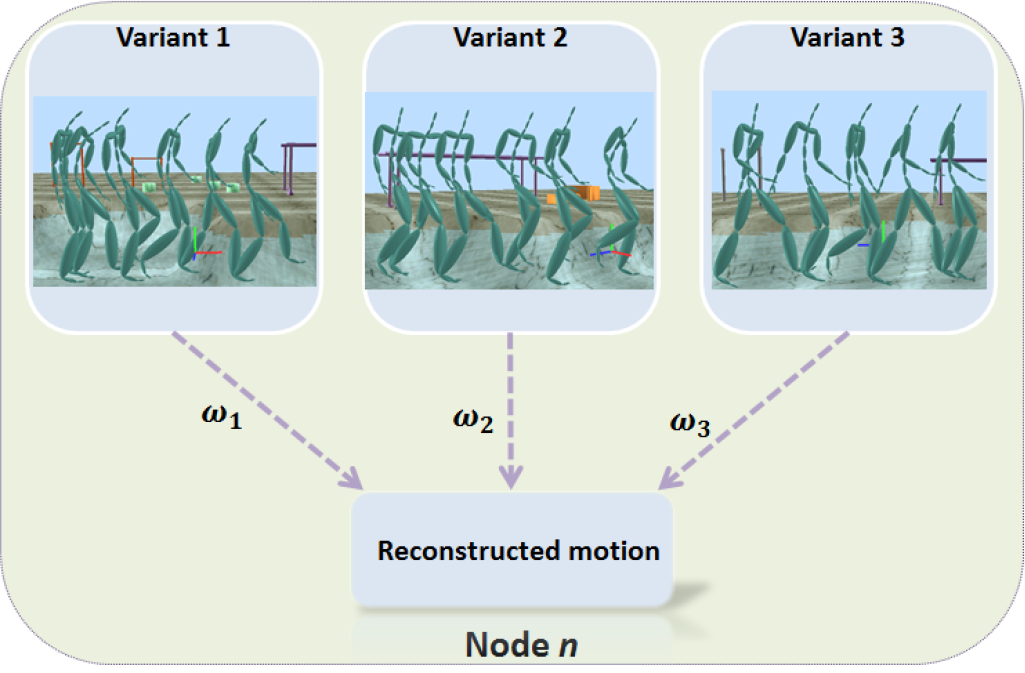
The interpolation process and results.
6.2 State-based Motion Graph
The general framework of the interpolated motion segment matching is based on the well-connected Motion Graph proposed in [21], and is combined with the interpolation process to construct a state-based motion graph. The state presents a type of motion that may contain several variant motions interpolated in the last step and the graph structure is built between each state.
Before generating the transition data, transition points of the motion graph are selected to ensure seamless connection of two clips of original data. A general way to measure the difference between poses at each pair of frames involves measuring the distance between two frames. The distance can be defined as the sum of sinusoidal rotational distances between each pair of joints.
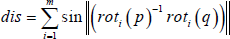
The motion clips are normalized and the distance between each of the two frames of different clips is calculated, with the nearest frame pair of each two motion clips selected to compare the distance with a user-defined threshold in order to get suitable or high connectivity transitions. The frame pairs that fall within the limits of the threshold can be classified as transition points. The value of the threshold depends on the length of the motion data segment.
The next step involves generating transition data. Given that each state of motion graph contains several variant motions for any particular motion type, the data generated at the beginning and end of these variant motions are similar enough to generate universal transition data. An average interpolation of these variant motion data is adopted to reduce the amount of the transition data. The process whereby transition data is generated is described elsewhere [22].
The transition data for each two states is generated along with the construction of the state-based motion graph. After the recognition process for motion signal sequence and interpolation of the corresponding variant motion data, the transition data between the last and the current motion data can be retrieved directly and employed to generate continuous motion.
7. Experiments and Discussions
To illustrate the effectiveness of our approach, we set up several experiments to test the performance of our method of motion control. The input devices used in our experiment were four Wiimotes which were attached to the hands and ankles of the body. During the preprocessing stage, the training signals were collected, the motion database was constructed and the state-based motion graph was built after generation of the transition data. The parameters of the recognition model were initialized and stored in configuration files. Once the recognition model training process was complete, the model parameters associated with each motion were updated in the configuration files for subsequent use. The performance of our motion control method can be verified primarily by measuring the accuracy, robustness and efficiency of the recognition process, as well as the effect and efficiency of motion reconstruction in the context of some practical applications.
To test performance of the method, we constructed a small motion segment database to build the state-based motion graph and adopted the relevant signal sequence to train the recognition model. The 16 motions applied in the experiment: three variances of walking, three variances of jumping, three variances of boxing, three variances of hello, two variances of running and two variances of kicking.
Segmentation during signal preprocessing generates independent signal segments. In the experiment, two adjacent motion signal segments can be separated with a large probability owing to the considerable variation in the velocity. It was necessary to introduce some constraints when dealing with periodic continuous motion, such as conducting the segmentation at every two alternative segment points. A brief pause between two motion signal segments can strengthen the accuracy of segmentation.
We next tested the accuracy and efficiency of our method during the recognition process and compare it with the Gaussian HMM method for a given set of input signals generated by sparse Wiimote accelerometers.
The recognition process shown in Figure 5 involved the “jumping” motion type and the last motion segment type is classified as “running”. Based on user-provided input signal segments, the 16 trained models for each motion calculate the similarity probability with the input signal. Both methods completed the recognition task correctly. The probabilities of variant motions with the same type “boxing” were much higher than the probabilities of the other possible type (Figure 5b), which had better classification capacity than the Gaussian HMM (Figure 5a). The graph constraint restricts the probability of motion types “hello” and “kicking”, which are not within the permitted next node in the graph. The method we propose presents a higher classifier capability, which can be properly applied to full-body recognition. Given the high classifier capability revealed by our method, the recognition process finishes sooner at about 40th frame, as shown by the dotted line in Figure 5(b).

Results of the two methods for the input motion “jumping”. The fiThe expresses the probabilities of the input signals for each trained model. The values on the y-axis indicate the logarithm of the probabilities and the correlation decreases with time. (a) Results obtained using the Gaussian HMM. (b) Results obtained without graph constraint.
The recognition results are presented in Table 1, with the left row showing the recognition result for actors who provided the trained signal data, and the right row showing those of other actors. The trained signals were gathered from three actors and other two actors just conducted the experiment without providing training data. Each actor generated ten sets of signal data for each motion type and three sets of signal data for each trained actor were employed during the training process. We observed a high recognition rate for actors who provided the trained signal data and a slightly reduced recognition rate for other actors owing to differences in the ways that different individuals move.
Recognition result for different motion types and actors.

Our recognition model can better distinguish between different types of motion. In the event of loss of parts of signal sequence from one or even two sensors (at least one is not built as a primary HMM), the recognition results will remain unchanged from those derived from the complete signal sequence.
During the reconstruction process, interpolation is conducted to generate the variant motion data which keep up with gathered signals. Figure 6 shows several generated motion segments using our method, the walking style can be mostly retained by interpolation based on the recognition probability and the step length of motion can also be retained. Some motions may not have been generated because the magnitude of the signal input exceeded the range of the trained signals. The continuous motion generated built by the state-based motion graph is presented in Figure 7(c). The transition of the motion data in our method is coherent and natural, and accurately reflects the actions of the user.

Motion segments generated on the basis of the recognition results. The pictures left of the arrows are training motion segments and the pictures to the right are reconstructed motion segments. (a) Walking with variance of different styles. (b) Jumping with variance of different step lengths.

The process of motion control interacted with a virtual environment. (a) Several motion types generated by our methods. (b) Continuous actions performed by an actor to interact with the virtual environment. (c) Continuous motion generated by the user's control signal sequence.
The efficiency of our motion control method can be demonstrated experimentally. The delay of our method mainly depends on the recognition process. The end of the recognition process can generally be ensured between 20th and 40th frames, which illustrates that the delay of the method will be 0.8–1.6 seconds with a 25 fps sampling time.
The method proposed is applicable to a variety of applications, such as robot operation, interactive games in virtual environments and activity simulation systems in large-scale scenes. Interactions in virtual environmental constitute the main application focus of our method. Virtual environment games and special training regimens require environmental immersion and interactions with virtual objects. Our method, based on sparse sensors, performed well in the context of these applications and can provide the user with an immersed experience (Figure 7(a)(b)).
8. Conclusion and Future Research
We propose a full-body motion control method based on the use of a sparse Wiimote sensor. The approach should be amenable to broad and effective use. Users can perform a range of continuous motions and our method can reconstruct the motion data accurately and efficiently with input from only four sources of input of acceleration sequences. In our method, a motion-oriented signal segmentation process separates the long continuous motion signal sequence into small segments, and these signal segments are recognized by a hierarchical FHMM with a graph constraint that presents a high classifier capability and early recognition process. Once the recognition process ends, the motion data segment is reconstructed and interpolated with the results of recognition probabilities, and the state-based motion graph ensures the continuity and naturalness of the generated motion data. The sparse low-cost accelerometer input and the accurate motion control method are central features of our contribution. Numerous potential applications require that input sensors be convenient for the user and the process by which motion is controlled should be both immersing and natural. Our method addresses both of these considerations.
Further work is needed to enhance the real-time features and accuracy of our approach. For instance, given that the acceleration signals collected here lacked angular components, it is possible that motions with the same directional accelerations may affect the recognition process, thus impacting control. Our future work will consider the use of global mapping with more detailed features from the sensor signal sequence to motion data, rather than frame-by-frame mapping to generate more similar motion data based on the input signals. Some works for generating stylized motion will be conducted using models such as the Gaussian process latent variable. It will then be possible to construct systems for large-scale scene monitoring and control.
Footnotes
9. Acknowledgements
The data used was obtained from HDM05 and the CMU public database. This work was supported by the Natural Science Foundation of China (Grant No.61170186).