
Abstract
It is an interesting and challenging problem to synthesise vivid facial expression images. In this paper, we propose a facial expression synthesis system which imitates a reference facial expression image according to the difference between shape feature vectors of the neutral image and expression image. To improve the result, two stages of postprocessing are involved. We focus on the facial expressions of happiness, sadness, and surprise. Experimental results show vivid and flexible results.
1. Introduction
Due to advances in information technology, issues related to facial imaging, such as face detection, face recognition, facial expression recognition, and facial expression synthesis have greatly advanced.
Turk and Pentland et al. [1] proposed an approach for the detection and identification of human faces that uses principal component analysis (PCA) to project face images onto a face space or eigenspace. This framework provides the ability to learn to recognize new faces in an unsupervised manner.
C.-W. Chang et al. [2] proposed a head pose estimation method that trains a nonlinear interpolative mapping function in a supervised manner for mapping input images to predicted pose angles.
X. Hong et al. [3] also proposed a PCA based method to reduce the dimensionality of discrete cosine transform (DCT) coefficients for visual only lip-reading systems.
J. Yang et al. [4] developed a technique called two-dimensional principal component analysis (2DPCA) for image representation. As opposed to PCA, 2DPCA is based on 2D image matrices rather than 1D vectors, so the image matrix does not need to be transformed into a vector prior to feature extraction. Instead, an image covariance matrix is constructed directly using the original image matrices and its eigenvectors are derived for image feature extraction.
H. J. Lin et al. [5] proposed a module E-2DPCA for face recognition that applies DCT for image enhancement and 2DPCA for feature extraction. They chose the best two from those analysed and compared them with the E-2DPCA module, and found that although the E-2DPCA module outperforms the other two modules, each of the three modules behaved better than the others over some specific set of samples. Thus, they combined the three modules and applied a weighted voting scheme to choose the recognition result from those given by the three modules.
B. Abboud et al. [6] addressed the issues of facial expression recognition and synthesis and compared the proposed bilinear factorization based representations with previously investigated methods such as linear discriminant analysis and linear regression. They concluded that bilinear factorization outperformed these techniques in terms of correct recognition rates and synthesis photorealism especially when the number of training samples was restrained.
T. F. Cootes et al. [7] described a method for building models by learning patterns of variability from a training set of correctly annotated images. These models can be used for image searches in an iterative refinement algorithm analogous to that employed by Active Contour Models (Snakes). The key difference is that our Active Shape Models (ASMs) can only deform to fit the data in ways consistent with the training set.
T. F. Cootes et al. [8] improved the ASM and described a new method of matching statistical models of appearance to images. A set of model parameters, control modes of shape and gray-level variation learned from a training set. They constructed an efficient iterative matching algorithm by learning the relationship between perturbations in the model parameters and the induced image errors.
H.-X. Wang et al. [9] presented an easy-to-use framework for facial image composition based on an Active Appearance Model (AAM), which can automatically exchange the source image's face or facial features onto the target image.
L. Xiong et al. [10] proposed a Statistical Shape and Radio Texture Fusion Model for facial expression sequence synthesis. In this framework, facial shape and texture are processed separately, then fused together to synthesize the final result.
C.-K. Yang et al. [11] proposed an interactive facial expression generation system. In this system, a user is only required to give a single photo and roughly mark the positions of the eyes, eyebrows and mouth in the photo and different expressions can then be generated and morphed from a facial expression database.
In this paper, we propose a facial expression synthesis system which refers to the difference between an expression image (happiness, sadness, surprise and so on) and a neutral expression image of a specific person. To have the target facial image “imitate” the expression of the reference facial image, the system evaluates the difference between the feature vector of the facial image with an expression and that with a neutral expression as a reference and adds it to the feature vector of the target image. In our system, users can select facial expression images from different references as the target image to imitate different expressions from different people. Finally, we propose two stages of postprocessing to improve the synthesis results and make the system more flexible to use.
The rest of this paper is organized as follows. Section 2 introduces the concept of the Active Shape Model. In Section 3, the proposed facial expression synthesis method is described. Experimental results and comparisons are given in Section 4. Finally, conclusions and suggestions for future work are stated in Section 5.
2. The Active Shape Model
The Active Shape Model [7] is a method for building models by learning patterns of variability from a training set of correctly annotated images. It has been applied in many fields.
The first step of the ASM is to align the images to be processed. There are three steps in the alignment algorithm, including shape feature (vector) extraction, mean shape vector training and shape vector alignment.
A shape vector if formed by a sequence of coordinates of control points (feature points). As shown in (1), xi is the shape vector of the ith image, where (xik, yik) are the coordinates of the control points.

Firstly, the mean of the shape vectors in the database is evaluated. Each of the shape vectors is then aligned with the mean shape by an iterative algorithm that iteratively minimizes the difference (error) between the transform version of an image xj and the reference image xi. As shown in (2–4), Ej represents the error, M(s, θ)[x] represents transformation of x of scaling by factor s and rotation by angle Θ and tj represents the translation vector. W is a weighted diagonal matrix according to the different shape vector.


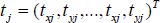
The alignment algorithm is given as follows:
Repeat:
Calculate the mean shape of the image in the data set. Normalize the orientation, scale and origin of the current mean to suitable defaults. Realign every shape with the current mean.
Until the process converges.
3. Facial Expression Synthesis System
The proposed facial expression synthesis system consists of the following steps: preprocessing (including selection of feature points, triangulation segmentation and shape vector alignment), expression synthesis and postprocessing.
3.1 Preprocessing
For the sake of flexibility, users can decide the amount of control points selected. Theoretically, the more control points used the finer the result achieved. However, selection of a large number of control points makes it difficult to use the system. In this study, we select 95 control points for our system, as shown in Fig 1.
After the selection of control points, the triangulation algorithm is utilized to segment the face image into triangular regions based on the selected control points, as shown in Figure 2.

An example of the control point selection

An example of the triangulation segmentation
For the correct correspondence of points between two face images, alignment of each face image is necessary. The purpose of alignment is to normalize the position, orientation, and size of face images. In this paper, we adopt the alignment algorithm proposed by T. F. Cootes et al. [7] to normalize all facial images.
3.2 Facial Expression Synthesis
After alignment, we calculate the difference between the shape vector of each of his/her face image with the expression and that of his/her face image with a neutral expression (or no expression) for each person. As shown in (5), SD i p represents the shape difference for the ith expression of the pth person, S i p =(x i0 p , y i0 p , x i1 p , y i1 p , hellip;, x in p , y in p ) represents shape feature for the ith expression of the pth person and (x 00 p , y 00 p , x 01 p , y 01 p ,…, x 0n p , y 0n p ) represents the neutral expression of the pth person.
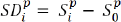
After computing the shape difference for the expression, we add the shape difference to the shape vector of the neutral expression of the target image, as shown in (6).

Then, if desired, paste the texture from the source image S0q to the modified version of the shape vector of the target image IMSq (p, i), as shown in (7).
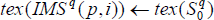
We use a technique called triangulation algorithm [12] to paste the texture from a source image to a target image. Before pasting a triangular region Sh in the source image on the corresponding region Th in the target image, region Sh must be warped into the same shape as Th. As a result, the color of each pixel x' in Th is replaced with that of the corresponding pixel x in Sh. The relationship between x and x′ is stated as follows. As illustrated in Figure 3, if a point x is located at the triangle on the left side with three vertices a, b, and c, then x can be represented as a linear combination of a, b, and c as x = αa+βb+γc, where α+β+γ = 1. If the triangle on the right side with three vertices a′, b′, and c′ corresponds to that on the left side. A point x = αa+βb+γc in the triangle on the left side corresponds to a point x' in the triangle on the right side if and only if x′ = αa′+βb′+γc′. With this relation, one can find, for each point in a triangle, the corresponding point in another triangle by solving a system of linear equations [12].

The correspondence between two triangular regions
Now, it is ready to paste the texture from the source image S0q onto a modified target image shape IMSq (p, i), as shown in the example in Figure 4.

an example of the imitating result, (a) neutral expression of the reference (b) happy expression of the reference (c) triangulation segmentation of the target image (d) triangulation of the imitating shape (e) result of the imitation of the target
3.3 Postprocessing
To improve the result, two stages of postprocessing are provided: (1). Paste some important texture to the resulting synthesized image, and (2). Blending and seamless processing.
When the facial expression changes, some texture might change. As shown in Figure 4(b), different textures like wrinkles might appear in different expressions. Different textures are important for different expressions, as shown in Figure 5.

different textures appearing in different expressions of (a) happiness (b) sadness (c) surprise
However, artefact effects might be caused by pasting textures. We simply apply blending and seamless processing to address this problem as stated in the following example.
Assume that the polygon shown in Figure 6 is a pasted texture region, whose contours are composed of 5 boundary lines L1 = t1t2, L2 = t2t3, L3 = t3t4, L4 = t4t5, and L5 = t5t1. Two sides of each boundary line with skin colors from two different individuals yield artefact effects. To address this problem, the difference of the mean color for a local region in each side of each boundary line is first evaluated. Let the two local regions on the two sides of the ith boundary line Li be Ris and RiT, i = 1, 2, …, 5, inside and outside the region, respectively. Note that the local regions Ris and RiT of the ith boundary line Li have skin colors from the source image and the target image, respectively. The mean color for each local region Rir, r = S or T, is evaluated and denoted by Cir. The difference Δ i between the mean colors for each pair of local regions Ris and RiT is then evaluated, as shown in (8). The color adjustment amount Δ(x, y) for each pixel (x, y) in the region is evaluated by (9) as a weighted sum of those differences of color means. Finally, the color adjustment amount is added to the color of each pixel, as shown in (10). The result of color adjustment for Figure 7(c) is given in Figure 7(d).

The pasted region is blended according to the difference of the mean colors for the local regions on two sides of each boundary line.

skin color adjustment (a) target image (b) reference image (c) result of imitating and texture pasting on target image (d) result of (c) after blending and seamless processing

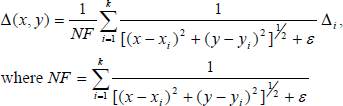
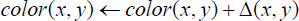
4. Experimental Results
Our experiments were implemented on a PC with a 2.8 GHz Pentium Dual-Core processor and 2.0-GB RAM using Matlab 7.0. Test images of size 480×460 were collected from the TIFF free database [13]. Manual Selection of 95 control points by an experienced user takes around 49 seconds on average, and the subsequent automatic expression synthesis requires an average of 5.72 seconds. Figures 8 and 9 show some synthesis results of a person according to various expressions of different references.

Set 1 of results of expression synthesis; (a) reference 1 – neutral expression (b) reference 1 – happy expression (c) reference 1 – sad expression (d) reference 1 – surprised expression (e) target image – neutral expression (f) synthesis result of happy expression (g) synthesis result of sad expression (h) synthesis result of surprising expression

Set 2 of results of expression synthesis; (a) reference 2 – neutral expression (b) reference 2 – happy expression (c) reference 2 – sad expression (d) reference 2 – surprised expression (e) target image – neutral expression (f) synthesis result of happy expression (g) synthesis result of sad expression (h) synthesis result of surprised expression
Figure 10 shows the synthesis results obtained by the method proposed by C.-K. Yang et al. [11] and our method. The method proposed by C.-K. Yang et al. can produce only a single result for each target image and each expression; while our method can imitate and produce different results according to the expression of a reference chosen by the user.

Synthesis results (a) target image, (b) & (c) synthesis results of happy expression and sad expression, by C.-K. Yang et al., (d) & (e) synthesis results of happy expression and sad expression according to reference 1 by our proposed method (f) & (g) synthesis results of happy expression and sad expression according to reference 2 by our proposed method
5. Conclusions and Future Work
In this paper, we have proposed a facial expression synthesis system that synthesizes facial expressions according to the change of shape feature of the expression of a specific person. In addition to the change of shape feature, we consider the change of texture to improve the synthesis results. The advantages and characteristics of our system are summarized as follows.
The user may choose different expressions of the reference to obtain the result they desire.
The more control points selected, the more vivid and natural the results obtained.
The expression of the reference image is not unique.
In this study, the control points are manually selected and the method by which the triangulation algorithm segments the facial image is also manually indicated. In the future, we will try to develop an algorithm that automatically detects the control points (the feature points based on which it automatically segments the image into triangular regions). Furthermore, we would like to extend our research to 3D models.