
Abstract
We discuss a new design methodology for an inductive self-organizing network using an evolutionary algorithm and its practical applications. The inductive self-organizing network centres on the idea of a group method for data handling. The performances of this network depend strongly on the number of input variables available to the model and the number of input variables and type (order) of the polynomials to each node. They must be fixed by the designer in advance before the architecture is constructed. So the trial and error method must be used with its heavy computation burden and low efficiency. Moreover it does not guarantee that the obtained model is the best one. In this paper, we propose an evolutionary inductive self-organizing network to alleviate these problems. The order of the polynomial, the number of input variables and the optimum input variables are encoded as a chromosome and the fitness of each chromosome is computed. So the appropriate information for each node is evolved accordingly and tuned gradually throughout the genetic iterations. We can show that the proposed model is a sophisticated and versatile architecture which can construct models for limited data sets, as well as heavy complex robotic systems.
Keywords
1. Introduction
Group Method of Data Handling (GMDH) was introduced by Ivakhnenko in the early 1970s [1-3]. GMDH-type algorithms have been extensively used since the mid-1970s for predicting and modelling complex nonlinear processes. The main characteristics of GMDH is that it is self-organizing and provides an automated selection of essential input variables without using prior information on the relationship between input-output variables [4]. A Self-organizing Polynomial Neural Network (SOPNN) is GMDH-type algorithm and one of the most useful approximator techniques [5]. SOPNN has an architecture similar to feed-forward neural networks whose neurons are replaced by polynomial nodes. The output of the each node in the SOPNN structure is obtained using several types of high-order polynomials such as linear, quadratic and modified quadratic of input variables. These polynomials are called Partial Descriptions (PDs). SOPNN have fewer nodes than NNs, but the nodes are more flexible. The SOPNN shows a superb performance in comparison to the previous fuzzy modelling methods. Although the SOPNN is structured using a systematic design procedure, it has some drawbacks which need to be solved. If there is a sufficiently large number of input variables and data points, the SOPNN algorithm has a tendency to produce overly complex networks. On the other hand, if a small number of input variables are available, SOPNN does not maintain good performance. Moreover, the performances of the SOPNN depend strongly on the number of input variables available to the model, as well as the number of input variables and polynomial types or order in each PD. They must be chosen in advance before the architecture of the SOPNN is constructed. In most cases, these are determined by the trial and error method with a heavy computational burden and low efficiency. Moreover, the SOPNN algorithm is a heuristic method so it does not guarantee that the obtained SOPNN is the best one for nonlinear system modelling. Therefore, more attention must be paid to solve the above-mentioned drawbacks.
In this paper we will present a new design methodology for SOPNNs using an evolutionary algorithm (EA) in order to alleviate the above-mentioned drawbacks. The presented network is applied to a 3-input nonlinear system and a humanoid robot which has heavy nonlinearity and complexity.
2. Evolutionary Inductive Self-organizing Network
In this section we will depict the evolutionary inductive self-organizing network (EISON) to be applied to 3-input nonlinear system and practical humanoid robot. Firstly the algorithm and its structure are shown and an evaluation of the usefulness of the method will follow.
2.1 Algorithm and structure
The EISON has an architecture similar to feed-forward neural networks whose neurons are replaced by polynomial nodes. The output of the each node in the EISON structure is obtained using several types of high-order polynomial such as linear, quadratic and modified quadratic of input variables. These polynomials are called Partial Descriptions (PDs). The PDs in each layer can be designed using evolutionary algorithms. The framework of the design procedure of the EISON comes as a sequence of the following steps.
[Step 1] Determine input candidates of a system to be targeted.
[Step 2] Form training and testing data.
[Step 3] Design partial descriptions and structure evolutionally.
[Step 4] Check the stopping criterion.
[Step 5] Determine new input variables for the next layer.
In the following, a more in-depth discussion on the design procedures, step 1~5, is provided.
We define the input variables such as x1i, x2i, ··· xNi related to output variables yi, where N and i are the number of entire input variables and input-output data set, respectively.
The input-output data set is separated into training (ntr) data set and testing (nte) data set. Obviously we have n = ntr + nte. The training data set is used to construct an EISON model and the testing data set is used to evaluate the constructed EISON model.
When we design the EISON, the most important consideration is the representation strategy, that is, how to encode the key factors of the PDs, order of the polynomial, the number of input variables and the optimum input variables, into the chromosome. We employ a binary coding for the available design specifications. We code the order and the inputs of each node in the EISON as a finite-length string. Our chromosomes are made of three sub-chromosomes. The first one consists of 2 bits for the order of polynomial (PD), the second one consists of 3 bits for the number of inputs of PD and the last one consists of N bits which are equal to the number of entire input candidates in the current layer. These input candidates are the node outputs of the previous layer. The representation of binary chromosomes is illustrated in Fig. 1.

Structure of binary chromosome for a PD
The 1st sub-chromosome is made of 2 bits. It represents several types of order of PD. The relationship between bits in the 1st sub-chromosome and the order of PD is shown in Table 1. Thus, each node can exploit a different order of the polynomial.
Relationship between bits in the 1st sub-chromosome and order of PD.

The 3rd sub-chromosome has N bits, which are concatenated bits of0's and 1's coding. The input candidate is represented by a 1 bit if it is chosen as input variable to the PD and by a 0 bit it is not chosen. This way the problem of which input variables to be chosen is solved.
If many input candidates are chosen for the model design, the modelling is computationally complex and normally requires a lot of time to achieve good results. In addition, it causes improper results and poor generalization ability. Good approximation performance does not necessarily guarantee good generalization capability. To overcome this drawback, we introduce the 2nd sub-chromosome into the chromosome. The 2nd sub-chromosome consists of 3 bits and represents the number of input variables to be selected. The number based on the 2nd sub-chromosome is shown in Table 2.
Relationship between bits in the 2nd sub-chromosome and number of inputs to PD.

Input variables for each node are selected among entire input candidates as many as the number represented in the 2nd sub-chromosome. The designer must determine the maximum number in consideration of the characteristic of the system, design specification and some prior knowledge of the model. With this method we can solve problems such as the conflict between overfitting and generalization and the requirement of a lot of computing time. The relationship between chromosome and information on PD is shown in Fig. 2. The PD corresponding to the chromosome in Fig. 2 is described briefly in Fig. 3.

Example of a PD whose various pieces of required information are obtained from its chromosome
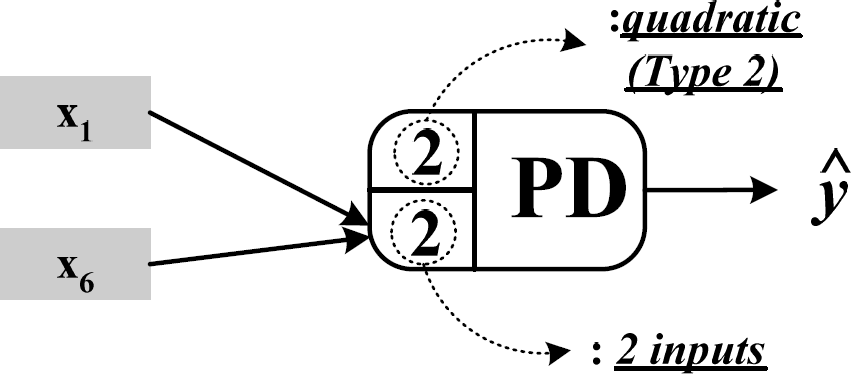
Node with PD corresponding to chromosome in Fig. 2.
Fig. 2 shows an example of the PD. The various pieces of required information are obtained from type of each chromosome. The 1st sub-chromosome shows that the polynomial order is Type 2 (quadratic form). The 2nd sub-chromosome shows two input variables to this node. The 3rd sub-chromosome tells that x1 and x6 are selected as input variables. The node with PD corresponding to Fig. 2 is shown in Fig. 3. Thus, the output of this PD, ŷ can be expressed as (1).
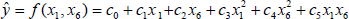
where coefficients c0, c1, …, c5 are evaluated using the training data set by means of the standard least square estimation (LSE). Therefore, the polynomial function of PD is formed automatically according to the information of sub-chromosomes.
The EISON algorithm terminates when the 3rd layer is reached.
If the stopping criterion is not satisfied, the next layer is constructed by repeating step 3 through to step 4.
The overall design procedure of the EISON is shown in Fig. 4. At the beginning of the process, the initial populations comprise a set of chromosomes that are scattered all over the search space. The populations are all randomly initialized. Thus, the use of heuristic knowledge is minimized. The assignment of a fitness function in the evolutionary algorithm serves as guidance to lead the search toward the optimal solution. The fitness function with several specific cases for modelling will be explained later. After each of the chromosomes is evaluated and associated with a fitness, the current population undergoes the reproduction process to create the next generation. The roulette-wheel selection scheme is used to determine the members of the new generation. After the new population is built, the mating pool is formed and the crossover is carried out. The crossover proceeds in three steps. First, two newly reproduced strings are selected from the mating pool produced by reproduction. Second, a position (one point) along the two strings is selected randomly. The third step is to exchange all characters following the crossing site. We use a one-point crossover operator with a crossover probability of Pc (0.85). This is then followed by the mutation operation. The mutation is the occasional alteration of a value at a particular bit position (we flip the states of a bit from 0 to 1 or vice versa). The mutation serves as an insurance policy which would recover the loss of a particular piece of information (any simple bit). The mutation rate used is fixed at 0.05 (Pm). Generally, after these three operations, the overall fitness of the population improves. Each of the population generated then goes through a series of evaluation, reproduction, crossover and mutation, and the procedure is repeated until a termination condition is reached. After the evolution process, the final generation of population consists of highly fit bits that provide optimal solutions. After the termination condition is satisfied, one chromosome (PD) with the best performance in the final generation of the population is selected as the output PD. All the remaining chromosomes are discarded and all the nodes that had no influence on this output PD in the previous layers are also removed. By doing this, the EISON model is obtained.

Block diagram of the design procedure of the EISON.
2.2 Fitness function for the EISON
The important thing to be considered for the evolutionary algorithm is the determination of the fitness function. The genotype representation encodes the problem into a string, while the fitness function measures the performance of the model. It is quite important for evolving systems to find a good fitness measurement. To construct models with significant approximation and generalization ability, we introduce the error function such as

Input-output data of 3-input nonlinear function.

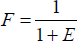
Maximizing F is identical to minimizing E.
3. Evaluation of the EISON
3.1 3-input nonlinear system
In this example, we will demonstrate how the proposed EISON model can be employed to identify the highly nonlinear function. The performance of this model will be compared with that of earlier works. The function to be identified is a 3-input nonlinear function given by (4)

which is widely used by Takagi and Hayashi[6], Sugeno and Kang[7], and Kondo[8] to test their modelling approaches. Table 3 shows 40 pairs of the input-output data obtained from (4) [9]. The data in Table 3 is divided into training data set (Nos. 1–20) and testing data set (Nos. 21–40). To compare the performance, the same performance index, average percentage error (APE) adopted in [6-9] is used.
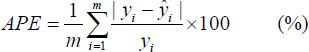
where m is the number of data pairs and yi and ŷi are the i-th actual output and model output, respectively.
A series of comprehensive experiments was conducted and the results are summarized. The design parameters of the EISON in each layer are shown in Table 4.
Design parameters of the EISON for modelling.
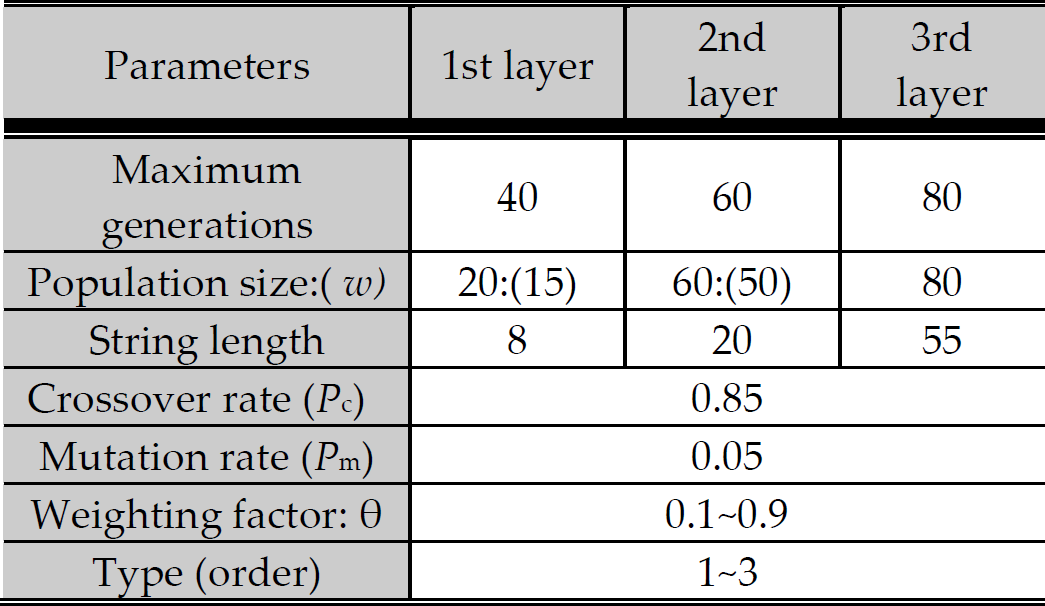
w: the number of chosen nodes whose outputs are used as inputs to the next layer. This number can be decided heuristically by the designer according to the uncertainty and nonlinearity of the target system.
The simulation results of the EISON are summarized in Table 5. The overall lowest values of the performance index, PI=0.188 EPI=1.087, are obtained at the 3rd layer when the weighting factor (θ) is 0.25.
Values of performance index of the proposed EISON model.

Fig. 5 illustrates the trend of the performance index values produced in successive generations of the EA when the weighting factor θ is 0.25. Fig. 6 shows the values of error function and fitness function in successive EA generations when the θ is 0.25.

Trend of performance index values with respect to generations through layers (θ =0.25)

Values of the error function and fitness function with respect to the successive generations (θ =0.25).
Fig. 7 depicts the proposed EISON model with three layers when the θ is 0.25. The structure of the EISON is very simple and has a good performance. But for the conventional SOPNN from a few numbers of input candidates, it is impossible to structure the model for this nonlinear function.
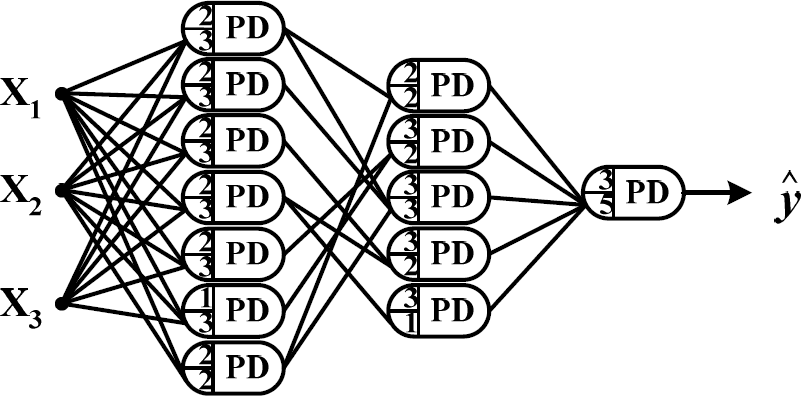
Structure of the EISON model with three layers (θ =0.25).
Fig. 8 shows the identification performance of the proposed EISON and its errors when the θ is 0.25. The output of the EISON follows the actual output very well.

Identification performance of the EISON model with three layers and its errors.
Table 6 shows the performance of the proposed EISON model and other models studied in the literature. The experimental results clearly show that the proposed model outperforms the existing models both in terms of better approximation capabilities (PI), as well as superb generalization abilities (EPI). But the conventional model cannot be applied properly to the identification of this example.
Performance comparison of various identification models.

3.2 Practical biped humanoid robot
The bipedal structure is one of the most versatile ones for the employment of walking robots. The biped robot has almost the same mechanisms as a human and is suitable for moving in an environment which contains stairs, obstacle etc., where a human lives. However, the dynamics involved are highly nonlinear, complex and unstable. So it is difficult to generate a human-like walking motion. To realize human-shaped and human-like walking robots (humanoid robots), much research on biped walking robots has been conducted [11-14]. In contrast to industrial robot manipulators, the interaction between the walking robots and the ground is complex. The concept of the zero moment point (ZMP) [12] is known to give good results in order to control this interaction. As an important criterion for the stability of the walk, the trajectory of the ZMP beneath the robot foot during the walk is investigated [11-17]. Through the ZMP, we can synthesize the walking patterns of humanoid robot and demonstrate the walking motion with real robots. Thus, ZMP is indispensable to ensure dynamic stability for a biped robot. The ZMP represents the point at which the ground reaction force is applied. The location of the ZMP can be obtained computationally using a model of the robot, but it is possible that there is a large error between the actual ZMP and the calculated one, due to the deviations of the physical parameters between the mathematical model and the real machine. Thus, actual ZMP should be measured to realize stable walking with a control method that makes use of it.
In this paper, actual ZMP data throughout the whole walking phase are obtained from the practical humanoid robot and the EISON is applied. Joint angles, practical views and a block diagram of the implemented robot are shown in Fig. 9. The specifications of the biped robot are depicted in Table 7. The robot has 19 joints and height and weight are about 445mm and 3000g, respectively, including the vision camera. For the reduction of weight, the body is made of aluminium materials. Each joint is driven by the RC servomotor that consists of a DC motor, gear and simple controller. Each of the RC servomotors is mounted on the link structure.
Specifications of the robot.


Implemented humanoid robot, practical views and its block diagram.
As an important criterion for the stability of the walk, the trajectory of the ZMP beneath the robot foot during the walk is investigated. Through the ZMP, we can synthesize the walking patterns of a biped walking robot and demonstrate a walking motion with real robots. Thus, the ZMP is indispensable to ensure dynamic stability for a biped robot. The measured ZMP trajectory data to be considered here are obtained from 10 degree of freedoms (DOFs). Two DOFs are assigned to hips and ankles, and one DOF to the knee on both sides. From these joint angles, a cyclic walking pattern has been realized. This biped walking robot can walk continuously without falling down. The ZMP trajectory in the robot foot support area is a significant criterion for the stability of the walk. In many studies, the ZMP coordinates are computed using a model of the robot and information from the joint encoders, however, we employed a more direct approach which is to use measurement data from sensors mounted on the robot's feet.
The type of force sensor used in our experiments is FlexiForce sensor A201 which is shown in Fig. 10. They are attached to the four corners of the sole plate. Sensor signals are digitized by an ADC board, with a sampling time of 10 ms. Measurements are carried out in real-time. The foot pressure is obtained by summing the force signals. By using the force sensor data, it is easy to calculate the actual ZMP data. Feet support phase ZMPs in the local foot coordinate frame are computed by equ. 6

Employed force sensors under the robot's feet.

where fi is each force applied to the right and left foot sensors, and ri is sensor position which is vectored.
The walking motions of the biped humanoid robot are shown in Fig. 11. The figure shows a series of snapshots in the side views of the biped humanoid robot walking on a flat floor.

Side view of the biped humanoid robot on a flat floor.
Experiments using the EISON were conducted and the results are summarized in the tables and figures below. The design parameters of evolutionary inductive self-organizing network in each layer are shown in Table 8. The results of the EISON for the walking humanoid robot on the flat floor are summarized in Table 9. The overall lowest values of the performance indices, 6.865 and 10.377, are obtained at the 3rd layer when the weighting factor (θ) is 1. In addition, the generated ZMP positions and corresponding ZMP trajectory are shown in Fig. 12.
Design parameters of the evolutionary inductive self-organizing network.

Condition and the corresponding MSE are included for the actual ZMP position in the four step motion of our humanoid robot.


Generated ZMP positions and corresponding ZMP trajectories.
w: the number of chosen nodes whose outputs are used as inputs to the next layer. This number can be decided heuristically by the designer according to the uncertainty and nonlinearity of the target system.
4. Concluding remarks
In this paper, we propose a new design methodology for the EISON using evolutionary algorithms and the study properties of EISONs. We can see that the EISON is a sophisticated and versatile architecture which can construct models for limited data sets and complex humanoid robots. Moreover, the architecture of the model is not predetermined, but can be self-organized automatically during the design process. The example employed in the paper, a 3-input nonlinear system, is well modelled using the proposed method and we can get a reasonable approximation capability. In particular, the network size is smaller and the performance is better than the classical model. This could be possible due to two techniques combining optimization of evolutionary algorithms and polynomial approximation of SOPNNs. Occasionally, these good results can be varied according to the peculiarity of the system to be identified so this needs further research. The EISON model can be an effective means by which to construct a predictive model for poorly defined complex systems. According to the sophisticated and versatile architecture, the significance of these works is not restricted to a nonlinear static function. A humanoid robot is versatile and has almost the same mechanisms as a human – it is therefore suitable for moving in a human's environment – however, the dynamics involved are highly nonlinear, complex and unstable. It is therefore difficult to generate a human-like walking motion. In this paper, we have employed the zero moment point as an important criterion for the balance of the walking robots. In addition, the EISON is also utilized to establish empirical relationships between the humanoid walking robot and the ground, and to explain empirical laws by incorporating them into the humanoid robot. Thus, this work is significant for any complex process with nonlinearity.
Footnotes
5. Acknowledgments
This research was supported by the Basic Science Research Programme through the National Research Foundation of Korea (NRF) funded by the Ministry of Education, Science and Technology (grant no. 2011-0010579).
This research was supported by the Basic Science Research Programme through the National Research Foundation of Korea (NRF) funded by the Ministry of Education, Science and Technology (grant no. 2011-0010579). Y-G Kim was supported by Ministry of Culture, Sports and Tourism and KOCCA in the CT R&D Program 2011.