
Abstract
In this paper, we present a new framework for face recognition with varying illumination based on DCT total variation minimization (DTV), a Gabor filter, a sub-micro-pattern analysis (SMP) and discriminated accumulative feature transform (DAFT). We first suppress the illumination effect by using the DCT with the help of TV as a tool for face normalization. The DTV image is then emphasized by the Gabor filter. The facial features are encoded by our proposed method - the SMP. The SMP image is then transformed to the 2D histogram using DAFT. Our system is verified with experiments on the AR and the Yale face database B.
1. Introduction
Image representation is one of the key issues in the computer vision and image processing communities. It is usually proposed for transforming the raw image to a new domain in which the recognition process can be tolerated against illumination changes, rotation and scaling, pose, occlusions, etc. Several techniques have been proposed for solving the problems in face recognition by means of image representation. For a holistic approach, PCA and LDA [10, 3] may be offered as the most prominent methods for face recognition. The concept of an eigenface is an optimal reconstruction method in the sense of minimum mean square error, which projects an image onto the directions that maximize the total scatter across all classes of face images [10]. This means that the eigenface is not the optimal method in the sense of discrimination ability, which depends upon the separation between different classes rather than the spread of all classes. For the problems of class separation, a method based on class-specific linear projection was proposed by Belhumeur et al. [3]. This method tries to find the eigenvectors for which the ratio of the between-class scatter and the within-class scatter is maximized. Recently, methods based on local encoding enhancement have been proposed for face recognition under variable illuminations [1, 2]. Ahonen et al. [1] propose a new face representation based on a local binary pattern (LBP) histogram. They divide the face areas into 49 small (7×7) windows. The LBP8,2U2 was used to encode the local pixels of the face images. Zhang et al. [12] presented a combination of Gabor filter and the LBP, which was called a local Gabor binary pattern histogram sequence (LGBPHS). They applied the Gabor filters at five scales and eight orientations on the face image. The LBP was then applied to all 40 Gabor magnitudes to generate the LGBPHS. The extension of the LGBPHS was proposed in [2]. The Gabor phase was used to encode and represent the histogram of the Gabor phase pattern (HGPP). The quadrant-bit codes, extending from the IrisCode [6], were first extracted from the face images based on the Gabor phase information. Global and local GPPs were proposed to encode the phase variations. GGPP captured the variations of the orientation changes of the Gabor wavelet at a given scale while the LGPP encodes the local variations by using a local XOR pattern.
In this paper, we present a method for illumination normalization and facial feature amplification. We combined the discrete cosine transform and total variation minimization - which is called DTV - for suppressing the variations in illumination. The aims of our normalization process are to suppress the illumination variations while enhancing the facial structures. In general, a face normalization method should satisfy the following criteria:
Good Normalization: the illumination variations should be suppressed and the facial components must not be destroyed.
Good Preservation: the facial structures (eyes, eyebrows, nose and mouth) must be maintained and should be more prominent than the others.
We will present our normalization process in order to achieve these criteria. Next, we encode the pre-processed image using our method - the SMP. Finally, the 2-D SMP image is transformed into the 2-D feature space - the 2-D histogram. The test statistic is used to measure the 2-D histogram.
This paper is organized as follows. Section 2 presents the face normalization and face encoding techniques. We introduce a feature transform in section 3. Extensive experimental results will be demonstrated in section 4. Finally, we conclude in section 5.
2. The Basic Principles
We give a brief overview of the basic principles which are used in this paper, including the discrete cosine transform, the total variation minimization, the Gabor filter and a sub-micro-pattern analysis.
2.1 Discrete Cosine Transform
The discrete cosine transform (DCT) is a useful tool in signal processing for frequency analysis. Its results correspond to the frequency components in an (signal) image - i.e., the low and high frequencies are arranged in DCT components. The DCT represents a sequence of finite pixel elements in terms of the sum of cosine functions oscillating at different frequencies. For a 2D image of size M × N, the DCT-II is defined as:

with its inverse transform:

where

and

with all other Q(a,b)s set to 1, where β0 ∈ [0.85,1.3], β1 ∈ [0.5,0.7], β2=β1 + 0.1 and β3 = β2 + 0.1. We define the quantized DCT face image as:

where DCT and iDCT are the discrete cosine transform and its inverse as defined in equations (1) and (2). Using DCT in conjunction with TV is useful insofar as the facial features are enhanced while the illumination variations are suppressed. The quantized DCT D will be used in the next subsection.
2.2 Total Variation Minimization
Without lost of generalization, we define the input image for the TV model as f - in fact, f is the quantized DCT D generating from the previous subsection. Total variation (TV) minimization is a tool for image reconstruction which preserves edges and allows for sharp boundaries [4]. It can be used to decompose a large-scale component from a small-scale one, which separates an image f into two parts. In particular, the TV model decomposes an input image f into a large-scale output u and a small-scale output v, where f, u and v are functions of image intensity values with f,u,v ∈ ℝ2. We assume that u and v are two images, extracting from an image f, defined on Ω. A general way to obtain the decomposition images is to solve the minimization problem:

where
Minimize the total variation
Compute the regulation measure term ‖
The regularization measure term ‖

such that

where ct ∈ ℝni and At ∈ ℝm × ni, b ∈ ℝ m . Each sub-vector xt must lie in an elementary second-order cone of dimension ni
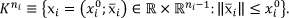
We assume that the images are represented as 2-D n × n matrices, whose elements give the grey values of corresponding pixels, i.e.:

Let ∂+ be the discrete differential operator defined by:
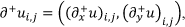
where (∂+xu)i,j = ui+1,j-ui,j, for i = 1,…, n − 1, j = 1, …, n, and (∂+yu)i,j = ui,j − ui,j for i = 1,…, n,j = 1, …, n − 1, which are equivalent to the first derivative in any image processing's definition. The discrete total variation of u is defined by forward finite differences as:

By introducing tt,j and the relation
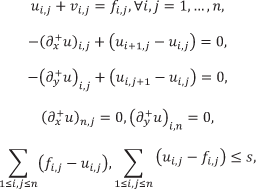
such that:

Having solved the total variation of u, the normalized face image can be formulated as:
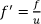
where f is a quantized DCT as defined in equation (3) and u is a large-scale image, solved by SOCP-TV. We called this normalization method the DCT-TV or – in short-the DTV.
2.3 The Gabor Transform
Now, the DTV face image is emphasized using the Gabor transform. Let

where σ governs the spatial extent and bandwidth of the Gaussian function and μ and v control the orientation and scale of the Gabor kernel, z = (ξ1-x1, ξ2-x2,). The wave vector

where
2.4 A Sub-Micro Pattern Encoding Operator
In general, a 2-D isotropic Gaussian function is defined as
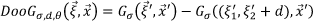
where ξ'1 ξ1 = ξ1 cos θ + ξ2 sin θ and ξ'2 = −ξ1 sin θ + ξ2 cos θ with

Ψ measures the texture variations around the centre positive Gaussian and gives the differences as the positive or negative values. Therefore, we define the ζ function as:
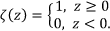
ζ encodes the sign of the differences as 0 or 1. Consequently, the texture coding for each pixel can be written as:
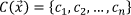
with

where θ
i
is a specified orientation of the DooG, e.g., θ
t
= 0°, 15°,…,345° for θ = 15°, and
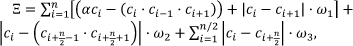
where α and ω
i
are constant values defined by a user to determine the number of unique values, |ci − ci+1| is the successive absolute different operator,
3. The Feature Transform
In this section, we propose a new 2-D global image descriptor which describes the characteristics of the SMP face image. As can be seen in Fig. 1 (a), the SMP image has more distinctive features. We therefore need a method for depicting the structure of the SMP face image. We know that the 1-D histogram is not appropriate for this case. We construct the global histogram for each image by accumulating the sign of the difference of the values of the SMP. Let SMP(
1. Initializes the histogram H to zero.
2. For each pixel

with
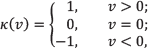
where
3. Repeat step 2 for all pixels
In this paper, Nr = 40 is fixed for all rings r ∈ R and R ={5,11,15,20,25} is setup for all experiments. The

The construction of the histogram DAFT descriptor.
Having constructed the global histogram H, it is common to use the χ2 test statistic:

where Hi and Hj represent the DAFT histograms.
4. Experimental Results
To assess the face recognition problem, we evaluated our approach on the Yale face database B (YaleB) [7] and the AR face database (ARDB) [8]. It should be noted that there are variations in illumination, facial expressions and occlusions for the two databases. The YaleB [7] contained 10 people viewed under 64 different illumination conditions. It has been used as a de facto standard for the evaluation of variable lighting face recognition. For this database, we mainly dealt with the illumination problem. The images are divided into five subsets according to the illumination directions: Subset 1 (0° to 12°), Subset 2 (13° to 25°), Subset 3 (26° to 50°), Subset 4 (51° to 77°) and Subset 5 (above 78°). Fig. 2 demonstrated the experiments of face normalization on the YaleB with variable illuminations. The first row showed the original images ranging from neutral to extreme light sources. The corresponding normalization results were shown in the second. When using the DTV, the illumination variations were suppressed while the facial structures were still maintained. In addition, the facial components (eyes, eyebrows, nose and mouth) were more prominent than the cheek and forehead, obviously. One can see that the eyes, eyebrows, nose and mouth were emphasized whereby the facial structures remained the same for all variable illuminations.

The example results of our face normalization method on YaleB. The columns give images from subsets 1 to 5, respectively. 1st row) original images, 2nd row) DTV images.
Another benefit of the proposed approach was demonstrated in Fig. 3. The original and normalized versions of the face images were shown in Figs. 3 (a) and (b). The LBP face image was shown in Fig. 3 (c). The discriminative features of the SMP and DAFT were demonstrated in Figs. 3 (d) and (e). It is clear that our SMP and DAFT methods are rich features in which the facial images were described as discriminated characteristics. In addition, the SMP images as shown in Fig. 3 (d) can serve as the ‘faceprints’ which can help us recognize human faces better. We believed that using the SMP image would give us a more prominent representation than the LBP one.

Examples of our descriptors. (a) Original images (b) DTV images (c) LBP images with DTV (d) SMP images with DTV and the Gabor filter and (e) the histogram DAFT.
4.1 Yale Face Database B
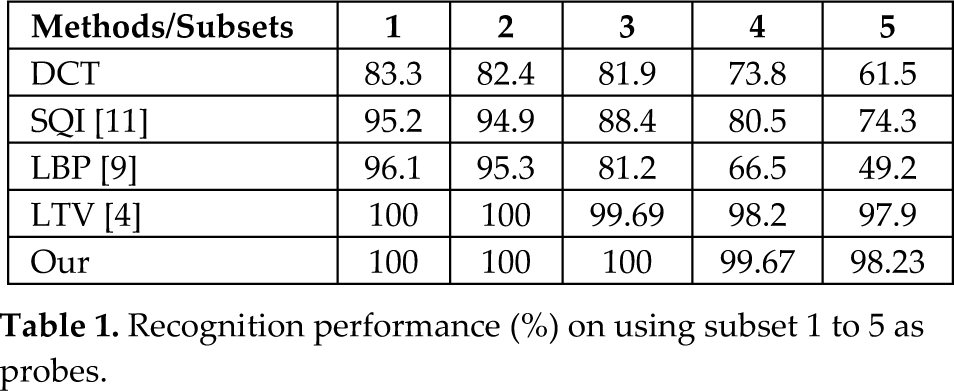
A comparison on different methods for YaleB was shown in Table 1. In this experiment, the neutral light source images were created as the gallery and all other subsets were used as the probes. The most difficult of YaleB were subsets 4 and 5. We achieved the best performance (99.67%, 98.23%), followed by LTV (98.2%, 97.9%). This stemmed from the fact that our proposed method attempted to suppress lighting variations while enhancing the facial structures in the face images.
Recognition performance (%) on using subset 1 to 5 as probes.
4.2 AR Face Database
For ARDB, the first three images for each subject were used as the training set while the rest were used as the test set. To demonstrate the additional usefulness of the proposed illumination normalization process, we provide the results of face normalization on the ARDB in Fig. 4. The images in the first row were the original images with different variation conditions - e.g., expression, screaming, left-right light on, wearing a scarf, wearing sun glasses, etc. In the second row, the images were normalized using the LTV technique [4]. The results of our proposed method were shown in the third row. It is clear that our proposed method normalizes the illumination variations while maintaining the facial components with more prominence. This helps us in enhancing the facial features in which more accurate face recognition can be achieved. In order to suppress the illumination variations and enhance the facial components, the parameters for DTV were setup as shown in Table 2. As mentioned in subsection 2.1, the first component of the DCT transform is an average value of the sample sequences. Hence, β0 was used to normalize the overall illumination conditions of the face images with β0 > 1 (darker) or β0 < 1 (brighter) as settings. The parameters β1 to β0 were used to enhance the facial components for which they are more prominent than the others.

Face normalization methods. 1 st row) original images, 2 nd row) the LTV images [11] and 3 rd row) the DTV images.
The parameter settings for DCT and TV. Note: When setup β1, β2 = β1 + 0.1 and β3 = β2 + 0.1.

Table 3 compares the different approaches for face recognition in terms of recognition rate. When we evaluated the face recognition results, we count the number of correct recognitions which were in ranks 1, 5, 10 and 15. For the correct recognition that was within rank 1, the proposed approach achieved the best performance (73.02%), followed by the LTV (61.61%) and LBP methods (57.8%). If we count the number of the recognition rate that was within rank 15, our approach still achieved the best performance with 95.67%, while the recognition rate of LTV was 93.22% and that of LBP was 68.9%. It is clear that our proposed method has very high recognition accuracy, even in the case of extreme conditions.
Comparison of the face recognition rate (%) for different approaches tested on the AR face database.

5. Conclusions
We have presented a new framework for face recognition under varying illumination based on DTV, SMP and DAFT. The illumination variations were first suppressed using the DCT with TV. The facial features were amplified by our proposed method - the Gabor + SMP. The DAFT method was used to transform the 2D image into the 2D feature space. Finally, the χ2 test statistic was used for histogram matching. Our system was verified with experiments on the ARDB and YaleB databases and has achieved a very high recognition rate.