
Abstract
In this paper, a novel manifold learning algorithm for face recognition and gender classification – orthogonal nearest neighbour feature line embedding (ONNFLE) – is proposed. Three of the drawbacks of the nearest feature space embedding (NFSE) method are solved: the extrapolation/interpolation error, high computational load and non-orthogonal eigenvector problems. The extrapolation error occurs if the distance from a specified point to one line is small when that line passes through two farther points. The scatter matrix generated by the invalid discriminant vectors does not efficiently preserve the locally topological structure – incorrect selection reduces recognition. To remedy this, the nearest neighbour (NN) selection strategy was used in the proposed method. In addition, the high computational load was reduced using a selection strategy. The last problem involved solving the non-orthogonal eigenvectors found with the NFSE algorithm. The proposed algorithm generated orthogonal bases possessing more discriminating power. Experiments were conducted to demonstrate the effectiveness of the proposed algorithm.
1. Introduction
Face recognition (FR) and gender classification (GC) are widely used in many commercial systems for monitoring pedestrians who watch advertisements on TV walls or else for monitoring the behaviour of buyers at vending machines. The ID and gender of pedestrians is automatically identified for further application. Though FR and GC are two different applications, gender classification could be considered to be a two-class classification problem – a special case of FR. Three approaches – classifier design, image enhancement and feature discriminative analysis – are proposed to achieve better performance.
The first step is to design a good classifier. Neural network-based classifiers are frequently used in FR. A principle component neural network with a self-configurable systolic architecture to automatically update eigenfaces whenever training faces change was proposed in [1]. Fuzzy measures and fuzzy logic improved the aggregation operator in neural networks [2]. The modular neural network outputs are integrated and performance is improved. Similarly, a radial basis function enhances the neural network's performance with an incremental learning mechanism [3]. The re-training process is unnecessary because new data is locally selected and updated by a regressor. From the results of [3], a higher average accuracy and a much lower computational load were achieved. A neuro-fuzzy quantification method [4] is proposed to describe the Iyashi of human faces, increasing accuracy by 2–8%. An AdaBoost-based classifier is another popular classifier through the boosting method. Weak classifiers are integrated to construct a strong classifier and several strong classifiers are cascaded to enhance performance for gender classification [5-7]. Besides this, certain tricks were also utilized for the improvement of efficiency. For example, a look-up-table is used in [6] and a 93% identification rate was achieved by pixel comparisons in [7].
Second, images are enhanced for the improvement of recognition by using image processing methods. A set of weighted colour-component features is found from various colour spaces and integrated by a boosting selection algorithm for face recognition [8]. Local colour vector binary patterns (LCVBPs) [9] consisting of colour-norm patterns are extracted from the norm values of a pixel and its four neighbours. In addition, colour angular patterns are also extracted from the angles between the vectors of colour features. 3-D face features are extracted from the shape-based method [10] against the variations of face expressions, illumination and poses.
Third, eigenspace projection methods are successfully used for feature extraction. Recently, manifold learning algorithms have attracted much attention because samples are always presented in a manifold structure in high dimensional feature spaces [11]. By preserving non-linear local structures, the discriminative power of manifold learning-based classifiers is greatly increased when compared to conventional global Euclidean structure preserving methods, such as principle component analysis (PCA) [12] and linear discriminative analysis (LDA) [13]. A third-order tensor colour representation and a tensor discriminant colour space (TDCS) model [14] preserve the spatial structure of colour images. A colour space transformation matrix is obtained to maximize Fisher's criterion. Images are convoluted by a complete set of bases – e.g., blur kernels – to construct a new subspace against blur variance [15]. A view-manifold-based TensorFace (V-TensorFace) and a kernelized TensorFace (K-TensorFace) [16] generate a continuous view manifold structure of unseen views in the tensor-based analysis. Other, remaining, problems with FR include occlusion and poor image quality. Outliers caused by occlusion and illumination variations are solved by kernel discriminant analysis [17] and the spectral-graph-based method [18]. In addition, low-resolution images are enhanced and identified in video surveillance. The non-linear mapping from low-resolution images to high-resolution images is constructed with the canonical correlation analysis and radial basis functions [19]. For gender classification, another PCA variant, called principle geodesic analysis (PGA), was proposed. Sample data with a manifold structure in Euclidean spaces was transformed into data in Riemannian spaces by using exponential log maps [20]. Furthermore, the linear discriminant techniques for gender classification have been reviewed in [21]. When the training samples are sufficient, the SVM-based classifier outperforms the others. On the other hand, if the training samples were only a few, the linear approaches achieved better results. In addition, the accuracy rates of gender classification are significantly improved by automatic face alignment [22].
In this paper, we focus on the study of feature discriminative analysis. An algorithm – orthogonal nearest neighbour feature line embedding (ONNFLE) – was modified based on previous work (e.g., nearest feature line embedding (NFLE) [23]). With the NFLE method, two problems – extrapolation/interpolation error and high computational load – were remedied during the computation of the class scatters. Those discriminant vectors which were only a small distance from a specified point on the feature lines were chosen for scatter computation. An extrapolation error occurs when the distance is small while two prototypes are far away from the specified point. At the same time, the near neighbours are not chosen due to the large distances involved. This selection strategy violates the rule of local structure preservation. To remedy this problem, the ONNFLE algorithm modified the selection rule. A point-to-line (P2L) adjacency matrix was constructed to preserve the local topology structure. Three characteristics – NFL-based measurement, neighbourhood structure preservation and class separability – were presented in ONNFLE. In addition, orthogonal projection bases were obtained in ONNFLE.
The rest of this paper is organized as follows: In Section 2, eigenspace projection methods, LPP, modified NFL and NFLE, are briefly reviewed. The algorithm ONNFLE is presented to obtain the orthogonal projection matrix in Section 3. In Section 4, two experiments – face recognition and gender classification – are presented to show the effectiveness of the proposed method. Finally, conclusions are given in Section 5.
2. Eigenspace projection methods
Given N training samples
2.1. Locally preserving projection algorithm
Locally preserving projection (LPP) [11] is a popular and effective manifold learning algorithm for preserving the manifold structure of samples. The transformation matrix

The matrix
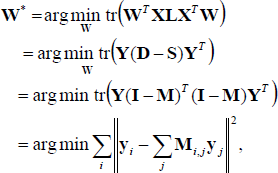
in which
2.2. Modified nearest feature line method
Li showed the discriminative power of nearest linear combination (NLC) in face classification [26]. Generally, the NLC algorithm generates virtual prototypes for matching using straight lines passing through prototype pairs. The capacity of prototype representation is increased because of infinite virtual prototypes. However, two problems – extrapolation and interpolation errors – exist for the NLC algorithm, as shown in Fig. 1. Consider two feature line points L2,3 and L45 generated from two prototype pairs (x2, x3) and (x4, x5), respectively. Points f2,3(x1) and f4,5(x1) are two projection points of lines L2,3 and L4,5 for a query point x1. From Fig. 1, it is clear that point x1 is close to points x2 and x3, but far away from points x4 and x5. However, the distance ‖x1 – f4,5(x1)‖ for line L4,5 is smaller than that for line L2,3 – i.e., ‖x1 – f2,3(x1)‖. The discriminant vector for line L4,5 to point x1 was selected rather than the other one. In addition, a great deal of computational time was needed due to the vast number of feature lines in the classification phase-i.e., C2N–1 possible lines.

(a) An extrapolation error and (b) an interpolation error.
A local nearest neighbour classifier (LNNC) [27] was designed to solve the extrapolation inaccuracy problem of the NLC algorithm. The feature lines passing through the nearest two prototypes of a probe were chosen for matching. Both the extrapolation inaccuracy and high computation problems were mitigated. However, the proposed method decreased the classification ability of the NLC-based classifier. A rectified nearest feature line segment (RNFLS) [28] algorithm – another modified version – was proposed to remedy both extrapolation and interpolation inaccuracy. Line segments trespassing on the territory of different classes were removed. The specified subspace for a class was constructed from the satisfied line segments. However, RNFLS requires high computation because a vast number of segments must be checked. The NLC, LNNC and RNFLS algorithms check the possible feature lines in the classification phase, which is an impractical strategy for many systems. In the NFLE algorithm [23], the NLC strategy is performed in the training phase rather than in the classification phase. The point-to-line distance metric is embedded into the transformation matrix. As shown in [23], not only is the matching time reduced but so too is classification performance improved.
2.3. Nearest feature line embedding
The NFLE algorithm is a new linear transformation method for face recognition. The point-to-line (p-2-l) strategy originated from the NLC approach [26]. The class scatter using the p-2-l strategy is represented as a Laplacian matrix, defined as follows:
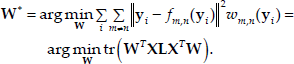
Here, point f(
Though the p-2-l strategy was successfully adopted in the training phase instead of the classification phase for the NFL-based classifier, some drawbacks remained and limited its performance. Three problems are: (1) extrapolation/interpolation inaccuracy: NFSE may not preserve the locality precisely when prototypes are far away from the probes. Thus, the discriminant vector from point x1 to feature line L4,5 was selected instead of that from point x1 to line L2,3, as shown in Fig. 1; (2) high computation complexity: a large number of feature lines are generated when the number of training samples N is large; and (3) non-orthogonal bases: non-orthogonal eigenvectors are generated from the NFLE algorithm, which does not reconstruct the original images and the intrinsic structure properly.
3. Orthogonal nearest neighbour feature line embedding
In this section, an algorithm – Orthogonal Nearest Neighbour Feature Line Embedding (ONNFLE) – is proposed. Three problems – extrapolation/interpolation inaccuracy, high computational complexity and non-orthogonal bases – are all considered as having more discriminant power when obtaining the transformation.
3.1 Nearest neighbour feature line embedding (NNFLE)
In order to overcome the extrapolation and interpolation inaccuracy, the feature lines for a query point were generated from the K nearest neighbourhood prototypes. More specifically, when two points
The discriminant vector The within-class scatter
The between-class scatter

And

The proposed algorithm is a simple and effective method for alleviating extrapolation and interpolation errors. In addition, the scatter matrices were also represented as a Laplacian matrix. The complexity of NNFL was more efficient than that of NFL. Consider N training samples, C2N–1 possible feature lines generated and a distance of C2N–1 calculated for a specified point. The K1 nearest feature lines were chosen from all possible lines in order to calculate the class scatter. The time complexity was O(N2) for line generation and O(2N2 log N) for distance sorting. At the same time, when the k nearest prototypes were chosen for line generation, where k « N, the time complexity for selecting the K1 nearest feature lines was O(k2) + O(2k2 logk). Extra overhead O(N logN) was needed for finding the k nearest prototypes. When N was large, the traditional method needed more time to calculate the class scatter.
3.2 Orthogonal nearest neighbour feature line embedding (ONNFLE)
According to the consequences of [29], non-orthogonal basis functions make it difficult to reconstruct the original data. In addition, orthogonal basis functions have more locality preserving power than non-orthogonal ones. The proposed ONNFLE method was modified from the NFLE approach in which the within-class scatter

The derivation of orthogonal bases is very similar to that in [29]. The optimization in Eq. (6) is equivalent to maximizing
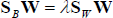
Vector
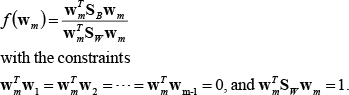
Eq. (8) was formulated using the Lagrange multipliers to include all constraints:

The parameters α1,α2,…,αm–1, λ and
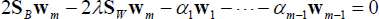
Next, Eq. (11) was obtained by multiplying the left side of Eq. (10) with a term

m – 1 equations were obtained next by successively multiplying the left side of Eq. (10) with m – 1 terms
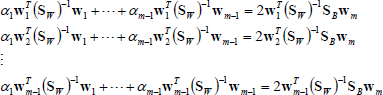

Here,

Third, the left side of Eq. (10) is multiplied by a term (

Parameter α(m–1) was substituted into Eq. (14) as follows:

From Eq. (15), when the parameter λ in Eq. (11) was maximized, the eigenvector
4. Experimental results
In this section, the experimental results of face recognition and gender classification are presented to show the effectiveness of the proposed NNFLE and ONNFLE methods. Besides this, they are compared with four state-of-the-art methods. The algorithms were evaluated using three public face databases: the dataset CMU [30] for face recognition and the datasets XM2VTS [31] and Max-Planck [32][33] for gender classification. The performance was also evaluated according to the ROC curves for face recognition and the accuracy rates for gender classification.
4.1. Face recognition
The CMU [30] database was composed of 68 people and 170 images per individual with PIE variations for evaluation. Four state-of-the-art methods – LPP [11], orthogonal LPP [29], NFLE [23] and orthogonal NFLE – were implemented for comparison. In the experiments, several images were randomly selected from the data sets for training while the others were used for testing. The face-only images (sized 32-by-32 pixels) were cropped from the original ones to eliminate the influence of hair and background. In addition, the projection matrix
The recognition performance on the CMU database. (%)


The recognition rates of various algorithms for various training samples.
4.2 Gender classification
For gender classification, two face datasets were used for evaluation. The dataset XM2VTS [31] was composed of 295 people (viz., 153 males and 142 females) and 12 images per individual with various expressions. As with the experiments for face recognition, the four state-of-the-art methods were implemented for comparison. In the experimental configurations, the data set was separated into two parts: Tn for training and Pm for testing. Sixty images (30 males and 30 females) and eighty images (40 males and 40 females) were randomly selected from the data set for training. The other 3480 images (1806 males and 1674 females) and 3460 images (1796 males and 1664 females) were used for testing. The NN matching strategy was adopted for matching the testing samples. The average rates were obtained by running the algorithms ten times. The highest recognition rates and their corresponding reduced dimensions for various algorithms are tabulated in Table 2. The proposed ONNFLE method outperformed the other algorithms both in the 60 and the 80 training samples. The NN strategy preserved more of the local topological structure than the other algorithms. In addition, the orthogonal bases reconstructed the images better than the non-orthogonal bases.
The performance of gender classification on the database XM2VTS. (%)

Secondly, the data set Max-Planck [32][33] was composed from the data for 200 human face images generated from laser scanning heads without any hair. 100 male and 100 female face images were used for gender classification. The recognition rates were directly compared with the results in [20] which were generated from seven algorithms: Weighted PGA, Supervised Weighted PGA, Supervised PGA, Standard PGA, Real AdaBoost, Gentle AdaBoost and Modest AdaBoost. The frontal images (sized 142-by-124 pixels) were cropped from the original ones in [20]. 160 samples and the remaining 40 samples were used for training and testing, respectively. The classification results using the seven algorithms in [20] are listed in Table 3. In our experiments, smaller images (sized 43-by-37) pixels were cropped to illustrate the robustness of the proposed method. In addition, it was evaluated by fewer training samples (100 images) and more testing samples (100 images). The algorithm was run ten times so as to obtain the average rates. Due to the S3 problem, PCA projection was first executed for dimension reduction in the proposed method. The experimental results tabulated in Table 3 show the robustness of the proposed method. The reduced dimensions are listed in the parentheses in Table 3. More restricted conditions (i.e., fewer training samples and more testing samples with a smaller image size) were adopted in this experiment. Table 3 shows that the proposed ONNFLE method outperformed the other algorithms in more restricted conditions.
The gender classification performance on the Max-Planck database.

5. Conclusions
In this study, a nearest neighbour selection strategy was adopted through the ONNFLE method to alleviate extrapolation and interpolation inaccuracies. In addition, high computational complexity was reduced by using the NN selection strategy. The projection transformation was obtained from orthogonal bases with more discriminating powers in the feature spaces. According to the experimental results of both face recognition and gender classification, the ONNFLE algorithm outperformed the other state-of-the-art methods.