
Abstract
Facial expression is one of the major cues for emotional communications between humans and robots. In this paper, we present emotional human robot interaction techniques using facial expressions combined with an exploration of other useful concepts, such as face pose and hand gesture. For the efficient recognition of facial expressions, it is important to understand the positions of facial feature points. To do this, our technique estimates the 3D positions of each feature point by constructing 3D face models fitted on the user. To construct the 3D face models, we first construct an Active Appearance Model (AAM) for variations of the facial expression. Next, we estimate depth information at each feature point from frontal- and side-view images. By combining the estimated depth information with AAM, the 3D face model is fitted on the user according to the various 3D transformations of each feature point. Self-occlusions due to the 3D pose variation are also processed by the region weighting function on the normalized face at each frame. The recognized facial expressions - such as happiness, sadness, fear and anger - are used to change the colours of foreground and background objects in the robot displays, as well as other robot responses. The proposed method displays desirable results in viewing comics with the entertainment robots in our experiments.
1. Introduction
Currently, various types of robots - such as intelligent service robots, entertainment robots, etc. - are in various stages of development. One of the key issues for these robots is human-robot interaction (HRI). For successful HRI, it is desirable for a robot to recognize and interact with the user's facial expressions and pose, as well as their gestures and voice. For instance, this applies to entertainment robots: a new type of media machine with the ability to transfer various contents to audiences. Children can read and hear fairy tales, comics and sing songs through a robot. However, almost all methods for HRI are developed for controlling robots, not for interacting with them. For natural communications between robots and humans, it is necessary for the robot to be able to respond according to the user's emotional state [1]. In general, the user may feel more satisfied with and friendly towards the robot when it responds in parallel with the user's emotion.

Face pose, facial expression and hand gesture-based human robot interaction
Facial expression is one of the most important means of interaction in using emotions [1, 2, 3]. To recognize the facial expressions of the input face, it is important for the robot to get an accurate reading of the positions of facial feature points, such as the nose, mouse, eyes and eyebrows, since the locations of the facial feature points are largely varied according to the facial expression. To define these feature points, some methods [2, 3] detect skin regions and extract feature points by searching for minima in the topographic grey level relief. More recently, some approaches [4, 5] have used face models - such as the Active Appearance Model (AAM) [6] - for real-time feature extraction. However, almost all of the proposed methods have the limitation of requiring a frontal view for facial input, which ignores the 3D transformations of each feature point. For accurate feature point extraction and natural HRI, the 3D positions of feature points rather than their 2D positions should be considered.
To acquire the 3D positions of feature points, one method is to directly use the 3D information of a face captured by special equipment, such as 3D scanners or depth cameras. The most popular such method is the 3D Morphable Model (3DMM) [7]. The 3DMM is the statistical representation of both the 3D shape and texture of a face. Sun and Yin [8] detected the eyes and the tip of a nose by using 3D information acquired from the 3dMD face imaging systems. Next, they estimated the 3D shape of the input face using information about the detected eyes and the tip of nose. However, since special and expensive cameras are necessary to acquire 3D information, this method cannot be easily used [9].
A more practical method for gaining 3D information is to extrapolate from 2D inputs rather than directly acquiring the 3D information. To acquire 3D information from 2D images, stereo vision [10] is generally used. Stereo vision uses two different images to estimate depth information. Chen and Wang [11] proposed the 3D AAM method combining the AAM and depth information estimated from input pair images using stereo imaging. Sung and Kim [12] proposed the 2D+3D AAM, which fits a face onto the View-based AAM [13] and reconstructs it as a 3D model through stereoscopic approximation. However, the method of combining the stereo images cannot estimate the 3D face model in real-time or near real-time, since it requires complex calculations to compute the depth information using the stereo method. In addition, the stereo for a face often results in inaccurate depth information since the facial region frequently has consistent skin colour (except for some small regions, such as the eyes, eyebrows, lips, etc.).
In this paper, we describe a new method for the recognition of facial expressions using an estimation of 3D feature points based on the AAM. In our approach, we acquire simple depth information from frontal and two-sided face views in the training phase, but we efficiently control 3D shape variations and self-occlusion by combining the acquired depth information with the AAM. With the extracted 3D facial feature points from the 3D face model, we approximate a Gaussian Mixture Model (GMM) where each Gaussian represents each different facial expression. By defining the probability density function of the input facial expression from the GMM, a robot is able to recognize the user's emotions and respond with appropriate actions.
As an example of emotional interaction with a robot, we present an efficient experiment in which a comic book is viewed on a robot's display, as shown in Figure 1. We designed a non-linear control for the viewing order of the comic book panels and in order to adjust the size and colour of the objects in the specified panel according to the user's emotional state. For control, we also use face pose and hand gesture recognition. The content provided is generated by a multi-layer structure that includes both a foreground and a background layer. Several objects are segmented in the foreground layer. According to the recognized emotions of the user, the objects in the panel can be modified in respect of colour, size, orientation or location. Based on the content of the comic book, the robot exhibits responses such as “move forward”, “move backward” or “make a circle”. As a result, a user can appreciate the comics in his or her own style.
The remainder of the paper is organized as follows. Section II describes the proposed facial expression recognition method. In Section III, we discuss face pose recognition. The hand gesture recognition method is presented in Section IV. In Section V, we show our content manipulation scheme for viewing comics. Section VI presents the experimental results of our proposed method.
2. Facial Expression Recognition
2.1. Active Appearance Model
The AAM represents a face by combining its shape and appearance. The shape and appearance are acquired from manually marked landmarks (facial feature points) on face images. The shapes used for the exercise are represented by a
The shape subspace is constructed by applying Principal Component Analysis (PCA) to the set of shape vectors which are aligned by the mean shape

To create the appearance subspace, each training image is warped in order to remove spurious texture variations due to shape differences. As a result, we can obtain shape-free images. The appearance of each image is represented as a vector in the same order and with a dimension corresponding to these shape-free images. The appearance subspace is constructed by applying PCA to the set of appearance vectors, centred on the mean appearance vector,


The AAM fitted onto four different facial expressions

The AAM variations for the first three AAM parameters
The AAM combines the shape model and the appearance model by applying PCA on the connected vector of the shape and appearance parameters:

where κ is the weight parameter for the shape calculations, allowing for the difference in units between the shape and the grey models of the appearance. We set this weight parameter as the ratio of the total intensity variations to the total shape variation in our experiments. q and c are n eigenvectors and AAM parameters, respectively. Figure 3 shows the variation results of the AAM for the first three AAM parameters
To fit the input face with the AAM, the transformation parameters are necessary. We assume that any arbitrary input face X can be generated by applying the similarity transformation
The AAM utilizes the parameter

To estimate the parameter

where
2.2. Depth Estimation
We calculate the depth information of each facial feature point by using a frontal and two side-view faces, as shown in Figure 4. Although this method shows lower accuracy than some other recently proposed methods, it is sufficiently accurate to estimate the 3D face model of the input face with the aid of the AAM.
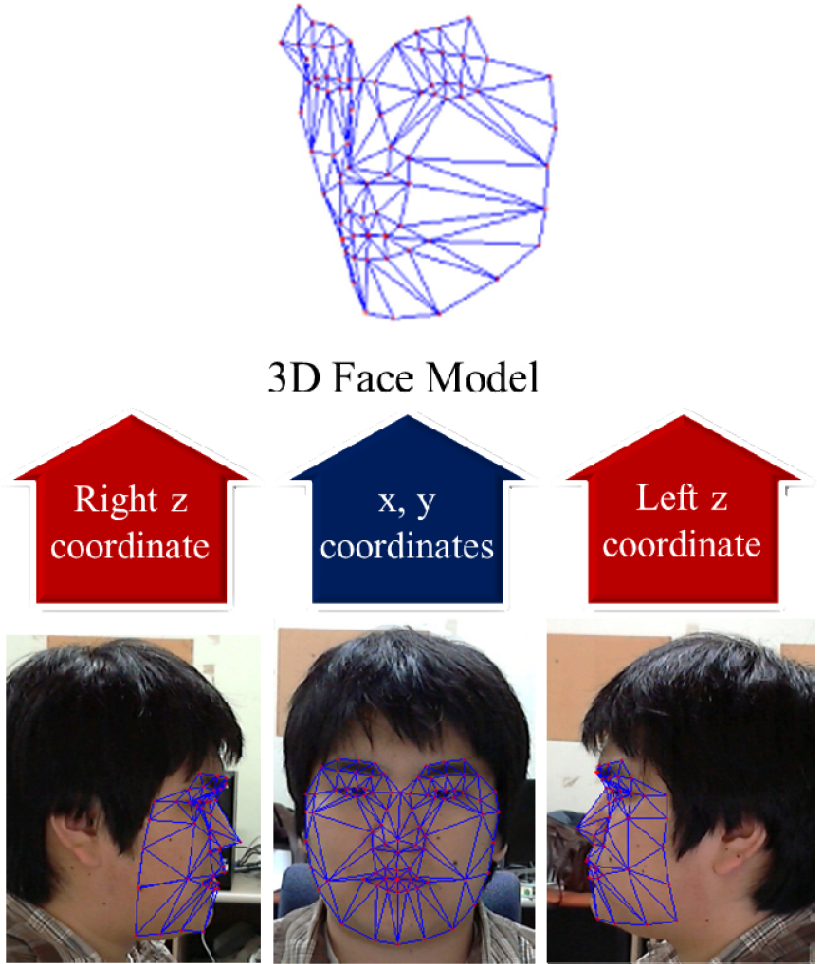
The estimation of the 3D face model for a frontal and two side-view faces
To estimate the depth information of a face, we manually marked landmarks on a frontal and two side-view face images, as shown in Figure 4. The frontal face provides the x and y locations and the side faces provide depth locations. However, the images captured by the cameras show the face at differing scales due to variations in the distance between the camera and the captured face. To take account of this scale difference, we use Procrustes Analysis [16] to minimize the shape difference error as follows:

where
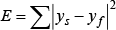
where
2.3. 3D Face Model Estimation
To estimate the 3D face model according to the 3D transformation of the input face, the transformation parameter

If the AAM is learned with 3D shapes, as with [11], the Jacobian representation of the variations in the appearance with respect to the 3D rotation
Figure 5 shows the overview of the proposed 3D face model estimation. We first fit the input face using the AAM in the same way as with the typical AAM method. This updates the 2D parameters. Next, we fit the input face again using the 3D face model to update the 3D parameters. We repeatedly apply these two steps until convergence is achieved with respect to parameter
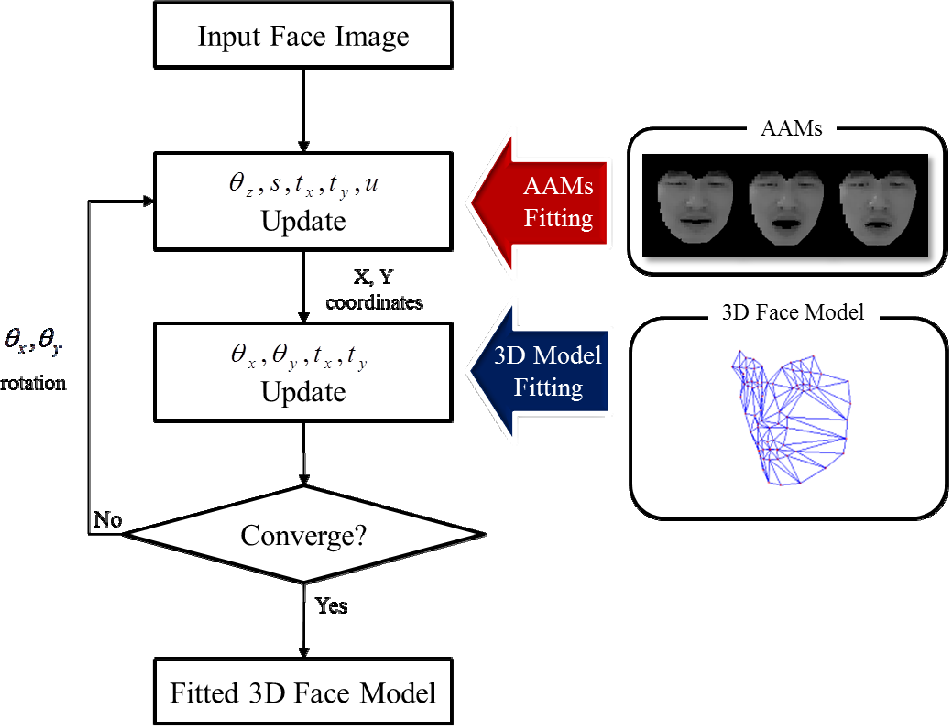
Overview of the estimation method for the 3D face model fitted on the input face
To fit the AAM to the input face, we estimate the parameter

A first-order Taylor expansion of Equation (9) gives the following Equation (10):
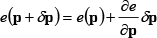
For the current residual r,

Since the typical AAM fits the input face with the parameters in Equation (4), it is hard to deal with 3D pose variations when compared with the construction of the 3D face model with the parameters in (8) in our method. We update them by using Equation (11).
The face that fits with a typical AAM defines the x, y coordinates of the model. With this fitting result, we update the rotation parameters
Although the 3D face fitting with the parameters in (8) deals with the variations of 3D pose and facial expression, this does not provide sufficiently accurate fitting results when the input face pose is far from its frontal position due to self-occlusion. For this reason, further processing for self-occlusion is essential.
We use the direction of the mesh construction to describe its occlusion in relation to the occurrence of the x and y rotations. The direction of the three points in the mesh is reversed when it is occluded. Let us consider the case in Figure 6(a), in which the red mesh is constructed by A-B-C. After the y rotation of the face in the case of Figure 6(b) is applied, the red mesh is constructed by C-B-A due to the occlusion which occurs when the mesh is at the back of the face. Therefore, we check the directions of all of the mesh construction parameters and we assign a weight of zero to the mesh which has the reverse direction. A zero weight value means that the mesh is replaced by the mean appearance. The direction of the mesh construction can be decided efficiently by the inner-product between the vectors.
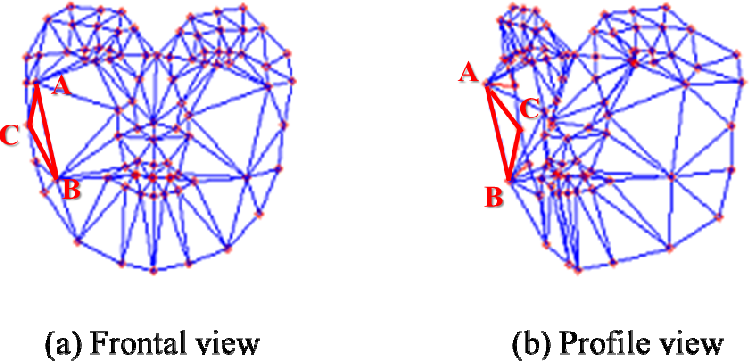
The change of direction of the mesh construction according to 3D pose variation
2.4. Facial Expression Recognition
Assuming that we have K states of emotion resulting from recognized facial expressions, such as happiness, sadness, fear and anger, we represent the facial expression appearance manifold by a set of simple linear K sub-manifolds, as constructed by the parameters of 3D AAM in the previous section. The facial expression appearance is represented as an approximated GMM where each Gaussian represents a different facial expression. We can define the probability density function of the input facial expression from the approximated GMM as:

where

where

3. Face Pose Recognition
The interaction with robots using the commands of face poses is very useful and helps users to more easily understand their potential for interaction. As we have approximated the facial expression manifold in a linear way, we are also able to approximate the face pose manifold using the approximated GMM that each Gaussian represents with respect to each different face pose. That is, we can use Eq. (12) for the probability density function of the input face pose derived from the approximated GMM. The likelihood of an input image x that has N dimensions is given by:
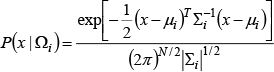
From [15, 16], we can approximate the ith Gaussian component

where M and

The parameter ρ in Equation (16) can be represented as
Finally, we can linearly approximate Eq. (12) as:
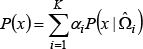
When the input face image is similar to the ith face pose, the weight parameter

4. Hand Gesture Recognition
The user executes a small set of commands on the robots using hand gestures. In our system, the user manipulates the object's size and position. To recognize the user's hand gestures, we first extract skin-like regions based on skin colour statistics and then classify the skin-like regions with respect to face and hand regions. Face candidate regions are detected using the Viola and Jones method [17]. From skin-like regions, we delete face candidates and eliminate false hand candidates using size constraint values.
Among the hand candidate regions, it is necessary to extract hand regions by removing forearm regions. To do this, we compute a skeleton of the hand candidate regions and then draw a circle to detect the hand region along the skeleton. The circle will be small at the wrist point and large in the hand region. When we find the largest circle along the skeleton - as in Figure 7 - the centre of the circle is labelled as the COG of the hand.
From the COG, we detect the farthest and the nearest points in the hand. Usually, the farthest point is the tip of the longest active finger. To count the number of active fingers, we draw a circle from the COG, as in [18]. The radius is 0.7 of the farthest distance, which is the distance from the COG to the farthest point. Following this, we can recognize the intersection area for counting the active fingers of the hand. The fist shape of the hand is detected by comparing the nearest and farthest distances from the COG. If two-times the shortest distance is greater than the farthest distance, the shape of the hand will be a fist. We can thus classify hand gestures as either a fist or an open palm, with a further distinction made for the number of active fingers. These classifications are used for the control of object manipulation in the activated panel of the comic book [19].

COG of the hand
In our system, zooming in and out of the panel is controlled by counting the number of active fingers. Object translation and rotation are also controlled by the number of active fingers.
5. Contents Manipulation
To control the viewing style of the comics and manipulate contents at will, the user will utilize face pose, facial expression and hand gestures. For various manipulations, object-based multi-layer comic contents were created. The scene in the panel of the comics is represented by the scene graph. Each leaf node in the scene graph contains information about the location, rotation and scale of the object.
The viewing style is determined by the face pose and hand gesture recognition results. Only one panel is activated while the other panels are deactivated. The activation order of panels in the comic book is one of four directions, i.e., up, down, right or left. Hand gesture recognition results control the activated panel with respect to “zoom in” or “zoom out” using the user's left fist and the open right hand with five fingers recognized. When the panel is zoomed in, the robot moves towards to the user by about 20cm, following which the user can translate the object into one of the four directions by using the motion of the index finger. Scaling is performed by indicating three or four. Rotation is performed using two fists. When the object is rotated, the robot also makes a circle.
Based on the facial expression, we also manipulate the colour of the objects in the comics. To analyse emotional characteristics in the colour feature, we performed an empirical study of the images. The statistical baseline for the four emotions was manually determined by surveying 10 students with regard to 300 images. If the image is labelled with the same emotion by at least 7 of the 10 students, we assign the image as having one of four emotions. From these labelled images, we extract emotion-related colour features in the HSV colour space. Figure 8 shows our hue and value template. For example, one main sector covers an area around 60 degrees for the happiness hue template. In the value template, the upper arc contrast is selected for “happiness” and the lower arc contrast is selected for “fear, sadness and anger.”

(a) Hue template, (b) Brightness template: happiness-upper arc contrast, sadness, fear, anger-lower arc contrast
To transform the pixel values according to the emotions, we use hue templates [20, 21]. The new hue value

where
To perform brightness transformations, we use a value template, as in Figure 8(b). The brightness value transformation is performed by non-linear characteristics like:

The brightness value at pixel p is transformed by:

where γ is 2.0 for happiness, 0.4 for sadness, 0.5 for anger and 0.3 for fear, respectively.
6. Experimental Results
To evaluate the performance of the proposed method, we first evaluated the fitting result of the proposed 3D AAM, because the estimated positions of the facial feature points are important in recognizing the facial expressions of the input user. To do this, we compared our method with the typical AAM [6] learned from face images, including various facial expressions and the View-based AAM [13] learned from three distinct pose images with various facial expressions for each pose. For learning, we made training videos with nine volunteers. All of the videos have a 640×480 image size, 15 fps, are about 23 seconds in length and are taken by a web camera. The test video and training video were independently captured for each person. The training video includes variations between four facial expressions: expressionless, happiness, surprise and disgust, as shown in Figure 2, but do not include variations of scale or translation. However, the test video includes all such variations of facial expressions, scale and translation; all of the variation combinations were randomly changed. For training, we sampled the training videos at a ten-frame interval.
For the AAMs, we marked 86 landmarks using 35 training frontal faces per subject. The AAM trained by frontal faces is also used in our method. For the view-based AAM, the training faces are captured from three perspectives: −45, 0, 45 degrees of viewing. With each view, 35 training faces with various facial expressions are used.

Some results of the depth estimation (top: frontal face, middle: one side face, bottom: the estimated 3D face model)
To estimate the depth information for each person, we used frontal and two side-view faces. We marked landmarks on these three faces and constructed a simple 3D face model. Figure 9 shows some examples of the frontal and one sided faces used for estimation and the subsequently obtained 3D face results. As shown in Figure 9, our depth estimation is calculated from subjects who include various face shapes: lean-faced, round faces, etc. The estimated 3D face models using the proposed method did not have high accuracy. However, they do express the adaptive shape for each person and efficiently help our method by defining a relationship of fit between the input face and 3D face transformations.
We combined the estimated depth information with the AAM learned from frontal faces. From this combination, we fitted the input faces using the method explained in Figure 5. Figure 10 shows one of the fitting results on the training video, which includes frequent changes of 3D pose and facial expression. The graph in Figure 10 shows the errors that occur between the appearances of the input face and the model from Equation (9). When the method fits the input face correctly, we observe lower error values. However, higher error values are observed when the method does not have an accurate fitting result or else misses the input face. In the case of a typical AAM, it is not possible to fit the input faces when the input face is far from the frontals, because the AAM is learned from frontal faces. In Figure 10, the AAM attempts to fit the input faces unsuccessfully until the 190th frame, but not subsequently, because significant 3D pose variation has occurred. After the 190th frame, the AAMs missed all of the input faces due to non-correspondence in the scale and translation parameters of its model. The view-based AAM can fit on a wider selection of input faces than the AAM since it selects the adaptive pose model for the input face from the training data. However, and as shown around the 50th and 250th frames in Figure 10, this model provides unstable fitting results due to the difference between the poses of the input and the training. Although the fitted face model is similar to the input face, the pose difference leads to inaccurate fitting. As a result, these unstable fitting results have a higher rate of error than our method, which has accurate fitting results. It also missed the input faces after 305th frame due to the incorrectly selected pose model. Because of the wrong pose, this model misses all of the parameters, including those in Equation (4). By comparison, the proposed method fitted the input faces with the lowest rate of error and more accurate face models, as shown at the bottom of Figure 10. Our method does not require the choice of an adaptive pose model and does not include pose-varied face images in the training data. Nevertheless, our method had very accurate fitting results on input faces which have significant pose variations. In our method, the pose of the input face is estimated with reference to the results of the previous frame. Since our method calculates the Jacobian values for the 3D parameters at each frame, our fitting results are not dependent on the pose variations in the training data. Although our training data includes only frontal faces, our method provides accurate fitting results, even with respect to dramatic pose changes. Moreover, any error caused by appearance differences between frontal- and pose-varied views is decreased by means of the region weighting function proposed; thus, it continues to provide accurate results with a lower error rate, even where the input pose is more distant than the frontal view.
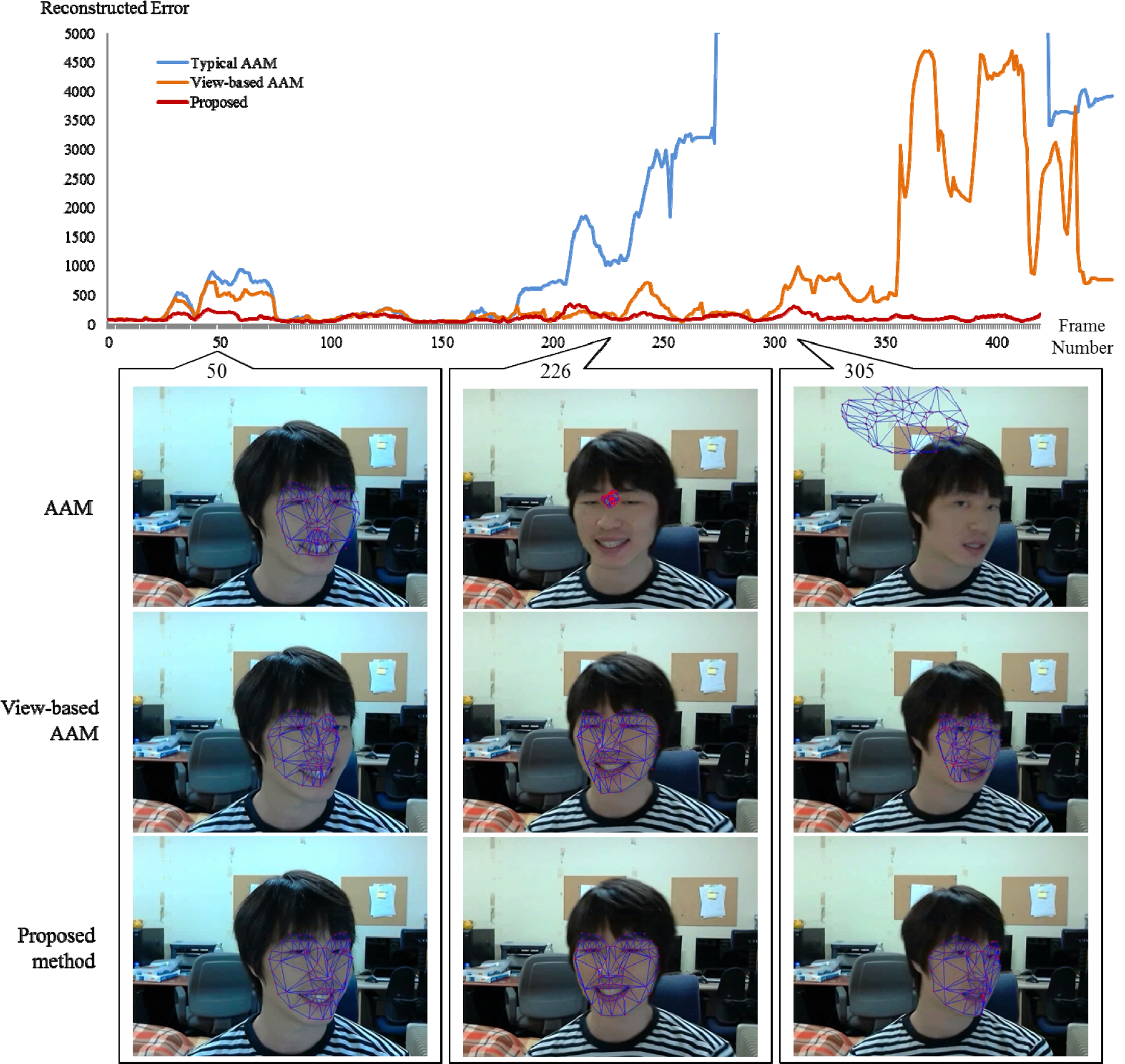
Comparison of face fitting results between our proposed method and other methods

Human Robot Interaction
Using the 3D facial feature points extracted from the fitted 3D face model, we designed an HRI interface on the viewing comic robot. Our human-robot interaction scheme is shown in Figure 11. The wheeled robot is equipped with a webcam, as in Figure 1. To interface with the designed robot, we used the recognition of the facial expression, face pose and hand gesture of the user. The input image is taken from the camera and, initially, skin-like regions are extracted. Next, we use morphological filters to filter out noise and holes for gesture recognition. Face detection and hand segmentation are executed from probable face and hand regions. A face candidate is detected from the grey image using Viola and Jones' method [17]. Subsequently, the face is recognized and a tracking process is executed for video-based face pose recognition. Figure 12 shows our strategy for controlling the viewing order by means of recognized face poses and hand gestures.

The viewing panel is changed using face poses. Objects are manipulated by hand gesture recognition.

Examples of hand gesture images
Pose Estimation Results
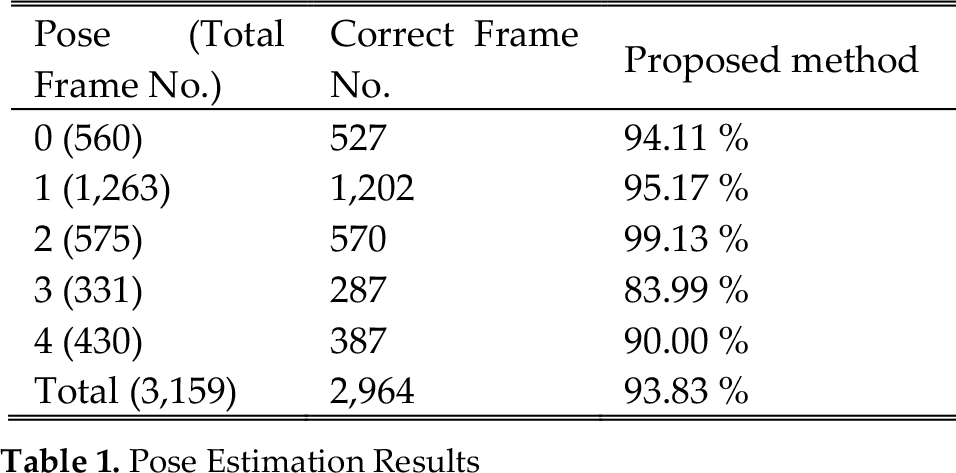
To control the viewing order using the face pose information, the user's face should first be detected and then recognized. Next, the face tracking process is executed for video-based face pose recognition. For face tracking, 80 sample windows with different sizes and orientations are created around the previous face position. Each sample window is converted to a 20 × 20 size window and skin regions are extracted. For the skin regions, the colour histogram is equalized. Afterwards, the sample windows are compared with the identified person's face pose sub-manifold. At this time, the face pose sub-manifold is the face pose of the previous frame. If the minimal distance between the sample window and the sub-manifold is larger than the threshold value, we conclude that the face tracked is incorrect, and a new face detection process is initiated. We evaluated our face pose recognition method on 10 sequences captured from 6 subjects. Table I shows our results.

Re-coloured image. (a) happiness, (b) sadness, (c) fear and (d) anger.

Facial expression-based re-colouring
Hand gesture recognition is also one of the important factors in controlling our viewing system. To evaluate the performance of the gesture recognition, we generated 120 hand gesture images captured at in-door and out-door environments, as shown in Figure 13. We evaluated hand gesture recognition rates between our proposed method and that of Malima [18]. Table 3 shows the recognition results. Our method demonstrated more accurate classified results from the various input hand gesture images than Malima's.
To evaluate the performance of the facial expression recognition system, we labelled its facial expression on the training set used for the face fitting evaluation. The facial expressions are classified into five categories: normal, sadness, anger, fear and happiness. The test sequences used for this evaluation have lengths of about 30 seconds and 30fps. Our system classified each facial expression at each frame and compared our results with the ground-truth data. Table 2 shows the recognition results for each emotion.
Facial Expression Recognition Results

Hand Gesture Recognition Results

For emotional interaction with our robot, we performed the content re-colouring method based on the user's emotional states. To do this, we transform the hue and brightness value using Eq. (21) and (22). The resulting images are shown in Figure 14. After obtaining the images, we carry out a survey of the perception of emotion for each image obtained from our emotion-based contents re-colouring method. 87% of the students show a strong preference for our re-colouring images. Figure 15 also shows one of the re-colouring examples based on the user's emotion, which is recognized by the facial expression of the user. By the manipulation of the colour of the contents, the user has more fun in viewing the contents and interacting with the robot.
7. Conclusions
In this paper, we proposed an emotional interaction method with a robotic interface for viewing comic books. To acquire accurate facial feature points, we constructed a 3D AAM which combines the AAM with the estimated depth information. From the fitted 3D face model, we extracted 3D facial feature points to accurately recognize the facial expressions of the user. The facial expression of the user is estimated by computing a minimal distance between the given distance and the facial expression sub-manifold. Our proposed face pose and hand gesture recognition method also displays good performance in controlling the viewing order of the comics. By re-colouring contents based on the user's emotion from a recognized facial expression, we could provide an intuitive HRI interface which provides more enjoyment for the user in viewing visual materials. It is worth noting that our proposed method provides various new and promising viewing methods for comics with a robotic interface.
Footnotes
8. Acknowledgments
This research is supported by the Basic Science Research Program through the National Research Foundation (NRF) funded by the Ministry of Education, Science and Technology (2010-0024641).