
Abstract
As intelligent mobile devices become more popular, security threats targeting them are increasing. The resource constraints of mobile devices, such as battery life and computing power, however, make it harder to handle such threats effectively. The existing physical and behavioural biometric identification methods - looked upon as good alternatives - are unsuitable for the current mobile environment. This paper proposes a specially designed biometric identification method for intelligent mobile devices by analysing the user's input patterns, such as a finger's touch duration, pressure level and the touching width of the finger on the touch screen. We collected the input pattern data of individuals to empirically test our method. Our testing results show that this method effectively identifies users with near a 100% rate of accuracy.
1. Introduction
The use of intelligent mobile devices such as Smartphones is becoming more popular. According to an industry figure, the number of global Smartphone users in 2010 was 326.5 million, an increase of about 15 times since 2005, and it is forecast to reach 766.1 million in 2012 [1]. Mobile devices are used for many services closely linked to people's lives (e.g. banking, education and shopping), as well as basic functions, such as web surfing and checking e-mail. However, this popularity causes mobile devices to become attractive targets for attackers. McAfee's threat report revealed that 10 million new mobile malwares were found in 2010 [2]. Such malware causes serious damage to users, such as the leakage of personal identification information. Mobile devices have a higher risk of malware infection than PCs because there are more infection routes, such as Multimedia Messaging Service (MMS), Bluetooth and PC-sync [3]. In addition, the vulnerable points of mobile platforms, such as iOS and Android, are spreading so rapidly that the number of them in the second quarter of 2011 increased by 43% from last year [4].
Despite these security threats, mobile devices have trouble defending against mobile malware and vulnerabilities, unlike PCs, due to their restricted resources [5]. Also, there is a possibility that the current mobile OS working on intelligent mobile devices can be adopted in many traditional embedded or industrial control systems. So, the vulnerability existing in mobile devices can affect embedded machines and industrial control systems when these mobile OSs are broadly adopted.
So far, limitations on battery life, computing power and the availability of network bandwidth reduce the effectiveness of traditional countermeasures working in PCs or server platforms. The countermeasures, based on anti-virus programs and security patches generally, do not work well on mobile devices or industrial control systems. It is difficult for users to apply the latest antivirus software's signature files and OS security patch files from security vendors in a timely manner. As previously mentioned, mobile devices are used for a service which uses sensitive personal or financial information, such as mobile banking. In this case, there are high risks of leaking personal identification information to attackers, since mobile devices have trouble defending against mobile malware and vulnerabilities. Also, when a mobile OS is used on an embedded system or an industrial control system, there are high risks leading to the malfunction of those machines. In many cases, such industrial control systems are running in an environment where security patches are not easily applicable.
Thus, biometric identification methods are highlighted as effective security measures for intelligent mobile devices [6]. Biometrics can be excellent alternatives to common identification methods, such as password-based authentication, because they cannot be lost or stolen without trauma to the individual [7]. Mobile devices have a big edge in applying biometric identification methods because they are equipped with cameras, microphones and touch screens for scanning biometric information [8].
In this paper, we propose a novel biometric identification method for mobile devices. Unlike a PC, most mobile device users input with their fingers on a touch screen. In this case, input duration time, the touch pressure level and the touching width of the finger can be recognized as individual biometric characteristics. This unique input pattern can be used to identify an individual and distinguish users from attackers. Personal identification information, such as a password, can easily be leaked by mobile malware or other attacks. If an attacker possesses all the identification information of a specific user, he can perform illegal activities, such as an unauthorized access of the user's banking account. However, our method can check if the activity is done by the user or the attacker, because the input pattern of the attacker will differ from the pattern of the original user.
Our method has the following advantages over other biometric identification methods when implemented for mobile devices. First, it does not cause inconvenience for mobile users, because it does not require additional procedures, such as scanning fingerprints. Second, it can prevent spoofing attacks. Even if attackers get the input pattern data of users, they are unable to recognize the data for what it is, because it just consists of simple and variable numbers, which are not predictable. Third, implementation is easy, given that text-based data does not require much storage. Fourth, collecting input pattern data does not violate a user's private rights, because this method is not related to privacy infringement issues. Fifth, this method can be used for personal authentication methods in the middle of e-financial transactions. Also, this method can be applicable as a secondary authentication method for an industrial control system that is running an intelligent mobile OS.
We collected the input pattern data of each individual from a major mobile platform and tested how well it distinguished each user through learning and verification so as to prove the efficiency of our method. A Back Propagation Neural network (BPN), which uses a supervised learning method and feed-forward architecture was used as the pattern classification algorithm. We recognized that our method can distinguish between users with near a 100% probability and estimated that it can effectively identify users in a mobile environment. This experiment presents more enhanced results than our previous work [23].
The composition of this paper is as follows. Section 2 explains the biometric identification methods. Section 3 outlines the basic principles of our method. Section 4 details the design and realization plan. Section 5 explains the performance and efficiency of our method through tests. Section 6 summarizes this paper.
2. Biometric Identification Methods
2.1 Physical Biometric
Physical biometric identification methods are becoming popular with traditional identification methods to provide an extra level of security. Hand geometry is a very simple, relatively easy to use and inexpensive identification method. Using a built-in video camera to scan hand geometry, it looks at the shape of a hand in every direction. The dirt and stains on hands have little influence on performance, and the hand is easily guided into the correct position for scanning [9].
A fingerprint is popular for general security and computer access. It is the pattern of ridges and valleys on the surface of a fingertip [10]. The chance of two people having the same fingerprint is estimated as being less than one in a billion [11]. Biometric systems based on fingerprints are commonly embedded in systems, such as a laptop computer, and have become affordable for a large number of applications.
Iris recognition is an area of physical biometrics. The iris is a thin, circular structure in the eye, responsible for controlling the diameter and size of the pupils. It is easily visible from yards away, as the coloured disk behind the clear protective window of the cornea. The structure of the iris is unique - like a fingerprint - and it remains stable over decades of life. According to a survey, the probabilities of false acceptance and false rejection in iris recognition are approximately 1 in 131,000 [12].
However, these physical biometric identification methods have weaknesses. First, they require users to perform additional tasks for identification, such as scanning fingerprints and hand geometry, thereby inconveniencing users. Second, using these methods may also increase the risk of spoofing attacks, because attackers can recognize how identification is performed by the physical biometric data required. A variety of biometric spoofing attacks, such as forging fingerprints with gelatine, have been studied. It was recognized that the technique has a very high probability of bypassing physical biometric identification methods [13]. Third, physical biometric data, such as image and voice data, require huge storage capacity due to their large size. For example, if the number of users of mobile banking service reaches several thousands or millions, it has to store a prohibitively expensive amount of physical biometric data. Fourth, physical biometric data may infringe privacy. A corporation will need a user's consent to collect the physical biometric data, because it is private [14].
2.2 Behavioural Biometric
Behavioural biometric identification methods use unique behavioural characteristics, such as the method of signing names and keyboard typing rhythms for identification. These methods mostly need the process to enrol the reference of personal behavioural characteristics through several trainings; identification can be performed after references are registered successfully. The differences between physical and behavioural biometrics are important. Behavioural characteristics are generally more subject to deviation than physical ones. A high variability leads to a high identification error. For example, the fingerprint is almost the same, day in and day out; whereas a signature is relatively influenced by controllable actions and unintentional psychological factors [15]. Conversely, behavioural biometrics can be smaller and cheaper to implement than physical biometrics. Equipment to scan physical biometric data tends to be larger and more expensive. No one biometric method will serve every need due to these differences. Thus, appropriate biometric techniques need to be determined according to circumstances and operations.
A handwritten signature is a behavioural biometric technique. It uses various handwriting features, such as writing time, angle and distance. It normally has a very high accuracy rate in identifying genuine signatures [16]. However, signatures are a behavioural biometric that can easily be changed by the physical and emotional condition of users. It has already been proven that professional forgers can reproduce the original user's signatures to fool identification systems [17].
Keystroke dynamics are another behavioural biometric identification method. When a user types on a keyboard, the latency between successive keystrokes, keystroke duration and finger placement can be used to construct a unique feature for that user [18]. This method guarantees the user's convenience, is easy to deploy without high cost, is difficult for an attacker to forge, and there is no infringement of privacy. A recent study identified users with keystroke dynamics on mobile devices. However, this method has a relatively high error rate (about 4 ∼ 21% per person) - too high to use in a mobile environment [19]. The keystroke pattern will change whenever the input values change. This method is just for old phones (so-called feature phones), not for Smartphones. Mouse dynamics based on selected mouse movement characteristics is a similar method as that of keystroke dynamics. This method has a relatively low average error rate (2.46%) compared to keystroke dynamics [20]. However, a user's error rate reaches about 19% in the experiment, and this method did not prove to be efficient in the identification of mobile devices.
3. Overview of the Approach
Mobile devices, like Smartphones, mostly adopt the touch screen as the input medium, because they are smaller than PCs and it is difficult to use a separate keyboard and mouse. Thus, users use their fingers to input on mobile devices. A pattern is created from the input duration, the pressure level and the touching width of the finger, when using fingers as an input on the touch screen. These input patterns can be recognized as a kind of biometric data, because they are based on the user's physical and behavioural characteristics.
Users continually touch the buttons or a keyboard widget with fingers on touch screen to input text or select items in mobile applications. In addition, they scroll several times to move the screen. A great deal of input pattern data is collected during these actions, and this data is expected to be able to identify users. Mobile devices are not trusted devices, and it is hard to completely protect personal identification information like passwords. However, our method can check if a mobile user is the usual one or else an illegal one even when all the personal identification information of the user is leaked to the attacker by mobile malware.
Figure 1 depicts the architecture of our method, which consists of preparation, identification and countermeasure. The preparation stage defines a user's input pattern profile for identification in mobile devices. It can be divided into a pattern analyser, a learning engine and pattern profiling. The input pattern data is collected whenever an input is made when using a mobile application. The data is transmitted to the server for learning. In the preparation stage, the pattern analyser analyses the collected input pattern data and selects the primary input pattern data to display archetypical personal characteristics. Next, the learning engine goes over the selected input pattern data several times to learn the unique characteristics of each individual. In the pattern profiling step, a reference value to identify a user is set up. The preparation stage is better performed in the server than in a mobile device, which has restricted resources, because a specific level of calculation is required to learn a user's input pattern. This is also useful, given that it can prevent the fabrication or alteration of data by attackers up to a certain point, because the input pattern data is not located on mobile devices. The identification stage, which is performed after finishing the preparation stage, checks to see if a user is normal to approve, comparing the input pattern data created using a mobile application with the pre-learned user's input pattern profile. If the input pattern data to be requested significantly differs from the profile of the normal user over a specific degree, the user can be recognized as suspicious, and in this case, the countermeasure is performed without approving the use of the application.
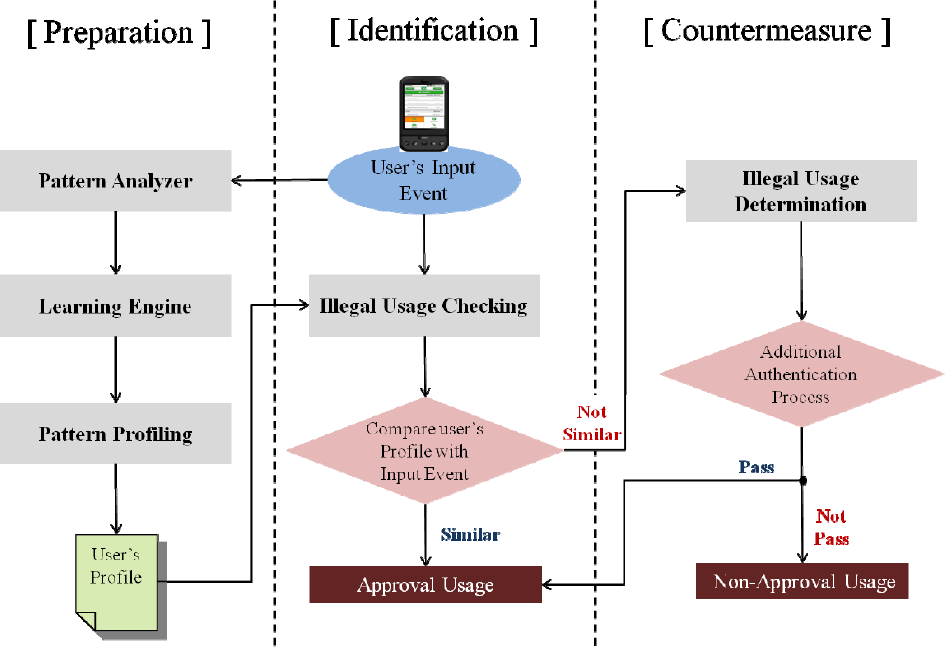
The architecture of our method consists of preparation, identification and countermeasure
The countermeasure stage performs an additional authentication process against the suspicious usage during the identification stage. Most users input consistently in mobile devices. The normal user is rarely checked as suspicious due to an unexpected situation, such as using the application in a moving car. Therefore, it is desirable to block the usage of the application after making sure it is an illegal usage by attackers, rather than immediately blocking the usage after the non-standard input is checked, even if it is an extremely low possibility. In this paper, we exclude detailed methods for the countermeasure from our discussion.
4. Design and Implementation
4.1 Collection of the input pattern data
Input methods in mobile devices are composed of a series of touch and several scroll-wheel actions. The touch is the input to press mobile widgets, such as buttons with fingers, and consists of input pattern data regarding input duration, the pressure level and the touching width of the finger on the touch screen.
The scroll-wheel action is the input to move the touch screen with a finger pressed and dragging on the screen, and consists of input pattern data about the start and finish position of the scroll, the scroll speed and length, in addition to the touch input pattern data. The hands and fingers used for the input influence the values of each piece of the input pattern data.
Table 1 summarizes the input pattern data regarding touch and the scroll-wheel. As Table 1 shows, many factors influence the input pattern, so there is little possibility of the existence of two users with a similar input pattern. Also, given that physical characteristics, such as the touching width of the finger and behaviour characteristics, are combined in the input pattern data, it is estimated that our method can decrease the identification error rate compared with other methods that only use behavioural characteristics, such as keystroke dynamics.
The input pattern data regarding touch and the scroll-wheel

The collection of a user's input pattern data can be easily realized by adding a separate module to mobile applications. Mobile platforms, such as iOS and Android, provide an Application Program Interface (API) that can collect the input pattern data. Figure 2 shows the form of a diagram in which the input pattern data is collected in mobile devices. Once an input event occurs in a mobile application, an event handler is immediately invoked and it distinguishes between touch and scroll-wheel actions during its procedure. Next, the event handler invokes a function to collect input pattern data against each input and the collected data is transmitted to the server for the preparation stage. In the case of Android, MotionEvent and Gesture classes provide functions to collect input pattern data. Input duration, the pressure level, the touching width of the finger and the start and finish coordinates can be collected by invoking the functions of getEventTime(), getPressure(), getSize(), getX(), and getY() of each MotionEvent class. Scroll length can be collected using the function getLength() of the Gesture class. Scroll-wheel speed can be calculated by the method that divides scroll length by time.

The form of a diagram in which the input pattern data is collected in mobile devices
4.2 Analysing, learning, and identification
Figure 3 shows the analysis and learning procedure. Once multiple input pattern data is collected for learning, the Standard Deviation (SD) regarding each input pattern data type is calculated. Input pattern data types that have a relatively large SD cannot be regarded as data for showing individual characteristics because the variability of data values is too large whenever an input is made. Therefore, input pattern data types with a large SD cannot be the main factor in identifying a user. It is desirable that these data types are removed from learning factors so as to increase the accuracy and effectiveness of learning.
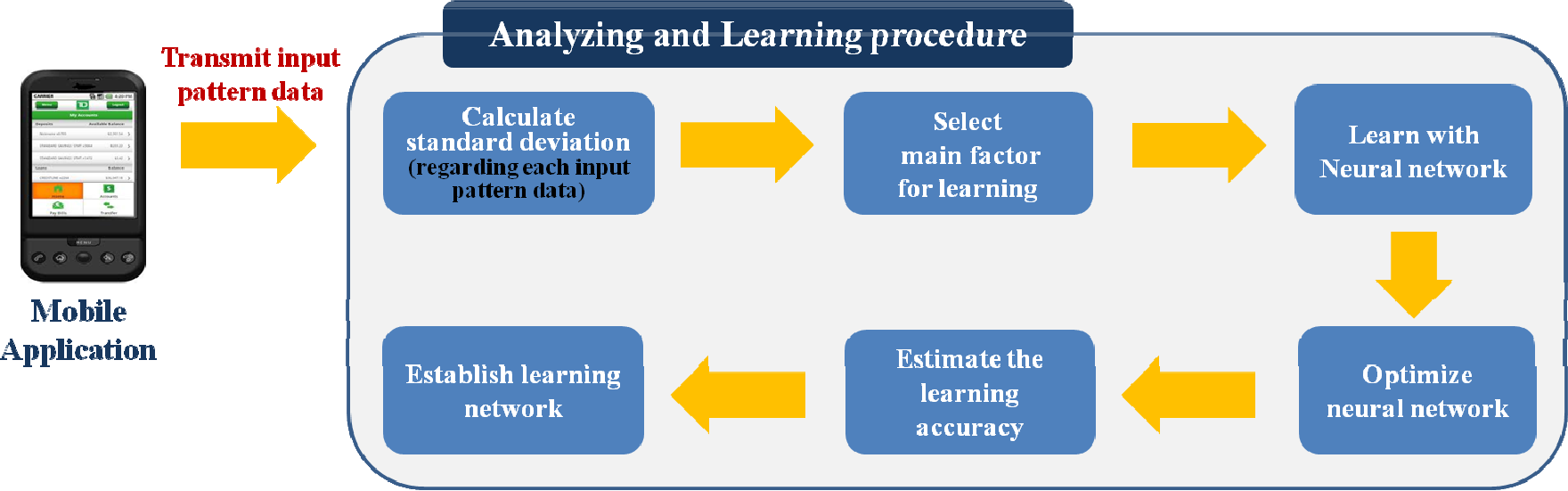
The analysis and learning procedure
Learning starts after input pattern data types for learning are selected. We use a BPN as the learning algorithm. BPN is a pattern recognition method that uses the Least Squares Method (LSM). It is the most used of many neural network algorithms [21]. The biggest reason for offering BPN as a learning algorithm is that its fault tolerance capability is excellent [22]. In the case of input pattern data, noise which differs from previous inputs can be rarely included in a specific input, because it is difficult for a human to input consistently like machines. However, BPN has the strength of drawing the desired learning results and decreasing learning errors compared with other pattern recognition algorithms.
Figure 4 shows a three-layered BPN structure for learning input pattern data. If a certain user's input pattern data is given, this signal is changed in each input node and transmitted to the hidden layer. The resulting value is an output from the output layer after passing through a calculation procedure. The BPN compares the resulting output value to a target value, and constitutes a learning network, repeatedly adjusting the weight with the method of decreasing the difference of those two values. The accuracy and efficiency of learning are affected by the number of layers and nodes in a neural network. Most optimized compositions of the neural network should be determined by changing the number of layers and nodes, because it is difficult to directly measure the propriety of a neural network through a BPN.

A three-layered BPN structure for learning input pattern data
The identification stage is implemented after learning the user's input pattern. The collected input pattern data is transmitted to the pre-learned BPN during this stage. A trained neural network checks if this information matches that of the normal user. It is possible that the user's input pattern must be re-learned, even after completing the composition of the neural network through learning. This might occur if a user changes his mobile device. A new mobile device may show different responses against the same input depending on the manufacturer or platform, and if the touch screen size or resolution differs, the coordinate values of input positions also differ. The second reason for needing re-learning might be when a user's input pattern actually changes. For example, if a user who uses just one finger to input on a mobile device decides to switch to two fingers, the normal user might be recognized as being suspicious at the identification stage due to the changed input pattern. If identification errors last more than a specific time, re-learning is required with new input pattern data, because the user's input pattern has changed.
5. Evaluation
5.1 Experimental setting
Increasing use has been made of the Linux-based Smartphones. We used a Motoroi, which is a Smartphone using the Android platform, for our test. Motoroi is equipped with Android version 2.2 and a 3.7 inch touch screen with a resolution of 854 × 480. We developed and installed a separate mobile application to collect input pattern data in Motoroi. We arranged nine buttons in the form of a 3-by-3 matrix on the touch screen in this application, because the values of some input pattern data types could be influenced by a widget's position.
Fifty 20 to 30 year olds who were familiar with mobile devices participated in the test. Each Test participant took a touch and scroll-wheel input test ten times. We never explained the purpose of the test to participants, because if it was disclosed to them, their input pattern data values could be influenced. In the touch input test, we collected three kinds of input pattern data, such as input duration, the pressure level and the touching width of the finger from each button widget. We collected the scroll-wheel's start and finish positions (x and y coordinates), speed and length, besides three instances of touch input.
The BPN was applied as a learning algorithm against the collected input pattern data. The detailed training configuration values are as follows: the number of layers (3), the activation function (sigmoid), the initial weight (a selected random value within the range of ± 0.3), and the stop condition (when the number of iterations was 5000 or the Network Mean Square Error (MSE) reached 10−7).
5.2 Experimental results
Input methods in mobile applications are generally composed of many touch inputs and several scroll-wheel actions. Thus, we focused on constituting a learning network with only the touch input pattern data of 50 test participants, and evaluated how correctly this data could cluster test participants. We individually selected three button widgets in a low Standard Deviation (SD) order of input pattern data among the nine button widgets in the test application before learning, and the input pattern data of these selected three buttons was utilized for learning. In this case, nine input nodes in BPN were set up because there were three kinds of input pattern data points (input duration, the pressure level and the touching width of the finger) per button. If the input pattern data of all the buttons was used for learning, it would be possible that the learning efficiency would drop due to the generation of too many input nodes.
Figure 5 is a learning graph describing the training improvement of the BPN when performing learning with the touch input pattern data of the three selected buttons. If the learning is successful, a gentle downward curve is drawn on the learning graph. However, Figure 5 shows that learning cannot be successfully performed with only touch input pattern data, and the clustering success rate was just 47.5%.

A learning graph describing the training improvement of the BPN
Thus, we tested how much the clustering success rate improved when adding the scroll-wheel input pattern data to that of the touch data. Table 2 is the result of this test. As seen in Table 2, the clustering success rate was significantly improved after scroll-wheel input pattern data types were added; we obtained a clustering success rate of nearly 100% when performing learning with more than three scroll-wheel input pattern data types.
The result of the test

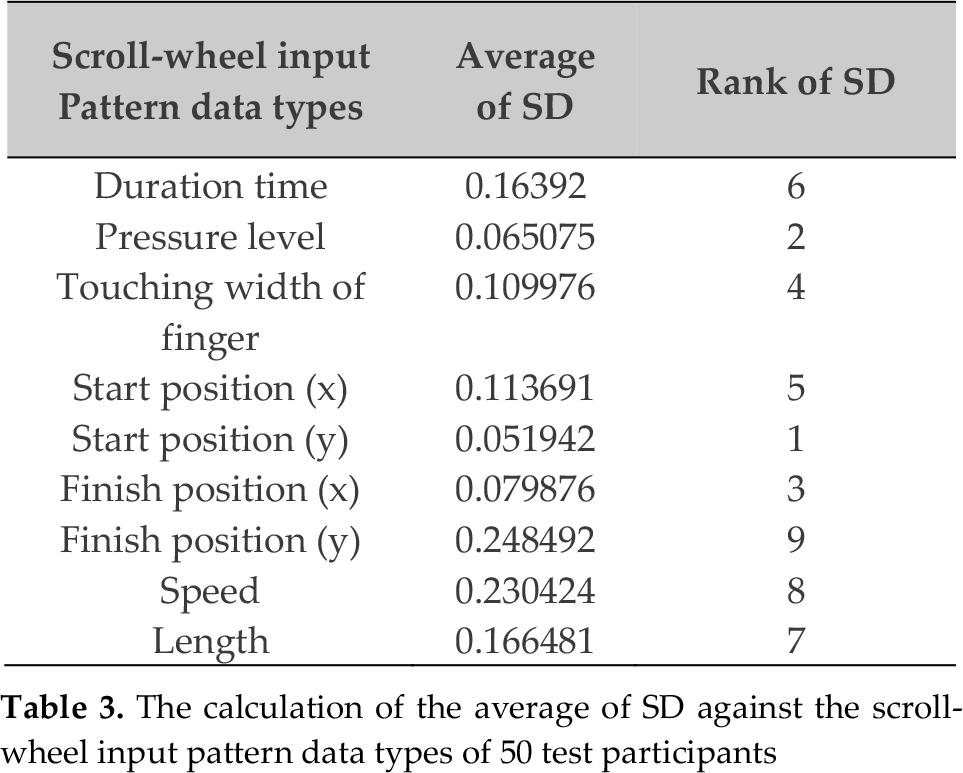
We used SD as the criteria to select scroll-wheel input pattern data types to add to those of the touch data. The scroll-wheel input pattern data types with a higher SD include too much noise or else the pattern is not uniform. Table 3 is the calculation of the average of the SD against the scroll-wheel input pattern data types of the 50 test participants. The SD of the y coordinates at the scroll-wheel's start position is the smallest and, following in decreasing order, is the pressure level, the x coordinates at the scroll-wheel finish position, and the touching width of the finger. The figures in Table 3 are the average SD of all 50 test participants and the rank of the SD per person may differ.
The calculation of the average of SD against the scroll-wheel input pattern data types of 50 test participants
We also changed the number of hidden nodes when the number of input nodes was 12 in order to determine the most optimized neural network, and we recorded the clustering success rate and learning time together to check the accuracy and efficiency of learning. Table 4 shows the differences regarding the accuracy and efficiency of the learning depending on the number of hidden nodes. In this test, we recognized that a higher clustering success rate could be obtained as the number of hidden nodes was increased. The learning time also appeared to be influenced by the number of hidden nodes. Such test results were shown in Figure 6, which compares the learning graphs based on the number of hidden nodes. All the learning graphs are the structure in which the propriety of the BPN increases as the number of hidden nodes increases. Even though our method guarantees a very high clustering success rate, it is desirable to use as many hidden nodes as possible, if the server in the organization has sufficient capacity, because just one identification error may inconvenience the user.
The differences regarding the accuracy and efficiency of learning depending on the number of hidden nodes


The results of the test compares the learning graphs based on the number of hidden nodes
In these test results, our method can identify users with an accuracy of nearly 100%. Its accuracy is very high considering that the success rate of other biometric identification methods is 91 ∼ 98.5% [6]. In addition, our method can prevent spoofing attacks. Even if all of the input pattern data are exposed to attackers, it is very hard for attackers to become aware of the meaning or contents of the collected input pattern data, because they are just simple numbers. What is more, our method is simply implemented by adding modules for the collection of input pattern data to mobile applications, and has the strength of not requiring much space, because the input pattern data format is text. Also, a privacy infringement problem caused by the collection of input pattern data is not anticipated.
Analysing the test results, we might recognize that a Deviation Coefficient (DC), the distance from the average value, differs for each test turn. Table 5 is the calculation of the DC's average according to test turns. As seen in Table 5, the DC of the 1st test turn was higher by 1.5∼2 times than for other turns. We assumed that noisy input was higher, because the test participants were not accustomed to the test application during the 1st test turn. We experimented without input pattern data for the first turn, and obtained a higher accuracy rate and better performance, as shown in Table 6. The learning accuracy improved and the learning time shortened to less than one minute. Thus, if the input pattern data is learned after users become somewhat experienced with the mobile application, it is expected that the identification accuracy and efficiency will be much higher.
The calculation of the DC's average according to test turns

The result of experiments without input pattern data of the first turn

6. Conclusion
Mobile technologies have developed at a fast pace. However, these intelligent mobile devices continue to suffer from high security risks, such as leaking critical information to attackers under the restricted security measures imposed by the device's resource constraints and the limitations of existing biometric identification methods.
This paper offered a novel biometric identification method based on the analysis of the user's input pattern for mobile devices, and verified the performance of this method through a test in an actual mobile device. Our method can be regarded as appropriate for application to the current mobile environment, because it guarantees high accuracy, ease of deployment without a high cost, is difficult for attackers to forge, and does not infringe privacy. Also, given that our method can check if mobile devices are used by the true owners, it is expected to be used widely to detect illegal usage by unauthorized users, in the case of the theft or loss of mobile devices. In particular, if our method is adopted in a mobile banking service, it is thought it may be an effective security measure to prevent mobile e-financial incidents, because illegal transactions by attackers can be detected at the final transfer procedure, even when all the mobile banking identification data of a user is leaked to the attackers. In addition, as a useful second factor authentication method, our proposed method can be applied in embedded systems or industrial control systems that are running mobile OSs.
We foresee that the mobile environment and device techniques will have greater diversity in the near future, and thus this work can be expanded in many areas that use intelligent mobile devices.
Footnotes
7. Acknowledgements
This research was supported by the MKE (The Ministry of Knowledge Economy), Korea, under the ITRC (Information Technology Research Center) support program (NIPA-2012-H0301-12-3007) supervised by the NIPA (National IT Industry Promotion Agency).