
Abstract
A robot can perform a given task through a policy that maps its sensed state to appropriate actions. We assume that a hand-coded controller can achieve such a mapping only for the basic cases of the task. Refining the controller becomes harder and gets more tedious and error prone as the complexity of the task increases. In this paper, we present a new learning from demonstration approach to improve the robot's performance through the use of corrective human feedback as a complement to an existing hand-coded algorithm. The human teacher observes the robot as it performs the task using the hand-coded algorithm and takes over the control to correct the behavior when the robot selects a wrong action to be executed. Corrections are captured as new state-action pairs and the default controller output is replaced by the demonstrated corrections during autonomous execution when the current state of the robot is decided to be similar to a previously corrected state in the correction database. The proposed approach is applied to a complex ball dribbling task performed against stationary defender robots in a robot soccer scenario, where physical Aldebaran Nao humanoid robots are used. The results of our experiments show an improvement in the robot's performance when the default hand-coded controller is augmented with corrective human demonstration.
1. Introduction
Transferring the knowledge of how to perform a certain task to a complex robotic platform remains a challenging problem in robotics research with an increasing importance as robots start emerging from research laboratories into everyday life and interacting with ordinary people who are not robotics experts. A widely adopted method for transferring task knowledge to a robot is to develop a controller using a model for performing the task or skill, if such a model is available. Although it is usually relatively easier to develop a controller that can handle trivial cases, handling more complex situations often requires substantial modifications on the controller. Due to interference among the newly added cases and the existing ones, it becomes a tedious and time consuming process to ameliorate the controller and the underlying model as the number of such complex cases increases. That brings out the need for a new approach to robot programming.
Learning from Demonstration (LfD) paradigm is one such approach that utilizes supervised learning for transferring task or skill knowledge to an autonomous robot without explicitly programming it. Instead of hand-coding a controller for performing a task or skill, LfD methods make use of a teacher who demonstrates the robot how to perform the task or skill while the robot observes the demonstrations and synchronously records the demonstrated actions along with the perceived state of the system. The robot then uses the stored state-action pairs to derive an execution policy for reproducing the demonstrated task or skill. Compared to more traditional exploration based methods, LfD approaches aim to reduce the learning time and eliminate the necessity for defining a proper reward function, which is considered to be a difficult problem (7). Moreover, since the LfD approaches do not require the robot to be programmed explicitly, they are very suitable for cases where the task knowledge is available through a user who is an expert in the task domain but not in robotics.
Providing a way for humans to transfer task and skill knowledge to robots via natural interactions, the LfD approaches are also suitable for problems, where an overall analytical model for the task or skill is not available but a human teacher can tell which action to take in a particular situation. However, providing sufficient number of examples is a very time consuming process when working with robots with highly complex body configurations; such as humanoids, and for sophisticated tasks with very high dimensional state and action spaces.
LfD based methods have been applied to many learning scenarios involving high level task and low level skill learning on different robotic platforms varying from wheeled and legged robots to autonomous helicopters. Here we present a few representative studies and strongly encourage the reader to resort to (7) for a comprehensive survey on LfD.
While learning to perform high level tasks, it is a common practice to assume that the low level skills required to perform the task are available to the robot. Task learning from demonstration have been studied in many different contexts; such as, (from reinforcement learning point of view) learning how to bake a cake (40), (from an active learning point of view) learning concepts (14), and (from the sliding autonomy point of view) learning of general behavior policies from demonstration for a single robot (19; 21; 22; 24) and multi-robot systems (20; 23) via the “Confidence Based Autonomy (CBA)” approach.
Several approaches to low level skill learning in the literature utilize LfD methods with different foci. Tactile interaction has been utilized for skill acquisition through kinesthetic teaching (31) and skill refinement through tactile correction (4–6; 8; 15). Motion primitives have been used for learning biped walking from human demonstrated joint trajectories (36) and learning to play air hockey (11).
Several regression based approaches have been proposed for learning quadruped walking on a Sony AIBO robot and learning low level skills for playing soccer (28; 29), learning several skills with different characteristics (cyclic, skills with multiple constraints, etc.) using a probabilistic approach that utilizes Hidden Markov Models (HMM) along with regression (16), and learning non-linear multivariate motion dynamics (27).
Interacting with the learner using high level abstract methods has been introduced in forms of natural language (12; 39) and advice operators as functional transformations for low level robot motion, demonstrated on a Segway RMP robot (2; 3). Reinforcement learning methods have been investigated in conjunction with the LfD paradigm for teaching a flying robot how to perform a complex skill (1), learning to swing up a pole and keep it balanced (9; 10), learning constrained reaching tasks (30), and hierarchical learning of quadrupedal locomotion on rough terrain (33).
In our previous work on complementary skill refinement, we used real-time corrective human demonstration to improve the biped walk stability of a Nao humanoid robot (17; 18). An existing walk algorithm was used to capture a complete walk cycle, and the captured walk cycle was played back to obtain a computationally cheap open-loop walking behavior. A human demonstrator monitored the robot as it walked using the open-loop controller and modified the joint commands in real-time via a wireless game controller to keep the robot stable. The recorded demonstration values together with the corresponding sensor readings were used to derive a policy for computing proper joint command correction values for a given sensory reading to recover the balance of the robot.
In this paper, we present a corrective demonstration approach for task execution refinement where a hand-coded algorithm for performing the task exists but is inadequate in handling complex cases. The human demonstrator observes the robot carry out the task by executing the hand-coded algorithm and provides corrective feedback when the hand-coded controller computes a wrong action. The received demonstration actions are stored along with the state of the robot at the time of correction as complements (or “patches”) to the base hand-coded algorithm. During autonomous execution, the robot substitutes the action computed by the hand-coded algorithm with the demonstrated action if the corrective demonstration history database contains a demonstration provided in a similar state. The key idea is to keep the base controller algorithm as the primary source of the action policy, and use the demonstration data as exceptions only when needed instead of deriving the entire policy out of the demonstrations and the output of the controller algorithm. We applied this approach to a complex ball dribbling task in humanoid robot soccer domain. Experiment results show considerable performance improvement when the hand-coded algorithm is complemented by corrective human feedback. Since the human teacher provides correction only when the robot performs an erroneous action, the number of corrective demonstration examples needed to improve the task performance is smaller compared to other LfD approaches in the literature.
The rest of the paper is organized as follows: In Section 2, we describe the robot soccer domain and the hardware platform used in this study, followed by a brief overview of the software infrastructure used in our humanoid robot soccer system. In Section 3, we first give the problem definition for the ball dribbling task, which is our application domain, and then we present a thorough explanation of the special image processing system for free space detection, the ball dribbling behavior developed using the available low level skills and the software infrastructure described in Section 2, and a hand-coded algorithm for action selection parts of the ball dribbling behavior. Section 4 contains the explanation of the corrective demonstration setup for delivering the demonstration to the robot and a domain-specific correction reuse system used for deciding when to apply a correction based on the similarity of the current state of the system to the states in the correction database. We present our experimental study in Section 5 with results showing a considerable improvement in the task completion time using corrective demonstration as a complement to the original hand-coded algorithm over using the original hand-coded algorithm alone. Pointing out some future directions to be further explored, we conclude the paper in Section 6.
2. Background
2.1 Robot Soccer Domain
RoboCup is an international research initiative that aims to foster research in the fields of artificial intelligence and robotics by providing standard problems to be tackled from different points of view; such as, software development, hardware design, and systems integration (37). Soccer was selected by the RoboCup Federation as the primary standard problem due to its inherently complex and dynamic nature, allowing scientists to conduct research on many different sub-problems ranging from multi-robot task allocation to image processing, and from biped walking to self-localization. With its various categories focusing on different challenges in the soccer domain; such as, playing soccer in simulated environments (the 2D and 3D Simulation Leagues) and physical environments using wheeled platforms (the Small Size League and the Middle Size League), humanoid robots of different sizes and capabilities (the Humanoid League), and a standard hardware platform (the Standard Platform League), the ultimate goal of RoboCup is to develop, by 2050, a team of 11 fully autonomous humanoid robots that can beat the human world champion soccer team in a game that will be played on a regular soccer field complying with the official FIFA rules.
In the Standard Platform League (SPL) of RoboCup (38), teams of 3 autonomous humanoid robots play soccer on a 6 meters by 4 meters green carpeted field (Figure 1(a)). The league started in 1998 as an embodied software competition with a common and standard hardware platform, hence the name. Sony AIBO robot dogs had been used as the standard robot platform of the league until 2008, and the Aldebaran Nao humanoid robot was decided to be the new standard platform thereafter. A snapshot showing the Nao robots playing soccer is given in Figure 1(b).

a) The field setup for the RoboCup Standard Platform League (SPL), and b) a snapshot from an SPL game showing the Nao robots playing soccer.
2.2 Hardware Platform
The Aldebaran Nao robot (Figure 2) which is the standard hardware platform for the RoboCup SPL competitions, is a 4.5 kg, 58 cm tall humanoid robot with 21 degrees of freedom 1 . The Nao has an on-board 500 MHz processor, to be shared between the low level control system and the autonomous perception, cognition, and motion algorithms. It is equipped with a variety of sensors including two color cameras, two ultrasound distance sensors, a 3-axisaccelerometer, a 2-axis gyroscope (X-Y), an inertial measurement unit for computing the absolute orientation of the torso, 4 pressure sensors on the sole of each foot, and a bump sensor at the tiptoe of each foot.
The Nao runs a Linux-based operating system and has a software framework named NaoQi, which allows users to develop their own controller software and access the sensors and actuators of the robot. The internal controller software of the robot runs at 100Hz, making it is possible to read new sensor values and send actuator commands every 10ms.

The Aldebaran Nao humanoid robot.
2.3 Software Overview
Being able to play soccer requires several complex software modules (i.e., image processing, self localization, motion generation, planning, communication, etc.) to be designed, implemented, and seamlessly integrated with each other. In this section of the paper, we present a brief overview of the software infrastructure developed for the RoboCup SPL competitions and also used in this study.
2.3.1 Image Processing
The Nao humanoid robots perceive their environment via their sensors, namely the two color cameras, the ultrasound distance sensors, the gyroscope, and the accelerometer. All the important objects in the game environment (i.e., the field, the goals, the ball, and the robots) are color coded to facilitate object recognition. However, perception of the environment remains the most challenging problem primarily due to the extremely limited on-board processing power that prevents the use of intensive and sophisticated computer vision algorithms. The very narrow fields of view (FoV) of the robot's cameras (≈ 58° diagonal) and their sensitivity to changes in light characteristics like the temperature and luminance levels are among the other contributing factors to the perception problem.
The job of the image processing module is to extract the relative distances and bearings of the objects detected in the camera image. In addition to the position information, the image processing module also reports confidence scores indicating the likelihood of those objects being actually present in the camera image.
2.3.2 Self Localization and World Modeling
These modules are responsible for determining the location of the robot as well as the locations of the other important objects (e.g. the ball) on the field. Our system uses a variation of Monte Carlo Localization (MCL) called Sensor Resetting Localization (34) for estimating the position of the robot on the field. For calculating and tracking the global positions of the other objects, we employ a modeling approach which treats objects based on their individual motion models defined in terms of their dynamics (25; 26).
2.3.3 Planning and Behavior Control
Our planning and behavior generation module is built using a hierarchical Finite State Machine (FSM) based multi-robot control formalism called Skills, Tactics, and Plays (STP) (13). Plays are multi-robot formations where each robot is executing a tactic consisting of several skills. Skills can be stand-alone or formed via a hierarchical combination of other skills.
2.3.4 Motion Generation
The motion generation module is responsible for all types of movement on the field including biped walking, ball manipulation (e.g., kicking), and some other motions such as getting back upright after a fall. For the biped walking, we use the omni-directional walk algorithm provided by Aldebaran. For kicking the ball and the other motions, we use predefined actions in the form of sequences of keyframes, each of which define a vector of joint angles and a duration value for the interpolation between the previous pose and the current one. Two variations (strong and weak) of three types of kick (side kick to the left, side kick to the right, and forward kick) are implemented to be used in the games.
3. Proposed Approach
3.1 Problem Definition
Technical challenges are held as a complementary part of the RoboCup SPL competitions with the aim of creating a research incentive on complex soccer playing skills that will help leverage the quality of the games and enable the league to gradually approach the level of real soccer games both in terms of the field setup and the game rules. Each year, the technical challenges are determined accordingly by the Technical Committee of RoboCup SPL.

An example scenario for the dribbling challenge.
Our application and evaluation domain, the “Dribbling Challenge”, was one of the three technical challenges of the 2010 SPL competitions. In that challenge, an attacker robot is expected to score a goal in three minutes without having itself or the ball touching any of the three stationary defender robots that are placed on the field in such a way to block the direct shot paths. The positions of the obstacle robots are not known beforehand; therefore, the robot has to detect the opponent robots, model the free space on the field, and plan its actions accordingly. An example scenario is illustrated in Figure 3.
3.2 Free Space Detection using Vision
Instead of trying to detect the defender robots and avoid them, our attacker robot detects the free space in front of it and builds a free space model of its surroundings to decide which direction is the best to dribble the ball towards. The soccer field is a green carpet with white field lines on it. The robots are also white and gray, and they wear pink or blue waist bands as uniforms (Figure 1(b), Figure 3). Therefore, anything that is non-green and lying on the field can be considered as an obstacle, except for the detected field lines. We utilize a simplified version of the Visual Sonar algorithm by Lenser and Veloso (35) and the algorithm by Hoffmann et al. (32). We scan the pixels on the image along evenly spaced vertical lines called scanlines, starting from the bottom end and continue until we see a certain number of non-green pixels. Although the exact distance function is determined by the position of the camera, in general the projected relative distance of a pixel increases as we ascend from the bottom of the image to the top, assuming all the pixels lie on the ground plane. If we do not encounter any green pixels along a scanline, we consider that scanline as fully occupied. Otherwise, the point where the non-green block starts is marked as the end of the free space towards that direction. To further save some computation time, we do not process every vertical line on the image. Instead, we process the lines along every fifth pixel and every other pixel along those lines. As a result, we effectively process only 1/10 th of the image(Figure 4(b)). The pixels denoting the end of the free space are then projected onto the ground to have a rough estimate of the distance of the corresponding obstacle in the direction of the scanned line. In order to cover the entire 180° space in front of it, the robot pans its head from side to side. As the head moves, the computed free space end points are combined and divided into 15 slots, each covering 12° in front of the robot. In the mean time, each free space slot is tagged with a flag indicating whether that slot points towards the opponent goal or not based on the location of the opponent goal in the world model, or the estimated location and orientation of the robot on the field (Figure 4(c)).
3.3 Ball Dribbling Behavior
We used the Finite State Machine (FSM) based behavior system explained in Section 2.3.3 for developing the ball dribbling behavior. The FSM structure of the ball dribbling behavior is depicted in Figure 5. The robot starts with “searching for the ball” by panning its head from side to side several times using both cameras. If it cannot find the ball at the end of this initial scan, it starts turning in place while tilting its head up and down, and this cycle continues until the ball is detected. Once the ball is located on the field, “approach the ball” behavior gets activated and the robot starts walking towards the ball. Utilizing the omni-directional walk, it is guaranteed that the robot faces the ball when the “approach the ball” behavior is executed and completed successfully. After reaching the ball, the robot pans its head one more time to gather information about the free space around it, calculates its current state, selects an action that matches its state, and finally kicks the ball towards a target point computed according to the selected action. If the robot loses the ball at any instant of this process, it goes back to the “search for the ball” state. Except for the lightly colored select action and select dribble direction states shown on the state diagram, each state in the given FSM corresponds to a low level skill. We use the existing low level skills in our robot soccer system without any modifications; namely, looking for the ball, approaching the ball, lining up for a kick, and kicking the ball to a specified point relative to the robot by selecting an appropriate kick from the portfolio of available kicks.

The environment as perceived by the robot: a) the color segmented image showing the potential obstacle points marked as red dots, b) the computed perceived free space segments illustrated with the cyan lines overlaid on the original image, and c) the free space model built out of the perceived free space segments extracted from a set of images taken while the robot pans its head. Here, the dark triangles indicate the free space slots pointing towards the opponent goal.

The state diagram of the base system.
3.4 Action and Dribble Direction Selection
The select action and the select dribble direction states constitute the main decision points of the system we aim to improve using corrective demonstrations. The hand-coded algorithms for both the action and the dribble direction selection parts utilize the free space model in front of the robot. After lining up with the ball properly, the robot selects one of the following two actions:
Shoot
Dribble
The shoot action corresponds to kicking the ball directly towards the opponent goal using a powerful and long range kick. The dribble action, on the other hand, corresponds to dribbling the ball towards a more convenient location on the field using a weaker and shorter range kick. When the robot reaches the decision point; that is, after it aligns itself with the ball and scans the environment for free space modeling, the action selection algorithm checks if any of the free space slots pointing towards the opponent goal has a distance less than a certain fraction of the distance to the goal. If so, the path to the opponent goal is considered “occupied” and the dribble action is selected in that situation. Otherwise, the path is considered “clear” and the shoot action targeting the center of the opponent goal is selected. The pseudo-code of the action selection algorithm is given in Algorithm 1.
If the action selection algorithm deduces that the path to the opponent goal is blocked and subsequently selects the dribbling action, a second algorithm steps in to determine the best way to dribble the ball. All slots in the free space model are examined and assigned a score computed as the weighted sum of the distance values of the slot itself and its left and right neighbors. The free space slot with the maximum score is selected as the dribble direction. The algorithm for dribble direction selection is given in Algorithm 2.
Using the two algorithms explained above for the two action selection states in the behavior FSM, the robot is able to perform the ball dribbling task and score a goal with limited success. We define the success metric for this task to be the time it takes for the robot to score a goal. The performance evaluation results for the hand-coded action selection algorithms are provided in Section 5. In the following section, we present the corrective demonstration system developed as a complement to the hand-coded action selection algorithms for refining the task performance.
4. Corrective Demonstration
Argall et al. (7) formally define the learning from demonstration problem as follows. The world consists of states S, and A is the set of actions the robot can take. Transitions between states are defined with a probabilistic transition function T(s' s, a): S x A x S → [0,1]. The state is not fully observable; instead, the robot has access to an observed state Z with the mapping M: S → Z. A policy n: Z → A is employed for selecting the next action based on the current observed state.
an alternative action to be executed in that state, or
a modification to the selected action.
The usual form of employing corrective demonstration is either through adding the corrective demonstration example to the demonstration dataset or replacing an example in the dataset with the corrective example, and re-deriving the action policy using the updated demonstration dataset.
However, re-deriving the execution policy each time a correction is received can be cumbersome if the total number of state-action pairs in the demonstration database is large. On the other hand, accumulating a number of corrective demonstration points and then re-deriving the execution policy may be misleading or inefficient since the demonstrator will not be able to see the effect of the provided corrective feedback immediately.
In our approach, we store the collected corrective demonstration points separate from the hand-coded controller, and utilize a reuse algorithm to decide when to use correction. In the following subsections, we first describe how the corrective demonstration is delivered to the robot, and then we explain how the stored corrections are used during autonomous execution.
4.1 Delivering Corrective Demonstration
During the demonstration session, the robot is set to a semi-autonomous mode in which it executes the dribbling behavior with the hand-coded action selection algorithms and performs the dribbling task. Each time an action selection state is reached, the robot computes an action, announces the selected action, and asks the teacher for the feedback. The teacher can give one of the following commands as the feedback:
Perform the selected action
Revise the action
If (1) is selected, the robot continues with the action computed by the hand-coded action selection system. If (2) is selected, the robot provides the available actions and asks the teacher to select one. If the robot is in the dribble direction selection state, it first selects a free space slot according to the hand-coded dribble direction selection algorithm. If the teacher wants to change the selected dribble slot, the robot provides the directions that can be chosen and waits for the teacher to select one. In both revision cases, the action provided by the teacher is paired with the current state of the system and stored in a database. No records are stored in the database when the teacher approves the robot's selection as the next action to be executed.
4.2 Reusing the Corrections
By the end of the demonstration session, the robot has built a demonstration database of state-action pairs denoting what action is provided by the teacher as a replacement of the action computed by the hand-coded algorithms and what was the robot's state when that correction is received. During autonomous execution, the decision of when to execute the action selected by the hand-coded algorithms and when to use corrective demonstration samples is made by a correction reuse system based on the similarity of the current state of the robot to the states in which the demonstration samples were collected.
We define the observed state of the robot as

where slotDist i is the distance to the nearest obstacle inside slot i, and goal i ∈ true, false is a Boolean flag which is set to true if the slot i intersects with the goal, and set to false otherwise.
Since the robot is expected to kick/dribble the ball into the opponent goal, rather than the mere position of the robot on the field, the distribution of the free space with respect to the direction towards the goal needs to be taken into account. Therefore, we calculate the sum of the absolute differences of the free space slots using the slot pointing towards the center of the goal as the origin if the goal is in sight. If the goal is not somewhere within the 180° in front of the robot, we calculate the sum of absolute differences of the free space slots using the rightmost slot as the origin. The similarity value in the range [0,1] is then calculated as

where K is a coefficient for shaping the similarity function, anddiff is the calculated sum of absolute differences of the slot distances. In our implementation, we selected K = 5. The algorithm for similarity calculation is given in Algorithm 3.
During execution, when the robot reaches the action selection or dribble direction selection states, it first checks its demonstration database and fetches the demonstration sample with the highest similarity to the current state. If the similarity value is higher than a threshold value τ, the robot executes the demonstrated action instead of the action computed by the hand-coded algorithm. In our implementation, we user τ = 0.9.
5. Results
We evaluated the efficiency of the complementary corrective demonstration using three instances of the ball dribbling task with different opponent robot placements in each of them. The test cases were designed in such a way that the robot using the hand-coded action selection algorithm would be able to complete the task, but not through following an optimal sequence of actions (Figure 6). The following criteria were kept in mind while designing the test cases:

Three different configurations used in the experiments. a) Case 1, b) Case 2, and c) Case 3.
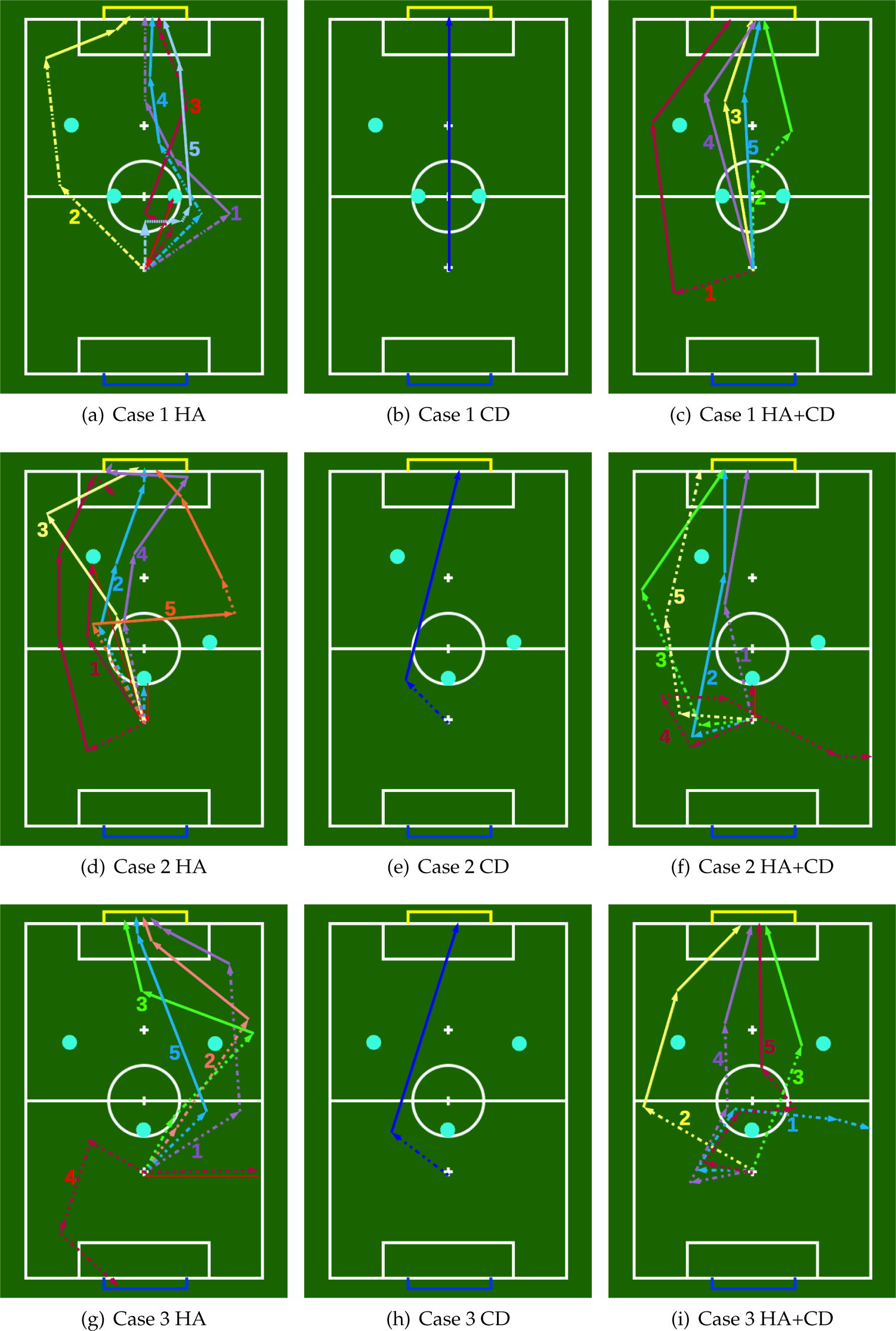
The illustrations of the performance evaluation runs. Different colors denote different runs. For each run, a dashed line represents a dribble and a solid line represents a kick. HA stands for hand-coded algorithm and CD stands for corrective demonstration. HA+CD shows the cases where the robot is in autonomous mode using both hand-coded algorithm and the corrective demonstration database.
We gathered corrective demonstration data from all three cases and formed a common database. A total of 42 action selection and 21 dribble direction selection demonstration points were collected in a roughly 30 minutes long demonstration session. Time required to score a goal being the success measurement metric, we then evaluated the performance of the system with and without the use of the corrective demonstration database.
We ran 10 trials for each case, 5 with the hand-coded action and dribble direction selection algorithms (HA), and another 5 trials with the corrective demonstration data (CD) in addition to the HA (HA+CD). The sequence of actions taken by the robot at each trial are depicted in Figure 7, and the timing information is presented in Table 1. In the figures, a dashed line indicates dribble action, a solid line indicates a shoot action, and a thin line indicates the replacement of the ball to the initial position after committing a foul. In the table, “out” means that the robot kicked the ball out of bounds from the sides, “missed” means that the robot chose the right actions but the ball did not roll into the goal due to imperfect actuation, and “own goal” means that the robot accidentally kicked the ball into its own goal. The failed attempts are excluded from the given mean and standard deviation values. The failures were mostly due to the imperfection of the lower level skills like aligning with the ball, and the high variance in both the kick distance and the kick direction.
Elapsed times during trials.

The decrease in the timings in all three test cases when using (HA+CD) compared to the system using (HA) alone shows an improvement in the overall performance since according to the problem definition, the shorter completion times are considered more successful. In
6. Conclusions and future work
In this paper, we contributed a task and skill improvement method which utilizes corrective human demonstration as a complement to an existing hand-coded algorithm for performing the task. We applied the method on one of the technical challenge tasks of the RoboCup 2010 Standard Platform League competitions called the “Dribbling Challenge”. Corrective demonstrations were supplied at two levels: action selection and dribble direction selection. The hand-coded action selection algorithms for kick type and dribble direction selections can handle most of the basic cases; however, they are unable to perform well on all the defined test cases, as the test cases are designed in such a way to measure different aspects of the developed ball dribbling behavior. A human teacher monitors the execution of the task by the robot and intervenes as needed to correct the output of the hand-coded algorithm. During the advice session, the robot saves the received demonstration examples in a database, and during autonomous execution, it fetches the demonstration example received for the most similar state in the database using a domain specific similarity measure. If the similarity of those two states is above a certain threshold, the robot executes the fetched demonstration action instead of the output of its own algorithm. We presented empirical results in which the proposed method is evaluated in three different field setups. The results show that it is possible to improve the task performance by applying “patches” to the hand-coded algorithm through only a small number of demonstrations as well as “shaping” a hand-coded behavior by complementing it with corrective demonstrations instead of modifying the underlying algorithm itself.
Investigating the possibility of developing a domain-free state similarity measure, applying the corrective demonstration to the other sub-spaces of the task space, considering other demonstration retrieval mechanisms allowing better generalization over the state-action landscape, and applying the proposed method to more sophisticated tasks are among the future work that we aim to address.
7. Acknowledgments
The authors would like to thank the other members of the CMurfs RoboCup SPL team for their invaluable help, and to Tekin Meriçli for proofreading the manuscript.