
Abstract
This paper shows how Q-learning approach can be used in a successful way to deal with the problem of mobile robot navigation. In real situations where a large number of obstacles are involved, normal Q-learning approach would encounter two major problems due to excessively large state space. First, learning the Q-values in tabular form may be infeasible because of the excessive amount of memory needed to store the table. Second, rewards in the state space may be so sparse that with random exploration they will only be discovered extremely slowly. In this paper, we propose a navigation approach for mobile robot, in which the prior knowledge is used within Q-learning. We address the issue of individual behavior design using fuzzy logic. The strategy of behaviors based navigation reduces the complexity of the navigation problem by dividing them in small actions easier for design and implementation. The Q-Learning algorithm is applied to coordinate between these behaviors, which make a great reduction in learning convergence times. Simulation and experimental results confirm the convergence to the desired results in terms of saved time and computational resources.
1. Introduction
The existence of robots in various types (walkers, manipulators, mobiles…) became very significant in the industrial sector and especially in the service sector (Youcef, Z., 2004). Due to the growing interest of the service robots, they can achieve their mission in an environment which contains several obstacles (Ulrich, I. & Borensstein, J., 2001) (i.e. in factories, hospitals, museums and even in our houses). The mobile robots, known also as wheeled robots, have the advantage of the simplicity of manufacturing and mobility in complex environments. The capacity to move without collision in such environment is one of the fundamental questions to be solved in autonomous robot-like problems. The robot should avoid the undesirable and potentially dangerous objects. These possibilities have much interest of the subject of robot-like research.
A Behavior Based Navigation (BBN) system is developed using fuzzy logic. The main idea is to decompose the task of navigation into simple tasks (Parasuraman, S.; Ganpathy, V. & Shiainzadeh, B., 2005). With this type of navigation system we should identify a behavior for each situation defined by the sensory inputs of the robot (Fatmi, A.; Al-Yahmedi, A.; Khriji, L. & Masmoudi, N., 2006). All actions (behaviors) are mixed or fused to produce only one complex behavior. However, a number of problems with regard to this type of navigation system are always in study.
In this paper, we study the use of the reinforcement learning algorithm, Q-learning, to answer the question of coordination between the behaviors. The motivation of this study is as follows: Q-learning is a simulation- based stochastic technique which provides a way to relate state, action and reward through Q-value in the look up table. In real application, a controller simply searches the look up table and chooses the best-valued decision, no need to perform a complex on-line computation. Hence, the real time requirement of decision can be met in this way.
However, the dynamic coordination between behaviors is a large space Markov decision process (MDP) when the practical application involves a large number of behaviors; this is due to the exponential increase in the number of admissible states with the number of behaviors. In this situation, Q-learning will encounter two main problems. First, learning the Q-value in tabular form may be infeasible because of the excessive amount of memory needed to store the look up table. Second, because the Q-value only converges after each state has been visited multiple times, random exploration policy of Q-learning will result in excessive slowness in convergence. In this study, we solve the above large space Q-learning problems by taking advantage of fuzzy logic techniques.
The remainder of this paper is organized as follows: related researches on Fuzzy Behavior Based Navigation are reviewed in Section 2. Section 3 gives the basic principle of Reinforcement Learning (RL) (i.e. Q-learning). Simulation and experimental results are given in Section 4. Section 5 concludes the paper.
2. Fuzzy Behavior Based Navigation
Fuzzy logic is very much used for the control in the robotics field (Das, T. & Kar, I., 2006; Antonelli, G.C. & Fusco, S.G., 2007; Dongbing, G. & Huosheng, H.,2007). The basic idea in the fuzzy logic is to imitate the capacity of reasoning and decision making from the human been, using uncertainties and/or unclear information. In fuzzy logic the modeling of a system is ensured by linguistic rules (or fuzzy rules) between the input and output variables (Fatmi, A.; Al-Yahmedi, A.; Khriji, L. & Masmoudi, N., 2006; Aguirre, E. & Gonzalez, A., 2000). A fuzzy rule can be described by:
R1: If goal is far then speed is large and rotation is zero.
R2: If goal is right then speed is medium and rotation is right.
…
Rn: If goal is near then speed is zero and rotation is zero.
All input and output variables (i.e. goal, speed, and rotation) have degree of memberships in their membership functions (ex: goal: far, right… speed: large, medium, zero… and rotation: right, zero…). For the behavior based navigation, the problem is decomposed into independent and simpler behaviors (go to goal, avoid obstacles…). Each behavior is designed using fuzzy logic.
Let us mention for example the behavior go to goal; the objective of this behavior is to guide the robot to reach a desired target point. For testing purposes we considered an environment without obstacles. To reach the goal, the robot turns right then left with a high, medium or null speed depending on the inputs which are;
Distance: [meter] is the distance between the robot and the goal.
θ-error: [degree] is the difference between the desired angle and the current angle of the robot.
Figs. 1–2 show the fuzzy membership functions of the input distances and the input θ-error, respectively.

Membership functions of the input distances

Membership functions of the input θ-error.
(N: Near, S: Small, B: Big)
The two outputs of this behavior, which are also identical for the other behaviors, are:
Steering: [degree] is the desired angle for the next step.
Velocity: [meter/sec] is the speed of the robot.
Figs. 3–4 show the fuzzy membership functions of the output steering and the output velocity, respectively.

Membership function of the output steering

Membership function of the output velocity
(SN: Negative Small, Z: zero, SP: Positive Small)
(R: Right, FR: Right Forward, F: Forward, FL: Left Forward, L: Left)
(Z: zero, SP: Positive Small, P: Positive)
The goal reaching behavior is expected to align the robot with the direction of the goal. To achieve this behavior the rules, shown in Table I, were devised. By choosing different start points, Fig. 4 shows that in simulation the robot reaches the desired goal based on the minimization of the way to be taken.
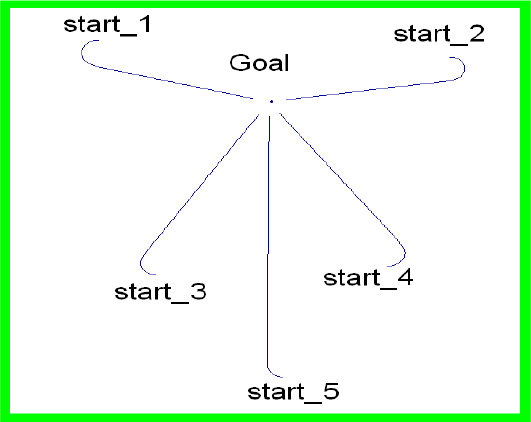
Simulation results of the behavior goal reaching.
Inference rules of the behavior go to goal

The other behaviors are:
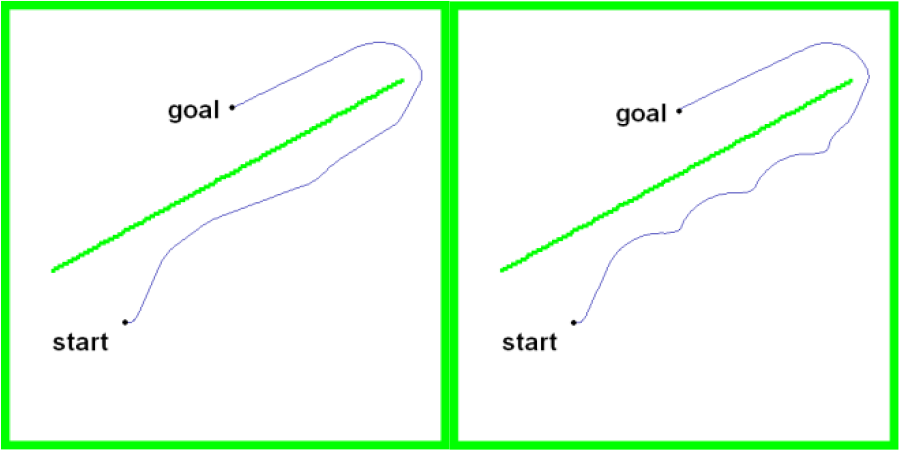
Simulation results with and without Wall Following behavior.
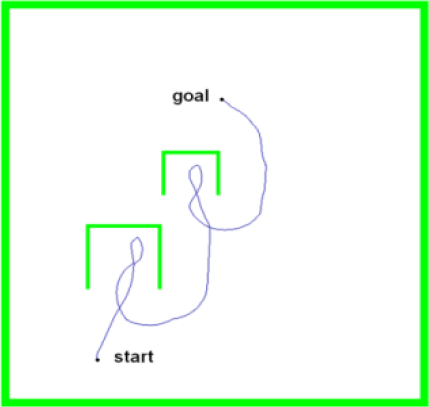
Simulation results of the emergency situation behavior
The inputs of the supervision layer are the distances to obstacles as measured by the different sonar's fixed on the robot as well as Drg and θ error . The supervision layer is made up based on fuzzy rules as follows,
IF context THEN behavior
For example a rule could be
R(i): IF RU is F and FR is F and FL is F and LU is F THEN Goal reaching
Where RU, FR, FL and LU are the Right up, Front right, Front Left and Left up respectively-IR sensors readings as defined in Fig.7. F is far and Goal Reaching is the goal reaching behavior.
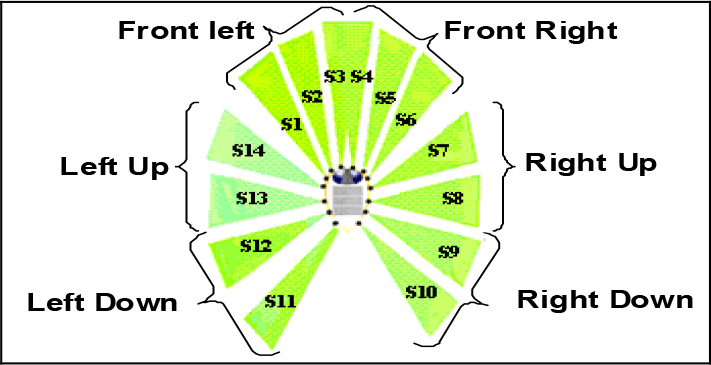
Clustered sensors
These three behaviors need inputs to read information about the navigation environment. The Pekee robot is equipped by 15 infrared sensors integrated on its body. For reason of simplification of the problem, this work considers clustered sensors into 6 groups. Each group informs the robot on the nearest obstacle detected. Fig. 8 shows the membership functions of the distance between the robot and the obstacle i, D_roi (mm).
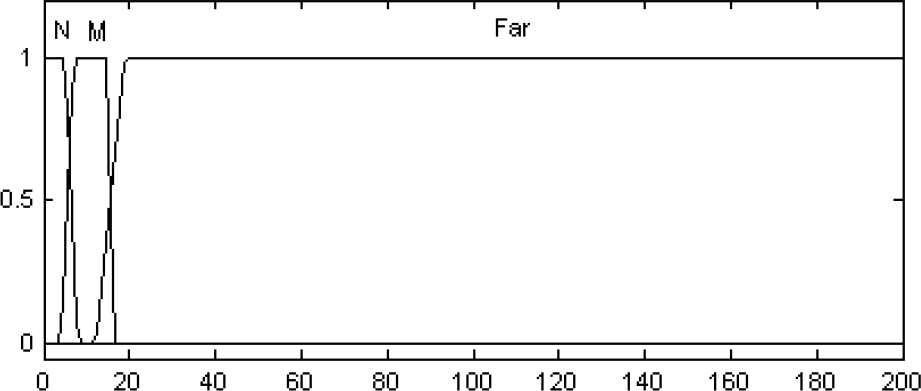
Membership functions of the input D_ro. (N: Near, M: Medium, F: Far)
It is well known that in the field of mobile robots, the coordination between behaviors is a major behavior based navigation problem (Fatmi, A.; Al-Yahmedi, A; Khriji, L. & Masmoudi, N., 2006; Aguirre, E. & Gonzalez, A., 2000). Several strategies have been proposed in literature to overcome this problem. Among them we can site for instance:
A first strategy based on the weighted combination between the behaviors. The velocity will be the weighted sum of the velocities of the behaviors (Cang, Y. & Danwei, W., 2001; Althaus, P. & Christensen, H.I., 2002). This strategy can be applied using the hierarchical fuzzy logic (Hasegawa, Y.; Tanahashi, H. & Fukuda, T., 2001; Hagars, H.A., 2004; Ziying Z.; Rubo, Z. & Xin, L., 2008).
A second strategy consists on the activation of, only, one behavior in each situation (Fatmi, A.; Al-Yahmedi, A.; Khriji, L. & Masmoudi, N., 2006). As a result time and computational resources are saved.
We have followed the second strategy in our work. The reinforcement learning technique used to improve the suitable choice of behavior by exploiting the acquired experimental learning of the robot during its navigation.
3. Reinforcement Learning
Reinforcement Learning (RL) is a machine learning paradigm (Lanzi, P.L., 2008). It makes possible the solution of the problem in a finite time based on its own experimental learned knowledge. The basic idea in reinforcement learning is that an agent (robot) is placed in an environment and can observe the results of its own actions. It can see the environment and concludes its current state (s t ). Then the algorithm selects a decision (d t ). This decision can change the environment and the state of the agent becomes (st+1). The agent receives a reward r for the decision d t . While processing, the agent keeps trying to maximize this reward.
3.1. Q-Learning Algorithm
Q-learning is an artificial intelligent technique that has been successfully utilized for solving complex MDPs that model realistic systems.
In the Q-learning paradigm, an agent interacts with the environment and executes a set of actions. The environment is then modified and the agent perceives the new state through its sensors. Furthermore, at each epoch the agent receives an external reward signal. In this learning strategy, an objective is defined and the learning process takes place through trial and error interactions in a dynamic environment. The agent is rewarded or punished on the basis of the actions it carries out. Let s denote a state and d denote a decision, the objective of this learning strategy is teaching agent the optimal control policy, s → d, to maximize the amount of reward received in the long term. Over the learning process, Q-value of every state-decision pair, Q(s,d), is stored and updated. The Q-value represents the usefulness of executing decision d when the environment is in state s. Q-learning directly approaches the optimal decision-value function, independently of the policy currently being followed. Its updating rule is (Akira, N.; Hiroyuki W.; Katsuhiro H. & Hidetomo I., 2008),
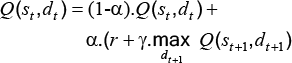
Where r t denotes the reward received at epoch t, 0 ≺ γ ≺ 1 denotes the discount factor and α denotes the learning rate. Let Q*(s,d) denotes the optimal expected Q-value of state-decision pair (s,d). If every decision is executed in each state infinitely, Q(s,d) will converge to Q*(s,d).
The Q-Learning algorithm can be written:
Obtain the current state s t .
Choose a decision d t , and execute it.
Obtain the new state st+1 and the immediate reward r.
Update the matrix Q(s t , d t ) with the equation:

Assign s t = st+1
While s t ≠ s optimal return to 2.
where α and γ are the training rate and the discount factor, respectively. Both parameters belong to the interval
3.2 Application of the Q-Learning algorithm
The Q-Learning algorithm is exploited to coordinate between the fuzzy behaviors. The different parameters are:
D_roi, i = 1…4: The distance between the robot and the obstacle i. (D_roi ∈ [0, 0.3]m or D_roi > 0.3m)
Distance: The distance between the robot and the goal (Distance ∈ [0, 0.3]m or Distance > 0.3m)
θ-error: The difference between the desired angle and the current angle of the robot
(Absolute value (θ-error) <5deg. else if θ-error > 0 else θ-error < 0).
4. Simulation and experimental results
This section will be devoted to the simulation and experimental results after using the Q-Learning approach to coordinate between behaviors based on fuzzy logic. Our experimental procedure comprises two phases: learning and testing. The learning phase is used to obtain convergent Q-values. In each learning step of the learning process, the decision is chosen based on the fuzzy logic results of different behaviors and the Q-value is updated according to Eq. (1). Here, we use the number of learning cycles to measure the learning efficiency as shown in Fig. 9. It shows that the learning process of our Q-learning algorithm becomes stable at around 60 episodes. One learning cycle (episode) is the learning process from the start point to the end of the horizon. The test phase is used to measure the performance of the system and to determine when the learning process has converged. During the test phase, the stored Q-values are loaded and the best-valued decision for current state and event is always selected real robot navigation. In all our simulations and experiments the learning rate is 0.2 and the discount factor is 0.8.

Number of steps and Distance to goal versus Episode
It is noticed, in both cases of Figs. 10(a-b), that the robot reaches the goal at two different starting points with avoiding obstacles. In Fig. 10(a) the robot follows the walls then it avoids the obstacles and finally it can go to the goal when there are no obstacles. In Fig. 10(b) the robot is putted from the beginning in an emergency situation (3 obstacles in the 3 directions: front, right and left), it could leave this situation and then it avoids the obstacles and finally it goes straight to the goal. The effectiveness of the developed navigation approach was experimentally demonstrated on a Pekee robotic platform. The real experimental results are shown in Fig.11 (a-d) demonstrating the validity of our approach.

Navigation in a crowded environment after learning.
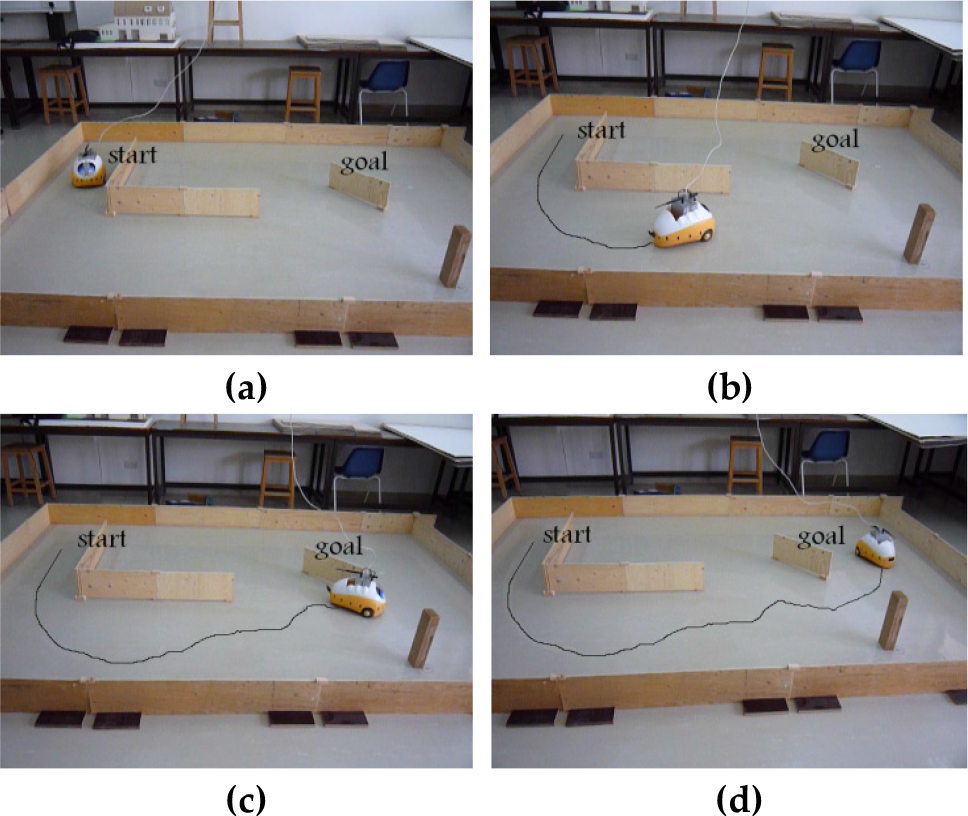
Pekee robot navigates in a real environment with obstacles.
5. Conclusion
In this paper we have shown how Q-learning approach can be used in a successful way of structuring the navigation task in order to deal with the problem of mobile robot navigation. In real mobile robot navigation system there often exists prior knowledge on the task being learnt that can be used to improve the learning process. A navigation approach has been proposed for mobile robot, in which the prior knowledge is used within Q-learning. Issue of individual behavior design were addressed using fuzzy logic (i.e. go to goal, obstacle avoidance, wall following and emergency situations). The strategy of behaviors based navigation reduces the complexity of the navigation problem by dividing them in small actions easier for design and implementation. In our strategy, the Q-Learning algorithm is applied to coordinate between these behaviors, which make a great reduction in learning convergence times. Our simulation and experimental results confirmed that a mobile robot with the Q-learning algorithm proposed in this paper is able to learn and choose the best decision in each situation of its dynamic environment.
Footnotes
6. Acknowledgment
The authors wish to thank SQU University for supporting the work and providing the Pekee robot and all licensed software's. SQU grant number “IG/ENG/ECED/08/02”.