
Abstract
The pathological description of the stage of a tumor is an important clinical designation and is considered, like many other forms of biomedical data, an ordinal outcome. Currently, statistical methods for predicting an ordinal outcome using clinical, demographic, and high-dimensional correlated features are lacking. In this paper, we propose a method that fits an ordinal response model to predict an ordinal outcome for high-dimensional covariate spaces. Our method penalizes some covariates (high-throughput genomic features) without penalizing others (such as demographic and/or clinical covariates). We demonstrate the application of our method to predict the stage of breast cancer. In our model, breast cancer subtype is a nonpenalized predictor, and CpG site methylation values from the Illumina Human Methylation 450K assay are penalized predictors. The method has been made available in the ordinalgmifs package in the R programming environment.
Introduction
Ordinal outcomes, or any outcome with inherent ordering, occur frequently in biomedical data. Examples of these types of ordered responses include severity of depression, grading of adverse events, the Knodell score for liver biopsies, 1 or stage of cancer. Stage of cancer is a pathological description of a tumor, and for breast cancer it considers the following: size of the tumor, number of cells in the tumor, location of tumor with respect to the chest wall and skin, the amount of cancer in mammary, axillary, and sentinal lymph nodes, the number of lymph nodes involved, and the spread of cancer to other organs. 2 Stage of cancer typically determines the course of therapy and is most often ascertained through a biopsy of the cancerous tissue. When modeling stage of cancer, it maybe of interest to predict which response level a patient may exhibit, given some set of explanatory variables. Ordinal regression may be used to model the probability of exhibiting a specific ordinal response, given some set of relevant covariates. However, ordinal regression methods require either that the sample size exceeds the number of features or that all covariate parameters be penalized. It is of interest here to develop a method that allows the model to penalize some covariates without penalizing others (such as demographic covariates).
In our research, we are interested in using high-dimensional methylation data from the Illumina Human Methylation 450K technology, in conjunction with other factors, to predict stage of cancer in a sample of women with breast cancer. Methylation is an epigenetic event that alters gene expression without altering the DNA sequence itself. It is the process by which a cytosine molecule on the DNA strand becomes a 5-methylcytosine through the addition of a methyl group, or a 5-hydroxymethylcytosine through the addition of a methyl group followed by a hydroxy group. Profound methylation changes are known to occur in the context of cancer; well-documented changes include the hypermethylation of tumor-suppressor genes 3 and the hypomethylation of protooncogenes. 4 Specific patterns of methylation exhibited in tumors are thought to not only detect cancer 5 but also predict tumor behavior 6 and illuminate differences and similarities across and within tumor types. 3 Jones and Laird stated that perhaps methylation patterns in cells could serve as “a rough blueprint for the expression profile of that cell” and envisioned that future development of science and technology might produce a useful methylation analysis to generate a “DNA methylation fingerprint for a tumor biopsy.” 7 Studies of methylation patterns in peripheral blood specimens from people diagnosed with cancer have also shown alterations. Of particular relevance, DNA methylation analysis from peripheral blood samples recently identified an association between methylation of the HYAL2 gene and breast cancer, 8 suggesting that methylation patterns in blood might be useful as a screening tool for evaluating tumors in other tissues. Because epigenetic changes, such as methylation, are reversible, identification of specific methylation changes occurring in specific cancers may lead to targeted therapies to return normal function to the cells. 7 Given this evidence, we hypothesized that differential methylation maybe predictive of stage of cancer in women with breast cancer.
Methods
Data
In this paper, we worked with one dataset from a breast cancer study conducted at Virginia Commonwealth University. This research was approved by the Institutional Review Board at Virginia Commonwealth University (VCU IRB #HM 13194) and complied with the principles of the Declaration of Helsinki. Our dataset included 73 women with breast cancer and included baseline clinical and demographic covariates such as estrogen receptor (ER), progesterone receptor (PR), and human epidermal growth factor receptor 2 (HER2) status, age, race (white or African-American), prior breast cancer surgery (lumpectomy, segmental, or simple surgery prior to study enrollment), and smoking status (currently smoking, yes or no). ER, PR, and HER2 status were collapsed into a single, categorical measure of breast cancer subtype, 9 defined in Table 1.
Criteria for breast cancer subtype classification.

Peripheral blood samples were collected at study entry, and DNA was subsequently extracted from these samples using standard methods, bisulphite converted (Zymo Research EZ Methylation Kit), and hybridized to Illumina's Human Methylation 450K array according to the manufacturer's protocol. To assess assay reliability, some samples were hybridized multiple times, resulting in a total of 82 methylation profiles.
The scanned arrays were processed using the minfi
10
Bioconductor package in the R programming environment to obtain the β-values for each probe, where β
ig
represents the proportion methylated for the ith sample and the gth. CpG site, defined here as

Some preprocessing of the methylation data was necessary prior to statistical analysis. Our first preprocessing step was to look at the distribution of β-values by the GC content. This is important because previous research has established that methylation may not be accurately measured in regions of high GC content. 12 Illumina's design for the 450K array includes two separate assays, Type I and Type II, for estimating methylation at a given locus. GC content was calculated as the proportion of the probe sequence comprised of C's and G's and reported separately for Type I and Type II design types. We then examined the boxplots of average β-values (across all samples) by the GC content for each of the assay types separately (Figs. 1 and 2). The resulting boxplots were used to determine a GC proportion cutoff value beyond which methylation seems to no longer be reliably measured. The choice of such a cutoff is clearly subjective, but it is important to remove the CpG sites beyond the cutoff because inclusion of unreliable probes may distort the analysis. We also removed CpG sites within which there were known single nucleotide polymorphisms (SNPs) according to the Illumina-provided annotation files. 11

Boxplot of mean β-values by percent GC content across all samples, for type I probes.
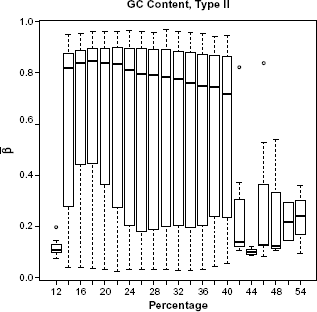
Boxplot of mean β-values by percent GC content across all samples, for type II probes.
The Type I design includes two bead types for each CpG site: one that detects methylated CpG sites, and the other that detects unmethylated CpG sites. The Type II design includes a single bead with a two-color readout; a different color is used to indicate whether the CpG site is methylated or unmethylated. In 2011, Dedeurwaerder et al examined the distribution of β-values produced by Type I and Type II bead types used in the 450K technology.
13
They noted that the distribution of β-values from both bead types, across the whole array, exhibited two distinct peaks, one close to 0 for the unmethylated CpGs and one close to 1 for the methylated CpGs. These peaks, however, when modeled separately by bead type, did not align exactly; the peaks for the β-values from the Type II beads were shifted inwards when compared to the Type I beads. This shift is attributed to the difference in chemistry between the beads and is acknowledged by Illumina in a Technical Note for the 450K technology on their Web site.
14
To correct this issue, we implemented the peak correction method by Dedeurwaurder et al on our β-values as a preprocessing step. This method adjusts the Type II peaks so that they align to the locations of the Type I peaks. The peak correction method uses the M-values and the logit of the β-values
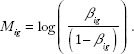
Prior to the logit transformation and peak correction, we modified the β-values slightly by adding or subtracting 0.001 to any β-value exactly equal to 0 or 1, respectively, in order to prevent errors during the logit transformation.
Finally, there were five patients having n1 = 4, n2 = 4, n3 = 2, n4 = 2, and n5 = 2 hybridized samples each. For each of these patients, we averaged the final peak-corrected M-values across the replicate samples and used this single, mean signal for each of these five patients in our analysis. All data analyses were conducted in R (version 3.1.0) utilizing the minfi 10 (version 1.10.2), limma 15 (version 3.16.8), VGAM (version 0.9–4), 16 and ordinalgmifs 17 (version 1.0.2) packages. In our analysis, we used the 450K annotation file version 1.2. 18
Analysis
In genomic research, traditional modeling methods are often inappropriate. Traditional ordinal regression methods, for example, require that the number of predictors (p) be smaller than the sample size (n) and that the predictors be independent. After filtering, our breast cancer study included 353,331 CpG sites and only 73 patients; such a situation, where p >> n, is typical when analyzing high-throughput genomic data. Furthermore, we know that methylation levels of CpG sites in close proximity to one another are highly correlated. To handle these challenges, we implemented penalized regression methods. Penalized regression introduces bias into the model in exchange for reducing variability. 19 The resulting model is sparse, which is an attractive feature when dealing with an overly large predictor space and we are interested in producing a parsimonious model.
There are a variety of algorithms available for finding a penalized solution. One such algorithm is the Incremental Forward Stagewise (IFS) method, which provides the monotone Least Absolute Shrinkage and Selection Operator (LASSO) solution in a linear regression setting. 20 Hastie et al modified and extended the IFS procedure, creating the generalized monotone incremental forward stagewise (GMIFS) method, which provides a penalized solution in a logistic regression setting. 20 Archer et al further extended the GMIFS method to provide the penalized solution in an ordinal regression setting. 21 In our work, we extended the GMIFS algorithm to allow a subset of covariates to be included in the model without penalization.
This so-called no-penalty subset, the subset of demographic variables not penalized, is included in the final model, and the fitting algorithm is not allowed to shrink any of these coefficients to 0. This no-penalty subset option is important in many scientific investigations where some biologically relevant demographic information should be retained in the model, regardless of statistical significance ascribed to the given covariates. For our breast cancer dataset, we fit univariate ordinal response models predicting stage for each of the following: age, race, body mass index (BMI), smoking status, prior surgery related to the management of breast cancer, and subtype, to see which of these will be important for inclusion in the full ordinal model. We conducted a likelihood ratio test (LRT) to obtain the P-values for each of these univariate models. We used a P-value cutoff of 0.05 to determine which demographic covariates were important for inclusion in the no-penalty subset.
Given the large number of CpG sites in the 450K array, we first filtered the M-values by significance in order to reduce the number of penalized coefficients considered by the model. We fit a model with only the demographic covariates found to be important from the previous LRTs and each of the CpG sites individually. We then conducted a series of LRTs between the demographic-only model and each of the CpG site models. Using a liberal P-value threshold of 0.25, we included in the penalized model only those CpG sites with a P-value <0.25. Additionally, we removed CpG sites that were universally unmethylated (β < 0.1) across all samples and those that were universally methylated (β > 0.9) in all samples. Removing these CpG sites constituted no loss of information since all the samples were either fully unmethylated or fully methylated.
The primary outcome measure of interest, as mentioned, was stage of cancer. Stage of cancer is measured as 0—IV and may be further subdivided into 0, IA-B; IIA-B; IIIA-C; and IV The patients in our study, which focused on ascertaining participants with early stage breast cancer, were classified as stage I (n = 21), IIA (n = 29), IIB (n = 15), or IIIA (n = 8). We constructed a response matrix 
We also constructed a matrix of nonpenalized predictors 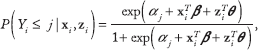

Therefore, the likelihood is given by



The specific steps of the modified GMIFS algorithm to obtain this solution are implemented in the ordinalgmifs package in R. 17 We outline the steps for the cumulative logit form of the model here.
Beginning at step s = 0,
Augment the
We augment the covariate space in this way so that we may avoid calculation of the second derivative to determine the direction of the update. 20
Set all of the β terms to 0 so that
Initialize the α terms as
Holding the β terms fixed, update α and θ by maximum likelihood.
Holding α and θ fixed, find
Update
Repeat steps 4–6 until log L(s+1) − log L(s) < τ, where τ is some small value. We used τ = 0.00001.
Once the algorithm converges, the parameter estimates achieved constitute the “converged model.” For each step of the algorithm, we calculated the log likelihood, Akaike Information Criterion (AIC), and the Bayesian Information Criterion (BIC) for the model at that iteration of the algorithm. AIC and BIC are measures of the relative quality of a statistical model. We then extracted the parameter estimates at the step that minimized the AIC.
The penalized covariates are given by 
The value of s is not specified by the user. Rather, each of the s values corresponds to a specific solution 20 so that both the AIC-selected and the converged model will have an associated s value. Note that this method is an incremental forward stagewise method, which differs from preselecting a tuning parameter, or set of tuning parameters, against which the model is fit, then subsequently selecting the best fitting model by some model-fitting criterion.
For our selected model, we were interested in how the blood methylation values predicted the stage of the actual tumor. For the nonzero coefficient estimates, we investigated whether any of the differentially methylated loci had been previously associated with breast cancer or other types of cancer.
Simulation Study
We also conducted a simulation study to further test the performance of the method. Currently, there exists no comparative method that fits a penalized cumulative logit model, so we have no method against which to test the GMIFS cumulative logit model performance. For our simulation study, we used a sample size of 80 subjects, where 100 predictor variables were generated from a uniform distribution on the [−1, 1] interval. Thereafter, the latent response, 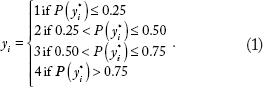
Thereafter, a cumulative logit GMIFS model was fit using X1 as an unpenalized predictor and X2, X3 X4 as penalized predictors and the AIC selected model was examined. This entire process was repeated 50 times. Characteristics of the fitted models examined included the number of times the coefficients for X2, X3, and X4 were nonzero (true positive rate); the number of times the coefficients for X5,…, X100 were nonzero (false positive rate); and the misclassification rate.
Our simulation study indicated that the method performed well. The true positive rate was 100%, as all models returned nonzero coefficient estimates for X 2 , X3 and X4. The median false positive rate was 5.2% (range 0–33%). The median misclassification rate was 13.75% (range 1.25–30.00%).
Results
Table 2 provides an overview of the distribution of the continuous and binary demographic covariates by stage of cancer. Table 3 provides the distribution of the multi-level categorical covariate.
Demographic characteristics by stage of cancer. The medians are reported for continuous variables (age and BMI) and the frequencies are reported for categorical variables (race, smoking status, and prior surgery).

Frequencies of breast cancer subtype by stage of cancer.

The original, unfiltered data had 485,512 CpG sites. The boxplots of GC content by CpG site (Figs. 1 and 2) indicate that methylation may not be accurately measured beyond 42% for Type I probes or beyond 40% for Type II probes. After examining these boxplots, we chose the more conservative of the two values and excluded CpG sites with greater than 40% GC content from further analysis. This GC content filtering criteria removed 52,077 CpG sites, leaving 433,435 CpG sites. Next we removed the 80,104 CpG sites that included SNPs, leaving 353,331 CpG sites. There were 1,742 β-values exactly equal to 0, while none were exactly equal to 1. We imputed those equal to 0 to be 0.001 before applying the logit transform. After this, we applied the peak correction method to align the Type II peaks to the locations of the Type I peaks. An LRT was conducted for each of the demographic covariates comparing the intercepts-only model to each of the univariate models when fitting cumulative logit models to predict stage of cancer. The results of these tests are given in Table 4.
LRT and resulting P-values from univariate cumulative logit models predicting stage of cancer.

In the interest of developing a parsimonious model, we used a P-value cutoff of 0.05. At this significance level, it was clear that only subtype (eg, Luminal A; Luminal B; HER2+; triple negative) was significantly related to stage of breast cancer in this univariate sense. A similar LRT was conducted for each of the 353,331 CpG sites using the filtered, peak-corrected β-values. The model for the LRTs included only the demographic variable for cancer subtype. After excluding CpG sites with P-values greater than 0.25, 103,001 CpG sites remained. Finally, after excluding CpG sites for which the β-value was <0.1 or >0.9 in all samples, 27,110 CpG sites remained. The ordinal cumulative logit GMIFS model was fit to the subtype covariate as a nonpenalized predictor and to the M-values for the 27,110 CpG sites as penalized predictors. The model attaining minimum AIC included 35 nonzero CpG sites (Table 5), while the fully converged model estimated 107 nonzero CpG sites. Subsequently, we ran the model again, this time filtering to exclude CpG sites with P-values greater than 0.05. Fitting the same GMIFS model to this smaller set of CpG sites resulted in exactly the same parameter estimates and class predictions as the previous model, which used a P-value cutoff of 0.25.
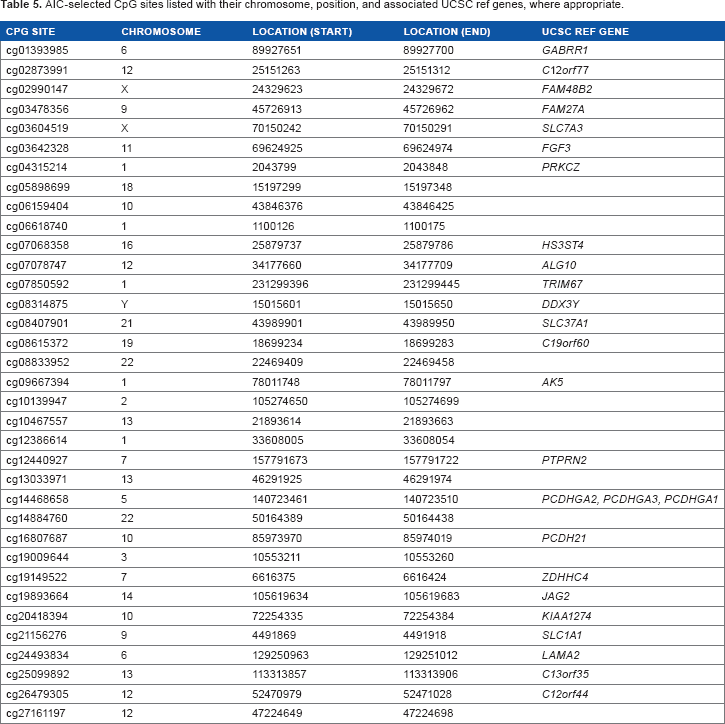
AIC-selected CpG sites listed with their chromosome, position, and associated UCSC ref genes, where appropriate.
Boxplots (Figs. 3 and 4) are shown for the two CpG sites from Table 5 with the largest absolute coefficient. The plots display the distribution of β-values for all subjects according to stage of cancer. The β-values for cg19149522 (ZDHHC4) seem to be monotonically decreasing, while the β-values for cg16807687 (PCDH21) seem to be monotonically increasing.
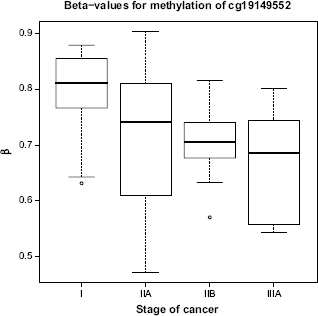
Boxplot of β-values for CpG site cg19149522 (ZDHHC4), for ail subjects, by stage of cancer.

Boxplot of β-values for CpG site cg16807687 (PCDH21), for all subjects, by stage of cancer.
The fully converged model predicted the stage without error, while the minimum AIC model had an error rate of 15.1%. Table 6 shows the cross-tabulation of observed versus predicted class. The fully converged model was without error; however, it included 107 nonzero parameter estimates indicating that it is likely overfit. The AIC model was less accurate for prediction, particularly for patients with stage IIIA cancer. This is likely due to the fact that our patient sample is unbalanced across the stages and is biased toward stages I–IIB.
Cross-tabulation of the observed (rows) versus predicted (columns) class for the AIC and the fully converged models.

Discussion
In this paper, we presented an ordinal response model for high-dimensional covariate spaces that allows the inclusion of nonpenalized covariates, penalized covariates, or both. This method can be applied to any cumulative link, forward continuation ratio, backward continuation ratio, adjacent category, or stereotype logit model using the ordinalgmifs R package. 17 While the fully converged model had 100% accuracy in predicting stage of cancer, there were several misclassifications for the AIC-selected model. This may be partially attributed to the imbalance and small class size, particularly for stage IIIA. However, several of the CpG sites included in the models were located within genes that have previously been associated with breast cancer. AK5, PTPRN2, LAMA2, FGF3, SLC37A1, and SLC1A1 have all been previously associated with breast cancer.22–28 SLC7A3, PRKCZ, JAG2, GABRR1, DDX3Y, and PCDHGA3 have been previously associated with other types of cancer.29–34 Our results, which agree with previously published results, indicate that methylation patterns of the tumor itself may impact the methylation patterns present in peripheral blood. Development of a model that can accurately predict stage of cancer from DNA methylation or other genomic profiles from peripheral blood samples and demographic information may have important healthcare implications. We hope that our work here will help future development of less invasive, less expensive methods for determining the stage of cancer.
Author Contributions
Conceived of this study: KJA. Planned the data collection and subject recruitment: CKJC, DEL. Analyzed the data: AEG, KJA. Wrote the first draft of the manuscript: AEG. Contributed to the writing of the manuscript: CKJC, DEL, KJA. Agree with manuscript results and conclusions: AEG, CKJC, DEL, KJA. Jointly developed the structure and arguments for the paper: AEG, KJA. Made critical revisions and approved final version: CKJC, DEL, KJA. All authors reviewed and approved of the final manuscript.
Footnotes
Acknowledgments
Research reported in this publication was supported by the National Library of Medicine of the National Institutes of Health under Award Number R01LM011169. Data collection was supported by the National Institute of Nursing Research of the National Institutes of Health under Award Number R01NR012667. Support was also provided under award number R25DA026119 from National Institute on Drug Abuse. Services in support of the research project were generated by the VCU Massey Cancer Center Biostatistics Shared Resource, supported, in part, with funding from NIH-NCI Cancer Center Support Grant P30 CA016059. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.