
Abstract
The problem of selecting important variables for predictive modeling of a specific outcome of interest using questionnaire data has rarely been addressed in clinical settings. In this study, we implemented a genetic algorithm (GA) technique to select optimal variables from questionnaire data for predicting a five-year mortality. We examined 123 questions (variables) answered by 5,444 individuals in the National Health and Nutrition Examination Survey. The GA iterations selected the top 24 variables, including questions related to stroke, emphysema, and general health problems requiring the use of special equipment, for use in predictive modeling by various parametric and nonparametric machine learning techniques. Using these top 24 variables, gradient boosting yielded the nominally highest performance (area under curve [AUC] = 0.7654), although there were other techniques with lower but not significantly different AUC. This study shows how GA in conjunction with various machine learning techniques could be used to examine questionnaire data to predict a binary outcome.
Introduction
High-dimensional datasets provide many mathematical and statistical challenges, as well as some opportunities, and will likely lead to novel theoretical developments. A major challenge of dealing with high-dimensional datasets is that, in many cases, not all the measured variables are considered important for understanding the underlying phenomena of interest. 1 While certain computationally expensive techniques 2 can construct predictive models with considerable accuracy from high-dimensional data, reduction of these data prior to modeling is a separate problem that has received recent attention. Genetic algorithms (GAs), in particular, provide an attractive approach to reduce such a dataset. 3 The GA method, compared to other popular methods, offers a wider solution space; handles noisy functions well; handles large, poorly understood search spaces easily; and can be easily modified for different problems. 4
Over the years, GA methodology has evolved, as has the range of its applications. GAs have been employed in searching for the best subset of single nucleotide polymorphisms (SNPs) associated with a phenotype,5–10 searching for the shortest route and multiple semishortest routes in one search, 11 and prediction of small molecule binding modes to macromolecules. 12
Surveys and questionnaires are widely used in various areas of research, especially in health-related fields, as they provide a relatively efficient method of sampling many individuals in an inexpensive and less obtrusive manner.13,14 Questionnaires have been used to study musculoskeletal, psychological, cardiovascular, and other disorders,15–21 and as the popularity of questionnaires has grown, so has the potential for new understanding via advanced statistical techniques such as GA. Although GA has been successfully applied to questionnaire variable selection in the context of family medicine, stressful life events, 22 and sleep apnea diagnosis, 23 its application to the selection of questionnaire data for predictive modeling of disease outcome is relatively novel. Outside biomedical research, Madden utilized GAs in the analysis of questionnaire data to ascertain students’ attitudes toward their schoolwork, showing that GAs may be used to generate logical rules, which predict one variable in relation to others. 24 Additionally, Yukselturk et al applied GA in predicting student dropout utilizing only 10 variables. 25
GAs use a heuristic search and optimization method inspired by natural evolution and have been successfully applied to a wide range of complex real-world problems. Beginning with a randomly generated population of chromosomes (potential solutions), the algorithm carries out a process of fitness-based selection in which the parent chromosomes are recombined to generate a successor population. The process is iterated, evolving a sequence of successive generations, until the average fitness of chromosomes increases to reach a stopping criterion. Thus, GAs evolve a best solution to a given problem according to the specified fitness function. 26 The detailed theories behind GA are beyond the scope of this article but are discussed in other publications.27–29
In our study, GA was used to select questions from the 1999 to 2000 National Health and Nutrition Examination Survey (NHANES) most predictive of five-year mortality as indicated in a follow-up survey. Specifically, GA selected the top 24 questions from an initial 123 variables. Utilization of these 24 variables and selected variable subsets for predictive modeling, using five-year mortality as the outcome of interest, was carried out using a variety of machine learning methods, including gradient boosting, artificial neural network (ANN), elastic net, support vector machine (SVM), ridge regression (RR), logistic regression, random forest, least absolute shrinkage and selection operator (LASSO), partial least squares-discriminant analysis (PLS-DA), and classification trees (implemented in the R package RPART [recursive partitioning and regression trees]). All of these techniques yielded optimum results when all 24 variables were included in the analysis, with gradient boosting demonstrating the best nominal performance.
Methods
Variable quality control and imputation
Participants with linked mortality data from the NHANES (1999-2000) were included in the study (Table 1). The NHANES is designed to monitor the health and nutritional status of the American civilian population using annual interviews and medical examinations. Mortality data were accessed from the National Death Index (NDI) with an end point of December 2006.
30
The 1999-2000 NHANES questionnaire data initially included a heterogeneous cohort of 9,965 individuals who answered 2,058 questions (variables), 5,444 of whom had available five-year mortality data and were included in the current study (412 cases/5,032 controls) (Table 1). Variables with > 30% missing information or zero variance were removed from the analysis, as were groups of highly collinear variables. All data were transformed to an integer scale with uniform directionality, with higher numerical responses indicating poorer health status. For variables where directionality was not explicit, the order was inferred from factors known to contribute to mortality. Variables that could not be transformed in this manner were removed, generating 123 variables to be used in our final analysis. Missing information for the remaining variables was imputed using Amelia II as required for implementation of GALGO GA software in R.31,32 Amelia II imputes missing values using the expectation-maximization (EM) with bootstrapping algorithm. The algorithm utilizes the familiar EM algorithm on multiple bootstrapped samples of the original incomplete data to draw values of the complete-data parameters.
31
Historically, the rule of thumb for multiple imputations is to use
Demographics of questionnaire respondents with available five-year mortality data.

Non-Hispanic.
The data were then randomly divided into 70% training (3,810 individuals [288 cases/3,522 controls]) and 30% testing (1,634 individuals [124 cases/1,510 controls]) sets. GA was performed in the training set using the procedure described in the following section. The predictive ability of the variables selected by the GA was then determined in an independent testing set.
Genetic algorithm
GA is a feature selection method that identifies variables that are most likely predictors of a given binary outcome. The procedure starts by generating a random population of variable clusters. These clusters, or chromosomes, are then assessed for their ability to accurately predict the binary outcome using a nearest centroid fitness function, which has been found to outperform other multivariate selection functions, including random forests and SVMs, when paired with GA. 32 In general, the initial variable cluster is mutated to form a new cluster of variables with higher classification accuracy, and the process is repeated until a desired level of accuracy is achieved.28,32 GA is advantageous in that during the exploration of the space of possible solutions, it does not evaluate solutions one by one but evaluates a set of solutions simultaneously. Moreover, it is less prone to entrapment within local minima and does not require assumptions about the interactions between features.34,35 To overcome the inherent problems of randomized algorithms, however, it is occasionally proposed that GA be run multiple times on a given optimization problem to provide the best solution. 36 Thus, we implemented 10 GA iterations to select NHANES questionnaire variables predictive of five-year mortality and considered the average output of GA. Further information about GA can be found in several references.4,27–29
Machine learning techniques
The optimally selected variables from the GA were then used to build predictive models using various machine learning techniques, including gradient boosting, ANN, elastic net, SVM, RR, logistic regression, random forest, LASSO, PLS-DA, and Classification Trees, with optimized parameters (Table 2). These algorithms were then compared to determine the technique and set of variables demonstrating the most accurate prediction. All machine learning technique calculations were performed using various R packages under R version 3.1.2.37–45 While the intent of this article is to compare the predictive performances of various machine learning algorithms, we also provide some background about these methods to assist the readers.
Fine-tuning parameters for ANN, gradient boosting, SVM, PLS-DA, elastic net, and random forests to achieve the highest AUC values in the test set (

Gradient boosting
This is a general method for improving the accuracy of any given learning technique. In this approach, the goal is to approximate the functional relationship between independent variables and the outcome variable by minimizing some prespecified loss function. This process involves the combination and weighting of many relatively weak or inaccurate rules (usually decision tree models) to produce an ensemble predictor with higher predictive accuracy. 46
Artificial neural network
Artificial neural networks are a family of machine learning techniques that are modeled after biological networks of neurons. This technique attempts to infer the relationship between a set of inputs and an outcome of interest by using learning algorithms to assign numeric weight to each input measurement. The sum of the weighted inputs is used for outcome prediction. 47
Elastic net
This technique combines the LASSO and ridge penalties, yielding an intermediate penalty with typically fewer regression coefficients approximating to zero than LASSO. Like LASSO, it is particularly useful for variable selection in high-dimensional settings, producing sparse models that preserve predictive power and encourage grouping of correlated predictors. 48
support vector machine
This algorithm involves projection of the data points in a training set with
Ridge regression
This method is an extension of classical regression that involves imposing a constraint on the sum of the squares of the regression coefficients such that they do not exceed a chosen tuning parameter. The effect of this is to shrink the regression coefficient estimates to small, nonzero values. This approach exploits the bias-variance tradeoff, reducing variance of the coefficient estimates by increasing their bias. This shrinkage of coefficients prevents overfitting by compensating for the variance inflation that occurs due to multicollinearity. This technique is particularly powerful for high-dimensional problems. 50
Logistic regression
This simple method is a special case of generalized linear models that evaluates the dependence of a binary variable on one or more independent variables using maximum likelihood techniques. It is intrinsically simple and valuable in solving binary classification problems. 51
Random forest
This algorithm involves constructing a collection of decision trees using rule-based classification or regression methods. Each tree is constructed from a bootstrap sample extracted from the training set and is developed independently of others. A large number of trees constructed this way are used to form an ensemble (known as a forest) that collectively votes to optimally classify input vectors.2,52
LASSO regression
Like RR, this method is an extension of classical regression but uses a different penalty. This penalty involves constraining the sum of the absolute values of the regression coefficients such that they do not exceed a chosen tuning parameter. Unlike RR, some coefficients may shrink to zero, making LASSO especially useful for variable selection problems. The result is a set of solutions that are shrunken versions of the typical least-squares estimates as in the case of linear regression, compensating for overfitting that may occur in the presence of multicollinearity, or in high-dimensional settings. 53
Partial least squares-discriminant analysis
In PLS-DA, the goal is to reduce the dimensionality of data with a large number of input variables, while simultaneously accounting for membership in classes representing categories of some discrete (eg, binary) outcome. Dimension-reduction is carried out by the construction of new variables (referred to as latent variables) using linear combinations of the input variables. The linear combinations are generated in such a way as to maximize correlation of the latent variables with the categorical outcome. This resulting model can then be used to carry out predictions for new samples. 54
classification trees
This is a powerful, intuitive non-parametric technique that involves binary recursive splitting of a training set into increasingly homogeneous subsets using the input variables. This produces a tree-like construct (known as a decision tree) that, after being optimized, can be used to categorize new samples. 55
Assessing model performance
Given a binary classification that can be positive or negative, the area under the receiver operating characteristic curve (area under curve [AUC]) measures the probability that a prediction method will rank a randomly chosen positive sample over a randomly chosen negative sample. Thus, AUC = 1 represents a perfect model and AUC = 0.5 represents a model that yields no advantage over random guessing. AUC is useful in that it is calculated from the direct value output of a prediction method across all thresholds rather than the binary output dependent upon threshold placement. Additionally, it does not vary with the distribution of class labels in the sample set.
56
We implemented the
Results and Discussion
From an initial 2,058 variables (questions), 123 remained after excluding variables with > 30% missing information, zero variance, or collinearity (Table 3). Data from this initial preprocessing were then subjected to imputation using Amelia II as required for the GA analysis using GALGO.31,32
Breakdown of variables used in the analyses.

GA was performed using the 123 variables (ie, questions, Supplementary Table 1) and the training set consisting of 3,810 individuals. The default configuration shows three plots summarizing the characteristics of the population of selected chromosomes (Supplementary Fig. 1) or, within the context of our study, variable clusters. The topmost plot shows the number of times each gene (ie, question/variable) is present in a stored chromosome. By default, the top 50 genes are colored, whereas the top 7 are labeled (variables 24, 27, 55, 59, 60, 90, and 118). From the plot (Supplementary Fig. 1, top), it is apparent that variable 60 was included most frequently in the stored chromosomes, followed by variables 90 and 59. Also frequently included were variables 24, 27, 55, and 118. Once the top-ranked genes are stabilized, a second plot shows the stability of the rank of the top 50 genes (Supplementary Fig. 1, middle), aiding in the decision of whether or not to continue the process further. Unstable genes that demonstrate inconsistent rank or importance are indicated by numerous colors besides black and gray. Commonly, the top 7 black genes are stabilized quickly, in 100-300 solutions, whereas low-ranked gray genes would require thousands of solutions to be stabilized. Again, the top 7 aforementioned variables were the most highly ranked in this GA run, suggesting that they are the most important questions for predicting mortality. Finally, the bottom plot displays the distribution of the number of generations needed by the GA process to produce a solution (Supplementary Fig. 1), indicating how difficult the search problem is for the configuration of GA.
Before further analysis and refinement were performed, we first determined whether we were getting acceptable solutions. The success of the configured GA search can be determined by looking at the evolution of the fitness value across generations. On average, GA reached a solution in generation 4, which indicates an excellent result (Supplementary Fig. 2). The blue and cyan lines show the average fitness for all chromosomes and for those that have not reached a goal, respectively. These lines delimit an empirical confidence interval for the fitness across generations. The characteristic plateau effect is useful to decide whether or not the search is working effectively to reach our goal, which is marked with a dotted line. In general, our result indicates that we have achieved a stable solution within early generations.
Stochastic searches such as the GA are very efficient methods to identify solutions to an optimization (ie, classification) problem. However, they only explore a small portion of the total model space. The starting point of any GA search is a random population. This implies that different searches are likely to provide different solutions. As such, in order to extensively explore the entire space of models, it is critical to collect a large number of chromosomes. GALGO offers a diagnostic tool to determine when the GA searches reach some degree of convergence. This analysis is simply based on the frequency with which each gene (ie, question) appears in the chromosome population. As chromosomes (ie, variable clusters) are selected, the frequency of each gene in the population changes until no new solutions are found.
32
Thus, we monitor the stability of gene ranks based on their frequency as a way to visualize model convergence (Supplementary Fig. 3). The most frequent 50 genes (ie, questions) are shown in eight different colors with about six or seven genes per color. The genes are ordered by rank along the horizontal axis, while the vertical axis indicates gene frequency (top portion of
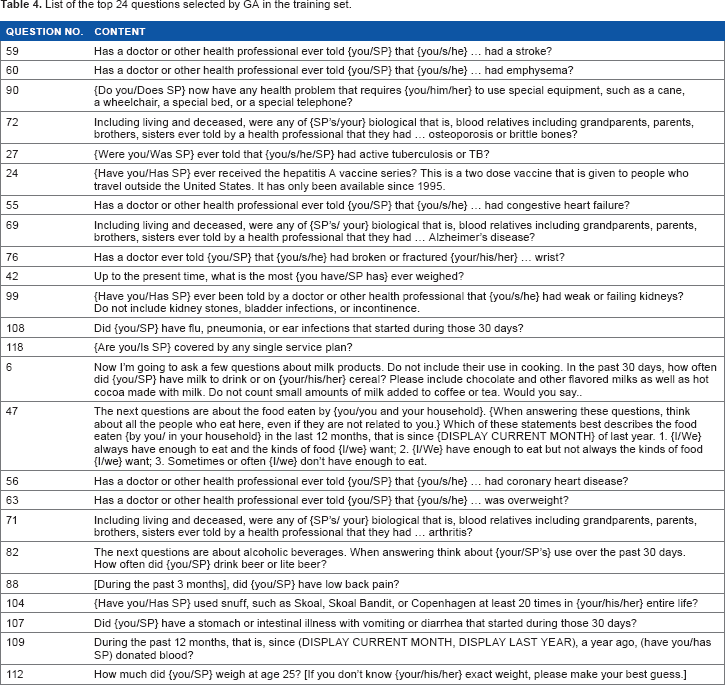
Ten GA iterations using the training set data were performed using 123 questions, and each run generated seven questions, with some overlapping results. Multiple GA runs were used because multiple isolated iterations are more advantageous than a single GA run and reach the global solution using fewer function evaluations. 58 From the initial 123 variables, GA output the top 24 questions for predictive modeling strategies (Table 4). Investigation of the most stable results (black color coded genes, Supplementary Fig. 3) shows that questions 90, 59, and 60 are the most frequent variables appearing in each of the GA iterations (Table 5). Variable 90 is a question regarding health problems that require the participant to use special equipment, such as a cane or a wheelchair; variable 59 is a stroke-related question; and variable 60 is an emphysema-related question. Physical disabilities often require the use of special equipment. 59 Persons with disabilities also have higher rates of hospitalization and emergency department use, yet they have more problems with health care access than those without disabilities. 87 It is reasonable, then, that variable 90 can serve as a probable predictor of an individual's five-year mortality. Stroke, on the other hand, is the leading cause of mortality and morbidity in developed countries, 60 and stroke survivors often face ongoing mortality risks and stroke recurrence. 61 In fact, it has been shown that the five-year survival rate after a single stroke is only 29%, 62 supporting our evidence for variable 59 as a five-year mortality predictor. Lastly, emphysema, an obstructive pulmonary disease characterized by the destruction and weakening of the alveolar walls, has been found in its advanced stages to influence mortality significantly. 63 Thus, this validates our assessment of variable 60 as a predictor of five-year mortality.
List of the top 24 questions selected by GA in the training set.
Selection frequency of questions in 10 GA iterations.
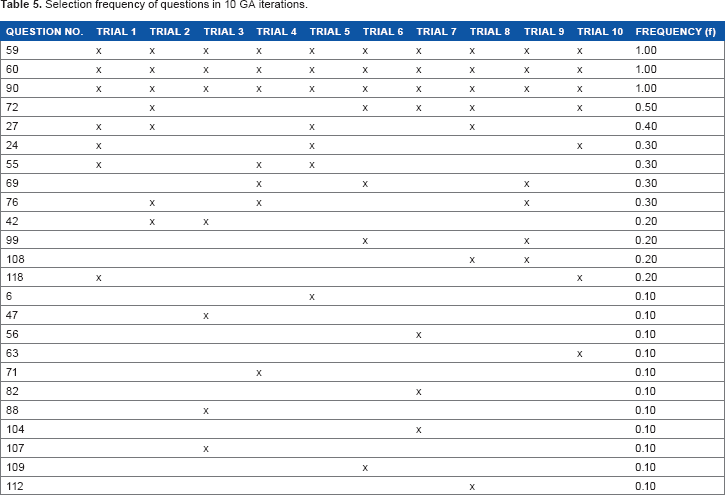
The GA methodology provides a large collection of variable clusters. However, even though these are indicated as adequate solutions, it is unclear which variables should be chosen for developing a classifier, that is, which of the questions are of significant biological interpretation or clinical importance. It is essential, then, to develop a model that is representative of the population. We accomplished this by using the frequency of questions in the population of variable clusters as the criterion for inclusion in our predictive modeling strategies. Prior to implementing these machine learning techniques, we first tested the predictive ability of the top variables using the default strategy of forward selection in GALGO. Using the forward selection method, GALGO generated only two representative models. The first model generated two genes (ie, questions), with variables 90 and 59, while the second model generated three genes with variables 90, 59, and 60. Clearly, these indicate the potential of implementing these variables for predictive modeling.
All questions (
AUC values of different algorithms using the top 24 questions generated by GA and selected subsets based on selection frequency (

DeLong's test comparing AUCs to that of the top performing technique (gradient boosting, AUC = 0.7654) using the top 24 questions.
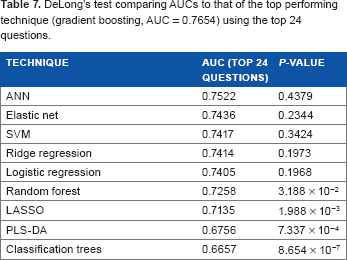
Fourteen questions used in PLS-DA after removing those with zero or near zero variance from the initial 24 variables (AUC = 0.6756).

We also considered subsetting variable clusters based on the frequency of their selection by GA. Owing to the aforementioned constraints on variable inclusion in PLS-DA, it was not performed with the smaller variable subsets. Utilizing the 13 most frequently selected variables, gradient boosting still garnered the best AUC performance (AUC = 0.7371), using 10,000 trees and allowing an interaction depth of one unit as the optimum parameter. Conversely, Classification Tree was still the least optimal technique (AUC = 0.6657) (Table 6). We further subset and analyzed the top nine most frequently selected variables and found ANN as the best performing technique (AUC = 0.7154), using 50 hidden layers and a 0.04 decay parameter. ANN was also the top performing technique (AUC = 0.6714) after further downsizing to include only the five most frequently selected questions, using three hidden layers and a 0.04 decay parameter. All of our ANN analyses utilized 200 maximum iterations as the optimum parameter. Finally, our analysis using the three most frequently selected variables yielded similar AUC values with 5 out of 10 techniques, including gradient boosting, ANN, elastic net, RR, and logistic regression (AUC = 0.6629). LASSO also performed quite similarly (AUC = 0.6628), while Classification Trees again yielded the poorest performance (AUC = 0.6470) (Table 6). It should be noted that despite tuning various parameters in each of these machine learning techniques, the AUC values converged similarly to a common value of -0.6629 in 50% of all algorithms when only the three most frequently selected variables were considered.
It is also important to observe that the AUC values decrease as fewer variables are considered in the analysis, suggesting that even the variables selected less frequently by GA contribute to predictive capability. Thus, the use of all 24 selected variables allowed for the best performance overall and gradient boosting in particular provided the most accurate model.
Gradient boosting ensemble classifiers are a family of powerful machine learning techniques that have shown considerable success and flexibility in a wide range of applications.65–68 The high flexibility of this technique can be attributed to its high degrees of freedom, which make the choice of the most appropriate loss function a matter of trial and error. 88 Thus, it is unsurprising that boosting performed so well in our study, as it has in other classification and prediction tasks.69–73 To fully understand the current study, however, it is important to note that no machine learning technique will perform best in all settings and that even traditional statistical approaches may outperform learning algorithms in some cases.74,75 The performance of statistical and machine learning techniques is dependent on the population and outcome of interest, the availability and dimensionality of variables,76,77 and the criteria used to evaluate algorithm performance. 78 Consequently, studies comparing machine learning techniques for various classification and prediction tasks have produced heterogeneous results. For example, while LASSO fared relatively poorly in our study, it has performed optimally compared to other machine learning algorithms in various settings.79–81 It has been shown, however, that LASSO provides better prediction in high-dimensional orthogonal problems with few true predictors, while RR and elastic net can effectively handle many variables with moderate predictive power. 89 Since our analysis only included variables suggested by GA to have some degree of predictive power, LASSO performance suffered while RR and elastic net had a slight advantage. The relatively accurate performance of ANN, too, may be attributed to its ability to handle complex or nonlinear relationships between variables, as are often encountered in predicting health outcomes.82,83 Decision tree-based methods (random forests and classification trees) yielded suboptimal performance in our study, likely due to the size and complexity of the training set, which can confound tree construction and reduce node purity. 84 Classification trees performed most poorly, however, likely due to the added tendency of individual decision trees to overfit in large training sets. 85 PLS-DA, on the other hand, is capable of handling more complex problems, 86 but its performance likely suffered from the limited number of variables utilized by the technique.
The optimization of questionnaire variable selection and the ability to construct predictive models using selected variables represent a promising enterprise for researchers and clinicians alike. With techniques such as those employed in our study, interesting questions may be posed regarding the importance of variables for understanding a certain outcome, enabling rational questionnaire design and improved diagnostic or prognostic capabilities. However, independent validation is needed before such methods are integrated into everyday clinical practice. Additionally, to optimize predictive reliability, machine learning techniques must be chosen according to the characteristics of the population and variables in question, as illustrated in our study.
We also explored the interdependency of our variables by implementing a gene interaction network model in GALGO. In Supplementary Figure 4, the numerical values 1 through 7 (coded in black) represent the seven most highly ranked or most prioritized variables (questions 59, 60, 90, 72, 27, 24, and 55 represent numerical values 1-7, respectively) from our earlier GA stochastic search analyses. This figure illustrates the interdependency of these top-ranked variables, with line thickness representing the relative dependency strength. The figure suggests that the top seven questions are, for the most part, independent of each other. It is shown, however, that numerical values 3 (question 90) and 5 (question 27), and 2 (question 60) and 6 (question 24) show strong interdependence, perhaps implying that such questions may cluster together in multivariate models. Further detailed investigation and explanation regarding these interactions are the next steps to follow in this study.
Conclusion
This study provided a novel examination of GA as a useful tool for variable selection in the context of questionnaire data. From an initial set of 123 variables, GA selected 24 variables from the NHANES for use in predictive modeling of five-year mortality with machine learning techniques. This study was uniquely comprehensive in its consideration of such techniques, and gradient boosting performed most optimally (AUC = 0.7654), significantly outperforming random forest, LASSO, PLS-DA, and Classification Tree techniques (
Author contributions
Conceived and designed the experiments: GGD. Analyzed the data: GGD, LJA, GB. Wrote the first draft of the manuscript: GGD. Contributed to the writing of the manuscript: GGD, LJA, GB. Agree with manuscript results and conclusions: GGD, LJA, GB. Jointly developed the structure and arguments for the paper: GGD, LJA, GB. Made critical revisions and approved the final version: GGD, LJA, GB. All authors reviewed and approved the final manuscript.
supplementary Materials
Footnotes
Acknowledgments
We would like to acknowledge the NHANES and the NDI for providing the data.