
Abstract
BACKGROUND:
With the rapid growth of Deep Neural Networks (DNN) and Computer-Aided Diagnosis (CAD), more significant works have been analysed for cancer related diseases. Skin cancer is the most hazardous type of cancer that cannot be diagnosed in the early stages.
OBJECTIVE:
The diagnosis of skin cancer is becoming a challenge to dermatologists as an abnormal lesion looks like an ordinary nevus at the initial stages. Therefore, early identification of lesions (origin of skin cancer) is essential and helpful for treating skin cancer patients effectively. The enormous development of automated skin cancer diagnosis systems significantly supports dermatologists.
METHODS:
This paper performs a classification of skin cancer by utilising various deep-learning frameworks after resolving the class Imbalance problem in the ISIC-2019 dataset. A fine-tuned ResNet-50 model is used to evaluate the performance of original data, augmented data, and after by adding the focal loss. Focal loss is the best technique to solve overfitting problems by assigning weights to hard misclassified images.
RESULTS:
Finally, augmented data with focal loss is given a good classification performance with 98.85% accuracy, 95.52% precision, and 95.93% recall. Matthews Correlation coefficient (MCC) is the best metric to evaluate the quality of multi-class images. It has given outstanding performance by using augmented data and focal loss.
Introduction
Nowadays, skin cancer is growing as the most hazardous type of cancer. As per the World Health Organization (WHO), every year more than 5.6 million new cases are identifying in the United States (US), and skin cancer occurs in one in every three cancer patients [1]. in skin cancer, melanoma is aggressive cancer; it occurs in 4% of the world’s population out of this, 75% of people cause death [2]. The crucial step is to detect or identify melanoma in an initial stage. The five-year survival rate is 98% in the starting stage, falling to 18% in the last stage. At the early stage, the cancerous cells are in the top layer of the skin only later abnormal cells penetrate the deep layers of the skin [3]. Dermatologists cannot identify the type of disease by the visual inspection of the naked eye in all cases, so they use a skin biopsy or histopathological examination. These approaches are so expensive and consume more time for diagnosis of disease. Sometimes an expert dermatologist uses the ABCDE properties for the analysis of lesions such as Asymmetry, Border, Color, Diameter and finally, Evolution but it requires a highly knowledgeable and more intensive dermatologist because only less than 60% of dermatologists only identify the diseases so accurately [4]. To support dermatologists for the early detection of cancer, it is crucial to design a highly automated and effective diagnostic tools. Clinical experts use dermoscopy to examine benign or pigmented lesions because it is a non-invasive diagnosis tool. To examine the cancerous cells, present in the deeper layers, the development of computer vision is required.
The growth of Computer Aided- Diagnosis (CAD) helps detect cancer in an early stage. Compared with the existing models, CAD approaches save time and manual effort. For this purpose, the development of AI techniques can be helpful in increasing the survival rate [5]. Initially, CAD models are developed to diagnose dermoscopy images as benign or malignant. Later, more research was tried to carry out the most challenging problems related to dermoscopy images. Machine learning algorithms with handcrafted features give the best performance for binary classification, but the biggest Problem with Machine Learning algorithms are required human-engineered features. In the last 10 years, deep learning models are becoming more popular due to their automatic feature extraction. Deep learning algorithms performs well for both binary and multi-class classification than conventional models. Still, many researchers have not produced better results for multi-class classification of skin cancer. The most significant advantage of Deep Learning models is to extract the features automatically by considering the lesion’s texture, shape, size and color [6].
Mostly, three types of skin cancers will affect the skin: Basal Cell Carcinoma (BCC), Squamous Cell Carcinoma (SCC) and Melanoma. Generally, BCC is less harmful, grows too slowly and does not spread to any other organs of body. Squamous cell carcinoma (SCC) develops at the top or middle layer of the skin but not into the deeper layer. SCC is not life-threatening, even though aggressive. Melanoma is becoming the most dangerous type of skin cancer caused due to the production of melanocytes when exposed to UV rays [7]. Based on the skin-damaging tendency, most researchers will say Basal & squamous cell carcinomas are benign and melanocytic cancer is malignant because the abnormal melanocytic cells penetrate the inner layers of the skin. To develop the research, every year International Skin Imaging Collaboration (ISIC) conducts the competition for producing the various types of skin lesions. These datasets are becoming a leading repository for the analysis of skin cancer malignancy in medical image processing. ISIC-2019 dataset contains eight classes of different skin lesions such as Actinic Keratosis (AK), Benign Keratosis (BKL), Basal Cell Carcinoma (BCC), Dermatofibroma (DF), Melanoma (MEL), Melanocytic Nevus (NEVUS), Squamous Cell Carcinoma (SCC) And Vascular Lesion (VASC). The sample images of each class are shown in Fig. 1.
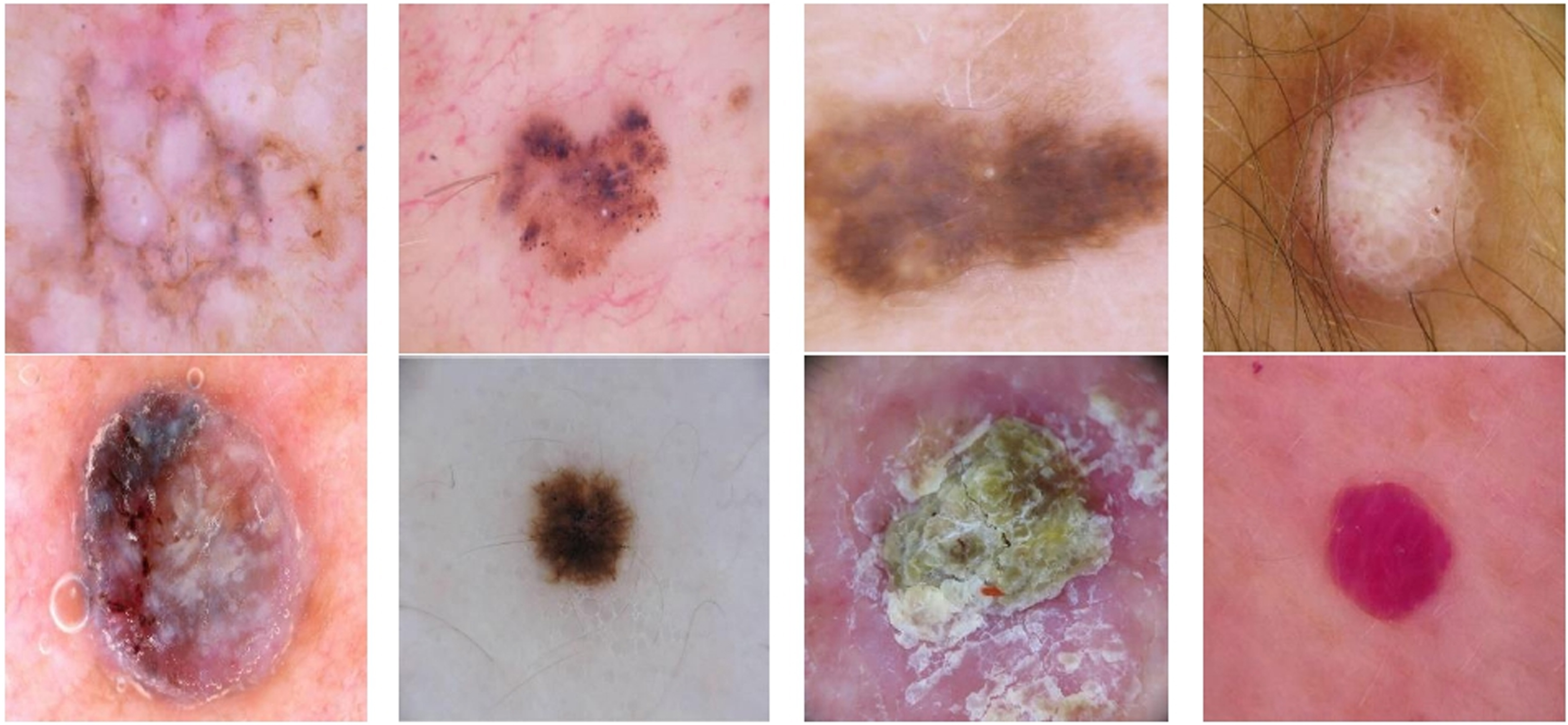
Different skin lesions from left to right and top to bottom are AK, BKL, BCC, DF, MEL, NEVUS, SCC and VASC.
Deep Convolutional Neural Networks (DCNN) is one of the best artificial intelligence algorithms for classifying medical images. ResNet-50 is an effective model for the classification that contains 48 convolutional layers, one max pooling layer and one average pooling layer. Moreover, it contains the residual blocks and skip connections to train the very deeper layers. ResNet maintains a lower error rate for much deeper networks and avoids the vanishing Gradient problem [8].
Deep Neural Networks require massive data for training and are prone to overfitting because the model is too fit for the training data [9]. Data augmentation, Early stopping, dropout, and regularization techniques can be used to reduce overfitting. Data augmentation is the best method to generate artificial images to reduce overfitting. Class imbalance also leads to overfitting. To fix the class imbalance problem, the focal loss is the best practical method that downsizes the weights of large data classes and focuses on the fewer data classes. Focal loss (FL) is an improvised model of cross-entropy (CE) loss that assigns the weight factors to the all-hard classes to improve classification accuracy.
This paper majorly focuses on the following. Recent and highly imbalanced ISIC-2019 skin cancer dataset is used for multi-class classification. In this dataset, some classes are severely out of number with other classes, which leads to overfitting. First, experimental analysis has been carried out to handle the imbalanced datasets to reduce overfitting. By using augmentation and focal loss, overfitting is reduced. Though augmentation techniques are used, still the classes are highly imbalanced. Focal loss is also added, which is the best method to handle the hard misclassified samples with their weights. Finally, ResNet-50 has been used for the classification of skin cancer. Unlike other methods, ResNet-50 has an identity mapping to expect the outcome from the previous layer outputs to reduce overfitting and vanishing gradient problems.
The organization of the paper is as follows: Section 2 is about related works, Section 3 is about materials and methods which are required, Section 4 is about results and discussions followed by a conclusion and finally, references.
Many attempts had been done for achieving the best results by integrating the different deep learning models. First, [10] using Deep Convolutional Neural Networks classified the skin lesion as a benign or malignant by connecting the multiple blocks to the network to extract many features. LCNet was used for binary classification and tested on the various datasets ISIC-2017 and PH2 with various parameters but achieved the highest accuracy with a learning rate of 0.001 and activation function Leaky ReLU. Later, [11] proposed an automated methodology for the detection of skin cancer by using the modified XceptionNet on HAM 10000 dataset. In this work, the Swish activation function is used because this network gives the exact classification results compared with the traditional processes and depth-wise separable convolutional layers added to maintain the Xception modules.
Later another study, [12] followed sequential modeling like data pre-processing, segmentation and classification. They used the squeeze and excitation blocks to improve the classification accuracy by extracting more features. In addition, the authors proposed a two-stage ensemble model using the five different types of pre-trained models (Inception-V3, DenseNet-169, ResNet-150, inception-resnet-v2 and Xception Net) for binary classification and multi-class classification. Finally, the authors achieved the 85.1% for multi-class classification.
Deep neural networks in medical imaging play a more vital role in assisting dermatologists. Recently, one survey was conducted [13] to compare the accuracy of the DNN and Dermatologists. For this purpose, they collected 4204 biopsy samples for evaluating the results.
Later on, [14] used Deep Convolutional Neural Networks to evaluate the results with 70% and 80% of training data. The authors trained a model with 200 epochs and the model gets over-fitted due to the imbalanced data. To reduce the overfitting, fine-tuned several parameters and finally, Area Under Curve (AUC) value is 84.7%. Also, tested with some transfer learning models but it took too much time to execute. A study [3] performed multi-class classification using six pre-trained models on the HAM 10000 dataset. A comparative analysis was made between the VGG 19, Inception V3, Inception-Resnet-V2, Resnet50, Xception and MobileNet. First, augmentation is done to balance the dataset then Xception gives good results in accuracy, precision, recall and F-measure for multi-class classification.
[15] Developed an AI-based diagnostic system for skin cancer detection at initial stages based on ISIC-2018 and PH2 datasets. First, Artificial Neural Networks (ANN) and Feed- Forward Neural Networks (FFNN) is utilised to extract the features from images then CNN models (ResNet-50 and AlexNet) are implemented for the same work. In the next step, the results of both the ANN&FFNN models and CNN models were compared. Finally, CNN models are better for the extraction of features.
A study [16] addressed the class imbalance problems for getting less accuracy, especially in deep learning algorithms. This work mentions many techniques to balance the dataset, like over-sampling, under-sampling, hard mining, and one-class learning. Compared with all those models, under-sampling and hard mining of background pixels are well suited for the medical images to balance the dataset. Later on, [17] used an AlexNet by adding the soft-max layer for the purpose of binary classification over PH2 dataset.
Moreover, most of the analysts compared the results of ML techniques with DL techniques. A study [18] compared the ML and DL models to find out better performance. The ML algorithms are Logistic Regression, Linear Discriminant Analysis, K-Nearest Neighbours’ Classifier, Decision Tree Classifier and Gaussian Naive Bayes used, and DL models are VGG16, Xception and ResNet50 used. Finally found that DL models outperformed than the ML models.
Another study [22] used the grab-cut method to segment the skin lesion then all pretrained models are used with SVM classifier. Out of all these models, resnet-50 has given an outstanding performance. Later, another study [24] used mobileNet-v2 as a base model followed by the global average pooling layer but this model achieved an accuracy of 85%. The existing deep -learning based models are listed in Table 1.
Overview of deep learning based existing methods
Overview of deep learning based existing methods
Proposed methodology
This section focuses on the various ways to tackle the overfitting problem of the highly imbalanced ISIC-2019 dataset. Figure 2. depicts the pictorial view of the proposed method.
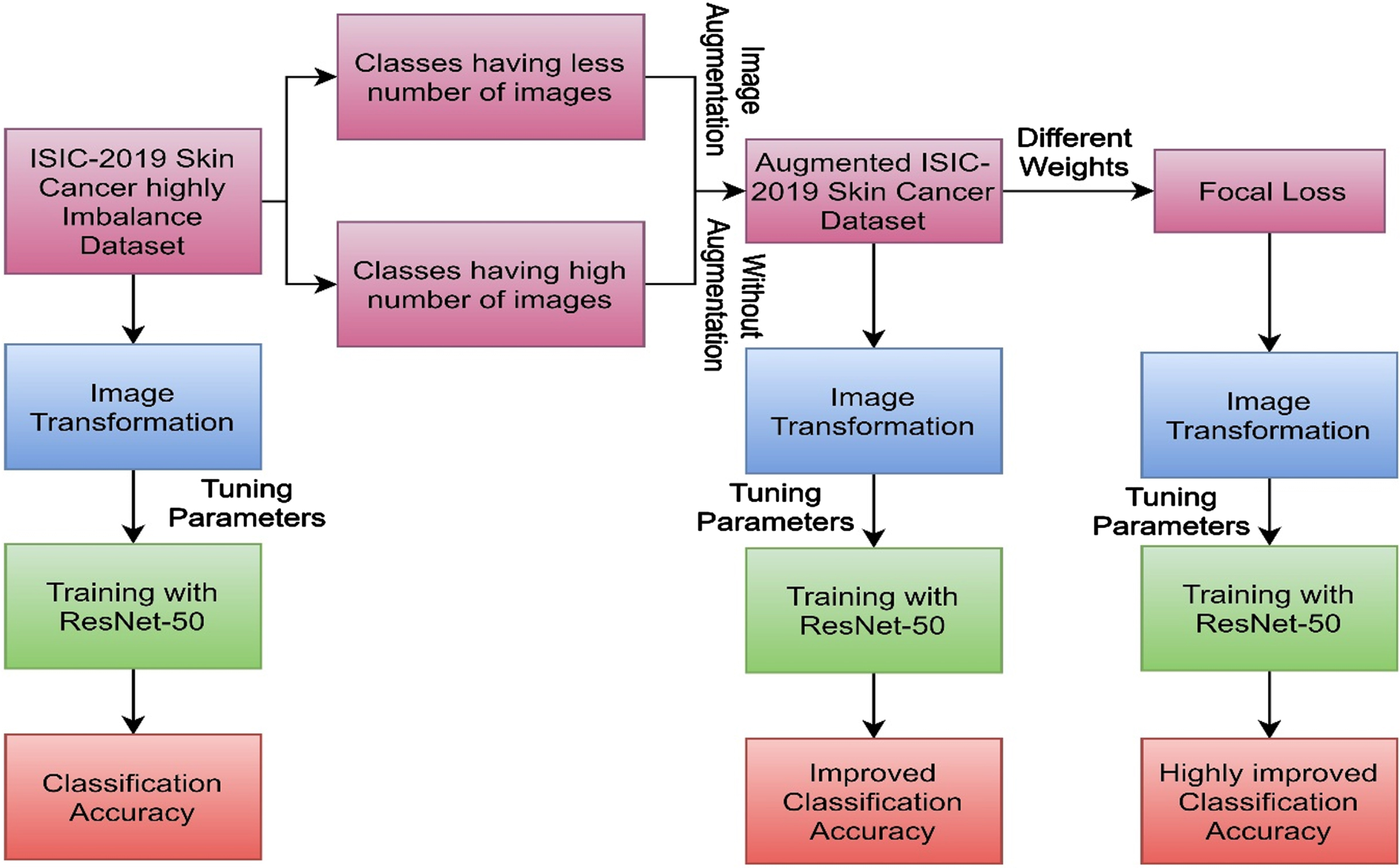
Proposed workflow.
The ISIC-2019 dataset contains the total 25331 images of 8-classes. The detailed view of dataset is shown in Table 2. (Dataset Link: https://challenge.isic-archive.com/data/#2019).
Detailed view of images in ISIC-2019 and no. of images after augmentation
Detailed view of images in ISIC-2019 and no. of images after augmentation
Recently, data augmentation techniques have been widely used in medical image processing due to the less no. of images for deep-learning models [23, 24–29]. Generally, domain-specific augmentation methods are used to increase the number of images. In two ways, augmentation techniques are used, one is to transform the images, and another is to generate fake images. Different techniques are used, like rotation, flipping, zooming, etc., to generate a greater number of labelled images to increase the model’s performance, and these techniques are used to tackle the overfitting problem. A detailed view of images in each class and images after augmentation is shown in Table 2.
In this work, due to imbalanced images in particular classes led to the overfitting issue. To overcome this problem, data augmentation is required for specific classes. A set of four classes (BCC, BKL, Melanoma and Nevus) are sufficient to train with the CNN model and another set (AK, DF, SCC and VASC) has a smaller number of images. To increase the model’s performance, rotation and flipping techniques are used to generate a greater number of images.
Rotation and flipping techniques are used to balance the lower image classes. Rotation is a technique to generate the multiple images at various angles. Flipping is an extension technique of rotation. It flips the image either left- right or up-down direction.
Focal loss
Class imbalance is one of the major reasons to get less accuracy of the targeted model detection. Focal loss is the best technique to address the class imbalance problem. Specially, it works on the hard samples to improve the performance. Focal loss is the improvised version of cross entropy loss that focuses on the hard negative training samples, and it increases the model’s performance by calculating the weight factors of each sample to reduce the class imbalance.
To improve the classification performance of the dermoscopy images, cross-entropy values are replaced with the focal loss function to adequate the number of samples automatically using the weight factor of the highest class. The focal loss can be proposed based on the cross-entropy loss to achieve the best results as shown in eq. (1).
Here, p is the model’s estimated probability that ranges from 0 to 1 and y is the class ground truth value from –1 to 1. To reduce the class imbalance, different weights are assigned to the samples of cross-entropy loss. The focal loss is calculated by using the Equations (2) & (3).
Where γ is a focusing parameter, always γ≥0. When γ= 0, it acts like a traditional cross-entropy loss. Whenever γ increases, it smoothly adjusts the co-efficient of hard samples. The value of p t becomes 0 when the hard sample is misclassified. By adjusting the values γ and p t , focal loss solves the class imbalance problem very well and gives the more weightage to hard samples which are misclassified.
One of the best Deep Neural Networks in computer vision is Convolutional Neural Networks due to their automatic features learning in a hierarchical manner. In medical imaging, CNN is a fabulous tool for detecting, segmenting, and classifying the targeted part. CNN contains an input layer, a hidden layer, and an output layer. The CNNs hidden layer has many convolutional layers, pooling layers followed by the fully connected layers for extracting global and local features. The deep-level layers can solve the most complex tasks, increasing classification accuracy. Sometimes, the deeper layers also lead to the problems like accuracy saturation/degrading and vanishing/exploding gradients. To solve such types of issues, ResNet works well by using deep residual networks. The ResNet-50 pre-trained model has been used for skin cancer classification by fine-tuning the parameters. Initially, ResNet-50 was trained on the ImageNet dataset containing 1.5M natural scenery images. ResNet-50 rearranges the layers that are presented in the network by using a mapping address to input layers [21].
The best idea of ResNet-50 is to utilize identity mapping to predict the final outputs of previous layers. The identity mapping identifies the unnecessary layers and allows the model to skip these layers. So, resNet-50 reduces the vanishing gradient problem and overfitting of the training samples. The challenge of training too deep neural networks has been resolved by introducing a new technique in Resnet called residual block identity mapping. The residual identity mapping is shown in Fig. 3.
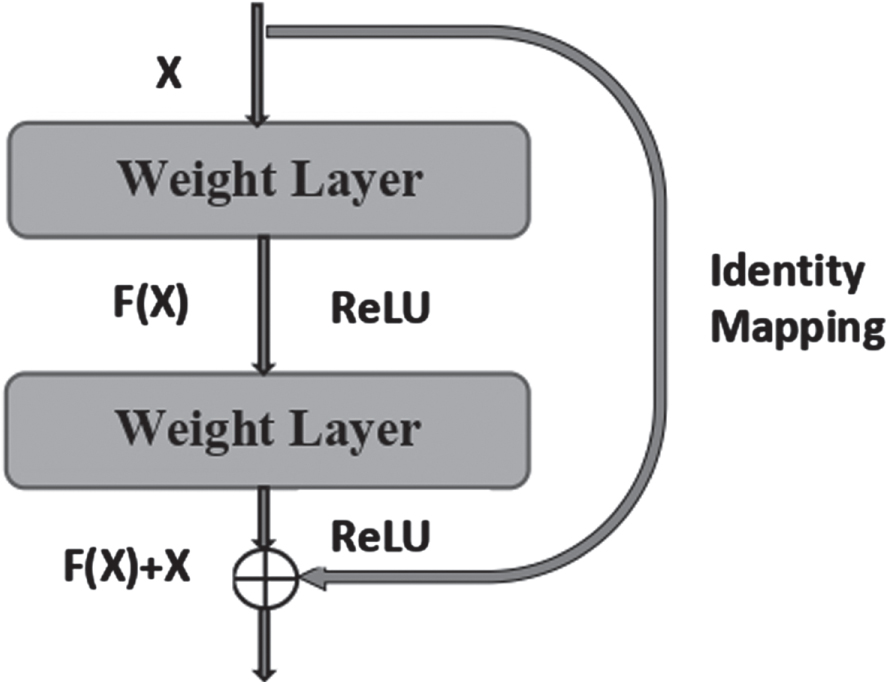
Residual block Identity Mapping.
Let H(X) be the desired mapping and X is the input. Identity mapping did not contain any parameter and was used to add the previous layer output to the input of the next layer in the residual block. H(X) can be represented as mentioned in eq. (4)
The pre-trained ResNet model was used in training along with the respective weights because training the deeper layer of the model improves the model’s accuracy and reduces the overfitting/underfitting. The ResNet-50 pre-trained model contains 50 deeper layers of 7X7 input layer followed by the 3X3 kernel size pooling layer.
In deep learning, the model needs a more significant number of deeper parameters for learning the features exactly. Handling more parameters is one of the big challenging tasks. To overcome this issue, optimization techniques are used to fine-tune the parameters of the network. To enhance the performance, various optimization techniques are utilized. ADAM optimizer is one of the best optimization techniques and has a significant role in deep learning models for attaining the best accuracy. The proposed Deep Neural Network uses fine-tuned parameters such as regularization, batch normalization, hyperparameter tuning, and optimization.
Regularization methods are used to enhance the model’s performance’s learnability and reduce the over-fitting by decreasing the generalization error without any effect on training data. Generalization error is the variation between the loss of the training set and test set loss. After training the network, some models perform well on an overall dataset but are very poor at generalizing the model, so these models also lead to over-fitting. Regularization methods are needed in deep learning to reduce over-fitting and maintain a lower training error rate.
Batch normalization is performed between the layers of the neural network. It segregates the whole dataset into some mini batches to speed up the training, use high learning rates, and make learning easier. To perform the standardization, at the time of training, batch normalization calculates the mean and standard deviation for each mini batch. To normalize features, the mean and standard deviation can be calculated as shown in Equations (5) and (6).
Here, m indicates the length of the mini-batch and x
if
represents the fth feature of ith sample. Using w
f
and σ
f
features can be normalized using the Equation (7)
Where, ξ used to reach the stability by adding a small integer.
Activation functions are necessary for CNN to identify whether the neuron is activated or not. A network without an activation function is called a linear regression model. These models cannot be able to learn complex features. In deep learning, non-linear models such as sigmoid and tanh can be used. The common problem with the sigmoid and tanh is the models will get the vanishing gradient problem due to the saturation and updating of gradient descent. Saturation is high for the positive values and low for the negative values. For improving the cost function, these non-linear models failed to receive the exact gradient information. This error led to updating the weights through backpropagation by reducing some additional layers.
A specific activation function is required to extract features using deep neural networks with deeper layers. This activation function mimics a linear function to be active for the weighted sum and also like a non-linear function to allow the neurons to learn the complex features to avoid saturation. Replacing the hidden sigmoid units significantly improves most of the algorithm’s performance. ReLU is one of the best activation function, half of the layers acts as a linear function and other layers are performed as a non-linear function.
ReLU is an activation function that can be applied to all hidden layers. ReLU rectifies many issues like vanishing or exploding gradient problems. ReLU is mostly used in multi-layer neural networks and does not activate all neurons at a time. In CNN, pooling layers are followed by output layers, then drop-out layers and SoftMax classifiers are added at the last layers to achieve the highest training accuracy. ReLU does not saturate because the output does not contain the highest value, so this function helps in the gradient descent problem. ReLU computes the result very fast over sigmoid and tanh. As shown in eq. (8) if the input value is less than 0 (Negative), then the outcome is set to 0, and if the input value is greater than or equal to 0, then the outcome value remains the same.
The weights of each class will be update by using the Updating rule shown in Equation (9)
Where w* is the updated weights based on the error in previous iteration, η is learning rate and
The Soft-Max is used in the final layer of a neural network to avoid non-linearity in output. SoftMax is used for multi-class classification, so the multinomial probability estimates the output. SoftMax is very useful for optimizing the model, and performance increases with an optimizer. It is a squashing function shown in Equation (10) that ranges from 0 to 1 and the overall sum is up to 1. Each class loss and value of the model can be summarized by comparing the predictions with target values. This iterative process stops when the model reaches a significant improvement in terms of performance.
Where z j is the scores obtained by all classes.
Optimization techniques are particularly used to reduce or summarize the loss. The enhancement of the backpropagation is also calculated based on the loss value then the performance is evaluated depending on the optimizer. While learning the features continuously (iteratively), the prediction values are compared with the targeted values then the loss value will be calculated. When the model achieves the best performance improvement, the continuous process stops. In this regard, optimization techniques are used within network architecture to increase the model performance and minimize the loss. Adam optimizer and focal loss is used to reduce the overfitting and loss of dermoscopy images.
The optimization techniques always aim to search for the best optimal method f(x) to reduce the loss L for total number of N training samples. The optimal function is represented in Equation (11)
Where, θ represents mapping function parameter, x i ,y i represents feature vector and corresponding label of Ith values, respectively.
Adaptive Momentum (ADAM) works efficiently for a large amount of data and takes much less memory. Adam is a combination of gradient descent and momentum. It always uses adaptive learning for each parameter. Adam considers an exponentially weighted average of the gradients so that the average values converge towards the local minimum.
The learning rate is a hyperparameter presented in an optimization algorithm to adjust the weights of ResNet-50 concerning the loss gradient. The learning rate handles the size of the step for every iteration.
All the experiments are carried out in GPU- based system for implementing the deep learning models, i.e., MSI GF-65 gaming laptop, Intel i7-10gen,750H with 6 cores and twelve threads GPU NVIDIA 2nd gen GeForce RTX-3060/144 Hz 6GB and windows 11 64-bit operating system. The pre-trained CNN model ResNet-50 is executed in Pytorch 1.8.0 + cu111 framework in python language.
Results and discussion
ISIC-2019 dataset consists of 25,331 dermoscopic RGB images of 8-different classes of skin diseases. The ResNet-50 model was run by splitting the 80% data for training and 20% for validation. Overfitting is the major challenging task to evaluate the model’s performance. To overcome this issue, four different runs are performed with different techniques. The first run was done to assess the overfitting of the ISIC-2019 dataset. The number of images used for the first run is 20265 for training and 5066 for validation. Four different performance metrics are used to assess the performance of the ResNet-50. The accuracies of each class are mentioned in Table 3 and overall performances are given in Table 7.
class-wise accuracies of ResNet-50 on ISIC-2019 dataset
class-wise accuracies of ResNet-50 on ISIC-2019 dataset
The number of iterations used to run the model is 100. The learning rate varies from 0.1 to 0.01 depending upon the error and weight decay set to 0.00001. There is an enormous gap between training and validation accuracy. In the ISIC-2019 dataset, the model exactly fits over the training data but not on the validation data, so the model is getting overfit. The total average gap in training and testing of all classes is around 13%, so we cannot diagnose or classify skin diseases accurately.
In the second run, data augmentation is performed on some specified classes. The whole dataset is divided into two groups. The first group contains 4 classes such as BCC, BKL, Melanoma and Nevus, which have enough images to run the model. Another group also includes 4 classes such as AK, DF, SCC and VASC, which have a smaller number of images and need data augmentation to balance the data. To balance the data to reduce the overfitting, data transformations such as Rotate- 90,180,270 and vertical flip are required. The total number of images used for the second run after transformations are 28856. With the varying learning rate, the overfitting gets reduced for each run. The class-wise accuracies of ResNet-50 with augmentation is shown in Table 4.
class-wise accuracies of ResNet-50 with augmentation
By doing the transformations, the overfitting is reduced compared with earlier. Augmentation over smaller classes can increase performance. In the second run, 23085 images are used for training and 5771 images are used for validation, so the average overall overfitting gap between training and validation accuracy is reduced to 11%. Still, it is required to reduce overfitting to increase the classification or detection accuracies of skin cancer very effectively. In the next step, focal loss is used to reduce overfitting.
The third run was done with focal loss by applying original ISIC-2019 data. Focal loss is a function that focuses on the hard negative images while training. Loss functions are very crucial to handle imbalanced datasets. It manages the data by assigning the weights to each class. The focal loss weight value will range from 0.1 to 1. The training and validation accuracy of each class is shown inTable 5.
class-wise accuracies of ResNet-50 with original data and with focal loss
Each class training and validation accuracies are increased with focal loss compared with the accuracies without focal loss. The overall average overfitting gap of focal loss is reduced to 4.9%. So still, to increase performance, the same loss function will apply to augmented data. In the fourth run, focal loss with augmented data is implemented. The weights are assigned to the augmented images to balance the data. In this run, all the accuracies are increased a lot. The overall overfitting gap was also reduced to 3% on the highly imbalanced dataset. In the first run the model is highly overfitted with an average gap 13% but with focal loss and augmentation techniques, maximum overfitting is reduced. The accuracies and overfitting gap of each class is shown in Table 6.
class-wise accuracies of ResNet-50 with Augmented data and with focal loss
Accuracy is used to measure the how many times correct predictions are made across the whole dataset. Precision calculates the total correct positive predictions and recall calculates the total positive samples correctly identified. F1-Score is the harmonic mean of both precision and recall. Mathews Correlation Co-efficient (MCC) is the best metric to evaluate the performance of imbalanced classes. The performance of ResNet-50 is evaluated by using the various types of performance metrics shown in Equations (12)–(16), and percentages in Table 7.
Where TP, TN, FP and FN represent true positives, true negatives, false positives and false negatives, respectively. The outcomes of the confusion matrix help to find out the performance metrics such as Accuracy, Precision, recall, F1- score and MCC. MCC Is an effective metric for calculating the performance of an imbalanced dataset. The performance metrics of each run is shown in Table 6.
The average performance metrics of ResNet-50 on highly imbalanced dataset
Table 7 shows that the original ISIC-2019 dataset is given the very few values due to imbalanced images of classes. To improve the performance, augmentation and focal loss are used so that Augmented images with focal loss is given high-performance values. Finally, the performance metrics averages are noted as 98.8%, 95.5%, 95.93%, 95.69% and 91.28% for accuracy, precision, recall, F1- score and MCC, respectively. The confusion matrices and graphs of ResNet-50 are shown in Figs. 4 and 5.
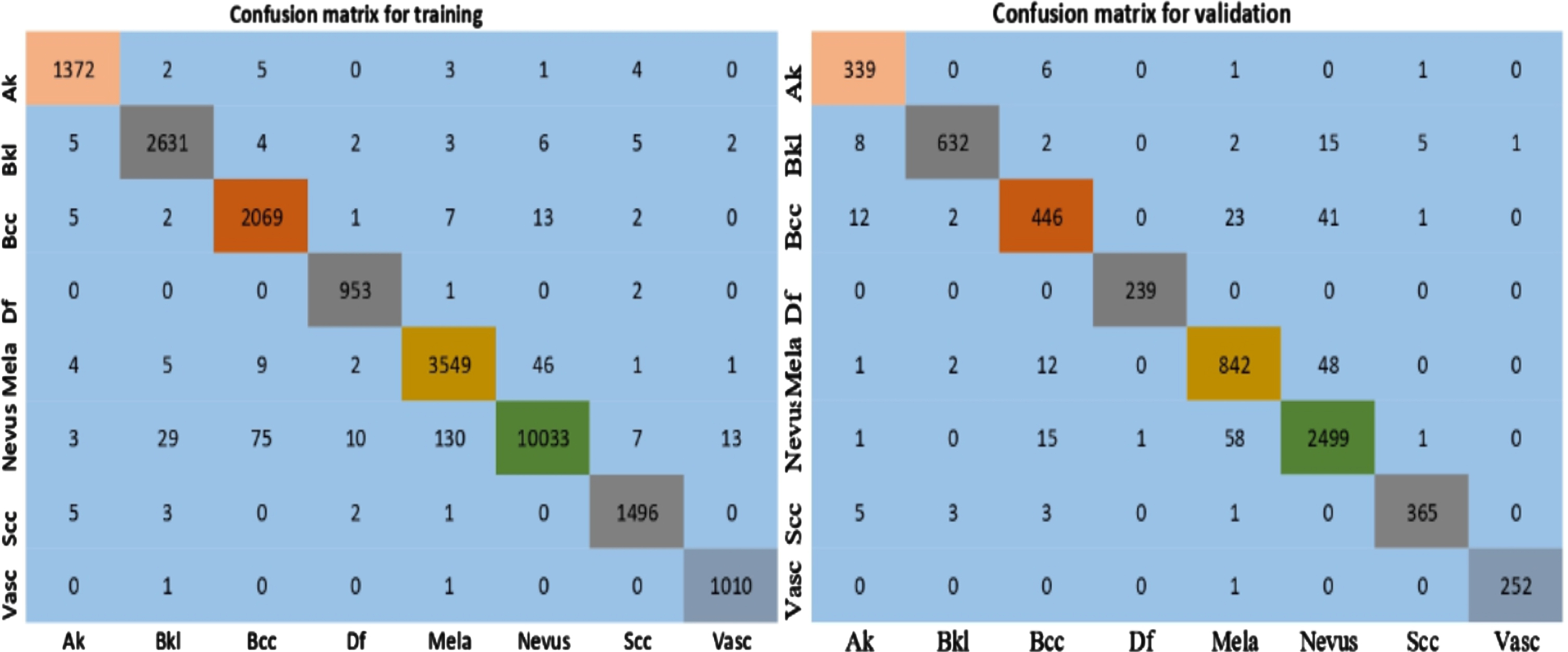
Confusion matrices of fine-tuned ResNet-50 on Augmented data with Focal loss.
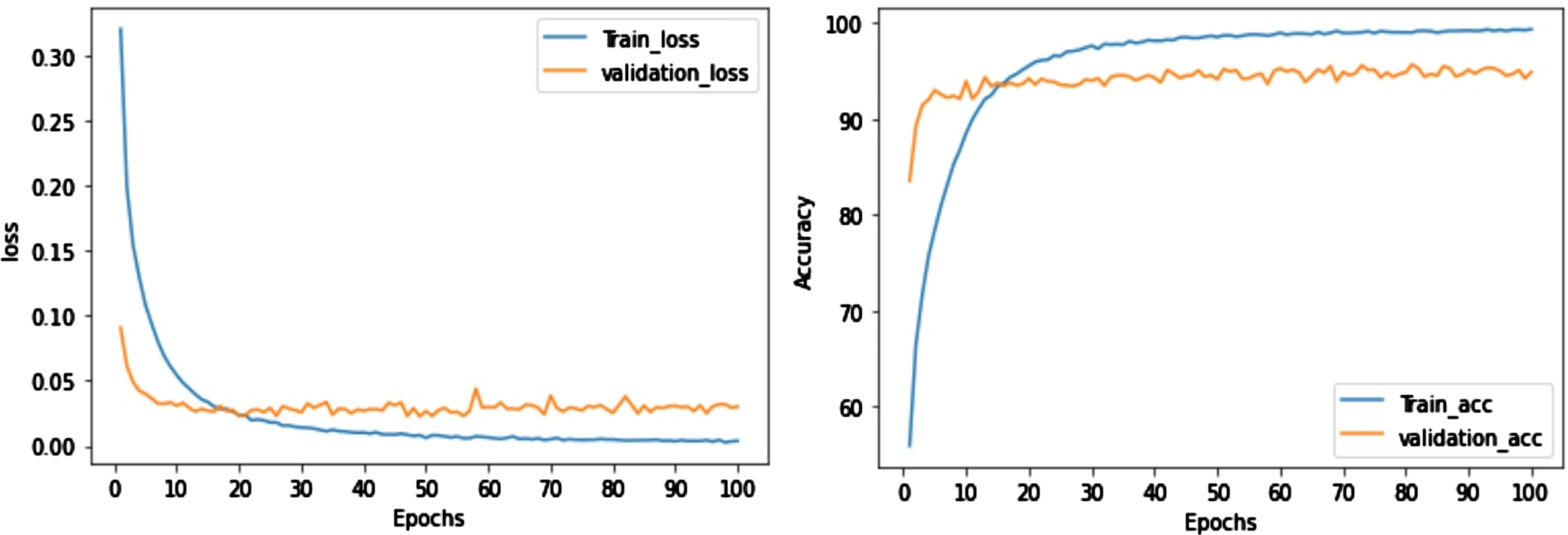
Loss and Accuracy graphs of fine-tuned ResNet-50 over Augmented data with Focal loss.
The performance comparison between our proposed model (Augmentation with focal loss) and existing work with base network Resnet-50 is shown in the Table 8.
Comparison of resnet-50 with previous study
In recent days, Skin cancer has been growing as a worldwide health problem, so the development of automated systems is required to assist dermatologists in identifying abnormal images in their early stages. Through this research work, it is shown that using various combinations of data augmentation and transfer learning methods, it is possible to attain a competitive result to overcome overfitting using ISIC-2019 imbalanced dataset. The classification results were obtained using the pre-trained ResNet-50 model, and various tuning parameters have been incorporated to attain the best results. To reduce the imbalance on multi-class classification, the focal loss has been used to balance hard misclassified images with weights so it has given tremendous performance by adding weights to each class of the augmented data. Finally, augmented data with focal loss has given promising results with an average classification accuracy 98.52%. In the future, the proposed methods will be extended with different types of pre-trained models for classification.
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Authorship contributions
Both the authors equally contributed to this paper.
Funding
There is no funding to this work.