
Abstract
BACKGROUND:
In clinical medicine, low-dose radiographic image noise reduces the quality of the detected image features and may have a negative impact on disease diagnosis.
OBJECTIVE:
In this study, Adaptive Projection Network (APNet) is proposed to reduce noise from low-dose medical images.
METHODS:
APNet is developed based on an architecture of the U-shaped network to capture multi-scale data and achieve end-to-end image denoising. To adaptively calibrate important features during information transmission, a residual block of the dual attention method throughout the encoding and decoding phases is integrated. A non-local attention module to separate the noise and texture of the image details by using image adaptive projection during the feature fusion.
RESULTS:
To verify the effectiveness of APNet, experiments on lung CT images with synthetic noise are performed, and the results demonstrate that the proposed approach outperforms recent methods in both quantitative index and visual quality. In addition, the denoising experiment on the dental CT image is also carried out and it verifies that the network has a certain generalization.
CONCLUSIONS:
The proposed APNet is an effective method that can reduce image noise and preserve the required image details in low-dose radiographic images.
Introduction
X-Ray and Computed tomography (CT) technologies have become widely used in clinical medicine over the past few years for both diagnosis and therapy. CT is an advanced technology that was developed based on X-Ray technology that can represent more information about organs in three-dimensional space. Existing medical imaging methods to minimize the radiation dose to which patients are usually exposed, the body is usually scanned with a low-dose CT (LDCT) device. Nevertheless, LDCT scanning will result in noise and a loss of image sharpness. Medical images typically contain granular noise because of the intrinsic qualities of imaging equipment, interference from the outside environment, and other causes. Two types of noise that frequently appear in medical images are Gaussian noise and Quantum noise. Whereas the quantum noise follows the Poisson distribution. Noise-polluted images lose features and reduce accuracy in clinical diagnosis. Therefore, the pre-processing stage for denoising is crucial for medical images.
The goal of image denoising is to remove noise from images. Existing noise reduction techniques first assume the same distribution of noise, such as the Additive white Gaussian noise (AWGN) [1–5], and then extended to the study of Poisson-Gaussian mixed noise [6, 7]. Because they can distort the details of image edges while denoising, traditional denoising techniques like wavelet filtering [8], non-local means (NLM) [9], and block-matching 3D (BM3D) [10] cannot meet the needs of medical diagnostics.
Convolutional neural network (CNN)-based image denoising has gained popularity thanks to the advance of deep learning. To enhance the performance of AWGN removal, DnCNN [1] adds batch normalization and residual learning. The FFDNet [11] and CBDNet [12] series gradually consider more sophisticated noise distribution. In order to achieve deep end-to-end denoising, Memory Network (MemNet) [13] presents an extended network memory model that incorporates the output of all short-term and long-term memory units. Convolutional Super-Resolution Network for Multiple Degradations (SRMD) [14] obtains a model appropriate for multiple degraded images by considering both the influence of noise level and fuzzy kernel. An architecture for full-resolution processing dubbed MIRNet was suggested by Zamir et al. [15]. The network may retain high-resolution spatial details while obtaining contextual information from low-resolution representations. Also, they suggested the MPRNet [16] multi-stage design, which significantly enhances the performance of noise removal. In the proposed NBNet, Chen et al. [17] introduced adaptive image projection to the job of image denoising for the first time, the network is capable of noise suppression and maximal detail retention. Instance normalization (IN) [18] is used as a building block by the Half Instance Normalization Network (HINet) [19] to enhance network performance.
Although the techniques have improved image denoising, several drawbacks remain. First, the CNN-based approach will result in a smooth transition and missing details because it cannot adapt to texture features. In a scene with hardly discernible details, it is challenging to restore high-quality images. Second, because there are many types of noise in LDCT images, channel characteristics should be changed based on the prior to giving areas with considerable noise more weight. Moreover, by adding more layers to networks, many networks improve model performance [20–22]. The redundant network layer, however, will cause model degradation as the network’s depth rises, which will increase the amount of time and memory used for computation.
At present, these above methods have been applied to LDCT image denoising. It is challenging for the model-based method [24–29] to accept the hybrid noise distribution as an a priori for the LDCT image denoising problem. Nevertheless, the learning-based approach [30–36] is not sufficiently adaptable to the image content, making it challenging to distinguish between noise and texture information. To address the abovementioned issues, a projection-based deep attention denoising network called Adaptive Projection Network (APNet) is proposed. The underlying clean image with texture features is recovered from the medical noise image using non-local information. To consider changes in texture and edges, we created a Dual Attention Residual Block (DARB) that weights significant features. The network uses DARB in the encoder-decoder structure based on U-Net [23] to eliminate noise from coarse to fine. Additionally, we created a Subspace Feature Fusion Module (SFFM) to separate the combined noise and detail texture in medical images by feature projection and further fuse features in skip connections. Our approach can achieve good performance while using significantly less computing than the most sophisticated approaches.
In brief, the contributions to this work are as follows:
A dual attention residual block that includes both spatial and channel attention mechanisms is suggested to integrate with the U-shaped network. While extracting noise features, the weight can be modified adaptively to suppress unnecessary information. A subspace feature fusion module that combines encoding and decoding capabilities is proposed. Convolution is used to enhance the stable network in hierarchical feature recovery. Then, the orthogonal projection approach is introduced to reconstruct the image in feature space. The combined noise and the intricate texture of the image may be distinguished in the rebuilt image. An adaptive projection network is proposed.
The remaining parts of the paper are organized as follows. Section 2 describes the motivation of the usage of the image projection for the image denoising problem. Section 3 presents the proposed method. Section 4 explains the innovation of the proposed approach. Section 5 presents experimental results. Section 6 concludes the paper.
Research motivation
Deep learning methods usually involve a huge amount of high-dimensional data, and in the case of images, each dimension is also known as an image feature. However, for the training dataset of the network, only a few features contain useful information, and the importance of features in other dimensions is insufficient. Through feature extraction, representative features are selected from the high-dimensional feature vectors to improve the performance of network learning information while reducing the dimension. However, information loss is inevitable in the process of dimension reduction. In order to reduce the loss of dimension reduction, it is necessary to find those dimensional features that represent important information as much as possible when designing the algorithm.
Therefore, some subspace methods are used in image processing, such as Fourier transform and wavelet denoising. The basic principle of this kind of method is to split the digital image into a set of bases, let the neural network to find the basis where the noise is located, and remove this part while preserving the original information as much as possible.
The algorithm proposed in this section uses non-local image information by orthogonal linear projection method to effectively compress high-dimensional data features. The principle of image projection is shown in Fig. 1. A set of image basis vectors are generated from the feature mapping of the input image through the neural network, and then the vectors in the original feature map are projected into these feature basis vectors, that is, the reconstructed image is obtained in the subspace spanned by these basis vectors. The learned feature basis vector can suppress the noisy vector without affecting the vector where the image texture is located. In the training of neural networks, deep learning is used to automatically learn a set of bases, and the network learns to generate the base vector of signal subspace, and projects the input image into the subspace. Since natural images are usually in low-rank signal space, the image texture information can be enhanced after reconstruction through accurate learning and generation of these base vectors. Through image projection, the reconstructed image can extract important features, retain most of the original information, and suppress noise unrelated to the generated basis vector. Subspace projection can train a network that separates information from noise.
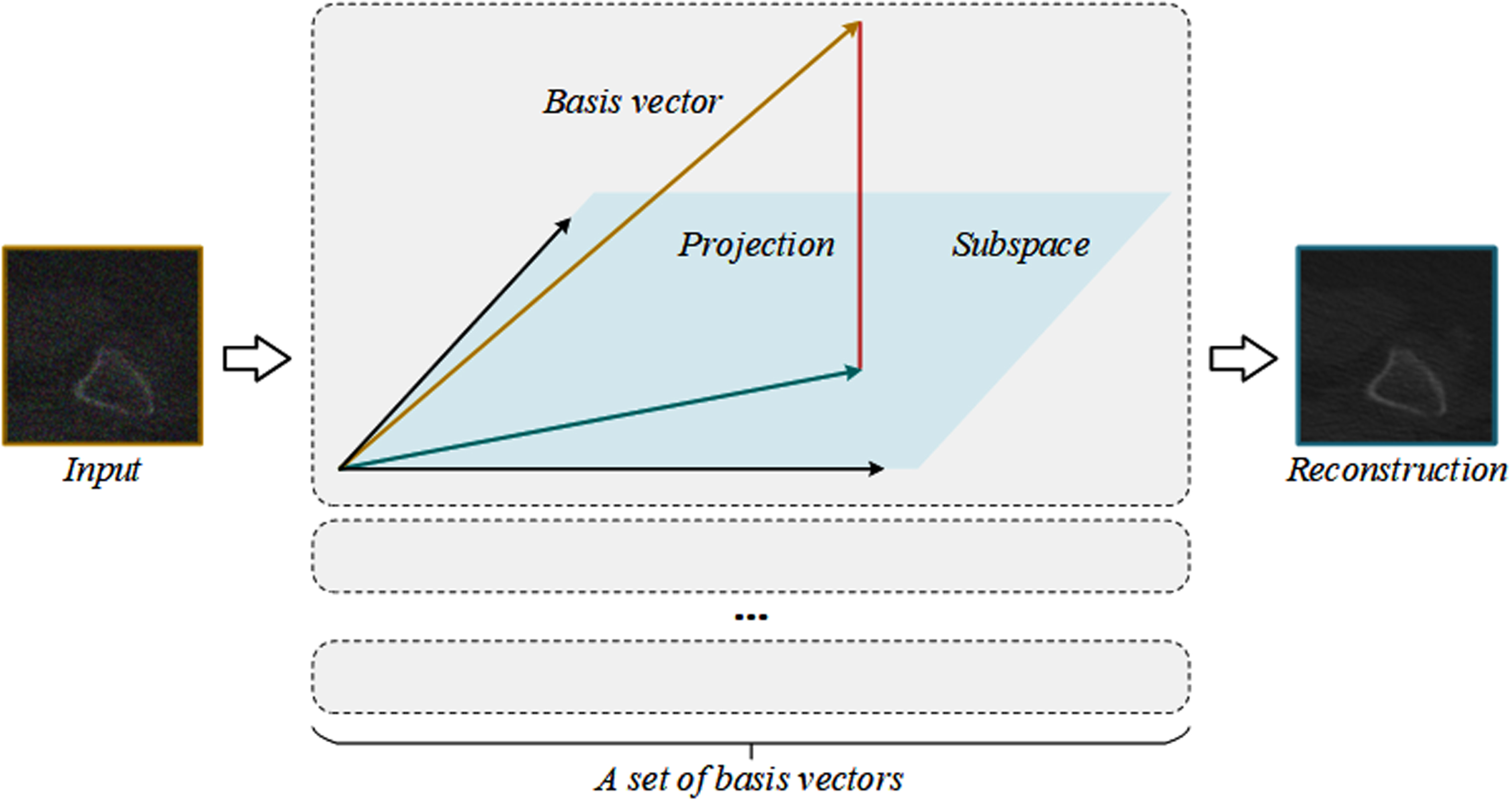
Principle of image projection. By learning and generating a set of feature basis vectors accurately through neural network, the vectors in the input feature map are projected onto these feature basis vectors, and the reconstruction image can retain the structure information of the image well and suppress the noise.
Network structure
Denoising algorithms in use have been successful at learning specific noise information, but when faced with more complicated noise intensity, these networks frequently fail to hold onto non-significant features. As a result, we suggest APNet, a network for denoising using image adaptive projection. The network uses the orthogonal linear projection given in the previous section and has adaptive learning ability. Figure 2 depicts the structure. The three steps of APNet are the encoder stage, decoder stage, and fusion stage.
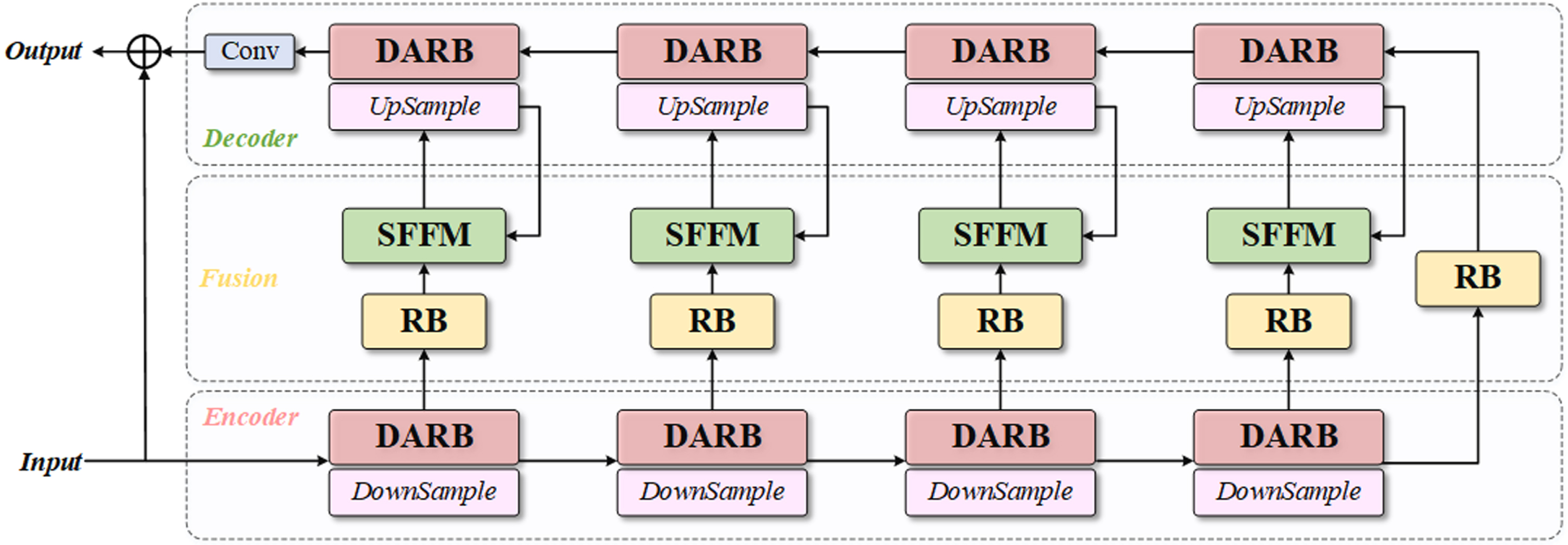
The network architecture of the Adaptive Projection Network (APNet).
Following the transmission of the noisy image into the network, the coding step does four times of down-sampling, and four groups of DARBs extract the characteristics of each scale. The decoder receives the low-level characteristics obtained by encoding via a residual block (RB). DARB is also used to up-sampling and extract sophisticated characteristics during the decoding phase. To make up for information lost during sampling, RB and SFFM are introduced in the fusion step in order to bypass connections. The encoder sends low-level features to the SFFM, and the decoder sends high-level features to the module. In order to further restore the image’s details, the projection features obtained from the low-level feature mapping are combined with the high-level features before being sent to the appropriate encoder. A convolution layer then obtains the residual output of the reconstructed image.
The network’s training set is made up of pairs of clear images and images with medical noise. We define a clean image x a noisy image y, and the denoised image
F
APNet
(·) stands for the model created through neural network training. L1 loss between the clean image x and the denoising result
The trained network model F APNet (·) can be used to directly generate the noise image in the test set.
We offer a residual learning design module to execute down-sampling and up-sampling operations to increase the stability of network training. Figure 3(a) demonstrates that our RB is made up of convolutional layers and the Leaky ReLU [37]. In contrast to the modules in the traditional residual network (ResNet) [38], our RB eliminates extraneous elements to streamline the information flow during the learning phase.
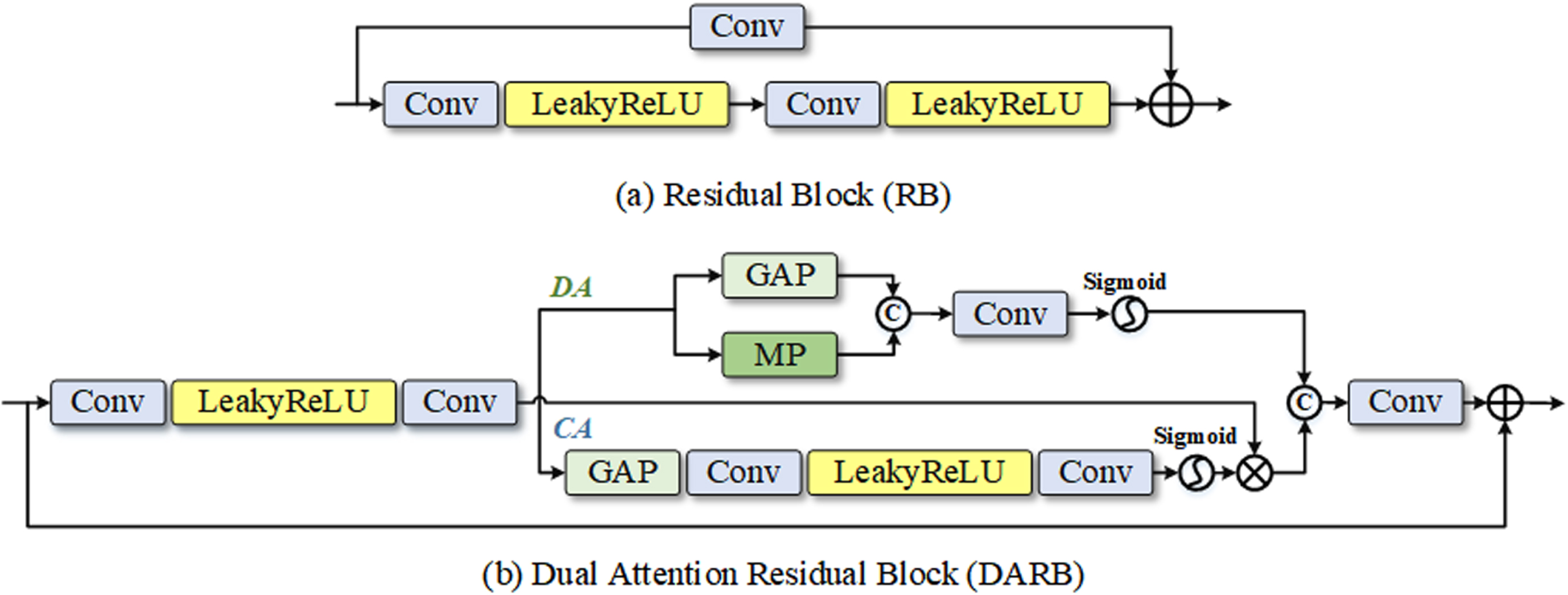
The structure of some key building blocks of the network.
To improve the network’s capacity for detail recognition, the RB contains a double attention mechanism. Figure 3(b) depicts the dual attention residual block’s organizational structure. The deep attention (DA) module is on the upper branch whereas the channel attention (CA) [39, 43] module is on the bottom branch. Convolution feature mapping is used by CA to extract significant channel characteristics. Enter a feature map and squeeze it using global average pooling (GAP) [41] to reduce its spatial dimension. Excitation operation using two layers of convolution and a Leaky ReLU activation function is the compressed feature descriptor. Lastly, dimension transformation of the features is performed using the Sigmoid activation function to obtain the CA branch output. To further delve into the network, DA branches mine the correlation of spatial variables. The DA module initially performs GAP and maximum pooling (MP) operations on the feature map before connecting the output features. The weight of the input characteristics is then calibrated in the spatial dimension, and the deep mapping is obtained using the convolutional layer and Sigmoid activation function.
The output feature graph I
DARB
of DARB can be expressed as follows given an input feature graph I:
Before the feature enters the attention branch, the shallow feature extraction process is represented by F S , the output of the CA and DA branches are represented by F C and F D , respectively, and the final convolution operation is represented by F Conv . To aid the network in learning features more effectively, DARB is utilized to extract useful detail texture information from feature maps and suppress irrelevant information.
Figure 4 depicts the structure of the Subspace Feature Fusion Module (SFFM), which is added to each skip connection during the Fusion phase. Before the low-level features from the encoder and the high-level features from the decoder are combined, two convolution layers are utilized for convolution aggregation. As a result, the network will be more stable during the optimization process. It can be solved by better integrating the structural information from the deep network and the texture information from the shallow network during the hierarchical feature recovery. The feature map was then resized using the fusion features that had been fed into the RB. The noise information is then separated using an orthogonal linear subspace projection. In the neural network-based image projection method, a set of basis vectors are created in the input image feature space, and the feature map’s vectors are then projected onto these basis vectors to transform the feature mapping into signal subspace.
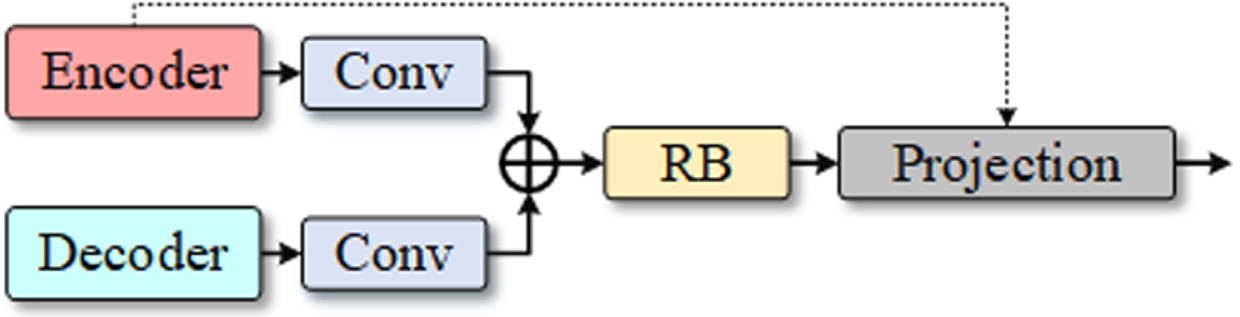
The architecture of the Subspace Feature Fusion Module (SFFM).
The lower-level feature graph from the skip connection is projected into the signal subspace that is guided by the up-sampled higher-level feature following the convolution refinement, and the projected feature is then further fused with the original higher-level feature. I de is the high-level feature graph that has been refined and is the same size as I en , which is the low-level feature graph that the encoder ran via skip joins and convolution to refine. Assume that a subspace U based on the feature graphs I en and I de has a set of bases [u1, u2, ⋯ , u k ]. The technique of projecting low-level feature graph vector I en to these basis vectors is denoted by the orthogonal linear projection as follows:
when λ = [λ1, λ2, ⋯ , λ
k
]
T
. As the vector I
en
- U (I
en
) is perpendicular to the foundation of the subspace U, we can also derive:
After that, the feature graph I
en
in the signal subspace produced the following reconstructed image:
More original information is present in the feature map that the encoder input. The image is rebuilt via a projection operation, and the denoising procedure incorporates the global structure. The projection can preserve the local structure information of the input signal, improve the reconstructed signal, and improve the ability of the denoising process to discriminate the noise.
The network proposed in this paper refers to the classic U-Net U-shaped structure, whose backbone is divided into two symmetrical left and right parts. On the left is the feature extraction network, the encoder, where the original input image is down-sampled four times through a stack of convolution and maximum pooling. On the right side is the feature fusion network, that is, the decoder. While up-sampling is carried out, the feature maps of each level and the feature maps obtained by deconvolution are fused by skip connection. Inspired by U-Net, we adopted this coding-decoding framework. The difference is that: For low-level visual tasks, especially images in the medical field, traditional network structures are not sufficient to extract multi-level features. Therefore, we introduce residual modules in encoder and decoder to extract the features of each scale. Compared with U-Net convolution, the structure of residual can solve the training optimization problem when the number of layers deepens. This is because the residual structure does not increase the number of parameters of the model through the identity mapping, which means that the computational complexity will not increase, and the convergence speed of the model will also be accelerated, so that the accuracy of the network performance will be improved to a certain extent. In particular, to further avoid the information loss in the transmission process of features, we transform the one-way skip connection in the traditional structure into a two-way information transmission. The skip connection in U-Net transmits the features from encoder to decoder, and our network receives the features from decoder and encoder at the same time in the jump connection to compensate for the information loss in the sampling process. The traditional convolution structure depends on the corresponding fixed local filter, so we also introduce the projection mechanism, which reconstructs the texture based on the globally determined coefficient, and the reconstructed image can help the network further refine and separate the mixed noise from the real texture information.
Experiments
Experimental setting
Dataset
2048 images from the Low-Dose Parallel Beam (LoDoPaB)-CT dataset [33] were utilized to train our model for image denoising tasks. The two-dimensional image form received from the LIDC/IDRI public database of CT reconstruction of the human chest was utilized in this dataset to represent the ground truth (GT). By adding simulated synthetic noise to 2048 GT images in the LoDoPaB-CT dataset and considering different noise levels, a variety of paired data was generated for the training model. The way to synthesize noise is to add Gaussian noise and Poisson noise respectively through MATLAB’s built-in function imnoise. To test the denoising effect of the model under various noise intensities, 256 images from the LoDoPaB-CT dataset were also included in the test set. In addition, we added dental CT images provided by SHDMU (Stomatological Hospital of Dalian Medical University, China) to further test the model’s denoising capabilities.
Baseline algorithm
As a baseline, the proposed network was evaluated against numerous image-denoising methods, such as DnCNN [1], IRCNN [40], FFDNet [11], and NBNet [17].
Evaluation metric
We calculated the peak signal-to-noise ratio (PSNR) and structural similarity (SSIM) of the denoised images as evaluation indices to compare the algorithm’s objective performance.
Network parameters and training settings
The three stages of the network structure proposed in this paper are the encoder stage, decoder stage, and fusion stage. Dual attention residual modules are presented in both the encoder and decoder and the fusion stage consists of residual modules and subspace feature fusion modules. The convolution layer utilized in these modules has a convolution kernel size of 3×3. When employing LDCT images, the clean images are truncated into 128×128 image blocks for the training set and the test set, respectively, and various amounts of synthetic noise are applied to the clean images. The batch size parameter was set to 4, the learning rate at le-5, the training procedure iterated 200 times, and Adam was utilized as the model optimizer. The PyTorch framework is used to implement the algorithms in this paper. On a workstation with an NVIDIA GeForce RTX 3090 GPU and a Core (TM) i7-7700K CPU, all the comparison algorithms are run on the same system.
Comparison of denoising performance of chest CT images synthesized with Poisson noise
Poisson noise is created in medical CT during photoelectric conversion, so the experimental component simulates the impact of low-intensity Poisson noise. To examine the effect of different denoising techniques, we added two different levels of Poisson noise intensities to the clean images of the test dataset before comparing the synthetic Poisson noise images. We synthesized two kinds of Poisson noise on the test set containing 256 LDCT images, and denoised them by using the method proposed in this paper and other comparison methods. The average results of image evaluation indicators are shown in Tables 1 and 2, respectively. The greatest value under the evaluated noise level is reached by our method.
Average PSNR (dB) and SSIM results on synthetic Poisson×1 noisy images
Average PSNR (dB) and SSIM results on synthetic Poisson×1 noisy images
Average PSNR (dB) and SSIM results on synthetic Poisson×2 noisy images
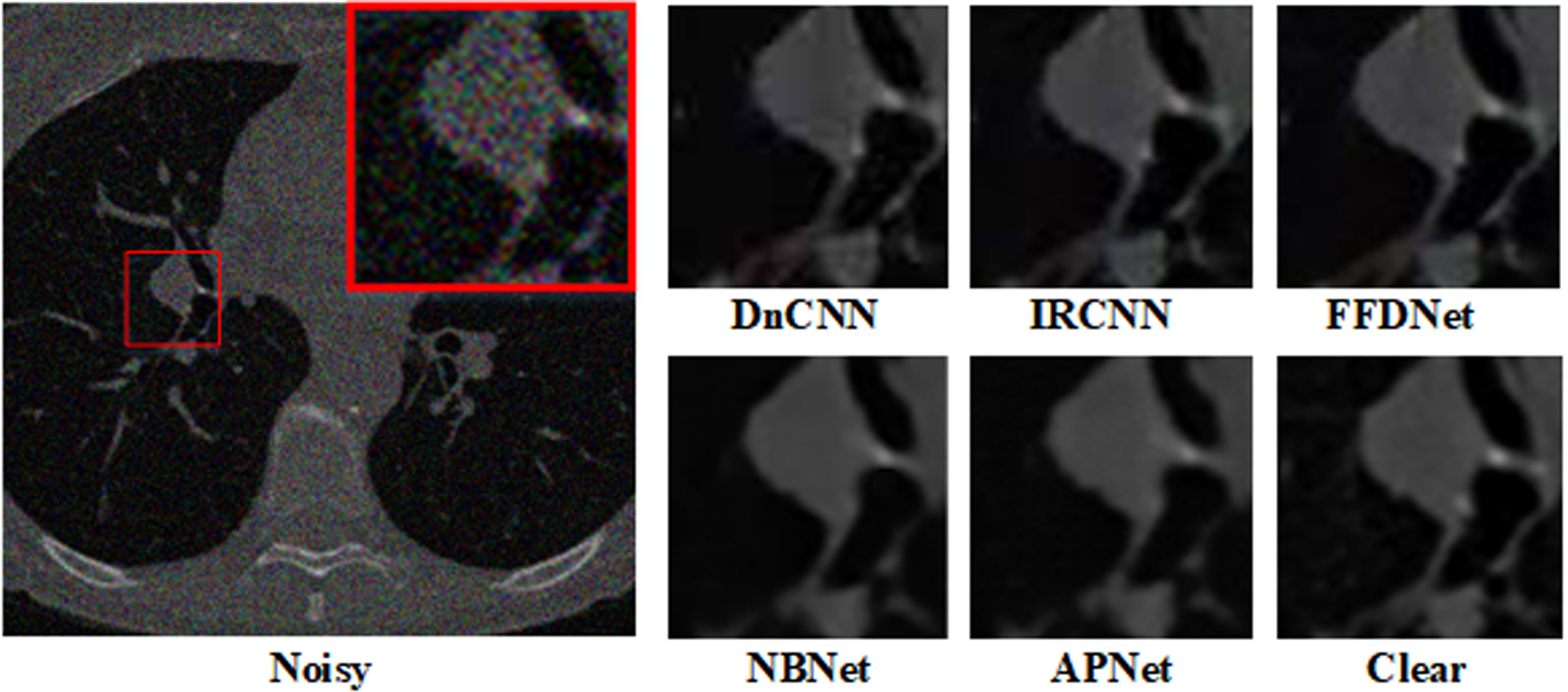
Figures 5 and 6 display the contrast in a visual manner. Our approach can recover intricate textures from low-intensity Poisson noise without adding artifacts since medical images self-adapt.
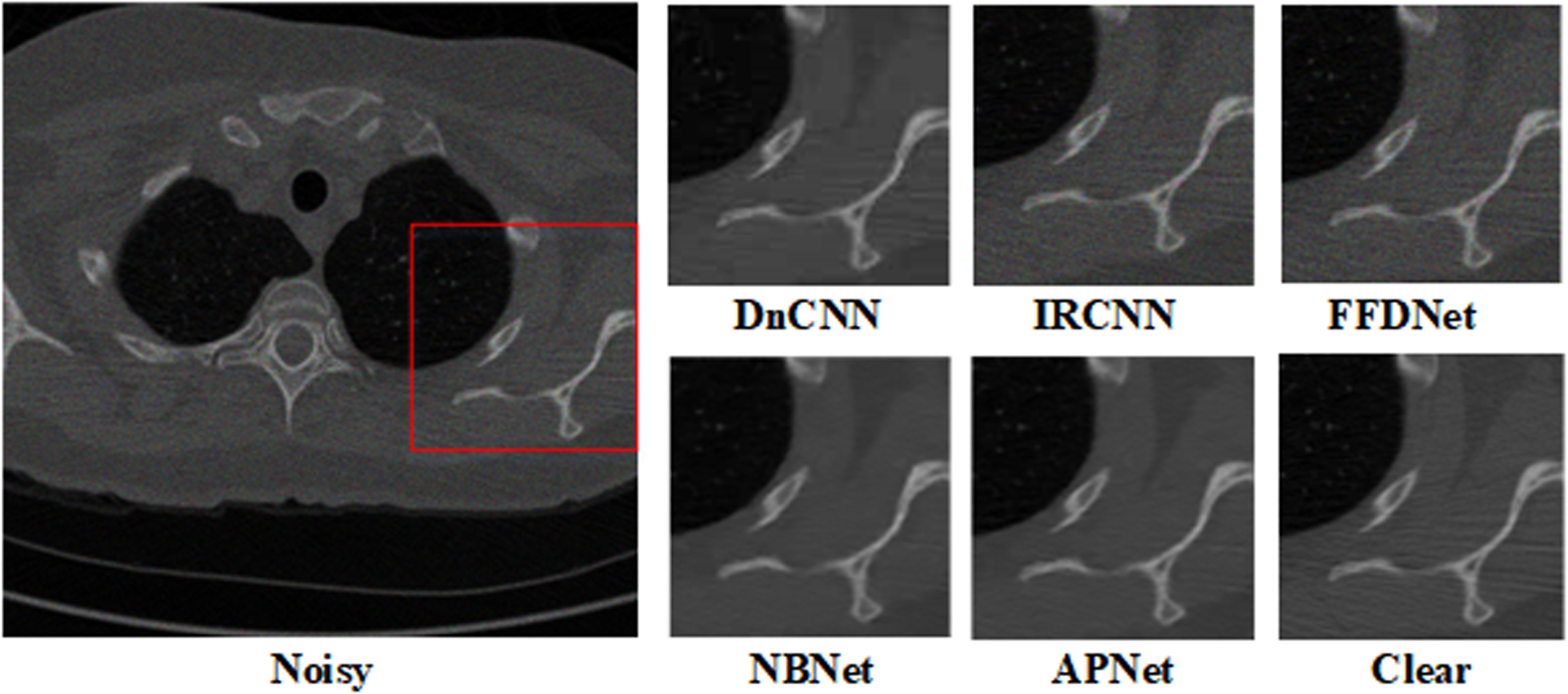
Denoising results of chest images with noise level Poisson×1.
Denoising results of chest images with noise level Poisson×2.
To simulate the mixed Poisson-Gaussian noise, we have added Gaussian noise to images first and then add Poisson noise. Because in the mixed Poisson-Gaussian noise model, the additive white Gaussian noise is usually used, we also consider this type of Gaussian noise. We take into consideration two noise variances for the Gaussian noise with σ= 10 and σ= 20. The average PSNR and SSIM values for the proposed technique and a few commonly used denoising methods are shown in Tables 3 and 4. Our approach considerably enhances the denoising performance of the LDCT images and outperforms other methods in terms of index average value.
Average PSNR (dB) and SSIM results on mixed Gaussian noise with σ= 10 and Poisson noisy images
Average PSNR (dB) and SSIM results on mixed Gaussian noise with σ= 10 and Poisson noisy images
Average PSNR (dB) and SSIM results on mixed Gaussian noise with σ= 20 and Poisson noisy images
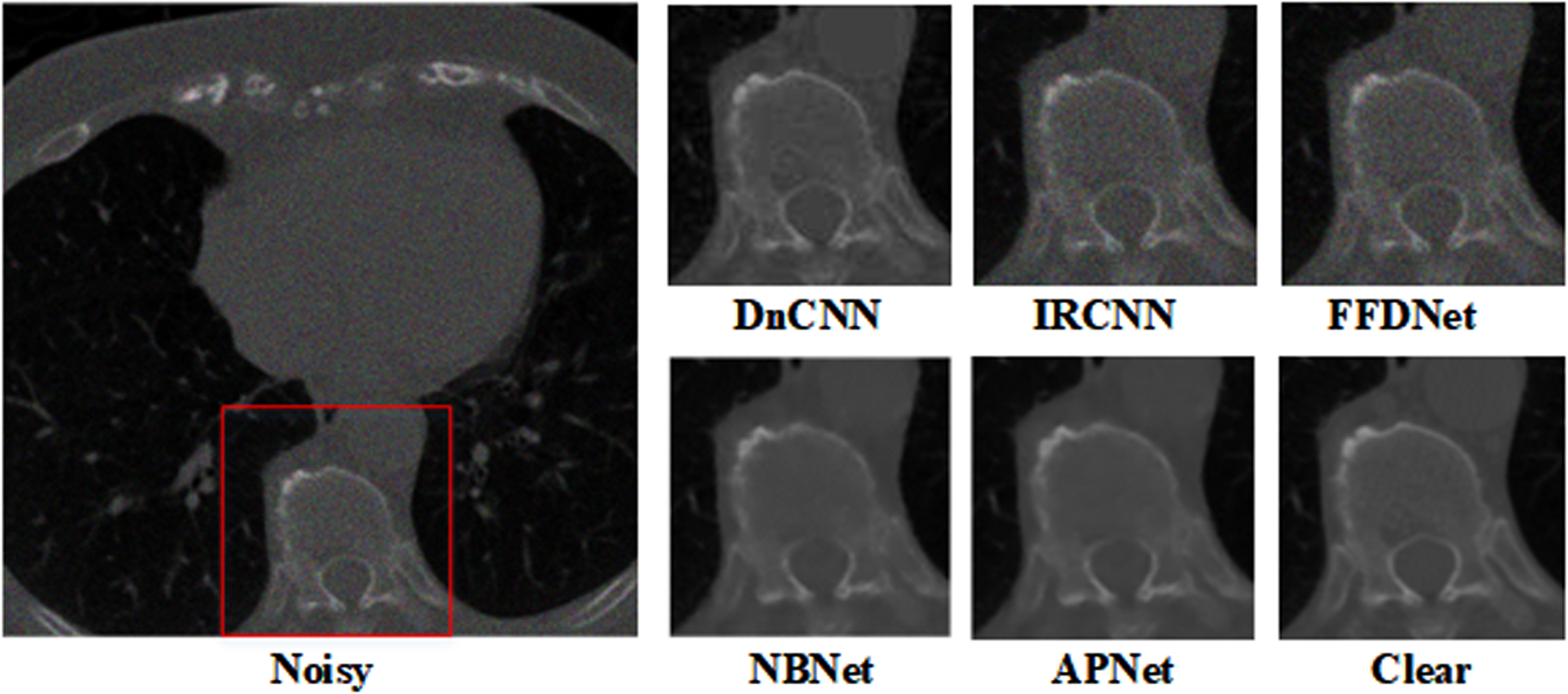
Figures 7 and 8 compare the denoising outcomes for various noise levels. As can be observed, while eliminating noise, our suggested method maintains and preserves the texture of microscopic lung tissue in medical images. The visual comparison confirms the proposed method achieved higher performance in LDCT image denoising.
Denoising results of chest images with mixed Gaussian noise level with σ= 10 and Poisson×1.
Denoising results of chest images with mixed Gaussian noise with σ= 20 and Poisson×2.
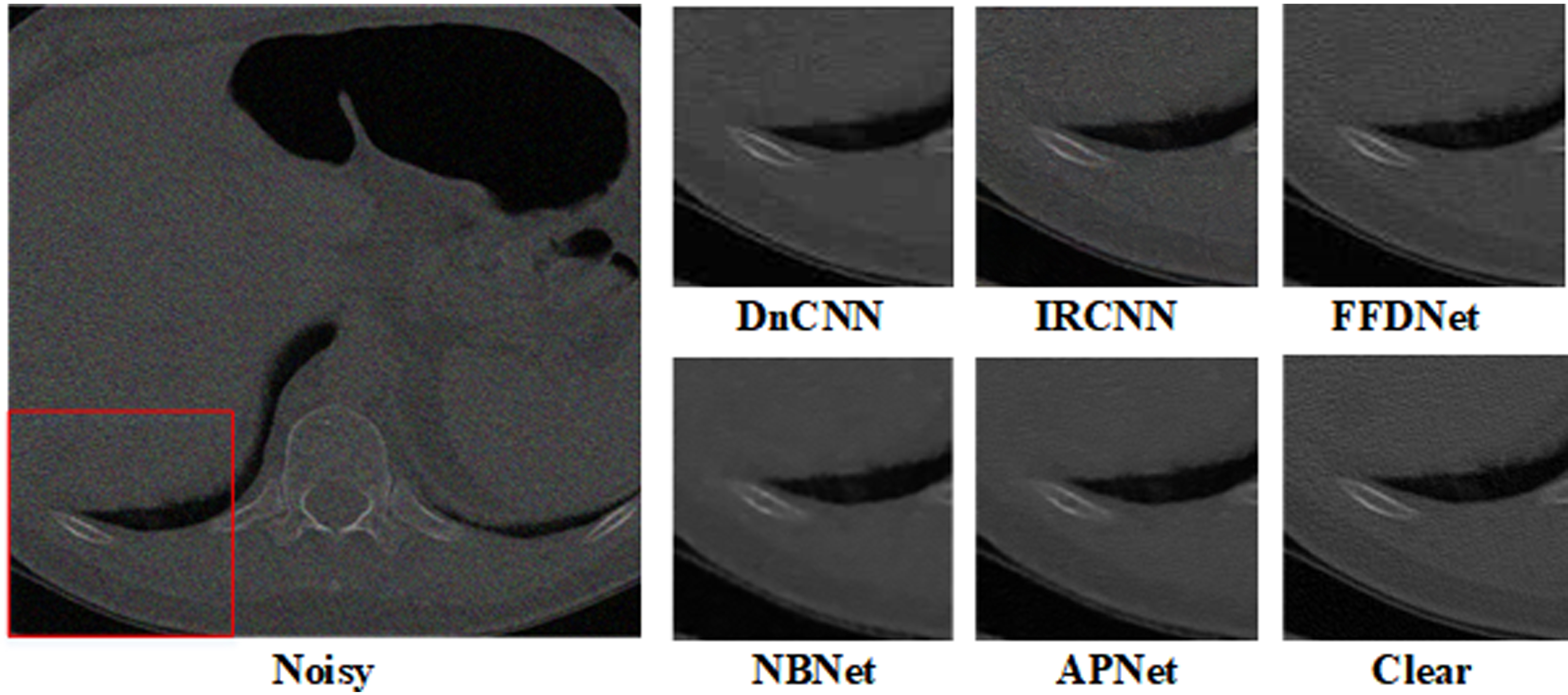
To further verify the denoising ability of the model, we added experiments in real scenarios. By synthesizing noise on dental CT images, the denoising results of different methods were tested. Two groups of experiments are shown in Figs. 9 and 10, which respectively compare the denoising results and evaluation indexes under Poisson noise and Poisson-Gaussian mixed noise. Comprehensively, the proposed method can obtain the best denoising effect.
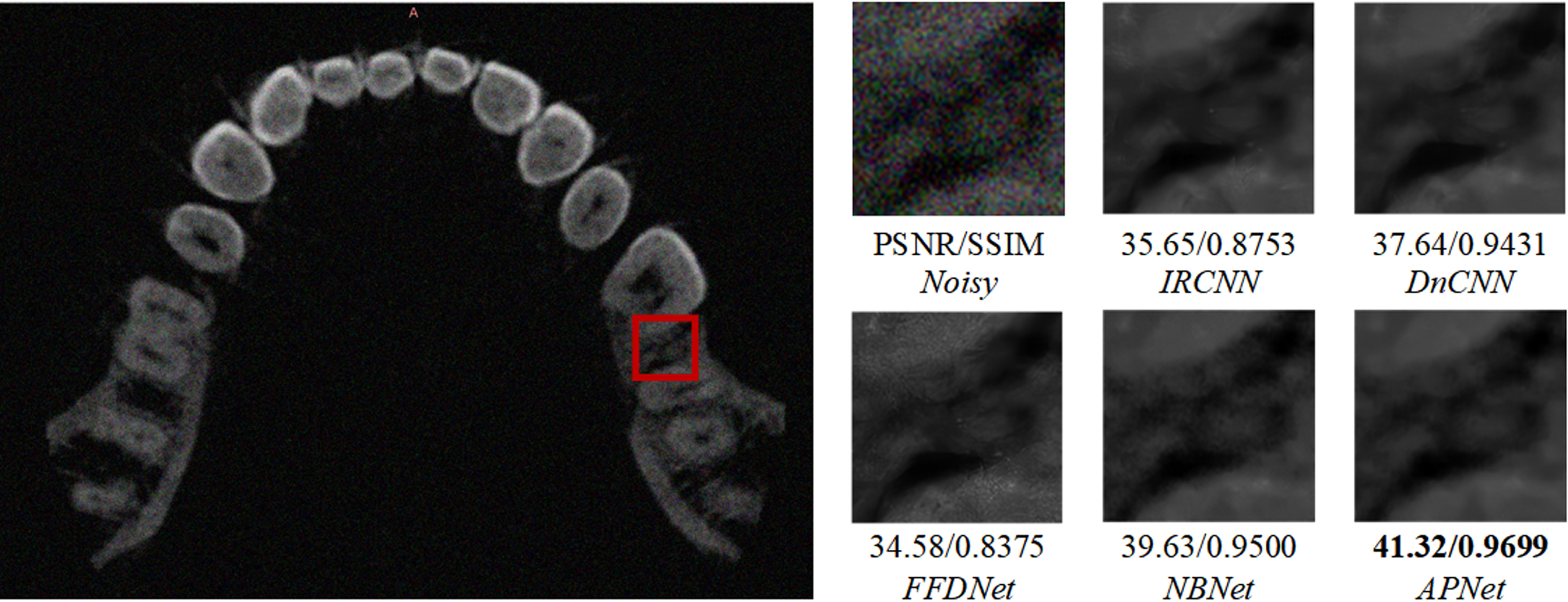
Denoising results of dental CT images with noise level Poisson×2.
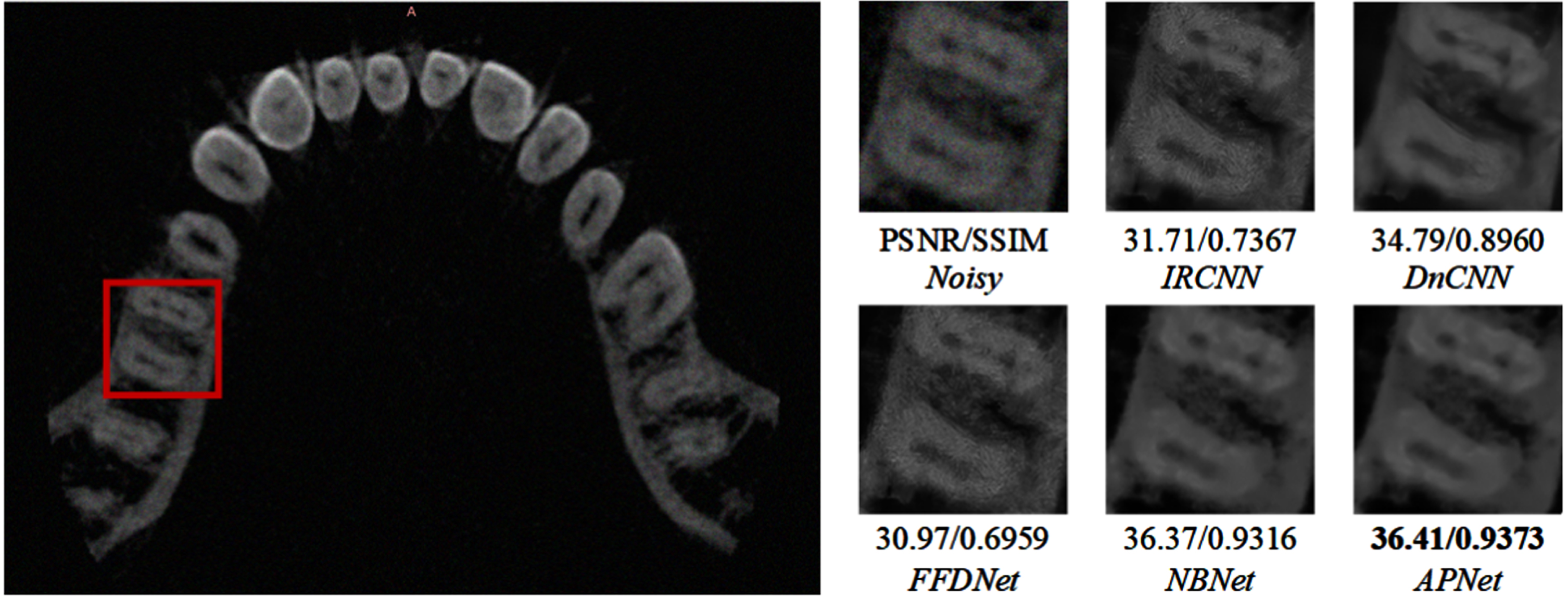
Denoising results of dental CT images with mixed Gaussian noise with σ= 10 and Poisson×1.
In this paper, we have proposed a deep projection-based attention image denoising network. By projecting features onto the network, it is possible to perform adaptive denoising and successfully separate the noise and texture of detail in LDCT images. The network can weight significant features based on content and texture to adjust to essential texture and edge information in medical images according to the use of dual attention residuals, the introduction of convolutional refinement, and the inclusion of orthogonal projection reconstruction. The encoder-decoder structure can also accurately store detailed rich images and guarantee the effectiveness of network operation. The proposed network offers qualitative and quantitative advantages over conventional image denoising methods. This technique can help the pathological judgment process in the medical diagnosis process and significantly improve the processing of uneven texture features in medical CT images.
Footnotes
Acknowledgments
This work is supported by General project of Liaoning Provincial Department of Education, China, No. LJKMZ20222010; Joint Fund LH-JSRZ-202205; Liaoning Provincial Education Science Planning Project JG21EB029. Fund receiver: Dr. Xiang Li. This study is funded by University of Economics Ho Chi Minh City, Vietnam. Fund receiver: Dr. Dang Ngoc Hoang Thanh.