
Abstract
User feedback data (e.g., clicks, dwell time in the product detail page) have been incorporated in the training process of many ranking models for better performance. Such approaches are widely used in many ranking applications, including search and recommendation. Recently, the inherent biases in user feedback data have been studied, which indicates how the users’ behaviors can be affected by factors other than relevancy. By identifying and removing these biases, the ranking models can be further improved. Researchers have developed a variety of debiasing methods on different bias factors. Most of them only focus on one type of bias and pay little attention to different types of bias from a unified perspective. In this paper, we conduct a comprehensive study of bias focusing on the application of ranking problems in recommender systems which is highly important for the research of web intelligence. Then, we share our experiences derived from designing and optimizing unbiased models to improve feeds recommendation. To uncover the effects of biases and achieve better ranking performance, we propose several unbiased models and compare with state-of-the-art models. We conduct extensive offline experiments on real datasets and validate the effectiveness of our method by performing online A/B testing in a real-world recommender system.
Introduction
Users have many behaviors on a website/app, such as clicks, dwell time, purchase, etc. These user feedback data are valuable for machine learning models to explore the underlying patterns, and therefore estimate better ranking results. For example, for a given query, a clicked document is regarded as relevant and a non-clicked document is regarded as non-relevant. Then these labelled data can be utilized to train a classification model [15,52,54]. Using these implicit feedback data has many advantages: (1) Rich information is implied, e.g. users’ interestingness and satisfaction level; (2) The training data is easy to collect and do not require high-cost manual labelling; (3) The feedback data is user-centric and therefore the ranked results tend to be more attractive to users. However, such user behaviors have inherent biases [4,5,16,30–32,38,46,51], i.e., the users can be affected/distracted by other factors than relevancy. For example, the higher ranked items are more likely to be clicked, which is the so-called position bias. In this case, using click data as a positive signal directly in learning to rank methods can lead to sub-optimal results and would cause a feedback loop effect.
In literature, researchers have proposed many debiasing methods on different bias factors. Nevertheless, most of works only focus on one type of bias and pay little attention to different types of bias from a unified point of view. Motivated by this issue, in this paper, we conduct a comprehensive study of bias to identify the appropriate bias factors in learning to rank and discuss the approaches to remove them. First, we formally give a definition of bias. Specifically, bias refers to those factors that will affect customer’s click behaviors, which are only available during offline training, but cannot be obtained or is inconvenient to be obtained in online inference. Next, we identify three types of bias factors, including position bias factor, items’ context bias factor, and users’ status bias factor. Then specifically, we introduce some concrete biases in e-commerce feeds recommendation. Finally, we give the bias estimation methods and introduce how to debias those biases in learning ranking model.
After a comprehensive study of bias, we share our experiences in designing and optimizing models to improve feeds recommendation with bias. Modern e-commerce sites (e.g. Amazon, Alibaba) offer hundreds of millions of products for sale, which is challenging for customers to find their interested items. With the emergence of smartphones, product recommendation has been widely used in mobile websites and apps, which provides users an interactive manner of blended results of recommended products in never-ending feeds. Specifically, when interacting with product stream, the users could click on the items and enter the product detail page. Meanwhile, one could also skip unattractive items and scroll down. The abundant implicit user feedbacks (e.g., clicks, dwell time in the product detail page) are collected for training ranking models. In E-commerce application, the following concepts will be used interchangeably: item/product, user/customer and feed/product recommendation.
To uncover the effects of biases and achieve better ranking performance, we propose several unbiased models by leveraging bias embeddings in deep neural networks [23,56]. We build this work in a real-world e-commerce portal and the proposed idea and approaches can be applied to other learning to rank systems. Empirically, we conduct extensive offline experiments on datasets gathered from a real-world e-commerce portal and validate the effectiveness of our method by performing online A/B testing in a real-world e-commerce recommender system. Experimental results demonstrate that our unbiased models is able to achieve superior quality of recommendation against state-of-the-art baselines.
In summary, we highlight our contributions as follows:
To the bias our knowledge, we are the first to conduct a comprehensive study of bias, including formally proposing a bias definition and discuss how to distinguish factors as bias or not.
We identify three unified types of biases, as well as design the bias estimation for unbiased learning to rank models.
We propose several unbiased neural network models by adopting deep neural networks and bias embedding to reduce the effect of bias.
The proposed models are instantiated on a real-world E-commerce recommendation problem which is very important for Web Intelligence research, and can achieve better performance compared to several state-of-the-art models.
The rest of this paper is organized as follows. Section 2 discusses related works about ranking models, click models, unbiased learning algorithms, and bias in recommender system. Section 3 gives a comprehensive study of bias, including the definition of bias, three types of bias, and example biases in recommender system. We share our model design experience of an unbiased model in Section 4. Our experimental setups and results are described in Section 5. Finally, we conclude this paper in Section 6.
Related work
Ranking models
The ranking models aim to generate a score for each document, with which the documents are ranked in an descending order. The goal of ranking models is to rank the more relevant documents as higher as possible. For a search task, the score is to estimate the relevancy between a query and a document [27,28,37,53,55]. For a recommendation task, the score is to estimate the relevancy between a user and a document/item [26,48,49].
Click models
Under some assumptions about user behavior, we can estimate the parameters of the click model from data via generative maximum likelihood and then use the learned click model for learning to rank. For example, the user browsing model [20] allowed users skipping some results, which extended position based model [41] to condition the examination on a previously clicked position, in addition to the position of the current result. The work [19] designed a Cascade model to separate click bias from relevance signals by assuming that users read search result pages sequentially from top to bottom. To further handle multiple clicks, researchers constructed dynamic Bayesian network model [9] and click chain model [22] by assuming a sequential user behavior over the result list. The click models are usually optimized for the likelihood of observed clicks but not the ranking performance of the overall system.
Unbiased learning algorithms
Unbiased learning algorithms [3,5,46] was proposed to address bias by leveraging counterfactual techniques like inverse propensity weighting (IPW). Different techniques have been proposed to estimate the propensity. For example, in [32], the authors introduced to shuffle position 1 and k and [47] proposed to randomly flip adjacent positions to obtain the propensity based on [46]. To infer bias without relying on randomization, [47] proposed a regression-based Expectation–Maximization (EM) algorithm which fits the Position-Based Model (PBM) into the regular click logs for personal search. [3] proposed random pairs harvesting from logs of multiple rankers in operational systems. Different from two-step methods, i.e., estimating click propensities and using them to train unbiased models, there is an another line of work. [25] introduced unbiased LambdaMART that can simultaneously conduct debiasing of click data and training of a ranker using a pairwise loss function. [5] proposed dual learning algorithm to jointly learn propensity models and ranking models from regular click data by optimizing two objective functions. TrustPBM [2] was proposed to model trust bias in the unbiased learning-to-rank setting for personal search data and [6] introduced to maximize a derived likelihood function for estimating click propensities in e-commerce search. Recently, a recurrent survival ranking framework was proposed by [29] to formulate the unbiased learning-to-rank task as to estimate the probability distribution of user’s conditional click rate. In [45], propensity ratio scoring was derived that takes a holistic treatment on both clicks and non-clicks. The work [38] formalized the problem of selection bias in learning-to-rank systems and proposed an approach for correcting for selection bias.
Bias in recommender system
The work [11] showed how understanding decision bias can improve recommender systems. There are some studies on position bias in recommender systems [16,24,35]. Another types of biases have been proposed, such as selection bias [42], algorithmic confounding bias [8], popularity bias [1,50], and marketing bias [44]. Recently, a novel attribute-based propensity estimation framework for unbiased learning in recommender systems was proposed in [40].
Comprehensive study of bias
In this section, we conduct a comprehensive study of bias from the following aspects. In Section 3.1, we formally give a definition of bias and discuss which factors should be considered as biases in learning to rank problem. In Section 3.2, we identify the types of biases based on the common characteristics of various biases. In Section 3.3, we then introduce some concrete biases in e-commerce feeds recommendation as examples. In Section 3.4, we summarize the bias estimation approaches and introduce how to debias in learning ranking model.
Definition of bias
In this work we focus on learning an unbiased ranking model in the ranking stage of recommender system [17]. Ranking model usually learns a scoring function from user feedback. The click data are user-centric and cheap, but it is biased, i.e., it cannot always convey the true relevance label. This will result in inconsistency between the actual ranking loss and the empirical ranking loss using click data. Thus, we need to estimate the true relevance from the user’s click behavior, which will be influenced by two types of factors:
Factors that are relatively easy to obtain during online service, such as the characteristics of user, product, and interactions between user and product. For example, user characteristics can be the user’s preference for particular brand or shop, etc. We can use the price, click quantity, sales volume, rating, and comment to depict the product. These factors can be timely used as ranking features for online model.
Factors that have an impact on user’s behavior, but cannot be obtained timely or its acquisition will affect the effectiveness of online prediction. For example, a user is more likely to click the higher ranked products than the lower ones regardless of the product’s relevancy. Nevertheless, we can’t get the position of a product until the ranking stage and re-ranking stage (e.g. diversity-aware reordering) [39] in real-world recommender systems are finished.
Researchers have studied the influence of bias in learning to rank [5,32,47]. However, most of them only focus on one type of bias and pay little attention to different types of bias from a unified perspective. In addition, the unified bias is dependent on the specific system, i.e., a bias of one system may become a ranking feature in another system since it may be available during online inference. We argue that the bias definition should be more general and system dependent. Motivated by this issue, we aim to study bias factors from a unified point of view, and identify the appropriate bias factors in real-world recommender system. Therefore, we formally propose a bias definition as follows. Bias refers to factors those will affect the customer’s click behaviors, which can be available during offline training, but cannot be obtained or is inconvenient to be obtained during online inference.
We give three unified types of bias factors as follows.
Position Bias Factor represents the location where the item is placed in, which can influence users’ choice [4,5,47]. In an e-commerce app, it can be represented as ranking order number, page, and in the left or right side of the page. Take ranking order number as example, a user is more likely to click the higher ranked products than the lower ones regardless of the product’s relevancy. Only after all items are sorted by scores, the position value of an item can be obtained. Hence, we can obtain the position values for offline training, but it’s missing for online inference. Items’ Context Bias Factor refers to the contextual situation of item which will influence users’ choice. For instance, the contextual situation could be whether there are similar items around, whether they are clicked or not, whether they are advertising products or recommended products, whether they are product or other materials (e.g., article, video), and the number of times the item was previously impressed. If there are similar items nearby (e.g., both iPhone and Samsung belong to the mobile phone category), a user’s attention on Samsung may be distracted by iPhone. In [43], the authors study context of the composition of the choice set. Only after all items are sorted and exposed to the users, the contexts of target items can be observed. Users’ Status Bias Factor indicates the status of user (e.g. the user’s current mood) which may influence users’ click behaviors. For example, whether the user have seen the products for many times may lead to different feedbacks. In [10], they assume that a user’s examination action is only affected by her actions on previous results in the current query. The current status of users is inconvenient to obtain for online inference, so we incorporate it as a bias.
Example biases in real-world recommender systems
In this section, we investigate instances of biases in real-world recommender systems: position and page for the position bias factor, near exposures for the items’ context bias factor, and previous exposures for the users’ status bias factor.
Position
Position is a representation of an item’s absolute ranking order in the results. In mobile feeds recommendation, four items are usually displayed in one phone screen at the same time. The position value of item is increased from left to right, and from top to bottom accordingly. The lower the position is, the less likely the user will see it [23], so that the product has less probability of being clicked.
Page
Page is a representation of an item’s relative location. Every ten items have the same page number, and the page number of the next ten items will be increased by one. Similarly, as the page increases, the click-through rate (CTR) shows a downward trend. A commonly used practice for dealing with position or page is to inject it as an input feature in model training and then removing the bias through setting position feature to an fixed value such as missing value at serving, which leads to sub-optimal online performance [34]. We use embedding vectors instead in this paper.
Near exposures
Near exposures belongs to the category of items’ context bias factor. Usually, several products are displayed on one phone screen at the same time in a e-commerce site. Inspired from [13,43], the near exposures will affect the CTR of target product. We also leverage the embeddings of near exposed items to represent the near exposures bias, which have good generalization ability and can fully express the item information.
Previous exposures
For users’ status bias factor, we introduce previous exposures as an bias example. We use previous exposures and their labels (e.g., click or non-click, and order or non-order) to model user’s current status. Besides, we can record their browsing time and use it in learning to rank.
Bias estimation
As mentioned above, the biases influence user’s click behavior. If the click-through rate drops, the conversion rate will be decreased, which results in a lower revenue and further lead to poor recommendation. In most prior works for the search, the estimation of propensity is based on the position-based model, where the examination bias in it is the propensity needed. There are some techniques to estimate the examination bias, such as result randomization [32,46], and regression-based EM technique [47]. Nevertheless, there are some limitations of EM method. On one hand, we have to define a reasonable click model when encountering a new bias factor, then need to derive the formulas of parameter estimation. On the other hand, when the bias cannot be enumerated, EM becomes useless. As we know, conducting real-world experiments with random assignments in e-commerce site is not a good way. In this work, by leveraging neural network to deal with biases [23,56], we have the benefit of learning bias without resorting to random experiments and trying different bias combination. Furthermore, neural network can handle various representations of bias, such as numerical values, embeddings, or other substitutions.
Debiasing for learning to rank
Click-through rate prediction is an essential task in industrial applications, such as e-commerce recommendation and online advertising. However, the CTR prediction is known to suffer from the problem of biases in click data. Therefore, we need to deal with the bias for CTR prediction. Recently, deep learning based models have been proposed for CTR prediction task [17,57]. Therefore, we adopt a framework of two deep neural networks to debiasing for CTR prediction. Specifically, one neural network is used to estimate the relevance (relevance NN), i.e., we directly construct the ranking function with neural network. Another neural network is used to model biases (bias NN). In offline training, we model different biases in the training data and give a scalar output, which serves as a bias term to the final prediction of the relevance model. Then we carry out online inference without using the bias NN.
Our model design experience: An unbiased neural network model
In this section, we share our experiences on designing and optimizing models to improve product recommendation with bias. We first describe the biased model and then introduce unbiased neural network models, including a prior unbiased method and our proposed unbiased models.
Biased model
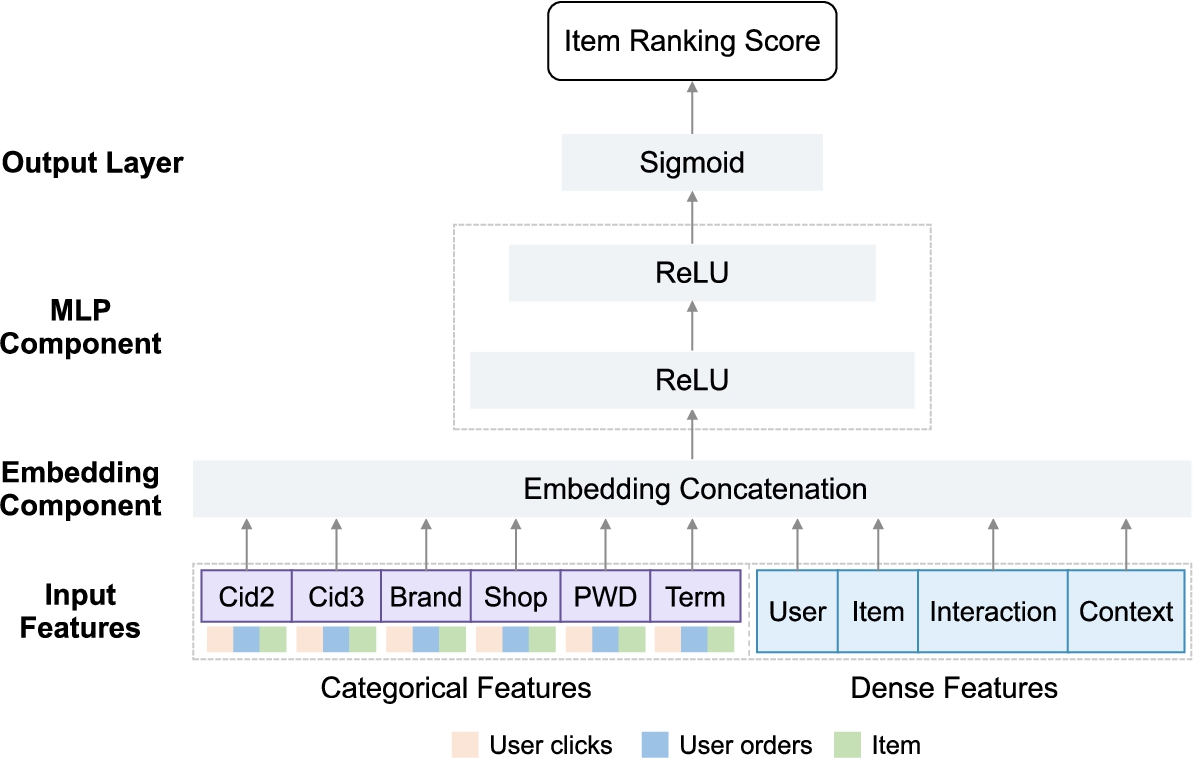
Framework of the biased model.
In this paper, we employ a deep neural network [14,57] for CTR prediction. The network architecture is shown in Fig. 1 which we refer as a biased model. The input layer consists of dense features and categorical features. We set up a lookup layer to transform the one-hot representations of users and items into low-dimensional dense vectors, called embeddings. We concatenate the embeddings with dense features. Then, they go through two fully connected layers (Multi-layer Perceptron, i.e. MLP) with Rectified Linear Units (ReLU) activation function. The output layer has a Sigmoid activation function to produce an output score, which indicates its likelihood of belonging to the clicked category. Let a binary label
Overview
We first introduce two design principles. (1) On one hand, we use the estimated bias as a weight to loss function, and then minimize the unbiased loss function. Given a pair of user request u and item x, we denote them as a feature vector
Please refer to the supplementary material for derivations.
In this section, we first introduce an unbiased baseline model, which fits into the first design principle. We employ the regression-based Expectation–Maximization method to estimate the position bias [47] and combine it with a relevance neural network, which serve as the score function
Bias NN and relevance NN
From now on, we introduce our unbiased model. As shown in Fig. 2, the proposed model consists of two components: (a) modeling bias with a MLP from bias embeddings; (b) learning the relevance prediction with another MLP from dense and categorical features. We give four models as follows: Bias NN as Weight, Multiplication Combination, Addition Combination, and Combined Loss.
Please note that, in the subsequent sections, we leverage the second design principle.
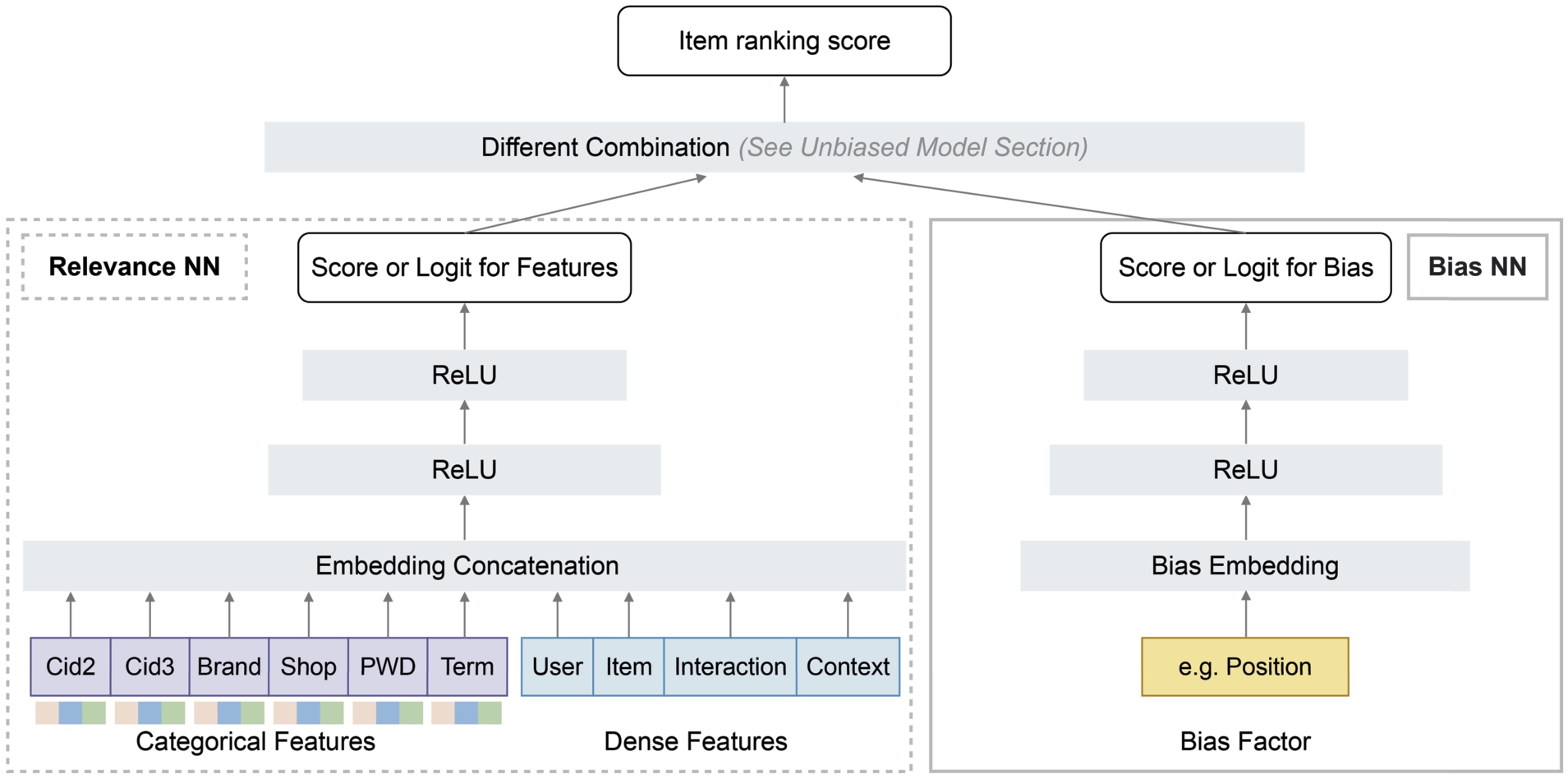
Framework of the proposed unbiased model.
At last, we give a summary of models in Table 1, including the biased neural network, regression EM and relevance neural network, and our proposed unbiased models. The notations will be used in the experiment section.
In this section, we first introduce the experimental settings. Then we conduct extensive experiments to evaluate the effectiveness of the proposed unbiased models.
Setup
Our experiments are based on offline evaluation and online experiments. For offline evaluation, we use the standard framework for supervised learning to rank evaluation by splitting the data into training, validation, and test datasets. We trained a 2-layer MLP model on the training data set. For the relevance NN, the hidden units of the two fully-connected layers are 256 and 128, respectively. For the bias NN, the hidden units are 16 and 8, respectively. We performed Adam optimizer [33] in training with a mini-batch size of 2048 and used an initial learning rate 0.001. The experiments were conducted on a 4 cards GPU and is built on TensorFlow.2
In addition, we evaluate our proposed unbiased models through online A/B testing.A summary of models
Statistics of the datasets used in offline evaluation
Statistics of the datasets used in offline evaluation
To evaluate the proposed approach, we collect traffic logs, including item impressions, clicks and orders label, from a real world e-commerce portal. The input features consist of dense features and categorical features, which describe different aspect of an data sample. For example, the dense features including the features describing user profile, item profile, and user-item interactions. Table 2 summarizes basic statistics of the used dataset in offline evaluation. The training data set consists of about 0.66 billions samples, where each sample has an observed click label 0 or 1. For offline test evaluation, we design two datasets: click dataset and order dataset. On the click dataset, the impression labels are recorded as 0, the click and order labels are recorded as 1. While on the order dataset, the impression and click labels are recorded as 0, and the order labels are recorded as 1.
Evaluation metrics
We describe metrics used in offline evaluation and online experiments. The offline comparisons are made on two tasks [10]: item ranking and click prediction.
For item ranking task, we use the scores of relevance neural network to ranking the items. We adopt Precision (Prec)@k and Mean Reciprocal Rank (MRR)@k [18]. Specifically, for Prec@k, we set a rank threshold k, compute the relevant percentage in top-k items, and ignore items ranked lower than k. Reciprocal rank accounts for the first relevant item in top-k items and MRR@k is the mean Reciprocal rank across multiple requests.
For click prediction task, we ranking all the items with predicted CTR. We use Area Under the ROC Curve (AUC) [21,57] as evaluation metrics for the goodness of predicting user’s clicks.
More importantly, we conduct A/B testing to further validate our unbiased model. We use three important online indicators: Click-through Rate (CTR), Conversion Rate (CVR), and Gross Merchandise Volume (GMV) to measure the online performance.
Note that all metrics are the higher the better.
Comparison of the item ranking performance of each model on order dataset
Comparison of the item ranking performance of each model on order dataset
For item ranking, we report the results on order dataset in Table 3. For the sake of length limitation, we put the result of item ranking on click dataset in the supplementary material. The first column in Table 3 denotes different biases and the second column is the compared models. We compare the unbiased models with biased model and all the values in bold means it is better than the corresponding results of the biased NN. We can observe:
Overall, the unbiased model using near exposures achieve better performance than the biased NN. On the order dataset, the bias near exposures stand out and its exploitation by using multiplication has the best metrics. While on the click dataset, the exploitation of near exposures by using addition performs best.
For position bias, it is worse than the biased NN. As for page bias, the combined loss almost outperforms biased NN on the order dataset. We suspect that, since it is an indirect optimization of relevance NN for the unbiased NN, so the item ranking performance is likely to perform weaker than the biased NN (an direct optimization of relevance NN). On the other hand, it may result from that the granularity of position and page in e-commerce site is too fine for users to perceive compared with near exposures. When users browse and click products, they will first be affected by the items around the target items. Secondly, they will be influenced by the depth of pages.
Besides, biased NN performs better than Reg-EM&Rel NN. We guess it may because the propensity result of regression-based EM method is dependent on training data, which lead to poorer performance than the biased model.
The above observations show that, by using neural network and bias embedding to model the near exposures bias, we can achieve better performances of item ranking than the baselines both in the click and order datasets.
Comparison of the click prediction performance on order dataset
Comparison of the click prediction performance on order dataset
For the click prediction task, we compare the click prediction performance of biased model and unbiased models on the order dataset, as shown in Table 4. All the lines in bold means better performance than the biased model. We have the following observations. Biased NN model outperforms Reg-EM&Rel NN. Different from the item ranking results in Table 3, the position or page bias have better performances than the near exposures. Overall, modelling position bias outperforms using page bias. We can observe that the exploitation of position by using addition combination has the highest AUC value. The results show that, by using neural network and bias embedding to model the position or page bias, we can improve the performance of click prediction on the order dataset.
Online A/B testing results. “∗” indicates a statistically significant improvements (
) over the baseline
Online A/B testing results. “∗” indicates a statistically significant improvements (
We evaluate the performances of
In consideration of there has no unified bias analysis, we first perform a comprehensive study of biases to identify the appropriate bias factors in real-world learning to rank systems, and discuss the approaches to remove the effect of biases. We then share our experiences derived from designing and optimizing models to improve feeds recommendation with bias. To uncover the effects of biases and achieve better ranking performance, we propose several unbiased models by leveraging deep neural network. Empirically, we conduct extensive offline experiments on datasets gathered from a real-world e-commerce portal and validate the effectiveness of our method by performing online A/B testing in a real-world e-commerce recommender system. Experimental results demonstrate that our unbiased models is able to achieve superior performance against state-of-the-art baselines. In this paper, we have given an identification of three types of bias factors, while it is possible that more bias factors exist. Therefore, one possible future work is to investigate more types of potential biases in ranking systems. In our experiments, we consider one bias as an input. However, there are some cases with two or more biases simultaneously. It would be interesting to study how to debias multiple biases at the same time, which can also be our future work.
Footnotes
Acknowledgements
We thank the reviewers and associate editor. This research is supported by the research grant from Natural Sciences and Engineering Research Council of Canada (NSERC).
Derivations of unbiased point-wise loss
One challenge of industrial recommendation systems is the scalability. To achieve a trade-off between model quality and efficiency, a popular choice is to use deep neural network-based point-wise ranking models. Given a pair of user request u and item x, we denote them as a feature vector
Experimental results for the click dataset
We show the experimental results for the click dataset in Table 6. On the click dataset, the exploitation of near exposures by using addition performs best.