
Abstract
Exploring the potential of neuro-symbolic hybrid approaches offers promising avenues for seamless high-level understanding and reasoning about visual scenes. Scene Graph Generation (SGG) is a symbolic image representation approach based on deep neural networks (DNN) that involves predicting objects, their attributes, and pairwise visual relationships in images to create scene graphs, which are utilized in downstream visual reasoning. The crowdsourced training datasets used in SGG are highly imbalanced, which results in biased SGG results. The vast number of possible triplets makes it challenging to collect sufficient training samples for every visual concept or relationship. To address these challenges, we propose augmenting the typical data-driven SGG approach with common sense knowledge to enhance the expressiveness and autonomy of visual understanding and reasoning. We present a loosely-coupled neuro-symbolic visual understanding and reasoning framework that employs a DNN-based pipeline for object detection and multi-modal pairwise relationship prediction for scene graph generation and leverages common sense knowledge in heterogenous knowledge graphs to enrich scene graphs for improved downstream reasoning. A comprehensive evaluation is performed on multiple standard datasets, including Visual Genome and Microsoft COCO, in which the proposed approach outperformed the state-of-the-art SGG methods in terms of relationship recall scores, i.e. Recall@K and mean Recall@K, as well as the state-of-the-art scene graph-based image captioning methods in terms of SPICE and CIDEr scores with comparable BLEU, ROGUE and METEOR scores. As a result of enrichment, the qualitative results showed improved expressiveness of scene graphs, resulting in more intuitive and meaningful caption generation using scene graphs. Our results validate the effectiveness of enriching scene graphs with common sense knowledge using heterogeneous knowledge graphs. This work provides a baseline for future research in knowledge-enhanced visual understanding and reasoning. The source code is available at
Keywords
Introduction
Neuro-symbolic integration is an emerging area of research that aims to jointly leverage the large-scale learning capability and generalizability of neural approaches along with the reasoning capability and explainability of symbolic approaches in Artificial Intelligence (AI) [33]. These hybrid approaches leverage the unique strengths of each class to broaden their scope and applicability while mitigating their individual limitations. For instance, structured knowledge bases and symbolic reasoning help in explaining as well as improving the performance of black-box neural networks [6]. On the other hand, neural networks and machine learning enable large-scale symbolic reasoning and knowledge base completion [15]. In addition, neuro-symbolic integration enables data and memory efficiency in deep learning [34]. These hybrid approaches either involve utilizing neural representations in symbolic reasoning, infusing symbolic knowledge into neural networks or combining both with the integration of neural and symbolic components ranging from loose to moderate and tight coupling [24,97]. To enable AI to reason with human-like common sense, it is essential to integrate knowledge graphs (KG) with deep learning, which is a crucial aspect of neuro-symbolic integration. Common sense knowledge is implicit and difficult to leverage for reasoning, as people often overlook it when they write or speak about everyday scenarios [37]. However, external domain knowledge and factual information presented in symbolic form by heterogeneous KGs offer a promising source of common sense knowledge that can be integrated with deep learning models.
The past decade witnessed significant advances in deep learning and multi-modal approaches in visual intelligence, resulting in solutions to several challenging problems in basic vision tasks, including image classification, object detection, and image segmentation [28]. However, high-level understanding and reasoning about visual scenes require semantic and relational information, particularly about object interactions. As a result, there is a growing trend toward neuro-symbolic hybrid approaches in the area of visual understanding and reasoning, such as symbolic image representation [43], image captioning [98], image reconstruction [39], multimodal event processing [16], video stream reasoning [51], Visual Question Answering (VQA) [49], and image retrieval [96]. These hybrid techniques have various applications, including visual storytelling [95], autonomous driving [83], mathematical reasoning [71], robotic control [80], and medical diagnosis [29] to name a few. The performance of downstream tasks in visual understanding and reasoning depends on the quality and expressiveness of the image representation. To this end, numerous attempts have been made to explicitly and systematically capture the visual features and object interactions. Scene graph, which models objects and their relationships in a structured and semantically grounded way, has become a widely used symbolic image representation [9]. The process of Scene Graph Generation (SGG), illustrated in Fig. 1(a), involves detection and contextual analysis of objects, attributes, and semantic relationships in a visual scene, followed by constructing symbolic scene representation. The symbolic scene graphs serve as a foundation for higher-level visual reasoning, as illustrated in Fig. 1(b) with examples of image captioning and VQA.
The annotation quality and long-tailed distribution of relationship predicates in crowd-sourced datasets severely impact the relationship prediction accuracy, especially for infrequent relationship predicates, and also limit the expressiveness of SGG. In Visual Genome [50], for instance, the head of the distribution comprises highly generic relationship predicates, such as “on”, “has” and “in” etc., as shown in Fig. 1(c). These relationship predicates have limited significance for visual understanding and reasoning because they cannot completely and clearly express the actual visual relationships in the scene. For example, the relationships (man, riding, bike) and (man, wearing, helmet) are more expressive as compared to the relationships (man, on, bike) and (man, has, helmet) as shown in Fig. 1(d). The complexity of visual relationship prediction is further increased by the high variability in the visual appearance of relationships across different scenes and as a result of a huge number of possible object-predicate triplet combinations. For example, the relationships (man, holding, food), (man, holding, bat) and (man, holding, umbrella) have the same predicate but a very different appearance as shown in Fig. 1(e). To this end, several efforts have been made to address these problems by exploring new aspects of visual relationships, such as saliency [115] and heterophily [60]. In addition, cutting-edge techniques such as knowledge transfer [31], self-supervised learning [75], zero-shot learning [52], counterfactual analysis [84] and linguistic supervision [109] have been employed. However, the performance of SGG is still far from practical and needs to improve accuracy, robustness and expressiveness significantly.

(a) A high-level overview of scene graph generation (SGG), including the typical components of the SGG pipeline. (b) Downstream reasoning tasks that leverage scene graphs to generate scene descriptions or to answer questions about the scene. (c) The long-tailed distribution problem in visual genome [50] with generic relationship predicates, such as “on”, “has” and “in”, occur more frequently than the more expressive relationship predicates, such as “riding”, “looking at” and “carrying”. This uneven distribution causes (d) bias in relationship prediction. Relationships like (man, riding, bike) and (man, wearing, helmet) are more expressive than (man, on, bike) and (man, has, helmet), but are underrepresented in the training datasets. (e) The challenge of different appearances of the same visual relationship, all of which cannot be covered in training datasets due to the huge number of possible object-predicate triplet combinations and the high variability in the visual appearance of relationships across different scenes.
Common sense knowledge infusion is a promising approach to addressing these challenges in visual understanding and reasoning. Since the training datasets used for SGG provide limited or no explicit common sense knowledge, the background information and related facts about the scene elements can help in improving the expressiveness of the representation, and the performance of downstream reasoning [44]. In this direction, statistical and language priors have been extensively used as sources of common sense knowledge in SGG. However, the heuristics of the statistical priors do not generalize well, and the limitations of semantic word embeddings affect the performance of language priors, especially in the case of infrequent or unseen relationships. Some KGs, such as ConceptNet [81], and WordNet [65], have been leveraged in SGG. These KGs provide text-based and lexical knowledge representing different forms and notions of common sense. Still, they do not provide broad common sense knowledge about visual concepts. Heterogeneous KGs, such as Common Sense Knowledge Graph (CSKG) [38], cover a significantly broader range of dimensions of common sense. These heterogeneous sources are essential but underappreciated sources for common sense knowledge infusion in visual understanding and reasoning. These sources provide a rich and diverse collection of facts about the semantic elements in visual scenes, such as “car is used for transport”, “street is used for parking”, and “car requires parking”. The intelligent integration of heterogeneous KGs can enrich the understanding of complex visual scenes, thus providing rich and expressive representations for effective visual reasoning.
The enriched scene graph shown in Fig. 2 is a motivating example of common sense knowledge-based scene graph representation. The conventional scene graph of the image contains visual relationships, including (woman, on, tennis_court) and (woman, holding, racket), that represent objects and their interactions in the scene. Common sense knowledge extracted from CSKG plays a crucial role by providing related facts and background knowledge, such as the edges (racket, usedFor, playing_tennis) and (woman, capableOf, playing_tennis), that are essential for reasoning. In this paper, we systematically and substantially extend our previous ESWC work [43], in which we proposed a common sense knowledge-based SGG technique. It generates a scene graph of an image using a DNN-based vision-language hybrid approach, followed by graph refinement and enrichment that incorporates pertinent details and background information about the visual concepts in the scene using based on the similarity of graph embeddings. The experimental analysis was performed on the VG dataset using Recall@K (R@K) metric for evaluating the visual relationship prediction performance. The main improvements and new contributions made in this paper are listed below.
We present a loosely-coupled neuro-symbolic visual understanding and reasoning framework consisting of three main components (Fig. 2): Image Representation: DNN-based object detection and multi-modal pairwise relationship prediction to construct symbolic scene graphs of images. Knowledge Enrichment: Rule-based refinement and enrichment of the scene graphs by leveraging common sense knowledge about the scene entities extracted from a heterogeneous KG. Downstream Reasoning: DNN-based visual reasoning using enriched scene graphs for caption generation. We evaluated the proposed approach on the standard datasets, Visual Genome [50] and Microsoft COCO [12], using the standard evaluation metrics, Recall at K (R@K) [62] and mean R@K (mR@K) [85]. As a result of knowledge enrichment, the relationship recall scores R@100 and mR@100 increased from 36.5 and 11.7 to 39.1 and 12.6, respectively, on the Visual Genome dataset and similar results were observed for the COCO dataset (Fig. 4). We also performed a comparative analysis with the state-of-the-art methods on the benchmark VG dataset using R@K and mR@K metrics, which showed that our approach outperformed them by a significant margin (Table 3). We employed the enriched scene graphs in downstream visual reasoning for image captioning. As a result of enrichment, the SPICE and CIDEr scores of the image captioning model increased from 20.7 and 115.3 to 23.8 and 131.4, respectively (Fig. 7). The qualitative analysis showed that the enriched scene graphs resulted in more intuitive and meaningful captions (Fig. 8). The proposed captioning approach outperformed the state-of-the-art scene graph-based image captioning techniques in terms of SPICE and CIDEr scores and achieved comparable performance in terms of BLEU, ROGUE and METEOR scores (Table 4).
The proposed framework combines neural and symbolic approaches to jointly leverage the efficient learning capabilities of neural networks (in SGG and downstream tasks) and the representational and reasoning power of symbolic approaches (in scene representation and knowledge enrichment). The neural and symbolic components in the proposed framework are loosely coupled as per the taxonomy of neuro-symbolic approaches in [24,97]. Contrary to tightly coupled neuro-symbolic approaches, the neural and symbolic components in our framework operate in tandem to enhance collective performance without directly affecting each other’s internal parameters. The interdependence of the neural and symbolic components is crucial for the framework’s performance, i.e. the accuracy of the predicted scene graph elements plays a crucial role in effectively enriching the representation, which ultimately impacts the performance of downstream reasoning tasks. This type of neuro-symbolic integration is weak but flexible and effective, as depicted by the state-of-the-art results. The rest of the paper is organized as follows: Section 2 presents a comprehensive review of the recent literature on this topic. The proposed neuro-symbolic visual understanding and reasoning framework is explained in Section 3. The comprehensive experiments and results are presented in Section 4. The limitations of the proposed framework and future improvements are discussed in Section 5, followed by the conclusion and prospects in Section 6.
Image representation
The scene graph is a structured image representation with detailed semantic information about a visual scene, including objects, attributes and visual relationships. The SGG techniques generally follow a bottom-up approach, as shown in Fig. 1(a), in which objects in an image are detected using DNN-based object detectors, pairwise relationships between the objects are predicted using DNN-based vision-language hybrid features. The object pairs and relationship predicates are linked to construct the symbolic scene graph of the image. The most challenging task in SGG is the prediction of pairwise visual relationships between objects due to highly imbalanced training datasets in terms of relationship predicates [45] (Fig. 1(c–d)), highly varying visual feature representation of the relationships in different scenes (Fig. 1(e)) and insufficient training samples of a huge number of possible triplet combinations, which considerably limit the accuracy, robustness and expressiveness of SGG techniques. The current limitations of SGG and its promising use in various visual reasoning tasks have attracted significant attention in visual intelligence research [9]. The compositional SGG approaches detect the subject, predicate, and object independently and aggregate them subsequently. For example, Li et al. [54] used the detected objects to create independent region proposals for each subject, predicate, and object, consolidated with DNN features and used to predict the relationship triplets. Such approaches are scalable but have limited performance when dealing with unseen or infrequent relationships. On the other hand, the relationship triplets are treated as standalone units by the visual phrase models for SGG. For instance, Sadeghi et al. [77] used DNNs to detect objects and simultaneously predict visual phrases or triplets, which were refined by comparing them to other predictions. As compared to compositional models, the visual phrase models are less sensitive to the diversity of visual relationships, but they require larger training data with a large vocabulary of objects and relationship predicates. Teng et al. [86] proposed Structured Sparse R-CNN, composed of a set of learnable triplet queries that capture the general prior for object pairs and their relations and a structured triplet detection cascade that provides an initial guess of scene graphs for subsequent refinement.
Recent SGG techniques integrate visual and semantic embeddings in DNNs for large-scale visual relationship prediction. Zhang et al. [114] captured visual features in three streams, one for the subject, one for the predicate, and one for the object; the features from the subject and object streams are integrated with the predicate stream to utilize the subject-object interactions for visual relationship prediction. During the learning process, features obtained from the text space are incorporated as labelling for the visual features. Peyre et al. [74] used a visual phrase embedding space during learning to enable analogical reasoning for predicting unseen relationships and to reduce sensitivity to appearance changes of visual relationships. Tang et al. [84] leveraged causal inference with the total direct effect mechanism to alleviate relationship prediction bias in SGG. Zhang et al. [115] proposed visual Saliency-guided Message Passing (SMP) to improve relationship reasoning and generalizability of scene graphs by focusing on the most prominent visual relationships using ordinal regression. Lin et al. [60] exploited heterophily in visual relationships for refining relationship representation and improving message passing in a Graph Neural Network (GNN) along with an adaptive re-weighting transformer module for information integration across layers. Except for a few recent approaches, the existing approaches mainly focus on visual and linguistic patterns in images while ignoring the background knowledge and relevant facts about visual concepts and their structural patterns in heterogeneous KGs, which have significant potential for understanding and interpretation of visual concepts. The approaches explicitly using common sense knowledge in KGs for visual understanding and reasoning are discussed in the following section.
Knowledge enrichment
Since the 1960s, one of the major challenges in AI has been the acquisition, representation, and reasoning with common sense knowledge [64], which has led the research community to build and compile knowledge sources containing common sense knowledge in various forms and contexts [37]. For common sense knowledge enrichment, early approaches in visual understanding and reasoning relied on statistical and language priors. Deep Relational Network (DR-Net) was proposed to recognize visual relationships, with DNNs leveraging statistical interdependence between objects and predicates [17]. Chen et al. [11] and Zellers et al. [112] used pre-computed frequency priors to incorporate common sense knowledge from dataset statistics for visual relationship prediction. Recently, Zhou et al. [118] proposed a deep sparse graph attention network (DSGAN) for SGG, which uses graph attention networks to learn object and predicate features and constructs a sparse KG representation using statistical co-occurrence information. Lu et al. [62], on the other hand, used region-based CNN for object detection followed by a relationship prediction framework based on semantic word embeddings. Based on Deep Q-network and language priors, Liang et al. [57] proposed a variation-structured reinforcement learning framework for visual relationship prediction. Although SGG approaches based on statistical [11,17,112,118], and language [57,62] priors have improved relationship prediction performance in SGG, these approaches have several drawbacks that limit their expressiveness and applicability in mainstream visual reasoning methods. Statistical priors are often dependent on heuristic approaches that are not generalizable. On the other hand, language priors are vulnerable to the constraints of semantic word embeddings, particularly when generalizing to infrequent objects in training datasets.
Knowledge graphs used for common sense knowledge infusion in SGG
Knowledge graphs used for common sense knowledge infusion in SGG
KGs have emerged as a viable source of common sense knowledge in visual understanding and reasoning. Table 1 summarizes KGs used for common sense knowledge infusion in SGG. ConceptNet [81] is a multilingual KG with mostly lexical nodes interconnected via 34 relations. The data in ConceptNet is mostly drawn from the crowdsourced Open Mind Common Sense corpus, and it is supplemented with knowledge from other sources such as WordNet. WordNet [65] is a hand-made lexical database with ten relations. WordNet covers over 200 languages and contains terms, meanings, and taxonomical structures. Visual Genome (VG) [50] is a crowd-sourced dataset of images with entity and relationship annotations. VG contains more than 40K relationships, and the concepts are automatically linked to WordNet senses. Seven key KGs [4,47,50,65,78,81,90] containing common sense knowledge in different dimensions were systematically and formally integrated into a rich, well-connected and heterogeneous Common Sense Knowledge Graph (CSKG) [38] with 2.16 million nodes, 58 relations and 6 million edges. Some SGG approaches based on KGs extract relevant knowledge from a KG and integrate it into the model at one of the stages within the SGG pipeline [26,67,82,112]. Alternatively, some approaches employ graph-based message propagation [11,52,99,111] to embed structural information from the KG in the model representations. Wan et al. [91] proposed complementing visual features with common sense knowledge from KGs to improve relationship predicate prediction in SGG. Gu et al. [26] employed recurrent neural networks with an attention mechanism for SGG and encoded background knowledge for each object retrieved from ConceptNet into the network layers. Similarly, Kan et al. [40] leveraged background knowledge from ConceptNet in zero-shot learning for visual relationship prediction in SGG. Existing techniques primarily include triplets from knowledge sources while ignoring the substantial structural information beyond individual triplets. Buffelli et al. [8] proposed a neuro-symbolic regularization technique that uses negative integrity constraints to enforce symbolic background knowledge on a neural model. This is achieved through a logic-based loss function, which amends the neural network to minimize the maximum violation of the integrity constraints. Van et al. [88] introduced Differentiable Fuzzy Logics (DFL) that constructs differentiable loss functions based on fuzzy logic semantics in neuro-symbolic models to perform learning and reasoning simultaneously using gradient descent. To tackle the challenge of fusing deep learning representations with expert knowledge, Diaz et al. [19] proposed a compositional convolutional neural network that utilizes symbolic representations and an explainable training procedure to align deep learning processes with symbolic representations in the form of knowledge graphs. Donadello et al. [20] introduced a semantic image interpretation method based on logic tensor networks, a statistical relational learning framework. The authors addressed the challenge of zero-shot learning by exploiting similarities with other seen relationships and background knowledge, expressed with logical constraints between subjects, relations, and objects, to predict triples not present in the training set.
When consolidated, the richness, diversity, and coverage of common sense knowledge are merged into a heterogeneous knowledge source, which can have a greater impact on downstream tasks. Zareian et al. [110] proposed Graph Bridging Network (GB-Net) that generates a scene graph, connects its entities and edges to the corresponding entities and edges in a common sense graph retrieved from VG, WordNet, and ConceptNet, and uses GNN-based message propagation to refine the scene graph relationships recursively. Guo et al. [27] extracted relational and common sense knowledge from VG and ConceptNet and encoded it in an Instance Relation Transformer (IRT) for SGG. These SGG techniques employed multiple knowledge sources but have not been employed for visual reasoning tasks, which is important to evaluate the effectiveness of incorporating common sense knowledge from multiple KGs. Some visual reasoning techniques for VQA [61,99] have directly used a subset [93] of DBpedia, ConceptNet, and WebChild; however, these techniques did not use scene graphs, ignoring the structural information about visual concepts. CSKG is the most recent, largest and systematically consolidated common sense knowledge source. Ma et al. [63] used CSKG in language models and reported state-of-the-art performance in common sense question answering by combining diverse, relevant knowledge from CSKG and aligning it with the task. CSKG was employed for knowledge infusion in SGG [43], and the resulting scene graphs were employed for downstream image synthesis; however, there is a significant need for investigation of heterogeneous common sense knowledge-based scene graphs in the mainstream visual reasoning tasks, such as image captioning, VQA and image retrieval. Moreover, some knowledge infusion methods leveraged KG embeddings, widely adopted in the vector representation of entities and relationships in KGs [72]. The KG embeddings capture the latent properties of the semantics in the KG, due to which similar entities are represented with similar vectors. The similarity of entities in the vector space is interpreted using vector similarity measures, such as cosine similarity. KG embeddings have been used in several link prediction tasks, including visual relationship prediction [3], recommender systems [92] and SGG [43].
Scene graphs are widely utilized in image captioning, VQA, MEP, image retrieval, and image synthesis, among the common visual reasoning tasks. The expressiveness and quality of the scene graphs determine the efficacy of these downstream tasks. Image captioning techniques use scene graphs to leverage the pairwise semantic relationships between objects to effectively generate scene descriptions, as it is more challenging to achieve it solely based on vision-language features. Abstract Scene Graph (ASG) [10] representation recognizes and encodes users’ intentions in scene graphs along with the semantics information that aids the generation of desired and diverse text descriptions of scenes. The scene graphs generated by SMP [115] based on the saliency of visual relationships were leveraged for improved caption generation. Scene graphs have been found to be more efficient and adaptive than textual scene descriptions for image generation while text-based techniques struggle to sustain performance when the number of objects and their interactions increases [39]. Common sense knowledge-based scene graphs were leveraged in a scene graph-based image synthesis network that resulted in the generation of more realistic images [43]. Gu et al. [26] employed ConceptNet for object and phrase refinement based on common sense knowledge in an attention-based RNN for image reconstruction from scene graphs.
VQA models determine the best answers to questions about visual scenes using multi-modal features and semantic relationships in scene graphs [14]. For example, Zhang et al. [113] proposed encoding the structural information of scene graphs in GNNs to leverage it as the foundation for VQA. Similarly, Ziaeefard et al. [119] proposed a Graph Attention Networks-based VQA method for encoding scene graphs along with background knowledge from ConceptNet. Graph-based visual semantic models are also used for multimedia stream representation for real-time multimedia event processing in IoMT [46]. Objects and attributes are detected using DNNs, and symbolic rules are employed to identify spatial-temporal interactions between the objects, which are required for matching high-level events questioned by users. In image retrieval, scene graphs are used to explicitly define the semantics and structured information of images, allowing images to be efficiently retrieved from large-scale databases depending on their content. Schroeder et al. [79] presented Structured Query-based Image Retrieval (SQIR) that represents visual interactions in scene graphs as directed sub-graphs for the graph matching task in image retrieval using scene graph embeddings and structured queries. Donadello et al. [21] presented a novel approach for Semantic Content-Based Image Retrieval (SCBIR) that leverages ontological constraints and low-level image features to generate semantically rich descriptions of image content. The authors propose an unsupervised method where the interpretation of an image is considered a logical model of an ontology describing the image domain.
Proposed visual understanding and reasoning framework
The proposed visual understanding and reasoning framework comprises three main components: (1) scene graph generation (neural) for (symbolic) image representation, (2) scene graph enrichment (symbolic) using a common sense KG, and (3) downstream reasoning (neural) to leverage the enriched scene graphs for image captioning. The proposed framework is illustrated in Fig. 2, and each component of the framework is detailed in the following sections. The neural and symbolic components of the framework are loosely coupled but interdependent, i.e. the accuracy of object detection is required for effective enrichment, and the performance of downstream reasoning depends on the quality of scene graphs. This design enables independent operation and modification of each component without affecting the others, thus ensuring flexibility.
Scene graph generation
The SGG method in the proposed framework uses a multi-modal DNNs cascade for object detection followed by pairwise visual relationship prediction to generate a scene graph of an image. We used Faster RCNN [76] for object detection. The ResNeXt-101-FPN CNN architecture [59] serves as the base feature extractor for the Faster RCNN. For an input image I, the Faster RCNN outputs the object bounding boxes b and object class labels l of each object that is detected in the image. The feature maps F are also taken from the underlying CNN in Faster RCNN, which are used for extracting and encoding region features in a subsequent step.
The relationships between object pairs are predicted after object detection and feature map extraction. The region features a of each detected object are computed using RoIAlign [30], which is applied to the image regions
The combined pairwise object features

Proposed neural-symbolic visual understanding and reasoning framework based on enriched scene graph representation.
These three types of extracted features of the object pairs, i.e.
The scene graph representation captures the objects in an image and their visual relationships. Still, it may not fully convey the meanings and inter-relatedness of the objects, which are crucial for complete visual understanding. To address this limitation, we enhance the scene graphs by infusing common sense knowledge to improve the expressiveness of the representation and correct any inaccurately predicted visual relationships. We used CSKG [38] for the enrichment of scene graphs with background knowledge and related facts in the form of triplets. Graph embeddings were used to compute the similarity of nodes in the graph refinement and enrichment stages, as similar entities often have similar vector representations in the embedding space. Algorithm 1 was used to refine the scene graph predictions by eliminating potentially irrelevant or redundant predictions, indicated by the similarity of labels, overlapping of bounding boxes, and the structural patterns of their corresponding nodes in CSKG. At this stage, the prediction errors have been reduced by eliminating objects with high intersection over union (IoU) of its bounding boxes or high CSKG embedding similarity scores with another object in the scene graph.

Graph refinement

Graph enrichment
We utilized Knowledge Graph Toolkit (KGTK) [36] to query CSKG and pull new triplets that contain a subject or object node in the predicted scene graph. Duplicate triplets and triplets with the same node on both ends, such as (person, synonym, person) and (chair, similarTo, chair), are not useful and thus eliminated in the pre-processing stage prior to complementing the scene graph with the new triplets. Next, we connect the nodes of the new triplets that have reasonable structural similarities with the corresponding object nodes in the scene graph to those object nodes. This enables the addition of new triplets to the scene graph. If a node from a new triplet already exists in the scene graph, we link the edge of that triplet to the existing object node instead of creating a redundant node. After enriching the scene graphs with common sense knowledge, the enriched scene graphs need to be employed for downstream reasoning tasks. This requires the enriched scene graphs to be post-processed to match the original representation model of scene graphs for consistent integration with downstream reasoning models. In the VG subset of CSKG, all predicates of the triplets are expressed as “LocatedNear” edge type. We substitute the predicates of the new triplets having VG as their source in CSKG with the most common predicate in the original VG dataset between the nodes of those triplets. This step relies on the statistical prior knowledge about relationships in VG for consistency and better interpretation of visual relationships in downstream reasoning. The process of complementing scene graphs with common sense knowledge from CSKG is outlined in Algorithm 2. During the experiments, a threshold of 0.5 was set in both algorithms to achieve a balance between the quantity and precision of visual relationships detected through SGG and those added via knowledge enrichment.
The proposed framework includes scene graph-based image captioning [117] as a downstream task of scene graph generation and knowledge enrichment, which enables it to generate precise and meaningful captions using the enriched scene graphs. The proposed framework can be extended to include more scene graph-based visual reasoning tasks, such as VQA, multimodal event processing, and image retrieval.
The enriched scene graphs are first decomposed into sub-graphs and the sub-graphs are sampled using neighbour sampling [48]. This involves selecting a random set of seed nodes on the graph and extracting the immediate neighbours of these nodes, along with the edges connecting them, to get a sampled sub-graph. Similar sub-graphs are removed to avoid redundancy, and greedy non-maximal suppression is used to filter out sub-graphs with high IoU scores of their nodes. The nodes and edges of the scene graph are then augmented with their visual features and text embeddings using a Graph Convolutional Network (GCN). The GCN aggregates information from the neighbouring nodes via multiple graph convolutions and ReLU layers to integrate contextual information within the scene graph. The relationship information has been integrated using GCN; thus, only the features of nodes obtained from the GCN are used for sub-graph scoring to select the most meaningful sub-graphs. A two-layer Multi-Layer Perceptron (MLP) with a sub-graph readout function [102] is used to rank sub-graphs, followed by sigmoid normalization. Finally, an attention-based LSTM is used to assign importance scores to the sub-graph nodes. These scores are used by a language LSTM to generate sentences corresponding to each sub-graph. Sub-graph scoring and ranking ensure that the network prioritizes the most relevant and meaningful triplets for generating captions. The enriched scene graph-based caption generation pipeline is illustrated in Fig. 2.
Experiments and results
Experimental setup
Platform specifications and tools
We used a machine with AMD Ryzen 7 1700 Eight-Core Processor, 16 GB RAM, NVIDIA TITAN Xp GPU (with 12 GB memory) and Ubuntu 18.04 LTS (64-bit) operating system for implementation and experiments. We used the PyTorch deep learning library1
We used the Visual Genome (VG) [50] and Microsoft COCO [12] datasets for experimental analysis and benchmark comparison of SGG. VG contains 108K labelled images and annotations for objects and visual relationships. COCO contains 132K labelled images with annotations for objects and captions. The standard subset [101] of VG contains the most frequent 50 predicate classes and 150 object classes, which was used for training Faster RCNN and SGG pipeline. 70% of the training samples were used for training, out of which 5000 samples were used for validation during training. The remaining 30% of samples were used for testing. Following the state-of-the-art methods, we used the standard split [41] of COCO for the evaluation of enriched scene graph-based image captioning. The standard split comprises 5K images each for validation and testing and the rest for training. We used the pre-trained CSKG embeddings [38] for computing the similarity of nodes in the graph refinement and enrichment steps of the scene graph enrichment part of the proposed framework.
Evaluation metrics
We used cross-entropy
We used mean average precision (
For evaluating the performance of SGG, we used the commonly used evaluation metrics for relationship prediction, i.e. Recall@K (
Results
Training and evaluation of models
The two main components of the SGG pipeline in the proposed framework, i.e. Faster RCNN for object detection and the LSTM-based deep learning cascade for relationship prediction, are separately trained and evaluated. The Faster RCNN model was trained on images and ground truth annotations of objects in the dataset using Stochastic Gradient Descent (SGD) as an optimizer, a batch size of 2, and an initial learning rate of 0.002, which was reduced by a factor of 10 after 60,000 and 80,000 iterations. We froze the trained Faster RCNN model and trained the entire SGG pipeline on images and ground truth annotations of visual relationships in the dataset using SGD as an optimizer, batch size of 4, and an initial learning rate of 0.04 that was reduced by a factor of 10 twice during training when validation performance stopped improving considerably. The Scene Graph Detection (SGDet) configuration was used for training and evaluation of the SGG pipeline. Figure 3 depicts the plots of training loss and validation
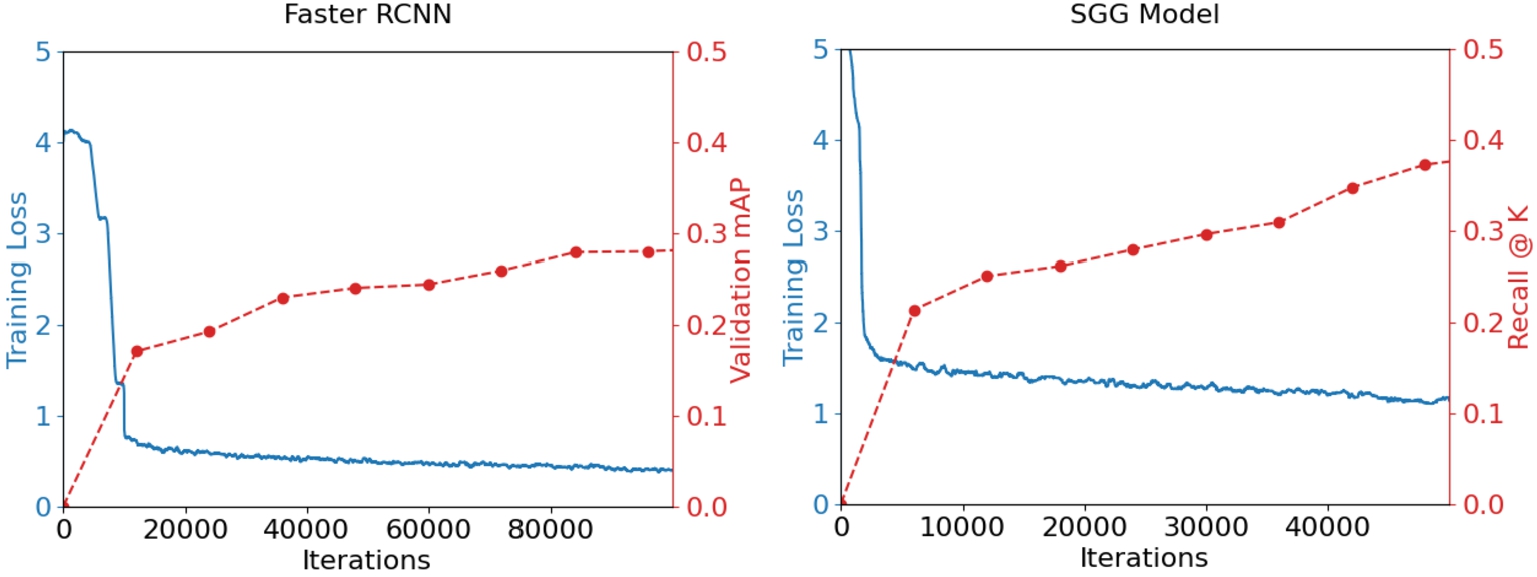
Training progress plots along with periodic validation checks of the faster RCNN and SGG models.
We repeated the SGG evaluation after integrating the proposed knowledge enrichment steps after the typical scene graph generation. We obtained
Benchmark comparison
Table 2 and Table 3 present a detailed comparison of the proposed enriched scene graph-based approach with the state-of-the-art SGG techniques evaluated on the benchmark VG dataset. The recall scores for each method are reported for the same experimental setting of SGG, i.e. SGDet, for the sake of fair comparison. The performance of the proposed SGG method without knowledge enrichment is comparable to the existing data-centric SGG techniques, as shown in Table 2. On the other hand, the proposed SGG method combined with knowledge enrichment obtained considerably higher recall scores, outperforming the state-of-the-art knowledge-based SGG techniques, as shown in Table 3. The proposed method achieved
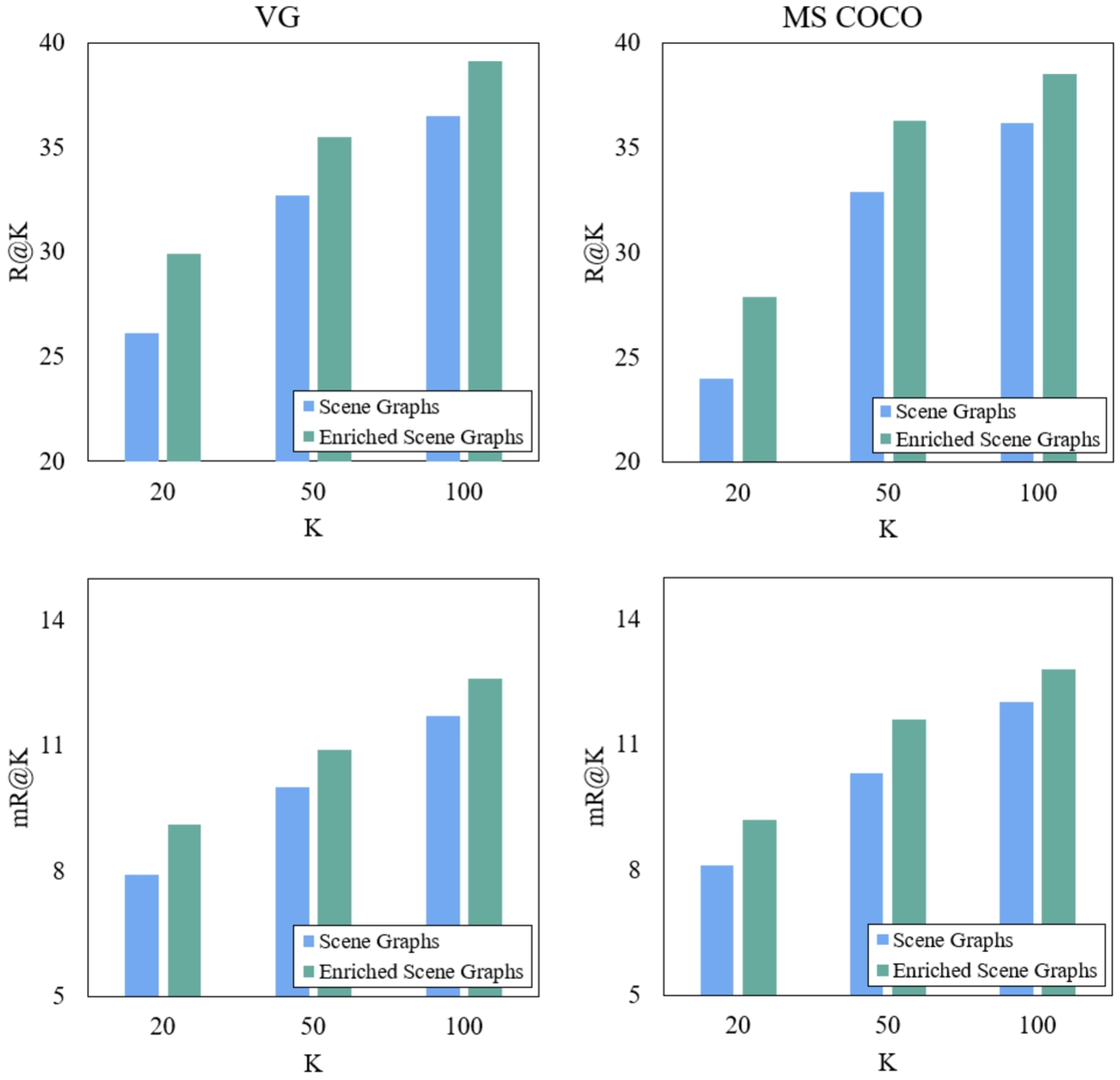
Comparison of conventional and enriched scene graphs on VG and COCO datasets using recall rates R@K and mR@K.

Detailed comparison of conventional and enriched scene graphs on top 50 relationship predicates in VG dataset using R@100.
Figure 6 shows some qualitative results of the proposed enriched scene graph-based SGG approach. The enriched scene graphs contain background facts about the underlying concepts, additional knowledge about the spatial placement of objects in the scene relative to each other, and possible physical interactions between the objects, in addition to the objects and their pairwise visual relationships. The scene graph representations are supplemented by common sense relationships about object interactions, such as (person, holding, surfboard) in the first row in Fig. 6, and spatial placement, such as (tree, on, street) in the last row of Fig. 6. In the third row in Fig. 6, (person, requires, eating) and (food, usedFor, eating) represent useful background facts extracted from CSKG.
Detailed comparison of the proposed method with the state-of-the-art data-centric SGG methods using common evaluation metrics (R@K and mR@K) and standard split of the VG dataset
Detailed comparison of the proposed method with the state-of-the-art data-centric SGG methods using common evaluation metrics (R@K and mR@K) and standard split of the VG dataset
Detailed comparison of the proposed method with the state-of-the-art common sense knowledge-based methods using common evaluation metrics (R@K and mR@K) and standard split of the VG dataset

Examples of the proposed enriched scene graphs for visual understanding and reasoning (VG images).

Comparison of image captioning using conventional scene graphs and proposed enriched scene graphs in terms of the standard evaluation metrics. Enriched scene graphs resulted in higher SPICE and CIDEr scores and comparable performance in terms of BLEU, ROGUE and METEOR scores.
Comparison of the proposed enriched scene graph-based image captioning method with the state-of-the-art conventional scene graph-based image captioning methods using the common evaluation metrics and standard split [41] of the COCO dataset [12]. The proposed approach outperformed the state-of-the-art methods in terms of SPICE and CIDEr scores and achieved comparable performance in terms of BLEU, ROGUE and METEOR scores
We trained the image captioning network on the COCO dataset that was used to train the SGG pipeline. The trained network was used to generate captions using conventional scene graphs as well as enriched scene graphs. The performance of the image captioning network using both types of scene graphs is evaluated in terms of the standard evaluation metrics, including SPICE, BLEU, CIDEr, ROGUE and METEOR, which is presented in Fig. 7. The SPICE and CIDEr scores obtained by the image captioning model increased from 20.7 and 115.3 to 23.8 and 131.4, respectively with the use of enriched scene graphs, which depicts the efficacy of enriched scene graphs for image captioning. The performance of both types of scene graphs is comparable in terms of BLEU, ROGUE and METEOR scores. Table 4 shows the performance comparison of the proposed enriched scene graph-based image captioning approach with the state-of-the-art scene graph-based image captioning techniques. The proposed approach outperforms the state-of-the-art techniques in terms of SPICE and CIDEr scores and achieves comparable performance in terms of BLEU, ROGUE and METEOR scores.

Qualitative results of caption generation using conventional scene graphs (blue) and enriched scene graphs (green). Enriched scene graphs result in more expressive and meaningful image captions. (COCO images.)
SPICE and CIDEr are the most reliable among these metrics because SPICE best simulates human judgment in the evaluation by leveraging semantic and structural information, while CIDEr was originally designed for scene graph-based image captioning. Since the network divides the enriched scene graph into subgraphs and prioritizes the most relevant and meaningful triplets for creating captions, it generally produces more meaningful text, leading to higher evaluation scores. Some qualitative results of caption generation using conventional and enriched scene graphs are shown in Fig. 8. The promising results show that enriched scene graphs result in more expressive and meaningful captions as compared to conventional scene graphs.
Limited contextual relevance
Heterogenous KGs are currently the richest and most diverse sources of common sense knowledge as they capture detailed structural and semantic features of general concepts in the world. The enrichment of scene graphs using heterogeneous KGs has demonstrated its potential to enhance the overall performance of SGG, as depicted by our results. Due to limited contextual knowledge [22], heterogenous KGs cannot always provide contextually valid information about visual concepts in a specific scene. Although a cosine similarity threshold is employed to effectively remove irrelevant relationships, it does not account for the contextual relevance of the new relationships, which can potentially lead to the addition of out-of-context relationships, limiting contextual reasoning ability in downstream tasks.
This highlights the need to evaluate the quality of enrichment based on the ratio of accurate and contextually valid relationships among the newly added relationships and use context-aware approaches [32,66] to ensure that only relevant as well as contextually valid relationships are added during enrichment, thus refining the enriched scene graph further and leading to improved downstream reasoning. Future work can also investigate approaches with feedback mechanisms, adaptive thresholds and domain-specific knowledge for incorporating new relationships based on contextual similarity in addition to structural and semantic similarity for more accurate and reliable scene graph enrichment. Future work in this direction would enable contextually accurate image generation [43] and historical image colourization [100].
Lack of knowledge-infused learning in DNNs
We have demonstrated that incorporating common sense knowledge to enrich scene representation improves the accuracy and expressiveness of SGG and enhances downstream reasoning. However, in our current approach, we only use common sense knowledge to enrich the scene graphs and do not integrate it into the neural learning process. Alternatively, common sense knowledge can be directly infused into neural learning: within the layers or feedback mechanism of DNNs [1,18] for SGG. This can enable DNNs to learn the patterns of visual relationships more deeply and effectively, leading to more accurate SGG that will no more require scene graph refinement. Enrichment can only add external contextual knowledge to the scene graphs, leading to more meaningful visual understanding and reasoning.
While this research direction has been explored to some extent [26,110], it would be useful to investigate how leveraging heterogeneous common sense knowledge can alleviate the challenges of such approaches. CSKG offers a diverse knowledge base that consolidates multiple sources of knowledge, making it interesting to explore and identify the common relation types and sources within CSKG that are most useful for visual understanding and reasoning. Heterogenous KGs can also help extract rules about visual concepts and encode them into DNNs [35,68] for visual understanding and reasoning. In addition, leveraging hard constraints from ontologies as prior knowledge [19,21], i.e. ontological priors, could help minimize errors in scene graph generation. Future work along these lines can pave the way for leveraging the maximum potential of common sense knowledge enrichment and infusion in visual understanding and reasoning.
Temporal patterns in visual relationships
The proposed framework can effectively process image data to extract semantic elements in scenes, predict visual relationships between them and enrich the representation for improved downstream reasoning. Visual understanding and reasoning also requires processing video data, where visual relationships can vary temporally, and common sense knowledge and rules about the varying patterns can be essential for reasoning. The proposed framework, in its current form, can only process each video frame individually, which can be computationally inefficient and might overlook the temporal aspects of visual relationships.
To address this limitation, incorporating object tracking [7], temporal dimensions of visual relationships [95], and graph aggregation [103,116] can help achieve semantically-rich and knowledge-enhanced summarization, providing a more concise and meaningful representation of video content. Integrating video data processing capabilities can expand the framework’s capabilities beyond static image understanding and reasoning. For example, it can use temporal relationship variations and common sense knowledge to identify congestion patterns and detect suspicious behaviour in smart city surveillance applications [87].
Limited generalizability to new concepts
Scene graphs rely on visual relationship prediction that struggles with the long-tailed distribution problem of crowdsourced datasets, limiting their generalizability to unseen or rare visual relationships. Many meaningful relationship predicates have only a few instances, making it difficult for SGG methods to learn their feature representations. On the other hand, frequent predicates are generic and do not express visual relationships as clearly as underrepresented predicates. In addition, visual feature representations of relationships can vary greatly across different scenes. Collecting and annotating sufficient training samples for all possible triplet combinations is nearly impossible, indicating the need for zero-shot approaches in addition to augmenting data-centric SGG methods with common sense knowledge.
Zero-shot [40,99] and few-shot [27] learning approaches for SGG have been explored to address this limitation. Zero-shot learning approaches utilize prior knowledge about seen relationships to recognize unseen visual relationships. In contrast, few-shot learning approaches learn from a small set of labelled examples for new relationships, which is useful where collecting large amounts of labelled data is costly and time-consuming. These approaches can leverage heterogeneous KGs to incorporate common sense knowledge and retrieve relevant triplets for improved prediction of unseen and rare visual relationships. Furthermore, knowledge transfer and distillation approaches [74,107] for SGG can employ models trained on heterogeneous KGs to use prior knowledge about visual relationships for enhanced generalization in SGG, making it more practical and applicable in real-world scenarios.
Weak neuro-symbolic integration
Loose coupling between neural and symbolic components in the proposed framework provides greater flexibility and ease of modification. However, the independent operation of neural and symbolic components in the framework can limit its ability to fully exploit the complementary strengths of neural learning and symbolic reasoning. The neural components may not be able to effectively leverage the knowledge encoded in the symbolic component, and the symbolic component may not be able to effectively incorporate the rich visual features learned by the neural component. While a tighter neuro-symbolic integration can lead to the increased complexity of the framework, it also has the potential to effectively combine the strengths of the neural and symbolic components to reason about complex relationships and improve its overall performance. As an example, instead of a sequential process, a feedback mechanism can be incorporated for error correction in scene graph generation, which could complement and further improve upon corrections carried out in the enrichment method.
To this end, few SGG techniques [26,27,110] have explored neuro-symbolic integration with neural learning diluted with external knowledge. Still, their applicability to downstream reasoning and incorporation of rich and diverse common sense knowledge is limited. A fully integrated neuro-symbolic visual understanding and reasoning framework can have symbolic structures integrated and grounded within neural learning, such as using tensor calculus to imitate logical reasoning in DNNs [94]. It can also be achieved with program synthesis approaches [13,70] or structured knowledge augmentation in reinforcement learning models [104]. An end-to-end approach will make the framework capable of inductive learning for logical reasoning in visual understanding and reasoning. Incorporating heterogeneous common sense knowledge at the same time can further strengthen the neuro-symbolic integration in visual understanding and reasoning, paving the way for groundbreaking progress in the field.
Conclusion
Scene graph is a semantically rich, symbolic image representation generated using DNNs, which is used for several visual reasoning tasks, including image captioning, VQA, image retrieval, multimedia event processing and image synthesis. Scene graph enrichment using heterogeneous KGs is a promising approach toward alleviating the existing challenges in SGG and improving the expressiveness of visual understanding and reasoning frameworks. We proposed a loosely-coupled neuro-symbolic visual understanding and reasoning framework based on enriched scene graphs. A DNNs cascade is used to generate symbolic scene graphs, followed by rule-based graph refinement and enrichment using common sense knowledge extracted from a heterogeneous KG in the form of related facts and background information about the scene graph elements. We integrated an image captioning model in the proposed framework as a downstream task of scene graph enrichment. The evaluation results showed that common sense knowledge enrichment resulted in a significant increase in the relationship recall scores R@100 and mR@100 from 36.5 and 11.7 to 39.1 and 12.6, respectively, on the VG test set. The proposed framework outperformed the state-of-the-art methods in terms of R@K and mR@K on the standard split of VG in the comparative analysis. These encouraging results depict the efficacy of scene graph enrichment using heterogeneous KGs. Moreover, the enriched scene graphs resulted in an increase in SPICE and CIDEr scores obtained by the downstream image captioning model from 20.7 and 115.3 to 23.8 and 131.4, respectively. The proposed approach outperformed the state-of-the-art scene graph-based image captioning techniques in terms of SPICE and CIDEr scores and achieved comparable performance in terms of BLEU, ROGUE and METEOR scores. The future work will focus on multi-hop KG reasoning to further refine visual relationship detection, zero- and few-shot methods with knowledge transfer for improved generalization and scalability, including more downstream reasoning tasks and strengthening the neuro-symbolic integration in visual understanding and reasoning.
Footnotes
Acknowledgement
This publication has emanated from research conducted with the financial support of Science Foundation Ireland under Grant number 18/CRT/6223 and 12/RC/2289_P2. For the purpose of Open Access, the author has applied a CC BY public copyright licence to any Author Accepted Manuscript version arising from this submission.