
Abstract
Using knowledge graph embedding models (KGEMs) is a popular approach for predicting links in knowledge graphs (KGs). Traditionally, the performance of KGEMs for link prediction is assessed using rank-based metrics, which evaluate their ability to give high scores to ground-truth entities. However, the literature claims that the KGEM evaluation procedure would benefit from adding supplementary dimensions to assess. That is why, in this paper, we extend our previously introduced metric Sem@K that measures the capability of models to predict valid entities w.r.t. domain and range constraints. In particular, we consider a broad range of KGs and take their respective characteristics into account to propose different versions of Sem@K. We also perform an extensive study to qualify the abilities of KGEMs as measured by our metric. Our experiments show that Sem@K provides a new perspective on KGEM quality. Its joint analysis with rank-based metrics offers different conclusions on the predictive power of models. Regarding Sem@K, some KGEMs are inherently better than others, but this semantic superiority is not indicative of their performance w.r.t. rank-based metrics. In this work, we generalize conclusions about the relative performance of KGEMs w.r.t. rank-based and semantic-oriented metrics at the level of families of models. The joint analysis of the aforementioned metrics gives more insight into the peculiarities of each model. This work paves the way for a more comprehensive evaluation of KGEM adequacy for specific downstream tasks.
Keywords
Introduction
A knowledge graph (KG) is commonly seen as a directed multi-relational graph in which two nodes can be linked through potentially several semantic relationships. More formally, a knowledge graph

Excerpt of a KG containing some influential political figures and relations holding between them.
KGs are inherently incomplete, incorrect, or overlapping and thus major refinement tasks include entity matching, question answering, and link prediction [48,72]. The latter is the focus of this paper. Link prediction (LP) aims at completing KGs by leveraging existing facts to infer missing ones. In the LP task, one is provided with a set of incomplete triples, where the missing head (resp. tail) needs to be predicted. This amounts to holding a set of triples
The performance of KGEM for LP is evaluated using rank-based metrics such as Hits@K, Mean Rank (MR), and Mean Reciprocal Rank (MRR) that assess whether ground-truth entities are indeed given higher scores [54,72]. However, various works recently raised some caveats about such metrics [5,19,64]. For instance, they are not well-suited for drawing comparisons across datasets [5]. More importantly, they only provide a partial picture of KGEM performance [5]. Indeed, LP can lead to nonsensical triples, such as
Few works propose to go beyond the mere traditional quantitative performance of KGEMs and address their ability to capture the semantics of the original KG, e.g., domain and range constraints, hierarchy of classes [22,40,49]. According to Berrendorf et al. [5], this would give a more complete picture of the performance of a KGEM. This is why we advocate for additional qualitative and semantic-oriented metrics to supplement traditional rank-based metrics and propose Sem@K to address this need. The relevance of using semantic-oriented metrics – more specifically Sem@K – is clearly visible in Fig. 2: Sem@K provides a supplementary dimension to the evaluation procedure and allows to confidently choose between two models. They are equally good in terms of rank-based metrics but Model A predicts entities that are semantically valid w.r.t. the range constraint.
More specifically, in this work, our goal is to assess the ability of popular KGEMs to capture the semantic profile of relations in a LP task, i.e., whether KGEMs predict entities that respects domain and range of relations. Henceforth, we refer to this aspect as the semantic awareness of KGEMs. To do so, we build on Sem@K, a semantic-oriented metric that we previously introduced [20,21] In [20], Sem@K was specifically defined for the recommendation task which was seen as predicting tails for a unique target relation. Sem@K was then extended in [21] to the more generic LP task, where not only tails but also heads are corrupted and all relations are considered. In the present work, we deepen the study of the semantic awareness of KGEMs by proposing different versions of Sem@K that take into account the different characteristics of KGs (e.g., hierarchy of types). Moreover, the semantic awareness of a wider range of KGEMs is analyzed – especially convolutional models. Likewise, a broader array of KGs is used, in order to benchmark the semantic capabilities of KGEMs on mainstream LP datasets. Thus, the following research questions are addressed:
RQ1: how semantic-aware agnostic KGEMs are? RQ2: how the evaluation of KGEM semantic awareness should adapt to the typology of KGs? RQ3: does the evaluation of KGEM semantic awareness offer different conclusions on the relative superiority of some KGEMs compared to rank-based metrics?
Accordingly, the main contributions of this work are:
to evaluate KGEM semantic awareness on any kind of KG, we extend a previously defined semantic-oriented metric and tailor it to support a broader range of KGs.
we perform an extensive study of the semantic awareness of state-of-the-art KGEMs on mainstream KGs. We show that most of the observed trends apply at the level of families of models.
we perform a dynamic study of the evolution of KGEM semantic awareness vs. their performance in terms of rank-based metrics along training epochs. We show that a trade-off may exist for most KGEMs.
our study supports the view that agnostic KGEMs are quickly able to infer the semantics of KG entities and relations.
The remainder of the paper is structured as follows. Related work is presented in Section 2. Section 3 outlines the main motivations for assessing the semantic awareness of KGEMs. Section 4 subsequently presents Sem@K, the semantic-oriented metric that fulfills this purpose. Sem@K comes in different flavors based on the typology of the datasets at hand and the intended use cases. In Section 5, we detail the datasets and KGEMs used in this work, before presenting the experimental findings in Section 6. A thorough discussion is provided in Section 7. Lastly, Section 8 outlines future research directions.
Link prediction using knowledge graph embedding models
Several LP approaches have been proposed to complete KGs. Symbolic approaches relying on rule-based [16,17,31,38,47] or path-based reasoning [12,32,79] are somewhat popular but are not considered in the present work. Instead, KGEMs are the focus of this paper.
In particular, this work is concerned with assessing the semantic awareness of agnostic KGEMs. The semantic awareness of such models is defined as their ability to score higher entities whose types belong to the domain and range of relations. Agnostic KGEMs are defined as KGEMs that rely solely on the structure of the KG to learn entity and relation representations. In this respect, these models differ according to several criteria, such as the nature of the embedding space or the type of scoring function [25,54,70,72]. In this work, KGEMs are considered with respect to three main families of models that are traditionally distinguished in the literature.
Combining embeddings and semantics
The possibility of using additional semantic information has been extensively studied in recent works [10,23,30,37,46,71,78]. In general, the semantic information stems directly from an ontology, originally defined by Gruber as an “explicit specification of a conceptualization” [18]. Ontologies formally describe a specific application domain of interest (e.g. education, pharmacology, etc.) in which several classes (or concepts) and relations are identified and formally specified. Ontologies support KG construction by providing a schema that specifies the nature of entities, the semantic profile of relations, and other constraints that give the KG a semantic coherence.
A significant part of the literature incorporates such semantic information to constrain the negative sampling procedure and generate meaningful negative triples [23,30]. For instance, type-constrained negative sampling (TCNS) [30] replaces the head or the tail of a triple with a random entity belonging to the same type (
Semantic information can also be embedded in the model itself. In fact, some KGEMs leverage ontological information such as entity types and hierarchy.
Embedding models project entities and relations of a KG into a vector space. Thus, the semantics of the original KG may not be fully preserved [23,49]. As stated by Paulheim [49], because embeddings are not meant to preserve the semantics of the KG, they are not interpretable and this can severely hinder explainability in domains such as recommender systems. Consequently, Paulheim [49] advocates for semantic embeddings. Similarly, Jain et al. [22] perform a thorough evaluation of popular KGEMs to better assess whether embeddings can express similarities between entities of the same type. A key finding is that because of overlapping relations among entities of different types, fine-grained semantics cannot be properly reflected by embeddings For instance, the task of finding semantically similar entities does not always provide satisfying results when working with entity embeddings [22].
Evaluating KGEM performance for link prediction
KGEM performance is evaluated in two stages. During the validation phase, KGEM performance is evaluated on the validation set
In both cases, the rank of the ground-truth entity from the test (resp. validation) set is used to compute aggregated rank-based metrics based on the top-K scored entities. The rank of the ground-truth entity can be determined in two different ways that depend on how observed facts – i.e. facts that already exist in the KG – are considered. In the raw setting, observed facts outranking the ground-truth are not filtered out, while this is the case in the filtered setting. For instance, assuming head prediction is performed on the given ground-truth triple (
KGEM performance is almost exclusively assessed using the following rank-based metrics: Hits@K, Mean Rank (MR), and Mean Reciprocal Rank (MRR) [19]. Disagreements exist as to how and when these metrics can be used and compared properly. In the following, we recall their definitions and discuss their limits.
As mentioned in Section 1, these metrics present some caveats. LP is often used to complete knowledge graphs, where the Open World Assumption (OWA) prevails. KGs are incomplete and, due to the OWA, an unobserved triple used as a negative one can still be positive. It follows that traditional evaluation methods based on rank-based metrics may systematically underestimate the true performance of a KGEM [73].
In addition, the aforementioned rank-based metrics have intrinsic and theoretical flaws, as pointed out in several works [5,19,64]. For example, Hits@K does not take into account triples whose rank is larger than K. As such, a model scoring the ground-truth in position
Recent works recommend using adjusted version of the aforementioned metrics. The Adjusted Mean Rank (AMR) proposed in [1] compares the mean rank against the expected mean rank under a model with random scores. In [5], Berrendorf et al. transform the AMR to define the Adjusted Mean Rank Index (AMRI) bounded in the
In Section 2.2, several approaches incorporating the semantics of entities and relations into the embeddings were mentioned. However, in such cases, the use of semantic information such as entity types and the hierarchy of classes is intended to improve KGEM performance in terms of the aforementioned rank-based metrics only. The underlying semantics of KGs is considered as an additional source of information during training but the ability of KGEMs to generate predictions in accordance with these semantic constraints is never directly addressed. This encourages further assessment of the semantic capabilities of KGEMs, as firstly suggested in [21]. In our work, we directly address this issue by assessing to what extent KGEMs are able to give high scores to triples whose head (resp. tail) belongs to the domain (resp. range) of the relation. When such information is not available – i.e. the KG does not rely on a schema containing
Motivations and problem formulation
Motivating example
To motivate the use of Sem@K to evaluate KGEM quality, this section builds upon a minimalist example which is representative of the issue encountered while benchmarking the performance of several KGEM on the same dataset. As depicted in Fig. 2, two KGEMs that have been trained on the whole training set are tested on a batch of test triples. These KGEMs are referred to as Model A and Model B. Without loss of generality, it is assumed that the test set only comprises the three triples shown in Fig. 2. For the sake of clarity, only the tail prediction pass and the top-5 ranked candidate entities are depicted in Fig. 2. It should be noted that the performance of both models are strictly equal in terms of MR, MRR and Hits@K with
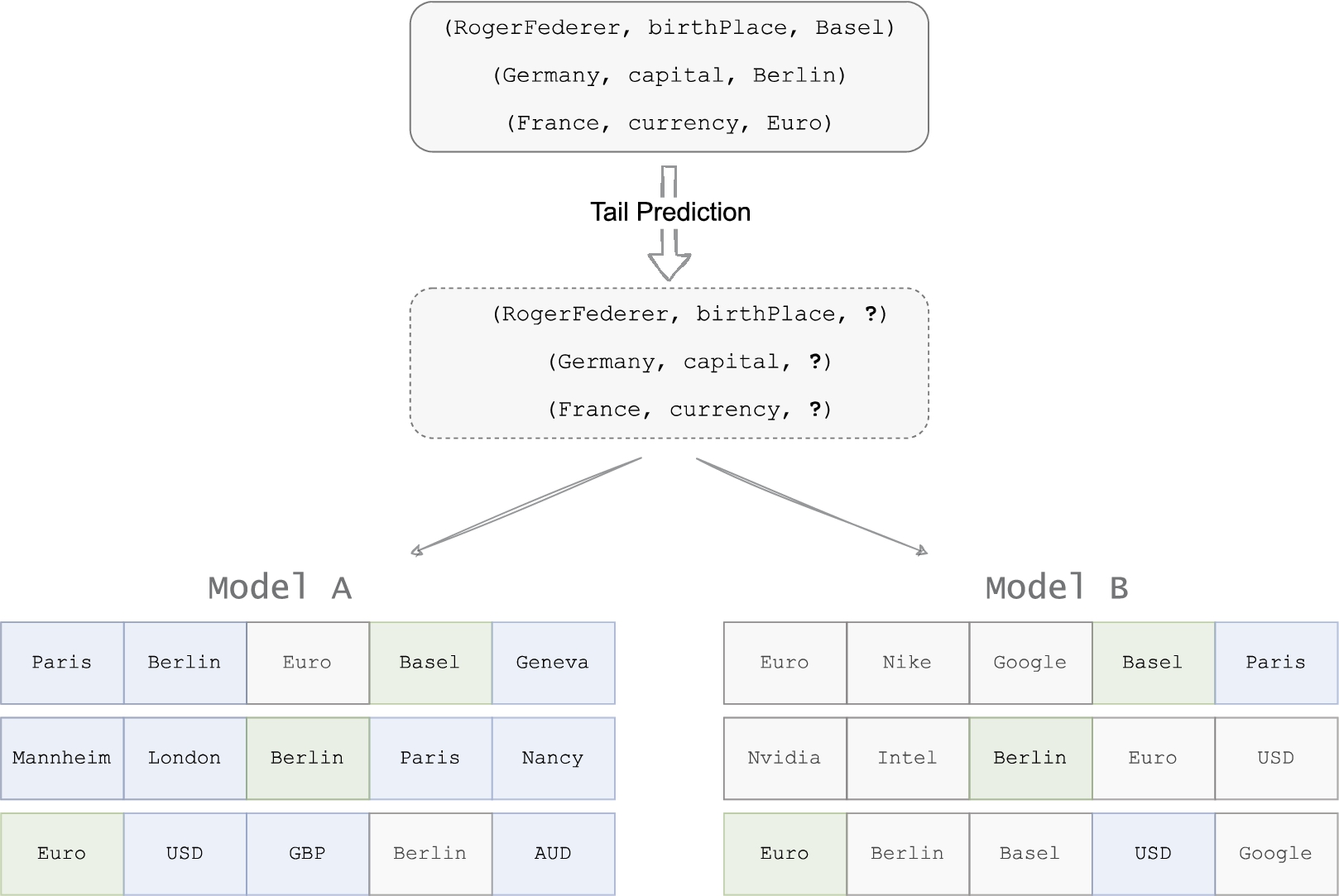
Motivating example. Tail prediction is performed for the three test triples contained in the upper insert. Model A and Model B output scores for each possible entity and only the top-five ranked tail candidates are depicted here. Model A and Model B have the same Hits@1, Hits@3 and Hits@5 values. But Model A has better semantic capabilities. Green, blue and white cells respectively denote the ground-truth entity, entities other than the ground-truth and semantically valid, and entities other than the ground-truth and semantically invalid.
The traditional evaluation of KGEMs solely based on rank-based metrics can be flawed for several reasons. First, KGEMs benchmarked on the same test sets can exhibit very similar results. Using only rank-based metrics, the final choice only depends on the best achieved MRR and/or Hits@K. This raises the questions whether the chosen model is actually the best one, or whether its slight superiority over other KGEMs can be due to other factors such as better hyperparameter tuning or better modeling of a relational pattern highly present in the test set. Moreover, using only rank-based metrics does not provide the full picture of KGEM quality for the downstream LP task, as some dimensions of KGEMs are left unassessed (see Section 2). In this work, contrary to the mainstream approach consisting in comparing KGEM performance exclusively in terms of rank-based metrics, the trained KGEMs are also evaluated in terms of Sem@K which measures the ability of KGEMs to predict semantically valid triples with respect to the domain and range of relations.
Measuring KGEMs semantic awareness with Sem@K
The standard LP evaluation protocol consists in reporting aggregated results, considering the rank-based metrics presented in Section 2.3. As mentioned above, these metrics only provide a partial picture of KGEM performance [5]. To give a more comprehensive assessment of KGEMs, we aim at assessing their semantic awareness using our proposed metric called Sem@K [20,21]. In [20], Sem@K was specifically defined for the recommendation task which was seen as predicting tails for a unique target relation. Sem@K was then extended in [21] to the more generic LP task, where not only tails but also heads are corrupted and all relations are considered. In this work, this original formalization for LP is presented in Section 4.1, and enriched to take into account schemaless KGs (Section 4.3), or KGs with a class hierarchy (Section 4.4). As a consequence, Sem@K comes in 3 different versions (respectively denoted Sem@K[base], Sem@K[ext], and Sem@K[wup]) so as to adapt to KG typology. These distinct versions and their adequacy regarding the KG at hand are summarized in Table 1 and further detailed below. In the following, when no suffix is provided, it is assumed that we are concerned with Sem@K in general, regardless of the actual version.
Typology of KGs and their respective adequacy for the presented Sem@K versions
Typology of KGs and their respective adequacy for the presented Sem@K versions
This version of Sem@K (Eq. (4)) accounts for the proportion of triples that are semantically valid in the first K top-scored triples:
A note on Sem@K, untyped entities, and the Open World Assumption
Traditional KGEM evaluation can be performed in all situations, regardless of whether entities are typed or whether the KG comes with a proper schema. When measuring the semantic capability of KGEMs – e.g. with Sem@K – some concerns arise. For instance, a fair question to ask is the following: how should untyped entities be considered? Indeed, in some KGs, some entities are left untyped. For example, in DBpedia the entity
Under the OWA, an untyped entity should not count in the calculation of Sem@K since it is not possible to determine whether this entity has no types or no known types. Although this seems to be a fair option, it raises a major issue: it makes possible to score different sets of entities with rank-based metrics and Sem@K, which is not desirable. If there are M untyped entities in an ordered list of ranked entities, Hits@K, MR and MRR are calculated regardless of this fact, i.e. still taking into account the M untyped entities. However, Sem@K cannot be calculated for these M untyped entities. As such, MR, MRR and Hits@K would be calculated on the original entity set, whereas Sem@K would be computed on a different set of entities. This issue would be even more acute in the case of Sem@1 when the first ranked entity is untyped: Hits@1 and Sem@1 would be calculated on two different entities, which is not acceptable. Consequently, one strategy consists in removing untyped entities from the evaluation protocol, both regarding rank-based and semantic-based metrics. By doing so, consistency is ensured in the ranked list of entities across rank-based and semantic metrics evaluation.
Sem@K[ext] for schemaless KGs
Not all KGs come with a proper schema, e.g. relations do not appear in any
Sem@K[wup]: A hierarchy-aware version of Sem@K
Sem@K as previously defined equally penalizes all entities that are not of the expected type. However, KGs may be equipped with a class hierarchy that, in turn, can support a more fine-grained penalty for entities depending on the distance or similarity between their type and the expected domain (resp. range) in this hierarchy. To illustrate, consider Fig. 3 that depicts a subset of the DBpedia ontology
To leverage such a semantic relatedness between concepts in Sem@K, the compatibility function can be adapted accordingly:
Several similarity measures σ have been proposed in the literature [33,34,52,53,76]. In this work, the Wu-Palmer similarity [76] (Eq. (7)) is used:
Considering the example in Fig. 3, using the Wu-Palmer score in the calculation of Sem@K, a head prediction of

Excerpt from the DBpedia class hierarchy.
Datasets
In order to draw reliable and general conclusions, a broad range of KGs are used in our experiments. They have been chosen due to their mainstream adoption in recent research works around KGEMs for LP and the fact that they have different characteristics (e.g. entities, relations, classes, presence of a class hierarchy). In this section, the schema-defined and schemaless KGs used in the experiments are detailed. Note that in our experiments, all the schema-defined KGs come with a class hierarchy inherited from either Freebase [6], DBpedia [2], YAGO [60], or
The statistics of the datasets FB15K237-ET, DB93K, YAGO3-37K and YAGO4-19K used in our experiments are provided in Table 2. As discussed in Section 4.2, to create an experimental evaluation setting as unbiased and flawless as possible, the schema-defined KGs used in the experiments are filtered to keep typed entities only. This way, Sem@K is calculated under the CWA.
SPARQL queries were fired against DBpedia as of November 9, 2022.
We built
Statistics of the schema-defined, hierarchical KGs used in the experiments
Another range of datasets used in these experiments do not come with an ontological schema. In particular, this means relations do not have a clearly-defined domain or range. Although Codex-S and Codex-M are based on the Wikidata schema which does possess property constraints linking subject types to value type constraints, we limit ourselves to KGs that represent this information with
Statistics of the schemaless KGs used in the experiments
Statistics of the schemaless KGs used in the experiments
In this work, the semantic awareness of the most popular semantically agnostic KGEMs is analyzed. More specifically, the translational models TransE [7] and TransH [74], the semantic matching models DistMult [81], ComplEx [66] and SimplE [29], and the convolutional models ConvE [13], ConvKB [42], R-GCN [57] and CompGCN [68] are considered. Note that in the analysis of the results in Section 6, a distinction will be made between pure convolutional KGEMs (ConvE, ConvKB) and GNNs (R-GCN, CompGCN). Although the latter have convolutional layers, they are able to capture long-range interactions between entities due to their ability to consider k-hop neighborhoods. The characteristics of the models used in our experiments are mentioned hereinafter and summarized in Table 4.
Summary of the KGEMs used in the experiments
Summary of the KGEMs used in the experiments
For the sake of comparisons, MRR, Hits@K and Sem@K all need to rely on the same code implementation. More specifically, for R-GCN7
In the following, we perform an extensive analysis of the results obtained using the aforedescribed KGEMs and KGs. For the sake of clarity, the complete range of tables and plots are placed in Appendix B and C, respectively. When necessary to support our claim, some of them are duplicated in the body text.
Semantic awareness of KGEMs
This section draws on the Sem@K values (see Tables 8 and 9) achieved at the best epoch in terms of MRR to provide an analysis of the semantic awareness of state-of-the-art KGEMs. In other words, for such models we only consider a snapshot of their best epochs in terms of rank-based metrics.
A major finding is that models performing well with respect to rank-based metrics are not necessarily the most competitive when it comes to their semantic capabilities. On YAGO3-37K (see Table 5) for instance, ConvE showcases impressive MRR and Hits@K values. However, it is far from being the best KGEM in terms of Sem@K, as it is outperformed by CompGCN, R-GCN and all translational models.

From a coarse-grained viewpoint, conclusions about the relative superiority of models with the distinct consideration of rank-based metrics and semantic awareness can be generalized at the level of models families. For example, semantic matching models (DistMult, ComplEx, SimplE) globally achieve better MRR and Hits@K values while their semantic capabilities are in most cases lower than the ones of translational models (TransE, TransH) – see Table 8 and Table 9 for detailed results w.r.t. rank-based and semantic-oriented metrics. A condensed view of the comparison between MRR and Sem@10 is also reported in Fig. 4 and Fig. 5. The respective hierarchies of such models for the benchmarked schema-defined and schemaless KGs are depicted in Fig. 6 and Fig. 7, respectively. It is clearly visible that KGEMs are grouped by family. In particular, GNNs and translational models showcase very promising semantic capabilities. GNNs are almost always the best regarding Sem@K[ext] values – not only for schemaless KGs (Fig. 7), but also for schema-defined KGs (see Table 8 for full results, and Fig. 4 for a quick glimpse). This means GNNs are more capable of predicting entities that have been observed as head (resp. tail) of a given relation. Translational models are very competitive in terms of Sem@K[base]. In Fig. 6, we clearly see that they consistently rank among the best performing models regarding Sem@K[base]. Interestingly, the semantic matching models DistMult, ComplEx and SimplE perform relatively poorly. This observation holds regardless of the nature of the KG, as they systematically rank among the worst performing models for schema-defined (Fig. 6) and schemaless (Fig. 7) KGs.
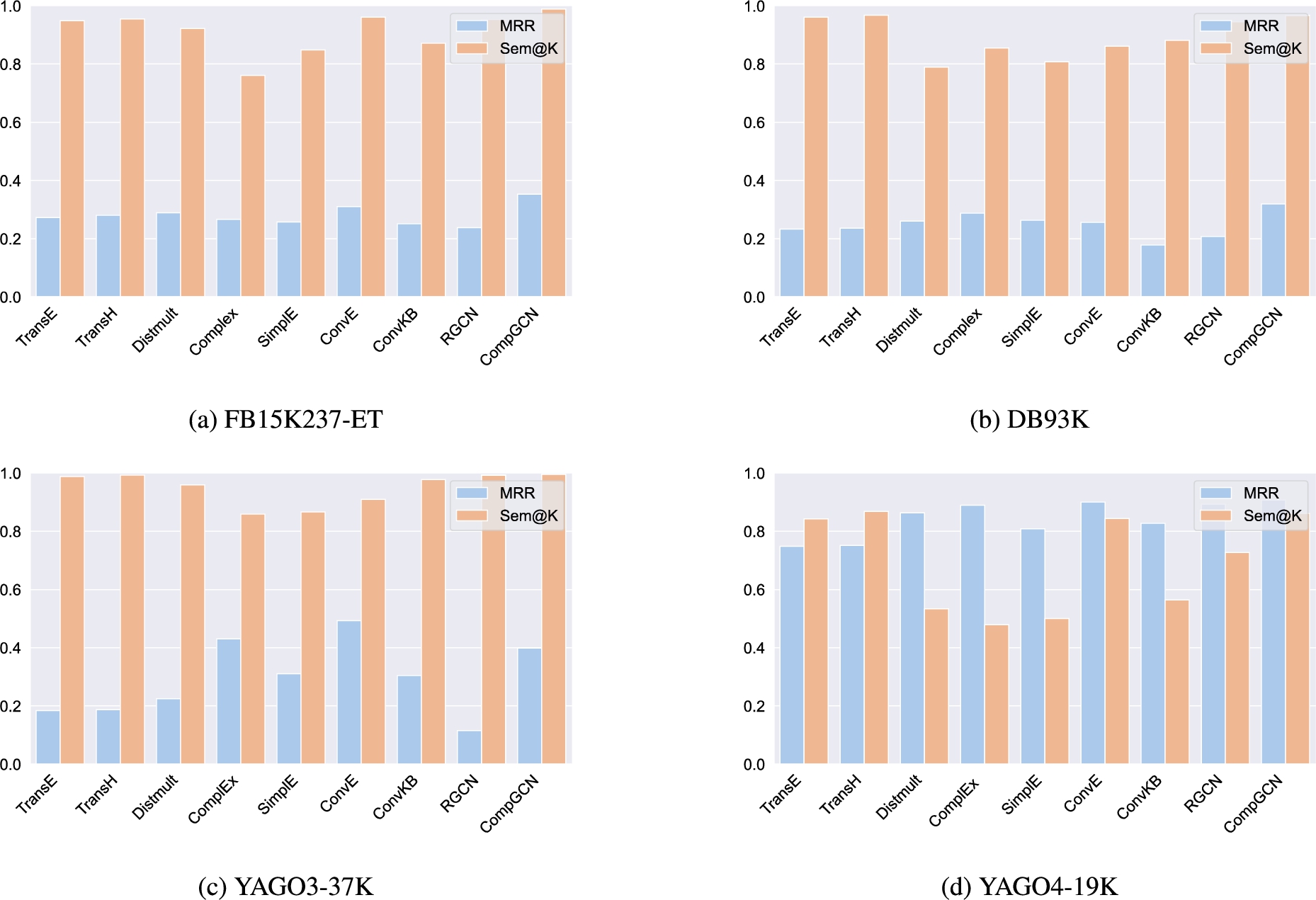
MRR and Sem@10 results achieved at the best epoch in terms of MRR for each model and on each schema-defined dataset.
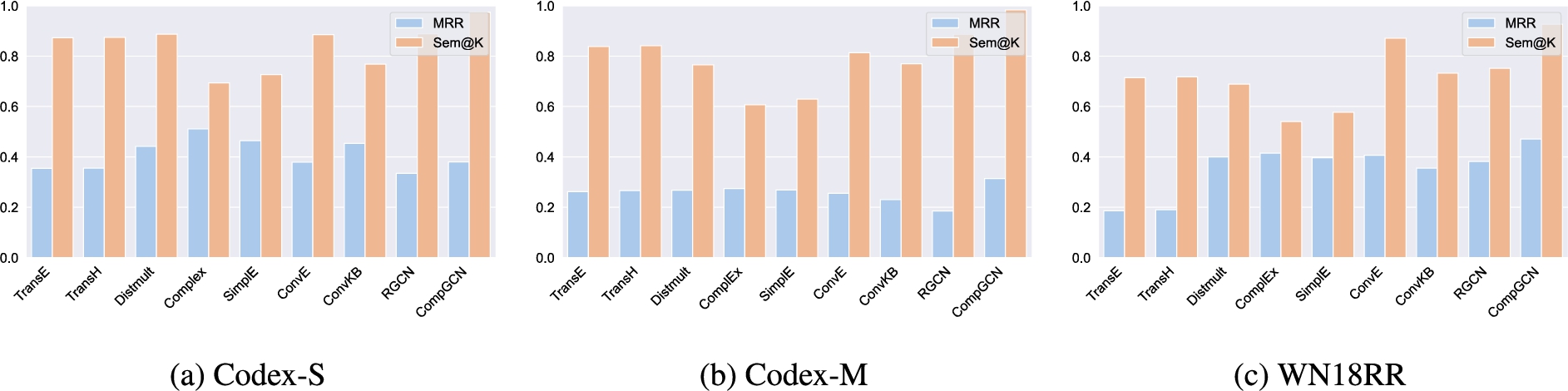
MRR and Sem@10 results achieved at the best epoch in terms of MRR for each model and on each schemaless dataset.

Sem@K[base] comparisons between KGEMs on the 4 benchmarked schema-defined KGs. Colors indicate the family of models: blue, purple, green, and yellow cells denote GNNs, translational, convolutional, and semantic matching models, respectively. Regarding Sem@K, the relative hierarchy of models is consistent across KGs and we can clearly see that KGEMs are grouped by families of models.
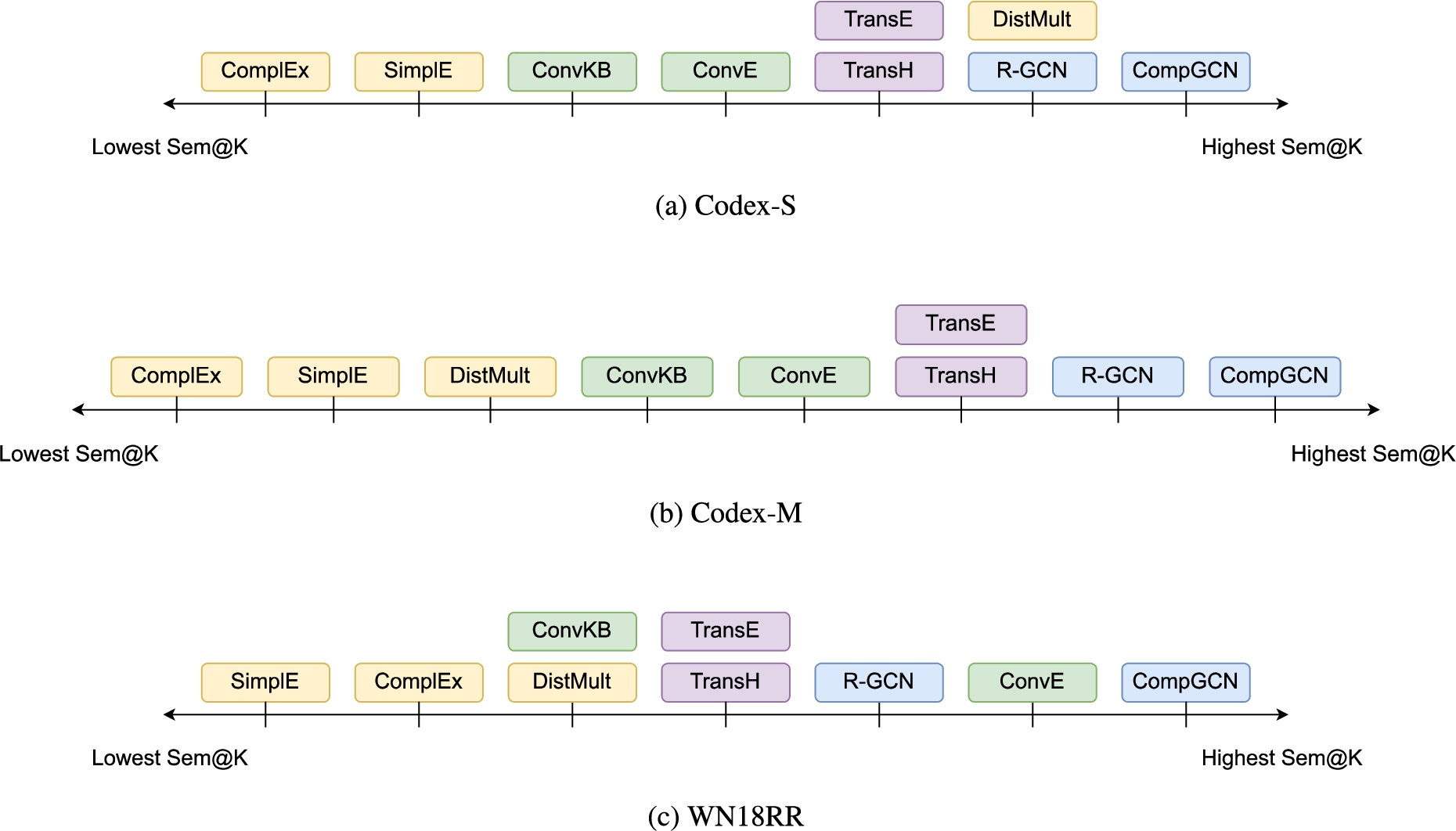
Sem@K[ext] comparisons between KGEMs on the 3 benchmarked schemaless KGs. Colors indicate the family of models: blue, purple, green, and yellow cells denote GNNs, translational, convolutional, and semantic matching models, respectively. Regarding Sem@K, the relative hierarchy of models is consistent across KGs and we can clearly see that KGEMs are grouped by families of models.
Therefore, it seems that translational models are better able at recovering the semantics of entities and relations to properly predict entities that are in the domain (resp. range) of a given relation, while semantic matching models might sometimes be better at predicting entities already observed in the domain (resp. range) of a given relation (e.g. DistMult reaches very high Sem@K[ext] values on Codex-S, as evidenced in Fig. 7a). In cases when translational and semantic matching models provide similar results in terms of rank-based metrics, the nature of the dataset at hand – whether it is schema-defined or schemaless – might thus strongly influence the final choice of a KGEM.
Interestingly, CompGCN which is by far the most recent and sophisticated model used in our experiments, outperforms all the other models in terms of semantic awareness as, with very limited exceptions, it is the best in terms of Sem@K[base], Sem@K[ext] and Sem@K[wup]. In addition, it should be noted that R-GCN provides satisfying results as well. Except in a very few cases (e.g. outperformed by ComplEx on Codex-S and WN18RR in terms of Sem@1), R-GCN showcases better semantic awareness than semantic matching models. Most of the time, R-GCN also provides comparable or even higher semantic capabilities than translational models. In particular, Sem@K values achieved with R-GCN are similar to the ones achieved with TransE and TransH (e.g. on FB15K237-ET and YAGO3-37K, see Tables 8a and 8c) while the latter models are actually outperformed by R-GCN in terms of Sem@K[ext]. It appears clearly on Codex-M and WN18RR (Tables 9b and 9c), although the conclusion holds for all datasets.
Our experimental results suggest that the structure of GNNs seems to be able to encode the latent semantics of the entities and relations of the graph. This ability may be attributed to the fact that, contrary to translational models which only model the local neighborhood of each triple, GNNs update entity embeddings (and relation embeddings in the case of CompGCN) based on the information found in the extended, h-hop neighborhood of the central node. While translational and semantic matching models treat each triple independently, GNNs model interactions between entities on a large range of semantic relations. It is likely that this extended neighborhood comprises signals or patterns that help the model infer the classes of entities, thus providing very promising semantic capabilities in all experimental conditions.
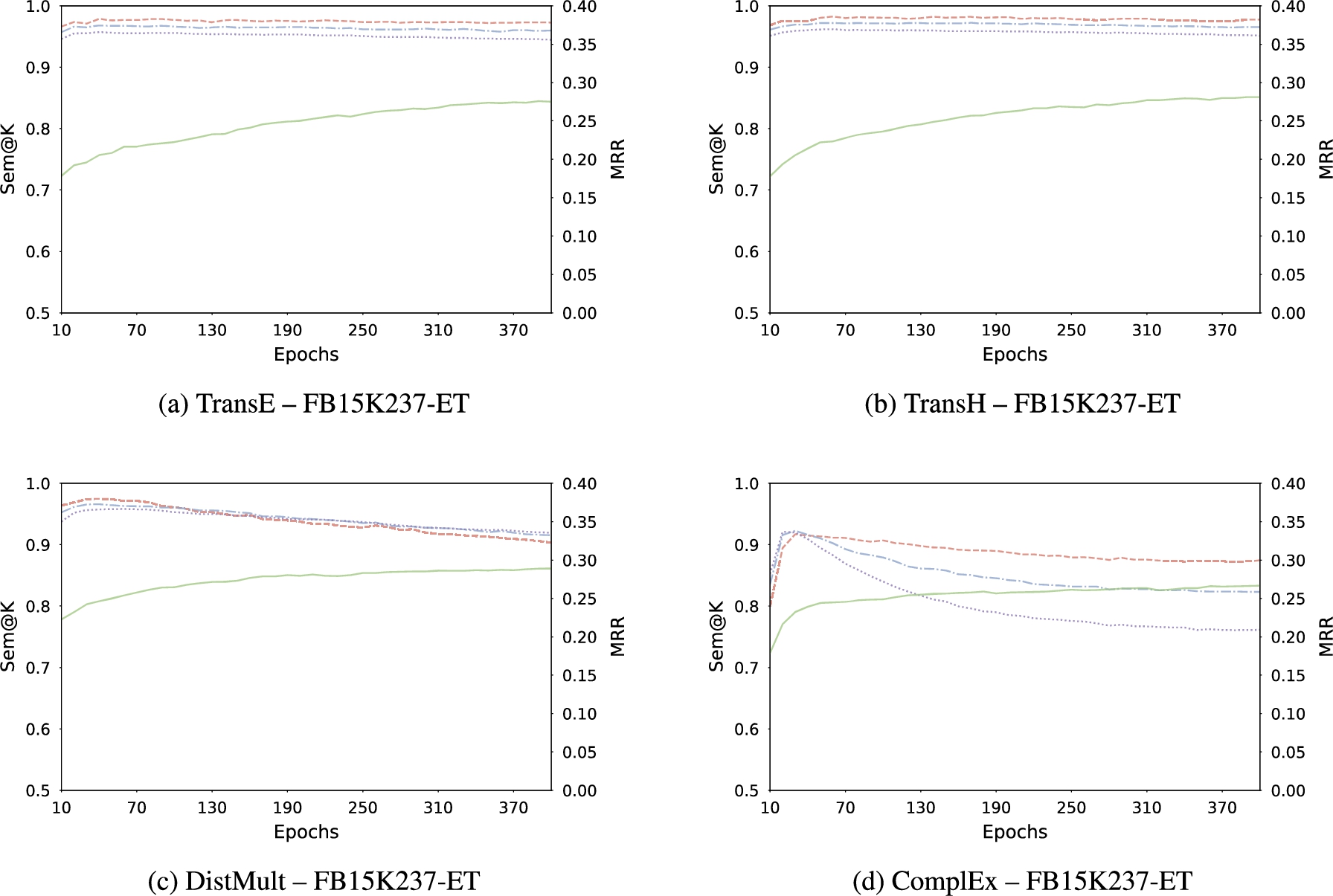
Evolution of MRR (green —), Sem@1 (red - -), Sem@3 (blue - · -), and Sem@10 (purple
For certain models, rank-based metrics performance and semantic capabilities improve jointly. For others, the enhancement of their performance in terms of rank-based metrics comes at the expense of their semantic awareness. Interestingly, trends emerge relatively to families of models. First, we observe that a trade-off exists for semantic matching models. Results are particularly striking on FB15K237-ET (see Fig. 8), where it is obvious that after reaching the best Sem@K values after a few epochs, Sem@K values of DistMult and ComplEx quickly drop while MRR continues rising. Conversely, translational models are more robust to Sem@K degradation throughout the epochs. Even though the best achieved Sem@K values are also reported in the very first epochs, once these values are reached they remain stable for the remaining epochs of training. This might be due to the geometric nature of such KGEMs, which will organize the representation space so as to
Plots of the joint evolution of MRR and Sem@K values show that most of the KGEMs reaches their best Sem@K values after a few number of epochs. This means that predictions get semantically valid in the early stages of training. As previously mentioned, Sem@K then usually start to decrease, as it has been noted for semantic matching models in particular. To this respect, an excerpt of the head and tail predictions of DistMult on YAGO3-37K is depicted in Fig. 9. Even though the ground-truth entity does not show up in neither the head nor the tail top-K list, we clearly see that after only 30 epochs of training, predictions made by DistMult are more meaningful than after 400 epochs of training. This relative trade-off between making semantically valid predictions and predictions that comprise the ground-truth entity higher in the top-K list calls for finding a compromise in terms of training. The LP task is usually addressed in terms of rank-based metrics only, hence the choice of performing more and more training epochs so as to find the optimal KGEM in terms of MRR and Hits@K. However, as discussed in the present work, adding training steps may improve KGEM performance at the expense of its semantic awareness. In many cases, rank-based metrics values only slightly increase, whereas Sem@K values drastically drop. For instance, comparing MRR vs. Sem@K evolution of DistMult on FB15K237-ET (Fig. 10c), we clearly see that after a moderate number of epochs, any additional epoch of training only provides a very slight improvement in terms of MRR, while it is very detrimental to Sem@K values. Depending on the use case, such a decline in the semantic capabilities of the model is not desirable, and a compromise is to be found between training more to increase KGEM predictive performance and stopping training early enough so as not to deteriorate its semantic awareness too much.

Top-ten ranked entities for head and tail predictions at epochs 30 and 400 for a sample triple from YAGO3-37K. Green, blue and white cells respectively denote the ground-truth entity, entities other than the ground-truth and semantically valid, and entities other than the ground-truth and semantically invalid. In this case, semantic validity is based on the domain and range of the relation
As reported in Table 1, KGs based upon a schema and a class hierarchy are candidates for the computation of all the versions of Sem@K. For the schema-defined KGs used in our experiments, we choose to report values regarding all these metrics so as to enable multi-view comparisons across models. From Table 8 it can be clearly seen that the relative superiority of models is consistent throughout the different Sem@K definitions. From a higher perspective, this means that even for schema-defined KGs with a hierarchy class, Sem@K[ext] is already a good proxy. This may be a good option to only rely on the Sem@K[ext] whenever the computation of Sem@K[base] is too expensive, due to the entity type checking part. This is even more true for Sem@K[wup], which requires an additional step of semantic relatedness computation.
Discussion
Three major research questions have been formulated in Section 1. Based on the analysis presented in Section 6, we discuss each research question individually. We ultimately discuss the potential for further considerations of semantics into KGEMs.
RQ1: How semantic-aware agnostic KGEMs are?
From a coarse-grained viewpoint, we noted that KGEMs trained in an agnostic way prove capable of giving higher scores to semantically valid triples. However, disparities exist between models. Interestingly, these disparities seem to derive from the family of such models. Globally, translational models and GNNs – represented by R-GCN and CompGCN in this work – provide promising results. It appears that the two aforementioned families of KGEMs are better able than semantic matching models (DistMult, ComplEx, SimplE) at recovering the semantics of entities and relations to give higher score to semantically valid triples. In fact, semantic matching models are almost systematically the worst performing models in terms of semantic awareness. From a dynamic standpoint, it is worth noting the high semantic capabilities of KGEMs reached during the first epochs of training. In most cases, this is even during the first epochs that the optimal semantic awareness is attained.
RQ2: How KGEM semantic awareness’ evaluation should adapt to the typology of KGs?
Drawing on the initial version of Sem@K as presented in [21] – referred to herein as Sem@K[base] – an issue is quickly encountered when it comes to schemaless KGs, which do not contain any
RQ3: Does the evaluation of KGEM semantic awareness offers different conclusions on the relative superiority of some KGEMs?
A major finding is that models performing well with respect to rank-based metrics are not necessarily the most competitive regarding their semantic capabilities. We previously noted that translational models globally showcase better Sem@K values compared to semantic matching models. Considering MRR and Hits@K, the opposite conclusion is often drawn. Hence, the performance of KGEMs in terms of rank-based metrics is not indicative of their semantic capabilities. The only exception that might exist is for GNNs that perform well both in terms of rank-based metrics and semantic-oriented measures.
The answers provided to the research questions also lead to consider new matters. As evidenced in Table 8 and Table 9, some KGs are more challenging with regard to Sem@K results. Due to its tailored extraction strategy that purposedly favored difficult relations to feature in the validation and test sets, YAGO4-19K is the schema-defined KG with the lowest achieved Sem@K. This observation raises a deeper question: what characteristics of a KG make it inherently challenging for KGEMs to recover the semantics of entities and relations? An extensive study of the influence of KGs characteristics on the semantic capabilities of KGEMs would require to benchmark them on a broad set of KGs with varying dimensions, so as to determine those that are the most prevalent. Such characteristics can be the total number of relations, the average number of instances per class, or a combination of different factors. We leave this experimental study for future work.
Recall that this work is motivated by the possibility of going beyond a mere assessment of KGEM performance regarding rank-based metrics. We showed that these metrics only evaluate one aspect of such models, somehow providing a partial view on the quality of KGEMs. Our proposal for further assessing KGEM semantic capabilities aims at diving deeper into their predictive expressiveness and measuring to what extent their predictions are semantically valid. However, this second evaluation component does not shed full light on the respective KGEM peculiarities. Other evaluation components may be added, such as the storage and computational requirements of KGEMs [51,69] and the environmental impact of their training and testing procedure [50]. Furthermore, the explainability of KGEMs is another dimension that deserves great attention [55,83].
Towards further considerations of semantics in knowledge graph embeddings models
The Sem@K metric presented in this work allows for a more comprehensive evaluation of KGEMs. Based on domains and ranges of relations, Sem@K assesses to what extent the predictions of a model are semantically valid. The present work constitutes one of several stepping stones toward the further consideration of ontological and semantic information in KGEM design and evaluation.
It should be noted that due to the only consideration of domains and ranges, Sem@K cannot indicate whether predictions are logically consistent with other constraints posed by the ontology. This is in contrast with Inc@K presented in [23] that takes a broader set of ontological axioms into account. However, Inc@K and Sem@K intrinsically assess distinct dimensions of predictions. While the former is concerned with the logical consistency of predictions, the latter focuses on whether these predictions are semantically valid. For instance, an ontology can specify that
KGEMs evaluated in this work are all agnostic to ontological information in their design. However, some models that consider or ensure specific ontological or logical properties exist. For example, HAKE [84] is constructed with the purpose of preserving hierarchies, Logic Tensor Networks [3] are designed to ensure logical reasoning, and the training of TransOWL and TransROWL [11] is enriched with additional triples deduced from, e.g., inverse predicates or equivalent classes. Because of the integration of semantic information in their design or training, one could wonder if they present improved semantic awareness compared to agnostic models. Additionally, KGEMs can also be used to predict triples that represent class instantiations. A possible extension of the present work thus consists in studying whether predicted links and class instantiations are consistent and lead to increased Sem@K values. This would further qualify and highlight the semantic awareness and the consistency of predictions of KGEMs. We leave these questions for future work.
Conclusion
In this work, we consider the link prediction task and extend our previously introduced Sem@K metric to measure the ability of KGEMs to assign higher scores to triples that are semantically valid. In particular, to adapt to different types of KGs (e.g., schemaless, class hierarchy), we introduce Sem@K[base], Sem@K[ext], or Sem@K[wup]. Compared with the traditional evaluation approach that solely relies on rank-based metrics, we show that the evaluation procedure is enhanced with the addition of semantic-oriented metrics that bring an additional perspective on KGEM quality. Our experiments with different types of KGs highlight that there is no clear correlation between the performance of KGEMs in terms of traditional rank-based metrics versus their performance regarding semantic-oriented ones. In some cases, however, a trade-off does exist. Consequently, this calls for monitoring KGEM training under more scrutiny. Our experiments also point out that most of the conclusions that have been drawn actually hold at the level of families of models.
In future work, we will conduct experiments considering a broader array of KGEM families (e.g., KGEMs that include semantics) and propose evaluation metrics that consider additional and more expressive ontological constraints.
Footnotes
Acknowledgements
This work is supported by the AILES PIA3 project (see
Hyperparameters
Results achieved with the best reported hyperparameters
Evolution of MRR and Sem@ K values with respect to the number of epochs
The evolution of MRR and Sem@K values with respect to the number of epochs is presented in Fig. 10, 11, 12, 13, 14, 15, and 16. For equity and clarity sakes, we choose to present 2 KGEMs for each family of model (translational models, semantic matching models, CNNs, and GNNs). Regarding semantic matching models, DistMult and ComplEx are chosen, as the evolution of their MRR and Sem@K values is less erratic than SimplE. The evolution of MRR and Sem@K values for SimplE are made available on the GitHub repository of the datasets.10