
Abstract
In the materials design domain, much of the data from materials calculations is stored in different heterogeneous databases with different data and access models. Therefore, accessing and integrating data from different sources is challenging. As ontology-based access and integration alleviates these issues, in this paper we address data access and interoperability for computational materials databases by developing the Materials Design Ontology. This ontology is inspired by and guided by the OPTIMADE effort that aims to make materials databases interoperable and includes many of the data providers in computational materials science. In this paper, first, we describe the development and the content of the Materials Design Ontology. Then, we use a topic model-based approach to propose additional candidate concepts for the ontology. Finally, we show the use of the Materials Design Ontology by a proof-of-concept implementation of a data access and integration system for materials databases based on the ontology.1
This paper is an extension of (In The Semantic Web – ISWC 2020 – 19th International Semantic Web Conference, Proceedings, Part II (2000) 212–227 Springer) with results from (In ESWC Workshop on Domain Ontologies for Research Data Management in Industry Commons of Materials and Manufacturing2021 1–11) and currently unpublished results regarding an application using the ontology.
Keywords
Introduction
Materials design and materials informatics is central for technological progress, not the least in the green engineering domain. Many traditional materials contain toxic or critical raw materials, whose use should be avoided or eliminated. Also, there is an urgent need for new environmentally friendly energy technologies. The design of viable materials with the right properties is a key component for enabling such technologies [21]. Computational materials design has contributed to recent progress in fields relevant to the move to eco-friendly solutions such as battery technologies and solar cells; other relevant examples of materials design for novel technologies include thermoelectrics and magnetic transport [10,13,31].
The space of potentially useful materials yet to be discovered – the so-called ‘chemical white space’ – is immense. The possible combinations of, say, up to six different elements, constitute many billions. The space is further extended by possibilities of different phases, low-dimensional systems, nanostructuring, and so forth, which adds several orders of magnitude. This space was traditionally explored by experimental techniques, i.e., materials synthesis and subsequent experimental characterization. Parsing and searching the full space of possibilities this way is, however, hardly practical. Recent advances in condensed matter theory and materials modeling make it possible to generate reliable materials data by means of computer simulations based on quantum mechanics [37]. High-throughput simulations combined with machine learning can speed up progress significantly and also help to break out of local optima in composition space to reveal unexpected solutions and new chemistries [25]. The progress brought by the combination of machine learning models and databases of materials data, is now so rapid that it can be discussed as a lead-up to a singularity for the field of materials design [6].
This development has led to several global efforts to assemble and curate databases that combine experimentally known and computationally predicted materials properties, along with a desire to make them interoperable [33]. These efforts have collectively been referred to as the Materials Genome Initiative (
Even when a new material has been invented and synthesized in a lab, much work remains before it can be deployed. Production methods allowing manufacturing the material at large scale in a cost effective manner need to be developed, and integration of the material into the production must be realized. Furthermore, life-cycle aspects of the material need to be assessed. Today, this post-invention process takes typically about two decades [31,43]. Shortening this time is in itself an important strategic goal, which could be realized with the help of an integrated informatics approach [31].
It is clear that materials data, experimental as well as simulated, has the potential to speed up progress significantly in many steps in the chain starting with materials discovery, all the way to marketable product. However, the data needs to be suitably organized and easily accessible, which in practice is highly nontrivial to achieve. It requires a multidisciplinary effort and the various conventions and norms in use need to be integrated. Materials data is highly heterogeneous [43].
In this paper we address the data access and interoperability issue by developing an ontology suitable for the OPTIMADE (Open Databases Integration for Materials Design,
The paper is organized as follows. In Section 3 we describe the development of MDO while the ontology itself is described in Section 4. In Section 5 we propose new concepts for an extension of MDO. Currently, these concepts are under discussion. In Section 6 we show the use of MDO in our MDO proof-of-concept implementation of a data access and integration system for materials science databases. The paper concludes in Section 7. We start with some background in Section 2.
Background
Ontologies in materials science
A number of ontologies in materials science have been developed. To find these ontologies, we used services such as BioPortal (
Characteristics of some materials ontologies
Characteristics of some materials ontologies
There are a number of top-level ontologies that are interesting for conceptualization in the materials science domain. For instance, these top-level ontologies commonly contain definitions relevant to continuants and occurrents. The former can represent materials objects that endure over time, and undergo a variety of changes, while the latter can represent events that unfold over time, and manifest as changes in continuants [9]. Examples of such top-level ontologies include EMMO (earlier known as European Materials & Modelling Ontology, and recently renamed Elementary Multiperspective Material Ontology,
Most ontologies, however, are domain ontologies, for which we show some characteristics from the knowledge representation and the materials science perspectives in Table 1. These ontologies focus on specific sub-domains of the materials field (Domain in Table 1) and have been developed with a specific use in mind (Application Scenario in Table 1). MatOnto [12], based on DOLCE, aims to represent structured knowledge, properties and processing steps relevant to materials for data exchange, reuse and integration. MatOWL [55] is extracted from MatML schema data to enable ontology-based data access. MatML ([32],
From the knowledge representation perspective, the basic terms defined in materials ontologies involve materials, properties, performance, and processing in specific sub-domains. All presented ontologies use OWL as a representation language (Language in Table 1). The number of OWL classes ranges from a few to several thousands (Ontology Metrics in Table 1). Some ontologies have more concepts than relations (e.g., MatOnto, Materials Ontology, NanoParticle Ontology, MMOY and EMMO), while some have many more relations (e.g., MDO). Several ontologies are developed in a modular fashion (Modularity in Table 1).
In Section 3 we describe the development of the Materials Design Ontology (MDO). Although, we could have used a more modern approach such as the eXtreme Design methodology [46] or its extension that integrates debugging [18], as our initial ontology was expected to be of a smaller size and given our earlier experience with the NeOn methodology for ontology engineering, we decided to use NeOn.
NeOn [51] is a methodology for ontology engineering that proposes nine scenarios which commonly occur, including Scenario 1: From Specification to Implementation, Scenario 2: Reusing and re-engineering non-ontological resources, Scenario 3: Reusing ontological resources, Scenario 4: Reusing and re-engineering ontological resources, Scenario 5: Reusing and merging ontological resources, Scenario 6: Reusing, merging, and re-engineering ontological resources, Scenario 7: Reusing ontology design patterns (ODPs), Scenario 8: Restructuring ontological resources, and Scenario 9: Localizing ontological resources. Depending on different background knowledge resources and purposes of the ontology, developers can make use of different scenarios or combinations of the scenarios. Scenario 1 is necessary in any ontology development and should always be included. The detailed use of NeOn for the development of MDO is described in Section 3.
Further, we also used two tools for detecting defects in the ontology during the development. The first tool, OntOlogy Pitfall Scanner! (OOPS!, [45]), helps to detect some of the most common pitfalls appearing within ontology development. The second tool, Repairing Ontological Structure Environment (RepOSE, [34]), allows to debug an ontology and proposes additional knowledge that could be interesting to add to the ontology.
Ontology extension
In Section 5 we describe work on generating new concepts that may be added to MDO. The new concepts are, however, not yet included in the public version of MDO as discussions regarding the scope and the use of the extension are ongoing.

Approach: the upper part of the figure shows the creation of a phrase-based topic model with unstructured text as input and phrases and topics as output. The lower part shows the formal topical concept analysis with as input topics and as output a topical concept lattice. In both parts a domain expert validates and interprets the results [39].
We used the phrase-based topic model generation approach we presented in [39], shown in Fig. 1. A topic model is a statistical model for discovering the abstract “topics” that occur in a collection of documents. The topics are often represented as lists of words or phrases. Given a corpus of documents related to the domain of interest and the number of requested topics, a phrase-based topic model is created using an extended version of the ToPMine [20] system as presented in [1].
First, frequent contiguous phrases are mined, which consists of collecting aggregate counts for all contiguous words satisfying a user-defined minimum support threshold. Given a minimum support threshold min_support, we say that phrases that occur at least min_support times are frequent phrases. The ToPMine system identifies frequent phrases of a length up to a maximum length that is given as an input parameter. Note that ToPMine does not generate all frequent phrases but uses a method based on partitioning documents and using a significance score for deciding which words likely belong together, to produce high-quality frequent phrases. The use of the significance score has, for instance, the effect that frequent sub-phrases of frequent phrases are not counted. In our extended version we also introduce a user-defined maximum threshold for word occurrences to, if so desired, remove very general words. Then the documents are segmented based on the frequent phrases. Further, an agglomerative phrase construction algorithm merges the frequent phrases guided by a significance score.
After this phrase mining, the system performs topic modeling by computing representations of latent topics in the documents. Topics are generated using a variant of Latent Dirichlet Allocation (LDA) [8], called PhraseLDA, that deals with phrases, rather than words. Essentially, topics can be seen as a probability distribution over words or phrases.
The phrases as well as the topics are suggestions that a domain expert should validate or interpret and relate to concepts in the ontology. Based on the validations and interpretations of the domain expert, concepts and axioms are added to the ontology. To help a domain expert with the validation, we implemented a tool of which an early version is described in [2]. The current tool deals with phrases, but not yet with topics. It is available at

Tool – Phrases tab.

Tool – From Phrase to Concept tab.
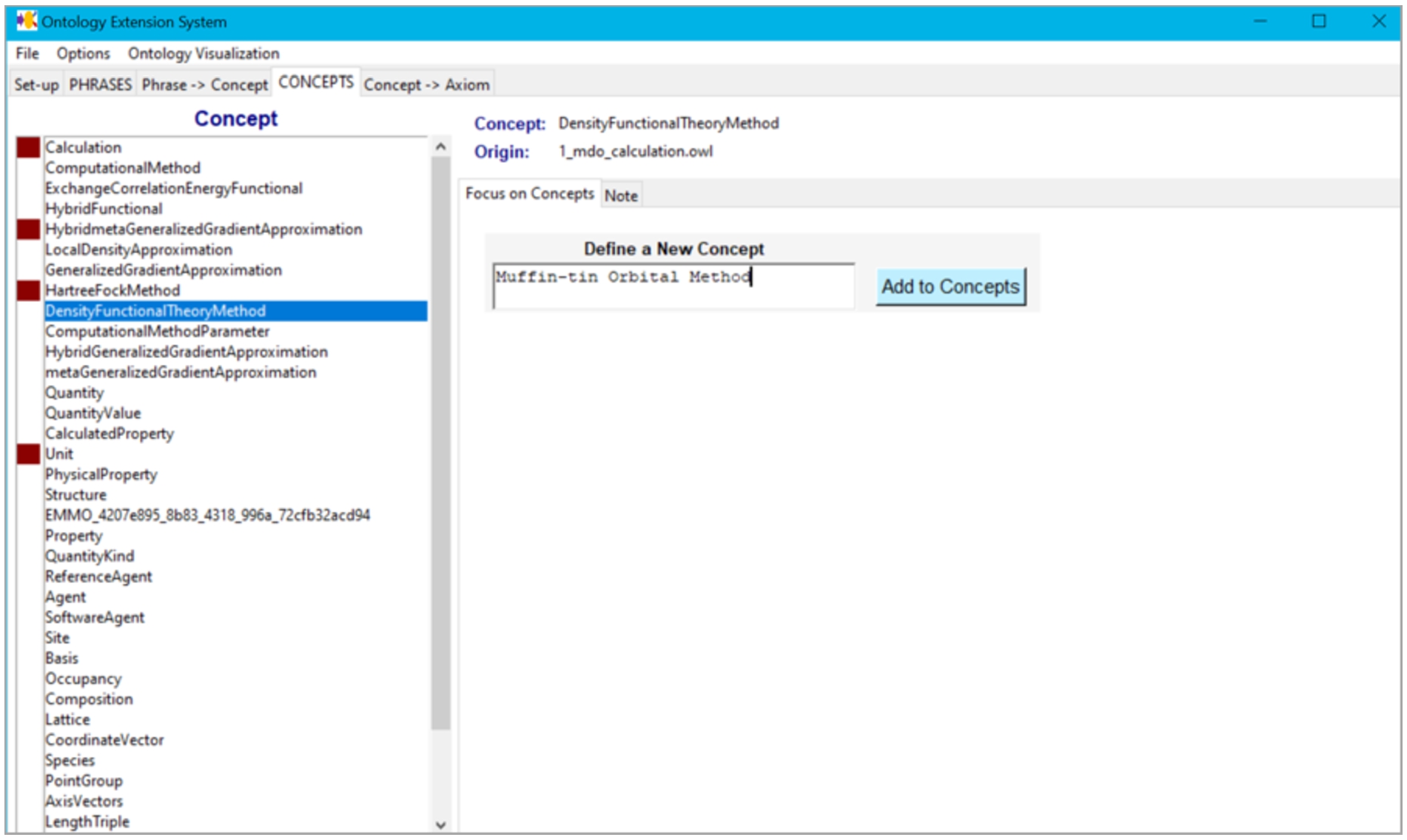
Tool – Concepts tab.

Tool – From Concept to Axiom tab.
The development of MDO followed the NeOn ontology engineering methodology [51]. We focused on applying scenario 1 (From Specification to Implementation), scenario 2 (Reusing and re-engineering non-ontological resources), scenario 3 (Reusing ontological resources) and scenario 8 (Restructuring ontological resources). We did not re-engineer or merge ontological resources, i.e., scenarios 4–6 (but did reuse some concepts from other ontologies) and did not translate MDO into another natural language (scenario 9). Further, we did not use existing ontology design patterns (scenario 7), as the only one we are aware of in the materials science field is about materials transformation [53] that is not covered by MDO.
We used OWL2 DL as the representation language for MDO. During the whole process, two knowledge engineers, and one domain expert from the materials design domain were involved. In the remainder of this section, we introduce the key aspects of the development of MDO.
Requirements analysis
During this step, we clarified the requirements by proposing Use Cases (UC), Competency Questions (CQ) and additional restrictions (AR).
The use cases, which were identified through literature study and discussion between the domain expert and the knowledge engineers based on experience with the development of OPTIMADE and the use of materials science databases, are listed below.
UC1: MDO will be used for representing knowledge in basic materials science such as solid-state physics and condensed matter theory.
UC2: MDO will be used for representing materials calculation and standardizing the publication of the materials calculation data.
UC3: MDO will be used as a standard to improve the interoperability among heterogeneous databases in the materials design domain.
UC4: MDO will be mapped to OPTIMADE’s schema to improve OPTIMADE’s search functionality.
The competency questions are based on discussions with domain experts and contain questions that the databases currently can answer as well as questions that experts would want to ask the databases. For instance, CQ1, CQ2, CQ6, CQ7, CQ8 and CQ9 cannot be asked explicitly through the database APIs, although the original downloadable data contains the answers.
CQ1: What are the calculated properties and their values produced by a calculation?
CQ2: What are the input and output structures of a materials calculation?
CQ3: What is the space group type of a structure?
CQ4: What is the lattice type of a structure?
CQ5: What is the chemical formula of a structure?
CQ6: For a series of calculations, what are the compositions of materials with a specific range of a calculated property (e.g., band gap)?
CQ7: For a specific material and a given range of a calculated property (e.g., band gap), what is the lattice type of the structure?
CQ8: For a specific material and an expected lattice type of output structure, what are the values of calculated properties of the calculations?
CQ9: What is the computational method used in a materials calculation?
CQ10: What is the value for a specific parameter (e.g., cutoff energy) of the method used for the calculation?
CQ11: Which software produced the result of a calculation?
CQ12: Who are the authors of the calculation?
CQ13: When was the calculation data published to the database?
Further, we proposed a list of additional restrictions that help in defining concepts.
AR1: A property can relate to a structure. AR2: A calculation has exactly one corresponding computational method. AR3: A structure corresponds to one specific space group. AR4: A calculation is performed by some software programs or codes. AR5: A structure is a part of some materials. AR6: A structure and a property can be published by references which could be databases or publications. AR7: A calculation can take some structures as input. AR8: A calculation can take some properties as input.
Reusing and re-engineering non-ontological resources
To obtain the knowledge for building the ontology, we followed two steps: (1) the collection and analysis of non-ontological resources that are relevant to the materials design domain, and (2) discussions with the domain expert regarding the concepts and relationships to be modeled in the ontology. The collection of non-ontological resources comes from: (1) the dictionaries of the Crystallographic Information Framework (CIF,
Connection and integration of existing ontologies
We reuse the concepts ‘Agent’ and ‘SoftwareAgent’ from PROV-O [36]. In terms of representation of units we reuse the ‘Quantity’, ‘QuantityValue’, ‘QuantityKind’ and ‘Unit’ concepts from QUDT (Quantities, Units, Dimensions and Data Types Ontologies) [26]. We use the metadata terms from the Dublin Core Metadata Initiative (DCMI,
Description of MDO
MDO consists of one basic module, Core, and two domain-specific modules, Structure and Calculation, importing the Core module. In addition, the Provenance module, which also imports Core, models provenance information. In total, the OWL2 DL representation of the ontology contains 37 concepts, 32 object properties, and 32 data properties. Figure 6 shows an overview of the ontology. The ontology specification is also publicly accessible at w3id.org at
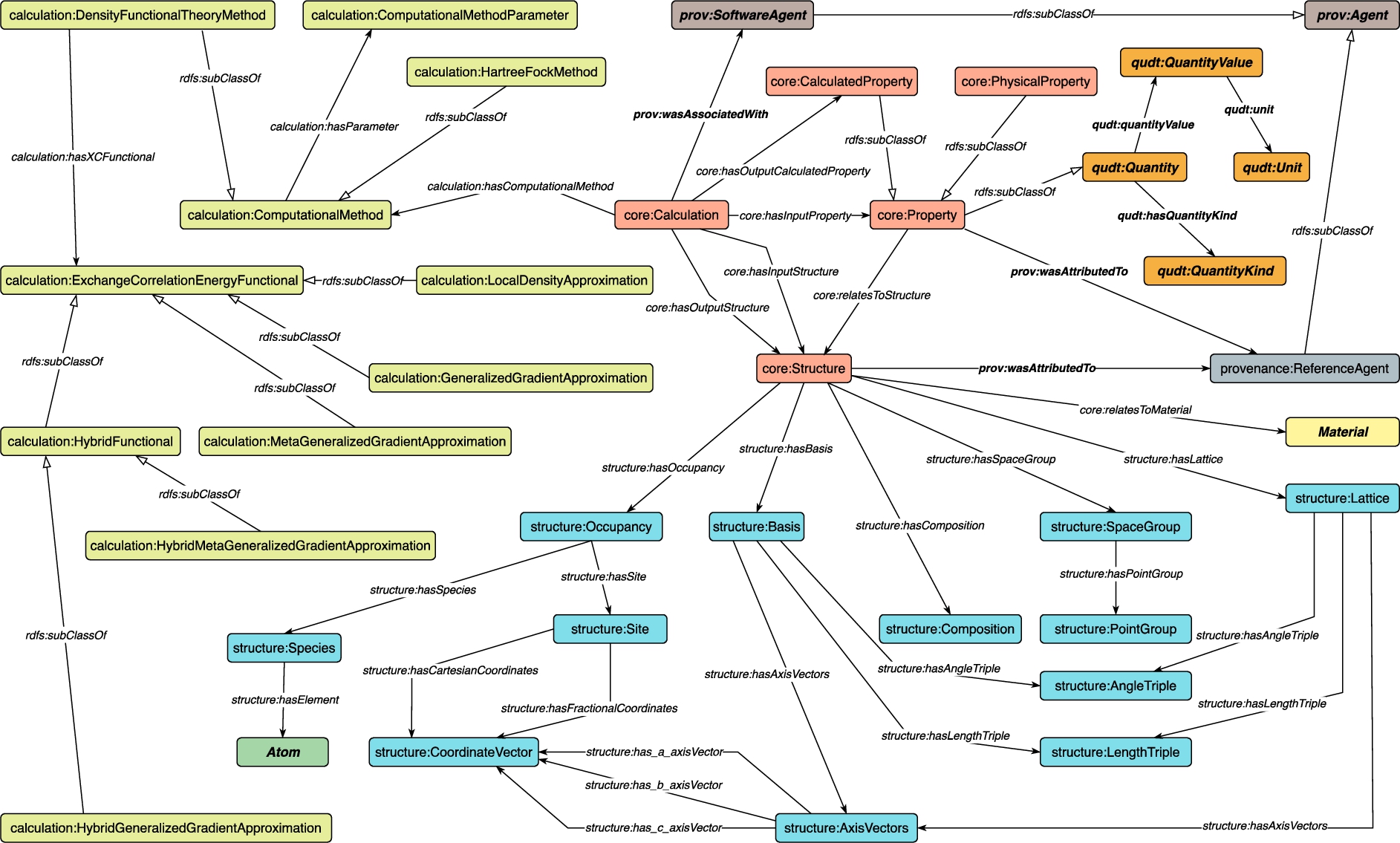
An overview of MDO.

Concepts and relations in the Core module.

Description logic axioms for the Core module.
The
It would be possible to extend MDO with a MeasuredProperty to represent the outcome of a specific experiment as a parallel concept to CalculatedProperty. However, since the current version of MDO does not aim to describe experiments, this was determined to be outside of its scope at the moment.
Properties are also related to structures (Core5). When a calculation is applied on materials structures, each calculation takes some structures and properties as input, and may output structures and calculated properties (Core6, Core7). Further, we define a concept Material and state that each structure is related to some material (Core8).
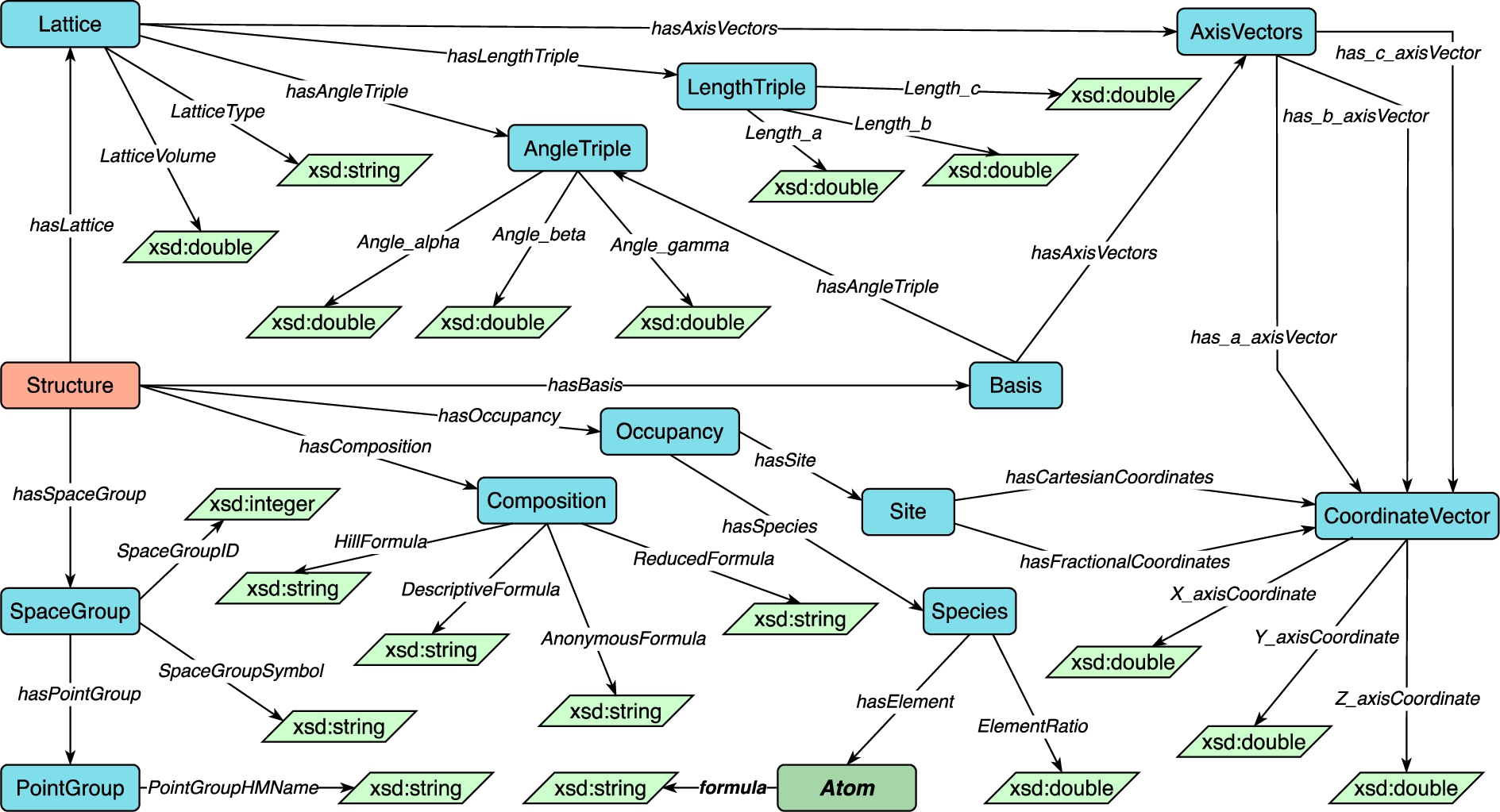
Concepts and relations in the Structure module.

Description logic axioms for the Structure module.
The
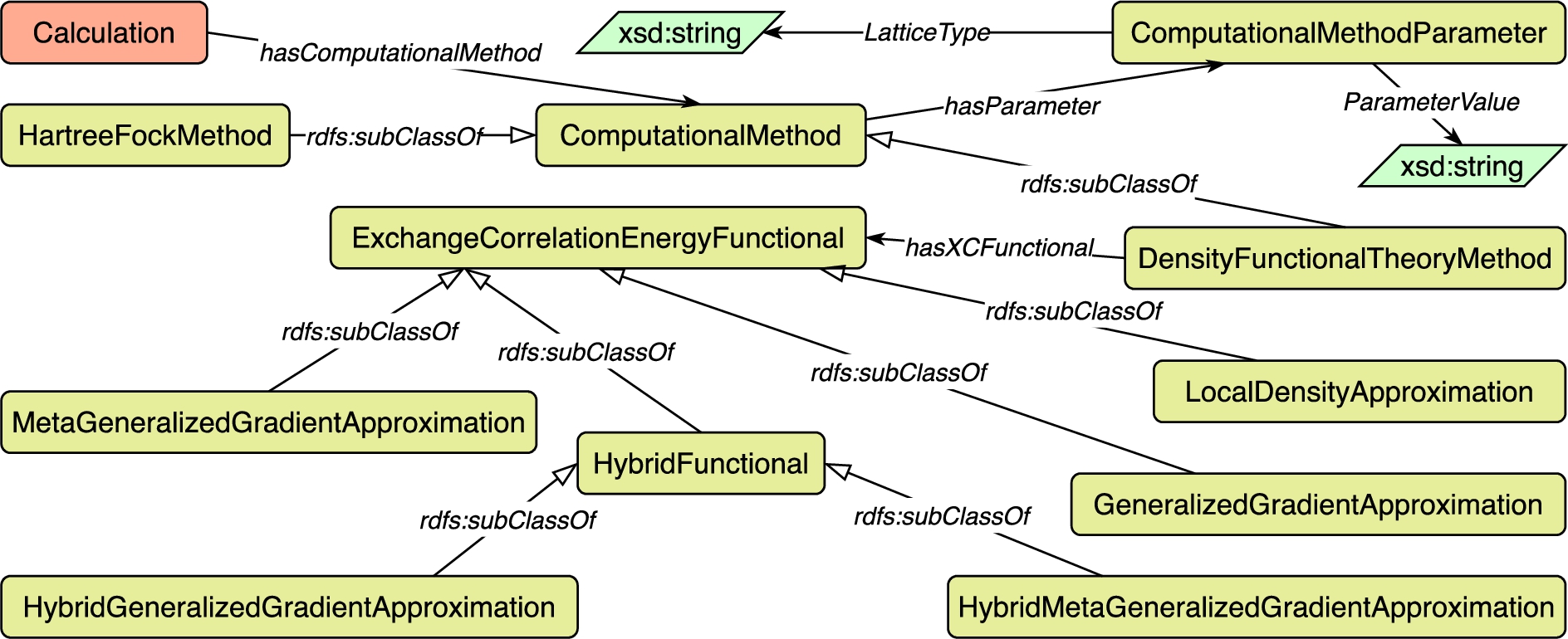
Concepts and relations in the Calculation module.

Description logic axioms for the Calculation module.
The
At the moment we have not considered calculations consisting of different steps, but each step would be a calculation on its own. Dealing with more complex representations is left for future work.
The

Concepts and relations in the Provenance module.

Description logic axioms for the Provenance module.
In Fig. 15 we exemplify the use of MDO to represent a specific materials calculation and related data in an instantiation. The example is from one of the 85 stable materials published in Materials Project in [23]. The calculation is about one kind of elpasolites, with the composition

An instantiated materials calculation.
In this section we use the approach in [39] to propose new concepts for MDO. The result of this work is a list of proposed concepts that are validated by a domain expert to be relevant to the domain. However, at this point the concepts are not yet included in the public version of MDO. Discussions are ongoing regarding the scope of the extension of MDO with respect to the domain and intended use of MDO.
A first step in the approach in [39] is to collect the corpus that is used as input. To be able to find as relevant information for MDO as possible, we used MDO as a seed for querying journal databases. The 37 concepts of MDO were used as search phrases for the titles and abstracts of two journals in the field of materials design, NPJ Computational Materials (
In the preprocessing step characters were set to lower case and punctuations were removed. Further, we removed words of length one or two. One consequence is that often materials symbols are removed. An advantage is that the phrases and words are usually not material dependent, but we miss cases where this is interesting.
After preprocessing there were 21,548 distinct words which together occur 808,862 times. An overview of the frequency of the words is presented in Table 2. Most of the words (72.27%) occur less than 10 times, while there are 17 words that occur more than 3000 times. These are ‘based’, ‘properties’, ‘method’, ‘calculations’, ‘phase’, ‘materials’, ‘study’, ‘structure’, ‘temperature’, ‘density’, ‘results’, ‘energy’, ‘electronic’, ‘model’, ‘molecular’, ‘simulations’, and ‘surface’.
The distribution of word frequency after preprocessing
The distribution of word frequency after preprocessing
As explained in Section 2.3, the ToPMine system [20] identifies high-quality frequent phrases of a length up to a maximum length that is given as an input parameter. In our experiments this was set to 10. The second column of Table 3 shows the number of frequent phrases that ToPMine4
Note that ToPMine, as described in [20], does not use the preprocessing step.
Number of frequent phrases for min_support 10, 15, 20, 25 and 30, respectively, and three different versions of the ToPMine algorithm. For the ToPMine_max versions, max_support_word is set to 8000
We also defined a maximum support threshold max_support_word. We call the system that uses this additional threshold and the preprocessing step, TopMine_max. Words that occur more than max_support_word times were removed. These words were usually very general terms that are not interesting for an ontology or that would not be interesting for a domain ontology, but possibly for a top-level ontology. We do note, however, that some of these words could be useful such as ‘method’, ‘electronic’, ‘model’, and ‘molecular’. The second column in Table 4 shows how max_support_word influences the number of generated frequent phrases with a constant min_support of 10. The higher max_support_word, the more frequent phrases are generated. Note that no word occurs more than 8000 times in our corpus, so setting max_support_word to 8000 allows all words (or, in other words, max_support_word is not used).5
Therefore, the difference in numbers for ToPMine and ToPMine_max without stemming in Table 3 shows the influence of the preprocessing step.
Number of frequent phrases for min_support 10 and for max_support_word 500, 1000, 3000, 5000, and 8000, respectively, for two different versions of the ToPMine_max algorithm
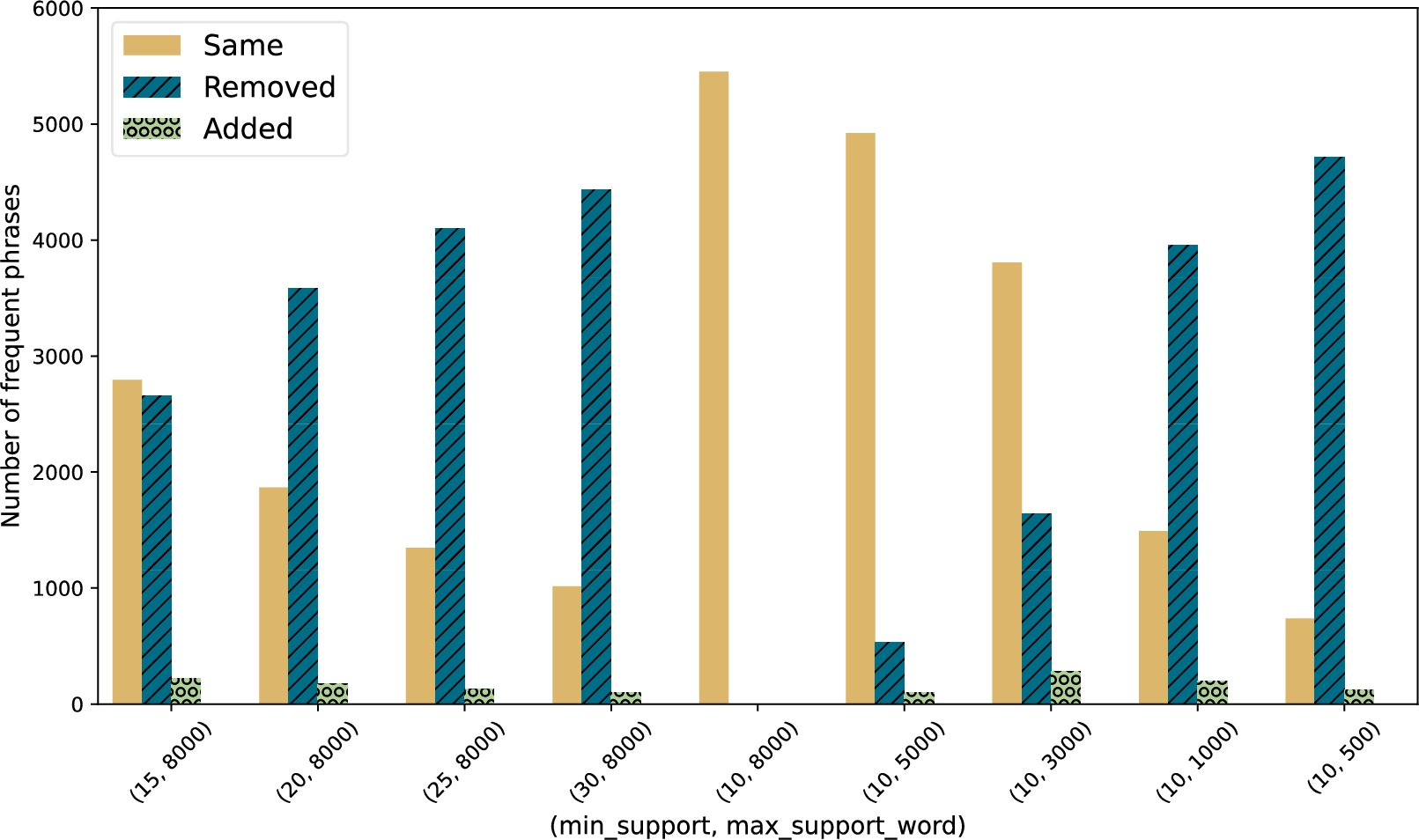
Comparison of the frequent phrases of ToPMine_max with stemming and min_support 10 (and max_support_word 8000) to settings with min_support 15, 20, 25 and 30, (and max_support_word 8000), respectively, and settings with min_support 10 and max_support_word 500, 1000, 3000, 5000, respectively.
Another way to look at the influence of min_support and max_support_word is to compare how many of the frequent phrases are the same and different for different settings. In Fig. 16 we show this comparison of different settings to the base setting (ToPMine_max with stemming) where min_support is 10 and max_support_word is 8000 (i.e., max_support_word is not used) which is shown in the middle of the figure. The ‘Same’ bars show how many generated phrases occur both in the base setting and the compared setting. The ‘Removed’ bars show how many frequent phrases occur in the base setting, but not in the compared setting. For the cases where we change min_support, these would be phrases that are frequent phrases for min_support 10, but not for the higher min_support in the compared setting. For example ‘computational screening’ is removed for min_support set to 15. For the cases where we change the max_support_word, these would be phrases with words that occur more often than the max_support_word in the compared setting. For instance, ‘sheet metal forming’ contains the word ‘metal’ with frequency 3457 and would be removed for max_support_word set to 1000. The ‘Added’ bars show which frequent phrases occur newly in the compared settings. This happens, as stated before, because ToPMine does not generate all frequent phrases, but focuses on high-quality frequent phrases. As an example, ‘exchange correlation potential’ appears at least 10 times and less than 30 times and ‘exchange correlation’ appears at least 30 times. Both are frequent phrases for min_support set to 10. However, ToPMine does not generate ‘exchange correlation’ for min_support set to 10, but it does generate ‘exchange correlation potential’. For min_support set to 30 ‘exchange correlation potential’ is not a frequent phrase, while ‘exchange correlation’ is, and ToPMine does generate ‘exchange correlation’ as a frequent phrase.
Further, we investigated the influence of using stemming on the frequent phrases. For instance, the phrases ‘molecular dynamics simulations’, ‘molecular dynamics simulation’, ‘molecular dynamic simulations’ and ‘molecular dynamic simulation’ have the same stem ‘molecular dynam simul’. Stemming allows for removing redundant phrases and thus reduces the work of the domain expert. The influence on the number of generated phrases can be seen by comparing the last two columns in Tables 3 and 4. A disadvantage is that in some cases possible concept candidates may be removed. To alleviate this problem we show the domain expert for each of the stemmed frequent phrases the list of corresponding original phrases. This also helps the domain expert to choose terms to be added to the ontology.
In Table 5, we show the candidate concepts based on the validation of a domain expert on the frequent phrases from the experiment with min_support 30 and max_support_word 500. In total, 88 candidate concepts are suggested based on 81 out of 131 frequent phrases generated by the experiment. Some candidate concepts can be added into MDO as sub-concepts of existing concepts. For instance, ‘Linearized Augmented Plane Wave Method’ is a sub-concept of ‘Density Functional Theory Method’. Some candidate concepts are relevant to the materials design domain but may be not interesting for data access or data integration over materials design databases. For instance, ‘Covalent Bond’ is a bonding type that can be used to describe materials structures.
After the phrase mining we generated topics represented as sets of phrases. The number of topics (num_topic) is an input parameter to ToPMine. Each topic contains a set of phrases and these sets do not have to be disjoint. For instance, Fig. 17 shows the overlap of phrases between topics for different settings of input parameters. In general, when we increase the number of topics, the number of frequent phrases in each topic decreases and the overlap between topics decreases as well.
The domain expert validates these topics and if possible, labels them to generate concepts for the ontology. In Table 6, we show the domain expert validation on 10 topics generated by ToPMine_max with stemming, min_support set to 30 and max_support_word set to 500. Among these topics, there are two topics (topics 0 and 9) that are interpreted with multiples labels, i.e., the domain expert divided the topic in different parts. The other topics received one label. Further, representative phrases are given for each topic. The labels and the representative phrases can all lead to new concepts.
Candidate concepts based on domain expert validation on the experiment with min_support 30 and max_support_word 500
Candidate concepts based on domain expert validation on the experiment with min_support 30 and max_support_word 500

Number of common phrases between pairs of topics.
Topic labelling based on domain expert validation on the experiment with min_support 30 and max_support_word 500 (Up to five representative phrases are selected for each label)
In this section we show how MDO can be used for providing semantic and integrated access to materials databases. As a proof of concept we implemented data integration over two data sources, Materials Project [31] and OQMD [47] using a new GraphQL-based framework for data access and integration. This framework is introduced in [38,41] and illustrated in Fig. 18. The framework generates a GraphQL server that provides integrated access to data from heterogeneous data sources. These data sources may be based on different schemas and formats and may be accessed in different ways (e.g., tabular data accessed via SQL queries or JSON-formatted data accessed via a REST API). To address the heterogeneity, the framework relies on an ontology that provides an integrated view of the data from the different sources, and corresponding semantic mappings that define how the data from the underlying data sources is represented as instances of the ontology (arrows (a)) and (b)). Furthermore, two processes are defined. The first process generates the GraphQL server. This includes generating both a GraphQL schema for the API provided by the server (arrow (i)) and a generic resolver function (arrow (ii)). This process does not need to be repeated unless the ontology or the mappings change. After this generation process, the GraphQL server can be set up. The second process deals with query answering and is performed after the GraphQL server is set up. During this process the query is validated against the GraphQL schema (arrow (1)); the underlying data sources are accessed via resolver functions, the retrieved data is combined, and the data is structured according to the schema (arrows (2) and (3)), and finally the query result is returned (arrow (4)). Details are available in [38,41].

Framework of ontology-based GraphQL server generation (OBG-gen).
In our proof of concept implementation we use MDO as the ontology to generate the GraphQL server. The GraphQL server contains a GraphQL schema generated based on MDO, and a generic resolver function that allows for accessing underlying data sources and restructuring the obtained data according to the GraphQL schema. This generic resolver function is implemented based on RML [16,17] semantic mappings defined using MDO terminology.
In a GraphQL API, the GraphQL schema defines types, their fields, and the value types of the fields. An object type represents a list of fields and each field has a value of a specific type such as object type or scalar type. A scalar is used to represent a value such as a string. An input object type can be used to define an input object with a set of input fields; the input fields are either scalars, or other input objects. A GraphQL schema also supports defining types that represent operations such as query and mutation. The schema presumes Query type as the query root operation type. The part of the final GraphQL schema shown in Listing 1 contains two basic object type definitions which are Calculation and Structure. Both have field definitions which represent the relationships to scalar types or to other object types. For instance, the Calculation type has a field definition ID of which the value type is String, and a field definition hasOutputStructure of which the value type is Structure. The Query type has a field definition which is CalculationList. This definition allows users to write a GraphQL query that accesses all the entities of Calculation type, as shown in the example in Listing 12. Further, the schema contains four input object type definitions which are CalculationFilter, CalculatedPropertyFilter, StringFilter and FloatFilter, for capturing notions of filtering conditions that should be taken into account in the evaluation of the GraphQL query. As an example, the CalculationFilter can be used as an argument of the CalculationList query. For instance, in the query example of Listing 12, the argument of the query from line 3 to line 10 is used to represent a conjunctive filter expression with the meaning ‘property name is band gap’ and ‘the value of the property is greater than 5’. In our generic implementation of GraphQL resolver functions, a filter expression represented by an input object type will be parsed and evaluated against the underlying data.

An excerpt of the GraphQL schema generated based on MDO.
Listing 2 shows an example of mappings in RML related to ‘band gap’ which is a CalculatedProperty. In general, an RML document has one or more Triples Maps which declare how input data is mapped into triples of the form (subject, predicate, object). A Triples Map contains the following three components; Logical Source, Subject Map and a set of Predicate-Object Maps. A logical source declares the source of input data to be mapped (e.g., line 2 to line 6). It contains definitions of source locating the input data source, reference formulation declaring how to refer to the input data, and logical iterator declaring the iteration loop used to map the input data. A subject map declares the rule for generating subjects when mapping input data into triples (e.g, line 7 to line 10). A predicate-object map consists of one or more predicate maps declaring how to generate predicates of triples (e.g., line 12), one or more object maps or referencing object maps defining how to generate objects of triples (e.g., line 19 to line 25). An object map can be a reference-valued term map (e.g., line 46 to line 48) or a constant-valued term map (e.g., line 13 to line 15). In Listing 3, we show an excerpt of the JSON response based on Materials Project for the query to retrieve the data in which the task_id of the calculation is mp-989579. All material needed to generate the server is available online at

An excerpt of the RML mappings defined based on MDO.

An excerpt of the JSON response based on Materials Project API.
We compare our tool, OBG-gen (Ontology-Based GraphQL Server Generation) with three systems: morph-rdb [42], HyperGraphQL [48], and UltraGraphQL [49]. Morph-rdb is a tool that can access a relational database by translating SPARQL queries into SQL queries based on R2RML mappings. HyperGraphQL and its extension UltraGraphQL are GraphQL interfaces to query Linked Data that may be provided by local RDF files and remote SPARQL endpoints.
The semantic mappings (for all the systems) are based on the MDO. OBG-gen generates the GraphQL schema based on MDO. For UltraGraphQL and HyperGraphQL we use a modified version of the generated schema since they require directive definitions, as additional configurations for object type or field definitions, to specify the context information when translating a GraphQL query to SPARQL query (e.g., for an object type in the GraphQL schema, what is the URL of the object type’s corresponding class in the RDF data.).
Data
The data from Materials Project and OQMD represents five different types of entities (Calculation, Structure, Composition, Band Gap and Formation Energy). We collected data in the sizes of 1K (i.e., 1000 entries), 2K, 4K, 8K, 16K and 32K from each database for populating the five entity types. We represented this data in different formats, i.e., tabular data for relational databases and for CSV files, and JSON-formatted data for JSON files. Additionally, for the RDF-based systems in our evaluation, we created an RDF file based on RML mappings and MDO for each dataset setting. We used six dataset settings for the experiments, which are 1K-1K, 2K-2K, 4K-4K, 8K-8K, 16K-16K and 32K-32K. Taking 32K-32K as an example, for each entity type, the test data contains the 32K data from Materials Project and the 32K data from OQMD.
Systems
Morph-rdb is served with data stored in a single database instance containing data from Materials Project and OQMD in separate tables. HyperGraphQL and UltraGraphQL are served with the same RDF data for each dataset setting. We use OBG-gen with two input settings. OBG-gen-rdb is served with two MySQL database instances hosting data from Materials Project and OQMD respectively. Conceptually, OBG-gen-mix is also served with two database instances. However, each instance contains different formats of data such as data in MySQL database, CSV or JSON files.
Query characteristics
Query characteristics
The queries that are used in our experiments are listed in the Appendix. We describe their characteristics in Table 7. The ‘CQ’ column describes which competency questions from Section 3.1 are covered by the queries. As the selected data covers competency questions CQ1-2 and CQ5-7, these are the ones that are covered. However, the other competency questions would in principle be easily covered with other or extended datasets. The ‘DI’ column shows which queries are of particular interest in the domain, i.e., these are often used queries to the materials databases. The other queries are mainly used to evaluate system performance on technically difficult queries. The ‘Filter’ column indicates whether the query contains filters.
As example, query Q9 in Listing 12 requests all the entities of Calculation type of which the value of the band gap property is larger than 5 electron volt. For such calculation entities, the query requests the corresponding values of ID, and reduced chemical formula of the composition of the output structure. Query Q12 in Listing 15 requests all the entities of type Structure which contain the silicon element.
Experiments and measurements
We evaluate the query execution time (QET) of the different systems over the six dataset settings. For each query separately, we run the query four times and always consider the first run as a warm-up, then take the average of the values of the remaining three runs. Figure 19 and Fig. 20 illustrate the measurements for all data sizes and all queries. The measures for all data sizes and all queries are available online at

Query Execution Time (QET) per data size on materials dataset.
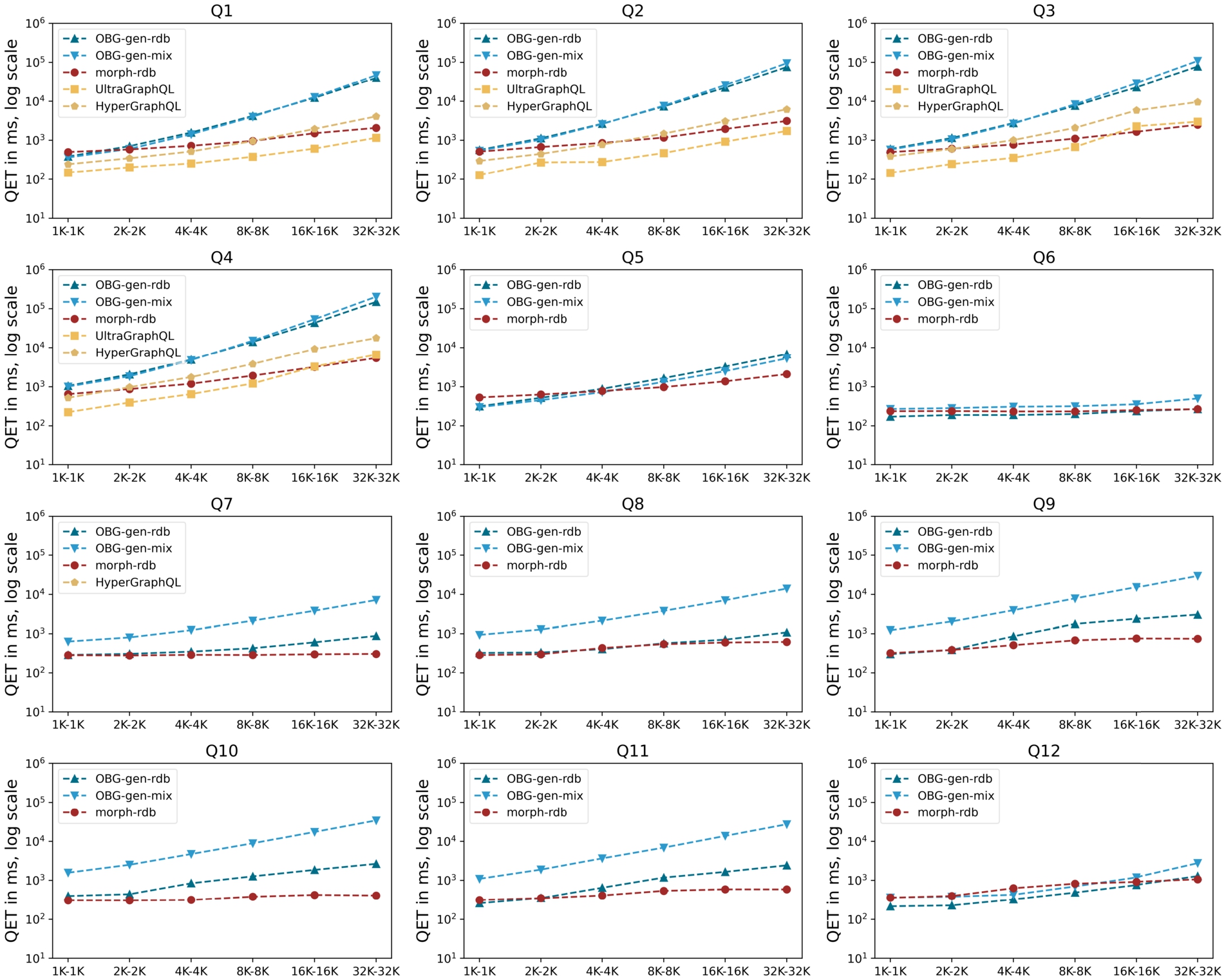
Query Execution Time (QET) per query on materials dataset.
We observe that both GraphQL servers generated by OBG-gen-rdb and OBG-gen-mix can answer all the 12 queries and thus the covered competency questions of MDO.
We also observe that increasing dataset sizes lead to increasing QETs (Fig. 20). For queries without filtering conditions (Q1-Q5) (Figs 19 and 20), all of the systems have increases of QETs as the size of the dataset increases. However, morph-rdb is less sensitive to the data size increase compared with other systems. UltraGraphQL and HyperGraphQL outperform other systems for some smaller datasets (e.g., UltraGraphQL’s QETs of Q1 and Q2, HyperGraphQL’s QETs for Q1 from 1K-1K to 4K-4K). We explain this by the fact that these two systems have additional context information declaring URIs of classes to which instances in the RDF data belong. This is in contrast with the other systems which have to make use of semantic mappings to output queries to be evaluated against the underlying data sources. OBG-gen-rdb outperforms morph-rdb for some queries in smaller datasets (e.g., Q1 in 1K-1K, Q5 in 1K-1K and 2K-2K). For some queries, OBG-gen-rdb and morph-rdb have close QETs (e.g., Q2 in 1K-1K).
Another observation is regarding how OBG-gen-rdb and morph-rdb perform for queries with filter conditions (Q6–Q12) (Figs 19 and 20). The two systems behave similarly for Q6 with stable QETs and Q12 with slight increases, as the data size increases. The result size of Q6 is a constant over all the datasets in different sizes. Additionally, the filter expressions for Q6 and Q12 are simpler compared with those of Q7–Q11. Therefore, the QETs consumed for evaluating filtering expressions for Q6 and Q12 are less than those of Q7–Q11. For other queries (Q7–Q11), morph-rdb outperforms OBG-gen-rdb, however the differences between the two systems are less than those for queries without filtering conditions (e.g., Q1–Q4). The filtering conditions in GraphQL queries for OBG-gen-rdb and in SPARQL queries for morph-rdb are written within WHERE clauses in SQL queries, thus will be evaluated against the back-end databases. A similar observation is also found in [11] where the experiments show that morph-rdb outperforms other systems (e.g., morph-graphql) as the size of dataset increases due to the SPARQL to SQL optimizations.
Conclusion
In this work we addressed the data access and interoperability issue for computational materials databases by developing MDO and providing a proof-of-concept implementation of an MDO-based data access and integration system for computational materials databases with a focus on solid-state physics and condensed matter theory. We have described MDO and a possible extension and showed that the proof-of-concept implementation can answer all competency questions for MDO, while not all of these could be answered by using the underlying databases’ APIs.
One direction of future work is to extend the current proof-of-concept implementation in different ways. We want to integrate more databases as well as the OPTIMADE API. Further, as many end users in this domain may be more comfortable with form-based user interfaces, we will look into providing a form-based user interface or one that aids users to pose queries.
After discussion with domain experts we will extend the public version of MDO with the concepts and relations they deem appropriate. This includes discussing the concepts proposed in Section 5, but also looking into recent ongoing work in other projects such as EMMO-CIF (
We will also look into top-level ontologies and investigate which ontological commitments would be fitting MDO. This is, for instance, one of the topics of a recently accepted OntoCommons (
Footnotes
Acknowledgements
This work has been financially supported by the Swedish e-Science Research Centre (SeRC), the Swedish National Graduate School in Computer Science (CUGS), the Swedish Research Council (Vetenskapsrådet, dnr 2018-04147), and the Swedish Agency for Economic and Regional and Growth (Tillväxtverket).