
Abstract
Data federation addresses the problem of uniformly accessing multiple, possibly heterogeneous data sources, by mapping them into a unified schema, such as an RDF(S)/OWL ontology or a relational schema, and by supporting the execution of queries, like SPARQL or SQL queries, over that unified schema. Data explosion in volume and variety has made data federation increasingly popular in many application domains. Hence, many data federation systems have been developed in industry and academia, and it has become challenging for users to select suitable systems to achieve their objectives. In order to systematically analyze and compare these systems, we propose an evaluation framework comprising four dimensions: (i) federation capabilities, i.e., query language, data source, and federation techniques; (ii) data security, i.e., authentication, authorization, auditing, encryption, and data masking; (iii) interface, i.e., graphical interface, command line interface, and application programming interface; and (iv) development, i.e., main development language, deployment, commercial support, open source, and release. Using this framework, we thoroughly studied 51 data federation systems from the Semantic Web and Database communities. This paper shares the results of our investigation and aims to provide reference material and insights for users, developers and researchers selecting or further developing data federation systems.
Keywords
Introduction
The convenience of digitization, the variety of data descriptions, and the discrepancy in personal preferences have led large enterprises to store massive amounts of data in a variety of formats, ranging from structured relational databases to unstructured flat files. According to the prediction by Reinsel et al. [1], the global data volume will reach 163 zettabytes by 2025, and half of that data will be produced by enterprises.
Since data becomes more valuable if enriched and fused with other data, decision-makers need to consider data distributed in different places and with different formats in order to get valuable insights that support them in their daily activities. However, data explosion in volume, variety, and velocity – i.e., the “3Vs” of Big Data [2,3] – increases complexity and makes the traditional ways of data integration [4–6], such as data warehousing [7,8], not only more costly in terms of time and money but also unable to guarantee the freshness of data. Integration solutions developed in a more agile way are thus demanded especially in the Big Data context. Data federation is a technology that makes this possible today, that is becoming more and more appealing in both industry and academia, and that has been studied for a long time in different communities such as the Database and (more recently) the Semantic Web ones.
Data federation systems (also known as federated database systems) are traditionally defined as a type of meta-database management system that transparently maps multiple autonomous database systems into a single federated database [9,10]. The key task of data federation systems is federated query answering, that is to provide users with the ability of querying multiple data sources under a uniform interface. Such an interface usually consists of a query language over a unified schema, such as SQL [11] over a relational schema or SPARQL [12] over an RDF(S)/OWL [13–15] ontology, this interface being often closely related or restricting the query languages and schemas of supported data sources. Unlike in traditional pipelines for data extraction, transformation, and loading (ETL) often used in data warehouse systems, federated query answering is achieved by data virtualization [16,17], i.e., all the data are kept in situ and accessed via a common semantic layer on the fly, with no data copy, movement, or transformation. As a result, federated query answering via data virtualization reduces the risk of data errors caused by data migration and translation, decreases the costs (e.g., time) of data preparation, and guarantees the freshness of data. Compared to centralized solutions, though, accessing multiple data sources on the fly renders query answering more challenging [18–20] and requires sophisticated optimization strategies to be devised. Besides federated query answering, modern data federation systems also offer a wide range of other important capabilities for data management, such as read-and-write data access for enabling users to both access and modify the data in the sources, data security for protecting the sensitive data of users and implementing secure data access, and data governance for managing the availability, usability, and integrity of the data.
Data federation is an active field and many data federation systems have been and are being developed. For example, FedX [21,22] and Teiid [23] are two systems supporting respectively SPARQL query answering over multiple SPARQL endpoints (i.e., standardized HTTP services [24] that can process SPARQL queries) and SQL query answering over multiple heterogeneous data sources, like relational databases, structured files and web services. More generally, current data federation systems include both industrial systems, mostly developed by software companies and more mature, and academic systems, mostly developed by research organizations and providing newer functionalities. Moreover, federated query answering facilities are often included in modern data management systems aimed at heterogeneous big data. These systems include logical data warehouses [25–27], data lakes [28–31], and polystores [32–36], and can be seen to all intents and purposes as special cases of data federation systems. All the aforementioned systems present substantial overlap in terms of adopted techniques and extra capabilities offered to users, while differences in the exposed unified interface may be often bridged – e.g., by using Ontology-Based Data Access (OBDA) [37] to adapt SQL over a federated relational schema to SPARQL over an OWL ontology – this way enabling the use of a data federation system in additional scenarios with respect to the ones it was primarily developed for – e.g., use a robust industrial SQL-based data federation system to create a “virtual” knowledge graph for Linked Open Data publishing. Therefore nowadays, users have access to a large number of data federation systems to choose among, but selecting the right system for a specific task requires collecting, analyzing, and comparing the capabilities and techniques of many systems, which is very time-consuming: for industrial systems, the information needed is usually fragmented and scattered, and the official documents often consist of hundreds of pages; for academic systems, conversely, end-user documentation is typically poor or unavailable, and system features are described in academic publications, when available.
This survey tries to shed some light on this complex matter by analyzing 51 state-of-the-art data federation systems, jointly covering systems from the Semantic Web and the Database communities thanks to their substantial interchangeability and their commonalities in implemented techniques and features. The considered systems, selected by following a rigorous and well-founded methodology, comprise 33 industrial systems under active development and with public official documentation, and 18 academic systems. This work has a twofold goal: help end users in identifying the systems best suited to their applications and tasks, and allow researchers and developers to gain more insights into the capabilities, techniques, strengths, and weaknesses of current systems, this way informing further work in the field.
In order to compare the considered systems from the perspective of data federation in a uniform way, this survey proposes a qualitative evaluation framework consisting of four dimensions further refined into several sub-dimensions, which we defined by considering and classifying the aspects that play crucial roles in the users’ choice of a system for employment in their applications and tasks:
The federation capabilities dimension concerns the federated query answering features offered by a system over multiple data sources, both homogeneous and heterogeneous in type. It is further refined into three closely related sub-dimensions: data source, query language, and federation techniques.
The data security dimension concerns the capabilities of a system of safeguarding the data in the sources participating in the federation from unwanted actions by unauthorized users, especially when such data is sensitive or private. It is refined into five sub-dimensions: authentication, authorization, auditing, encryption, and data masking.
The interface dimension concerns the usability of the systems. It is further divided into the three sub-dimensions of graphical interface, command line interface, and application programming interface, so as to measure the ability of supporting users in fully appreciating, accessing, and exploiting the features implemented by a system.
The development dimension, finally, concerns the development, release and support practices adopted by system vendors. Its five sub-dimensions of main development language, deployment, commercial support, open source, and release, aim overall at assessing the maturity of the systems and the possibilities for users to get help from vendors, and to maintain and improve the systems by themselves, if needed.
For all the 51 considered data federation systems, we collect information along the proposed four dimensions by consulting the official documentation of each system, as well as its related publications. Note that since not all the features of these systems are properly documented, our analysis is conducted using our best efforts.
This survey adds to an existing body of literature [20,38–43] that reviews the approaches and systems for federated query answering under multiple perspectives. For example, Oguz et al. [20] evaluate seven SPARQL federation query engines by focusing on their query evaluation techniques, while Azevedo et al. [42] study the modern data federation systems (including BigDAWG [33], CloudMdsQL [35], Myria [34], and Apache Drill [44]) by focusing on their features, owners, goals, and main components. Compared with all these works and summing up, we make the following contributions:
We carried out an extensive review of academic literature and documentation about industrial solutions to identify a large number of data federation systems from the Semantic Web and the Database communities.
We provide a framework for investigating data federation systems in a uniform and qualitative way by taking into account aspects of interest for data federation end users, developers and researchers.
We analyze the identified systems through the proposed framework, this work amounting to an extensive analysis covering 51 systems and 4 main evaluation dimensions overall divided into 16 sub-dimensions. To the best of our knowledge, this is the most extensive analysis on data federation so far in terms of investigated systems and considered aspects.
As a by-product of our analysis, we make explicit the common capabilities of current data federation systems, such as the capability of handling heterogeneous data sources, or the query optimization techniques used.
We discuss remaining open problems and challenges and point out the research directions that are interesting and valuable for pursuit.
The remainder of the survey is organized as follows. Section 2 presents an outline of data federation. Section 3 illustrates the overall methodology of the survey work. Section 4 describes the proposed framework for systems assessment and comparison. Section 5 lists and provides a summary of the selected systems. Section 6 thoroughly analyzes the capabilities of these systems according to the proposed framework. Section 7 discusses related work. Section 8 concludes by discussing open problems and challenges as well as giving directions for further work. Appendices A and B respectively provide further details on the specific sources supported by the systems and on our methodology. A Web version of the tables in this paper, including possible corrections and integrations, is available on GitHub.1
This section provides an overview of the main concepts underlying data federation that are addressed in this paper, for readers not already familiar with them.
The core task of data federation is federated query answering [20,38–41]. For a set of autonomous and possibly heterogeneous data sources, the goal of federated query answering is to provide a uniform interface, typically as a unified query language over a unified schema, to access the data of these sources in situ, i.e., without first copying the data to centralized storage. Given a user query over the unified schema, this task is carried out by issuing and orchestrating the evaluation of native sub-queries targeting the data sources of the federation.
Figure 1 depicts the typical architecture of a federated query engine providing federated query answering. Unified schema, mappings, metadata catalog are key components, which respectively provide a unified schema of the data sources participating in the federation, map the data in the sources to the unified schema, and provide statistical information about the data sources as well as the information of how these data sources can be accessed. For example, for a relational database, if the unified schema is an RDF ontology, then there exist mappings that map the tables of this database to the classes and properties of the ontology, and the metadata catalog could list the relevant content statistics, such as the number of rows of the referred tables, used in federated query optimization. Formally, a data federation instance usually consists of three components
Query parsing. This step deals with the syntactic issues of Q, i.e., checking whether the input queries are syntactically correct w.r.t. the adopted query language(s) as well as the unified schema. Some engines also transform Q into an algebraic form, such as a tree structure using internal nodes to denote operations (e.g., join, union, or projection) and leaf nodes to denote accessed relations.
Typical architecture of a federated query engine (inspired by Oguz et al. [20]).
Source selection and query partition. This step selects suitable data sources for each algebraic component of Q, and partitions Q into smaller sub-queries
Query optimization & query plan generation. This step computes an execution plan of the partitioned sub-queries
Query plan execution. This step, finally, evaluates the decomposed sub-queries
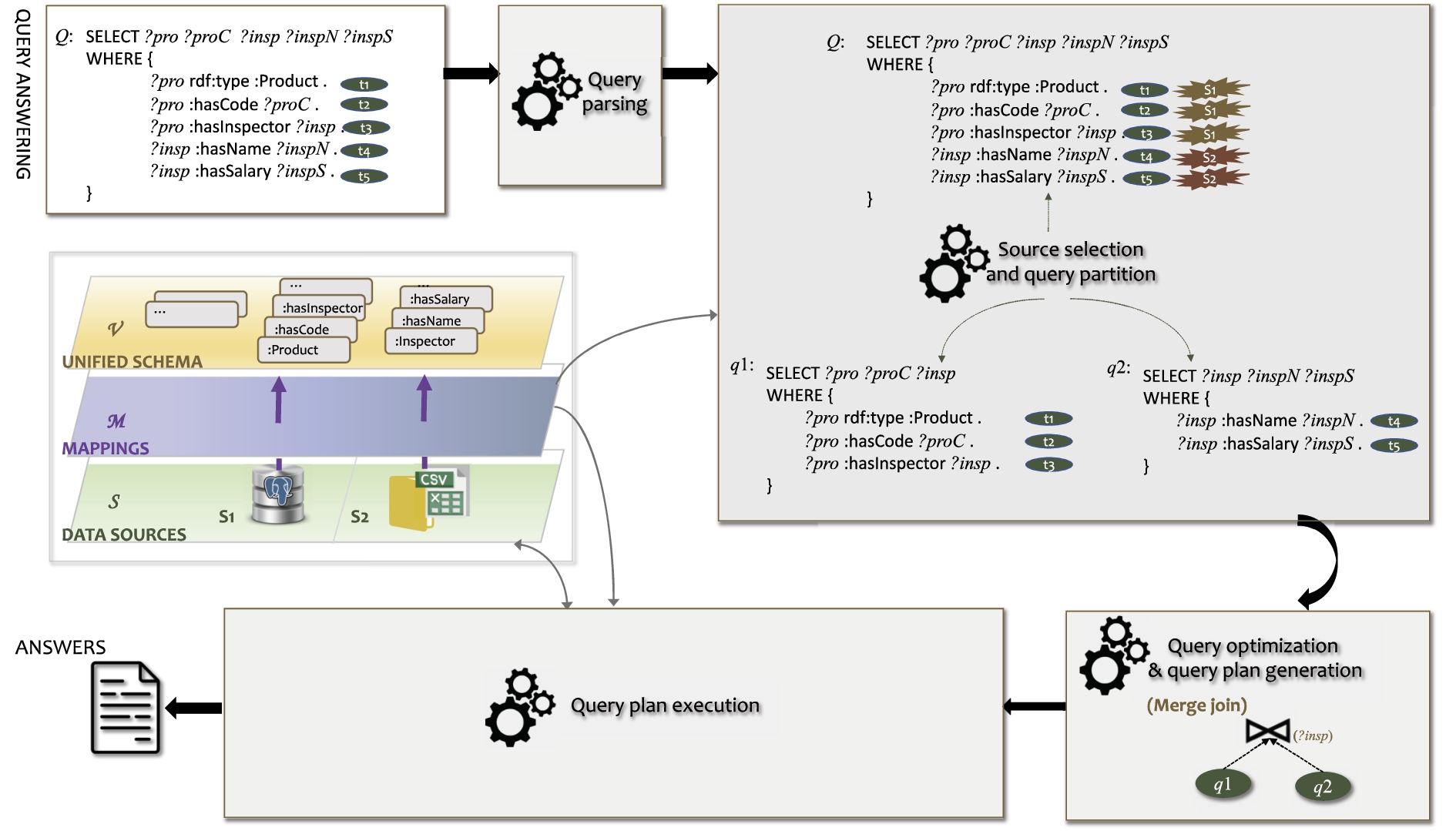
An example of federated query answering.
Next, we use an example to further clarify the inner workings of federated query answering.
Suppose we have a data federation instance
Suppose we want to retrieve the names of inspected products as well as the names and salary of their relative inspectors. For this purpose, we formulate a SPARQL query such as Q from Fig. 2, consisting of five triple patterns

Example of SPARQL query under the explicit federation setting (left-hand side), and its counterpart under the transparent setting (right-hand side).
From the perspective of whether the data source information is transparent for end users, federated query answering can be classified into transparent federation (the one we have discussed so far) and explicit federation [9,45]. Transparent federation gives users the impression to query one single data source despite data being distributed and possibly coming from heterogeneous sources [45]. Hence, it is recognized as a general and ideal2
A simplified setting is one where the unified schema is simply a merge of the source schemas, and the user explicitly states in the query the sources against which it should be evaluated. In such a scenario, we talk about explicit data federation. This approach is built-in into SPARQL 1.1 through its dedicated
Compared with transparent federated query answering, the explicit scenario does not require a procedure of source selection for delivering its task of accessing and joining multiple data sources. However, the burden is placed on end users, and this might constitute a major hindrance in case they are not familiar with the data sources participating in the federation and the data therein contained.
However, the transparent setting is not devoid of drawbacks. For instance, users lose the ability of communicating with specific data sources directly. Moreover, the transparent situation needs to maintain a unified schema mapped to multiple data sources, which means that it is more sensitive to schema updates: when the schema of a source is updated, the unified schema and the mappings may also need to be updated.
As mentioned earlier, beyond the core feature of federated query answering, data federation has evolved to offer a wide range of additional capabilities supporting more powerful and intelligent forms of data consumption and management. Next, we list some noteworthy capabilities supported by federation systems of this survey.
Data security. It provides techniques for protecting users’ privacy and sensitive data from leakage. Take the data federation platform Denodo as an example. The “unified security management” of Denodo offers a single point to control the access to any piece of information. Different users of Denodo are only allowed to access either filtered or masked data by using the Denodo role-based security model. Interested readers can refer to the official documents3
Data update. It provides the capability of enabling users to both read and write the data of the sources participating in the federation. For example, the SPARQL federation engine FedX4
Data quality. It provides the techniques for guaranteeing the correctness and consistency of data. Take the SAS Federation Server6
This survey work stems from our needs for selecting suitable data federation systems for heterogeneous data integration. Collecting, analyzing, and comparing the existing systems on data federation is a very time-consuming process. Sharing the results of our study can benefit readers interested in data federation solutions, such as end-users (consumers), developers, researchers and students. In this section, we present the overall methodology used for our study. Figure 4 provides a snapshot of our methodology, which consists of the identification of the considered systems, the design of the system evaluation framework, and the evaluation of the systems through the framework.

The overall methodology of the survey work.
As shown in Fig. 4, the systems considered in our survey are mainly identified through a four stage process: designing keywords and questions, searching in the search engines, finding the candidate data federation systems, and filtering according to the inclusion criteria. The bulk of candidate systems collection and filtering required three months, between the end of 2020 and the beginning of 2021. Although sharing the same stages, the criteria for selecting academic systems and industrial ones are a bit different. For clarity, in the following, we describe the selection of academic systems and industrial systems separately.
The selection of academic systems The considered academic systems are selected by reviewing the academic publications found via surfing the Google Scholar search engine. As a first step, we designed the following keywords to find the potential systems: “SPARQL federation”, “SQL federation”, “query federation”, “federated query answering”, “database federation”, “federated database”, “data federation”, “data virtualization”, “virtual data integration”
After reviewing these publications, we identified a total of 56 academic data federation systems that we narrowed down to a final selection of 18 representative systems based on the following inclusion criteria:
Scope. The system must focus on the problem of query federation, or introduce a data federation system. Venue. The system must be described in formal publications such as papers in journals or conference proceedings, and not only in preprints or technical reports. Availability. The system source code and official website must be available, either linked from the system publications or findable from the authors’ GitHub profiles (e.g., the SPLENDID system). Relevance. The system must satisfy at least one of the following criteria: it should be mentioned in system comparison publications; it should provide federation of heterogeneous data sources (e.g., RDBs and CSV files); it should ensure data security. Citations. For period ⩾2020, we do not consider citations. For period 2015–2019, systems should have at least 10 citations. For each prior period ⩽2008, 2009–2011 and 2012–2014, we only consider the system having the largest number of citations among the ones matching the previous criteria.
The citations criterion aims at keeping the scope of this survey manageable and focused on newer systems, also considering that most systems earlier than 2015 are covered by other system comparison publications and their source code is more likely to be unavailable, making them less interesting to our intended audience. Note that to apply this criterion, a system is classified into the year of its most recent conference or journal publication and a system number of citations is obtained by summing the Google Scholar citations of all its collected publications as of 2022/06/07.
Fine details of the selection process are provided in Appendix B, which reports on: (i) the collected 295 academic publications in terms of aggregated statistics (Section B.1) and full bibliography (Section B.4); (ii) the collected 17 system comparison publications, in terms of metadata, compared systems and considered aspects (Section B.2); and (iii) the selection of 18 systems out of the 56 identified ones, based on attained inclusion criteria (Section B.3).
The selection of industrial systems To find candidate industrial systems we adopted the Google search engine. We employed the following generic keywords/questions, aiming at including as many systems as possible:
“data federation”, “data virtualization”, “query federation systems”, “SPARQL query federation systems/tools/platforms/engines”, “SQL query federation systems/tools/platforms/engines”, “data federation systems/tools/platforms/engines”, “data virtualization systems/tools/platforms/engines”, “the systems like X”, Scope. The system must actually provide the capability of data/query federation. Community. There should be evidence for a user community around the system, e.g., via usage statistics and user messages in fora, mailing lists, issue trackers and the like. Documentation. Official system documentation must be publicly available, to support both (perspective) users and ourselves in conducting the analyses reported in this survey. Active development. There must have been at least a system release since 2015/10, i.e., in the last five year since the time we started this survey (2020/10).
where X denotes a data federation system already known by us, like Teiid and Denodo. We collected, deduplicated and reviewed the search results, looking for the websites of industrial data federation systems. Some search results already corresponded to a system website. Others were instead discussing more broadly about data federation/virtualization or recommending/listing/comparing systems referring to data federation, virtualization or integration, in which case we browsed page links to identify any referenced system website. As a result, we collected the official websites of 72 candidate systems that may provide (due to noise in search results following the use of generic keywords) the capability of data federation. We then consulted these websites, read the systems descriptions and documentation carefully, and eventually selected 33 industrial systems for our survey work that strictly meet all the following inclusion criteria:
The concrete information of the systems found, as their names, owners, and descriptions, can be found in Section 5.
The methodology for designing the evaluation framework

The generation of the system evaluation framework.
To design a framework for evaluating data federation systems in a uniform and qualitative way, also considering the intended audience of this survey, we focus on answering the following question (see framework design in Fig. 4):
What aspects of data federation systems are relevant for end users, developers and scholars?
While in principle answers can be obtained by interviewing these three groups (e.g., via questionnaires), this approach presents two main difficulties: (i) it is hard to identify a representative sample to interview; and (ii) it is hard for interviewees to answer the question in a general and comprehensive way. Instead, we rely on the fact that data federation is an established domain that has been studied for decades in both the Database and the Semantic Web communities, leading to a large body of information from which to extract the aspects of interest that answer our question. Concretely, we consider three information sources:
Academic publications. We look for aspects deemed important by other surveys on data federation, or that are frequent in academic publications referring to data federation systems.
Official documents. We look for aspects commonly present in official documents of data federation systems, such as user and developer guides.
Web pages. We look for aspects that are often considered when comparing data federation systems.7
E.g.,
The system evaluation framework, consisting of four dimensions with sub-dimensions, is generated by combining, classifying, and further refining the identified aspects. The full process is depicted in Fig. 5. Starting from our original question (Requirement box), we report the “raw” aspects identified in academic publications, official documents and web pages (Identification box). They were classified into four categories (Classification box), which then underwent a series of refining steps (Refinement box), guided both by the information sources we reviewed and by our own expertise as researchers and developers, as well as our own experience on the data federation task and systems. This refinement results in a final evaluation framework that addressess the information needs of the different audience groups targeted by this survey:
End users. They have the concrete need of integrating and federating data sources, and might lack technical skills like programming. Hence, aspects relevant to them are whether the system is able of handling their data sources, whether it provides a query language that they are familiar with, whether it offers a graphical interface to help them to set up a data federation instance easily, whether it provides the services for solving the problems they may encounter, whether it provides the techniques for protecting their data from leakage, and whether it is robust enough so as to withstand the technical difficulties that may be encountered in production (e.g., load spikes, temporary source unavailability, etc). Developers. Their need is to work with the systems at a lower-level than end users, for instance through programming interfaces, so as to enrich the functionalities delivered by their own applications. Other developers might also be interested in the source code of the systems themselves, for the purpose of extending it with new functionalities, e.g., to support more complex data consumption scenarios. Researchers and students. They conduct research or studies on data/query federation. Thus, the aspects of interest for them relate to the knowledge of the capabilities of the systems, or of the strategies they adopt.
All of the aforementioned aspects of interest are captured by the dimensions and sub-dimensions of our evaluation framework, as it will be detailed in Section 4.
After identifying the considered systems and the evaluation framework, we use such framework to investigate and analyze the capabilities, strengths, and weakness of the considered systems, e.g., the capability of handling data heterogeneity. Finally, we point out some open problems and challenges that might be addressed by further research.
The framework for system evaluation and comparison
In this section, we present our framework for analyzing and comparing the selected systems under a user and application perspective in a uniform and qualitative way. Our framework, shown in the right part of Fig. 5, consists of four dimensions: federation capabilities, data security, interface, and development. Each dimension is further characterized by sub-dimensions (16 in total). In the remainder of this section we discuss each of these dimensions, and relative sub-dimensions, in detail.
Federation capabilities dimension
This dimension evaluates the main task of data federation systems, i.e., federated query answering, in terms of data source, query language, and federation techniques.
Data source sub-dimension The types of supported data sources usually play a key role when choosing a data federation system. For example, if a company has massive CSV files that need to be virtually integrated with data stored in MySQL, then it will preferably take into consideration systems supporting CSV files and MySQL at the same time. This sub-dimension also permits users to distinguish whether a system focuses on heterogeneous or homogeneous data sources. Roughly speaking, the more different types of data sources a system supports, the more capable that system is in accessing heterogeneous data. By reviewing the data sources supported by the considered systems, we design six types of data sources, like relational and graph-based, to inspect this sub-dimension. The concrete information will be introduced in Section 6.1.
Query language sub-dimension We consider the query language(s) provided to users for accessing and managing the data in the federated sources. Generally speaking, a federation system should preferably adopt a standard query language that is familiar to most people, like SPARQL or SQL. In this way, users do not need to learn a new query language when using the system, and existing tools and resources for the adopted language can be reused. We considered the systems developed within the Semantic Web and Database communities, but not limited to these two kinds. Hence, we characterize this sub-dimension into SPARQL, SQL, and Other.
Federation technique sub-dimension We refer to the typical architecture for federated query answering described in Section 2, and assess the main techniques adopted by a system. We focus on the techniques for metadata catalog, unified schema and mappings, source selection and query partition, query optimization and plan generation, and query execution. The motivation is to help readers in forming a general idea about the techniques employed by each system.
Data security dimension
As a data-centric application, data federation offers a single logical point to integrate data from multiple sources that may contain sensitive and private data (e.g., financial transactions, users’ contact information, or medical procedures). The protection of such data represents a crucial problem for obtaining the trust of users and data providers. This problem is further complicated by the risk of leaking sensitive information through analysis and correlation of otherwise non-sensitive data from separate sources. Therefore, the data security dimension considers whether a data federation system has the ability of safeguarding data from unwanted actions of unauthorized users, and it is further organized in sub-dimensions according to the system’s support for the most common data security mechanisms.
Authentication sub-dimension Authentication refers specifically to accurately identifying users before they have access to data. It is the act of validating that users are whom they claim to be, and is the first step in any data security process. The most common authentication mechanism is a username and password combination. Other common authentication mechanisms use shared keys, PIN numbers, or security tokens.
Authorization sub-dimension Authorization is a mechanism for granting or denying access to a resource based on identity. More generally, it consists in defining an access policy, and is usually implemented through a set of declarative security roles which can be associated to users. Authorization is different from authentication, and usually happens after authentication.
Auditing sub-dimension Data auditing logs and reports on events like users’ accesses, modifications, changes of ownership, or permissions regarding sensitive data. Audit procedures increase visibility on data operations and are instrumental to the investigation and prevention of data breaches and other data security incidents.
Encryption sub-dimension Data encryption algorithms transform the original data into an unreadable format so that only authorized users having the corresponding key can decrypt and read the information. Encryption is commonly employed on data transiting between the system and the user, and possibly on data stored, cached, or otherwise materialized within the system as well, to protect them from unauthorized low level accesses.
Data masking sub-dimension Data masking8
The ultimate goal of system development is to support users in fully appreciating, accessing, and exploiting the features implemented by the system. Its achievement largely depends on the interface(s) offered to users for interacting with the system, which ultimately determine the ease of use, i.e., the usability, of a system. Such interfaces are the subject of this dimension, whose sub-dimensions are organized according to the different types of interfaces commonly offered by systems.
Graphical interface sub-dimension Setting up a data federation system is typically a complex task involving an extensive amount of configuration, e.g., for connecting the federated data sources, acquiring their necessary metadata, and setting up the system components. For example, Teiid supports the use of a complex XML configuration file10
Command line interface sub-dimension Data federation systems are typically used as components of larger information systems, where they need to be integrated with other components, such as business intelligence (BI), customized dashboards, or machine learning tools, to support or handle much more complex applications and tasks. To that respect, a command line interface provides a first, simple solution for automatically invoking the functionalities of a data federation system in other programs or scripts of a larger information system.
Application programming interface sub-dimension A further, more flexible integration mechanism is represented by application programming interfaces (APIs) offered by the data federation system, such as web APIs or client libraries in various programming languages (e.g., ODBC/JDBC drivers). Such APIs make it easier for developers to connect, configure, and operate an instance of the system at run-time within other applications.
This dimension considers the development, release, and support practices of a system, with its sub-dimensions capturing the aspects that are most relevant when matching the non-functional requirements of a user (in terms of, e.g., performance, robustness, flexibility, sustainability).
Main development language sub-dimension The main programming language(s) used to develop the core functionalities of a system influence system requirements (e.g., a Java Runtime Environment is required for the Java language), performance, customization, and integration options (e.g., embedding the system as a library), and consequently affect the system’s fitness for use in an intended user application.
Deployment sub-dimension The hardware/software infrastructure required to run a system, as well as its economic viability, are influenced by the deployment options offered for the system. At one end of the spectrum, we have on-premises deployment where the user obtains the software, possibly for a one-time license fee, and is in charge of its deployment, maintenance (e.g., updates) and configuration, which may occur on any machine(s) under the user control (i.e., “on the premises” of the user). The other end of the spectrum is represented by Software as a Service (SaaS),11
Commercial support sub-dimension Learning how to best use an unfamiliar and complex system and dealing with any issue preventing its normal operation are time-consuming activities, which may result in additional costs or even in economic losses due to system downtimes. Therefore, the availability of commercial support, e.g., in the form of training, timely bug fixes, and installation and customization services, plays a keys role when choosing a system.
Open source sub-dimension Systems whose source code is made freely available for modification and redistribution offer users more options for integrating the system while matching specific application requirements, for improving the system itself, and for maintaining the system even if it is no more supported by authors.
Release sub-dimension We consider the release history and practices of a system, focusing on the number of releases and the time between the first and the last release of the system. Generally speaking, the longer this time and the more numerous the releases, the more mature and robust the system typically is, since each new release is obtained by adding new functions or fixing some issues in the previous one. For example, the first release (v1.0) of the Denodo platform was in 2002 and the last here considered (v8.0) was in 2020. Thus, Denodo development has been active for almost 20 years, which makes it potentially more robust than some other younger systems.
Before reporting on the application of the framework of Section 4, we provide here the list and a brief overview of the selected systems involved in our evaluation and comparison, also to help readers become more familiar with the current offer on data federation, both industrial and academic, as a whole. For the data federation systems developed in the context of the Semantic Web community, more academic ones and less industrial ones were found. On the contrary, for the systems developed within the context of the relational databases community, more industrial ones and less academic ones were identified.
Summary of the selected data federation systems. Academic systems in italics

Summary of the selected data federation systems. Academic systems in italics
Table 1 lists the selected systems alphabetically, reporting for each one its name with relevant references where to gather detailed information, academic (name in italics) or industrial nature, provider, and a one sentence description introducing the system (in its latest version) and complementing the detailed information reported in the next sections. Note that here and in the following, the information for industrial systems (33 in total) was mainly extracted from their official websites, while for the academic systems (18 in total), information was mostly extracted and summarized from their academic publications, although we also considered their online documentation if available.
On the whole, the table exhibits a substantial variability in terms of system provider, nature, and their main characteristics. Providers range from university and research institutions for academic systems, to open source organizations, specialized companies, and major corporations for industrial systems. Systems range from database engines (RDBMS, graph databases, triple stores, polystores, and other multi-model systems) whose storage services are augmented with data federation capabilities, to purely mediator systems specifically focusing on data federation, possibly complemented with accessory functionalities (e.g., security). Some industrial systems can be accessed only as cloud services (SaaS).
In this section, we investigate and analyze in more detail each of the systems overviewed in Section 5, while applying the four dimensions of the proposed framework. The main goal is to better understand the main characteristics of each system and to reveal its strengths and weaknesses with respect to the main task of data federation. Notice that all the systems we investigated have been considered as per their latest version (last update on November 20th, 2021).
Federation capabilities dimension
In this subsection, we evaluate the selected systems with a special attention to their capabilities to support federated query answering. In doing this, we will highlight the query languages that are supported, the data sources each system is able to manage, and the adopted federation techniques. Concerning the first two aspects, a synthetic overview of the query languages and the types of data sources supported by the investigated systems is presented in Table 2. The concrete data source implementations (e.g., MySQL) supported by each system are instead listed in Table 7 of Appendix A.
Evaluation of query language and data source sub-dimensions. Academic systems in italics. “–” denotes feature/information not found in the systems’ official documentation, websites, or academic publications, to the best of our efforts

Evaluation of query language and data source sub-dimensions. Academic systems in italics. “–” denotes feature/information not found in the systems’ official documentation, websites, or academic publications, to the best of our efforts
Query language For columns 2–4 of Table 2, we can make the following observations:
With no significant distinction between industrial or academic systems, the standard and popular query languages SQL and SPARQL are adopted by most of these systems to query the data involved in the federation. This choice definitely eases the integration of the system with other possible interacting applications. Notice also that BigDAWG, CloudMds, Myria, and SAS Federation Server use alternative languages inspired by SQL to support the required capabilities in the distributed federation environment. Instead, Neo4j adopts the declarative graph language Cypher [74] as its underlying query language, with the motivation of making graph data querying easy to learn, understand, and use by the final users.
There exist very few systems that adopt multiple query languages at the same time. Among them, for instance, AllegroGraph supports SPARQL and Prolog simultaneously; GraphDB provides the capability of processing SPARQL, SQL, and Cypher queries; and Virtuoso takes both SPARQL and SQL as its query languages. This situation can be explained by taking into account that (i) the importance or necessity of supporting multiple query languages is unknown or ignored, and (ii) supporting multiple query languages within the very same system requires a lot of work from an engineering and development point of view.
Some of the academic SPARQL-based systems support only BGP-like queries, such as Obi-Wan [75] and Squerall [96]. Other systems support general SPARQL queries but their publications only discuss federation techniques tailored towards BGPs, such as CostFed [61], HiBISCuS [66], Ontario [28], PolyWeb [32], SAFE [89], SemaGrow [93] and SPLENDID [46]. General SPARQL support may be achieved by relying on a fully-fledged SPARQL engine like RDF4J12
For systems supporting SPARQL federation, only a few systems, like Amazon Neptune and Apache Jena, provide the capability of explicit query federation via the
Data source Uniformly evaluating and analyzing systems in terms of supported data sources is a challenging task for several reasons. Firstly, system providers usually adopt different standards and granularity to describe the data sources they support. Some systems classify supported data sources differently and possibly in incompatible ways. For example, relational sources all go under the databases class in Teiid,13
In order to understand the status quo of handling the variety dimension of big data in the data federation setting, after inspecting the data sources supported by each system, we take the following 6 types of sources into consideration: (i) Relational, including SQL-based RDBMS, (federated) relational query engines, and distributed/cloud relational stores; (ii) Graph-based, including SPARQL endpoints, RDF triple stores and property graphs; (iii) Aggregate-oriented, including key-value stores, wide-column stores, document stores and other NoSQL stores and search engines that organize data as “aggregates” [104], ranging from opaque values to arbitrarily complex nested documents;18
We use the broad “aggregate-oriented” category due to the difficulty of classifying many NoSQL stores into a single fine-grained category (e.g., Amazon DynamoDB is independently classified as key-value, wide-column, or document store by different academic and web sources).
By combining Table 2 and Table 7, we can observe the following:
Industrial systems usually support more data sources than academic systems (respectively, 3.2 vs 1.9 distinct source types per system on average). Consider for example Data Virtuality, which covers all the source types we considered. It is an unsurprising conclusion, since industrial systems usually focus more on coverage.
As for the systems covering multiple, possibly heterogeneous, types of data sources, no matter whether industrial or academic, relational sources have been considered extensively, and most of the mainstream RDBMS implementations have been supported (cf. second column of Table 7). This may be caused by the dominant role of relational sources in organizing data. This dominant role, along with the generality and well-understood semantics of the relational model, might also partially explain the proliferation of SQL connectors/adapters for non-relational data sources (see discussion in Appendix A). Such proliferation facilitates, for a data federation system supporting the connector/adapter data access interface (e.g., JDBC), extending the support to additional, unanticipated data sources.
Structured files like JSON, XML, and CSV, because of their importance and wide use, are also directly supported as native data sources by many systems considered in this survey (24 out of 51, i.e., 47%). Other systems not directly supporting structured files may instead support the database systems commonly used for storing and indexing the kind of data of these files (e.g., MongoDB and Elasticsearch for JSON data).
Aggregate-oriented sources mostly consist of NoSQL systems (cf. the fourth column of Table 7), exhibit overall support (24 systems out of 51, i.e., 47%) similar to the one for graph-based sources and structured files, and are present both in industrial systems (18 out of 33, i.e., 55%) and, to a lesser degree, in academic systems (6 out of 18, i.e., 33%).
Web service paradigms, although important (many sources are available only as web services), are considered less often (10 systems out of 51, i.e., 20%). This may be caused by the difficulty of implementing federated query answering over such kind of data, as their data models (where defined) and access patterns (usually restricted) are very dissimilar from the ones exposed by the data federation system to its users.
Other sources in our classification consist mostly of specialized web APIs (cf. last column of Table 7) and are supported by industrial systems (18 out of 33, i.e., 55%) more than academic systems (2 out of 18, i.e., 11%).
Systems supporting SQL queries focus on relational sources (21 systems out of 22, i.e., 95%) while graph-based sources have rarely been taken into account (5 out of 22, i.e., 23%). Conversely, systems supporting SPARQL queries focus on graph-based sources (25 systems out of 27, i.e., 93%) but support relational sources more frequently (10 out of 27, i.e., 37%) than SQL systems do with graph-based sources.
Federation techniques Besides the supported query languages and data sources, we also considered the specific techniques used by each of the selected systems. Table 3 organizes such techniques according to the main components of a typical data federation system as shown in Fig. 1. Note that the categories Unified schema and mappings and Source selection and query partition are only suitable for transparent federation. For each technique, we provide references to the literature and a list of systems for which the adoption of such technique is stated in official documents or publications. Hence, the lack of the indication of a particular system under a particular technique has to be interpreted as unavailable information, and not as negative information. This holds true especially for closed-source industrial systems, where information about these technical aspects is often covered scarcely or not covered at all in systems’ documentation. We next discuss each element of Table 3.
Summary of the main techniques used in federated query answering, grouped by affected main component of a typical data federation system. For each technique, we provide references to the literature describing the technique, as well as example systems known to implement the technique

Metadata catalog. A fundamental classification of federation techniques for this component distinguishes between techniques where the metadata catalog is automatically built out of source metadata accessed in a standard way (e.g., via the SQL “Information Schema”), and techniques that allow for manual provision of such metadata by users. These technique families are complementary and a system may adopt one or both of them (e.g., Denodo, see Table 3 for other examples). Manually supplied metadata may be described through self-defined dialects, such as the XML syntax of Teiid and the RDF molecule template of Ontario. Alternatively, some systems adopt standard languages, such as the VoID [94] vocabulary for Linked Data [126] (e.g., Squerall) or the SQL extension for the “Management of External Data”, SQL/MED [127] (e.g., Data Virtuality and Teiid, in alternative to its own XML). SQL/MED provides specialized SQL data definition language (SQL DDL) statements, such as
Unified schema and mappings. We divide the federation techniques for this component into two families: the one where the virtual schema is simply a merge of all the source schemas, and the one where the virtual schema is fully customizable by the user. In Table 3, many examples of the former category are SPARQL-based systems that federate SPARQL endpoints, while most of the examples of the latter category are either systems such as PolyWeb that allow the definition of a flexible virtual schema through R2RML/RML mappings, or SQL-based systems that allow the definition of views over the source data, as well as constraints over such views (e.g., primary and foreign keys).
Source selection and query partition. A common approach for the identification of the sources of a query relies on the pre-computation of an index out of the information available in the metadata catalog. Another technique involves the evaluation of probing queries and is exemplified by many SPARQL-based systems in Table 3. One of them is FedX (RDF4J), which issues a probing SPARQL ASK query for each triple pattern in the input query, so as to dynamically identify non-empty sources for that pattern in a more precise, albeit slower, way than using the index. Some systems, like SPLENDID, combine these two approaches to gather their respective strengths. Other systems, like HiBISCuS, propose a refinement of the query-based strategy where the candidate sources identified by the probing queries are further pruned through an analysis based on the structure of the SPARQL query. For SQL-based systems, source selection is straightforward in the typical scenario where tables of the unified schema are mapped 1:1 to their respective sources, but becomes non-trivial when table data is contributed by multiple sources, as it occurs with data partitioning or replication. Teiid “multisource models”,19
Query optimization and query plan generation. Some systems rely on fully-fledged cost models for generating an optimized query plan, as per the traditional setting of query answering against a single relational datasource. This plan also indicates the evaluation order of sub-queries and the types of joins to be used to combine their results. In other systems, like Ontario, the optimization is purely driven by heuristics and optimization steps are performed according to a pre-defined set of deterministic rules, such as pushing down certain operators (e.g., selection, projection) as much as possible to reduce the size of intermediate results. Cost-based and rule-based optimization may be also combined to attempt generating better query execution plans, as done for instance by Data Virtuality and SAP HANA. Finally, a complementary technique is the creation of materialized views, which can be used in place of re-computing each time the result of expensive distributed operations, in those scenarios where the source data is expected not to change frequently.
Query execution. Apart from standard join techniques such as nested loop or hash join, data federation systems provide techniques for query plan execution that are specifically tailored towards the federated setting. A common trait of these techniques is that they aim at minimizing data movement across the different systems participating in the federation. In the bind join between two relations, the outer relation is sequentially scanned for join values, which are then used to “bind” the attributes in the inner relation. For each such bind, the matching tuples in the inner relation are transferred to the source of the outer relation and used to construct the result. This approach can be seen as multiple application of the semijoin technique, where one side of the join is first filtered with the matching values, and then this “reduced” relation is sent to the other source for performing the actual join. The broadcast join, instead, “broadcasts” the matching tuples of the inner relation to all sources in the federation, which is an effective strategy when the outer relation is spread across several sources and the inner relation is much smaller than the outer relation. Splitting relations into smaller chunks lies at the basis of the partitioned join, where relations are partitioned according to values of the join keys. This join technique works in combination with parallelization, where computation is performed in a distributed way across multiple nodes at the same time. Finally, caching of the intermediate results allows further diminishing the number of distributed operations performed, and is popular among industrial systems.
Evaluation of the data security dimension. Academic systems in italics. “–” denotes feature/information not found in the systems’ official documentation, websites, or academic publications, to the best of our efforts. Subscript
denotes the use of named graph-based solutions to hide (mask) sensitive information in selected graphs to certain users, and possibly (for AnzoGraph DB) expose sanitized named graph views
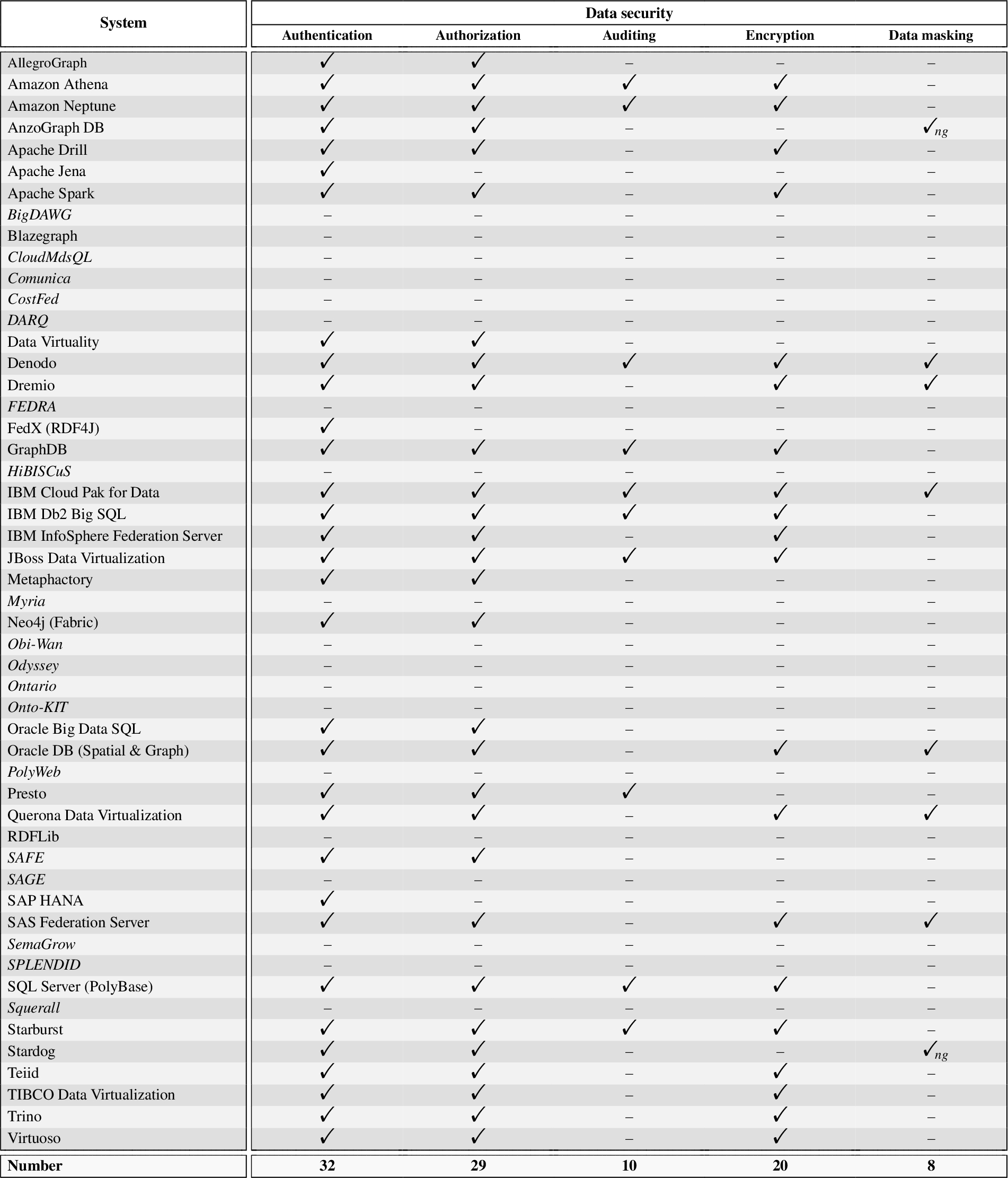
Evaluation of the data security dimension. Academic systems in italics. “–” denotes feature/information not found in the systems’ official documentation, websites, or academic publications, to the best of our efforts. Subscript
We evaluate here the data security dimension. The concrete investigation results are shown in Table 4, organized according to the sub-dimensions of authentication, authorization, auditing, encryption, and data masking. In particular, by analyzing the information we synthesized in the table, the following can be observed:
Almost all the considered industrial systems (31 out of 33, i.e., 94%) provide security mechanisms, such as authentication and authorization, to protect against unauthorized data access and leaking. This shows that the importance of data security is actually recognized by system providers in the data federation setting, where integrating multiple data sources via a unified virtual layer has the potential of making the private and sensitive data contained in federated sources more likely to be revealed.
Among the inspected mechanisms, authentication and authorization are definitely the most frequently adopted ones (see total counts in Table 4) and are implemented by almost all the industrial systems to identify users and control their access to data. For example, the Denodo Platform supports role-based authentication20
Besides authentication and authorization, the other three mechanisms, i.e., auditing, encryption, and data masking, are adopted by some industrial (only) systems to enhance security by auditing the actions of users and encoding and hiding sensitive information. Take again Denodo as an example. The Denodo Platform provides an audit trail of all the information about the queries and other actions executed on the system. It also supports the application of strategies on a per-view basis to guarantee secure access to sensitive data through encryption/decryption at different levels, and it masks (hides) sensitive data to ensure they are not accessed by unauthorized users. In SPARQL federation engines, data masking is provided by allowing hiding named graphs with sensitive information to certain users in AnzoGraph DB21
Data security has rarely been mentioned in the systems developed by academic and research institutions. Among the 18 systems we have evaluated in this category, just one system, i.e., SAFE, takes data security into consideration. SAFE is a SPARQL query federation engine that enables policy-aware access to sensitive, distributed statistical data sources represented as RDF data cubes.
Table 5 reports on the evaluation of the interface dimension, which is used to qualitatively evaluate the usability of the systems from both the end-user and the developer perspectives. As mentioned in Section 4 and reflected in the table, this dimension comprises the graphical, command line, and application programming interface sub-dimensions. Here, we analyze which of these interfaces are made available to the users, further identifying the different types of exposed application programming interfaces (e.g., JDBC drivers, web APIs). We cover only documented (vs. hidden in the code) interfaces and we do not consider effectiveness and ease of use, whose evaluation is largely subjective as, for any given interface, user experience is affected by individual user’s preferences and habits. In summary, from Table 5 we can derive the following observations:
Evaluation of the interface dimension. Academic systems in italics. “–” denotes feature/information not found in the systems’ official documentation, websites, or academic publications, to the best of our efforts
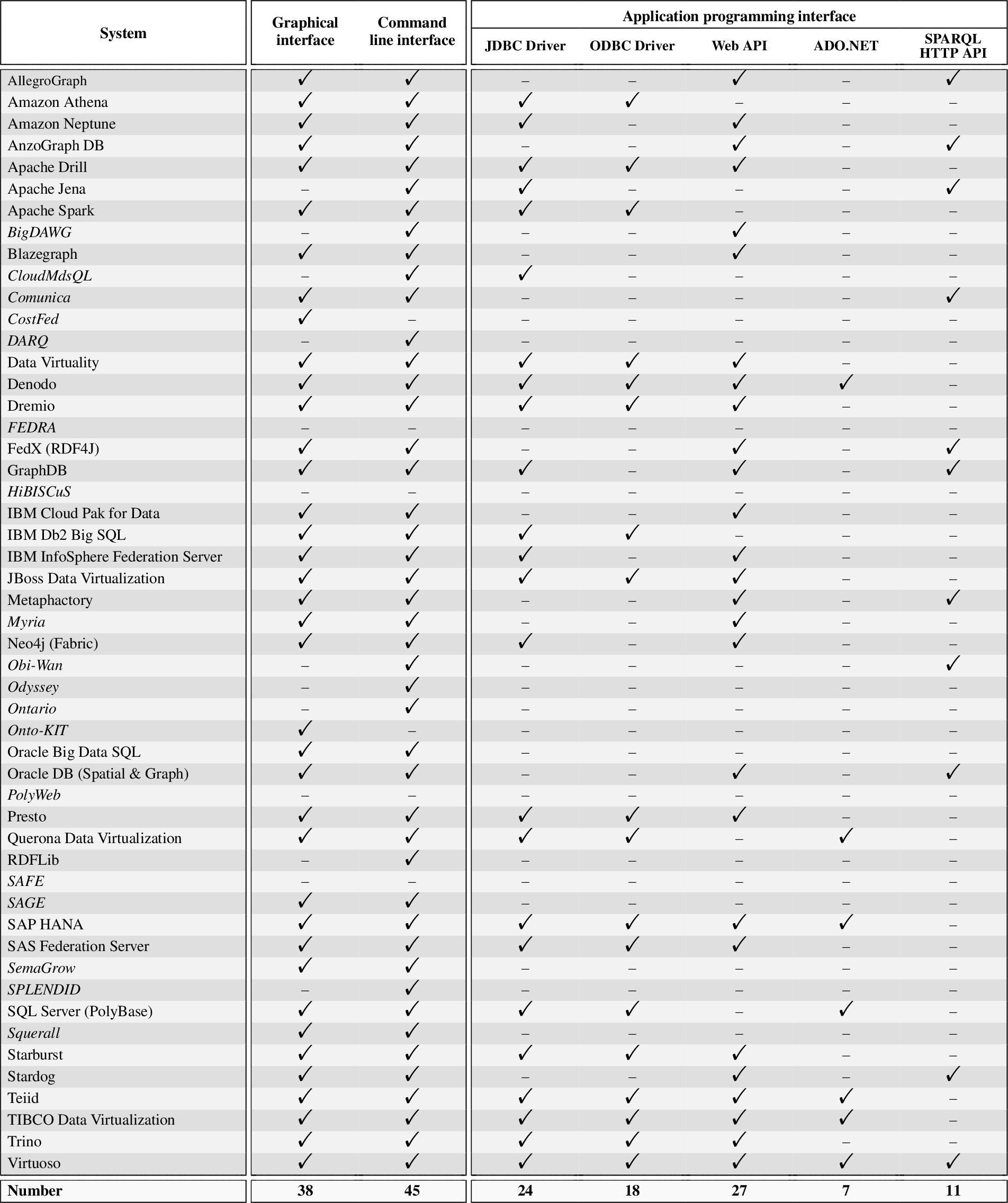
Evaluation of the interface dimension. Academic systems in italics. “–” denotes feature/information not found in the systems’ official documentation, websites, or academic publications, to the best of our efforts
Nearly all of the industrial systems (31 out of 33, i.e., 94%) provide graphical interfaces, which consist mainly in web consoles or web interfaces, and command line interfaces (all 33 industrial systems), which help users to deploy and manage data federation instances. For example, AllegroGraph provides the AllegroGraph Web View,24
Besides graphical and command line interfaces, most industrial systems like Denodo and Teiid also provide JDBC and ODBC drivers (respectively, 23 and 18 systems out of 33, i.e., 70% and 55%) to enable users to access and interact with them as standard relational sources. Web APIs (mainly RESTful) are also very frequent among industrial systems (25 out of 33, i.e., 76%), while there is less support for ADO.NET and the SPARQL HTTP API. The latter is exclusively provided by systems supporting the SPARQL query language (see Table 2) that also directly implement the associated SPARQL HTTP query protocol (instead of relying on other non-standard means for receiving a SPARQL query and returning its results). Furthermore, few systems, such as AllegroGraph, Presto and Stardog, provide also multiple client libraries to help users in interfacing with these systems using the most popular programming languages, like C, Go, Java, Python, R, and Ruby.
The three systems not associated to any interface in the table are all academic (Fedra, HiBISCuS, SAFE). For these systems, the documentation only covers the experiments conducted and indicates, at most, the script (Fedra) or the code entry points (HiBISCuS) for reproducing the specific experiments.
Table 6 reports on the evaluation of the development dimension and its sub-dimensions, which all together deliver information relevant to developers for integrating the system with other applications or for patching, extending, or otherwise modifying the system itself, if possible. Note that for the industrial systems, the information of the first release, i.e., the year and version number of the first version made available, is actually the information of the oldest versions we have been able to gather from their official websites. Note also that the academic systems often do not follow well-defined release cycles with proper versioning, e.g., CostFed.26
Evaluation of development dimension. Academic systems in italics. “F.” and “L.” denote “First” and “Latest” respectively. Subscript letters further qualify available deployment options: n = native; c = containerized; a = Amazon AWS; m = Microsoft Azure; g = Google Cloud Platform. “–” denotes feature/information not found in the systems’ official documentation, websites, or academic publications, to the best of our efforts

Java is the most used programming language for both industrial and academic systems, even when accounting for the incomplete information of this sub-dimension (see counts in Table 6). Comparatively less used languages include C/C++ (AnzoGraph DB, SAP HANA and other systems), Python (RDFLib, Squerall, SAGE), Scala (Apache Spark, Ontario), JavaScript (Comunica) and Lisp (AllegroGraph, in combination with Java).
Excluding two SaaS industrial systems from Amazon (Athena, Neptune), on-premises deployment is always offered, represents the only available option for academic systems, and concerns software both in native form (n subscript, almost always possible) and containerized form (c subscript, e.g., via Docker images), the latter supported more in industrial systems (21 out of 33, i.e., 64%) than academic systems (4 out of 18, i.e., 22%). SaaS (6 industrial systems out of 33, i.e., 18%) is less frequent than IaaS/PaaS (12 out of 33, i.e., 36%), the latter always supporting Amazon AWS (a subscript), followed by Microsoft Azure (m subscript, 8 IaaS/PaaS cases out of 12, i.e., 67%) and Google Cloud Platform (g subscript, 5 IaaS/PaaS cases out of 12, i.e., 42%).
Among the industrial systems, the majority are closed source (21 out of 33, i.e., 64%), and most of these come with commercial support services (19 systems out of 21, i.e., 90%). Similarly, most of the open source industrial systems offer the option of commercial support (7 systems out of 12, i.e., 58%). Academic systems are all open source without commercial support.
In comparison with academic systems, it is easy to see that industrial ones typically feature a much more active development. Some of these industrial systems have been developed, maintained, and improved for many years, such as Denodo and Teiid. Unfortunately, for the academic systems, despite the fact that all of them are open source initiatives, it is common that they are not enhanced or maintained after the publication of the respective academic papers.
Based on the above reported evaluation and analysis, and after having reviewed the official documentation and academic publications of each of the systems considered in this survey, in the following we summarize the most crucial and interesting lessons we learned.
Background theory and standards Data federation, especially over heterogeneous data sources, is currently a very active field in both industry and academia. However, the overall development of data federation systems still seems to lack background theory and standards. Let us note, for instance, that different systems force users to adopt their own dialects to develop and model the logical or meta-data layer of the target data sources. This strategy drastically hinders information reuse, as information produced for one system cannot be directly used in other systems.
Other capabilities Among the other capabilities beyond the data federation task itself (cf. Section 2.2), only data security was captured by our evaluation framework, which is based solely on the aspects of interest arising from applying the methodology of Section 3.2. This fact further remarks the importance of data security, especially among industrial systems, whereas data update and data quality have been less investigated in combination with the data federation. Nevertheless, some of the considered systems provide capabilities related to data update and data quality. Concerning data update over the federated data sources, Teiid27
Ontology-based data access Ontologies, providing a shared abstraction of a domain of interest, can play a key role in handling the heterogeneity of concepts in data integration. The so-called Ontology-Based Data Access (OBDA) approach has been studied intensively [37,77,129–134] in the last two decades. In OBDA, a mediating ontology provides a high-level representation of the data contained in a relational source, as well as an encoding of domain knowledge. The link between the ontology and the source is realized through mappings, e.g., expressed using R2RML [135]. The distinctive characteristics of OBDA are that query answers are enriched through automated reasoning over the ontology, and that such process is carried out in a virtual mode: the data in the database is not materialized as a graph, but rather queries are rewritten on-the-fly and executed against the original source.
The virtual characteristic of OBDA makes it a potential candidate for incorporating mediating ontologies in the data federation framework. Still, this marriage has rarely been discussed or considered to its fullest extent, and it represents an open research line. For instance, Squerall [96] and PolyWeb [32,85] are virtual systems based on RML/R2RML mappings but both lack reasoning support, hence they do not qualify as fully-fledged OBDA systems as per their definition in the literature [129]. An exception is Obi-Wan [75,76], an OBDA system32
Although, based on GLAV mappings as opposed to GAV mappings usually applied in OBDA contexts.
Obi-Wan is for the most part a proof-of-concept of a more general and insightful theoretical exercise. Hence, it does not present any optimization technique specific to the federated setting and is not tailored towards handling real-world, complex scenarios. Using domain ontologies to virtually integrate heterogeneous data sources combines the difficulties of ontology reasoning with the ones of integrating heterogeneous data, and this negatively affects performance. Further investigations and, possibly, innovative approaches are required to obtain systems that would exhibit a performance that is adequate to real-world application needs. A preliminary investigation towards this direction has been conducted by Gu et al. [136,137]. The use of ontology-based techniques – and, more generally, of Semantic Web methods and standards – to address data quality, update, and security aspects of data federation systems also appears promising and deserves further research.
Interrelationships between data sources Most of the time, the data sources that are subject to a data integration initiative are not fully independent from each other. Indeed, there may exist interrelationships among the integrated data sources, such as information overlapping, complementarity, and conflicts. Automatically discovering such interrelationships may help developing data federation systems of higher efficiency. As a simple example, if a data source
Most advanced methods and systems handle overlapping to some extent. BigDAWG exploits equivalence and containment information provided by data curators [138] to identify equivalent operations across different data models, so as to optimize its source-selection strategy. DAW [139], not considered in this survey, exploits a compact representation of data as vectors for which estimates on overlapping can be automatically found. This information is then used to prune, with high recall, redundant sources during source selection. FEDRA [64] does not require to encode data, but relies on fragment descriptions for its source selection, where each fragment essentially describe the triples that can be extracted out of a set of data sources.
Note that all approaches require a substantial amount of meta-information which might be hard or even impossible to produce automatically. It has been recently observed by Gu et al. [136,137] that this limitation is greatly reduced in OBDA settings, where one can exploit both the semantic information provided by the ontology and the URI construction rules encoded in the mappings. This fact allows for optimizations that are not specific to the source selection phase, such as the removal of redundant or empty operators, or the automatic leveraging of materialization of pre-computed results and on-the-fly access to the sources.
Combining systems The capabilities of a system can be extended through combination with other tools. We identify two mechanisms for combining a data federation system with a tool, the latter operating as adapter and possibly being a data federation system itself; these mechanisms can be iteratively applied to combine multiple components.
In the first mechanism, the tool acts as a source of the system and is used to add indirect support for some additional sources that cannot be natively connected to the system, by adapting them to one of the supported source types (e.g., JDBC or ODBC). For instance, the data sources directly supported by Querona Data Virtualization exclude MongoDB but include Denodo and Apache Drill, which instead support MongoDB and can be thus combined to add indirect support for MongoDB. As another example, one may extend SPARQL-based federation to relational sources through the combination with an OBDA engine, as successfully applied by Sima et al. [140] who use the OBDA system Ontop to expose biomedical data as RDF graphs, then federated through a SPARQL federation engine.
In the second mechanism, the tool acts as client of the system and is used to adapt or extend the unified schema, query language(s) or capabilities offered by the system. For example, one may deploy33
As remarked in the text (Section 6.1), the “Data source” dimension of Table 2 and in general all the dimensions and tables of this survey do not account for the combination of systems, but rather focus solely on sources and capabilities that are directly supported by the data federation system. The reason is that it is very difficult to comprehensively assess which sources or capabilities a data federation system may acquire by carefully combining it with other tools, as combinations are possibly limitless and the assessment of the practical feasibility of each is non-trivial and not clearly defined, as there might be hard-to-quantify integration costs involved (e.g., to remove minor incompatibilities at the interface between combined tools).
In this survey, we have investigated and analyzed a total of 51 data federation systems. Considering data federation in the broader context of data integration, in the following we situate this survey among other works in the Database and the Semantic Web literature that review existing approaches, techniques, and systems for both virtual and materialized data integration.
Database community Halevy et al. [6] discuss some of the most important results in the data integration field before 2006, and outline some challenges for data integration research. The survey by Magnani and Montesi [141] reports on the techniques for managing uncertainty in data integration, and the survey by Bikakis et al. [142] investigates the approaches focusing on semi-structured data. Finally, the works by Arputhamary et al. [143–145] mostly address the issues emerging when techniques and systems are meant to be applied to integrate big data.
Readers that are interested in knowing more about existing approaches and implemented systems for integrating data virtually can refer to several related surveys [9,42,43,146]. In particular, the survey by Sheth and Larson [9] discusses data federation systems. The authors define terminology and a “reference architecture” for distributed database management systems with the main aim of providing a framework in which to understand, categorize, and compare different architectural options for developing federated database systems. Additionally, they introduce a methodology for developing tightly coupled federated database systems with multiple federations and processors (that is, software modules that manipulate commands and data). In a different survey, Bondiombouy and Valduriez [146] investigate multistore systems by first introducing the currently available cloud data management and query processing solutions, then describing and analyzing some representative multistore systems according to their architecture, data model, query languages, and query processing techniques. They finally classify these systems into three categories, i.e., loosely-coupled, tightly-coupled, and hybrid. The survey by Tan et al. [43] focuses on query processing over heterogeneous data sources by first introducing a taxonomy that categorizes the solutions into data federation systems, polyglot systems, multistore systems, and polystore systems. On top of this categorization, the authors propose an evaluation framework, largely inspired by the work by Sheth and Larson [9], incorporating the axes of “Heterogeneity”, “Autonomy”, “Transparency”, “Flexibility” and “Optimality”. The survey finally compares and analyzes four specific systems – BigDAWG, CloudMdsQL, Myria, and Apache Drill – according to the introduced evaluation framework. Azevedo et al. [42] focus on new generation data federation systems addressing the manipulation of structured and unstructured data, usually in high volume, over distributed and heterogeneous data sources. The authors first review the literature aiming at giving an overview of state-of-the-art modern data federation systems and then analyze the four aforementioned systems – BigDAWG, CloudMdsQL, Myria, and Apache Drill – by reporting on their “Definition”, “Owners”, “Goals”, “Query Specification and Execution”, “Main Components”, and other significant dimensions.
Semantic web community Wache, Noy, Ekaputra et al. [147–149] provide general surveys of those solutions for integrating data that are based on Semantic Web technologies and that follow the so-called Ontology-Based Data Integration (OBDI) approach. OBDI is a broader approach than OBDA, and differs from the latter for the fact of allowing for very expressive ontology languages while dropping the requirement of virtual access to data. Hence, OBDI approaches are not really suited to the federation setting considered in this survey. Other works focus instead on specific subdomains in which semantic technologies have been applied to integrate data. In particular, Buccella et al. [150] analyze and compare existing approaches for ontology-driven geographic information integration. An investigation of the approaches and techniques developed in the ontology community for integrating biological data is given by Hassan et al. [151]. The survey by Mountantonakis and Tzitzikas [152] investigates the works that have been done in the area of Linked Data integration, covering both materialized and virtual integration approaches. This work provides a concise overview of the issues, methods, tools, and systems for semantic integration of data, and gives emphasis on the methods that provide support for the integration of large numbers of datasets.
As for the virtual approach to data integration, some literature can be found [20,38–41] surveying, in particular, approaches and systems for federated SPARQL query answering. To summarize, the survey by Rakhmawati et al. [38] gives an overview of SPARQL federation frameworks – i.e., frameworks supporting (i) SPARQL 1.1 federation extension, (ii) federation over SPARQL 1.0 endpoints, and (iii) federation over SPARQL 1.1 endpoints – and classifies and analyzes 14 existing SPARQL federation approaches. Oguz et al. [20] evaluate 7 federation engines by first providing a detailed and clear insight on data source selection, join, and query optimization methods. They also introduce a qualitative comparison of these engines according to the following criteria: “No Preprocessing per Query”, “Unbound Predicate Queries”, “Parallelization”, and “Adaptive Query Processing”. Ngonga Ngomo and Saleem [39] provide an overview of current challenges and opportunities of federated query processing as well as summarize the results of recent state-of-the-art studies. Saleem et al. [40] first provide a survey of 14 federated SPARQL query engines according to: “Code Availability”, “Implementation Language”, “Licensing”, “Source Selection Type”, “Join Type”, “Cache”, and “Index/Catalog Update”. They then compare 5 SPARQL endpoint federation systems by using the performance evaluation framework FedBench [153] and by considering the dimensions of query runtime, number of sources selected, total number of SPARQL ASK requests used, completeness of answers, and source selection time. Finally, Qudus et al. [41] first propose some metrics to measure the errors in cardinality estimations of cost-based federation engines and the correlation of the values of these metrics with the overall query runtimes. Then, they present an empirical evaluation of 5 cost-based SPARQL federation engines on LargeRDFBench [154] according to the proposed metrics.
Comparison This survey builds on the aforementioned literature and is consistent with the terminology, concepts and key distinctions adopted therein. For instance, considering the foundational work by Sheth and Larson [9], their terminology can be related to several (sub-)dimensions of our evaluation framework as follows: (i) “Heterogeneity” is captured at different levels by our Data source, Query language, Federation technique and various Development sub-dimensions; (ii) “Query processing and optimization” is also captured by our Federation technique sub-dimension; (iii) “Access Control” is related to our Data security dimension (especially, its Authorization sub-dimension). (iv) “Transparency” is captured by the distinction between Transparent vs. Explicit federation.
The key difference between our work and the aforementioned surveys is mainly reflected in the following two aspects. First, we have analyzed and investigated a larger number of systems, including among them both industrial and academic initiatives and systems adopting different data models, i.e., SQL-based and SPARQL-based. Second, we have introduced here as a novel contribution a framework to inspect, analyze, and then classify the main characteristics of each system. The framework has been developed by taking into consideration the requirements of the end-users, as well as those of the developers and of the scholars, this way trying to deliver the information that they need when making choices for their respective data federation activities and projects. Our main motivation is to assess the techniques and capabilities of the existing systems for data federation, so as to reveal their strengths and weaknesses in relation to the plurality of evaluation dimensions we consider, rather than classifying the systems along one single dimension or according to the requirements of one single category of prototypical users.
Concluding remarks and future work
In this paper, we provided a systematic overview of 51 data federation systems, with the motivation of evaluating their capabilities as well as the strengths and weaknesses of the employed techniques for integrating heterogeneous data sources uniformly and virtually. To do so, we have proposed a framework with four major dimensions and additional sub-dimensions to classify systems from the end-user, the developer, and the scholar perspectives, in a uniform and qualitative way. We think that the evaluation framework we have proposed can be valuable for all these target personas: it helps end-users in finding the system that most suits their application requirements and, at the same time, it drives decision making by developers and researchers in further improving the currently available solutions and in designing more powerful federation systems. Besides that, our work also aims at providing up-to-date reference information for all those interested in dipping their toes in the data federation water.
Integrating and managing heterogeneous data “uniformly and virtually” still have a long way to go both at the theoretical and at the practical application levels. Our future work will mainly focus on the following two aspects. In our current evaluation, efficiency of the investigated systems remains an ignored dimension. Therefore, one direction for future work is to design extensive experiments to evaluate the performance and assess the restrictions of each system in integrating and managing heterogeneous data virtually. On the other hand, it is well known that the Semantic Web provides standards for both knowledge and data representation and management. However, integrating heterogeneous data virtually by relying on semantic technologies and Semantic Web standards still represents an open and promising research field. The second main direction we want to take is indeed to develop innovative approaches for ontology-based heterogeneous data integration and management, covering federated query answering, data updates, security, and data quality assurance, where automated logic-based reasoning techniques play a central role.
Footnotes
Acknowledgements
This research has been partially supported by the EU H2020 project INODE (grant agreement No. 863410), by the Italian PRIN project HOPE (2019-2022), by the European Regional Development Fund (ERDF) Investment for Growth and Jobs Programme 2014-2020 through the project IDEE (FESR1133), by the RTD DM 1062/2021 project OntoCRM, by the Free University of Bozen-Bolzano through the project MP4OBDA, and by the “Fusion Grant” project HIVE sponsored by Fondazione Cassa di Risparmio di Bolzano and Ontopic s.r.l. in coordination with NOI Techpark, Südtiroler Wirtschaftsring and Rete Economia Alto Adige. G. Xiao is supported by the Norwegian Research Council via the SIRIUS Centre for Research Based Innovation (grant No. 237898). D. Calvanese is supported by the Wallenberg AI, Autonomous Systems and Software Program (WASP) funded by the Knut and Alice Wallenberg Foundation. We thank our colleagues, in particular Julien Corman, for their discussions and feedback. We would also like to thank the reviewers for their valuable feedback and comments on earlier versions of this article.
Specific data sources supported by the selected systems
Table 7 lists the specific sources supported by each investigated data federation system, obtained from available systems’ documentation and publications. Sources are classified on a local, per-system basis, along the source types defined in Section 6.1, with additional source information – such as the specific kind(s) of relational, graph-based or aggregate-oriented system – reported next to the source name via subscript letters (see table caption for legend). We remark the following:
Some sources correspond to data access interfaces that can be configured to connect additional systems beyond the ones explicitly listed in the table. In particular, companies such as CData34
Structured files are distinguished from other source types with the same data model (e.g., relational sources for CSV files, aggregate-oriented – specifically, document-based – for JSON files) by virtue of direct access to raw file contents by the data federation system. In some cases, however, access to stored structured files may require metadata services external to the filesystem (e.g., Hive Metadata Store) for locating and interpreting file contents, or may leverage processing services (e.g., from Hadoop) co-located with the nodes storing the file in a distributed filesystem (e.g., HDFS), for instance to push down data access operations and computations (e.g., filtering, sorting) close to where raw file data reside, this way reducing communication costs.
Some of the data federation systems investigated in this survey are also listed as supported sources (marked with ∗ subscript) of other systems in Table 7, reflecting the fact that the virtual data sources obtained through data federation can be used themselves in downstream federations. As a limit case (e.g., AllegroGraph), a system may list only itself as a supported data source, which occurs when the system offers both storage and data federation capabilities, and the latter are restricted to instances of the same system.
Test sources (e.g., emulating
Selection of academic systems
We report further details about the academic systems selection process described in Section 3.1, providing: (i) the statistics of the 295 academic publications found in our literature search (Section B.1); (ii) the metadata and the considered systems and aspects for the 17 system comparison publications found among them (Section B.2); (iii) the inclusion criteria satisfied or violated by the 56 academic systems found, which support our selection of 18 academic systems (Section B.3); and (iv) the full bibliography of all the 295 collected academic publications (Section B.4).